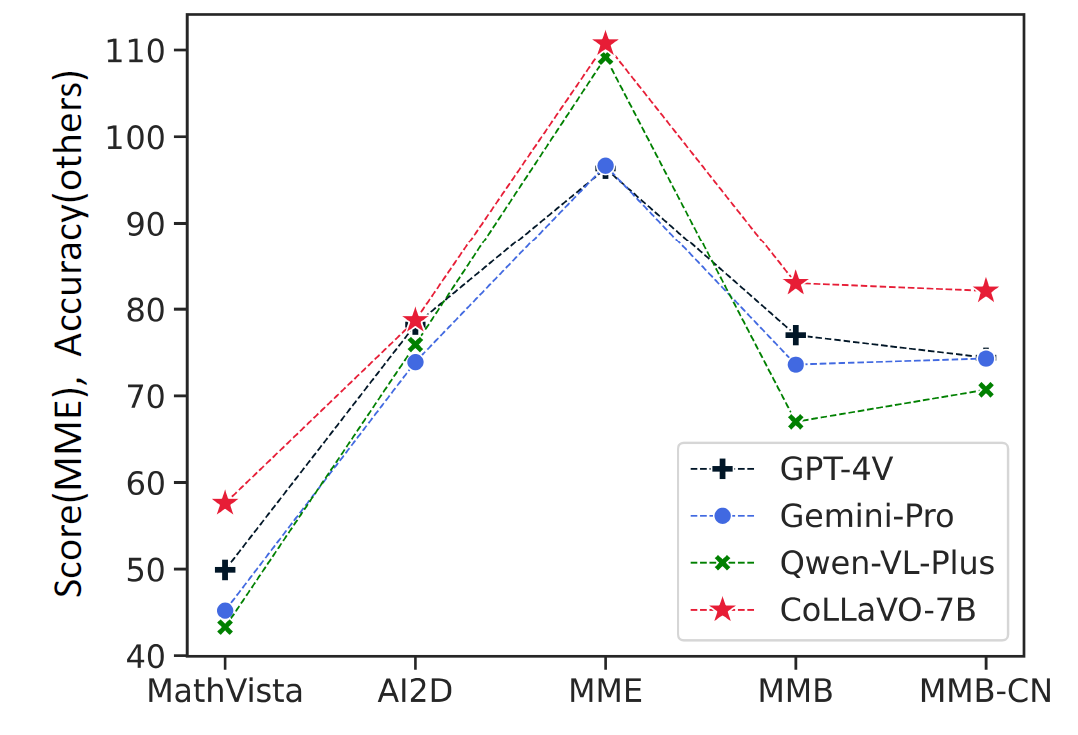
안녕하세요! 오늘은 최근 카이스트에서 개발한 국산 시각-언어 모델 CoLLaVO에 대해 알아보겠습니다. CoLLaVO 모델은 입력 이미지를 분석하여 객체의 의미 정보와 위치 정보를 추출하는 역할을 하는 크레용 프롬프트(Crayon Prompt)를 사용한 팬옵틱 컬러 맵 (Panoptic Colormap) 기반 시각적 프롬프트와, Dual QLoRA 학습전략 구현을 통해, 다양한 비전-언어 태스크에서 뛰어난 제로샷 성능을 보여주며, 객체 인식과 복잡한 이미지 이해에서 탁월한 성과를 냅니다. 이 블로그에서는 CoLLaVO 모델의 개요, 동작원리 및 기술적 특성, 성능평가 결과에 대해 알아보고, 직접 모델에 이미지를 입력해서 텍스트 출력을 확인해 보겠습니다.
https://v.daum.net/v/20240620161614101
오픈AI·구글 넘은 KAIST `멀티모달 AI`
오픈AI의 GPT-4V, 구글의 '제미나이 프로' 등에 비해 시각지능이 10% 이상 우수한 국산 멀티모달 대형언어모델(LLM)이 선보였다. 기존 상업용 비공개 LLM 모델과 달리 누구나 이용할 수 있도록 개방형
v.daum.net
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
CoLLaVO 개요
CoLLaVO(Crayon Large Language and Vision mOdel)는 7B 파라미터를 가진 모델로, 이미지에서 자동차, 사람, 동물 등과 같은 개별 객체들을 더 정확하고 세부적으로 인식하여 이해하는 능력을 높이고, 이를 통해 다양한 비전-언어 태스크에서 뛰어난 성능을 보이는 것을 목표로 하며, 다음과 같은 혁신적인 접근 방식을 도입했습니다:
- 크레용 프롬프트: 팬옵틱 컬러 맵(Panoptic Color map, AI 모델이 이미지의 각 픽셀을 객체와 배경으로 분류하고, 그 결과를 색상으로 시각화한 컬러 맵)을 기반으로 한 새로운 시각적 프롬프트 기법을 도입했습니다. 각 객체를 다양한 색상으로 구분하는 방식은 마치 어린이가 여러 색상의 크레용을 사용하여 그림을 그리는 것과 유사하며, 각 색상은 특정 객체를 나타내고, 색상이 다른 픽셀은 다른 객체를 의미합니다.(배경: 검정, 사람: 빨강, 자동차: 초록 등)
* 팬옵틱 컬러 맵 (Panoptic Colormap) : 이미지 내의 모든 픽셀을 사물분할 및 장면분할 두 가지 방식으로 동시에 분류한 결과를 시각적으로 표현한 것입니다.
- 사물 분할 (Instance Segmentation): 개별 객체(예: 사람, 자동차)를 분할하고 각 객체에 고유한 ID를 부여합니다.
- 장면 분할 (Semantic Segmentation): 배경과 같이 개별 객체로 나눌 수 없는 영역(예: 하늘, 도로)을 분할합니다.
