안녕하세요! 오늘은 마이크로소프트의 최신 비전 모델 Florence-2에 대해서 알아보겠습니다. 이 모델은 복잡한 공간적 계층 구조와 의미론적 세분화를 다루는 능력을 통해 객체 감지, 이미지 캡션 생성은 물론, 각 픽셀을 객체 또는 장면 범주로 분류하는 시맨틱 분할, 특정 구문과 관련된 영역을 식별하는 구문 분할, 객체가 있을 가능성이 높은 이미지 영역을 제안하는 영역 제안과 같은 다양한 시각 작업을 수행할 수 있습니다. 이 블로그에서는 Florence-2 모델의 개요 및 주요 특징, 동작리에 대해 알아보고 주요 기능에 대한 DEMO 테스트를 진행해 보겠습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Florence-2 개요 및 특징
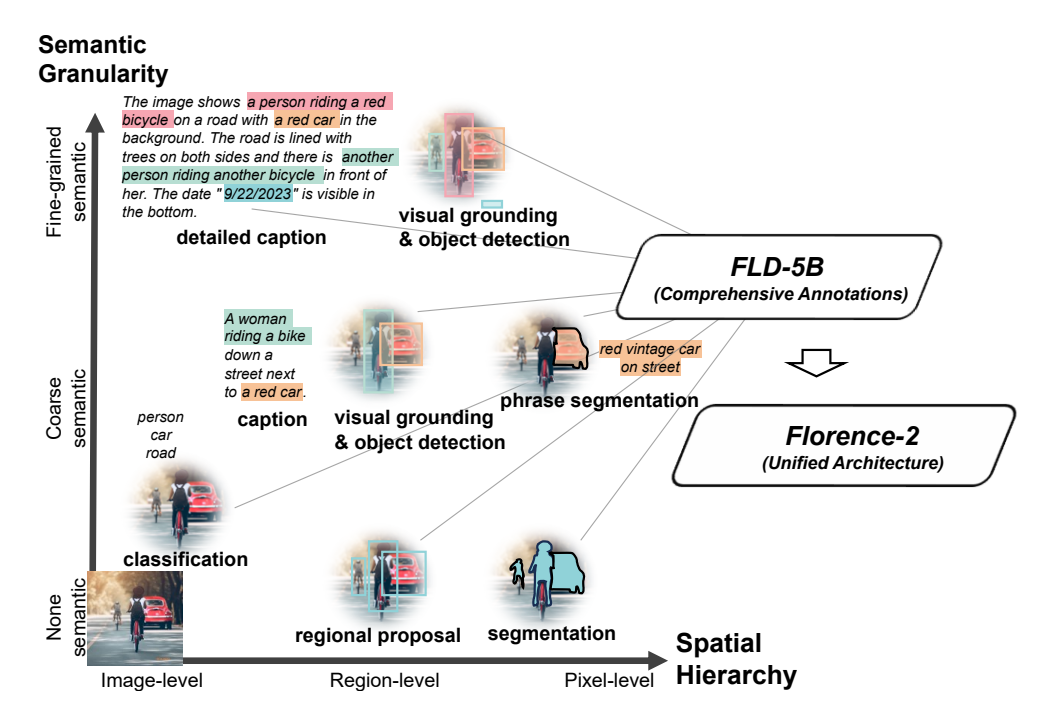
Florence-2의 핵심 아이디어는 텍스트 프롬프트를 태스크 지시로 받아 캡셔닝, 객체 탐지, 그라운딩(이미지 내 특정 영역을 텍스트 설명과 매핑) , 세그멘테이션(이미지 내 모든 픽셀을 클래스 또는 객체로 분류하여 경계와 형태를 파악) 등 다양한 비전 태스크의 결과를 텍스트 형태로 생성하는 것입니다. 이 모델은 1억 2천 6백만 개의 이미지와 54억 개의 주석으로 구성된 방대한 데이터셋인 FLD-5B를 사용하여 사전 학습되어, 이미지를 픽셀 수준에서부터 전체 이미지에 대한 설명에 이르기까지 다양한 작업을 0.23B/0.77B 단일 모델로 통합합니다.
Florence는 다양한 컴퓨터 비전 작업을 수행할 수 있는 강력하고 다재다능한 모델로서, 대규모 데이터셋과 통합 아키텍처를 통해 이미지를 포괄적으로 이해할 수 있습니다. Florence-2 모델의 주요 특징은 다음과 같습니다:
- 통합된 프롬프트 기반 표현: Florence-2는 다양한 비전 태스크를 위한 단일 통합 모델을 제공합니다. 텍스트 프롬프트를 통해 여러 태스크를 수행할 수 있어, 태스크별 특화 모델 없이도 다양한 비전 문제를 해결할 수 있습니다.
- 공간적 계층 구조와 의미론적 세분화 처리: 이 모델은 이미지 수준의 개념부터 픽셀 수준의 세부 사항까지 다양한 스케일의 공간적 세부 정보를 인식할 수 있습니다. 또한 고수준 캡션부터 세부적인 설명까지 다양한 의미론적 세분화를 다룰 수 있습니다.
- 대규모 고품질 데이터셋 활용: FLD-5B라는 54억 개의 주석을 포함한 대규모 데이터셋을 사용하여 훈련되었습니다. 이 데이터셋은 자동화된 주석 생성과 모델 개선의 반복적 과정을 통해 구축되었습니다.
- 제로샷 및 파인튜닝 성능: Florence-2는 다양한 태스크에서 뛰어난 제로샷 성능을 보여주며, 파인튜닝 후에는 더 큰 전문 모델들과 경쟁할 수 있는 성능을 보여줍니다.
구성요소 및 동작원리
Florence-2 모델의 구성요소는 이미지 인코더와 표준 멀티모달리티 인코더-디코더로 구성되어 있으며, 동작원리는 다음과 같습니다.
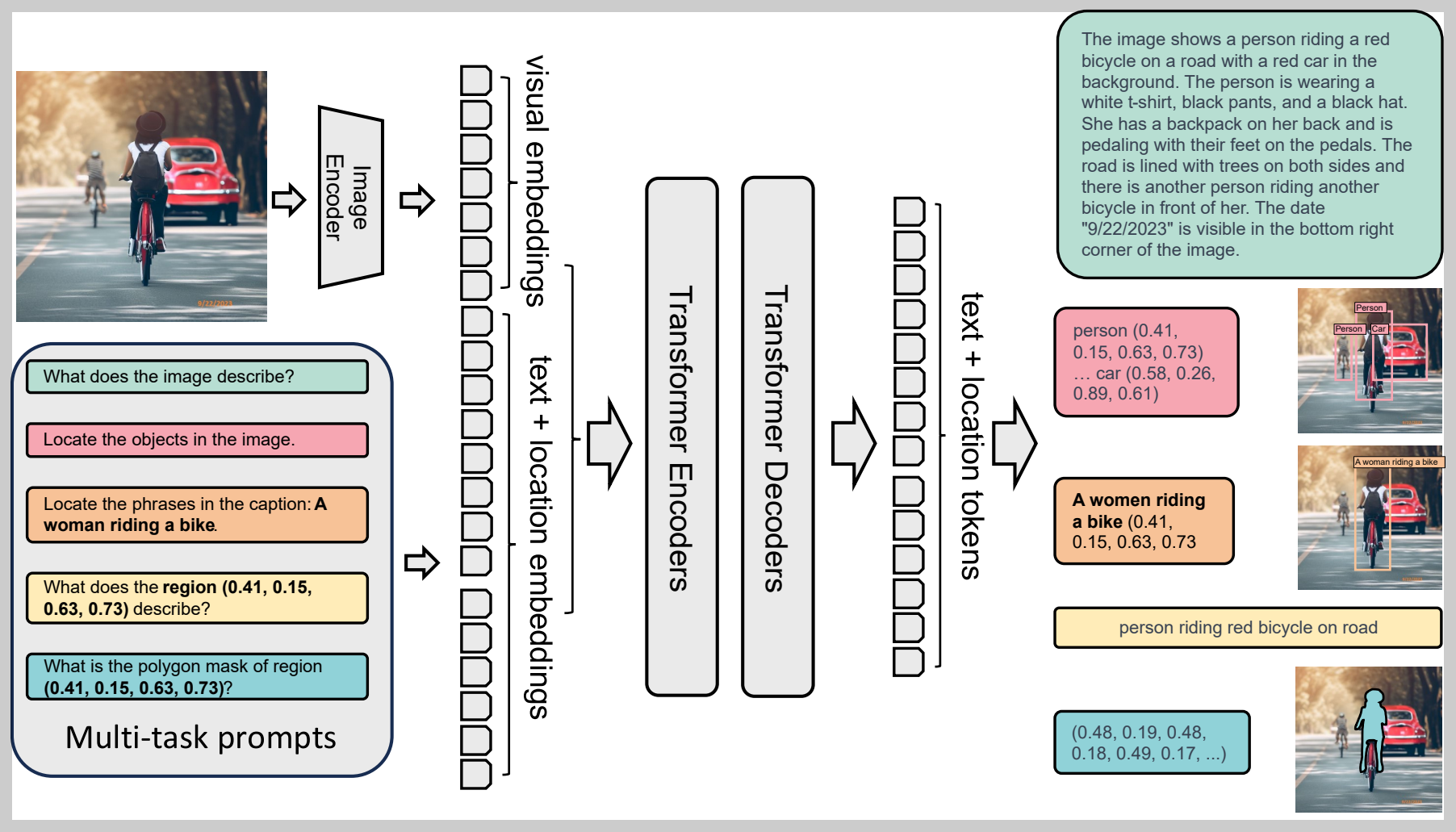
- 이미지 인코더: 이미지를 입력받아 시각적 특징을 추출합니다.
