안녕하세요! 오늘은 현존하는 이미지 생성 AI 중 가장 빠른 속도를 구현한 DMD(Distribution Matching Distillation, 분포 매칭 증류) 기술에 대해서 알아보겠습니다. DMD는 확산 모델(Diffusion Model)의 다단계 프로세스를 단일 단계로 단순화하는 방식으로 논문에 따르면 스테이블 디퓨전 1.5가 이미지 1장을 생성하는데 1.4초 걸리는 반면, DMD는 더 우수한 품질을 생성하면서도 이보다 약 28배 빠른 0.05초가 걸린다고 합니다. 이 블로그에서는 DMD 기술의 개요, 아키텍처, 동작원리, 성능에 대해서 살펴보겠습니다.
https://www.aitimes.com/news/articleView.html?idxno=158253
MIT "모든 이미지 생성 AI 중 가장 빠른 속도 모델 개발" - AI타임스
MIT 연구진이 \'실시간\'으로 이미지를 생성할 수 있는 프레임워크를 공개했다. 기존 확산 모델의 다단계 프로세스를 단일 단계로 단순화하는 방식으로, 생성 속도는 모든 이미지 생성 인공지능(A
www.aitimes.com

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문 개요
이 논문의 주요 목적은 디퓨전 모델과 같은 생성 모델의 효율적인 훈련과 가속화를 위한 새로운 방법을 제시하는 것입니다. 특히, 빠른 1단계 생성기를 활용하여 디퓨전 모델의 훈련 및 추론 속도를 크게 향상시키는 것을 목표로 합니다. 이를 통해 더 높은 효율성과 품질을 갖는 이미지 생성이 가능하도록 하고, 디퓨전 모델의 활용 가능성을 확대하는 것이 이 논문의 목적입니다.


논문의 연구내용
이 논문은 분포 매칭 증류(Distribution Matching Distillation, DMD)이라는 새로운 이미지 생성 기술을 제안합니다. 이 기술은 단일 단계 생성기를 사용하여 디퓨전 모델의 다단계 샘플링 과정을 단일 단계(One-step)로 축소합니다. 이를 통해 이미지 생성 속도가 크게 향상되면서도 이미지 품질을 유지합니다.
분포 매칭 증류란?
분포 매칭 증류는 대규모 학습된 선생 모델의 지식을 보다 작고 빠른 생성 모델로 전달하는 과정입니다. 이를 통해 생성 모델은 선생 모델이 보유한 데이터 분포와 관련된 정보를 습득하고, 이를 기반으로 이미지를 생성합니다. 이 과정에서 분포 매칭 증류는 선생 모델과 생성 모델 간의 분포 차이를 최소화하도록 하며, 생성 모델은 선생 모델이 보유한 데이터 분포와 유사한 이미지를 생성하도록 학습됩니다.
구체적으로, 분포 매칭 증류는 두 단계로 이루어집니다. 먼저, 생성 모델은 선생 모델로부터 샘플된 이미지와 짝을 이루는 가짜 이미지를 생성합니다. 그런 다음, 이 가짜 이미지와 짝을 이루는 실제 이미지의 분포를 최대한 유사하게 만들기 위해 생성 모델이 업데이트됩니다. 이를 통해 생성 모델은 선생 모델로부터 학습된 지식을 효과적으로 취득하고 선생 모델의 능력을 가능한 한 잘 따라잡도록 학습됩니다.
DMD는 가짜 이미지를 현실 세계의 실제 이미지와 유사하게 만들기 위해 소음 제거 및 차이 계산을 수행하여 생성기를 더 높은 품질의 이미지를 생성할 수 있도록 효과적으로 학습합니다. 이러한 기술은 다양한 이미지 생성 작업에 적용될 수 있으며, 빠른 속도와 높은 품질을 동시에 제공합니다.
https://tianweiy.github.io/dmd/
One-step Diffusion with Distribution Matching Distillation
Diffusion models are known to approximate the score function of the distribution they are trained on. In other words, an unrealistic synthetic image can be directed toward higher probability density region through the denoising process (see SDS). Our core
tianweiy.github.io
DMD 아키텍처와 구성요소
다음은 DMD의 아키텍처 개념도와 구성요소에 대한 설명입니다.
