안녕하세요! 오늘은 알리바바가 공개한 대형 언어 모델인 Qwen-2에 대해 알아보겠습니다. Qwen-2는 Qwen2-0.5B에서 1.5B, 7B, 57B, 72B까지 다섯 가지 크기의 사전 학습 및 명령어 조정 모델을 제공하며, 영어와 중국어를 포함해 27개의 추가 언어로 학습되었습니다. Qwen-2는 다양한 벤치마크에서 뛰어난 성능을 보였으며, 코딩과 수학에서 특히 큰 향상을 보여줍니다. 특히 Qwen2-7B-Instruct와 Qwen2-72B-Instruct는 최대 128K 토큰의 확장된 문맥 길이를 지원하여 긴 텍스트 처리에 강점을 보입니다. 이번 블로그에서는 Qwen-2의 주요 기능과 특징, 벤치마크 결과, 파이썬 및 자바스크립트 코딩 성능을 중점적으로 살펴보겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Qwen-2 개요
Qwen-2는 최신 대형 언어 모델 시리즈로, 고성능과 확장성을 자랑합니다. Transformer 아키텍처를 기반으로 다양한 크기의 모델을 제공하며, 다국어 처리와 코드 이해 능력을 갖추고, 특히 영어와 중국어에 강점을 보입니다. Qwen-2의 각 모델은 다음과 같은 특징을 가지고 있습니다.
| 모델 | 매개변수 수 (억) | 비임베딩 매개변수 수 (억) | GQA | 타이 임베딩 | 문맥 길이 |
| Qwen2-0.5B | 0.49 | 0.35 | TRUE | TRUE | 32K |
| Qwen2-1.5B | 1.54 | 1.31 | TRUE | TRUE | 32K |
| Qwen2-7B | 7.07 | 5.98 | TRUE | FALSE | 128K |
| Qwen2-57B-A14B | 57.41 | 56.32 | TRUE | FALSE | 64K |
| Qwen2-72B | 72.71 | 70.21 | TRUE | FALSE | 128K |
Qwen-2의 매개변수 수는 0.49억에서 72.71억까지 다양하며, 비임베딩 매개변수는 최대 70.21억 개입니다. 모든 모델은 Grouped Query Attention(GQA)을 지원하여 메모리 사용과 계산 효율성을 높이고, 문맥 길이는 최대 128K 토큰까지 지원하여 긴 텍스트 처리가 가능합니다.
- 매개변수 수 (억): 각 모델의 총 매개변수 수를 나타냅니다.
- 비임베딩 매개변수 수 (억): 임베딩을 제외한 매개변수 수를 나타냅니다.
- GQA: Grouped Query Attention의 지원 여부를 나타냅니다. GQA에 대한 내용은 아래 더 보기를 클릭하세요
- 타이 임베딩: 입력 및 출력 단어 임베딩의 연결 여부를 나타냅니다. 타이 임베딩을 사용하면 입력과 출력의 단어 임베딩을 공유함으로써 메모리 효율성, 단어표현 일관성, 모델 학습 성능을 향상시킬수 있습니다.
- 문맥 길이: 모델이 지원하는 최대 문맥 길이 (토큰 수)를 나타냅니다.
https://qwenlm.github.io/blog/qwen2/
Hello Qwen2
GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD Introduction After months of efforts, we are pleased to announce the evolution from Qwen1.5 to Qwen2. This time, we bring to you: Pretrained and instruction-tuned models of 5 sizes, including Qwen2-0.5B, Qwen2-1.
qwenlm.github.io
Qwen-2 벤치마크 결과
Qwen-2 시리즈는 다양한 벤치마크에서 높은 성능을 기록했습니다. Qwen-72B는 GPT-3.5와 LLaMA2-70B를 능가하며, 특히 수학 문제 해결, 코딩, 자연어 이해 등에서 뛰어난 성과를 보입니다. 대부분의 모델이 최대 32,000 토큰의 문맥 길이를 지원하며, 트릴리언 단위의 학습 데이터를 활용해 다국어로 학습되었습니다
Qwen-2는 영어와 중국어 외에도 다양한 언어적 스펙트럼을 포함한 학습 데이터의 양과 질을 증대하여 다국어 역량을 강화하는 데 많은 노력을 기울였습니다. 대형 언어 모델은 다른 언어로 일반화할 수 있는 능력을 기본적으로 갖추고 있지만, 이번에는 27개의 추가 언어를 명시적으로 포함해 학습했습니다.
