안녕하세요! 오늘은 Stability AI가 최근 출시한 Stable Diffusion 3 Medium에 대해 알아보겠습니다. 이 모델은 작년에 출시된 SDXL의 후속 모델로, 다중모달 확산 변환기(MMDiT, Multimodal Diffusion Transformer) 기반의 텍스트-이미지 생성 모델이며, 이미지 품질, 타이포그래피, 복잡한 프롬프트 이해 및 리소스 효율성 면에서 크게 향상된 성능을 자랑합니다. 이 블로그에서는 다중모달 확산 변환기의 개요와 동작원리, SwarmUI를 이용한 간단한 SD3 Medium의 설치방법에 대해 살펴보고 타이포그래피 성능테스트를 해보겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
다중모달 확산 변환기(MMDiT)
다중모달 확산 변환기는 다양한 모달리티(예: 텍스트, 이미지 등)를 입력으로 받아 이를 사용하여 특정 출력을 생성하는 기계 학습 모델을 의미합니다. 이 모델은 확산 과정과 변환기 아키텍처를 결합하여 입력 데이터를 이해하고 처리합니다.
- 다중모달 (Multimodal) : 텍스트, 이미지, 음성 등 다양한 유형의 데이터를 다룹니다.
- 확산 (Diffusion) : 노이즈가 추가된 데이터에서 점진적으로 학습하며 원하는 출력을 생성합니다.
- 변환기 (Transformer) : 자연어 처리에 사용되는 신경망 아키텍처로, 입력 데이터를 효과적으로 변환하고 예측합니다.
이러한 모델은 텍스트 프롬프트를 기반으로 이미지를 생성하거나, 다른 형태의 데이터를 생성 및 변환할 때 사용될 수 있으며, 개념도의 구성요소와 동작원리는 다음과 같습니다.

위 개념도의 구성요소는 다음과 같습니다.
- Noise Level Token (t): 모델이 학습 중에 사용하는 노이즈 수준 정보를 나타냅니다. 이 토큰은 이미지 생성 과정에서 노이즈의 수준을 조절하는 데 사용됩니다.
- Text Embeddings: 텍스트 입력을 임베딩(Embedding) 한 결과입니다. 입력 텍스트는 임베딩 레이어를 통해 벡터로 변환되어 이 부분에 입력됩니다.
- Image Embeddings: 이미지 입력을 임베딩한 결과입니다. 이미지 데이터를 벡터로 변환하여 이 부분에 입력됩니다.
- Modulation and Linear Layers: 텍스트와 이미지 임베딩은 먼저 Modulation 레이어를 거치고, 그다음 Linear 레이어를 통과합니다. 이는 임베딩 벡터를 조정하여 모델의 요구사항에 맞게 변환합니다. Modulation 레이어는 임베딩 벡터의 특정 특징을 조정하거나 강화하는 역할을 합니다. 이 레이어는 텍스트와 이미지의 특징 벡터를 조정하여 모델의 다른 부분과 효과적으로 상호작용할 수 있도록 돕습니다. Linear 레이어는 선형 변환을 수행하여 임베딩 벡터의 차원을 변경하거나 조정해서 입력 임베딩을 선형적으로 변환하여 필요한 출력 형태로 조정합니다.
- Joint Attention (Q, K, V): 텍스트와 이미지 임베딩이 Joint Attention 메커니즘에 의해 함께 처리됩니다. Q (Query), K (Key), V (Value)는 어텐션 메커니즘의 입력으로, 각 임베딩에서 추출된 정보를 결합하여 주의를 집중시킬 위치를 결정합니다.
- Linear and Modulation Layers (Post-Attention): Joint Attention에서 처리된 결과는 다시 Linear와 Modulation 레이어를 거칩니다. 이는 어텐션 결과를 모델의 다음 단계로 넘기기 전에 한 번 더 조정하는 역할을 합니다.