- Dual QLoRA: 두 개의 양자화된 가중치 행렬을 사용해 메모리와 연산 요구량을 줄이는 방법으로 객체 수준의 이미지 이해 능력을 유지하면서도 복잡한 비전-언어 태스크에 대한 성능을 향상시키기 위한 학습 전략입니다.
- 크레용 명령어 튜닝: 시각적 객체의 세분화된 정보를 포함하는 명령어를 생성하는 방법입니다. 여기에는 객체의 의미적 임베딩과 숫자 임베딩을 포함하여, 모델이 객체의 존재와 위치를 더 잘 인식할 수 있도록 합니다. 이러한 접근 방식은 모델이 객체 수준 이미지 이해를 강화하고, 객체의 수를 정확히 파악할 수 있도록 도와주며, 특히 제로샷 학습에서 모델의 성능을 크게 향상시킵니다.
- 비주얼 명령어 튜닝 데이터 세트 활용: 다양한 시각적 명령어 데이터 세트를 활용하여 모델을 학습시키는 방법으로, 여기에는 이미지 설명, 객체 인식, 시각적 추론 등을 포함한 다양한 태스크가 포함됩니다. 이 접근 방식은 모델이 다양한 시각적 정보를 이해하고 처리할 수 있는 능력을 향상시킵니다.
CoLLaVO는 이러한 요소들을 결합하여 객체 수준의 이미지 이해 능력을 크게 향상시키고, 이를 통해 다양한 비전-언어 태스크에서 뛰어난 제로샷 성능을 달성하는 것을 목표로 하며, 실제로 기존의 폐쇄형 및 개방형 VLM들과 비교했을 때 상당한 성능 향상을 보여주고 있습니다.
CoLLaVO 동작원리
다음은 CoLLaVO의 핵심 동작 원리에 대해 알아보겠습니다. CoLLaVO의 구조는 크게 비전 인코더, 크레용 프롬프트, 백본 MLM, MLP 커넥터의 네 가지 주요 구성 요소로 이루어져 있습니다:
- 비전 인코더: CLIP 모델을 사용하여 이미지 이해 능력을 향상시킵니다. CLIP (Contrastive Language–Image Pretraining)는 이미지와 텍스트 간의 관계를 학습하여, 텍스트 설명과 일치하는 이미지를 찾거나, 이미지에 대한 텍스트 설명을 생성할 수 있는 능력을 가지고 있습니다.
- 크레용 프롬프트: 객체 수준의 이미지 이해를 위한 새로운 시각적 프롬프트 기법입니다. 시각적 프롬프트란 이미지와 같은 시각적 정보를 사용하여 모델에게 특정 작업을 수행하도록 유도하는 방법이며, 여기에는 이미지 캡셔닝, 비주얼 질문 답변, 이미지 분류 등 다양한 작업이 포함됩니다.
- 백본 MLM(Multimodal Language Model): InternLM-7B를 기반으로 한 다국어 기초 모델입니다.
- MLP(Multilayer Perceptron, 다층 퍼셉트론) 커넥터: MLP 커넥터는 비전 컴포넌트(이미지 처리) 언어 컴포넌트(텍스트 처리)를 연결하는 역할을 함으로써, 이미지의 특성과 텍스트의 의미를 결합하여 이미지 설명 생성, 이미지-텍스트 일치 여부 판별 등의 작업을 수행할 수 있습니다.
크레용 프롬프트
크레용 프롬프트는 CoLLaVO의 핵심 혁신 기술입니다. AI 모델이 이미지의 각 픽셀을 객체와 배경으로 분류하고, 그 결과를 색상으로 시각화한 팬옵틱 컬러 맵(Panoptic Color map)을 기반으로 하며, 이 컬러 맵은 이미지에서 어떤 부분이 어떤 객체인지, 또는 배경인지 쉽게 파악할 수 있도록 도와줍니다. 크레용 프롬프트는 입력 이미지를 분석하여 객체의 의미 정보와 위치 정보를 추출하는 역할을 합니다.
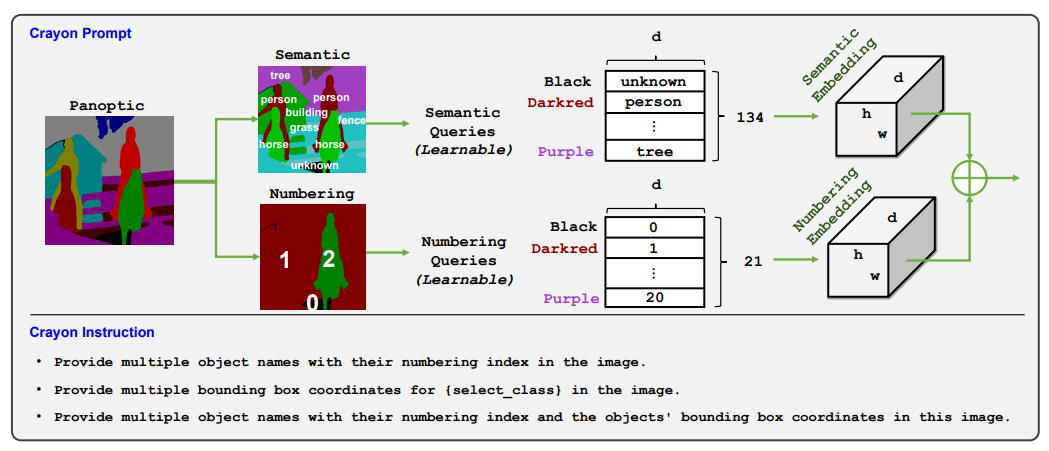
크레용 프롬프트의 생성 과정은 다음과 같습니다.
