안녕하세요! 오늘은 엔트로픽의 최신 대형 언어 모델 Claude 3.5 Sonnet에 대해서 알아보겠습니다. 이 모델은 경쟁 모델들과 이전 버전인 Claude 3 Opus를 뛰어넘는 성능을 가지면서도, 중급 모델인 Claude 3 Sonnet의 속도와 비용 효율성을 유지하며, 특히 대학원 수준의 추론 능력(GPQA), 학부 수준의 지식(MMLU), 그리고 코딩 능력(HumanEval) 등에서 업계 최고 수준의 벤치마크를 기록했습니다. 이 블로그에서는 Claude 3.5 Sonnet 모델의 개요 및 특징, 주요 성능에 대해 살펴보고, 새로운 인터페이스인 Artifact 기능에 대해 알아보고, 추론성능과 코딩 성능을 테스트해 보겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Claude 3.5 Sonnet 개요
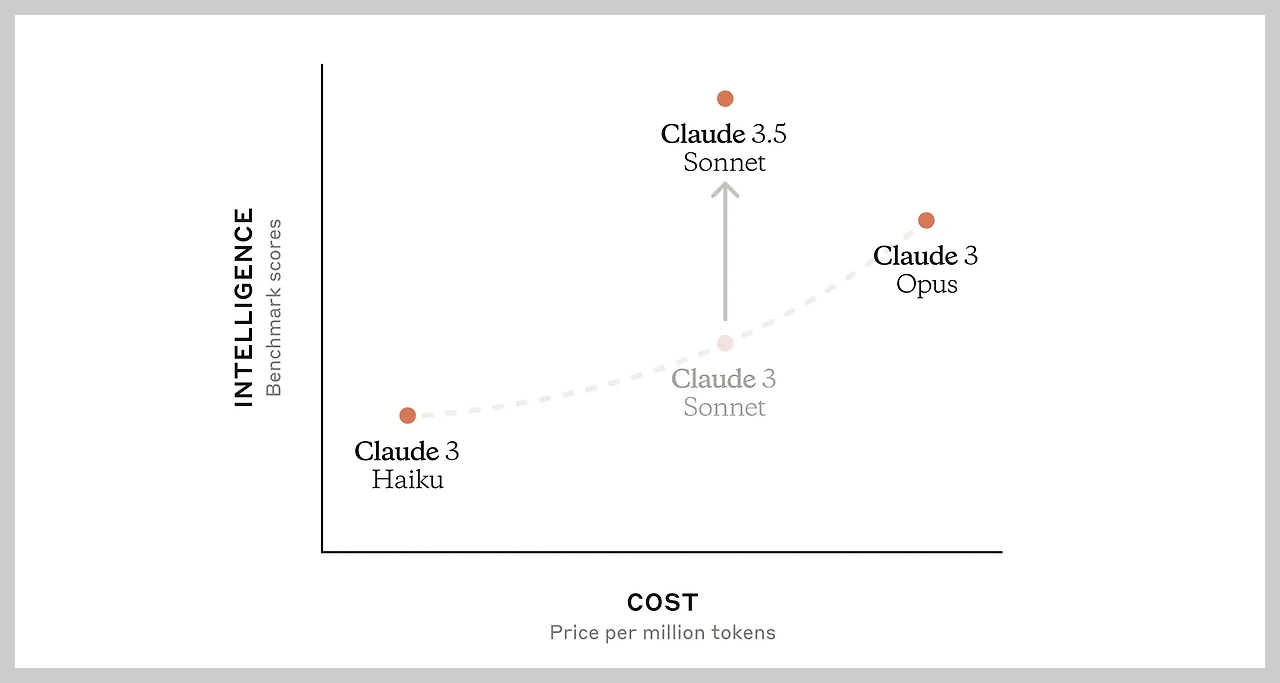
Claude 3.5 Sonnet은 Claude 3.5 모델 제품군의 첫 번째 모델로, 속도와 성능 모두에서 기존 모델보다 뛰어나며, Claude 3 Opus의 2배 속도로 작동하면서 내부 평가에서 코딩 문제의 64%를 해결하여 Claude 3 Opus의 38%에 비해 더 나은 성능을 보입니다. 비용 측면에서도 입력 토큰 백만 개당 3달러, 출력 토큰 백만 개당 15달러로, GPT-4o(입력/출력 토큰 백만 개당 5달러/15달러) 보다 합리적인 가격으로 이용할 수 있으며, 또한, 문맥창 길이는 200K 토큰으로 GPT-4o(120K 토큰) 보다 훨씬 넓어 더욱 풍부한 정보를 기반으로 작업을 수행할 수 있습니다.
Claude 3.5 Sonnet은 Claude.ai와 Claude iOS 앱에서 무료로 제공되며, Claude Pro 및 Team 플랜 구독자들은 훨씬 높은 사용 한도 내에서 이 모델을 이용할 수 있습니다. 또한, Anthropic API, Amazon Bedrock, Google Cloud의 Vertex AI를 통해서도 이용할 수 있습니다. AI 채팅 플랫폼인 Poe(https://poe.com/)에서도 Claude 3.5 Sonnet을 만나실 수 있습니다.
https://www.anthropic.com/news/claude-3-5-sonnet
Introducing Claude 3.5 Sonnet
Introducing Claude 3.5 Sonnet—our most intelligent model yet. Sonnet now outperforms competitor models and Claude 3 Opus on key evaluations, at twice the speed.
www.anthropic.com
Claude 3.5 Sonnet 주요 성능
Claude 3.5 Sonnet의 주요 성능은 크게 지능, 속도, 코딩 능력, 시각적 이해 네 가지 영역에서 두각을 나타냅니다.
1. 지능과 추론 능력
Claude 3.5 Sonnet은 복잡한 추론과 지식 적용 능력에서 뛰어난 성과를 보여주고 있습니다. 대학원 수준의 추론을 요구하는 GPQA(Graduate-level Professional Quality Assessment) 테스트와 학부 수준의 지식을 평가하는 MMLU(Massive Multitask Language Understanding) 테스트에서 업계 최고 수준의 성능을 보였습니다. 이는 Claude 3.5 Sonnet이 단순히 정보를 저장하고 검색하는 것을 넘어, 과학적 가설을 분석하거나 철학적 개념을 논의하는 등 복잡한 문제를 이해하고 해결할 수 있는 능력을 갖추고 있음을 의미합니다.
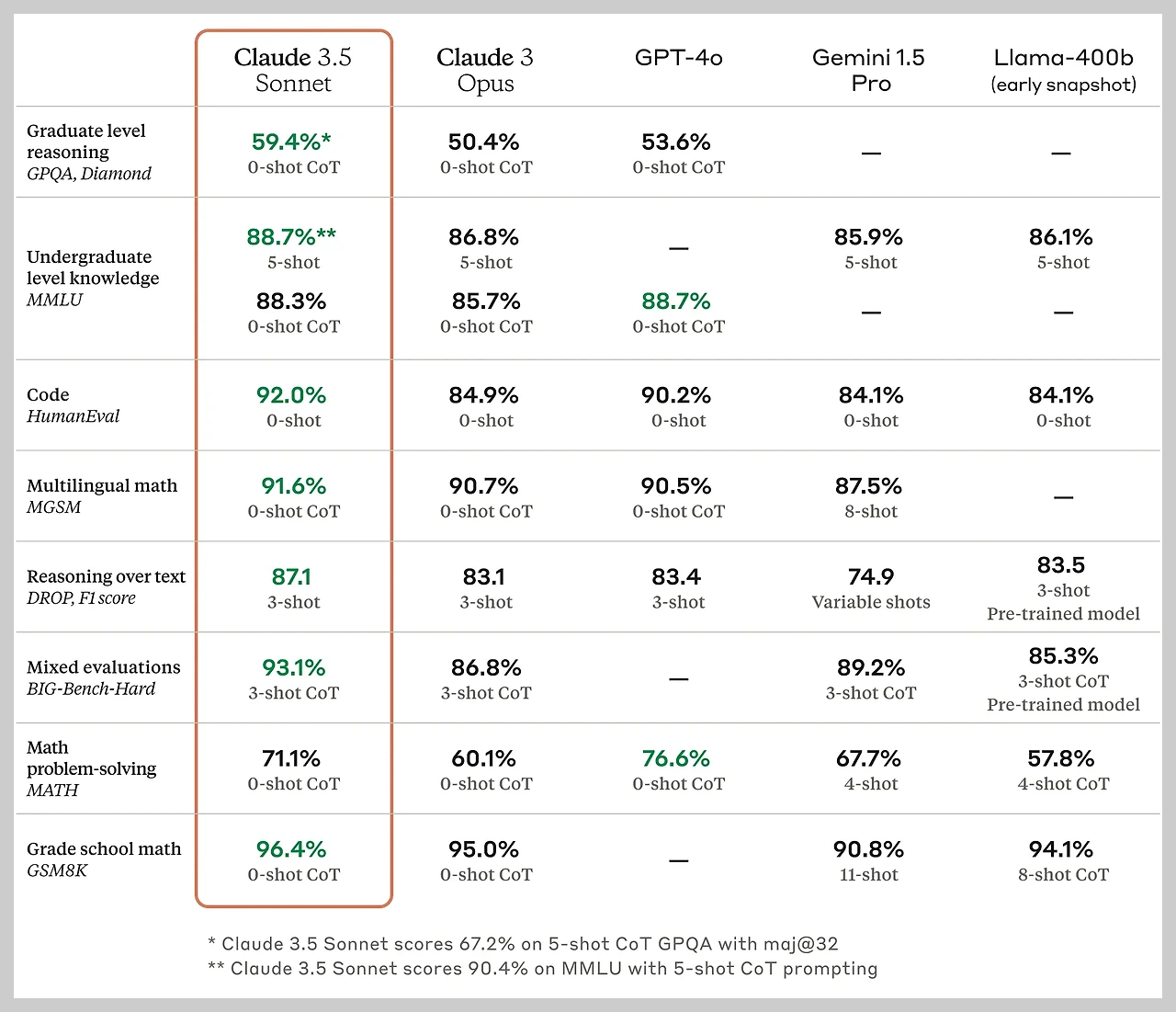
- Graduate 수준 추론 (GQA, Diamond): 대학원 수준 추론 테스트에서 Claude 3.5 Sonnet은 0-shot CoT*에서 59.4%의 정확도로 이 벤치마크에서 최고 성적을 달성했으며, 이는 Claude 3 Opus (50.4%)와 GPT-4 (53.6%) 보다 훨씬 앞선 것입니다. 이는 Claude 3.5 Sonnet이 복잡한 추론 작업을 처리할 수 있는 뛰어난 능력을 가지고 있음을 시사합니다.