| 지역 | 언 어 |
| 서유럽 | 독일어, 프랑스어, 스페인어, 포르투갈어, 이탈리아어, 네덜란드어 |
| 동유럽 및 중부 유럽 | 러시아어, 체코어, 폴란드어 |
| 중동 | 아랍어, 페르시아어, 히브리어, 터키어 |
| 동아시아 | 일본어, 한국어 |
| 동남아시아 | 베트남어, 태국어, 인도네시아어, 말레이어, 라오어, 버마어, 세부아노어, 크메르어, 타갈로그어 |
| 남아시아 | 힌디어, 벵골어, 우르두어 |
다음 표는 대형 언어 모델 Qwen2-72B가 Llama3-70B, Mixtral-8x22B, Qwen1.5-110B와 다양한 벤치마크 테스트에서 비교된 성능을 나타냅니다. Qwen2-72B는 대부분의 지표에서 다른 모델을 능가하거나 동등한 성능을 보입니다. 특히 MMLU(대규모 다중작업 이해 능력), GSM8K(기초 수학 문제 해결능력), HumanEval(코드 생성능력), C-Eval(중국어 이해 처리능력) 등에서 우수한 결과를 기록하며, 코드 작성 및 수학 능력에서도 높은 점수를 받았습니다. Qwen2-72B는 Qwen1.5-110B보다 매개변수가 적음에도 불구하고, 다양한 언어와 작업에서 탁월한 성능을 발휘합니다.
다음 표는 Qwen2-7B Instruct와 Llama3-8B Instruct, GLM4-9B Chat의 성능을 여러 지표에서 비교합니다. Qwen2-7B는 AlignBench (7.21), MT-Bench (8.41), MMLU (70.5), GSM8K (82.3), HumanEval (79.9), C-Eval (77.2) 등에서 최고 점수를 기록하며 전반적으로 우수한 성능을 보입니다. 특히, 코드 생성(HumanEval)과 수학 문제 해결(GSM8K)에서 탁월한 성과를 보여주며, 다중 과제 및 중국어 처리에서도 다른 모델들을 능가합니다.
Qwen-2 주요 특징