- 팬옵틱 입력: 먼저, 다양한 객체가 포함된 이미지가 입력됩니다.
- 의미 정보 추출: 입력 이미지에서 각 객체의 의미 정보(예: 사람, 나무, 말, 잔디)를 추출합니다. 이때, 각 객체에는 고유한 색상이 부여됩니다.
- 번호부여 정보 추출: 동시에, 각 객체에 고유한 번호를 부여하여 구분합니다.
- 의미정보 쿼리 및 번호부여 쿼리: 추출된 의미정보와 번호부여 정보는 각각 의미정보 쿼리와 번호부여 쿼리로 변환됩니다. 이 쿼리는 학습 가능한 형태로, 이미지의 특징을 잘 나타낼 수 있도록 설계됩니다.
- 의미정보 임베딩 및 번호부여 임베딩: 각 쿼리는 의미정보 임베딩과 번호부여 임베딩으로 변환됩니다. 이 임베딩은 각 객체의 의미 정보와 위치 정보를 고차원 벡터 공간에 나타냅니다.
- 정보 통합 및 출력: 마지막으로 두 임베딩 정보는 하나로 통합되어 다양한 작업에 활용될 수 있습니다.
크레용 프롬프트를 통해 "사람 1", "나무 2" 와 같은 객체 이름 및 번호 또는 객체에 대한 Bounding Box 좌표 정보 등 다양한 정보를 얻을 수 있으며, 이를 이용해서 이미지 검색, 객체 인식, 이미지 캡션 생성 등 다양한 작업에 활용할 수 있습니다.
학습 전략 및 학습 과정
CoLLaVO는 Dual QLoRA라는 독특한 학습 전략을 사용합니다. 이 전략은 두 개의 QLoRA(Quantized Low-Rank Adaptation) 모듈을 사용하여 객체 수준의 이미지 이해 능력과 비전-언어 태스크 성능을 동시에 유지하고 향상시킵니다. QLoRA는 모델 파라미터를 양자화하여 메모리 사용량을 줄이면서도 학습 성능을 유지할 수 있게 해 줍니다.
- 첫 번째 QLoRA 모듈: 크레용 명령어 세트에 대한 학습을 담당합니다. 이 모듈은 크레용 명령어 세트를 사용하여 객체 수준의 이미지 이해 능력을 강화합니다.
- 두 번째 QLoRA 모듈: 비주얼 명령어 튜닝 데이터 세트를 기반으로 학습됩니다. 이 모듈은 복잡한 비전-언어 태스크에 대한 성능을 향상시키는 데 중점을 둡니다.
크레용 명령어 세트는 크레용 프롬프트와 함께 사용되어 모델이 이미지 내의 객체들을 더 정확하게 식별하고 이해할 수 있도록 돕습니다. 예를 들어 "이미지에 {객체 이름}이 있습니까?", "지정된 바운딩 박스 [xmin, ymin, xmax, ymax]에 있는 객체는 무엇입니까?"와 같은 크레용 명령어는 모델이 객체의 존재 여부를 판단하고, 특정 위치의 객체를 식별하는 능력을 향상시키는 데 중점을 둡니다.
비주얼 명령어 튜닝 데이터 세트 (예: LLaVA-Instruct-665K)을 활용하여 다양한 비전-언어 태스크에 대한 제로샷 성능을 향상시킵니다. 이 데이터 세트들은 복잡한 시각적 추론, 상세한 이미지 설명, 다단계 시각적 대화 등 다양한 유형의 태스크를 포함하고 있어 모델의 종합적인 비전-언어 능력을 향상시키는 데 도움이 됩니다.
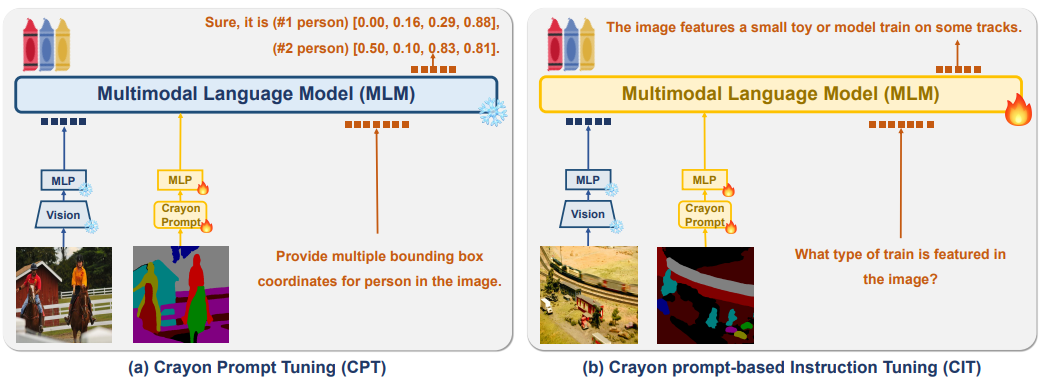
위 다이어그램은 두 가지 다중 모드 프롬프트 기술, 즉 (a) 크레용 프롬프트 튜닝(CPT) 및 (b) 크레용 프롬프트 기반 명령 튜닝(CIT)을 보여줍니다. 두 기술 모두 이미지 이해 및 생성을 개선하기 위해 다중모드 언어 모델(이하 MLM)에 시각적 정보를 통합하는 것을 목표로 합니다.