- 텍스트+위치 임베딩: 텍스트 입력을 받아 각 단어에 해당하는 임베딩을 생성하고, 이미지 내 위치 정보와 결합합니다.
- 트랜스포머 인코더: 텍스트 + 위치 임베딩을 받아 더 풍부한 의미 정보를 추출합니다.
- 트랜스포머 디코더: 이미지 인코더에서 추출된 시각적 특징과 트랜스포머 인코더에서 생성된 텍스트 정보를 결합하여 최종 출력을 생성합니다.
Florence-2는 이미지 캡션 생성, 객체 위치 파악, 영역 설명, 폴리곤 마스크 생성과 같은 다양한 작업을 수행할 수 있도록 다중 작업 프롬프트 (Multi-task prompts)를 입력받을 수 있습니다.
- "What does the image describe?": 이미지 전체에 대한 설명을 요구합니다.
- "Locate the objects in the image.": 이미지에서 특정 객체를 찾아 위치를 파악하도록 지시합니다.
- "What does the region (0.41, 0.15, 0.63, 0.73) describe?": 이미지 내 특정 영역에 대한 설명을 요구합니다.
- "What is the polygon mask of region (0.41, 0.15, 0.63, 0.73)?": 특정 영역을 나타내는 폴리곤 마스크 생성을 요청합니다.
성능 평가 결과
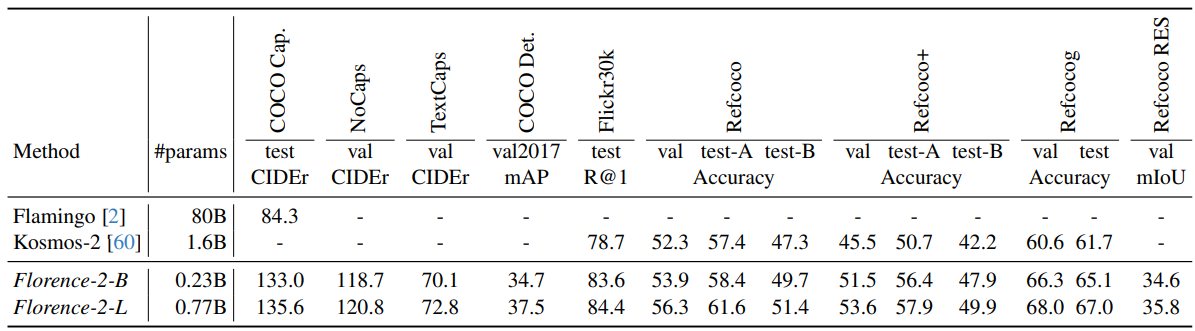
Florence-2 모델의 성능은 다양한 비전 태스크에서 평가되었으며, 제로샷 성능과 파인튜닝 후 성능 모두에서 뛰어난 결과를 보여주었습니다. 주요 성능 평가 결과는 다음과 같습니다:
1) 제로샷 성능: 모델이 학습하지 않은 새로운 데이터나 작업에서 성능을 평가
- 캡셔닝: COCO 데이터셋에서 최첨단 제로샷 성능 달성
- 시각적 그라운딩: Flickr30k 데이터셋에서 최고 성능 기록
- 참조 표현 이해: RefCOCO, RefCOCO+, RefCOCOg 데이터셋에서 최고 성능 달성
이러한 제로샷 성능 결과는 Florence-2가 사전 학습 과정에서 획득한 강력한 일반화 능력을 보여줍니다. 특별한 파인튜닝 없이도 다양한 비전 태스크에서 우수한 성능을 발휘할 수 있음을 의미합니다.
2) 파인튜닝 후 성능: 사전 훈련된 모델을 특정 작업에 맞춰 추가적으로 훈련한 후 해당 작업에서 모델이 보이는 성능
- 참조 표현 이해: RefCOCO, RefCOCO+, RefCOCOg 데이터셋에서 파인튜닝 후 새로운 최고 성능 기록
- 객체 탐지 및 인스턴스 세그멘테이션: COCO 데이터셋에서 기존 모델들을 크게 상회하는 성능 달성
- 의미론적 세그멘테이션: ADE20K 데이터셋에서 상당한 성능 향상 기록
Florence-2는 파인튜닝 후에도 더 큰 전문 모델들과 경쟁할 수 있는 성능을 보여주었습니다. 특히 컴팩트한 크기에도 불구하고 우수한 성능을 달성했다는 점이 주목할 만합니다.
3) 계산 효율성: Florence-2는 파라미터 수가 0.23B/0.77B로 기존의 대규모 비전 모델들에 비해 상대적으로 작은 규모임에도 불구하고 우수한 성능을 보여주었으며, 모델의 효율적인 설계를 통해 학습 효율성이 4배 향상되었다는 점은 실제 응용에 있어 큰 장점이 될 수 있습니다.
4) 다양성 및 일반화 능력: Florence-2는 이미지 분류, 객체 탐지, 세그멘테이션, 캡셔닝, 시각적 질문 응답 등 다양한 비전 태스크에서 고르게 우수한 성능을 보여주었습니다. 이는 모델이 획득한 시각 표현이 매우 범용적이고 일반화 능력이 뛰어남을 의미합니다.
DEMO 테스트
다음은 DEMO 테스트입니다. DEMO 앱은 Florence-2 모델의 이미지 캡셔닝, 이미지 객체검출 및 바운딩 박스 생성, 이미지 내 텍스트 인식, 생성된 캡션과 이미지 내의 특정 영역 매핑과 같은 다양한 비전 관련 작업을 수행하고 결과를 시각적으로 표시합니다.
이 블로그의 테스트 환경은 Windows 11 Pro(23H2), WSL2, 파이썬 버전 3.11, 비주얼 스튜디오 코드(이하 VSC) 1.90.2이며, VSC를 실행하여 "WSL 연결"을 통해 Windows Subsystem for Linux(WSL) Linux 환경에 액세스 하도록 구성하였습니다. DEMO 테스트의 실행순서는 다음과 같습니다.