- MLP (Multi-Layer Perceptron): 마지막 단계로, 어텐션 결과와 변형된 임베딩은 MLP 레이어를 통과합니다. 이 레이어는 추가적인 비선형 변환을 적용하여 모델이 학습한 정보가 다음 단계로 잘 전달되도록 합니다.
- Repeat d times: 이 과정은 d번 반복됩니다. 각 반복 단계는 모델이 텍스트와 이미지 임베딩 사이의 복잡한 상호작용을 더 잘 이해할 수 있게 도와줍니다.
다중모달 확산 변환기의 동작순서는 다음과 같습니다.
1. 입력 및 초기 설정: 입력된 텍스트 프롬프트는 임베딩으로 변환되고, 순수 노이즈 이미지가 생성됩니다.
- (1) 텍스트 프롬프트 입력: 사용자가 원하는 이미지를 설명하는 텍스트 프롬프트를 입력합니다.
- (2) 텍스트 임베딩 생성: 입력된 텍스트 프롬프트는 텍스트 인코더를 통해 텍스트 임베딩으로 변환됩니다. 이 임베딩은 프롬프트의 의미 정보를 담고 있습니다.
- (3) 순수 노이즈 이미지 생성: 모델은 임의의 노이즈로 가득 찬 이미지를 생성합니다. 이것이 디노이징 프로세스의 시작점이 됩니다.
- (4) 노이즈 레벨 설정: 초기 노이즈 레벨이 설정됩니다. 디노이징은 단계적으로 진행되므로, 초기에는 높은 노이즈 레벨에서 시작하여 점차 낮아집니다.
2. 반복적인 디노이징: 설정된 횟수만큼 반복적으로 디노이징을 수행하며, 각 반복은 다음 단계를 포함합니다.
- (1) 노이즈 레벨 토큰 임베딩: 현재 노이즈 레벨을 나타내는 노이즈 레벨 토큰도 임베딩됩니다.
- (2) 텍스트 및 이미지 정보 통합 (Cross-Attention): 텍스트 임베딩은 쿼리(Query)로 사용되어 현재 노이즈 레벨에서 이미지의 어떤 부분에 집중해야 하는지 나타냅니다. 노이즈 이미지는 키(Key) 및 값(Value)으로 변환되어 이미지 정보를 제공합니다. Cross-Attention 메커니즘을 통해 텍스트 정보를 기반으로 이미지 정보를 선택적으로 강조하거나 억제합니다.
- (3) 이미지 정보 업데이트: Cross-Attention 결과와 노이즈 레벨 정보를 사용하여 모델은 노이즈 이미지를 업데이트합니다. 이 과정에서 노이즈가 제거되고 텍스트 프롬프트에 맞는 이미지 정보가 생성됩니다.
- (4) 노이즈 레벨 감소: 다음 반복을 위해 노이즈 레벨을 감소시킵니다.
3. 최종 이미지 생성: 설정된 반복 횟수를 모두 완료하면 최종 노이즈가 제거된 이미지가 생성됩니다. 이 이미지는 텍스트 프롬프트에 따라 생성된 이미지입니다.
Stable Diffusion은 텍스트 정보를 기반으로 노이즈 이미지를 반복적으로 디노이징하여 최종 이미지를 생성합니다. 각 단계에서 노이즈 레벨을 조절하고 Cross-Attention 메커니즘을 통해 텍스트 정보를 이미지 생성에 반영합니다.
SD3 Medium 설치방법
다음은 Stable Diffusion 3 Medium 설치방법입니다. 설치를 위한 파일 구성은 다음과 같이 기본 모델 및 가중치 파일, 그리고 텍스트 인코더 파일로 구성되어 있습니다.