- 크레용 프롬프트 튜닝(CPT): 입력 이미지는 먼저 시각적 특징을 추출하는 시각 인코더를 통해 전달되고, 이러한 시각적 특징은 시각적 표현으로 변환된 다음 MLM에 공급되는 일련의 크레용 프롬프트를 생성하는 데 사용되며, MLM은 이미지에 있는 개체에 대한 경계 상자 좌표와 같은 시각적 정보를 나타내는 텍스트 출력을 생성합니다. 예: 다이어그램에서 CPT는 두 사람이 말을 타고 있는 이미지에 "(#1 사람) [0.00, 0.16, 0.29, 0.88], (#2 사람) [0.50, 0.10, 0.83, 0.81]입니다."라는 경계 상자 좌표를 제공합니다.
- 크레용 프롬프트 기반 명령 튜닝(CIT): CIT는 이미지에 대한 특정 질문에 답변하도록 MLM을 훈련하여 CPT를 기반으로 합니다. CPT와 유사하게 이미지는 시각 인코더를 통해 처리되고 크레용 프롬프트가 생성됩니다. 추가적으로 이미지에 대한 텍스트 기반 명령("이미지에 등장하는 열차의 유형은 무엇입니까?")도 MLM에 입력됩니다. MLM은 제공된 이미지와 텍스트 명령을 모두 기반으로 질문에 대한 텍스트 응답("모형 열차")을 생성합니다.
- 핵심 차이점: CPT는 객체 감지 및 경계 상자 생성과 같은 객체 수준 이해에 중점을 둡니다. CIT는 이미지에 대한 질문 답변과 같은 더 높은 수준의 추론 작업을 목표로 하여 MLM이 시각적 입력에서 의미론적 정보를 추론할 수 있도록 합니다.
CoLLaVO의 이러한 기술적 특성들은 객체 수준의 이미지 이해 능력과 복잡한 비전-언어 태스크 성능을 동시에 향상시키는 데 기여합니다. 크레용 프롬프트를 통한 세밀한 객체 정보 제공, Dual QLoRA를 통한 효과적인 학습 전략, 그리고 크레용 명령어와 비주얼 명령어 튜닝 데이터 세트의 조화로운 활용은 CoLLaVO가 기존 VLM들과 차별화되는 핵심 요소입니다.
CoLLaVO 성능평가 결과
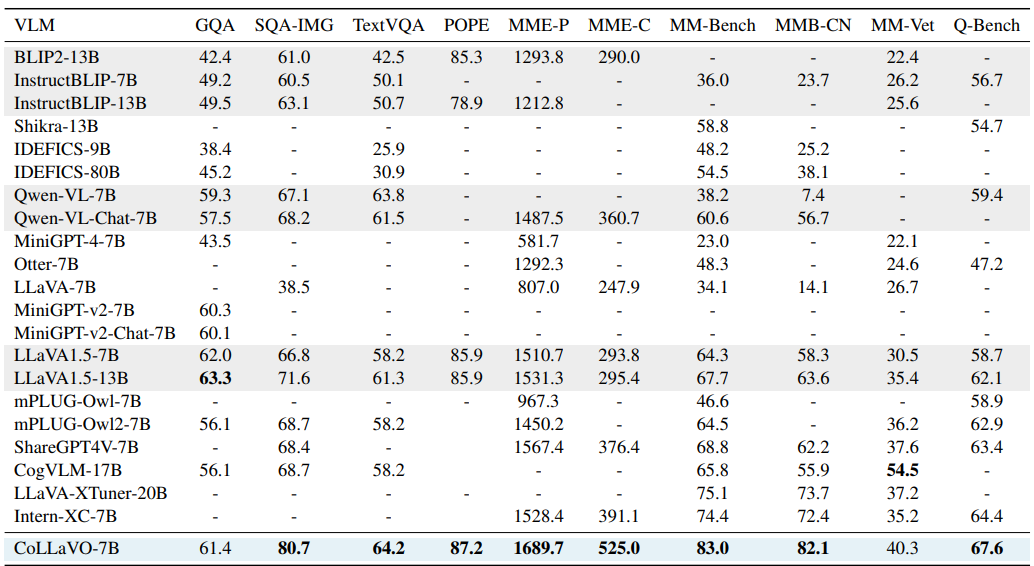
CoLLaVO의 성능은 다양한 비전-언어 태스크에서 평가되었으며, 특히 제로샷 설정에서 뛰어난 결과를 보여주었습니다. 주요 성능 평가 결과는 다음과 같습니다.
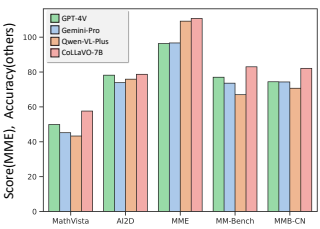
1) 객체 수준 이미지 이해 능력
CoLLaVO는 Class2Binary(C2B)와 Box2Class(B2C) 두 가지 유형의 질문을 통해 객체 수준 이미지 이해 능력을 평가받았습니다. 결과는 기존의 강력한 베이스라인 모델들(BLIP2, InstructBLIP, LLaVA1.5, Qwen-VL)과 비교되었습니다.
- Class2Binary(C2B): 이 이미지에 {객체 이름}이 있나요?
- Box2Class(B2C): ‘지정된 바운딩 박스 [xmin, ymin, xmax, ymax] 안에 어떤 객체가 있나요?’
CoLLaVO는 대부분의 객체 카테고리에서 베이스라인 모델들보다 높은 C2B와 B2C 정확도를 보여주었습니다. 특히, 기존 모델들이 어려워하던 작은 크기의 객체나 비일상적인 객체들에 대해서도 향상된 인식 능력을 보였습니다.
2) 제로샷 비전-언어 태스크 성능
CoLLaVO는 다양한 벤치마크 데이터 세트에서 제로샷 성능을 평가받았습니다. 주요 결과는 다음과 같습니다.