1. 가상환경 생성 및 활성화: VSC에서 아래 명령어를 통해 가상환경을 생성하고 활성화합니다.
python3.11 -m venv myenv
source myenv/bin/activate2. 의존성 설치: 이미지에 바운딩 박스를 그리거나, 시각적인 결과를 보여주기 위한 플롯을 생성하는 라이브러리인 matplotlib 등 필요한 의존성 패키지를 설치합니다.
pip install transformers chainlit Pillow matplotlib torch timm einops flash_attn
3. DEMO 앱 실행: 아래 코드를 복사하여 app.py로 저장하고 "chainlit run app.py" 명령어로 실행합니다.
import os
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from PIL import Image
import chainlit as cl
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
import numpy as np
# Initialize Florence-2-large model and processor
model_id = 'microsoft/Florence-2-large'
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True).eval().cuda()
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
# Function to resize and preprocess image
def preprocess_image(image_path, max_size=(800, 800)):
image = Image.open(image_path).convert('RGB')
if image.size[0] > max_size[0] or image.size[1] > max_size[1]:
image.thumbnail(max_size, Image.LANCZOS)
# Convert image to numpy array
image_np = np.array(image)
# Ensure the image is in the format [height, width, channels]
if image_np.ndim == 2: # Grayscale image
image_np = np.expand_dims(image_np, axis=-1)
elif image_np.shape[0] == 3: # Image in [channels, height, width] format
image_np = np.transpose(image_np, (1, 2, 0))
return image_np, image.size
# Function to run Florence-2-large model
def run_florence_model(image_np, image_size, task_prompt, text_input=None):
if text_input is None:
prompt = task_prompt
else:
prompt = task_prompt + text_input
inputs = processor(text=prompt, images=image_np, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(
input_ids=inputs["input_ids"].cuda(),
pixel_values=inputs["pixel_values"].cuda(),
max_new_tokens=1024,
early_stopping=False,
do_sample=False,
num_beams=3,
)
generated_text = processor.batch_decode(outputs, skip_special_tokens=False)[0]
parsed_answer = processor.post_process_generation(
generated_text,
task=task_prompt,
image_size=image_size
)
return parsed_answer, generated_text
# Function to plot image with bounding boxes
def plot_image_with_bboxes(image_np, bboxes, labels=None):
fig, ax = plt.subplots(1)
ax.imshow(image_np)
colors = ['red', 'blue', 'green', 'yellow', 'purple', 'cyan']
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
x, y, width, height = bbox[0], bbox[1], bbox[2] - bbox[0], bbox[3] - bbox[1]
rect = patches.Rectangle((x, y), width, height, linewidth=2, edgecolor=color, facecolor='none')
ax.add_patch(rect)
if labels and i < len(labels):
ax.text(x, y, labels[i], color=color, fontsize=8, bbox=dict(facecolor='white', alpha=0.7))
plt.axis('off')
return fig
# Chainlit message handler to process uploaded images
@cl.on_message
async def on_message(msg: cl.Message):
if not msg.elements:
await cl.Message(content="No file attached").send()
return
# Process images exclusively
images = [file for file in msg.elements if "image" in file.mime]
if not images:
await cl.Message(content="No image file attached").send()
return
image_path = images[0].path
image_np, image_size = preprocess_image(image_path)
# Image Captioning
caption_result, _ = run_florence_model(image_np, image_size, '<CAPTION>')
detailed_caption_result, _ = run_florence_model(image_np, image_size, '<DETAILED_CAPTION>')
# Object Detection
od_result, _ = run_florence_model(image_np, image_size, '<OD>')
od_bboxes = od_result['<OD>'].get('bboxes', [])
od_labels = od_result['<OD>'].get('labels', [])
# OCR
ocr_result, _ = run_florence_model(image_np, image_size, '<OCR>')
# Phrase Grounding
pg_result, _ = run_florence_model(image_np, image_size, '<CAPTION_TO_PHRASE_GROUNDING>', text_input=caption_result['<CAPTION>'])
pg_bboxes = pg_result['<CAPTION_TO_PHRASE_GROUNDING>'].get('bboxes', [])
pg_labels = pg_result['<CAPTION_TO_PHRASE_GROUNDING>'].get('labels', [])
# Cascaded Tasks (Detailed Caption + Phrase Grounding)
cascaded_result, _ = run_florence_model(image_np, image_size, '<CAPTION_TO_PHRASE_GROUNDING>', text_input=detailed_caption_result['<DETAILED_CAPTION>'])
cascaded_bboxes = cascaded_result['<CAPTION_TO_PHRASE_GROUNDING>'].get('bboxes', [])
cascaded_labels = cascaded_result['<CAPTION_TO_PHRASE_GROUNDING>'].get('labels', [])
# Create plots
od_fig = plot_image_with_bboxes(image_np, od_bboxes, od_labels)
pg_fig = plot_image_with_bboxes(image_np, pg_bboxes, pg_labels)
cascaded_fig = plot_image_with_bboxes(image_np, cascaded_bboxes, cascaded_labels)
# Prepare response
response = f"""
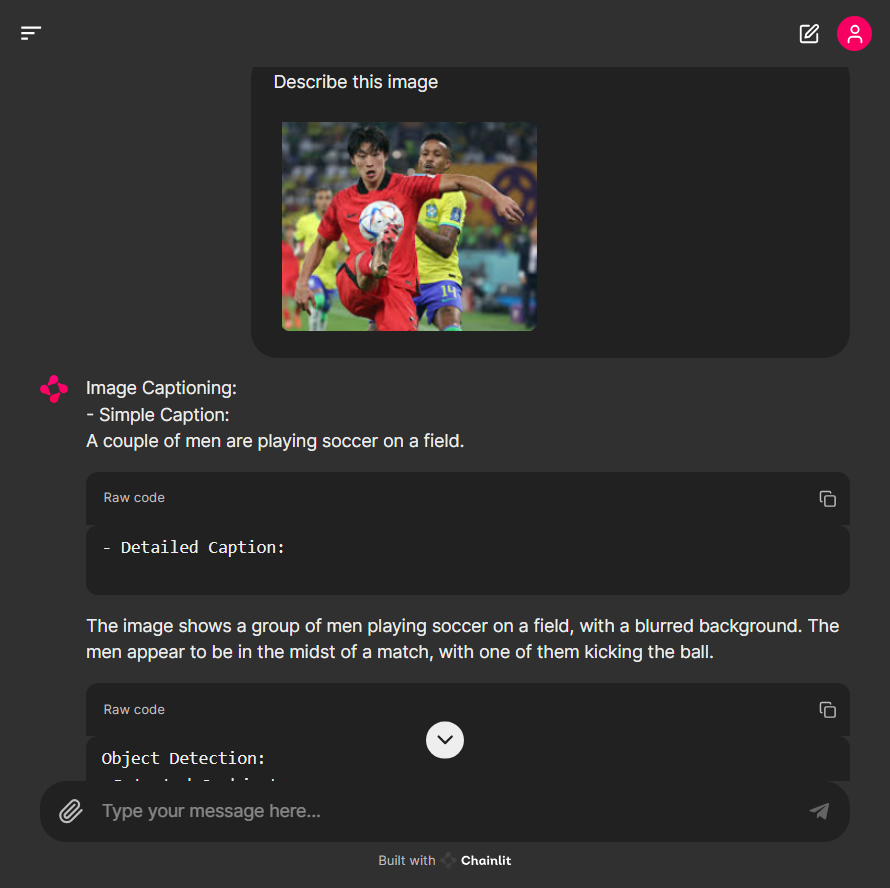
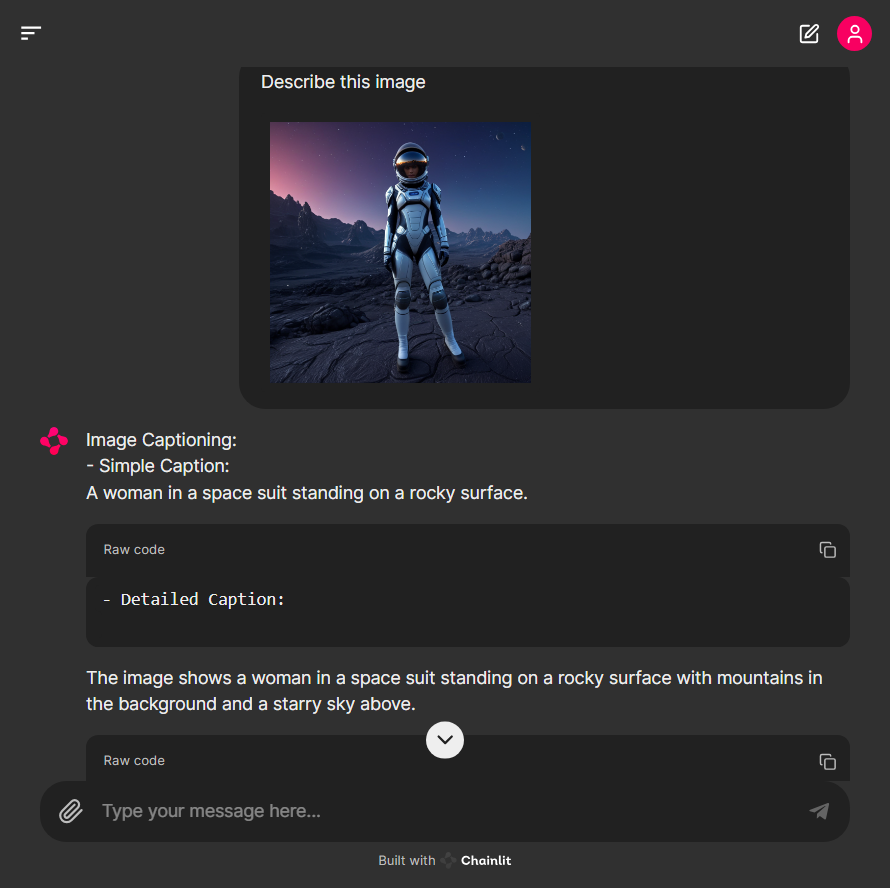
Image Captioning:
- Simple Caption: {caption_result['<CAPTION>']}
- Detailed Caption: {detailed_caption_result['<DETAILED_CAPTION>']}
Object Detection:
- Detected {len(od_bboxes)} objects
OCR:
{ocr_result['<OCR>']}
Phrase Grounding:
- Grounded {len(pg_bboxes)} phrases from the simple caption
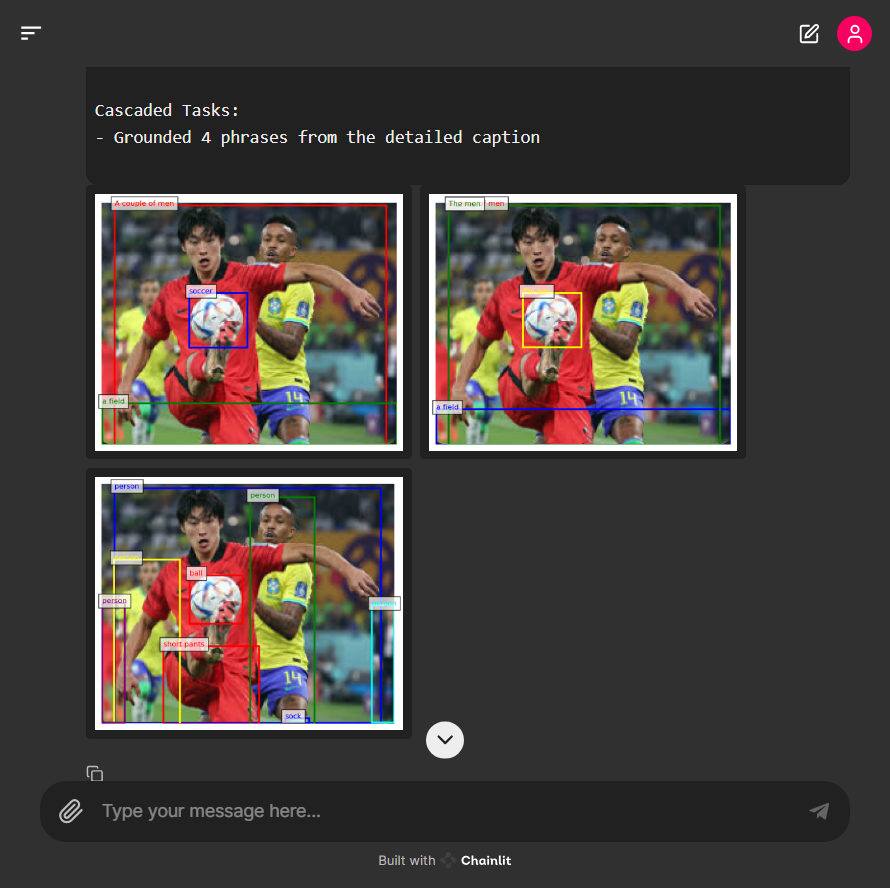
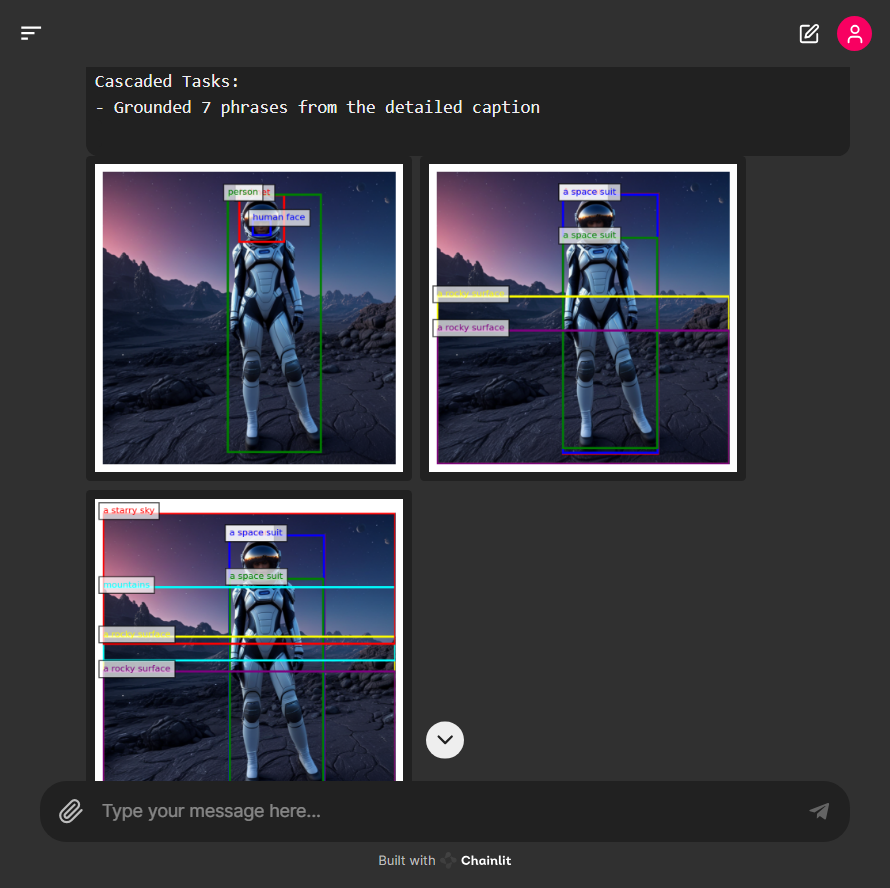
Cascaded Tasks:
- Grounded {len(cascaded_bboxes)} phrases from the detailed caption
"""
elements = [
cl.Pyplot(name="object_detection", figure=od_fig, display="inline"),
cl.Pyplot(name="phrase_grounding", figure=pg_fig, display="inline"),
cl.Pyplot(name="cascaded_tasks", figure=cascaded_fig, display="inline"),
]
await cl.Message(
content=response,
elements=elements,
).send()
if __name__ == "__main__":
cl.run()위 코드는 이미지를 업로드하여 다양한 비전 관련 작업을 수행하고 결과를 시각적으로 표시하는 Chainlit 애플리케이션입니다. 주요 기능은 다음과 같습니다:
- 1. 모델 및 프로세서 초기화: `AutoModelForCausalLM`과 `AutoProcessor`를 사용하여 Microsoft의 Florence-2-large 모델을 초기화합니다. 모델을 평가 모드로 설정하고 CUDA를 사용하여 GPU에서 실행됩니다.