Chain-of-Thought (CoT): 프롬프팅은 모델이 중간 추론 단계를 명시적으로 생성하도록 유도하여 문제 해결에서 인간과 유사한 사고 과정을 모방합니다.
0-shot CoT: 별도의 예시 없이 바로 문제와 함께 "생각을 단계별로 보여주세요"와 같은 프롬프트를 사용하여 모델이 스스로 추론 단계를 생성하도록 유도합니다.
5-shot CoT: 모델에게 5개의 예시를 보여주어 CoT 추론 방식을 학습시킨 후, 새로운 문제에 대해서도 동일한 방식으로 답변하도록 유도합니다.
- Undergraduate 수준 지식 (MMLU, Massive Multitask Language Understanding): 대학교 학부 수준 지식 테스트에서 Claude 3.5 Sonnet은 5-shot CoT 프롬프팅을 사용하여 90.4%의 정확도를 달성하여 이 벤치마크에서 최고 성적을 달성했습니다. 이는 0-shot CoT에서 88.3%를 기록한 것과 비교하면 Claude 3.5 Sonnet이 다양한 주제에 대한 광범위한 지식을 가지고 있음을 나타냅니다.
- HumanEval: Claude 3.5 Sonnet은 92.0%의 정확도를 달성하여 Claude 3 Opus (84.9%)와 GPT-4 (90.2%) 보다 우수한 코딩 능력을 보여주었습니다.
- 다국어 수학 (MGSM, MetaMath Grade School Math) : 초등학교 수학 문제를 통해 수학적 추론 및 문제 해결 능력을 평가하는 벤치마크에서 Claude 3.5 Sonnet은 91.6%의 정확도로 이 벤치마크에서 다시 한번 뛰어난 성능을 보여주었으며, 이는 다국어 수학 문제를 해결할 수 있는 뛰어난 능력을 보여줍니다.
- Grade school math (GSM8K): 96.4%의 정확도로 초등학교 수학 문제를 푸는 데 뛰어난 성능을 보여주었습니다.
- 혼합 평가 (BIG-Bench-Hard): 93.1%의 점수를 획득하여 다양한 복잡한 작업에서 강력한 성능을 보여주었습니다.
- 수학 문제 해결 (MATH): 71.1%의 정확도로 수학 문제를 해결하는 능력을 보여주었습니다.
요약하면 Claude 3.5 Sonnet은 추론, 코딩, 수학적 능력을 포함한 다양한 작업에서 우수한 성능을 보여주는 강력한 대규모 언어 모델입니다. 이러한 벤치마크에서의 뛰어난 성능은 자연어 처리 분야에서 상당한 진전을 보여줍니다.
2. 응답속도
Claude 3.5 Sonnet의 또 다른 주목할 만한 특징은 응답속도입니다. 이전 모델인 Claude 3 Opus에 비해 두 배 빠른 속도로 작동하며, 이는 특히 실시간 응답이 중요한 작업에서 큰 장점이 됩니다. 예를 들어, 고객 서비스 분야에서 Claude 3.5 Sonnet을 활용하면, 복잡한 질문에도 신속하고 정확한 답변을 제공할 수 있습니다. 또한, 여러 단계의 작업을 연속적으로 수행해야 하는 경우에도 지연 없이 원활하게 진행할 수 있습니다.
3. 코딩 능력
Claude 3.5 Sonnet의 코딩 능력은 특히 주목할 만합니다. HumanEval 테스트에서 뛰어난 성과를 보였으며, 내부 평가에서도 놀라운 결과를 보여주었습니다. 특히 에이전트 코딩 평가에서 Claude 3.5 Sonnet은 64%의 문제를 해결했는데, 이는 38%를 해결한 Claude 3 Opus를 크게 앞서는 수치입니다. 이 평가는 오픈 소스 코드베이스에서 버그를 수정하거나 새로운 기능을 추가하는 능력을 테스트합니다. Claude 3.5 Sonnet은 자연어로 된 개선 요구사항을 이해하고, 이를 바탕으로 독립적으로 코드를 작성, 편집, 실행할 수 있는 능력을 보여주었습니다.

또한, Claude 3.5 Sonnet은 코드 번역 작업도 쉽게 처리할 수 있습니다. 이는 레거시 애플리케이션을 업데이트하거나 코드베이스를 마이그레이션 하는 작업에 특히 효과적으로 활용될 수 있으며, 이러한 능력은 소프트웨어 개발 과정을 크게 가속화하고, 개발자들의 생산성을 높이는 데 기여할 수 있습니다.
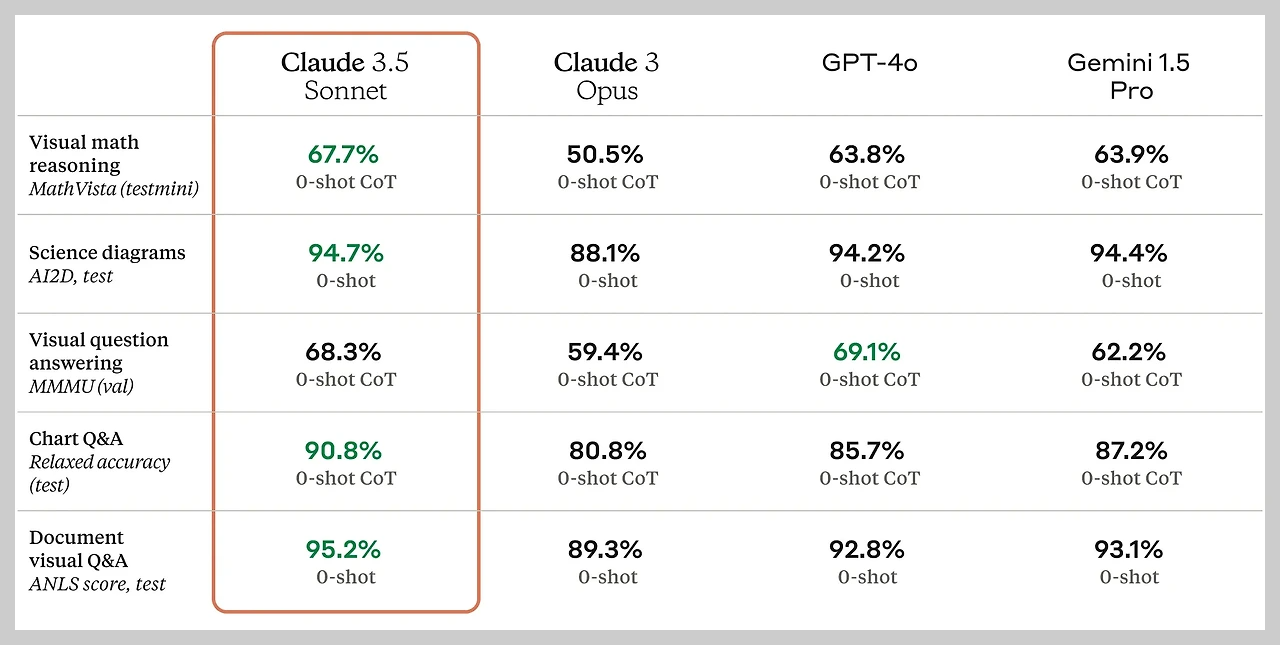
4. 시각적 이해 능력
Claude 3.5 Sonnet은 시각적 이해 능력에서도 큰 진전을 이루었습니다. 표준 시각 벤치마크에서 이전 모델인 Claude 3 Opus를 능가하는 성능을 보여주었으며, 특히 차트와 그래프를 해석하는 등 시각적 추론이 필요한 작업에서 개선을 보였습니다. 이러한 시각적 이해 능력의 향상은 AI의 응용 범위를 크게 확장시켜, 의료 영상 분석, 자율 주행 차량의 환경 인식, 보안 카메라 영상 분석 등 다양한 분야에서 Claude 3.5 Sonnet의 능력을 활용할 수 있을 것입니다.