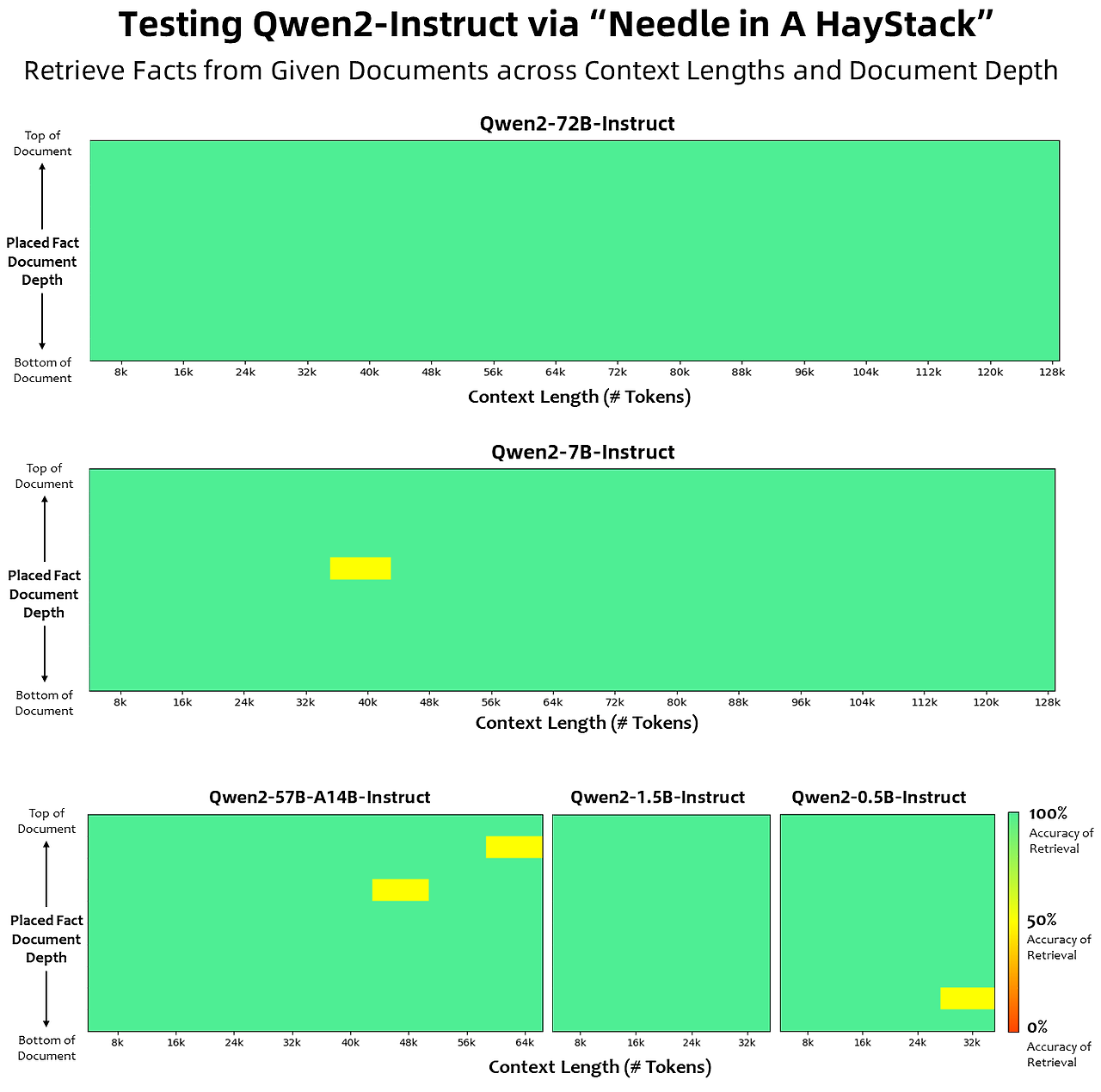
Qwen2는 코딩과 수학에서 뛰어난 성능을 보여줍니다. CodeQwen1.5 데이터를 통합해 다양한 프로그래밍 언어에서 성능을 향상시켰으며, 고품질 수학 데이터셋으로 수학 문제 해결 능력을 강화했습니다. 긴 문맥 이해에서는 YARN과 Dual Chunk Attention 기법으로 128K 토큰까지 문맥을 처리하며, Needle in a Haystack 테스트에서 Qwen2-72B-Instruct가 최상위 성능을 기록했습니다.
코딩 및 수학능력
Qwen2-72B-Instruct는 코딩과 수학 능력에서 뛰어난 성능을 발휘합니다. 코딩에서는 CodeQwen1.5의 코드 학습 경험과 데이터를 통합해 다양한 프로그래밍 언어에서 성능이 크게 향상되었습니다. 수학에서는 광범위하고 고품질의 데이터셋을 활용해 수학 문제 해결 능력이 강화되었습니다.
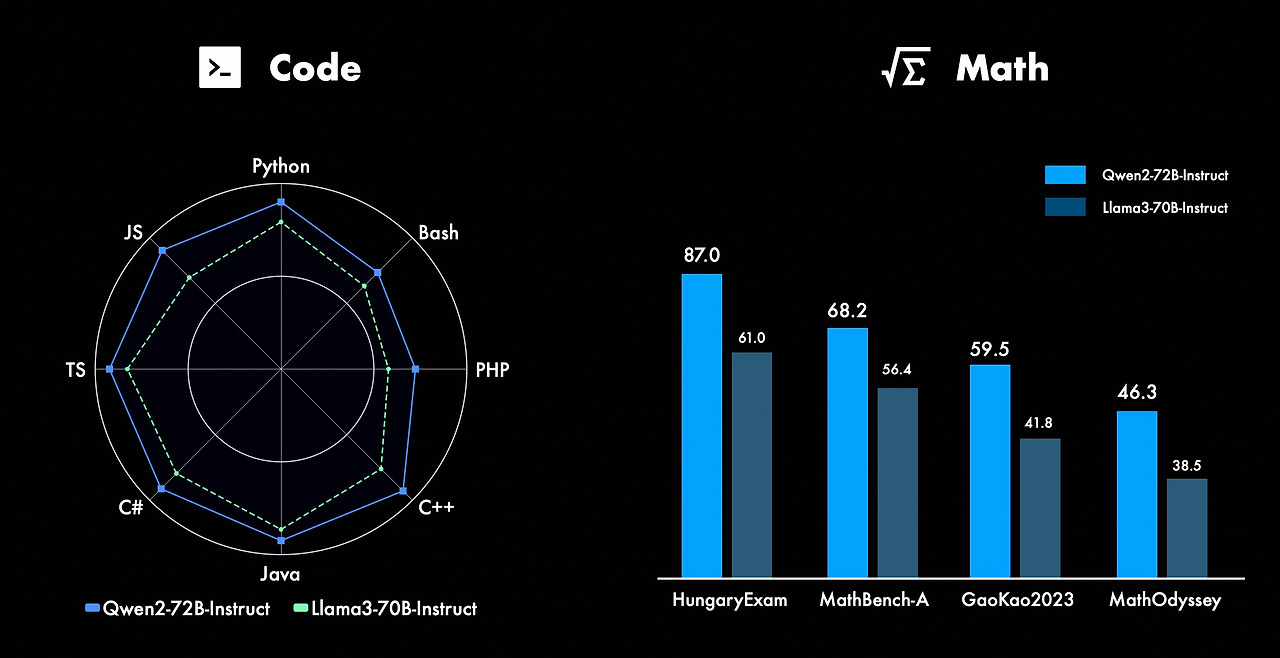
위 그래프는 Qwen2-72B Instruct와 Llama3-70B Instruct의 코딩 및 수학 성능을 비교합니다. 왼쪽의 방사형 그래프는 Python, JavaScript, TypeScript, C#, Java, C++, PHP, Bash 등의 프로그래밍 언어에서 Qwen2-72B Instruct가 전반적으로 더 우수한 성능을 보여주고 있음을 나타냅니다. 오른쪽의 막대그래프는 헝가리 수학 시험(HungaryExam), MathBench-A, GaoKao2023, MathOdyssey 등의 수학 벤치마크에서 Qwen2-72B Instruct가 Llama3-70B Instruct보다 높은 점수를 기록하고 있음을 보여줍니다. 전반적으로 Qwen2-72B Instruct는 다양한 프로그래밍 언어와 수학적 문제 해결에서 뛰어난 성과를 보입니다.
긴 문맥 이해