- VQAv2(Visual Question Answering v2): 이미지에 대한 질문에 답하는 모델의 능력을 평가하는 데이터셋에서 CoLLaVO-7B는 78.2%의 정확도를 달성하여, GPT-4V(77.2%)와 Gemini Pro(78.0%)를 뛰어넘었습니다.
- GQA(Graph Question Answering): 시각적 그래프 구조를 기반으로 질문에 답변하는 능력을 평가하는 데이터셋에서 61.8%의 정확도로 GPT-4V(60.0%)를 상회하는 성능을 보였습니다.
- TextVQA: 이미지 내의 텍스트 정보를 활용하여 질문에 답변하는 능력을 평가하는 데이터셋에서는 62.7%의 정확도로 GPT-4V(59.3%)와 Gemini Pro(61.9%)를 모두 앞섰습니다.
- POPE (Presence of Objects and People Evaluation): 이미지 내에 특정 객체나 사람의 존재 여부를 판단하는 능력을 평가하는 지표에서 85.9%의 정확도를 기록하여 최고 성능을 달성했습니다.
3) 다양한 비전-언어 태스크에서의 성능
CoLLaVO는 이미지 캡셔닝, 시각적 추론, 객체 위치 파악 등 다양한 태스크에서도 우수한 성능을 보여주었습니다:
- COCO 캡션: 인간 평가에서 높은 점수를 받아 상세하고 정확한 이미지 설명 능력을 입증했습니다.
- 시각적 추론: 복잡한 시각적 정보를 바탕으로 한 추론 질문에 대해 정확하고 논리적인 답변을 제공했습니다.
- 객체 위치 파악: Crayon Prompt의 도움으로 이미지 내 특정 객체의 위치를 정확히 파악하는 능력을 보여주었습니다.
4) 모델 크기 대비 효율성
CoLLaVO-7B는 7B 파라미터 규모의 모델임에도 불구하고, 대부분의 태스크에서 GPT-4V나 Gemini Pro와 같은 훨씬 더 큰 규모의 모델들과 비교 가능한, 때로는 더 뛰어난 성능을 보여주었습니다. 이는 CoLLaVO의 효율적인 아키텍처와 학습 전략이 모델 크기 대비 높은 성능을 달성했음을 보여줍니다.
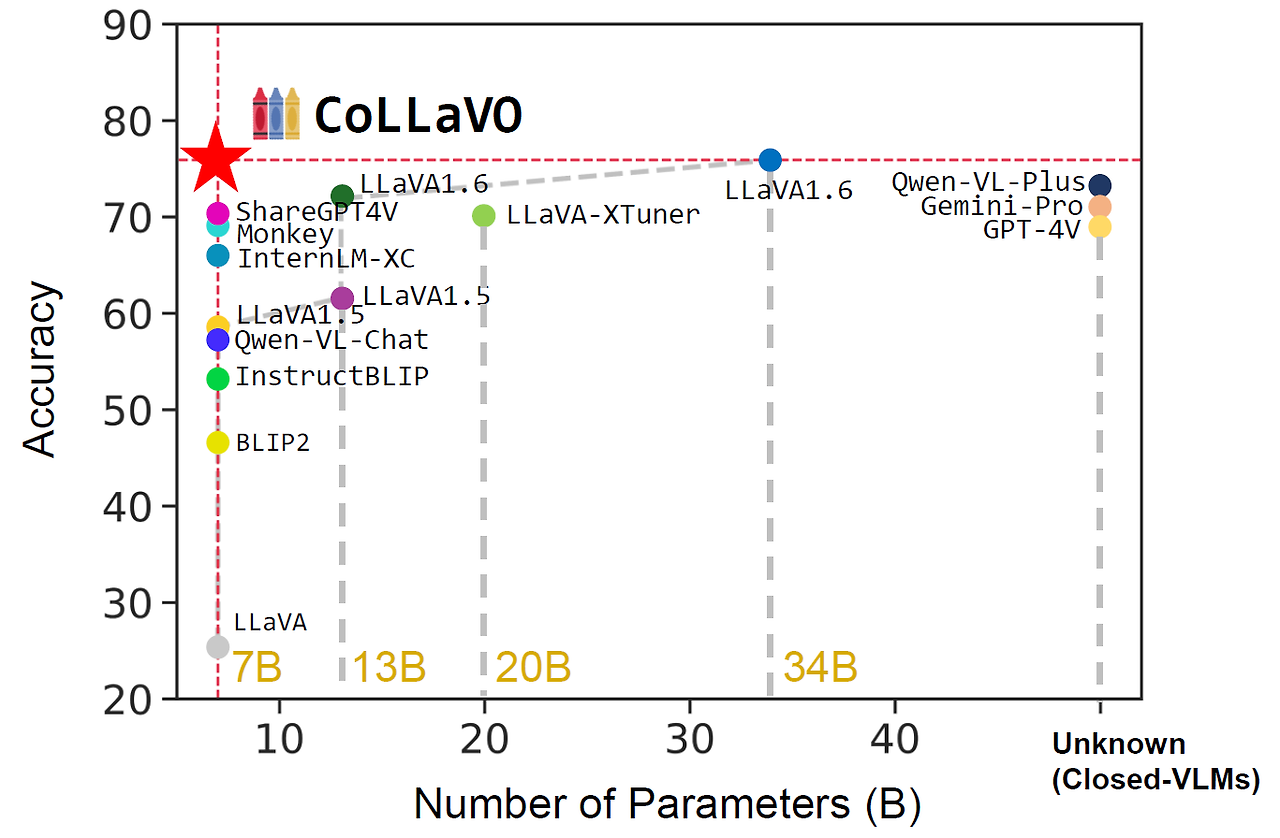
이러한 종합적인 성능 평가 결과는 CoLLaVO가 객체 수준의 이미지 이해 능력과 복잡한 비전-언어 태스크 성능을 동시에 향상시키는 데 성공했음을 보여줍니다. 특히, 제로샷 설정에서 최첨단 폐쇄형 및 개방형 VLM들과 비교했을 때 경쟁력 있는, 때로는 더 우수한 성능을 보여주었다는 점이 주목할 만합니다.
