안녕하세요! 오늘은 AutoCoder라는 코드 생성 대형 언어 모델에 대해서 알아보겠습니다. AutoCoder는 AIEV(Agent-Interaction and Execution-Verified, 에이전트 상호작용 및 실행검증)-INSTRUCT 방법론을 통해 에이전트 간 상호작용을 통해 코드를 작성하고, 단위 테스트 수행과 오류 수정의 반복 피드백으로 코드 정확성을 보장하여, 모델의 지시 수행 능력을 향상시키므로써, HumanEval 벤치마크에서 GPT-4 Turbo와 GPT-4o를 능가하는 성능을 보여줍니다. 이 블로그에서는 논문을 통해 AutoCoder의 개요와 특징, 동작원리, 성능평가 결과에 대해서 알아보고 코딩테스트를 해보겠습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문 개요
최근 대형 언어 모델(LLM)이 코드 생성과 이해에서 뛰어난 성능을 보여주고 있지만, 대부분의 기존 모델들은 외부 패키지 설치 작업에 제한이 있으며, 수동으로 대규모 데이터셋에 주석 달기에도 경제적, 시간적 한계가 있습니다. 이 논문은 이러한 문제를 해결하고자, 새로운 방법론인 AIEV-INSTRUCT(Agent-Interaction and Execution-Verified, 에이전트 상호작용 및 실행검증)를 통해 고품질의 대규모 코드 지시 데이터셋을 생성하고, 이를 통해 AutoCoder라는 새로운 코드 대형 언어 모델을 개발하는 것을 목적으로 합니다.
- 논문제목: AutoCoder: Enhancing Code Large Language Model with AIEV-INSTRUCT
- 논문저자: Bin Lei, Yuchen Li, Qiuwu Chen
- 논문게재 사이트: https://arxiv.org/abs/2405.14906
- 논문게재일: 2024년 5월 23일


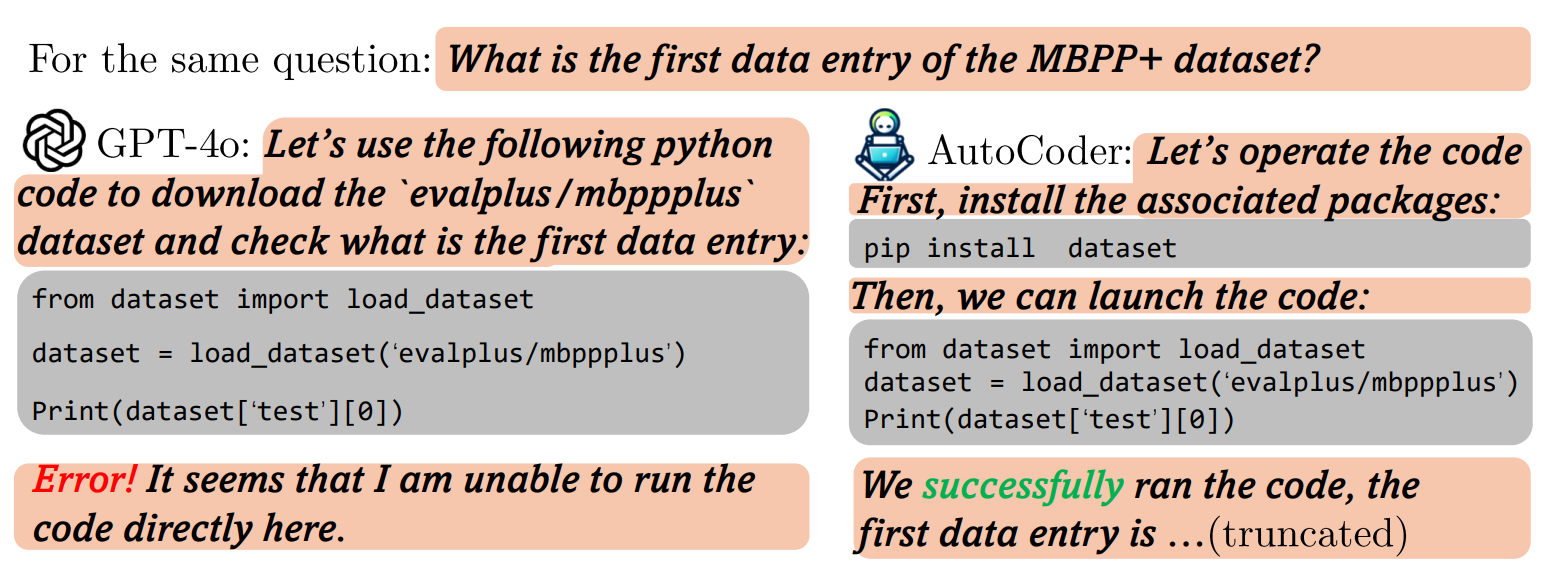 |
|
| GPT-4o : 패키지 설치 제한으로 코드 실행 불가 | AutoCoder : 패키지 설치를 통한 코드 실행 완료 |
논문의 연구내용 및 결과
논문에서 제시한 핵심기술인 AIEV-INSTRUCT는 에이전트 상호작용과 실행 검증을 통해 프로그래머가 코드를 작성하고 단위 테스트를 수행하는 과정을 시뮬레이션하여, 정확한 주석이 있는 고품질의 코드 지시 데이터셋을 자동으로 생성하는 방법론이며, 이 방법론은 두 단계로 나누어집니다.
- 1. 교수 단계(Teaching Stage): 교사 모델(GPT-4 Turbo)을 사용하여 초기 데이터를 생성하고, 이를 통해 학생 모델을 학습시킵니다. 이 데이터셋에는 코드 지시와 단위 테스트가 포함됩니다.
- 2. 자기 학습 단계(Self-Learning Stage): 학생 모델(AutoCoder)이 교사 모델을 능가하면, AutoCoder는 스스로 데이터를 생성하고 학습합니다. 이를 통해 AutoCoder는 더욱 정교해지고, 고품질의 코드를 생성할 수 있는 능력을 향상시킵니다.
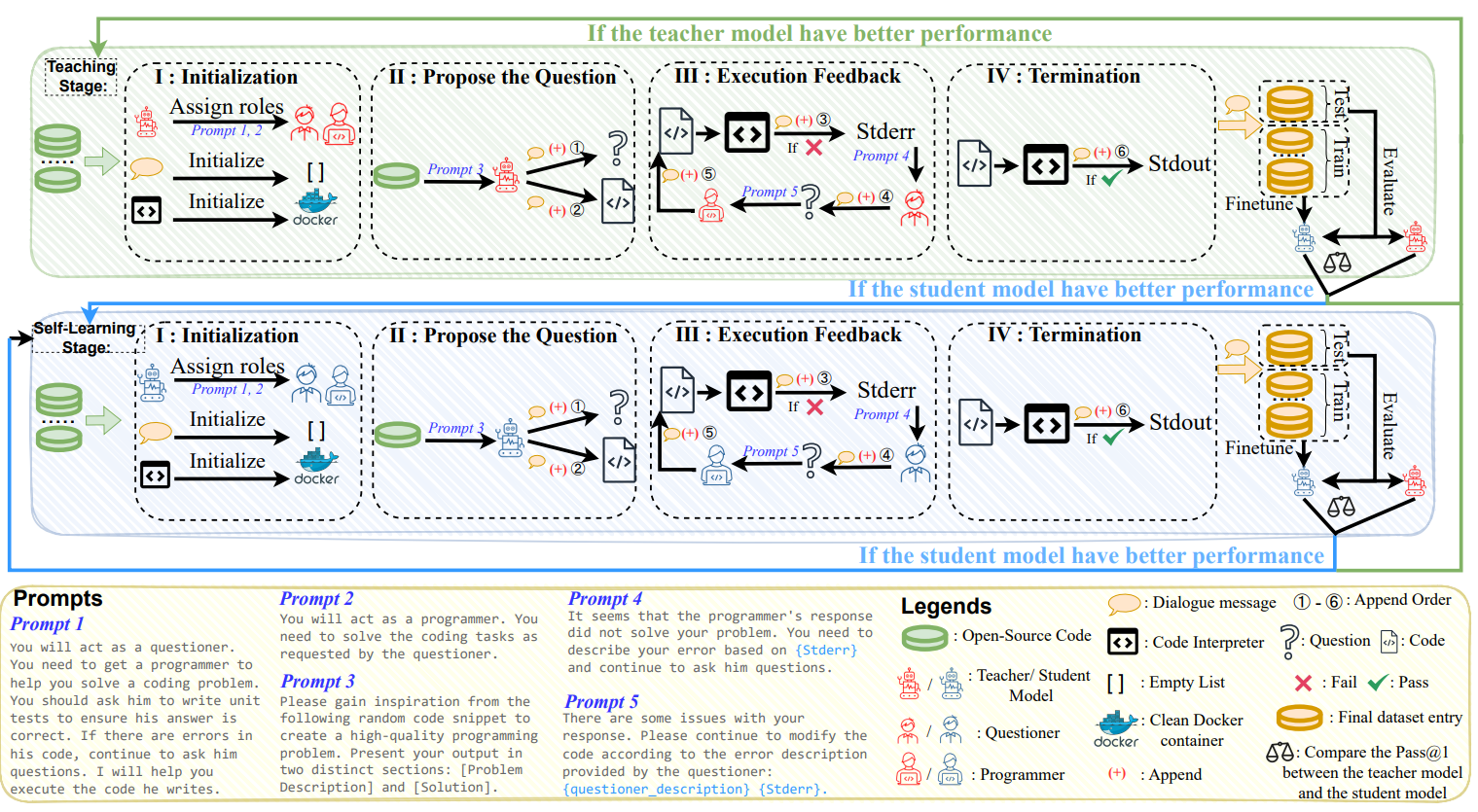
논문에서 제시한 아키텍처의 원리 및 동작순서는 다음과 같습니다:
- 1. 초기화 단계: 에이전트 상호작용을 위한 필요한 컴포넌트를 초기화합니다. 교사 모델은 학생 모델에게 "질문자"와 "프로그래머" 역할을 할당하고, 교사 모델은 학생 모델에게 문제를 설명하고 코드 작성에 필요한 정보를 제공합니다. 학생 모델은 교사 모델에게 코드를 작성하기 위한 필요한 도구 및 라이브러리를 요청할 수 있습니다. Docker 컨테이너를 코드 인터프리터로 초기화합니다.