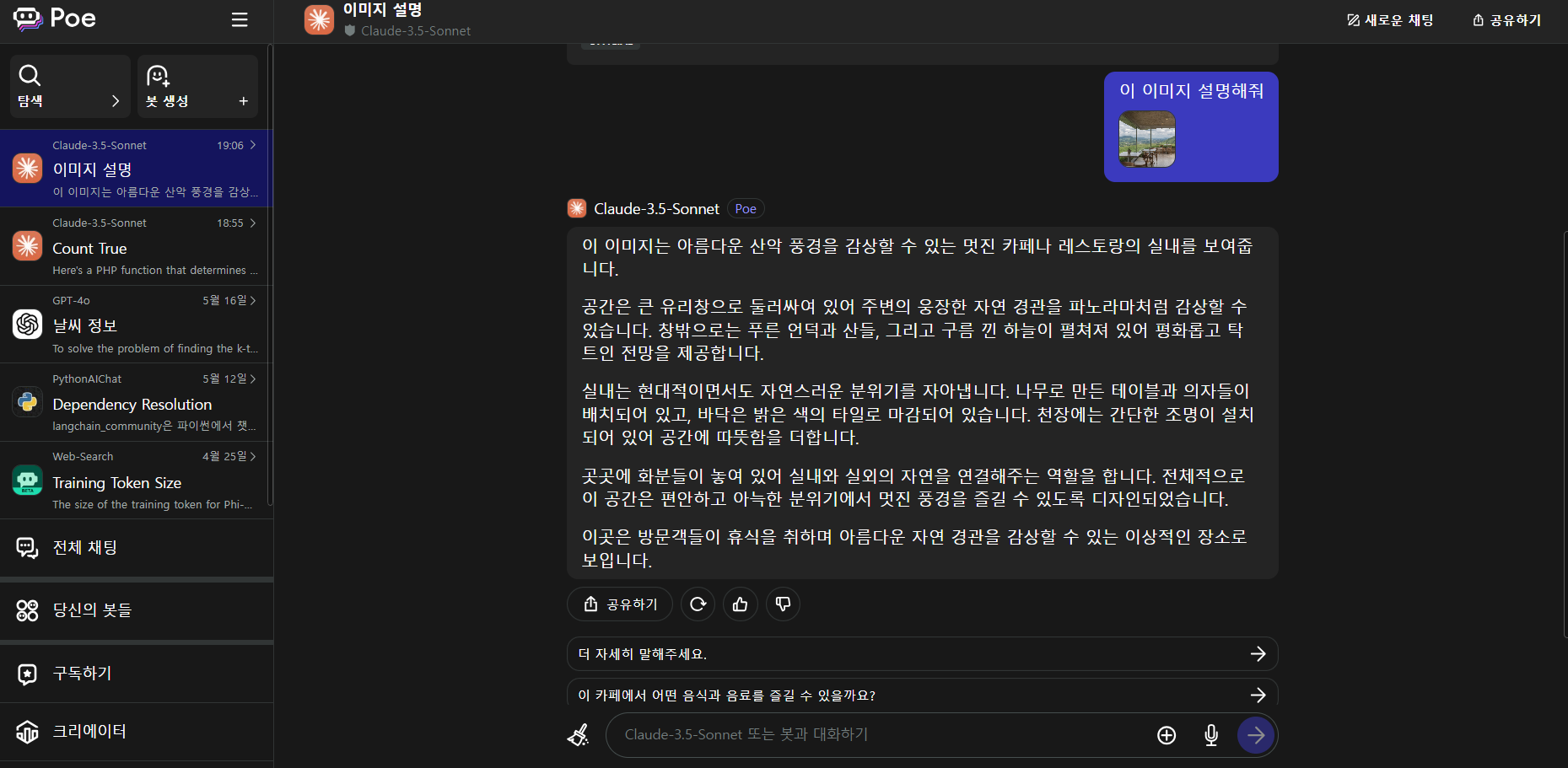

추론 및 코딩 테스트
다음은 Claude 3.5 Sonnet의 추론 성능과 코딩성능을 테스트해 보겠습니다. 추론성능은 오픈소스 최강 성능을 가진 DeepSeek-Coder-V2와 비교하였습니다.
1. 추론성능 테스트
| 추론 문제 |
결과 |
||
| Claude 3.5 Sonnet | DeepSeek-Coder-V2 | ||
| 5장의 셔츠를 햇빛에 건조하는데 4시간이 걸린다고 해보자. 그렇다면 20장의 셔츠를 건조하는 데는 얼마나 걸릴까요? 각 단계를 차근차근 설명해 주세요. 여러 셔츠를 동시에 건조할 수 있습니다. | Pass | Fail | |
| 방 안에는 살인자가 세 명 있습니다. 어떤 사람이 방에 들어와 그 중 한 명을 죽입니다. 아무도 방을 나가지 않습니다. 방에 남아 있는 살인자는 몇 명입니까? 단계별로 추론 과정을 설명하세요. 원래 방에 있던 살인자 말고도, 살아있거나 죽어있거나, 누구든지 죽인 살인자를 고려하세요. | Pass | Pass | |
| 베티는 새 지갑을 위해 돈을 모으고 있습니다. 새 지갑의 가격은 $100입니다. 베티는 필요한 돈의 절반만 가지고 있습니다. 그녀의 부모는 그 목적을 위해 $15를 주기로 결정했고, 할아버지와 할머니는 그녀의 부모들의 두 배를 줍니다. 베티가 지갑을 사기 위해 더 얼마나 많은 돈이 필요한가요? | Pass | Pass | |
| 제인이 조 보다 빠르고, 조가 샘보다 빠르다. 그렇다면 샘은 제인보다 빠른가요? 각 단계를 차근차근 설명해 주세요. | Pass | Pass | |

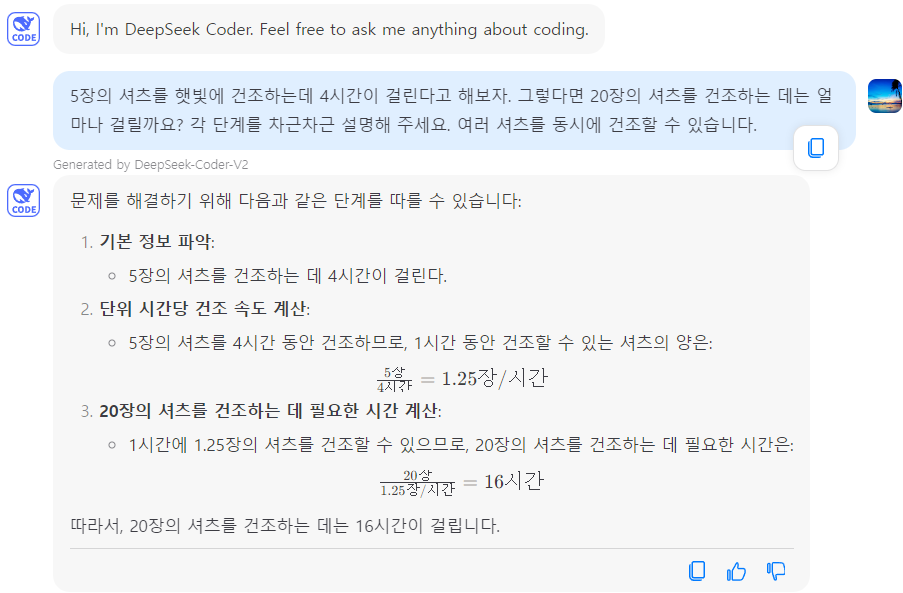
추론문제 1에서 DeepSeek-Coder-V2는 여러 셔츠를 동시에 건조할 수 있다는 것을 간과한 것 같습니다.