DEMO 테스트
다음은 CoLLaVO-7B 모델을 사용한 DEMO 테스트입니다. 전체 과정은 이미지를 로딩하고, CoLLaVO 모델을 사용하여 이미지 설명 텍스트를 생성하며, 이를 디코딩하여 출력하는 것입니다.
https://github.com/ByungKwanLee/CoLLaVO
GitHub - ByungKwanLee/CoLLaVO: Official PyTorch Implementation code for realizing the technical part of CoLLaVO: Crayon Large La
Official PyTorch Implementation code for realizing the technical part of CoLLaVO: Crayon Large Language and Vision mOdel to significantly improve zero-shot vision language performances (ACL 2024 Fi...
github.com
DEMO 테스트를 위한 이 블로그의 시스템 환경은 LightningAI를 이용하였으며, 작업순서는 다음과 같습니다. LightningAI에 대한 내용은 아래 포스팅을 참고하세요
2024.06.02 - [AI 도구] - ⚡️🆓Lightning AI: 무료 GPU 클라우드 기반 AI 개발 플랫폼 Ollama 가이드
⚡️🆓Lightning AI: 무료 GPU 클라우드 기반 AI 개발 플랫폼 Ollama 가이드
안녕하세요! 오늘은 Lightning AI라는 클라우드 컴퓨팅 기반 AI 개발 플랫폼을 소개해 드리겠습니다. Lightning AI는 머신러닝(ML)과 인공지능(AI) 프로젝트를 빠르고 효율적으로 개발, 프로토타입, 훈련,
fornewchallenge.tistory.com
1. 깃허브 리포지토리 복제 및 GPU 전환: 깃허브 저장소를 복제하고, LightningAI의 CPU를 GPU로 전환합니다.
git clone https://github.com/ByungKwanLee/CoLLaVO
2. CUDA 11.8 이상 호환버전 설치
- 기존 CUDA 제거 (이미 설치되어 있는 경우)
sudo apt-get --purge remove "*cuda*" "*cublas*" "*cufft*" "*cufile*" "*curand*" "*cusolver*" "*cusparse*" "*gds-tools*" "*npp*" "*nvjpeg*" "nsight*" "*nvvm*"- CUDA 저장소 추가 및 패키지 목록 업데이트
*CUDA 저장소 추가:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda-repo-ubuntu2204-11-8-local_11.8.0-520.61.05-1_amd64.deb sudo dpkg -i cuda-repo-ubuntu2204-11-8-local_11.8.0-520.61.05-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-11-8-local/cuda-*-keyring.gpg /usr/share/keyrings/
*패키지 목록 업데이트:
sudo apt-get update

- CUDA 11.8 설치:
sudo apt-get -y install cuda-11-8
- 환경 변수 설정:
'export PATH=/usr/local/cuda-11.8/bin${PATH:+:${PATH}}' >> ~/.bashrc
'export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}' >> ~/.bashrc
source ~/.bashrc- 설치 확인: nvcc --version

python -c "import torch; print(f'PyTorch version: {torch.__version__}'); print(f'CUDA available: {torch.cuda.is_available()}'); print(f'CUDA version: {torch.version.cuda}')"위 명령어를 실행하면 다음과 같이 CUDA 버전과 PyTorch 버전이 나오면 정상입니다.

3. 의존성 설치: 다음 명령어로 의존성 라이브러리와 패키지를 설치합니다.
pip install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
pip install -r assets/requirements/requirements.txt
pip install git+https://github.com/cocodataset/panopticapi.git
pip install git+https://github.com/MaureenZOU/detectron2-xyz.git
pip install git+https://github.com/huggingface/transformers
pip install git+https://github.com/arogozhnikov/einops.git
pip install flash-attn --no-build-isolation
4. 환경변수 설정: 아래 명령어를 복사해서 환경변수를 설정합니다.