- 2. 문제 제안 단계: 교사 모델은 학생 모델에게 코드 작성에 필요한 질문을 생성합니다. 질문은 코드 작성에 필요한 정보를 얻기 위해 설계됩니다. 학생 모델은 질문에 대한 답변을 코드 형태로 작성합니다. 단위 테스트를 추가로 제공하여 코드의 정확성을 보장합니다.
- 3. 실행 피드백 단계: 학생 모델은 작성한 코드를 실행합니다. 실행 결과에 따라 학생 모델은 교사 모델에게 실행 결과를 보고합니다. 교사 모델은 학생 모델에게 코드 작성에 대한 피드백을 제공합니다. 피드백은 코드의 오류 수정, 개선 방향, 추가적인 정보 요청 등을 포함합니다.
- 4. 종료 단계: 학생 모델은 교사 모델의 피드백을 반영하여 코드를 수정합니다. 학생 모델이 코드를 성공적으로 작성하면 시스템이 종료됩니다. 시스템은 교사 모델과 학생 모델의 상호작용을 기반으로 학습하고 개선됩니다.
에이전트 상호작용 및 실행검증 방법론은 다음과 같은 장점을 가지고 있습니다:
- 효율성: 교사 모델과 학생 모델의 협력을 통해 코드 작성 과정을 빠르게 진행할 수 있습니다.
- 정확성: 교사 모델의 피드백을 통해 학생 모델의 코드 품질을 향상시킬 수 있습니다.
- 범용성: 다양한 유형의 코드 작성 작업에 적용할 수 있습니다.
성능평가 결과
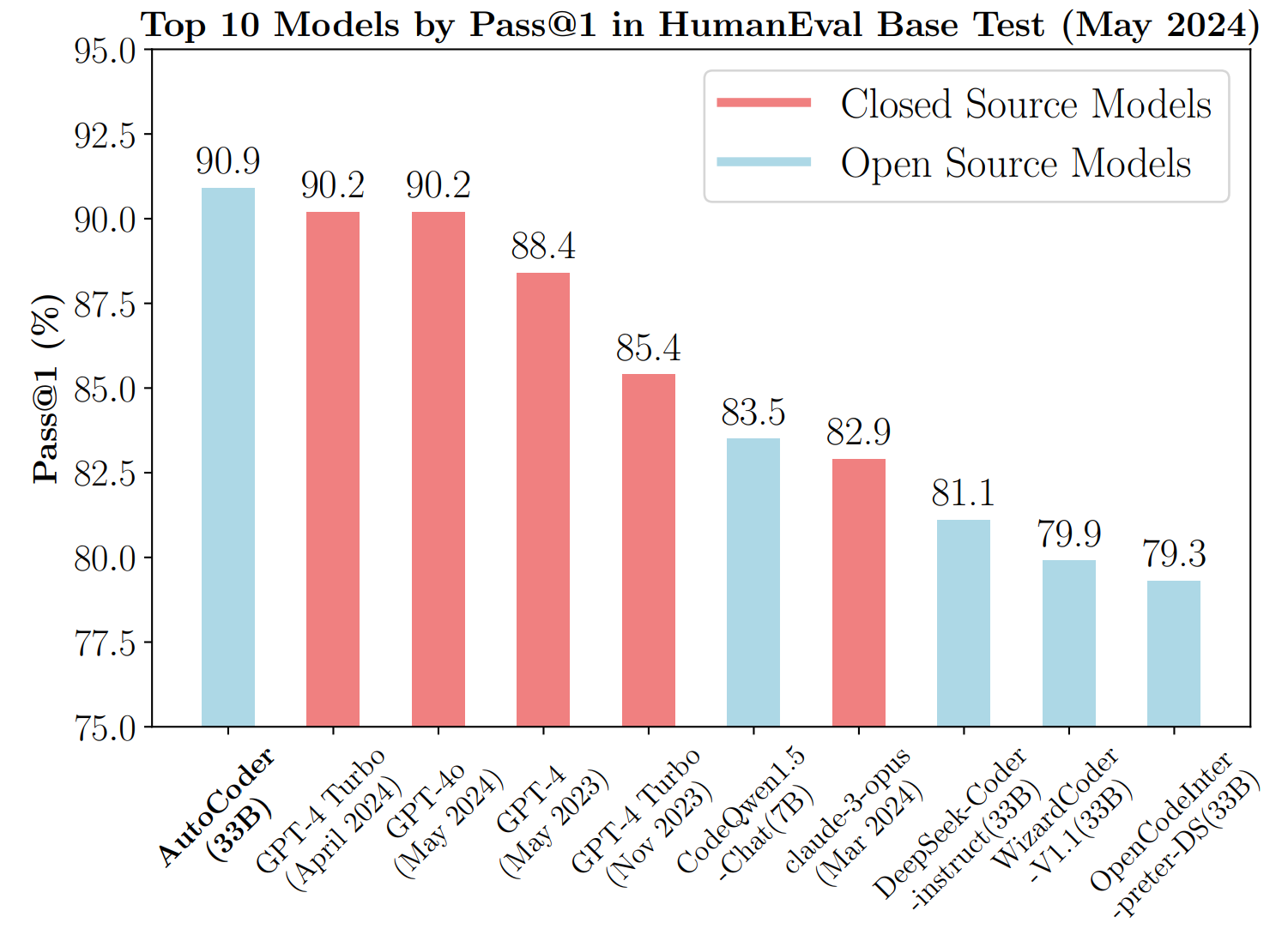
AutoCoder는 HumanEval 벤치마크에서 GPT-4 Turbo 및 GPT-4o를 능가하는 성능을 보였습니다. HumanEval에서 AutoCoder-33B는 90.9%의 Pass@1을 기록하며 모든 모델을 능가하였고, HumanEval+에서는 78%의 Pass@1을 기록하여 GPT-4 Turbo와 CodeQwen1.5-Chat에 이어 높은 성능을 보였습니다. MBPP와 MBPP+ 테스트에서도 각각 82.5%와 70.6%의 Pass@1을 기록하며 우수한 성능을 보였습니다.
Pass@1은 코드 생성 모델의 성능을 평가하는 중요한 지표 중 하나로, 모델이 첫 번째 시도에서 정확한 코드를 생성할 확률을 나타냅니다. MBPP(Multi-lingual Programming Problems Benchmark)와 MBPP+ 테스트는 여러 프로그래밍 언어를 포함하는 프로그래밍 문제의 벤치마크 세트입니다.
HumanEval 벤치마크는 코드 생성 모델의 성능을 평가하기 위한 표준 테스트 세트입니다. 이 벤치마크는 모델이 주어진 자연어 설명을 기반으로 올바른 파이썬 코드를 생성하는 능력을 평가합니다. HumanEval은 다양한 난이도의 164개 코드 문제로 구성되어 있으며, 각 문제는 정확한 솔루션을 요구합니다. 모델의 성능은 첫 번째 시도에서 올바른 코드를 생성하는 비율인 Pass@1로 측정됩니다. HumanEval은 GPT-4와 같은 최신 코드 생성 모델의 능력을 검증하는 데 널리 사용되며, 코드의 정확성과 효율성을 평가하는 중요한 도구입니다.