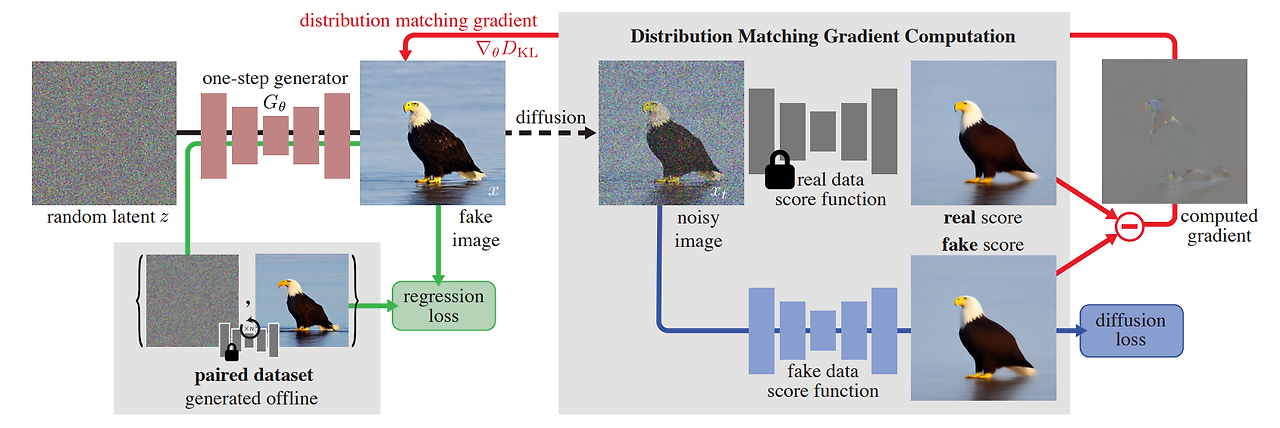
- 1. One-step generator (한 단계 생성기) : 주어진 랜덤 잠재 벡터나 노이즈를 입력으로 받아 실제와 유사한 가짜 이미지를 생성하는 모델입니다. 이 모델은 디퓨전 모델의 다단계 샘플링 과정을 단일 단계로 축소하여 더 빠르게 이미지를 생성할 수 있도록 합니다.
- 2. Paired dataset (쌍 데이터셋) : 미리 생성된 노이즈와 해당 노이즈에 대응하는 실제 이미지의 쌍으로 구성됩니다. 이 쌍들은 생성된 이미지와 실제 이미지 간의 유사성을 학습하고 평가하기 위해 사용됩니다.
- 3. Regression loss (회귀 손실) : 생성된 이미지와 실제 이미지 간의 유사성을 측정하는 손실 함수입니다. 이 손실 함수는 생성된 이미지를 실제 이미지와 유사하게 만들기 위해 사용됩니다. 주로 이미지 간의 거리를 측정하는 방법을 사용하여 계산됩니다.
- 4. Real data score function (실제 데이터 점수 함수) : 실제 이미지에 대한 점수 함수입니다. 이 함수는 주어진 실제 이미지의 품질이나 현실성을 측정하고, 생성된 이미지가 실제 이미지와 얼마나 유사한지를 평가하는 데 사용됩니다.
- 5. Fake data score function (가짜 데이터 점수 함수) : 생성된 가짜 이미지에 대한 점수 함수입니다. 이 함수는 생성된 이미지의 품질이나 현실성을 측정하고, 실제 데이터 분포와의 차이를 평가하는 데 사용됩니다.
- 6. Diffusion loss (확산 손실) : 생성된 이미지와 해당 이미지에 대한 노이즈를 활용하여 실제 이미지와의 유사성을 측정하는 손실 함수입니다. 이 손실 함수는 생성된 이미지를 실제 이미지와 유사하게 만들기 위해 사용됩니다.