export DETECTRON2_DATASETS=/teamspace/studios/this_studio/CoLLaVO/datasets
export DATASET=/teamspace/studios/this_studio/CoLLaVO/datasets
export DATASET2=/teamspace/studios/this_studio/CoLLaVO/datasets
export VLDATASET=/teamspace/studios/this_studio/CoLLaVO/datasets
5. DEMO 코드 실행: CoLLaVO 디렉토리 밑에 demo.py를 실행합니다. 코드는 다음과 같이 6단계로 실행됩니다.
- 1단계: 이미지 로딩
- 2단계: 지시 프롬프트 설정
- 3단계: CoLLaVO 모델 로딩
- 4단계: CoLLaVO 전처리
- 5단계: 텍스트 생성
- 6단계: 결과 디코딩
import torch
torch.cuda.empty_cache()
# [1] Loading Image
from PIL import Image
from torchvision.transforms import Resize
from torchvision.transforms.functional import pil_to_tensor
image_path = "figures/crayon_image.jpg"
image = Resize(size=(490, 490), antialias=False)(pil_to_tensor(Image.open(image_path)))
# [2] Instruction Prompt
prompt = "Describe this image in detail"
# [3] Loading CoLLaVO
from collavo.load_collavo import prepare_collavo
collavo_model, collavo_processor, seg_model, seg_processor = prepare_collavo(collavo_path='BK-Lee/CoLLaVO-7B', bits=4, dtype='fp16')
# [4] Pre-processing for CoLLaVO
collavo_inputs = collavo_model.demo_process(image=image,
prompt=prompt,
processor=collavo_processor,
seg_model=seg_model,
seg_processor=seg_processor,
device='cuda:0')
# [5] Generate
import torch
from torch.cuda.amp import autocast
with torch.inference_mode(), autocast():
generate_ids = collavo_model.generate(**collavo_inputs, do_sample=True, temperature=0.9, top_p=0.95, max_new_tokens=256, use_cache=True)
# [6] Decoding
answer = collavo_processor.batch_decode(generate_ids, skip_special_tokens=True)[0].split('[U')[0]
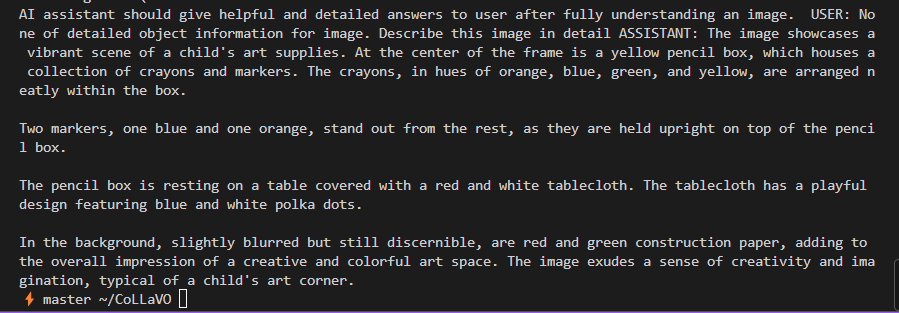
print(answer)

 |
 |
| The image showcases a vibrant scene of a child's art supplies. At the center of the frame is a yellow pencil box, which houses a collection of crayons and markers. The crayons, in hues of orange, blue, green, and yellow, are arranged n eatly within the box. Two markers, one blue and one orange, stand out from the rest, as they are held upright on top of the penci l box. The pencil box is resting on a table covered with a red and white tablecloth. The tablecloth has a playful design featuring blue and white polka dots. In the background, slightly blurred but still discernible, are red and green construction paper, adding to the overall impression of a creative and colorful art space. The image exudes a sense of creativity and imagination, typical of a child's art corner. | The image portrays a woman in a vibrant red and white martial arts outfit, standing confidently on a city street. Her long black hair is tied up, adding to her poised stance. She is holding a sword and a fire torch in her hands, ready for action. The city street behind her is alive with colorful lights and buildings, providing a stark contrast to her fiery attire. The woman's gaze is directed towards the camera, capturing the viewer's attention. The image is devoid of any text. The relative positions of the objects are such that the woman is in the foreground, while the city street forms the backdrop. The colors in the image are predominantly red, black, and white, reflecting the martial arts theme. The image does not contain any other objects or people, focusing solely on the woman and her surroundings. |
| 이 이미지는 어린이의 미술 용품을 생생하게 보여줍니다. 프레임 중앙에는 노란색 연필 상자가 있으며, 그 안에는 크레용과 마커들이 들어 있습니다. 크레용들은 주황색, 파란색, 녹색, 노란색 등의 색조로 상자 안에 깔끔하게 정리되어 있습니다. 두 개의 마커, 하나는 파란색이고 다른 하나는 주황색인데, 연필 상자 위에 똑바로 서 있어 다른 것들과 구별됩니다. 연필 상자는 빨간색과 흰색 체크무늬 테이블보로 덮인 테이블 위에 놓여 있습니다. 테이블보에는 파란색과 흰색 물방울 무늬가 재미있게 디자인되어 있습니다. 배경에는 약간 흐릿하지만 여전히 식별 가능한 빨간색과 녹색 건축용 종이가 보이며, 이는 전체적으로 창의적이고 다채로운 미술 공간의 인상을 더해줍니다. 이 이미지는 어린이의 미술 공간에서 전형적으로 볼 수 있는 창의성과 상상력의 분위기를 자아냅니다. | 이미지는 활기찬 빨간색과 흰색 무술 의상을 입고 도시 거리에 자신감 있게 서 있는 여성을 묘사합니다. 그녀의 긴 검은 머리는 묶여 있으며, 이는 그녀의 당당한 자세를 더욱 돋보이게 합니다. 그녀는 칼과 화염 토치를 손에 들고 있으며, 행동을 취할 준비가 되어 있습니다. 그녀 뒤의 도시 거리는 다채로운 불빛과 건물들로 활기를 띠고 있으며, 그녀의 불타는 의상과 강렬한 대비를 이룹니다. 여자의 시선은 카메라를 향해 있어 보는 이의 시선을 사로잡습니다. 이미지에는 텍스트가 전혀 없습니다. 객체들의 상대적 위치는 여자가 전경에 있고 도시 거리가 배경을 형성하도록 구성되어 있습니다. 이미지의 색상은 주로 빨간색, 검은색, 흰색으로 구성되어 있으며, 무술 테마를 반영합니다. 이미지는 다른 객체나 사람을 포함하지 않고 오로지 여자와 그녀의 주변 환경에만 집중하고 있습니다. |