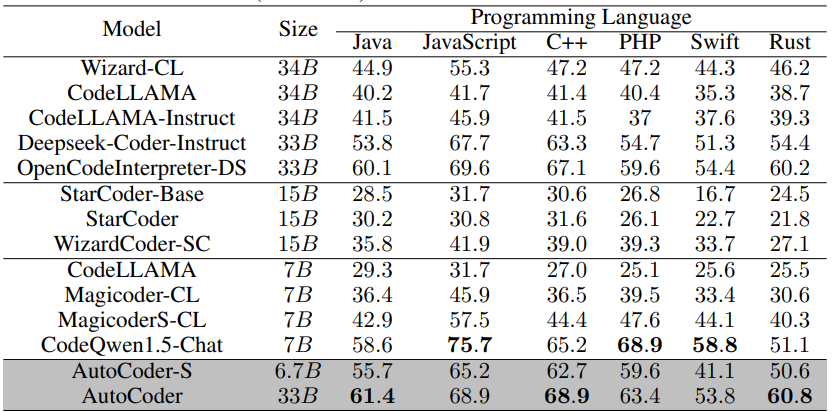
또한, MultiPL-E 벤치마크를 사용하여 AutoCoder의 다국어 코드 생성 능력을 평가한 결과, AutoCoder는 Java, C++, Rust에서 높은 성능을 기록하며, JavaScript, PHP, Swift에서도 우수한 성능을 보였습니다. DS-1000 데이터셋을 사용한 데이터 과학 문제 해결 능력 테스트에서도 AutoCoder는 Matplotlib, NumPy, Pandas, PyTorch, SciPy, Scikit-learn, TensorFlow 등의 라이브러리를 사용하는 문제에서 높은 성능을 보였습니다. 특히 그래프, 히스토그램, 산점도 등 시각화를 위한 라이브러리인 Matplotlib 관련 질문에서 GPT-4 Turbo를 능가하는 성과를 보였으며, 전체적으로 GPT-4를 제외한 모든 모델 중 45% 이상의 Pass@1을 기록한 유일한 모델입니다.
코딩 테스트 후기
