안녕하세요! 오늘은 멀티모달 대규모 언어 모델 LLaVA의 업데이트 소식에 대해 알아보겠습니다. LLaVA (Language-Image Visual Assistant, 언어-이미지 시각 어시스턴트)는 시각적 지시 조정기술(Visual Instruction Tuning, VIT)을 기반으로 개발된 언어와 이미지 간의 복합적인 상호 작용에 중점을 둔 멀티모달 모델입니다. 이번에 발표된 LLaVA NeXT는 여러 벤치마크에서 구글의 제미나이 프로를 능가하며, 이전 버전인 LLaVA 1.5에 비해 입력 이미지 해상도, OCR기능등이 개선되었다고 합니다. 이 블로그에서는 LLaVA NeXT의 특징, 개선 사항, 벤치마크 결과, 로컬 실행 방법 등에 대해서 알아보겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
LLaVA NeXT 특징 및 개선사항
LLaVA-NeXT는 개선된 추론, 광학 문자 인식(OCR), 그리고 다양한 지식을 갖춘 시각적 지시 기반 대규모 멀티모달 모델(LMM)입니다. 시각적 지시(Visual Instruction)란 화면이나 이미지 같은 시각적인 컨텐츠에 대한 언어적인 설명이나 지시를 말합니다.(예. 빨간색 자동차를 찾아라, 이 음식으로 어떤 요리를 만들 수 있는지 알려줘 등)
이 모델은 12개의 데이터셋을 기반으로 한 강력한 성능을 바탕으로 한 LLaVA-1.5의 기반을 이어받아 다양한 응용 프로그램에서 사용되고 있습니다. LLaVA-NeXT의 주요 특징과 개선 사항은 다음과 같습니다.
- 이미지 해상도 증가: 입력 이미지 해상도가 4배로 증가하여 시각적 세부 사항을 더 잘 파악할 수 있습니다. 672x672, 336x1344, 1344x336까지 3가지 종횡비를 지원합니다.
- 강화된 시각적 추론 및 OCR: 시각적 지시 튜닝 데이터 혼합을 개선하여 시각적 추론 및 OCR 기능을 향상시켰습니다. 다양한 응용 프로그램을 포함한 더 나은 시각적 대화가 가능합니다.
- 효율적인 배포: LLaVA-NeXT는 LLaVA-1.5의 미니멀한 디자인과 데이터 효율성을 유지하면서 효율적인 배포 및 추론을 지원합니다. 대규모 언어 모델 (LLMs)을 위해 설계된 구조화된 생성 언어, SGLang을 사용하여 효율적인 배포와 추론이 가능합니다.
- 다이내믹 고해상도(Dynamic High Resolution): 고해상도 이미지를 사용하여 모델을 설계하여 데이터 효율성을 유지합니다. 이는 모델이 더 정교한 세부 사항을 파악할 수 있게 합니다. 저해상도 이미지의 모델 환상을 줄이기 위해 'AnyRes' 기술을 도입하여 {2×2,1×{2,3,4},{2,3,4}×1}과 같은 그리드 구성을 채택했습니다. 이 그리드 구성은 이미지 처리를 위해 각기 다른 크기의 블록으로 이미지를 분할하는 방식으로, 모델이 다양한 고해상도 이미지를 효율적으로 처리할 수 있도록 합니다.

- 데이터 혼합(Data Mixture): 고품질 사용자 지시 데이터를 사용하여 모델을 학습했습니다. 이를 통해 다양한 사용자 의도를 대표할 수 있도록 하였습니다. 기존의 GPT-V 데이터뿐만 아니라 새로운 시각적 대화를 위한 작은 튜닝 데이터셋을 포함하는 여러 데이터 소스를 고려하여 모델을 향상시켰습니다.
- LLM 백본의 확장(Scaling LLM backbone): Vicuna-1.5 (7B 및 13B) 외에도 Mistral-7B 및 Nous-Hermes-2-Yi-34B를 포함한 여러 LLM들을 고려합니다. 이러한 LLM들은 우수한 특성 뿐 아니라, 유연한 상업적 이용 조건, 강력한 2개 국어 지원 및 더 큰 언어 모델 용량을 가지고 있습니다. 이는 LLaVA가 더 넓은 사용자 스펙트럼과 커뮤니티 내의 더 많은 시나리오를 지원할 수 있게 합니다.
https://llava-vl.github.io/blog/2024-01-30-llava-next/
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge
LLaVA team presents LLaVA-NeXT, with improved reasoning, OCR, and world knowledge. LLaVA-NeXT even exceeds Gemini Pro on several benchmarks.