파일구성
1. 기본 모델 및 가중치 파일
| 항목 | 설명 | 파일 크기 |
| SD3 Medium | 기본 모델 가중치와 VAE 포함, 텍스트 인코더 제외 | 4.2 GB |
| SD3 Medium Incl Clips | T5XXL를 제외한 텍스트 인코더와 모든 필요한 가중치 포함 | 5.8 GB |
| SD3 Medium Incl Clips T5XXLFP8 | T5XXL 텍스트 인코더의 fp8 버전을 포함한 모든 가중치 포함 | 10.6 GB |
| SD3 Medium Incl Clips T5XXLFP16 | T5XXL 텍스트 인코더의 fp16 버전을 포함한 모든 가중치 포함 | 15.8 GB |
2. 텍스트 인코더 파일
| 항목 | 설명 | 파일 크기 |
| Text Encoder Clip L | 작고 가벼운 텍스트 인코더, 기본적인 CLIP 기능을 제공하며 자원 소비가 적음 | 234 MB |
| Text Encoder Clip G | 더 많은 기능을 지원하며 다양한 텍스트를 다룰 수 있는 CLIP 인코더 | 1.3 GB |
| Text Encoder t5xxl_fp8 | T5XXL 모델의 fp8 버전, 자원 효율성을 높임. 균형잡힌 품질과 자원 사용 | 4.7 GB |
| Text Encoder t5xxl_fp16 | T5XXL 모델의 fp16 버전, 텍스트 표현의 정밀도가 높으며 더 많은 메모리 필요 | 9.5 GB |
설치방법
1. SwarmUI 설치: 아래에 install-windows.bat을 다운로드하여 실행하고 계속 진행하면 됩니다.