다음은 AutoCoder 모델의 코딩 테스트를 해보았습니다. 테스트 환경은 Windows 11 Pro(23H2), 파이썬 3.11, LM Studio 0.2.23에서 AutoCoder 6.7B의 양자화 버전 autocoder_s_6.7b-q6_k.gguf을 다운로드하여 진행하였습니다.
먼저 파이썬으로 스네이크 게임을 만들어 달라는 요청에 대한 첫 번째 결과는 게임화면이 표시되었으나, 뱀이 표시되지 않아 게임을 진행할 수 없었습니다. 두 번째 시도에서는 뱀이 아래에서 위로 자동으로 계속 이동해서 역시 게임을 진행하지 못하였습니다. 양자화 버전의 일부 성능 저하를 감안하더라도 만족할 만한 수준은 아니었습니다.
다음 코딩 테스트는 edabit.com 코딩 교육 사이트의 파이썬과 자바 스크립트 코딩 시험문제로 테스트하였습니다.
먼저, 파이썬 문제에 대한 테스트는 난이도 단계별로 1문제당 2회 시도하였으며, 유사한 매개변수를 가진 Llama3 8B와 결과를 비교하였습니다.
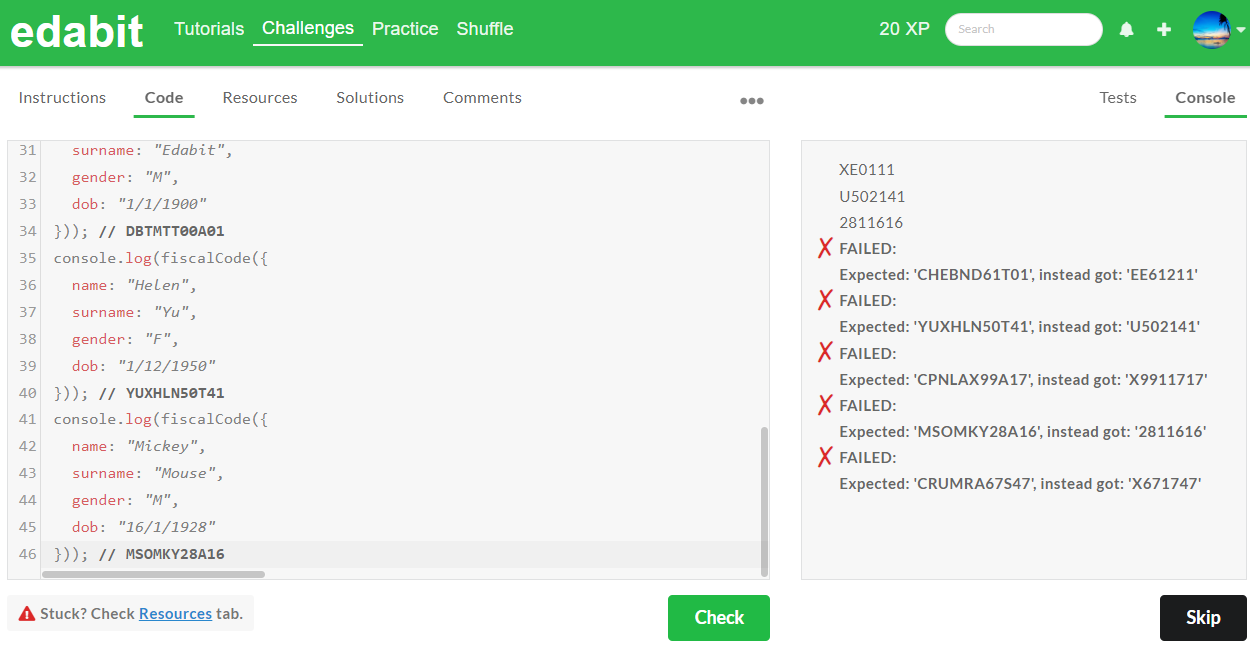