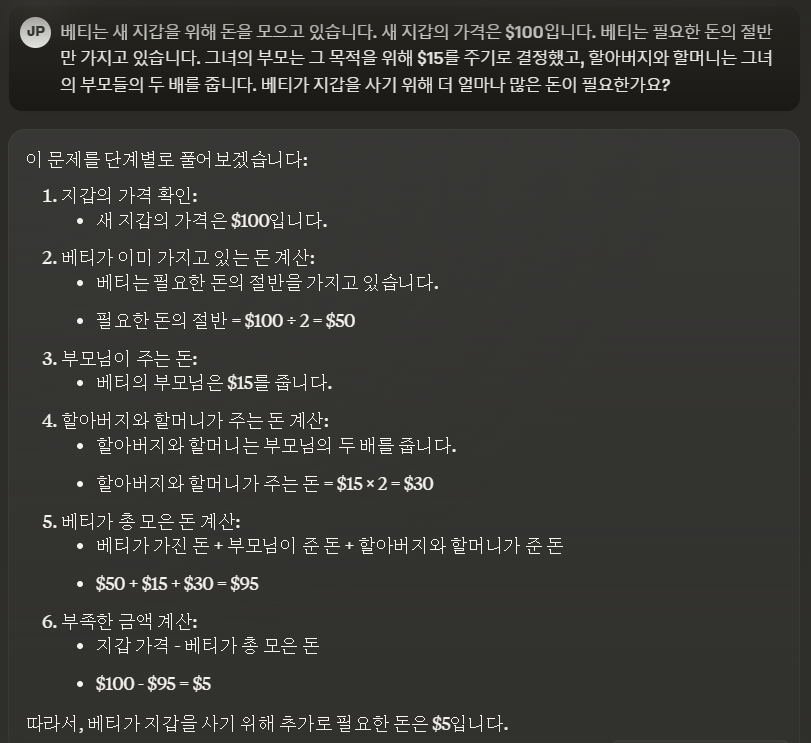



2. 코딩 성능 테스트
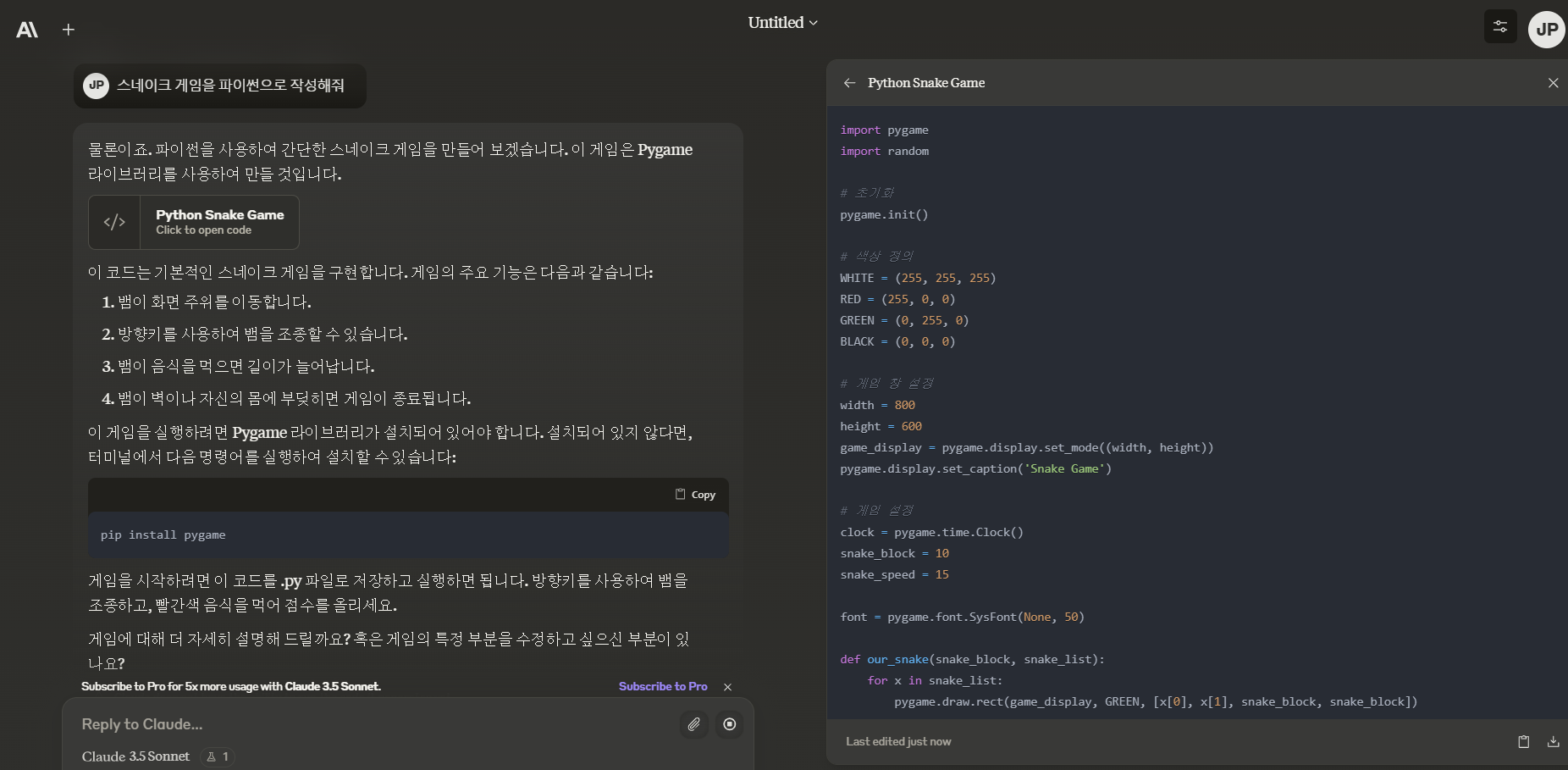
다음은 코딩 성능 테스트입니다. 먼저, 파이썬으로 스네이크게임을 작성해 달라고 하는 요청에 Claude 3.5 Sonnet는 첫 번째 시도에서 아래 화면과 같이 정상적으로 동작하는 코드를 작성하였습니다.
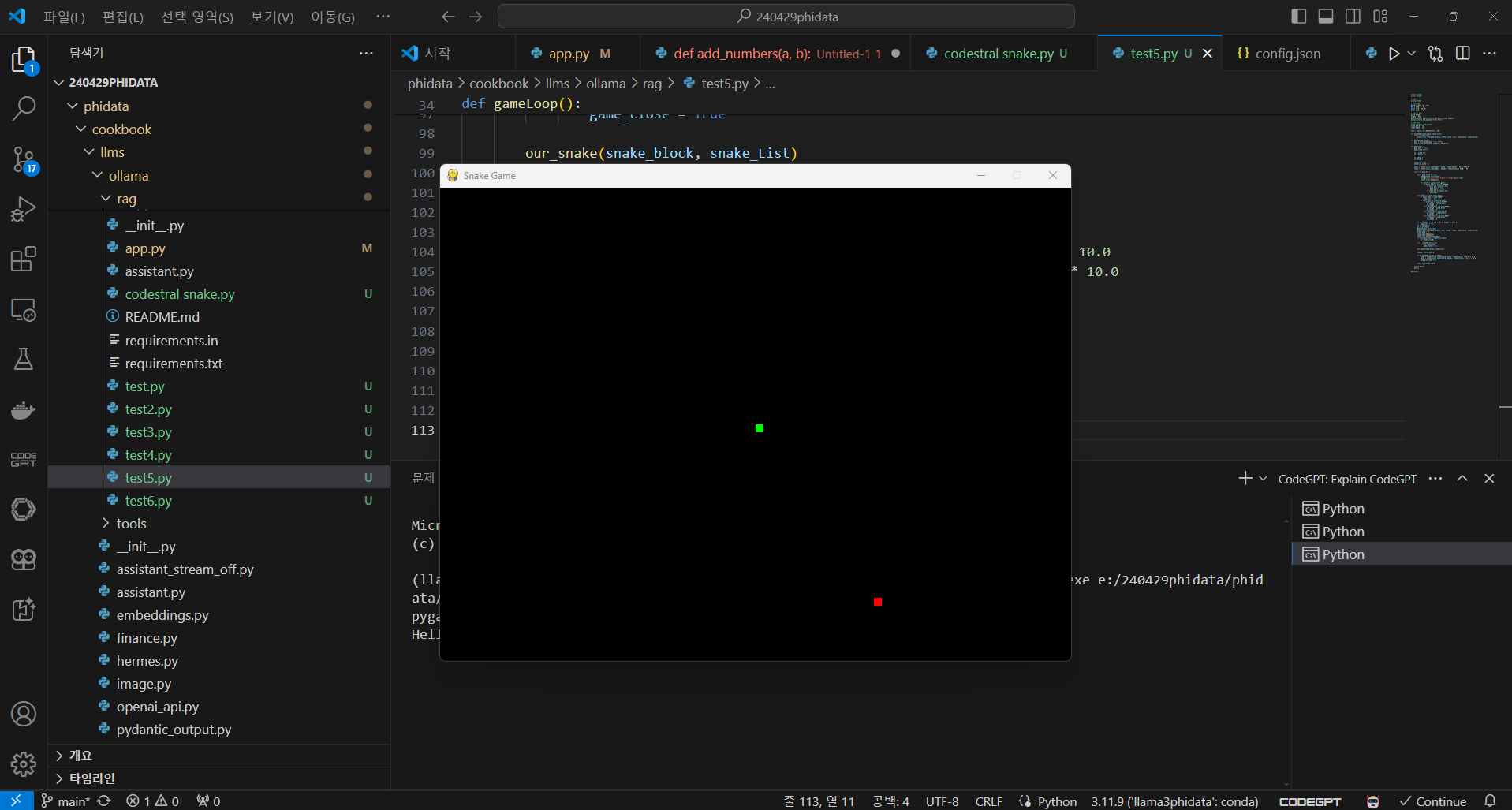
다음은 파이썬 JavaScript, PHP 코딩 테스트를 해보겠습니다. 테스트는 edabit.com 코딩 교육 사이트의 파이썬, 자바 스크립트, PHP 코딩 시험문제로 테스트하였으며, 난이도 단계별로 1문제당 2회 시도하고, 첫 번째 시도에서 성공하면 테스트를 종료하고, 두 번째 시도까지 실패하면 최종실패로 처리하였습니다.(*는 두 번째 시도 성공)