- 2. 이미지 전처리: `preprocess_image` 함수는 이미지를 읽고 RGB 형식으로 변환한 후, 최대 크기로 리사이즈하고 numpy 배열로 변환합니다. 이미지의 형식과 크기를 조정하여 모델에 적합하게 만듭니다.
- 3. 모델 실행: `run_florence_model` 함수는 텍스트 프롬프트와 이미지 입력을 처리하고 모델에 전달하여 결과를 생성합니다. 모델의 출력에서 텍스트를 디코딩하고, 후처리 하여 결과를 반환합니다.
- 4. 이미지와 바운딩 박스 시각화: `plot_image_with_bboxes` 함수는 이미지와 바운딩 박스를 matplotlib를 사용하여 시각화합니다. 각 바운딩 박스를 다양한 색상으로 그리고, 필요하면 라벨도 추가합니다.
- 5. Chainlit 메시지 핸들러: `@cl.on_message` 데코레이터로 정의된 핸들러는 업로드된 이미지를 처리합니다. 업로드된 파일이 이미지인지 확인하고, 이미지를 전처리한 후, 다양한 비전 작업(이미지 캡셔닝, 객체 검출, OCR, 구절 그라운딩)을 수행합니다. 각 작업의 결과를 수집하고 시각화하여 메시지로 반환합니다. 생성된 이미지와 결과를 Chainlit 메시지로 표시합니다.
Chainlit 애플리케이션 기능 요약
- 이미지 캡셔닝: 간단한 캡션과 상세한 캡션을 생성합니다.
- 객체 검출: 이미지에서 객체를 검출하고 바운딩 박스를 생성합니다.
- OCR: 이미지에서 텍스트를 인식합니다.
- 구절 그라운딩: 생성된 캡션의 구절을 이미지 내의 특정 영역에 매핑합니다.
- 종합 작업: 상세한 캡션을 기반으로 구절 그라운딩을 수행합니다.
이 모든 과정을 통해, 사용자는 업로드된 이미지에 대해 다양한 비전 작업의 결과를 시각적으로 확인할 수 있습니다.
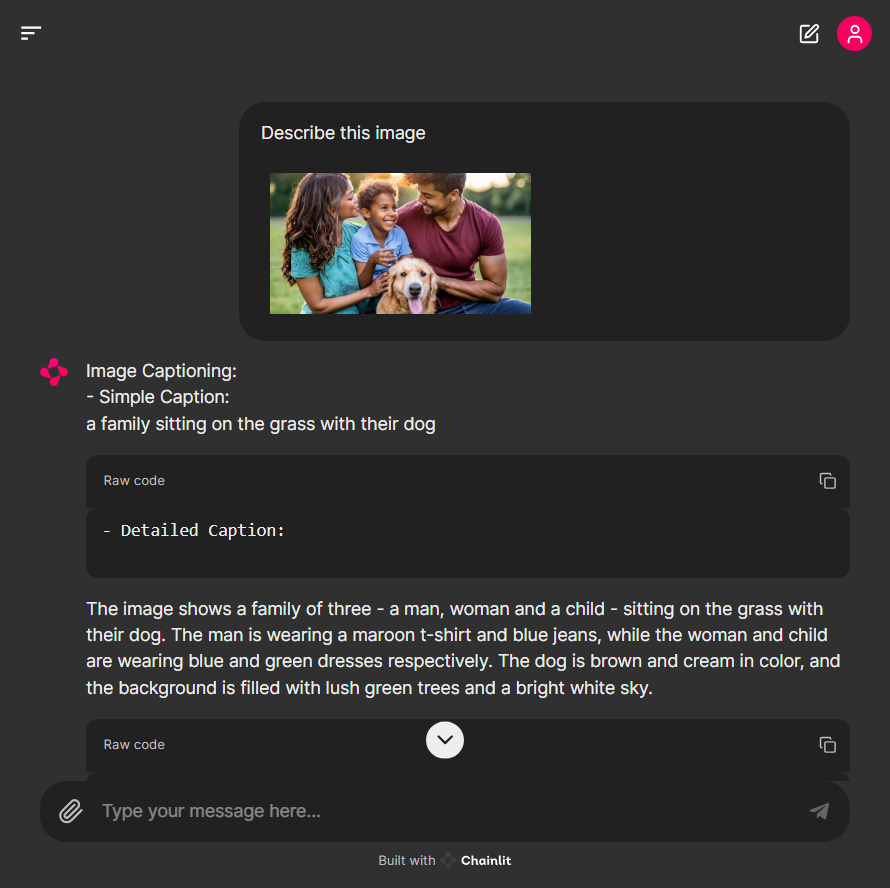
DEMO 앱을 실행하면 http://localhost:8000/의 주소에서 아래 화면과 같이 웹 인터페이스가 열립니다.