1. Easy단계 : AutoCoder 6.7B 첫 번째 - 실패, 두 번째 - 성공 (Llama3 8B : 첫 번째 - 실패, 두 번째 - 성공)
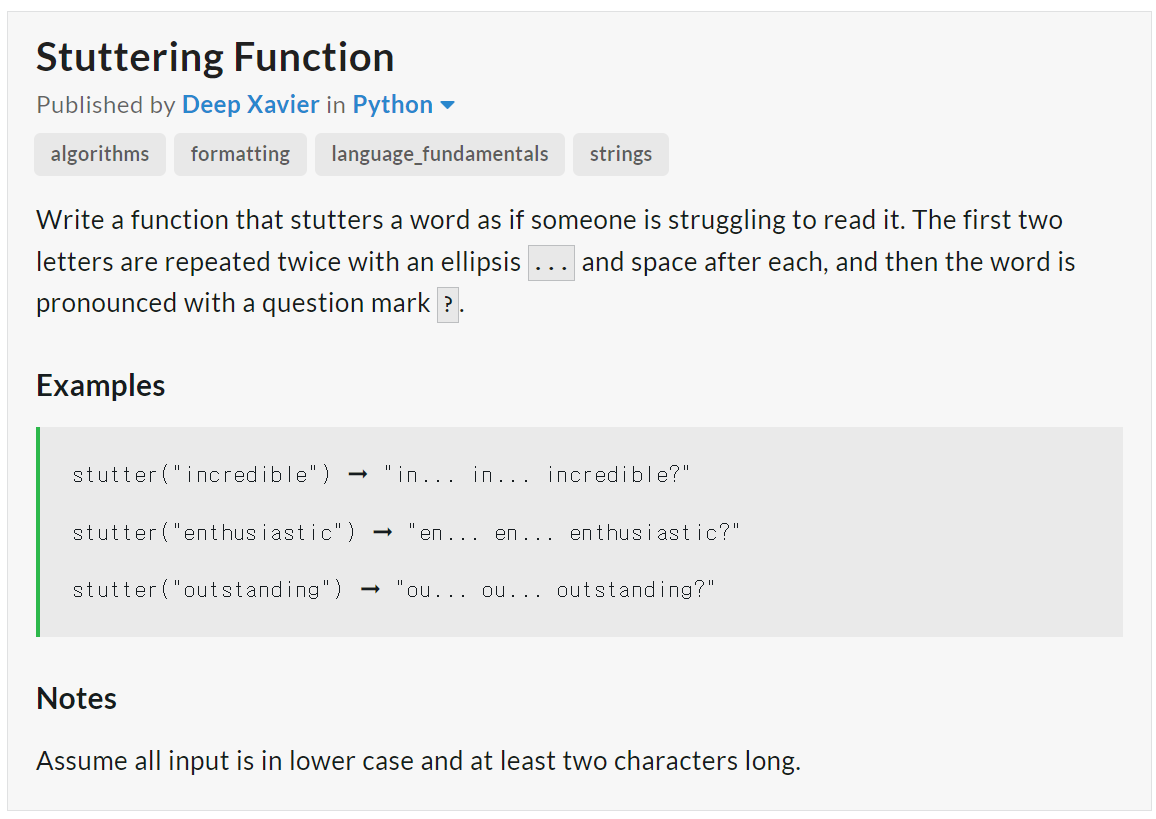
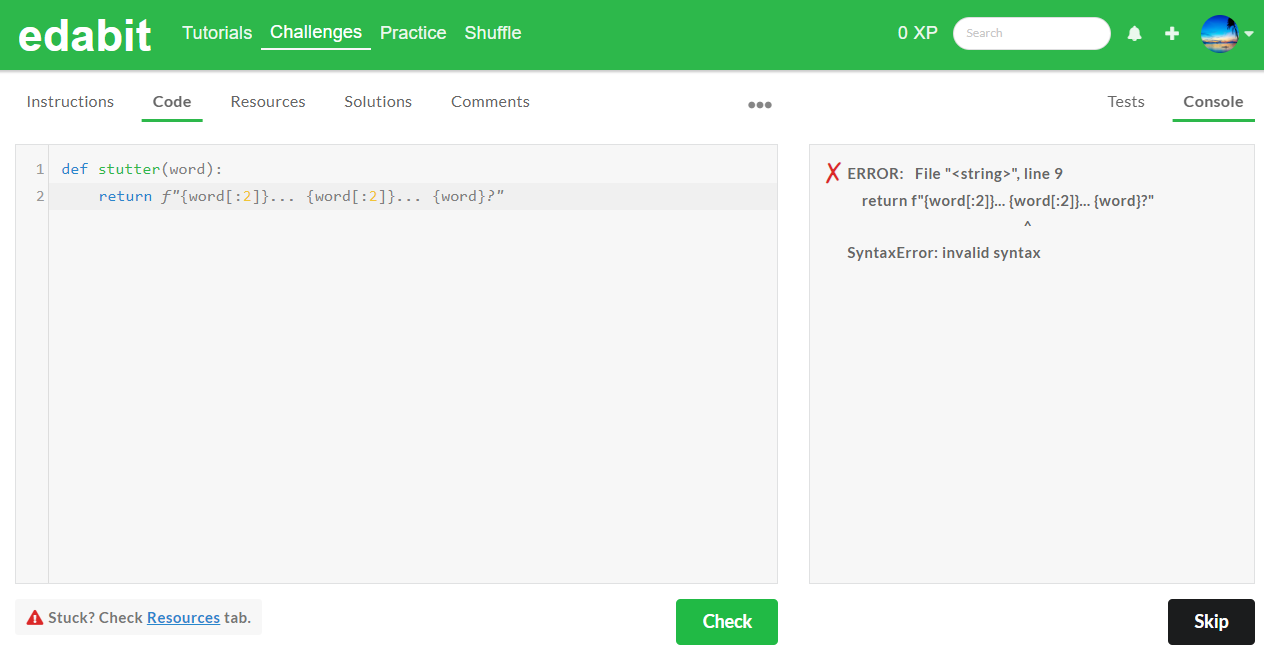
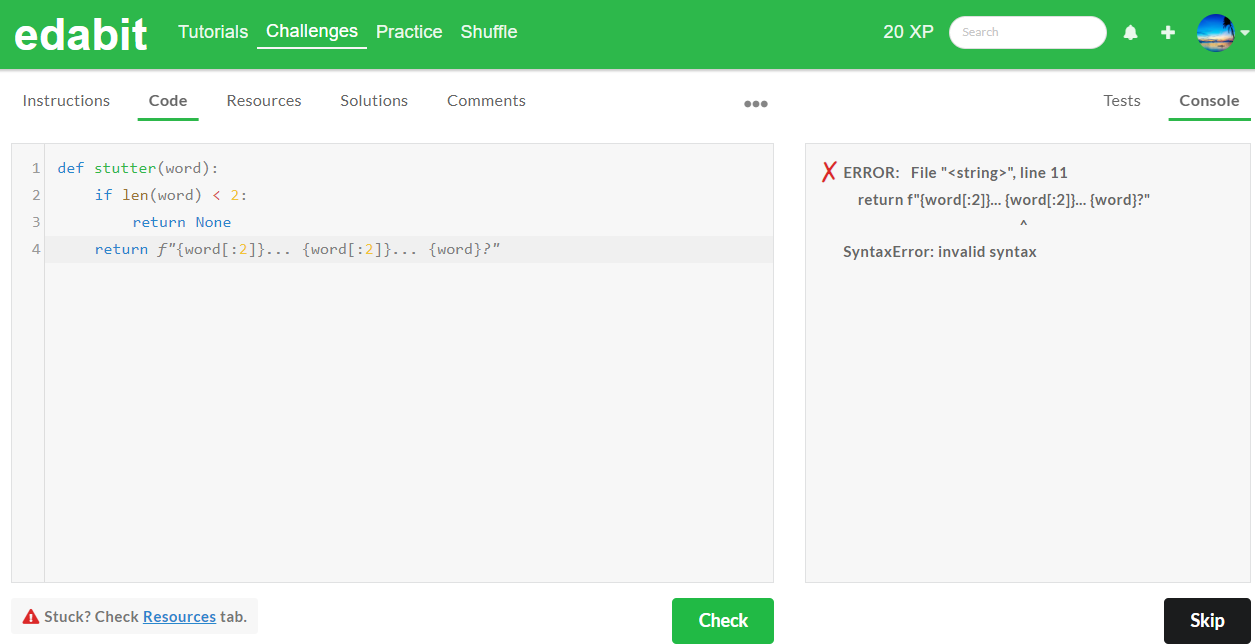
2. Medium 단계 : AutoCoder 6.7B 첫 번째 - 실패, 두 번째 - 실패 (Llama3 8B : 첫 번째 - 성공)


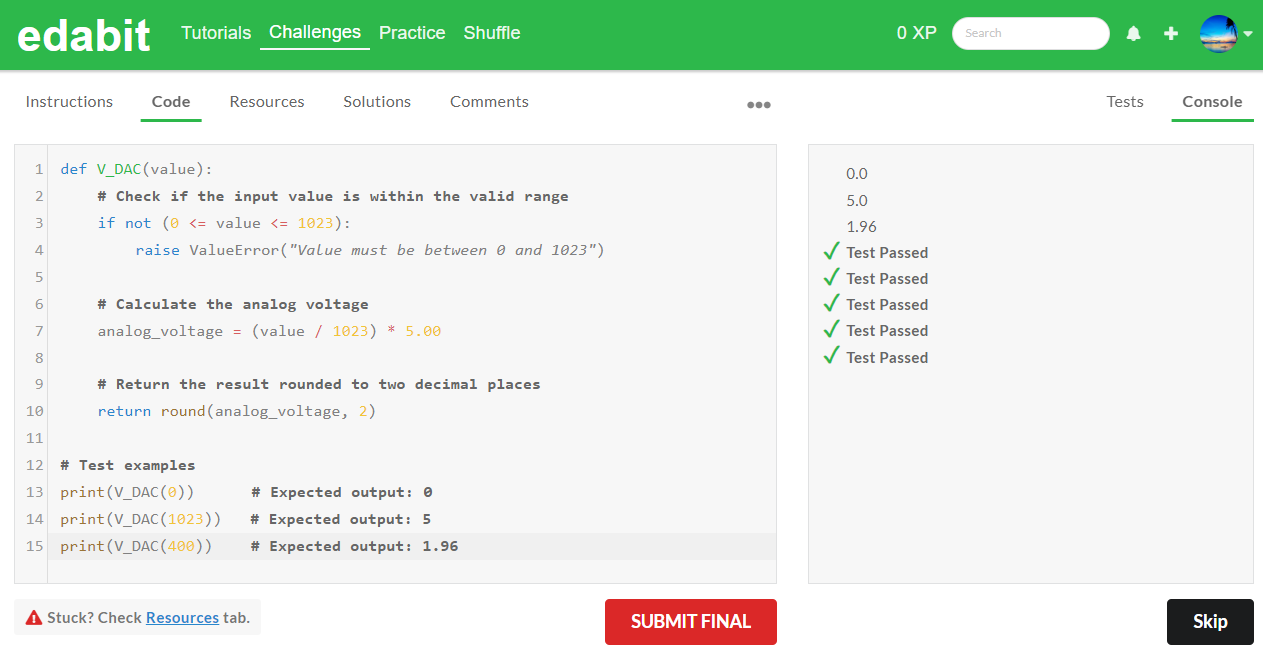
3. Hard 단계 : AutoCoder 6.7B 첫 번째 - 실패, 두 번째 - 실패 (Llama3 8B : 첫 번째 - 실패, 두 번째 - 실패)

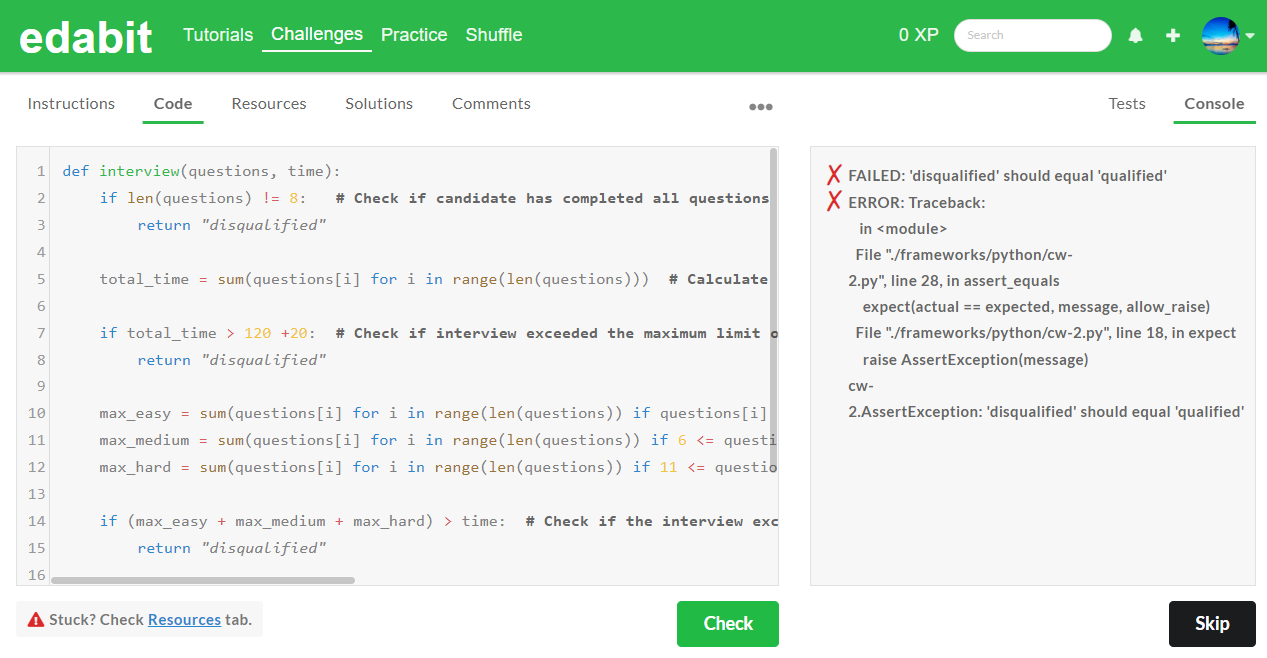
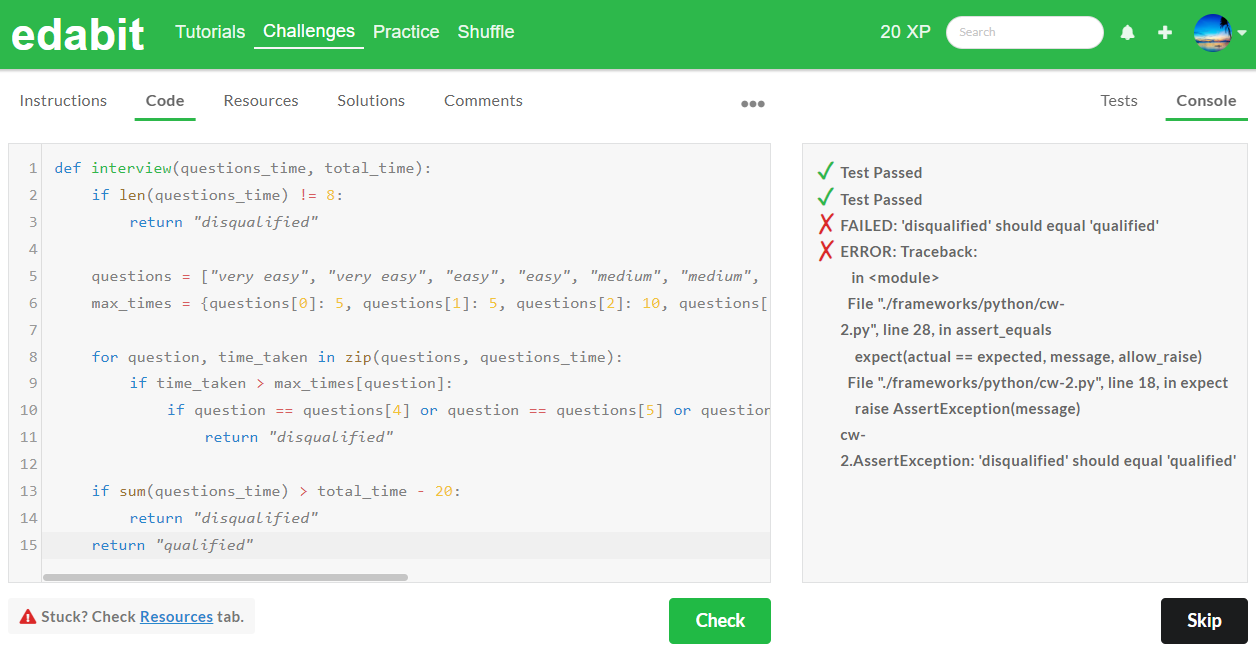