| 구 분 | Medium | Hard | Very Hard | Expert |
| Python | Pass | Pass | Pass | Pass |
| JavaScript | Pass | Pass | Fail | Pass |
| PHP | Pass* | Pass | Fail | Pass |
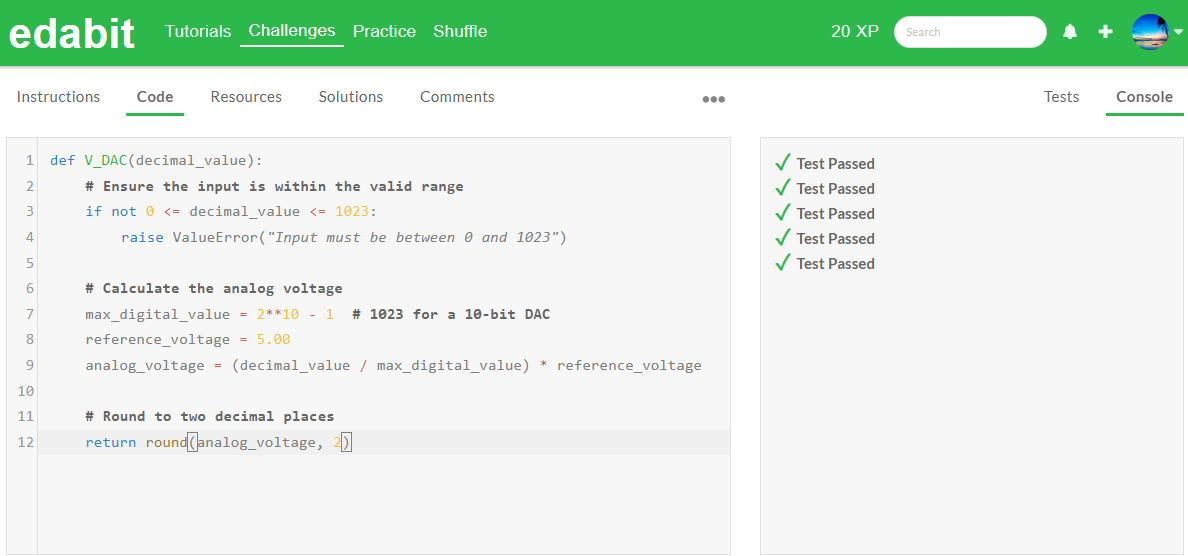
Python 테스트 결과
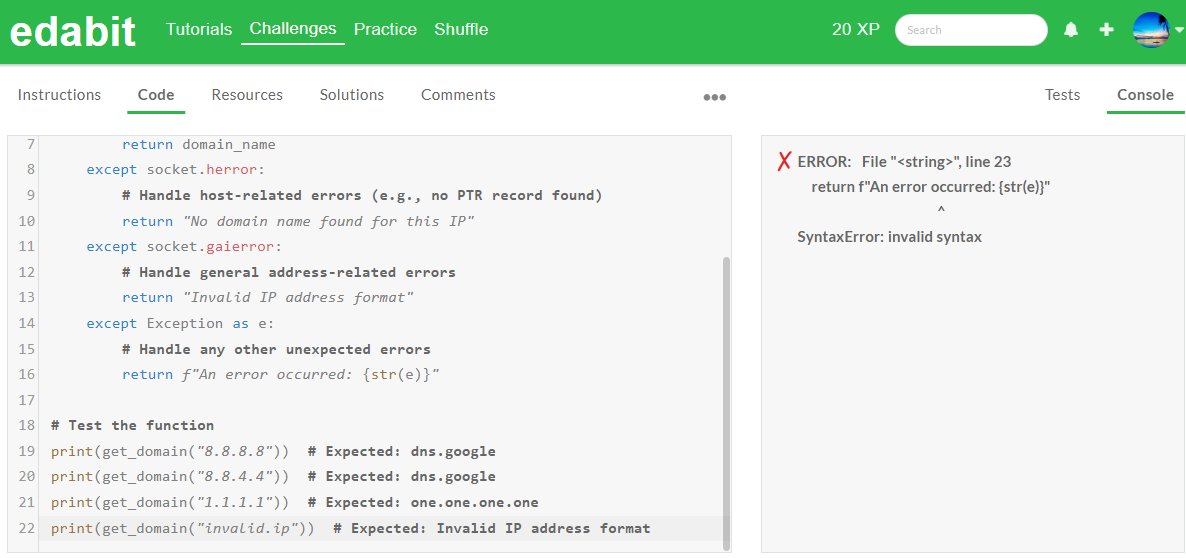
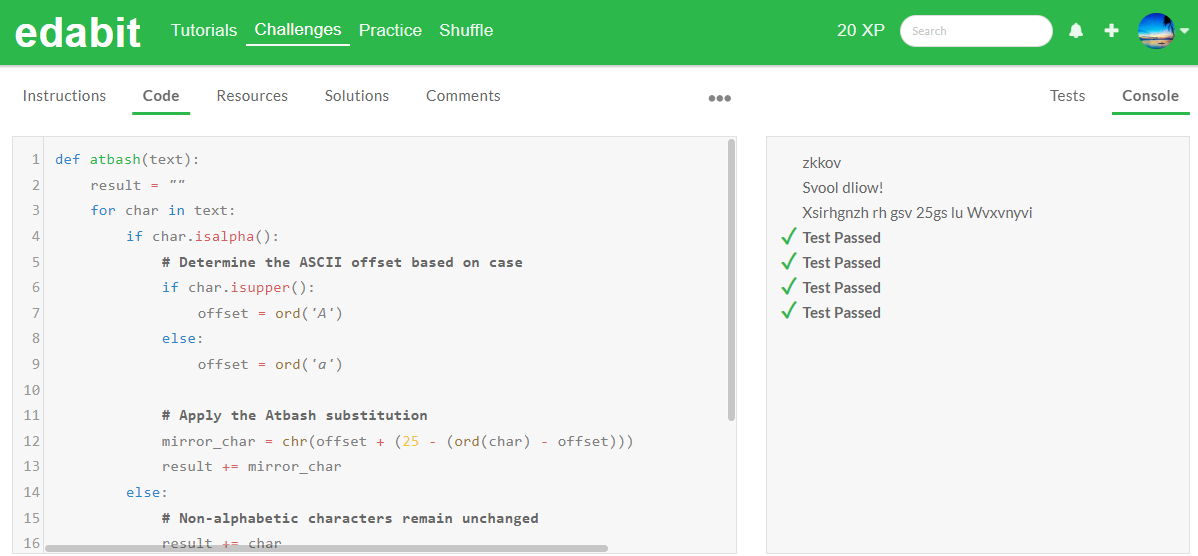
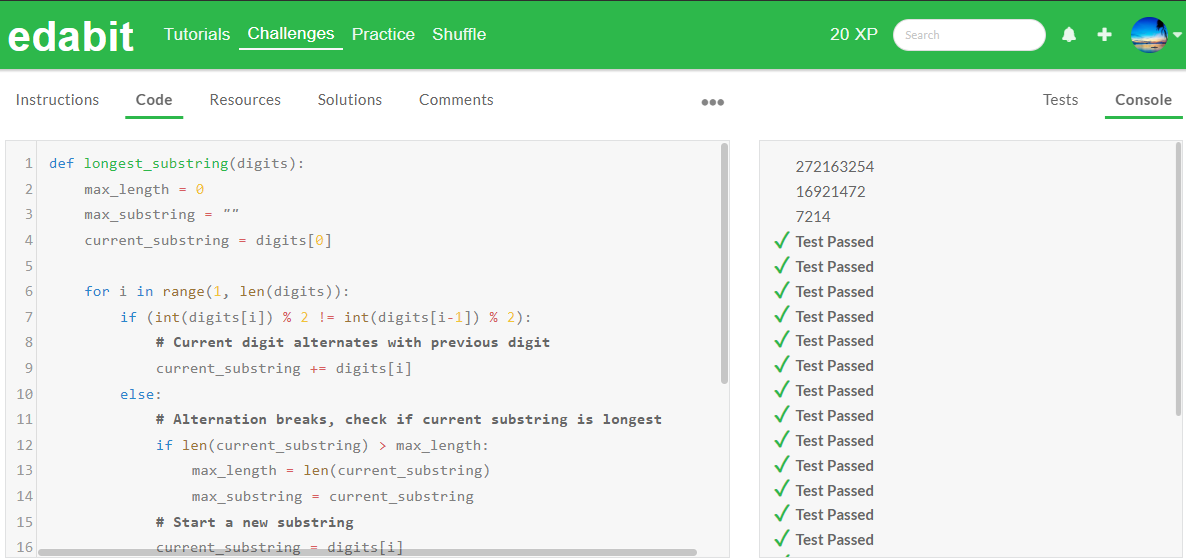
JavaScript 테스트 결과