Qwen2의 모든 명령어 조정 모델은 32K 토큰의 문맥 길이로 학습되었으며, YARN 및 Dual Chunk Attention 같은 기법을 사용해 더 긴 문맥 길이로 확장됩니다. Qwen2-72B-Instruct는 최대 128K 토큰에서 정보를 완벽하게 추출하며, Qwen2-7B-Instruct는 128K까지, Qwen2-57B-A14B-Instruct는 64K까지, Qwen2-1.5B-Instruct와 Qwen2-0.5B-Instruct는 32K까지 지원합니다. 또한, 최대 100만 토큰의 문서를 처리할 수 있는 에이전트 솔루션도 제공됩니다.
안전성과 책임
Qwen2-72B-Instruct는 다국어 안전 쿼리(불법 활동, 사기, 음란물, 개인정보 침해)에서 유해 응답의 비율을 낮추는 성능을 보입니다. GPT-4, Mistral-8x22B, Qwen2-72B-Instruct 모델들의 다국어 안전 쿼리(불법 활동, 사기, 음란물, 개인정보 침해)에 대한 유해 응답 비율을 비교한 결과, Qwen2-72B-Instruct는 대부분의 언어에서 0-4%의 낮은 유해 응답 비율을 보여, GPT-4와 유사하거나 더 나은 성능을 보입니다. 반면, Mistral-8x22B는 평균적으로 8-39%로 더 높은 유해 응답 비율을 기록합니다. Qwen2-72B-Instruct는 다국어 안전성에서 경쟁 모델들을 크게 앞서며, 다양한 언어에서 유해 응답을 효과적으로 억제합니다.
코딩 테스트
다음은 Qwen2-7B 모델의 코딩 테스트를 해보았습니다. 코딩 테스트는 스네이크 게임 만들기와 파이썬, 자바스크립트 시험문제 풀기입니다. 먼저 스네이크 게임을 파이썬으로 작성하는 테스트에서 Qwen2-7B가 작성한 코드를 실행한 결과 아래 화면과 같이 빈 화면만 나왔으며, 몇 차례 피드백과 수정에도 게임은 에러가 발생하며 실행되지 않았습니다.