install-windows.bat을 실행하면 아래 화면과 같이 팝업이 뜨고, 실행을 클릭해서 계속 진행합니다.



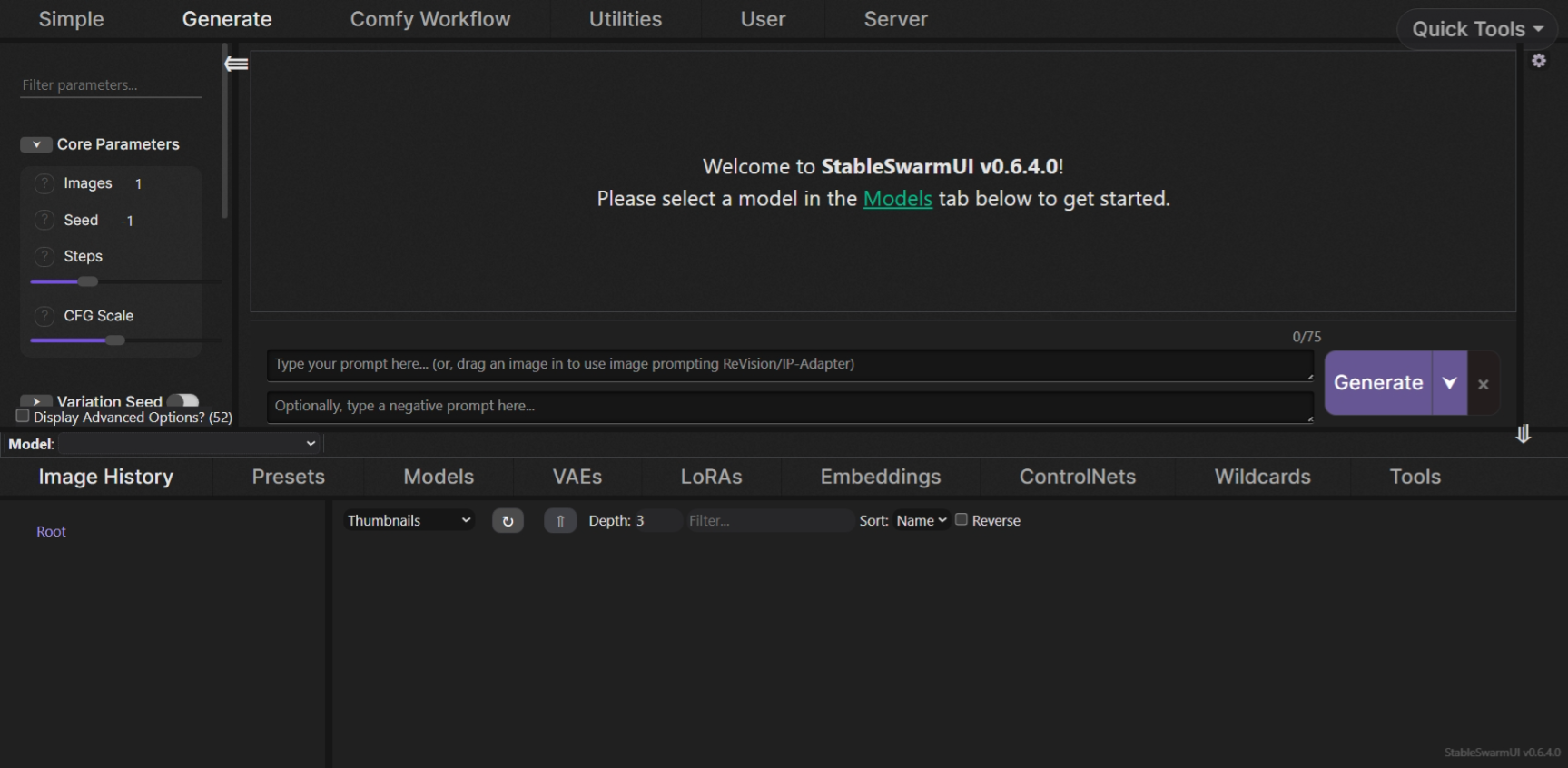
설치가 완료되면 아래와 같이 http://localhost:7801/Text2Image 주소에서 SwarmUI 초기화면이 열립니다.
2. Stable Diffusion 3 Medium 모델 다운로드
허깅페이스에서 아래 모델파일 3개를 다운로드하여 StableSwarmUI\Models\Stable-Diffusion 디렉토리에 저장합니다. 모델 다운로드를 위해 허깅페이스 모델 페이지에서 이메일과 기본 정보를 입력하고 동의하는 과정이 필요합니다.
- sd3_medium_incl_clips.safetensors
- sd3_medium_incl_clips_t5xxlfp8.safetensors
- sd3_medium_incl_clips_t5xxlfp16.safetensors
https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main
stabilityai/stable-diffusion-3-medium at main
You need to agree to share your contact information to access this model This repository is publicly accessible, but you have to accept the conditions to access its files and content. By clicking "Agree", you agree to the License Agreement and acknowledge