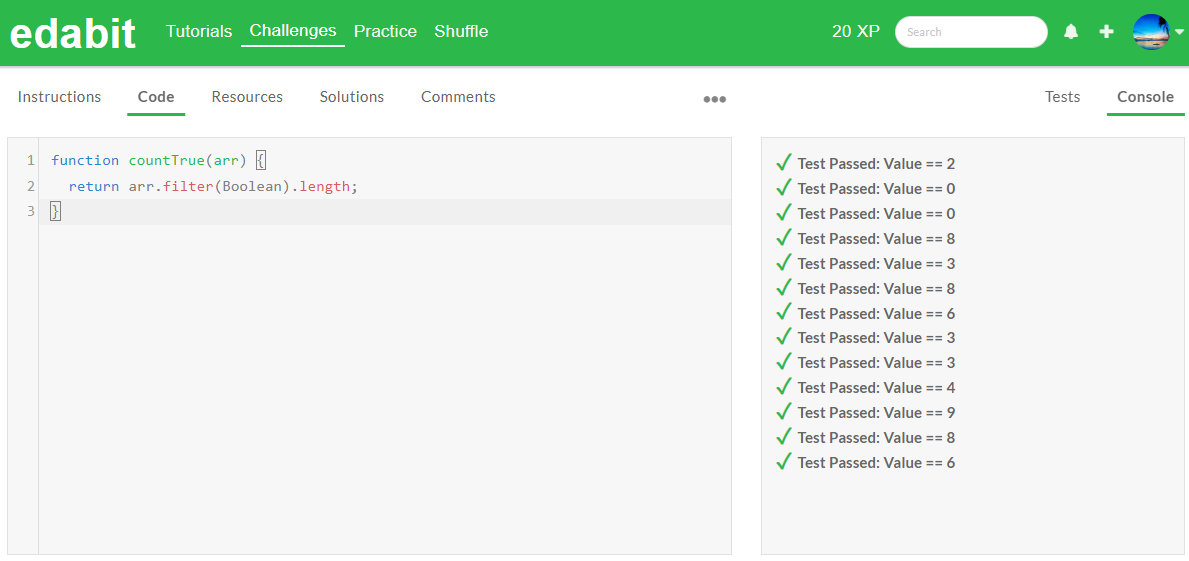
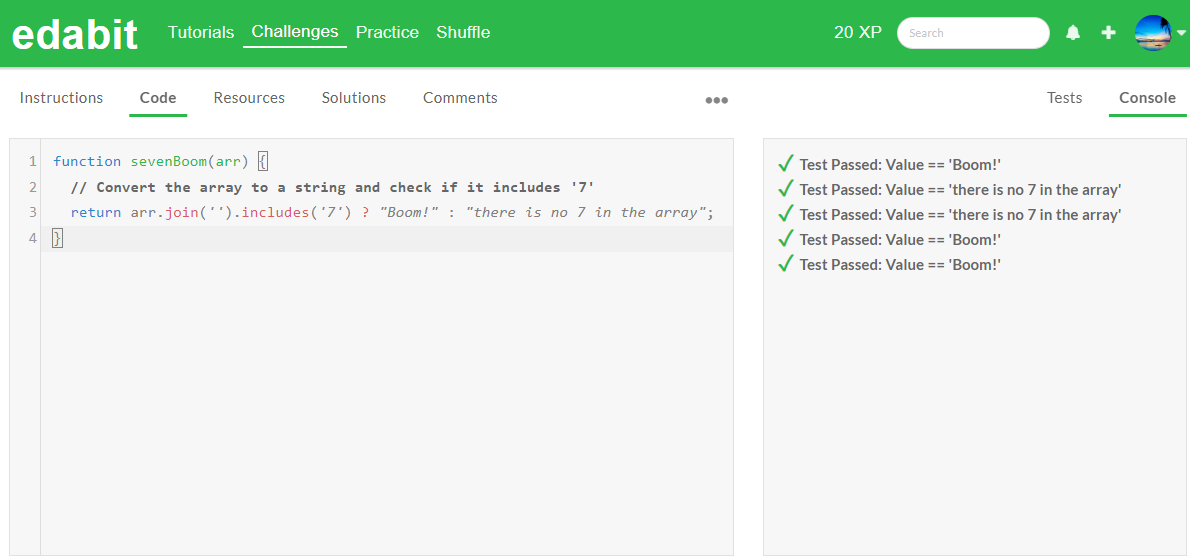
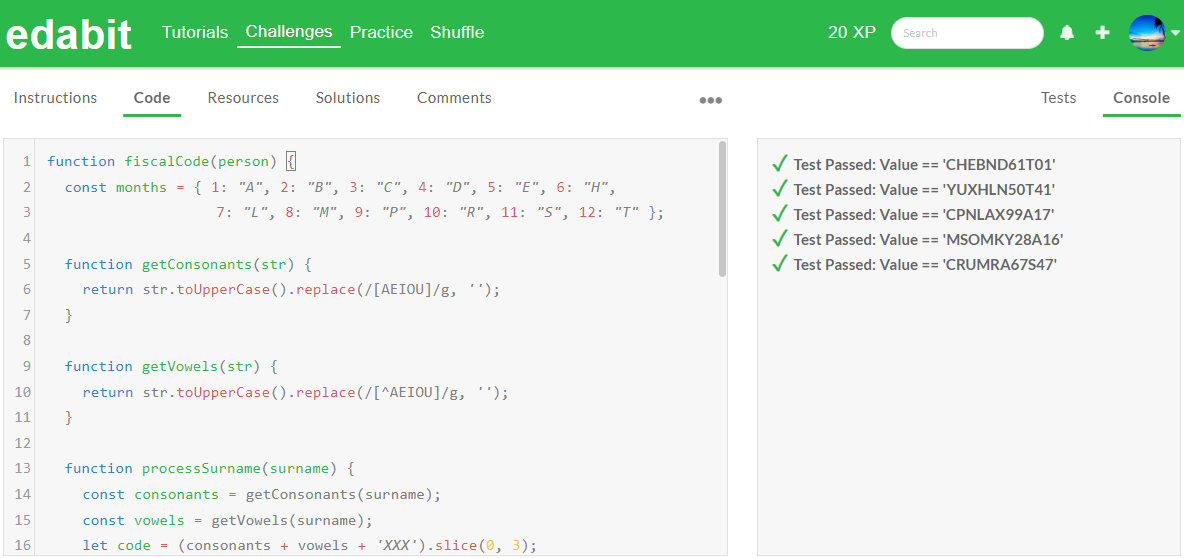
PHP 테스트 결과
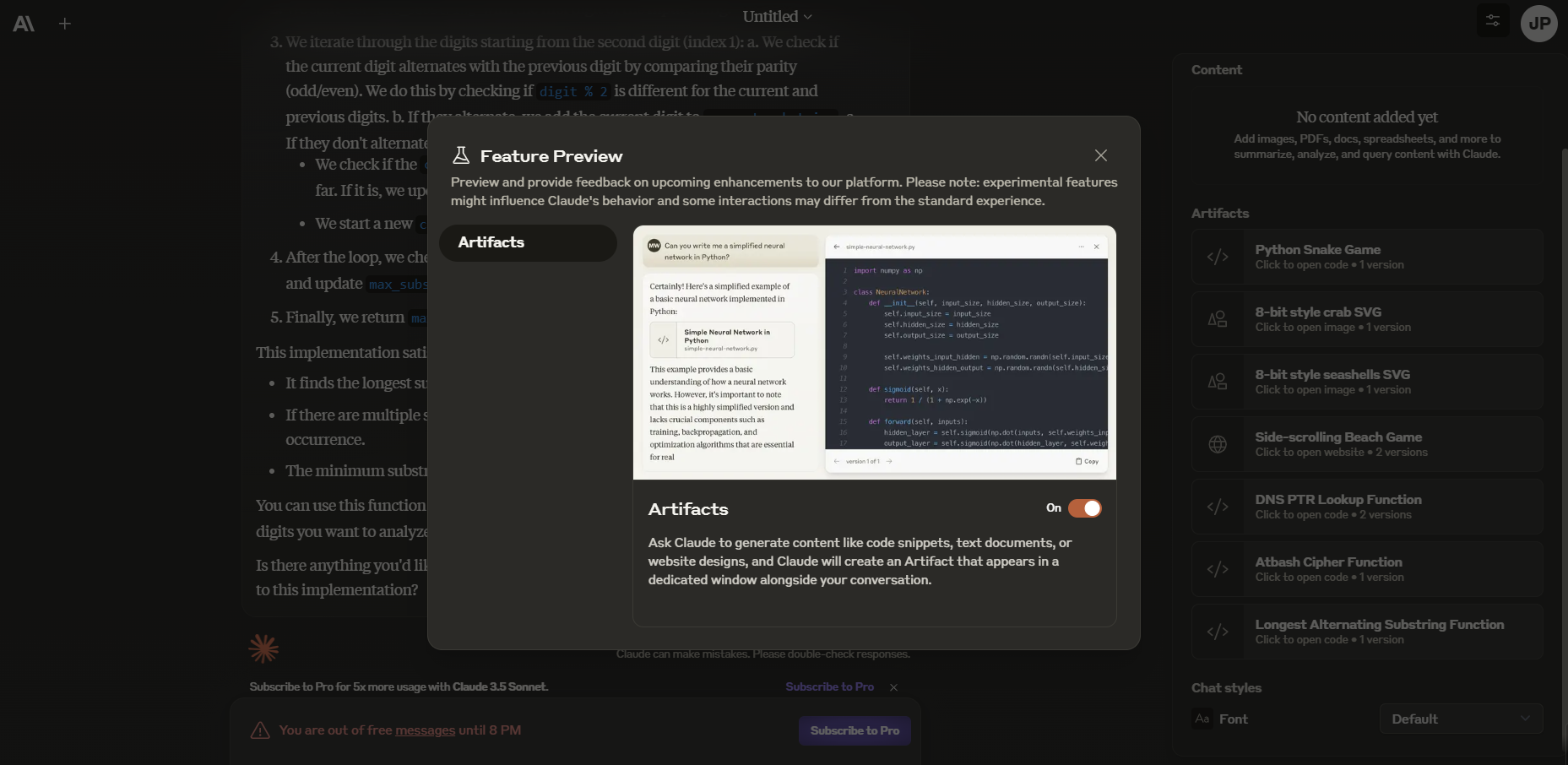
Artifacts 기능
Claude 3.5 Sonnet은 사용자가 상호작용할 수 있는 새로운 기능인 Artifacts(산출물)를 소개합니다. 사용자가 코드 스니펫, 텍스트 문서, 웹사이트 디자인 등의 콘텐츠 생성을 요청하면, 이러한 Artifacts가 대화와 나란히 전용 창에 표시됩니다. 이를 통해 사용자는 Claude의 창작물을 실시간으로 보고, 편집하고, 자신의 프로젝트와 워크플로우에 통합할 수 있는 동적 작업 공간이 만들어집니다. 이 기능을 사용하려면 우측상단 프로필 아이콘을 클릭하고 Feature Preview를 선택하면 됩니다.