llava-vl.github.io
LLaVA NeXT 벤치마크 결과
다음은 다양한 언어모델과의 벤치마크 결과를 나타내는 비교표 입니다. LLaVA-NeXT-34B는 대부분의 벤치마크 결과에서 제미나이 프로를 앞서는 것으로 나타났습니다.
| Model | MMMU (val) | Math-Vista | MMB-ENG | MMB-CN | MM-Vet | LLaVA-Wild | SEED-IMG |
| GPT-4V | 56.8 | 49.9 | 75.8 | 73.9 | 67.6 | - | 71.6 |
| Gemini Ultra | 59.4 | 53 | - | - | - | - | - |
| Gemini Pro | 47.9 | 45.2 | 73.6 | 74.3 | 64.3 | - | 70.7 |
| Qwen-VL-Plus | 45.2 | 43.3 | - | - | 55.7 | - | 65.7 |
| CogVLM-30B | 32.1 | - | - | - | 56.8 | - | - |
| Yi-VL-34B | 45.9 | - | - | - | - | - | - |
| LLaVA-1.5-13B | 36.4 | 27.6 | 67.8 | 63.3 | 36.3 | 72.5 | 68.2 |
| LLaVA-NeXT-34B | 51.1 | 46.5 | 79.3 | 79 | 57.4 | 89.6 | 75.9 |
- 높은 수준의 성능: LLaVA-NeXT는 CogVLM이나 Yi-VL과 같은 오픈 소스 LMM과 비교하여 높은 수준의 성능을 달성하였으며 선택된 벤치마크에서 상용 제품인 제미나이 프로와 Qwen-VL-Plus를 앞지르고 있습니다.
- 중국어 지원: LLaVA-NeXT는 중국어 지원이 가능하며, 영어 다중 모달 데이터만 고려한 제로샷(zero-shot) 기능을 갖추고 있습니다. 특히 중국어 다중 모달 시나리오에서의 성능이 우수하며 MMBench-CN에서 최고 성능을 보여줍니다.
- 저렴한 훈련 비용: LLaVA-NeXT는 32개의 GPU로 약 1일 동안 훈련되었으며, 총 130만 개의 데이터 샘플을 사용합니다. 다른 모델들과 비교하여 훈련 비용이 100-1000배 낮습니다.
LLaVA와 GPT-4의 비교 테스트를 위한 평가 데이터셋은 30개의 이전에 보지 않았던 이미지로 구성되어 있습니다. 각 이미지는 대화, 상세 설명 및 복잡한 추론과 관련된 세 가지 유형의 지시사항과 연결되어 있습니다. 총 90개의 새로운 언어-이미지 지시사항이 생성되며, 여기에 LLaVA 및 GPT-4를 테스트하고, GPT-4를 사용하여 그들의 응답을 점수 1에서 10까지 평가합니다. 아래 원 그래프는 LLaVA와 GPT-4의 비교 테스트 결과입니다.

전반적으로, LLaVA는 GPT-4와 비교하여 상대적 점수로 85.1%의 성과를 달성하였습니다.
LLaVA NeXT 로컬 실행
LLaVA NeXT를 로컬에서 실행할수 있는 방법은 오픈소스 대규모 언어모델 도구 Ollama를 활용하는 방법과 깃 허브 저장소를 이용한 방법이 있습니다. 먼저 Ollama를 활용한 방법은 아래 링크를 참조하여 간단한 명령어로 실행할 수 있습니다.
https://ollama.ai/blog/vision-models
Vision models · Ollama Blog
New vision models are now available: LLaVA 1.6, in 7B, 13B and 34B parameter sizes. These models support higher resolution images, improved text recognition and logical reasoning.
ollama.ai
Ollama는 아직 윈도우 운영체제를 정식으로 지원하지 않으므로 WSL 프롬프트 상에서 Ollama를 설치한 후 ollama run llava "describe this image: ./sample.jpg"와 같은 형식으로 명령어를 입력하면 LLaVA 모델을 실행할 수 있습니다.
Ollama의 설치는 아래 링크를 참고하시기 바랍니다.
2023.12.15 - [대규모 언어모델] - Ollama를 활용한 대규모 언어 모델 웹 인터페이스 만들기: Mistral 7B와의 대화
Ollama를 활용한 대규모 언어 모델 웹 인터페이스 만들기: Mistral 7B와의 대화
안녕하세요. 오늘은 내 컴퓨터에서 웹 인터페이스로 최신 언어모델과 대화하는 프로젝트에 도전해 보겠습니다. 이 블로그에서는 Ollama라는 오픈소스 도구를 이용해서 최신 인기 대규모 언어모
fornewchallenge.tistory.com
다음 이미지는 Ollama를 활용한 LLaVA NeXT의 이미지 설명에 사용할 test.png입니다.