huggingface.co
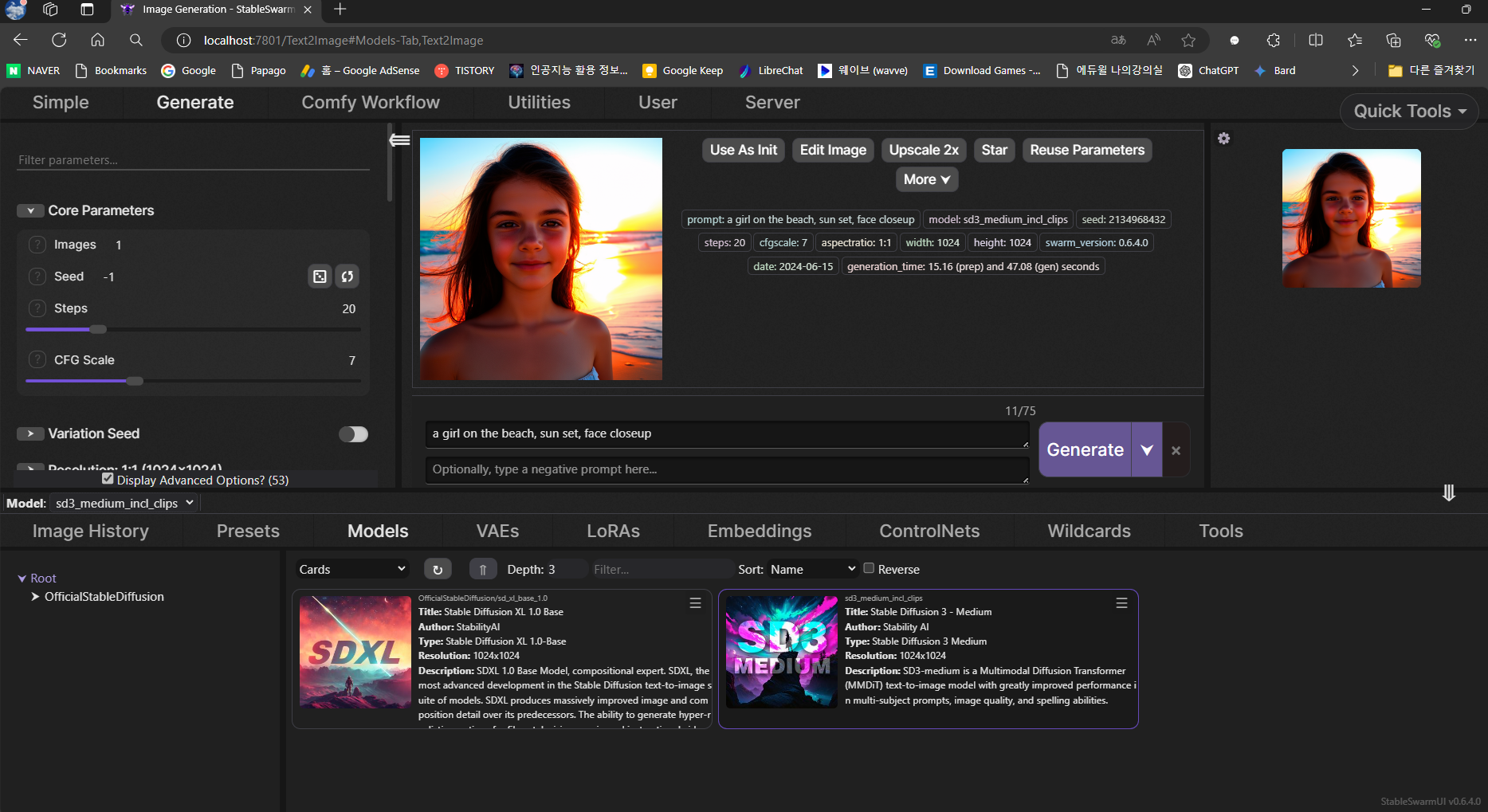
모델 파일을 저장하고 화면 아래 Models 메뉴에서 리프레시를 클릭하면 아래와 같이 모델 카드가 나타나며, 모델을 선택하고 텍스트 프롬프트를 입력하면 이미지가 생성됩니다. 텍스트 인코더 파일은 자동으로 다운로드됩니다.
타이포그래피 테스트
다음은 SD3 Medium 모델의 타이포그래피 성능을 테스트해 보았습니다. 이 블로그의 테스트 환경은 Windows 11 Pro(23H2), CPU i9-13900H, 2.60 GHz, RAM 16GB, GPU RTX4060 8GB입니다. 텍스트 프롬프트는 다음과 같습니다.
A beautiful girl, wearing white shirts and jeans, is holding a sign reading "Stable Diffusion 3 Medium is Here"
(하얀 셔츠와 청바지를 입은 아름다운 소녀가 " Stable Diffusion 3 Medium is Here "라는 문구가 적힌 표지판을 들고 있습니다.) Lora 등 추가 모델이나 편집 없이 텍스트 프롬프트 입력만으로 8회 생성시도하여 "Stable Diffusion 3 Medium is Here"에서 모든 스펠링이 맞아야 성공입니다.