다음 코딩 테스트는 edabit.com 코딩 교육 사이트의 파이썬과 자바 스크립트 코딩 시험문제로 테스트하였습니다. 테스트 환경은 Windows 11 Pro(23H2), 파이썬 3.11, Ollama에서 Qwen2-7B의 양자화 버전을 다운로드하여 웹 브라우저 Page Assist에서 진행하였습니다.
파이썬 코딩 테스트 결과, Qwen2-7B는 아쉽게도 Easy 단계를 제외하고 모든 문제를 첫 번째 시도에 맞히지 못했습니다.

| Python/Pass@1 | Easy | Medium | Hard | Very Hard | Expert |
| Qwen2-7B | Pass | Fail | Fail | Fail | Fail |
| Llama3 8B | Fail | Pass | Fail | Pass | Fail |
하지만 자바스크립트 코딩 테스트 결과 모든 단계의 문제를 첫 시도에서 성공하였습니다.
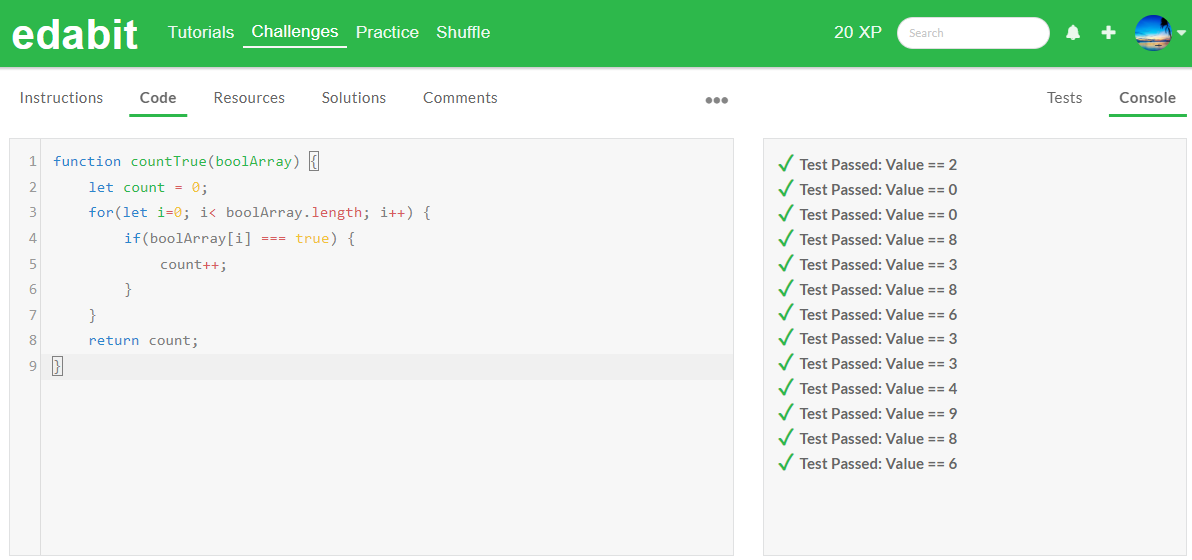
| JavaScript/Pass@1 | Medium | Hard | Very Hard | Expert |
| Qwen2-7B | Pass | Pass | Pass | Pass |
| Llama3 8B | Pass | Fail | Fail | Fail |

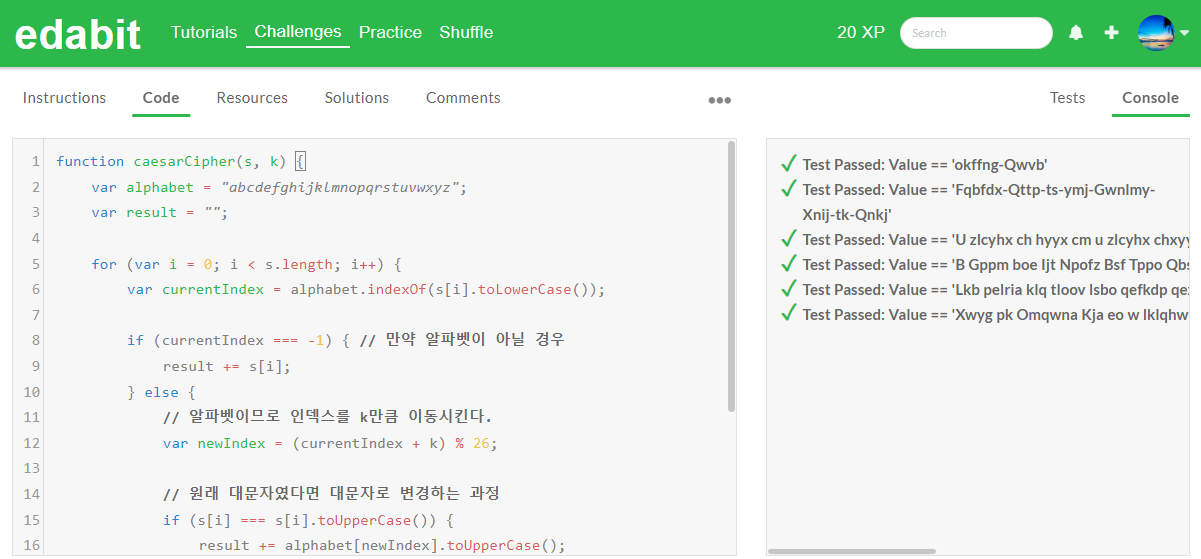
코딩 테스트 결과 Qwen2-7B의 파이썬 코딩 성능은 만족할 만한 수준은 아니었지만, 자바스크립트 코딩 성능은 놀라웠으며, Llama3 8B 보다 확실히 우수한 성능을 보여주었습니다.
맺음말
이번 블로그에서는 알리바바의 최신 대형 언어 모델인 Qwen-2에 대해 자세히 살펴보았습니다. Qwen-2는 코딩과 수학에서 뛰어난 성능을 발휘하며, 특히 Qwen2-7B Instruct와 Qwen2-72B Instruct 모델은 긴 문맥 처리와 다국어 지원에서 탁월한 역량을 보여줍니다. 또한, Qwen-2는 다국어 처리와 안전성 측면에서도 뛰어난 결과를 나타내어, GPT-4와 유사하거나 더 나은 안전성 성능을 보였습니다.