위 이미지에 대해 LLaVA NeXT가 응답한 설명은 다음과 같습니다.

사진 속에는 핑크빛 머리를 한 젊은 여성이 담겨 있습니다. 사진의 배경은 모래인 것으로 보이며, 모래의 입자와 질감이
눈에 띕니다. 여성은 진한 녹색 또는 검은색의 민소매 상의를 입고 있으며, 화려한 머리색과 대조적입니다.
그녀의 시선은 카메라에서 멀리 향하고 있습니다.
사진의 배경은 맑은 하늘을 보여주며, 햇빛이 있는 날씨일 것으로 보입니다. 멀리에는 식물의 힌트가 있어 해변 풍경에
약간의 식물이 더해졌습니다. 여성은 이미지의 왼쪽에 약간 비대칭적으로 위치하여 시선을 흥미롭게 만들었습니다.
이 사진은 고요하고 편안한 분위기를 담고 있으며, 안정된 설정과 주제의 편안한 자세로 나타납니다. 이는 일상에서 조금
벗어나 새로운 장소를 탐험하거나 휴식을 취하는 사람의 순간을 담은 것입니다. 이미지는 개인을 초점으로 삼고 자연광을
조명으로 사용하여 색상과 질감을 강조하는 예술적 품질을 가지고 있습니다.
LLaVA NeXT를 로컬에서 실행할 수 있는 두 번째 방법은 깃 허브 저장소와 Gradio 인터페이스를 이용한 방법입니다. 아래 플로우는 깃 허브 저장소를 이용한 방법의 DEMO 프로세스 구성입니다.
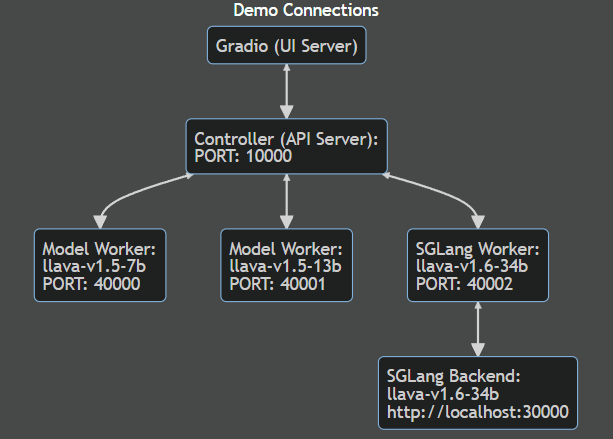
먼저 깃 허브 저장소 복사, 환경설정 및 종속성 설치는 다음 명령어를 참고해서 순서대로 실행합니다.
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA
conda create -n llava python=3.10 -y
conda activate llava
pip install --upgrade pip
pip install -e .
위 명령어는 LLaVA 프로젝트를 클론하고 로컬 환경에서 실행하기 위한 단계입니다. 각 단계는 다음과 같습니다:
- `git clone https://github.com/haotian-liu/LLaVA.git`: 이 명령어는 GitHub 저장소에서 LLaVA 프로젝트를 로컬 컴퓨터로 복제합니다. 이렇게 하면 현재 디렉토리에 'LLaVA'라는 폴더가 생성됩니다.
- `cd LLaVA`: 이 명령어는 'LLaVA' 폴더로 이동합니다. 이 폴더에는 클론한 LLaVA 프로젝트의 모든 파일이 포함되어 있습니다.
- `conda create -n llava python=3.10 -y`: 이 명령어는 이름이 'llava'인 새로운 Conda 환경을 생성합니다. 이 환경은 Python 버전 3.10을 사용합니다. `-y` 옵션은 사용자에게 확인 메시지 없이 진행하도록 합니다.
- `conda activate llava`: 이 명령어는 새로 생성한 'llava' 이름의 가상환경을 활성화합니다. 이렇게 하면 현재 쉘 세션에서 'llava' 환경의 패키지가 사용됩니다.
- `pip install --upgrade pip`: 이 명령어는 Python 패키지 관리자인 pip를 최신 버전으로 업그레이드합니다.
- `pip install -e .`: 이 명령어는 현재 디렉토리에 있는 LLaVA 프로젝트를 패키지로 설치합니다. `-e` 옵션은 editable 모드로 설치하며, 이는 소스 코드가 수정될 때 자동으로 변경 사항이 반영되도록 합니다. 이렇게 하면 LLaVA 프로젝트를 로컬 환경에서 사용할 수 있게 됩니다.