4. Very Hard 단계 : AutoCoder 6.7B 첫 번째 - 실패, 두번째 - 실패 (Llama3 8B : 첫번째 - 성공)

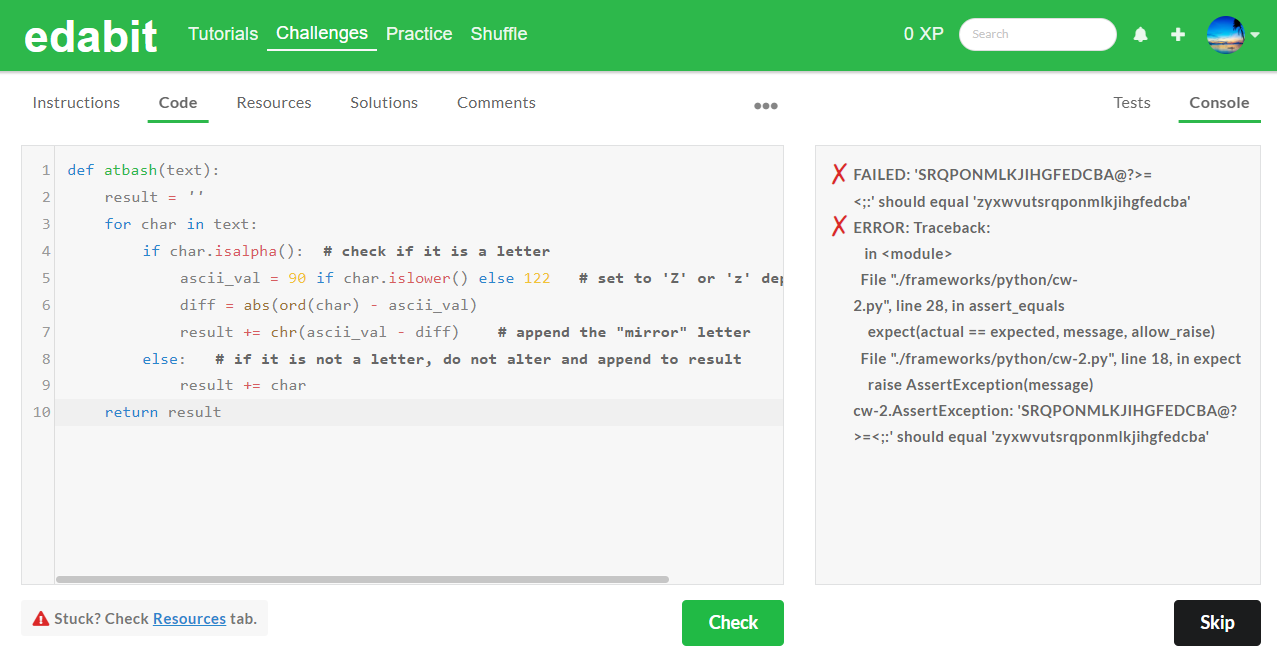
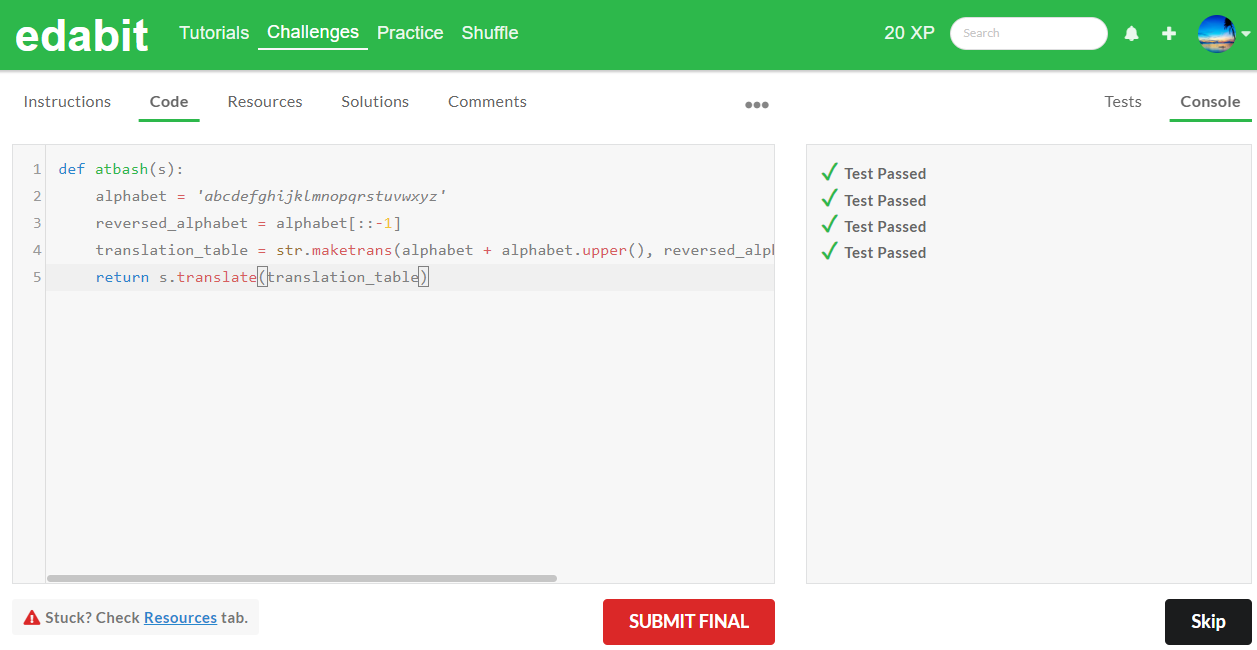
5. Expert 단계 : AutoCoder 6.7B 첫번째 - 실패, 두번째 - 실패 (Llama3 8B : 첫번째 - 실패, 두번째 - 실패)
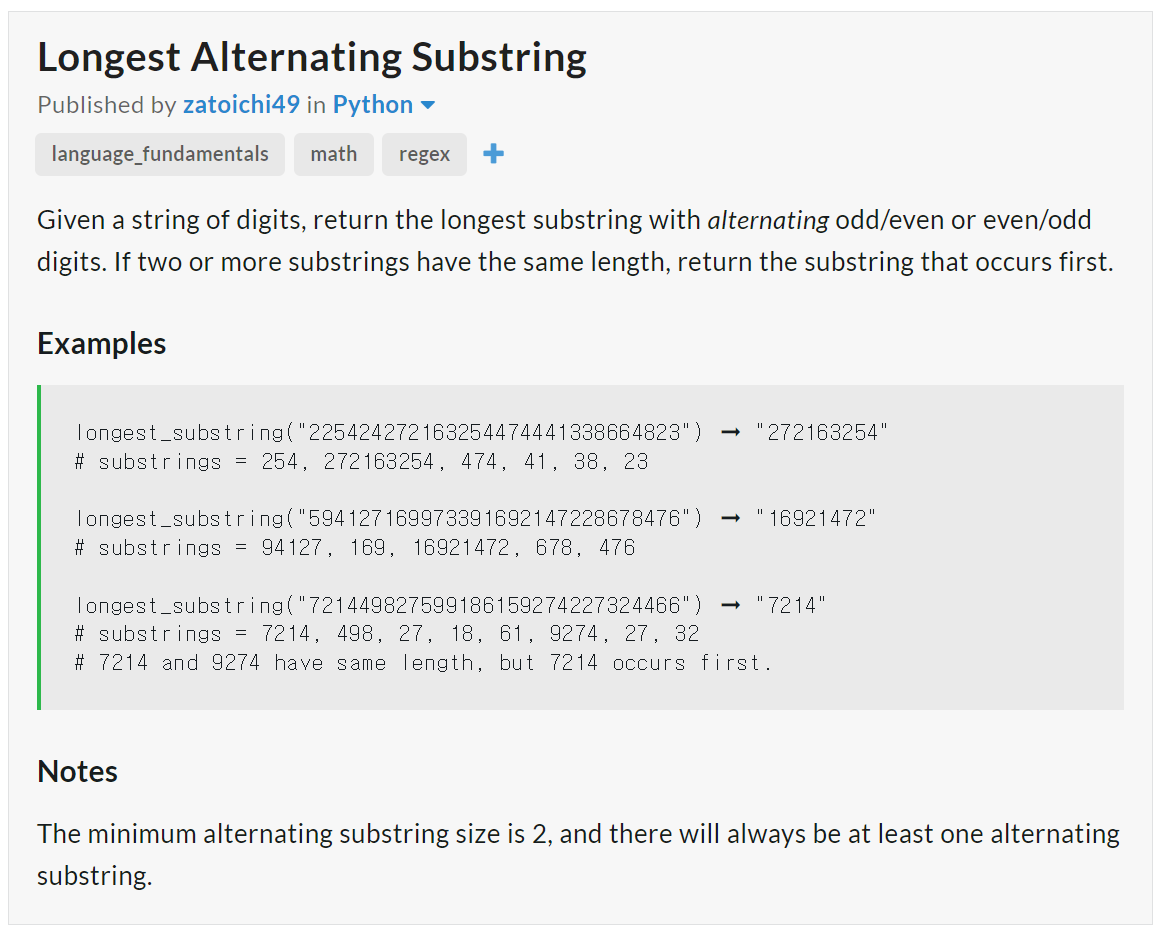
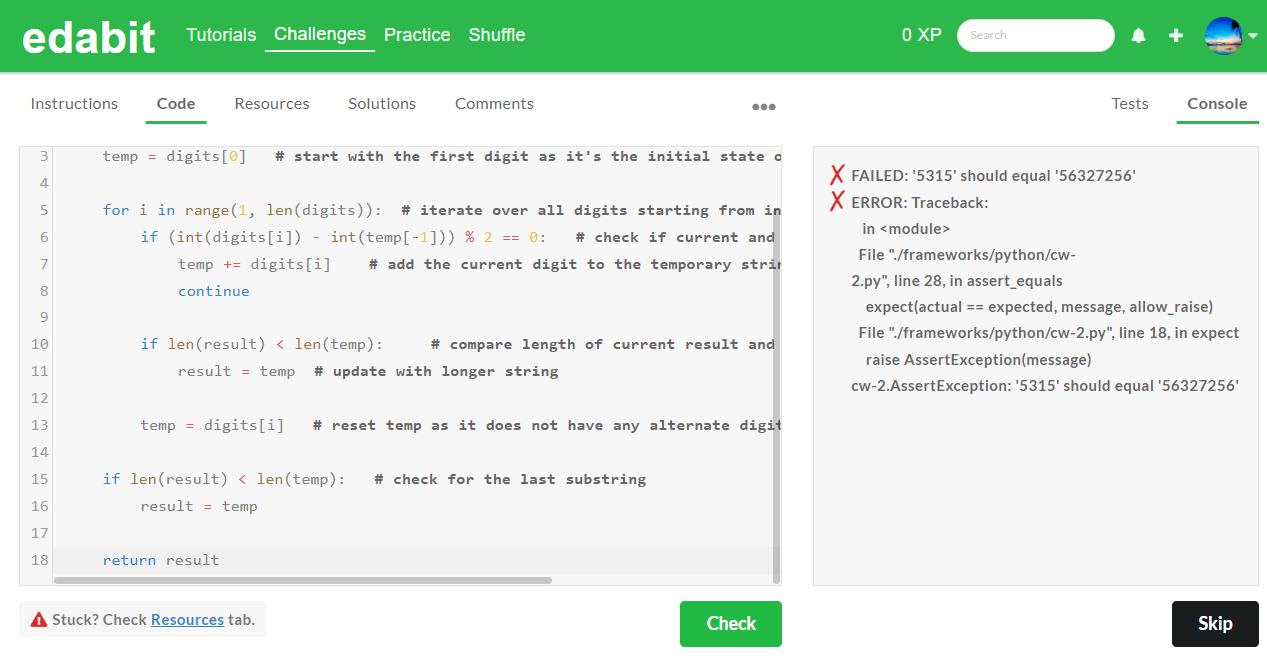
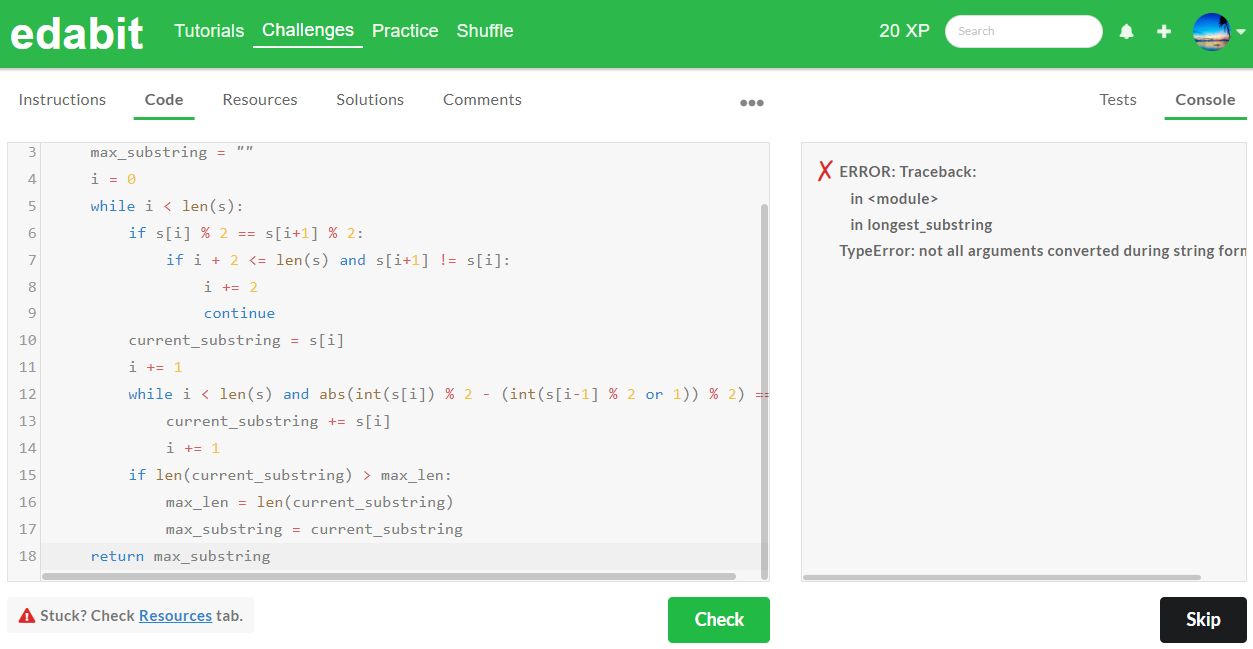
아래 표는 파이썬 테스트 종합결과입니다. 위에서 확인된 바와 같이 1차시도 기준으로 Python 코딩 테스트에서 AutoCoder 6.7B는 모든 단계에서 실패하였으며, Llama3 8B는 Medium과 Very Hard 단계에서 합격하였습니다.