코딩 테스트 결과에서는 Qwen2-7B가 자바스크립트에서 뛰어난 성능을 보인 반면, 파이썬에서는 개선이 필요함을 알 수 있었습니다. 이러한 분석을 통해 Qwen-2가 다양한 응용 분야에서 사용될 수 있는 강력한 도구임을 확인할 수 있었습니다. 알리바바의 Qwen-2는 최신 기술과 풍부한 데이터셋을 활용하여 여러 분야에서 혁신적인 가능성을 열어가고 있으며, 앞으로 더 많은 발전이 기대됩니다. 여러분도 Qwen-2를 통해 다양한 가능성을 탐구해 보시길 바랍니다. 더 자세한 정보와 Qwen-2에 대한 최신 업데이트는 공식 블로그를 방문해 보세요.
오늘 블로그는 여기까지입니다. 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.06.01 - [AI 언어 모델] - [AI 논문] Aya 23 모델: 🌐23개 언어 지원 다국어 LLM 성능 분석
[AI 논문] Aya 23 모델: 🌐23개 언어 지원 다국어 LLM 성능 분석
안녕하세요! 오늘은 Command R+ 언어모델로 유명한 Cohere의 최신 다국어 지원 언어모델 Aya 23에 대해서 알아보겠습니다. Aya 23 모델은 23개 언어를 지원하는 다국어 언어 모델로, 높은 성능의 사전 학
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| DeepSeek-Coder-V2: 현존 최강 AI 코딩 언어 모델 분석 및 테스트 (0) | 2024.06.20 |
|---|---|
| Stable Diffusion 3 Medium: 최신 T2I 모델 설치와 활용법(SwarmUI) (2) | 2024.06.15 |
| [AI 논문] Aya 23 모델: 🌐23개 언어 지원 다국어 LLM 성능 분석 (2) | 2024.06.01 |
| 🌟코딩 혁신: Codestral - 미스트랄이 만든 AI 코드 생성 끝판왕!🚀 (0) | 2024.05.31 |
| GPT-4o: 자연스러운 음성 대화와 뛰어난 코딩 성능을 갖춘 멀티모달 언어 모델 (0) | 2024.05.17 |