종속성 설치가 모두 끝나면 WSL 프롬프트 상에서 아래와 같이 명령어를 입력하여 Controller, Worker, Gradio UI의 세 가지 프로세스를 실행합니다. 각 프로세스는 실행한 후 터미널 창을 유지한 채로 다음 프로세스를 실행합니다.
- Controller : python -m llava.serve.controller --host 0.0.0.0 --port 10000
- Worker : python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.6-34b --load-4bit, <중요>이 단계에서 LLaVA 모델을 다운로드 하게 되는데, 디스크 용량이나 GPU 성능이 부족한 경우 파라미터가 작은 llava-v1.6-mistral-7b 모델로 수정해줍니다. 모델을 다운로드하는 과정에서 허깅페이스 로그인을 위한 토큰을 물어보는 경우, 허깅페이스 웹페이지에서 발급한 액세스 토큰을 "huggingface-cli login --token 발급받은 액세스 토큰 --add-to-git-credential"와 같이 입력합니다.
- Gradio UI : python -m llava.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload --share, 그라디오 인터페이스를 설정하는 명령어입니다.
허깅페이스 CLI 로그인을 위한 토큰을 물어보는 경우, 아래 링크를 참조하시면 됩니다.
https://huggingface.co/docs/huggingface_hub/main/en/guides/cli
Command Line Interface (CLI)
The huggingface_hub Python package comes with a built-in CLI called huggingface-cli. This tool allows you to interact with the Hugging Face Hub directly from a terminal. For example, you can login to your account, create a repository, upload and download f
huggingface.co
# Or using an environment variable
>>> huggingface-cli login --token $HUGGINGFACE_TOKEN --add-to-git-credential
Token is valid (permission: write).
Your token has been saved in your configured git credential helpers (store).
Your token has been saved to /home/wauplin/.cache/huggingface/token
Login successful
Gradio UI 명령어를 입력하면 http://localhost:7860/ 주소에서 다음 화면과 같이 로컬 LLaVA 모델에게 이미지와 텍스트를 입력할 수 있는 웹 인터페이스가 뜹니다. 실행 결과 LLaVA가 이미지를 잘 인식하여 설명해 주는 것을 확인할 수 있습니다.