 |
 |
| The image captures a close-up view of a person's eye, which is the central focus of the frame. The eye is open, revealing its blue iris that has a mesmerizing pattern of yellow and orange colors, resembling a flower in full bloom. The eyelashes are long and dark, framing the eye beautifully. The skin surrounding the eye has a slight pinkish hue, adding a soft contrast to the vibrant colors of the eye. The background is blurred and indistinguishable, ensuring that the eye remains the sole point of interest in this image. The image does not contain any discernible text. The relative position of the objects in the image places the eye in the center, with the surrounding elements serving to highlight its unique characteristics. | In the midst of a vibrant stadium, a young man confidently strides across the blue playing field. His attire is sporty and practical, with a black tank top clinging to his well-muscled torso, and a pair of white shorts contrasting against his skin. His arms, a testament to his strength, are adorned with black wrist wraps, adding an element of toughness to his ensemble. A gray headband encircles his forehead, holding back his dark hair that falls in soft waves. His blue eyes, full of determination, meet the camera's gaze as he looks over his shoulder, perhaps acknowledging the spectators in the stands. The image captures a moment of intensity and focus, set against the backdrop of a bustling sporting event. |
| 이미지는 사람의 눈을 클로즈업으로 담고 있으며, 눈이 프레임의 중심 초점입니다. 눈은 열려 있으며, 파란색 홍채는 마치 만개한 꽃처럼 보이는 노란색과 주황색의 매혹적인 패턴을 드러내고 있습니다. 긴 속눈썹은 짙은 색으로 눈을 아름답게 감싸고 있습니다. 눈 주위의 피부는 약간 분홍빛을 띠고 있어 눈의 생생한 색상과 부드러운 대비를 이룹니다. 배경은 흐릿하고 구별할 수 없게 처리되어 있어 눈이 이 이미지에서 유일한 관심의 초점으로 남아 있습니다. 이미지에는 식별 가능한 텍스트가 포함되어 있지 않습니다. 이미지 속 객체들의 상대적 위치는 눈을 중심에 배치하고, 주변 요소들은 눈의 독특한 특성을 강조하는 역할을 합니다. | 활기찬 경기장 한가운데서, 한 젊은 남자가 파란 경기장을 자신 있게 가로질러 걷고 있습니다. 그의 옷차림은 운동에 적합하며, 검은색 탱크톱은 잘 발달된 그의 상체에 딱 맞고, 흰색 반바지는 그의 피부와 대조를 이룹니다. 그의 팔은 강인함을 증명하듯 검은색 손목 보호대를 착용하고 있으며, 그의 차림에 터프함을 더해줍니다. 회색 머리띠가 그의 이마를 감싸고 있으며, 부드러운 파도로 떨어지는 그의 검은 머리를 뒤로 젖히고 있습니다. 결의에 찬 그의 파란 눈은 카메라의 시선을 마주하며, 아마도 관중석에 있는 사람들을 의식하고 있는 듯합니다. 이 이미지는 분주한 스포츠 이벤트를 배경으로 한 집중과 열정의 순간을 포착하고 있습니다. |
한글로 응답하도록 시스템 프롬프트를 변경해 보았는데, 만족할만한 응답은 나오지 않았습니다.

맺음말
CoLLaVO(Crayon Large Language and Vision mOdel)는 KAIST에서 개발한 혁신적인 시각-언어 모델로, 객체 수준의 이미지 이해 능력과 복잡한 비전-언어 태스크 성능을 동시에 향상시키는 데 성공했습니다. 크레용 프롬프트, Dual QLoRA 학습 전략, 그리고 효과적인 객체 인식 기술의 조합을 통해 CoLLaVO는 다양한 벤치마크에서 GPT-4V나 Gemini Pro와 같은 대규모 모델들과 경쟁할 수 있는, 때로는 더 뛰어난 성능을 보여주었습니다.
특히 주목할 만한 점은 CoLLaVO-7B가 단 7B 파라미터로 이러한 성과를 달성했다는 것입니다. 이는 모델의 효율성과 혁신적인 아키텍처의 중요성을 잘 보여줍니다. 또한 이 모델이 개방형으로 공개되어 있어, 연구자들과 개발자들이 자유롭게 활용하고 발전시킬 수 있다는 점도 큰 의의가 있습니다.
데모 테스트는 CoLLaVO의 실제 성능을 체험할 수 있는 좋은 기회였으며, 비록 한글 응답에서는 아직 개선의 여지가 있지만, 영어 응답에서 보여준 세밀한 이미지 묘사 능력은 인상적이었습니다. 앞으로 CoLLaVO의 다국어 지원이 강화되어 한국어를 포함한 다양한 언어에서도 뛰어난 성능을 보여주길 기대해 보면서, 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.02.08 - [AI 언어 모델] - LLaVA NeXT: 제미나이 프로를 뛰어넘는 오픈소스 멀티모달 AI!
LLaVA NeXT: 제미나이 프로를 뛰어넘는 오픈소스 멀티모달 AI!
안녕하세요! 오늘은 멀티모달 대규모 언어 모델 LLaVA의 업데이트 소식에 대해 알아보겠습니다. LLaVA (Language-Image Visual Assistant, 언어-이미지 시각 어시스턴트)는 시각적 지시 조정기술(Visual Instructi
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| ✨구글 Gemma 2 분석: 최신 오픈소스 모델로 무료 챗봇 만들기 🤖🔓 (2) | 2024.06.29 |
|---|---|
| 🖥️마이크로소프트 Florence-2 리뷰: 0.7B 비전 모델의 혁신🚀 (0) | 2024.06.28 |
| Claude 3.5 Sonnet: GPT-4o를 뛰어넘은 성능 및 새로운 인터페이스 Artifacts 리뷰 (0) | 2024.06.22 |
| DeepSeek-Coder-V2: 현존 최강 AI 코딩 언어 모델 분석 및 테스트 (0) | 2024.06.20 |
| Stable Diffusion 3 Medium: 최신 T2I 모델 설치와 활용법(SwarmUI) (2) | 2024.06.15 |