아래 동영상은 Claude 3.5 Sonnet 페이지에 소개된 Artifacts 기능 데모 동영상입니다.
| Artifact 기능소개 비디오 |
저도 위 동영상과 같은 프롬프트를 입력해서 SVG(Scalable Vector Graphics, 확장가능 벡터 그래픽) 생성을 요청해 보니, 아래 화면과 같이 산출물 표시창이 대화창과 나란히 표시되었습니다.
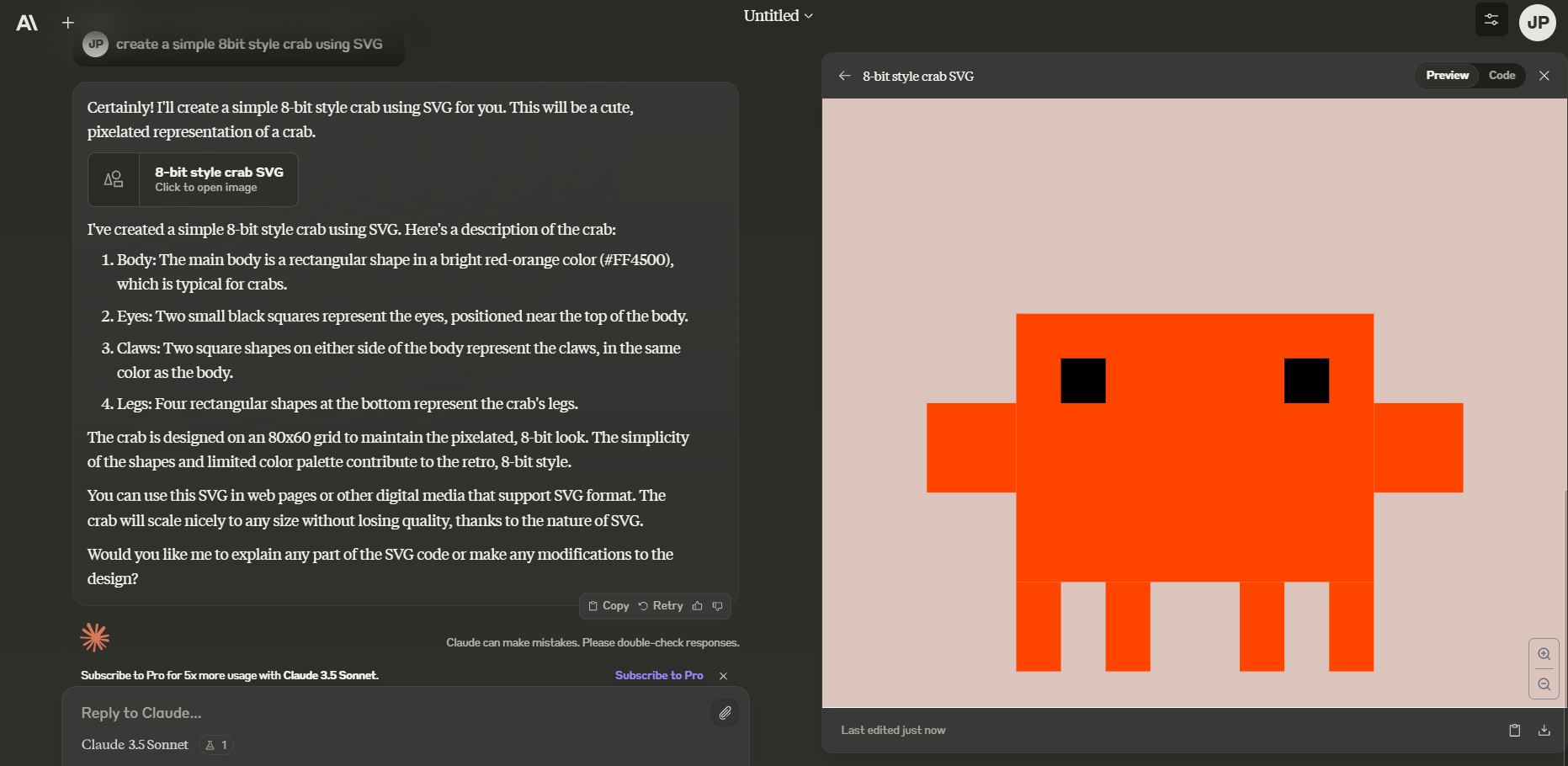
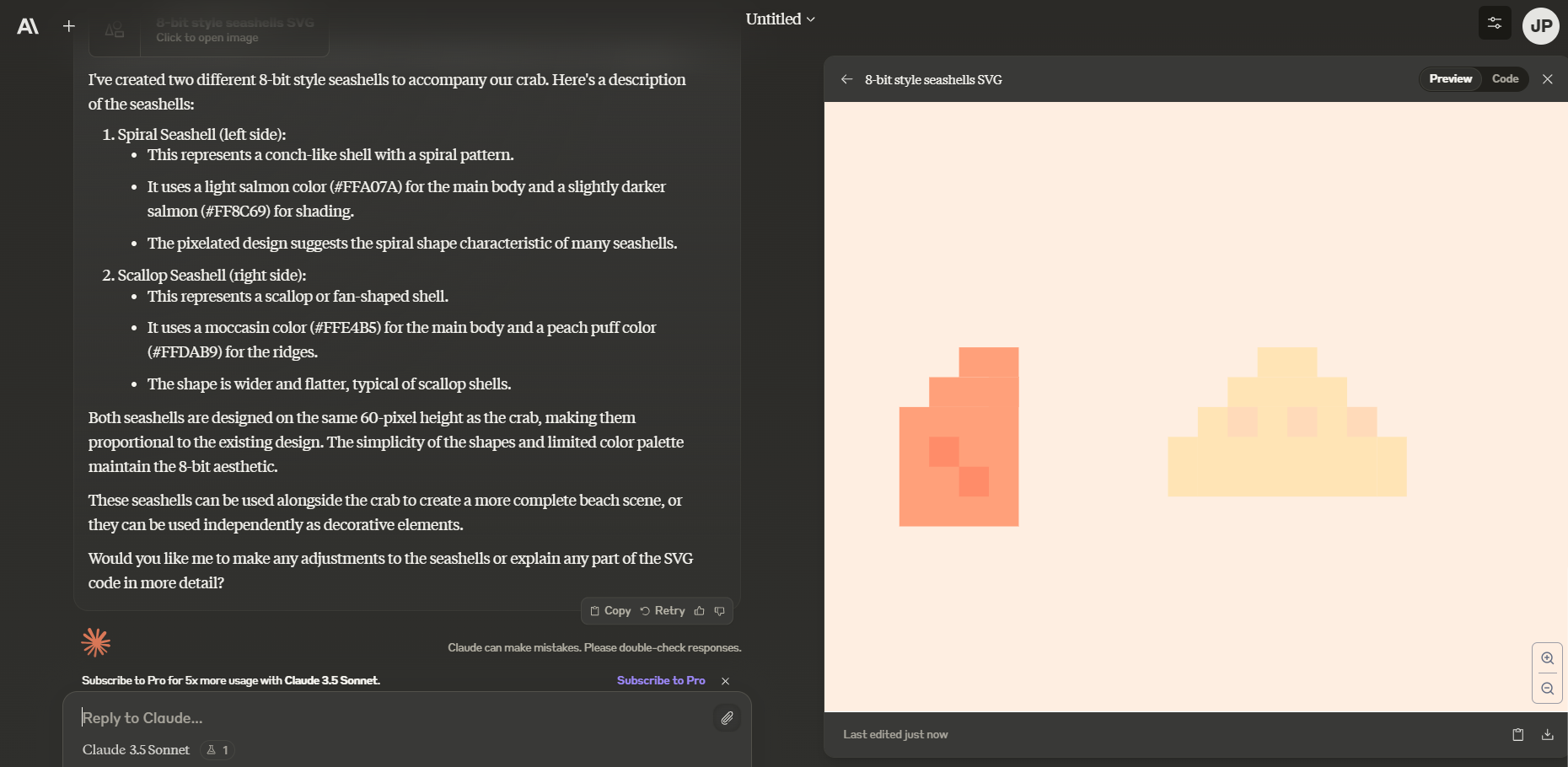
SVG 생성 응답 및 Artifacts 화면을 이용해서 아래 화면과 같이 간단한 횡 스크롤 게임을 만들어 볼 수도 있습니다.