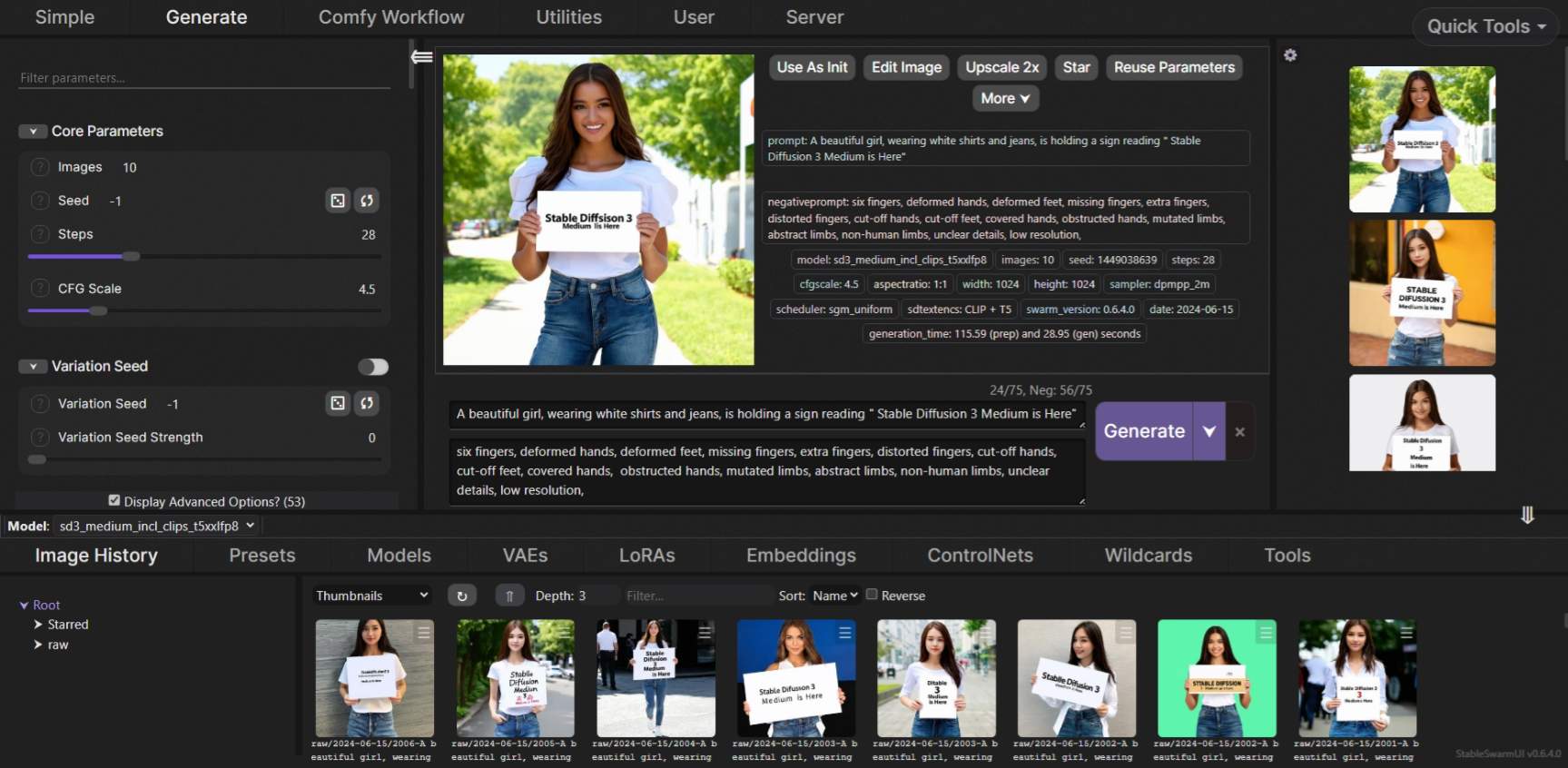
테스트 결과는 아쉽게도 sd3_medium_incl_clips 모델과 sd3_medium_incl_clips_t5xxlfp8 모델은 한 번도 스펠링을 정확하게 맞히지 못하였으며, sd3_medium_incl_clips_t5xxlfp16 모델만이 1회 성공하였습니다.