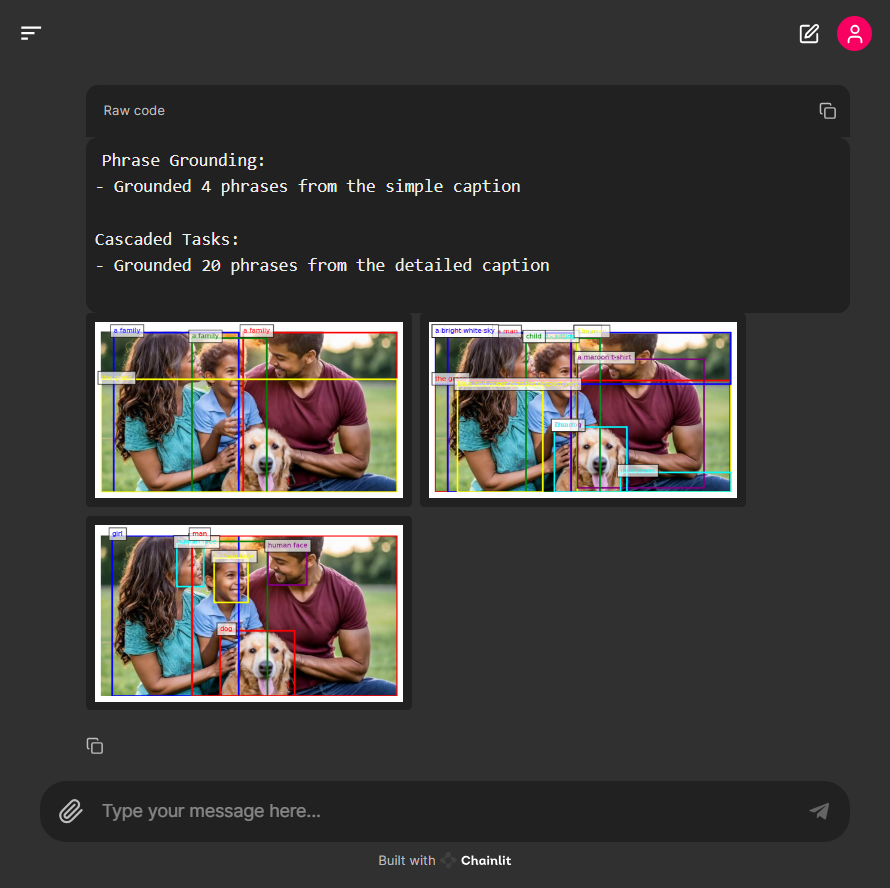
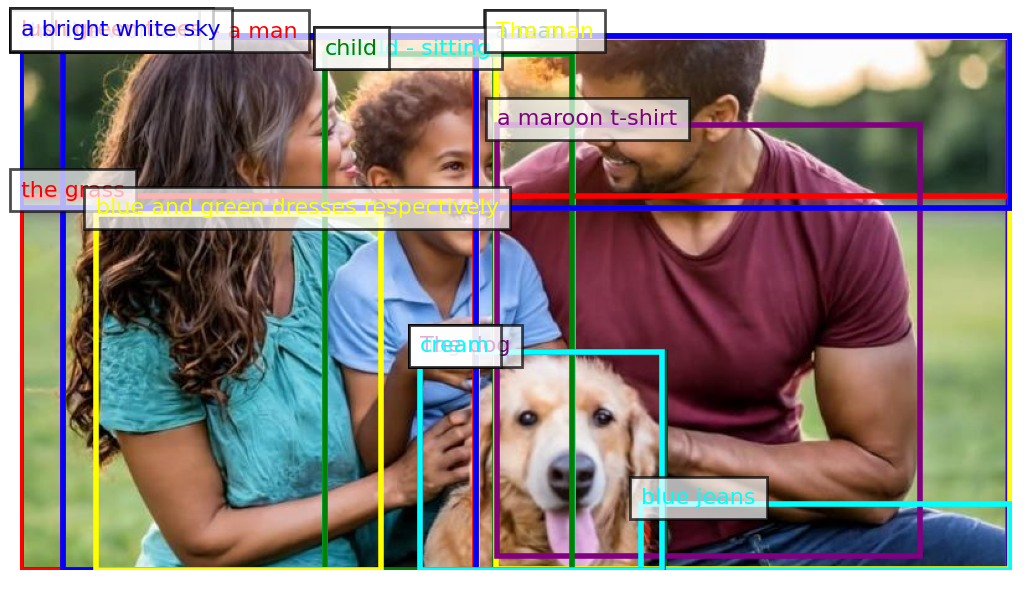
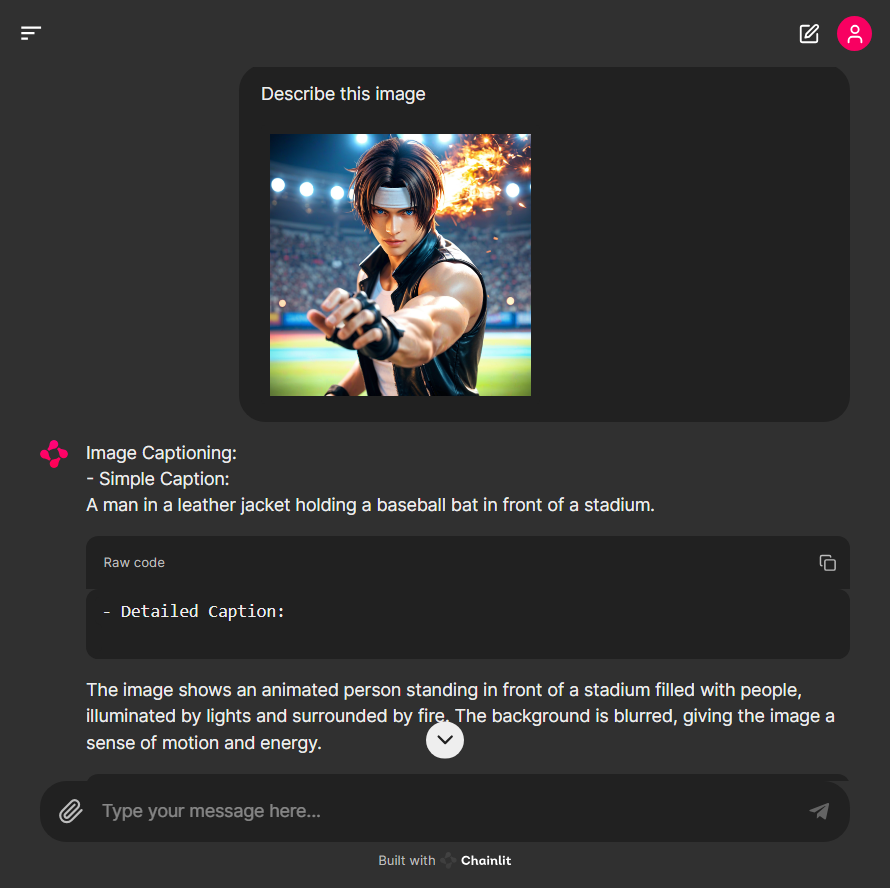
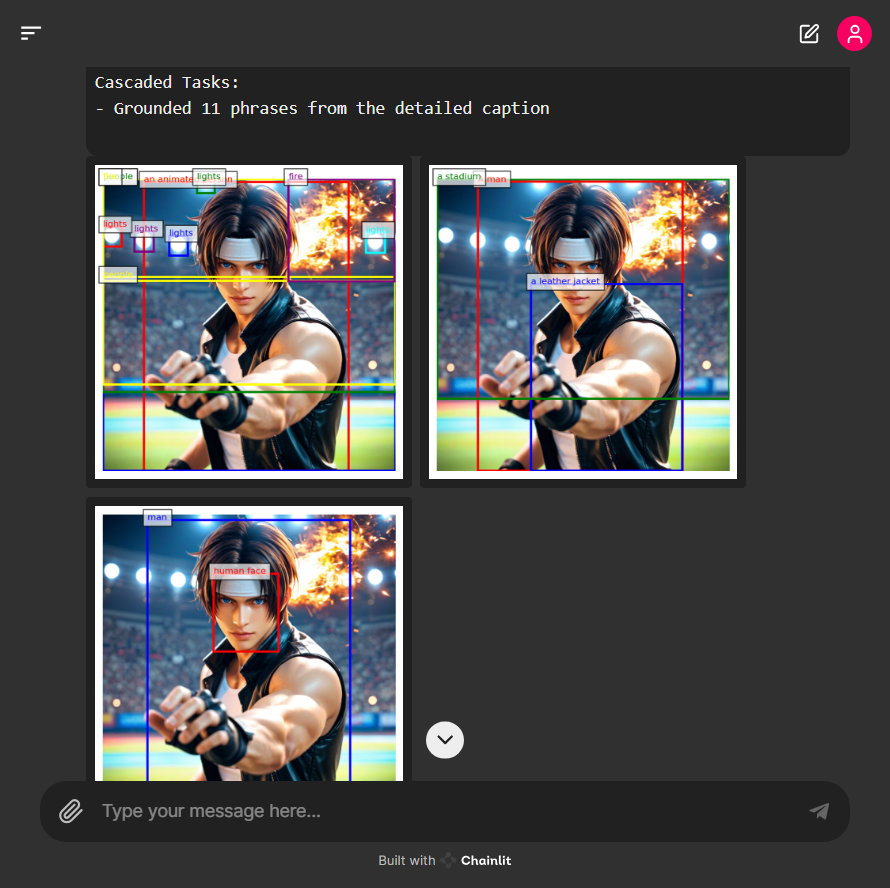
다음 이미지의 간단한 캡션은 "가죽 재킷을 입은 남자가 스태디움에서 야구 배트를 들고 있다"고 설명하였지만, 이미지에서 배트는 찾을 수 없습니다. Florence-2는 자세한 캡션에서는 이미지를 정확하게 설명하였습니다.