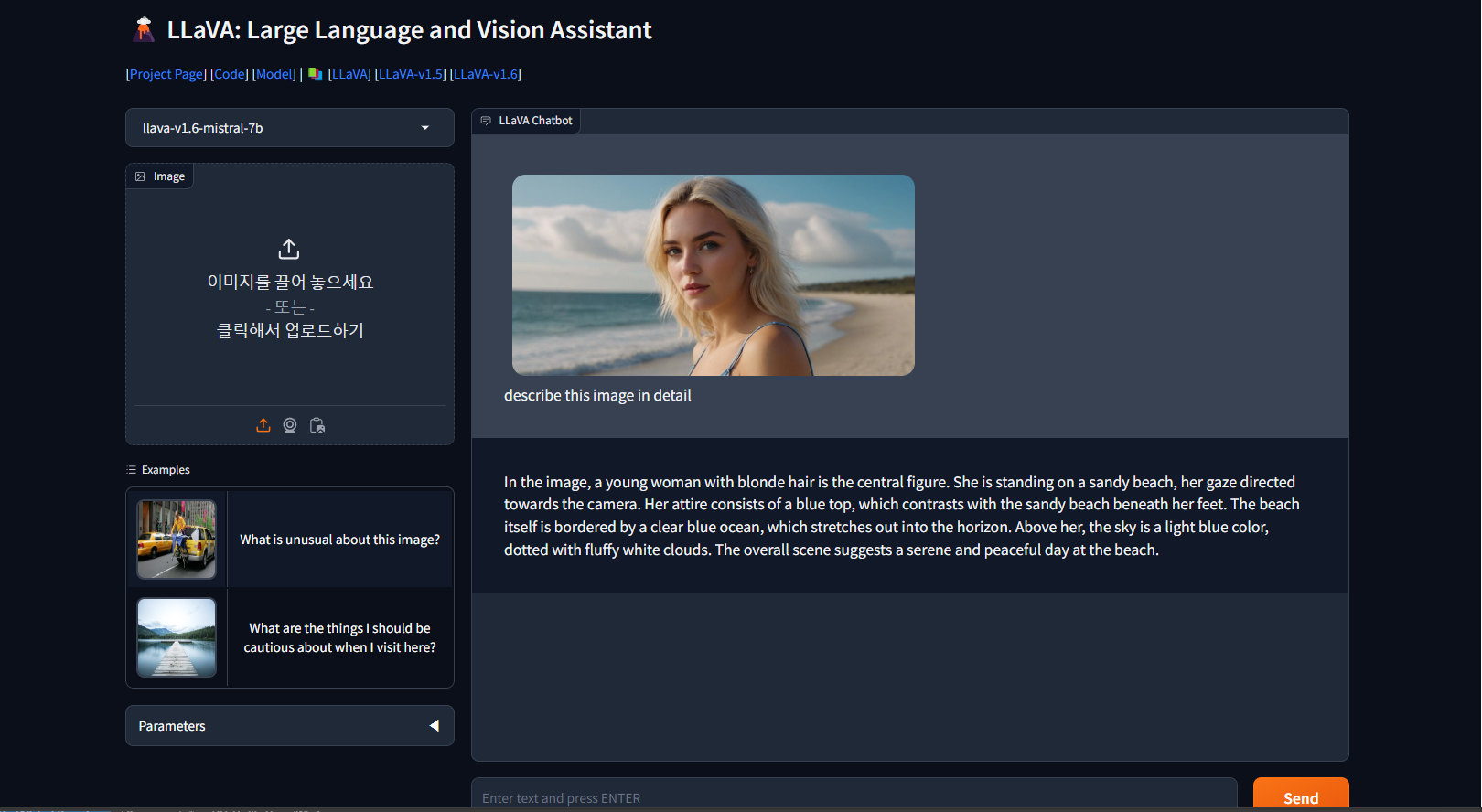
이미지에서, 금발의 젊은 여성이 중심 인물입니다. 그녀는 모래사장에 서 있고, 그녀의 시선은 카메라를 향합니다.
그녀의 의상은 발 아래의 모래사장과 대조되는 파란색 상의로 구성되어 있습니다. 해변 그 자체는 수평선으로 뻗어
있는 투명한 푸른 바다와 접하고 있습니다. 그녀의 위에, 하늘은 솜털로 덮인 하얀 구름으로 점철된 밝은 파란색입니다.
전체적인 장면은 해변의 조용하고 평화로운 날을 암시합니다.
마치며
LLaVA NeXT는 상세한 추론, 광학 문자 인식(OCR), 그리고 다양한 지식을 기반으로 한 멀티모달 모델로, 이번 업데이트에서는 이전 버전에 비해 여러 가지 측면에서 개선되었습니다. 먼저, 입력 이미지의 해상도가 4배로 증가하여 시각적 세부 사항을 더 잘 파악할 수 있게 되었습니다. 또한 시각적 지시 튜닝 데이터 혼합을 통해 시각적 추론 및 OCR 기능을 향상시켰으며, 이를 통해 다양한 응용 프로그램에 대한 더 나은 시각적 대화가 가능해졌습니다.
이 블로그에서는 LLaVA NeXT의 특징, 개선 사항, 벤치마크 결과, 로컬 실행 방법 등에 대해서 알아보았습니다. 제가 경험해 본 LLaVA NeXT의 이미지 해석기능은 놀라울 정도의 디테일과 이미지를 통해 우리가 쉽게 생각하지 못하는 다양한 상황에 대해 추론을 생성하였습니다. 여러분도 오픈소스 멀티모달 언어모델 LLaVA NeXT의 기능을 한번 체험해 보시면 좋은 경험이 될것 같습니다. 저는 그럼 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2024.01.31 - [대규모 언어모델] - 메타의 새로운 코딩용 대규모 언어 모델 : Code Llama 70B
메타의 새로운 코딩용 대규모 언어 모델 : Code Llama 70B
안녕하세요! 오늘은 메타에서 최근 공개한 Code Llama 70B에 대해서 알아보겠습니다. Code Llama 70B는 Code Llama 패밀리에서 가장 크고 성능이 우수한 모델로써, 이전에 공개된 Code Llama 모델과 동일한 세
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 벡터 데이터베이스와 Llama2를 활용한 arXiv 논문 자동검색 및 분석 (0) | 2024.02.16 |
|---|---|
| 구글 제미나이 울트라 1.0, 과연 진정한 AI 혁신인가? 솔직 후기 공개! (6) | 2024.02.12 |
| 메타의 새로운 코딩용 대규모 언어 모델 : Code Llama 70B (0) | 2024.01.31 |
| Ollama와 대규모 언어 모델 Llama2-uncensored를 활용한 PDF 요약과 음성변환 (3) | 2024.01.13 |
| Mixtral 대규모 언어 모델과 RAG을 활용한 위키피디아 검색 자동화 (1) | 2024.01.11 |