- 7. Distribution matching gradient (분포 일치 기울기) : 생성된 가짜 이미지를 실제 이미지와 유사하게 만들기 위해 사용되는 기울기입니다. 이 값은 가짜 이미지를 생성하는 과정에서 실제 데이터 분포와의 차이를 최소화하고, 한 단계 생성기를 업데이트하여 이미지 생성 과정을 개선합니다.

DMD 동작원리
Distribution Matching Distillation (DMD) 동작순서와 원리는 다음과 같습니다.
- 1. 랜덤 잠재 벡터 생성 (Random Latent): 이미지 생성을 위해 먼저 랜덤한 잠재 벡터가 생성됩니다. 이 잠재 벡터는 이미지 생성의 기반이 됩니다.
- 2. 한 단계 생성기 초기화 (One-step Generator): 생성된 랜덤 잠재 벡터를 기반으로 한 단계 생성기가 초기화됩니다. 이 생성기는 시간에 따라 조건이 없는 확산 모델의 아키텍처를 따르며, 초기 이미지를 생성합니다.
- 3. 가짜 이미지 생성 (Fake Image Generation): 먼저, 한 단계 생성기를 사용하여 랜덤 노이즈 벡터로부터 가짜 이미지를 생성합니다. 이 가짜 이미지는 사전 훈련된 내용을 기반으로 디퓨전 모델이 추론하여 생성한 것입니다.
- 4. 노이즈 주입 (Noise Injection): 가짜 이미지에 노이즈를 주입합니다. 잡음의 강도, 종류, 분포를 조절하여 가짜 이미지를 더 실제 이미지와 유사하게 만들 수 있습니다.
- 5. 실제 데이터 점수 함수와 가짜 데이터 점수 함수: 주입된 가짜 이미지는 두 개의 디퓨전 모델에 입력됩니다. 하나는 실제 데이터로 사전 훈련되었고, 다른 하나는 가짜 이미지를 사용하여 훈련됩니다.
- 6. 소음 제거된 버전 (Denoised Versions): 두 디퓨전 모델은 주입된 가짜 이미지에 대한 소음 제거된 버전을 생성합니다. 이 소음 제거된 버전은 실제 이미지와 유사한 특성을 가질 수 있습니다.
- 7. 차이 계산 (Difference Calculation): 소음 제거된 가짜 이미지와 실제 이미지 간의 차이를 계산합니다. 이 차이는 가짜 이미지를 실제 이미지와 더 유사하게 만드는 방향을 나타냅니다.
- 8. 역전파 (Backpropagation): 이 차이는 다시 한 단계 생성기로 역전파됩니다. 이 과정을 통해 한 단계 생성기는 가짜이미지를 더 실제 이미지와 유사하게 만드는 방향으로 업데이트됩니다.

DMD 성능평가 결과
DMD 모델은 선생님 모델 (Teacher Model)인 SDv1.5보다 월등한 생성속도를 보이며, LCM-LoRA 보다도 생성속도, 품질, 텍스트 프롬프트 상관점수가 우수합니다.

위 표는 다양한 이미지 생성 모델 및 방법에 대한 성능 비교를 보여줍니다. 표는 다음과 같은 정보를 포함합니다:
- Family: 각 모델이 속한 카테고리 또는 패밀리입니다. 이는 해당 모델의 기술적인 특징이나 접근 방식을 나타냅니다.
- Method: 각 모델의 이름 또는 식별자입니다.
- Latency (↓): 이미지를 생성하는 데 걸리는 시간을 나타냅니다. ↓ 기호는 시간이 더 적게 걸리는 것을 의미합니다.
- FID (↓): 생성된 이미지의 품질을 나타내는 지표 중 하나인 Fréchet Inception Distance를 나타냅니다. FID 값이 작을수록 이미지의 품질이 높다는 것을 의미합니다.