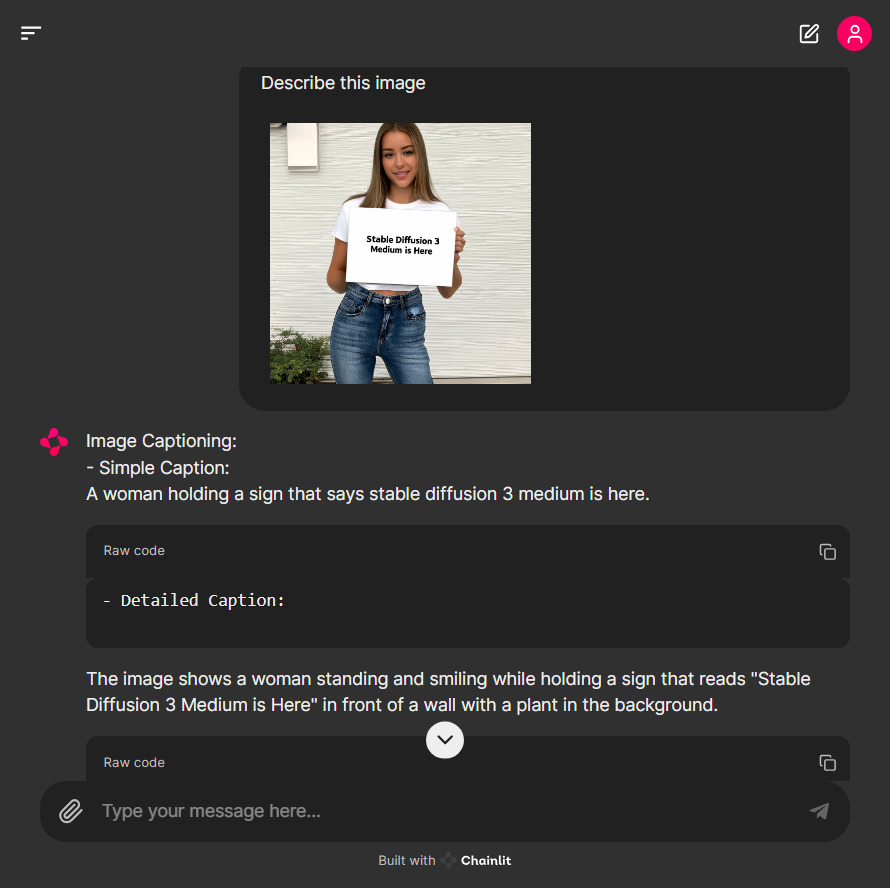
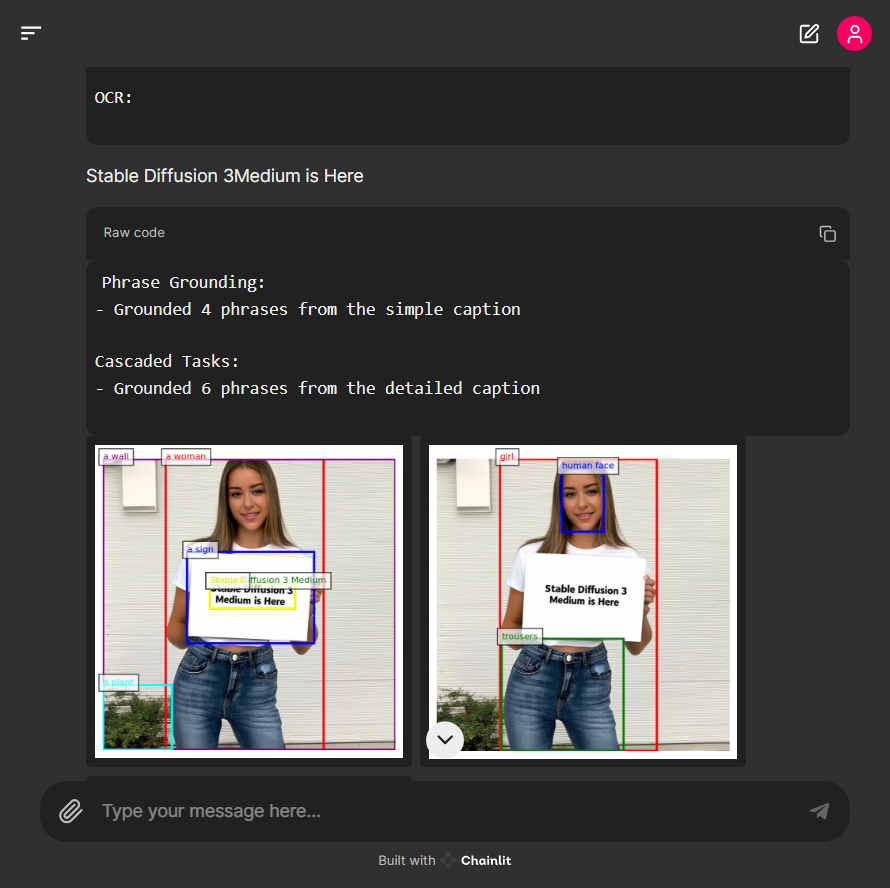
아래 화면에서 Florence-2는 "Stable Diffusion 3 Medium is Here"라는 사인을 들고 있는 여성의 이미지에서 문자를 잘 인식하고 출력하였습니다.
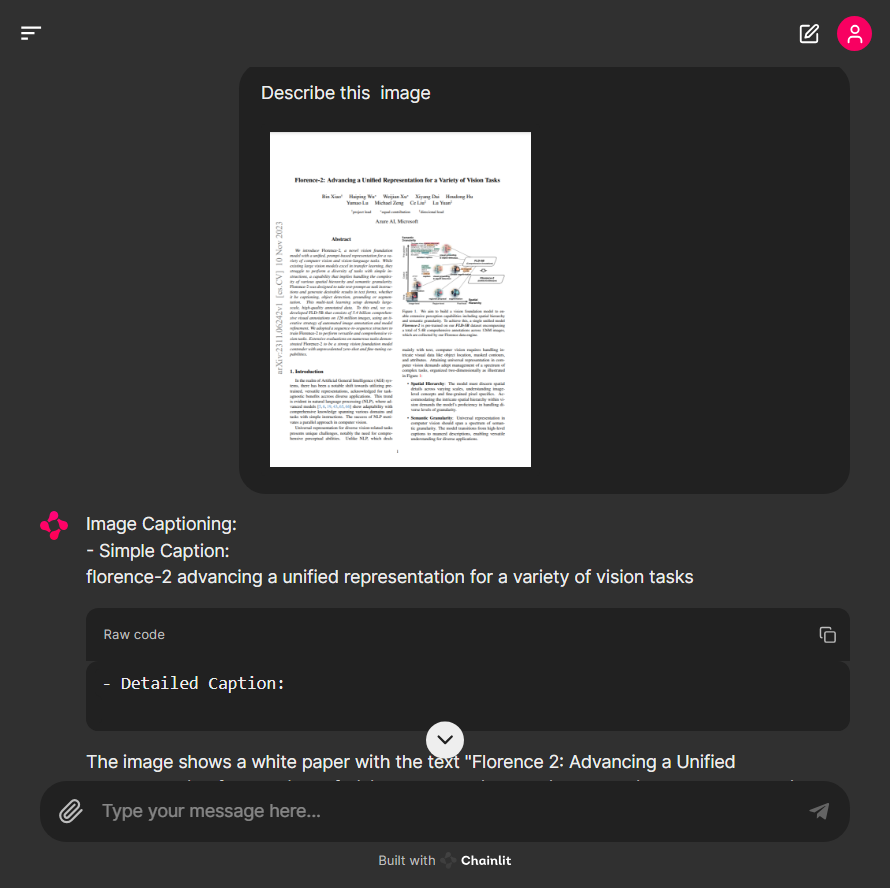
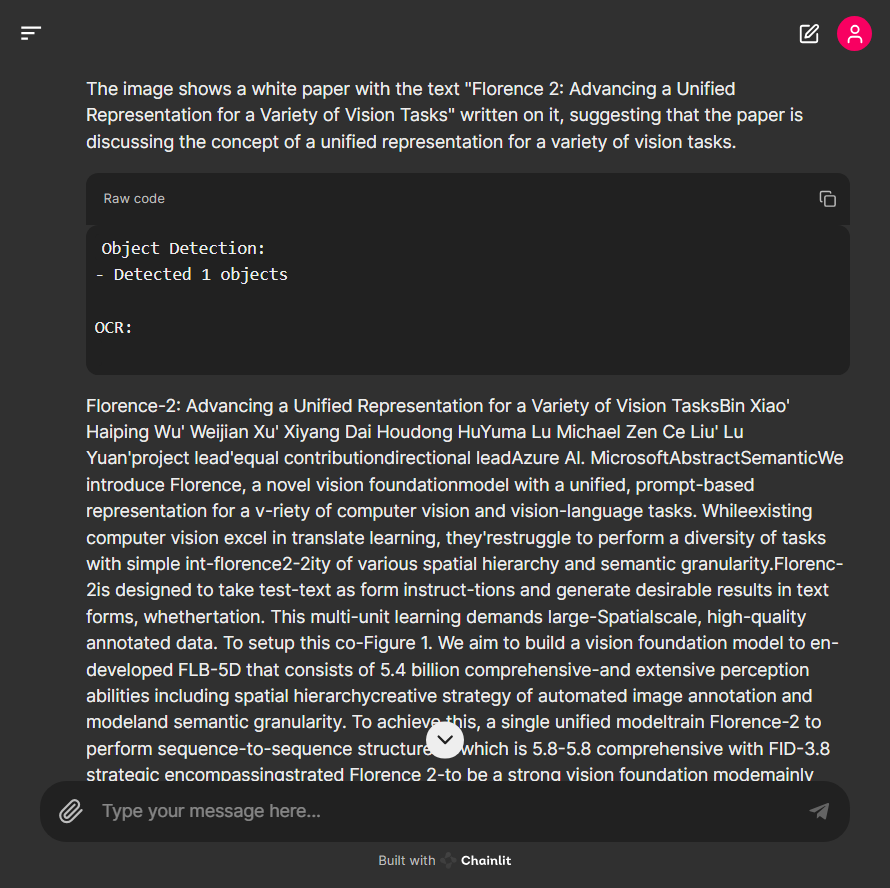
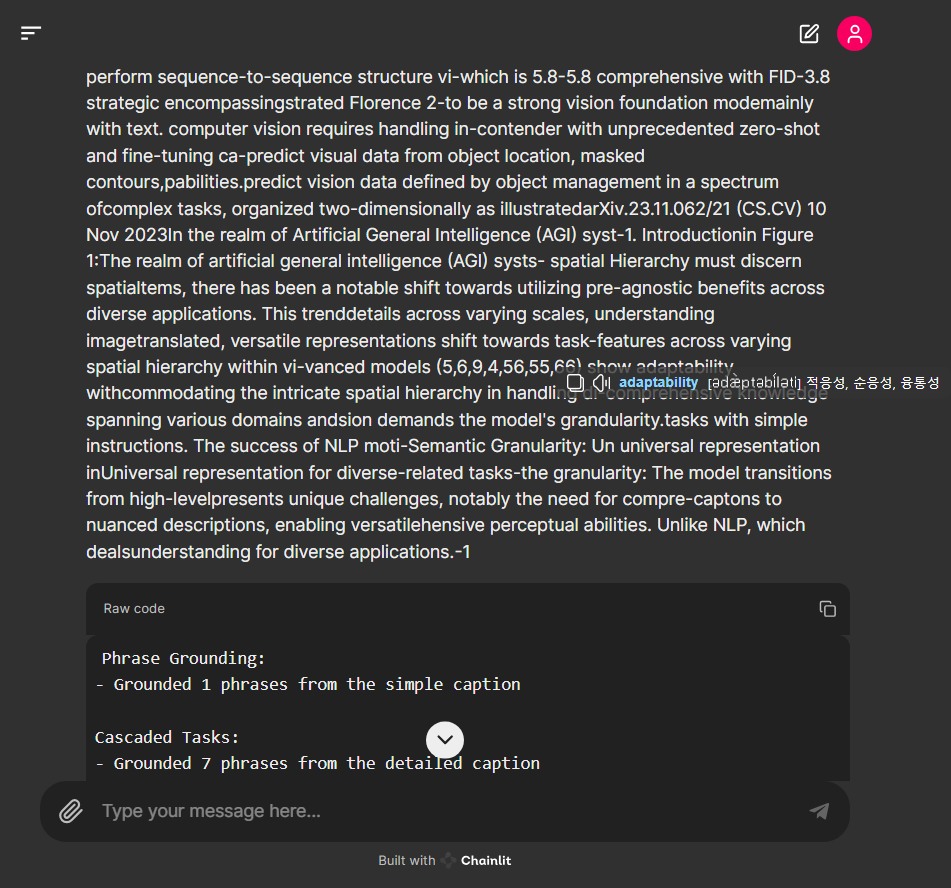
논문을 캡처한 이미지의 경우 문자를 잘 인식하였지만 페이지가 반으로 나뉘어 있는 문단의 특성을 반영하지 못해서 추출된 문장들의 배열이 뒤죽박죽 되는 문제가 발생하였습니다.

맺음말
이상으로 마이크로소프트의 최신 비전 모델인 Florence-2에 대한 개요와 주요 특징, 그리고 다양한 시각 작업에서의 성능을 살펴보았습니다. Florence-2는 통합된 공간적 계층 구조와 의미론적 세분화 처리, 대규모 데이터셋 활용 등을 통해 다양한 비전 작업을 수행할 수 있는 강력한 모델입니다. 특히 제로샷 및 파인튜닝 성능에서 우수한 결과를 보이며, 컴팩트한 크기에도 불구하고 뛰어난 효율성을 자랑합니다.
오늘은 Florence-2 모델의 동작 원리를 상세히 살펴보고, 실제 DEMO 테스트를 통해 이미지 캡셔닝, 객체 검출, OCR, 구절 그라운딩 등 다양한 작업을 수행하는 과정을 시각적으로 확인해 보았는데요. 테스트 후기는 다음과 같습니다.
- 모델이 가벼우면서도 시각작업 결과가 정확하고 빠르다