sd3_medium_incl_clips 모델로 생성한 이미지 : 8회 모두 실패
 |
 |
 |
 |
 |
 |
 |
 |
sd3_medium_incl_clips_t5xxlfp8 모델로 생성한 이미지 : 8회 모두 실패
 |
 |
 |
 |
 |
 |
 |
 |
sd3_medium_incl_clips_t5xxlfp16 모델로 생성한 이미지 : 1회 성공, 7회 실패
 |
 |
 |
 |
 |
 |
 |
 |
sd_xl_base_1.0 모델로 생성한 이미지 : 8회 모두 실패
 |
 |
 |
 |
 |
 |
 |
 |
SD3 Medium 모델의 타이포그래피 성능 테스트 결과, 이전 모델인 SDXL 모델보다 정교해진 것은 사실이지만, 아직 개선이 필요한 것 같습니다. 아래 사진이 모든 스펠링이 정확하게 생성된 이미지입니다. 그나마 오른팔이 잘못되었네요.

맺음말
Stable Diffusion 3 Medium의 출시는 텍스트-이미지 생성 기술의 진화에서 중요한 이정표입니다. 다중모달 확산 변환기(MMDiT)를 기반으로 하는 이 모델은 향상된 이미지 품질과 복잡한 텍스트 이해, 타이포그래피 생성 능력을 보여줍니다. SD3 Medium은 다양한 모달리티를 다루고 텍스트 정보를 효과적으로 활용하여 이미지를 생성하는 능력에서 크게 발전한 모습을 보였습니다.
설치 과정은 SwarmUI를 통해 간단하게 진행할 수 있으며, 허깅페이스를 통해 모델 파일을 다운로드하여 로컬 환경에서 바로 활용할 수 있습니다. 타이포그래피 성능 테스트 결과, SD3 Medium이 텍스트를 처리하는 능력이 SDXL 모델보다 개선되었으나 여전히 완벽하지는 않은 점을 확인할 수 있었습니다. 특히, 복잡한 문구나 철자 정확성에서 아직도 추가적인 발전이 필요함을 알 수 있었습니다. 향후 업데이트에서 텍스트 정확성을 더욱 향상시키고, 다양한 텍스트-이미지 응용 분야에서의 성능을 강화할 수 있기를 기대합니다.
이 글을 통해 SD3 Medium의 잠재력과 현재 한계를 이해하는 데 도움이 되었기를 바라며, 모델을 더욱 효율적으로 활용할 수 있기를 바랍니다. 그럼 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.06.12 - [AI 도구] - InvokeAI 설치 가이드: 최신 AI 모델로 이미지 생성 및 편집(feat. LightningAI)
InvokeAI 설치 가이드: 최신 AI 모델로 이미지 생성 및 편집(feat. LightningAI)
안녕하세요, 오늘은 AI 기술을 활용하여 창의적인 비주얼 미디어를 만드는 데 도움을 주는 강력한 도구인 InvokeAI를 소개해드리겠습니다. InvokeAI는 통합 캔버스를 통한 인/아웃페인팅, 노드 기반
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| Claude 3.5 Sonnet: GPT-4o를 뛰어넘은 성능 및 새로운 인터페이스 Artifacts 리뷰 (1) | 2024.06.22 |
|---|---|
| DeepSeek-Coder-V2: 현존 최강 AI 코딩 언어 모델 분석 및 테스트 (0) | 2024.06.20 |
| Qwen-2:🌐27개 언어 구사, 알리바바의 자바스크립트 천재 언어 모델 💻 (2) | 2024.06.08 |
| [AI 논문] Aya 23 모델: 🌐23개 언어 지원 다국어 LLM 성능 분석 (2) | 2024.06.01 |
| 🌟코딩 혁신: Codestral - 미스트랄이 만든 AI 코드 생성 끝판왕!🚀 (0) | 2024.05.31 |