- CLIP-Score(↑):는 이미지와 텍스트 간의 상관관계를 측정하는 지표입니다. 점수가 높을수록 이미지와 텍스트 간의 상호 작용이 더 강력하게 나타납니다.
표를 통해 제안된 DMD 모델이 낮은 지연 시간과 낮은 FID, 높은 CLIP 점수를 가진다는 것을 확인할 수 있습니다. 따라서 이 모델은 다른 비교 모델들에 비해 프롬프트에 맞는 빠르고 높은 품질의 이미지를 생성할 수 있다는 것을 시사합니다.
논문의 결론 및 전망
논문은 Distribution Matching Distillation (DMD)을 제안하고, 이를 통해 고품질의 이미지를 생성하는 속도를 크게 향상시켰습니다. DMD는 기존의 다단계 샘플링 방법을 단일 단계로 축소하여 속도를 높이는 데 성공했습니다. 실험 결과, DMD는 기존 모델에 비해 더 빠르면서도 품질을 유지하는 것으로 나타났습니다. 또한, DMD는 이미지 품질과 다양성을 조절하는 가이드 스케일에서도 우수한 성능을 보였으며, 이는 이미지의 세부 사항을 더 잘 캡처하고 더 높은 품질의 이미지를 생성할 수 있으므로 실제 응용 프로그램에 더 널리 사용될 수 있음을 시사합니다.
DMD의 한계는 주로 두 가지 측면에서 나타납니다. 첫째, DMD는 다단계 샘플링 과정을 단일 단계로 축소하는 데 주력하며, 이로 인해 세밀한 이미지 세부 사항을 잃을 수 있습니다. 둘째, DMD 모델의 성능은 주로 사용된 선생 모델(Teacher Model)에 의해 제한됩니다. 이는 선생 모델이 처리하기 어려운 일부 이미지 요소에 대한 처리 능력이 제한되는 한계를 의미합니다. 따라서 DMD의 성능은 선생 모델인 SDv1.5 한계에 따라 제한될 수 있습니다. 이러한 한계를 극복하기 위해서는 더 발전된 선생 모델의 사용이나 DMD 모델 자체의 개선이 필요할 수 있습니다.
오늘은 현존하는 이미지 생성 모델 중 가장 빠른 생성속도를 구현한 MIT의 DMD 모델에 대해서 알아보았습니다. 이러한 생성형 AI의 발전은 결국 모든 결과물의 실시간 생성으로 수렴되어, 우리의 상상력을 무한히 펼칠 수 있도록 해줄 것으로 기대됩니다.
오늘 내용은 여기까지입니다. 저는 다음에 더 유익한 내용으로 다시 찾아뵙겠습니다. 감사합니다.

2024.02.23 - [AI 논문 분석] - 🚀 SDXL-Lightning: 스테이블 디퓨전 기반 초고속 이미지 생성 기술 심층 분석
🚀 SDXL-Lightning: 스테이블 디퓨전 기반 초고속 이미지 생성 기술 심층 분석
안녕하세요! 오늘은 틱톡으로 유명한 중국의 IT기업, ByteDance에서 개발한 SDXL-Lightning이라는 이미지 생성모델에 대한 논문을 살펴보겠습니다. SDXL-Lightning은 " 점진적 적대적 확산 증류(Progressive Adve
fornewchallenge.tistory.com
'AI 논문 분석' 카테고리의 다른 글
| 알파폴드 3, 생명의 신비를 밝히다! 단백질, DNA, RNA까지 예측하는 혁신 인공지능 (1) | 2024.05.11 |
|---|---|
| [AI 논문] InstantStyle: 같은 스타일을 가진 새로운 이미지 만들기 (0) | 2024.04.09 |
| 구글 VLOGGER: 이미지 1장과 음성으로 움직이는 아바타를 만드는 방법 (0) | 2024.03.27 |
| LATTE3D: 엔비디아의 새로운 텍스트 기반 3D 생성 기술 (0) | 2024.03.25 |
| MM1: 애플의 새로운 멀티모달 언어 모델 (0) | 2024.03.21 |