- 논문과 같은 특수한 텍스트 배치에서 추출된 문장들이 뒤섞인다.
- 간단한 캡션 생성에서는 일부 객체인식의 불일치가 있을수 있다.
이번 블로그가 Florence-2에 대한 이해를 높이고, 실제 적용에 도움이 되었기를 바라면서, 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.06.25 - [AI 언어 모델] - CoLLaVO: 카이스트의 최첨단 시각-언어 모델 분석 및 테스트👀💬🔍
CoLLaVO: 카이스트의 최첨단 시각-언어 모델 분석 및 테스트👀💬🔍
안녕하세요! 오늘은 최근 카이스트에서 개발한 국산 시각-언어 모델 CoLLaVO에 대해 알아보겠습니다. CoLLaVO 모델은 입력 이미지를 분석하여 객체의 의미 정보와 위치 정보를 추출하는 역할을 하는
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 미스트랄 Codestral Mamba:🐍Mamba 아키텍처로 무장한 코드 생성 AI (2) | 2024.07.18 |
|---|---|
| ✨구글 Gemma 2 분석: 최신 오픈소스 모델로 무료 챗봇 만들기 🤖🔓 (2) | 2024.06.29 |
| CoLLaVO: 카이스트의 최첨단 시각-언어 모델 분석 및 테스트👀💬🔍 (0) | 2024.06.25 |
| Claude 3.5 Sonnet: GPT-4o를 뛰어넘은 성능 및 새로운 인터페이스 Artifacts 리뷰 (1) | 2024.06.22 |
| DeepSeek-Coder-V2: 현존 최강 AI 코딩 언어 모델 분석 및 테스트 (0) | 2024.06.20 |