| Python | Easy | Medium | Hard | Very Hard | Expert |
| AutoCoder 6.7B | Fail | Fail | Fail | Fail | Fail |
| Llama3 8B | Fail | Pass | Fail | Pass | Fail |
다음은 JavaScript 코딩 테스트입니다.
1. Medium 단계: AutoCoder 6.7B 첫번째 - 성공 (Llama3 8B : 첫번째 - 성공)

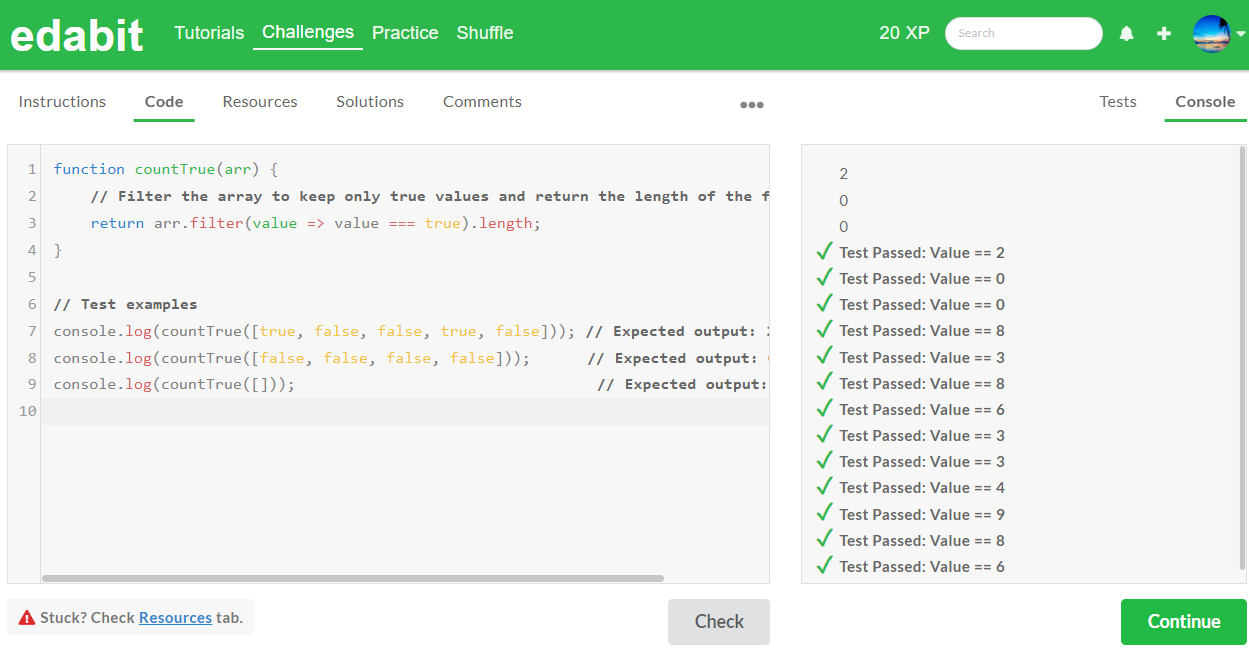
2. Hard 단계: AutoCoder 6.7B 첫번째 - 성공 (Llama3 8B : 첫번째 - 실패, 두번째 - 실패)

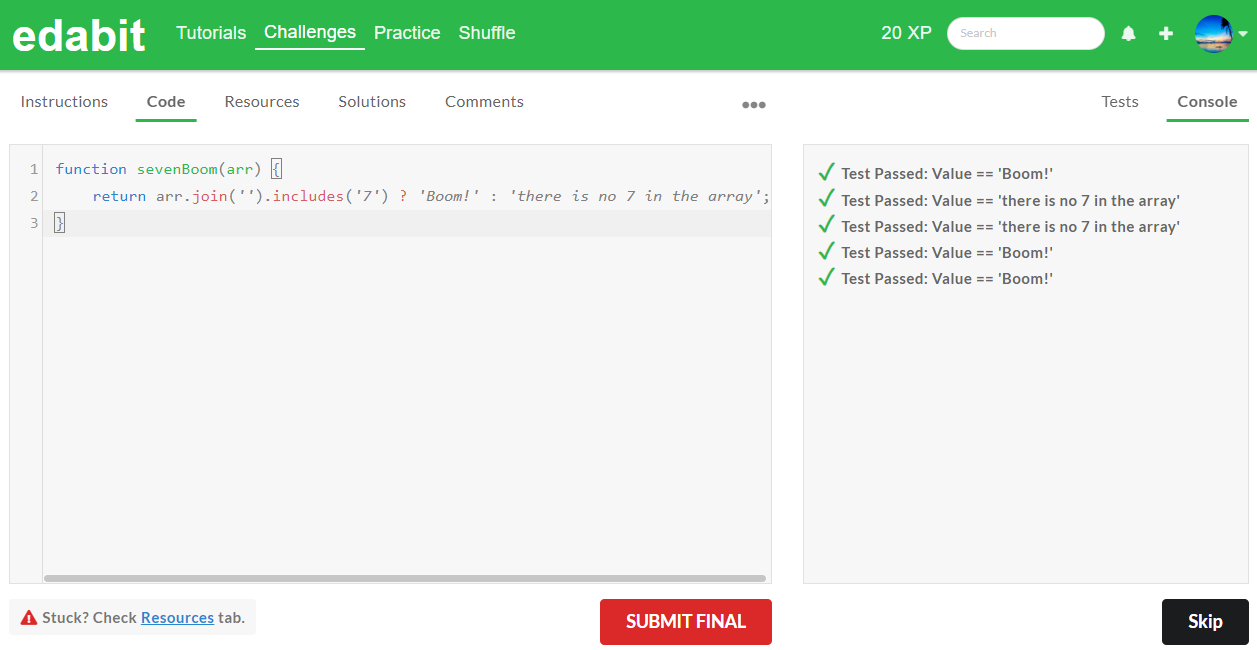
3. Very Hard 단계: AutoCoder 6.7B 첫번째 - 성공 (Llama3 8B : 첫번째 - 실패, 두번째 - 실패)
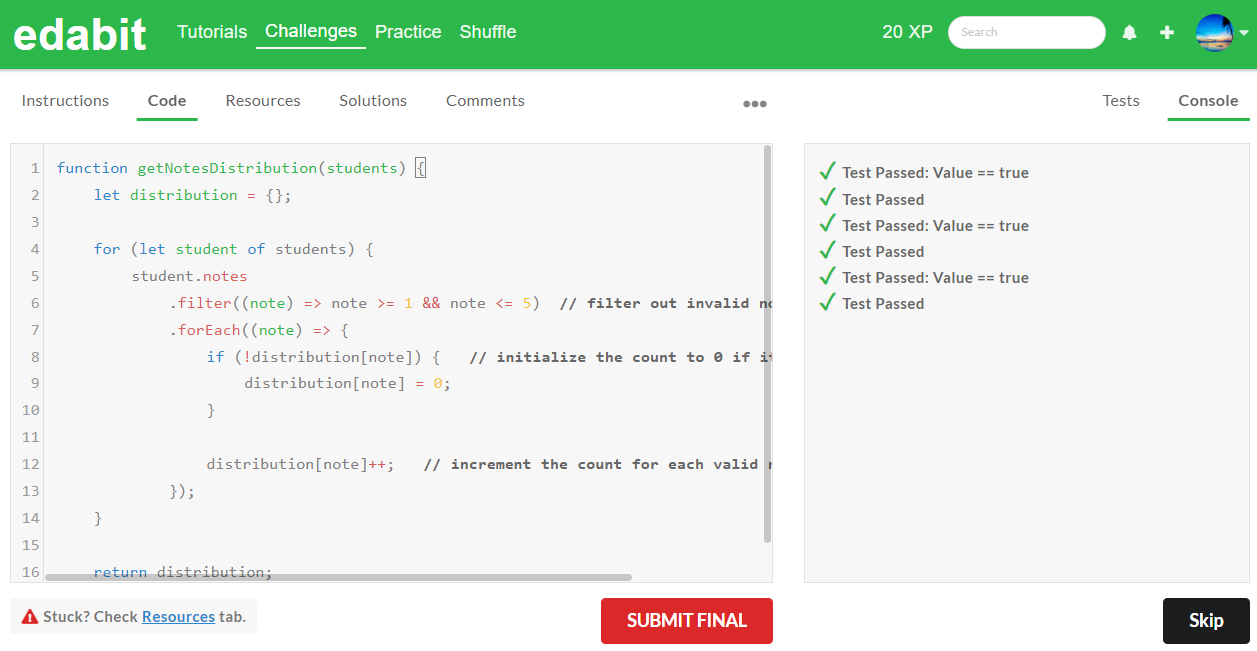

4. Expert 단계: AutoCoder 6.7B 첫번째 - 실패, 두번째 - 실패 (Llama3 8B : 첫번째 - 실패, 두번째 - 실패)

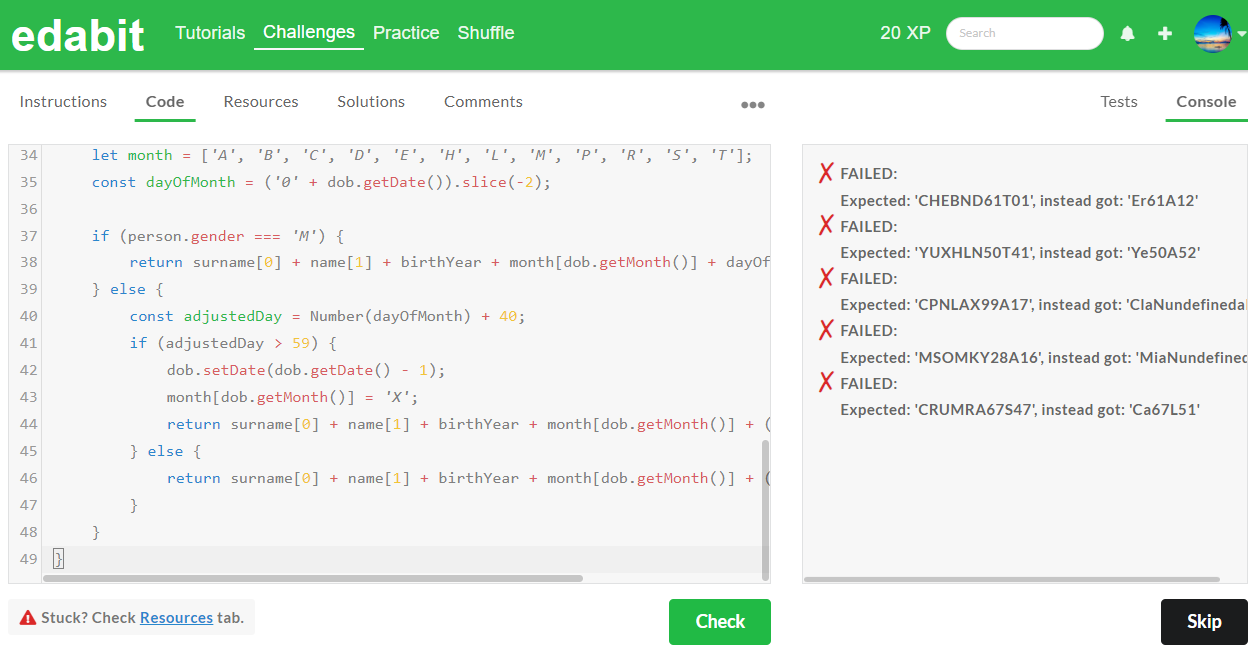
아래 표는 JavaScript 코딩 테스트에 대한 종합결과입니다. JavaScript 코딩 테스트에서 AutoCoder 6.7B는 Expert 단계에서 실패하였으며, Medium, Hard, Very Hard 단계 모두 합격하였습니다. Llama3 8B는 Medium 단계만 합격하였습니다.
| JavaScript/Pass@1 | Medium | Hard | Very Hard | Expert |
| AutoCoder 6.7B | Pass | Pass | Pass | Fail |
| Llama3 8B | Pass | Fail | Fail | Fail |
제가 테스트해 본 결과 AutoCoder 6.7B는 Python 코딩에서 부족한 성능을 보였으며, JavaScript에서는 Llama3 8B보다 우수한 성능을 보였습니다. AutoCoder 33B는 온라인 호스팅 제공자가 없어서 아직 테스트해보지 못했습니다.
논문의 결론 및 전망