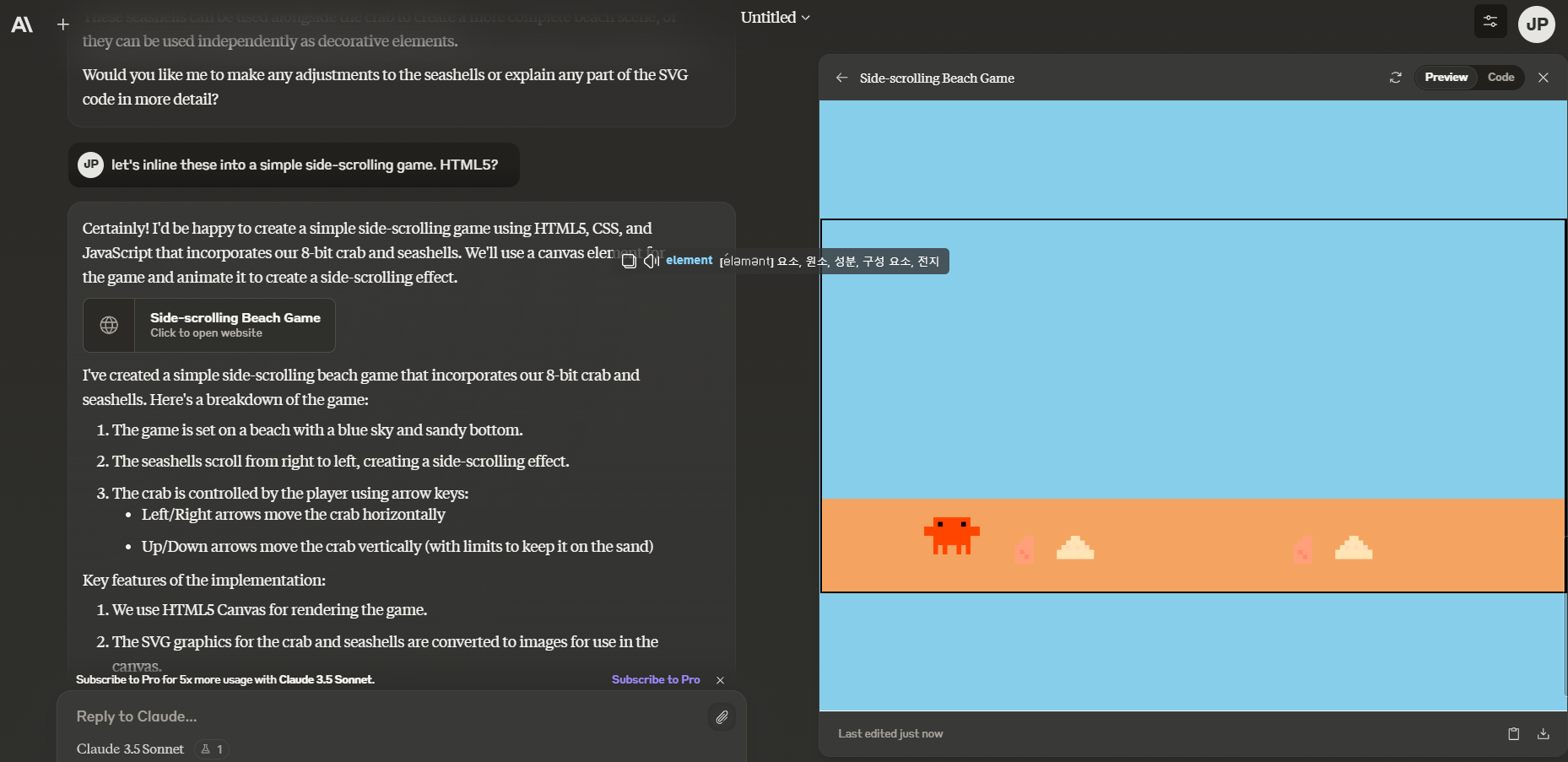
| Artifacts 화면을 이용한 횡 스크롤 게임 미리보기 |
기타 제한사항
참고로 클로드 모델은 응답할 때 인터넷 검색을 할 수 없으며, 이미지 생성기능은 없습니다.


맺음말
오늘은 Anthropic의 최신 대형 언어 모델인 Claude 3.5 Sonnet에 대해 자세히 살펴보았습니다. Claude 3.5 Sonnet은 속도, 성능, 비용 효율성 등 여러 면에서 기존 모델들을 뛰어넘으며, 대학원 수준의 추론 능력과 학부 수준의 지식, 그리고 뛰어난 코딩 능력 등에서 업계 최고 수준의 성과를 기록했습니다. 특히 Artifacts 기능을 통해 사용자와의 상호작용을 강화하여 더욱 풍부한 작업 환경을 제공합니다.
Claude 3.5 Sonnet은 복잡한 추론 문제부터 다양한 코딩 작업, 시각적 이해 능력까지 폭넓은 영역에서 탁월한 성능을 발휘하며, AI 모델이 갖추어야 할 핵심 역량을 보여줍니다. 이러한 발전은 자연어 처리 분야에서 상당한 진전을 의미하며, 앞으로의 AI 응용 분야에서도 큰 가능성을 시사합니다.
여러분도 이 모델을 사용해서 여러 가지 성능을 직접 체험해 보시기를 추천해 드리면서, 그럼 저는 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.03.06 - [AI 언어 모델] - 클로드(Claude) 3: GPT-4와 제미나이를 뛰어넘은 언어 모델의 등장!
클로드(Claude) 3: GPT-4와 제미나이를 뛰어넘은 언어 모델의 등장!
안녕하세요! 오늘은 3월 4일 발표된 앤트로픽의 최신 대형 언어 모델 클로드(Claude) 3에 대해서 알아보겠습니다. 이번에 발표된 클로드 3 모델 패밀리는 Haiku, Sonnet 및 Opus라는 세 가지 최신 모델로
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 🖥️마이크로소프트 Florence-2 리뷰: 0.7B 비전 모델의 혁신🚀 (0) | 2024.06.28 |
|---|---|
| CoLLaVO: 카이스트의 최첨단 시각-언어 모델 분석 및 테스트👀💬🔍 (0) | 2024.06.25 |
| DeepSeek-Coder-V2: 현존 최강 AI 코딩 언어 모델 분석 및 테스트 (0) | 2024.06.20 |
| Stable Diffusion 3 Medium: 최신 T2I 모델 설치와 활용법(SwarmUI) (2) | 2024.06.15 |
| Qwen-2:🌐27개 언어 구사, 알리바바의 자바스크립트 천재 언어 모델 💻 (2) | 2024.06.08 |