본 논문에서는 코드 생성 모델의 성능을 획기적으로 향상시키기 위한 새로운 방법론인 AIEV-INSTRUCT를 소개했습니다. 이 방법론은 에이전트 상호작용과 실행 검증을 통해 고품질의 대규모 코드 지시 데이터셋을 자동으로 생성합니다. 이러한 데이터셋을 통해 학습된 AutoCoder 33B모델은 HumanEval 벤치마크에서 GPT-4 Turbo 및 GPT-4o를 능가하는 성과를 보였습니다.
특히, 외부 패키지를 설치할 수 있는 유연한 코드 인터프리터 기능을 통해 다양한 프로그래밍 언어와 데이터 과학 문제 해결에서 높은 성능을 입증했습니다. AIEV-INSTRUCT는 교수 단계와 자기 학습 단계를 포함하여, 초기에는 교사 모델(GPT-4 Turbo)을 사용하고, 이후에는 학생 모델(AutoCoder)이 자율적으로 데이터를 생성하고 학습하는 방식으로 진행됩니다. 이를 통해 비용과 시간을 절감하면서도 높은 정확성을 유지할 수 있습니다.
AIEV-INSTRUCT와 AutoCoder는 코드 생성 모델의 미래에 중요한 시사점을 제공합니다. 다양한 도메인 확장으로 의료, 금융, 법률 등 특수 분야에 적용할 수 있으며, 모델 경량화와 실시간 응용을 통해 모바일 및 임베디드 시스템에 효율적 사용이 가능하고, 교육, 연구, 산업 등 다양한 분야에서의 응용 사례 확대를 통해 소프트웨어 개발의 효율성과 정확성 향상에 기여할 수 있을 것으로 전망됩니다.
오늘 블로그는 여기까지입니다. 저는 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

'AI 논문 분석' 카테고리의 다른 글
| [최신 AI 논문]🤖Mobility VLA: 구글의 스마트한 멀티모달 내비게이션 기술 (0) | 2024.07.13 |
|---|---|
| 알파폴드 3, 생명의 신비를 밝히다! 단백질, DNA, RNA까지 예측하는 혁신 인공지능 (1) | 2024.05.11 |
| [AI 논문] InstantStyle: 같은 스타일을 가진 새로운 이미지 만들기 (0) | 2024.04.09 |
| 스테이블 디퓨전보다 28배 빠른 DMD 기술, 1장당 0.05초! (3) | 2024.03.29 |
| 구글 VLOGGER: 이미지 1장과 음성으로 움직이는 아바타를 만드는 방법 (0) | 2024.03.27 |



