안녕하세요! 오늘은 얼굴 사진 한 장으로 딥페이크를 생성하는 InstantID 기술을 공개했던 베이징의 스타트업 인스턴트 X에서 최근 공개한 InstantStyle이라는 기술에 대해서 알아보겠습니다. InstantStyle은 텍스트 기반 이미지 생성 시 컨텐츠와 스타일을 명확하게 구분하여 주어진 스타일을 유지하면서 새로운 이미지를 생성하는 기술입니다. 이 블로그에서는 InstantStyle의 개요, 구성요소, 동작원리에 대해 알아보고 DEMO 이미지를 생성해 보겠습니다.


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문 개요
InstantStyle은 주어진 참조 이미지의 스타일을 보존하면서 텍스트 입력을 통해 새로운 이미지를 생성하는 것으로, 기존의 방법들은 스타일 전달 시 세부 디테일 손실, 스타일 강도와 텍스트 제어성 간의 균형에 문제점이 있었으나, 이 논문은 스타일과 콘텐츠의 분리를 통해 이러한 문제를 해결하고자 하였습니다.
- 논문제목 : InstantStyle: Free Lunch towards Style-Preserving in Text-to-Image Generation
- 논문저자 : Haofan Wang 등 InstantX Team
- 논문게재 사이트: https://arxiv.org/abs/2404.02733
- 논문게재일 : 2024년 4월


이 연구의 목적은 텍스트-이미지 스타일 전송 작업에서 기존 모델의 한계를 극복하고 새로운 프레임워크인 InstantStyle을 소개하는 것입니다.
논문의 연구내용 및 결과
논문은 이미지와 텍스트 간의 상호작용을 이해하고 둘을 동일한 임베딩 공간으로 매핑하여 이미지와 텍스트 간의 유사성을 학습하는 CLIP(Contrastive Language–Image Pre-training, 대조적 언어-이미지 사전훈련) 모델을 사용하여 이미지와 텍스트의 특성을 추출하고, 이를 활용하여 참조 이미지의 스타일과 콘텐츠를 분리하는 방법을 제안합니다.
문제 해결 전략
InstantStyle은 스타일과 콘텐츠를 분리하여 스타일 보존 및 텍스트 입력을 통한 이미지 생성의 문제를 해결하는 것입니다. 이를 위해 InstantStyle은 두 가지 간단하고 효과적인 전략을 도입했습니다.
- 첫 번째 전략은 이미지에서 콘텐츠를 분리하는 것입니다. 콘텐츠는 이미지에 포함된 사물, 장면, 또는 다른 시각적인 특징들을 나타냅니다. 이를 위해 CLIP의 텍스트 인코더를 사용하여 콘텐츠 텍스트의 특성을 추출하고, CLIP의 이미지 인코더를 사용하여 참조 이미지의 특성을 추출합니다. 그런 다음 콘텐츠 텍스트 특성을 이미지 특성에서 빼내면, 해당 이미지의 콘텐츠와 관련된 정보가 제거됩니다. 이렇게 하면 이미지의 시각적 특성만 남게 됩니다. 즉, 이미지에서 텍스트로 설명할 수 있는 내용이 제거되고, 남은 것은 주로 시각적인 스타일이나 모양에 대한 정보입니다. 이렇게 함으로써 이미지의 시각적 스타일적 특성을 강조하고 콘텐츠와 스타일을 명확하게 분리할 수 있습니다.
- 두 번째 전략은 스타일 블록에만 이미지 특성을 주입하는 것입니다. SDXL UNet과 같은 딥 네트워크의 각 레이어가 다른 의미 정보를 포착한다는 것을 고려하여, 특정 어텐션 레이어를 스타일 블록으로 식별합니다. 이를 통해 이미지 특성이 스타일 관련 블록에만 주입되어 입력된 이미지의 시각적 스타일을 보존하면서 새로운 이미지를 생성할 수 있습니다.
논문에서는 CLIP 모델을 사용하여 이미지 특성을 추출한 후, SDXL 모델의 특정블록을 통해 이미지 스타일을 보존하기 위해 SDXL 모델의 블록 구조를 분석하고, 이 중에서 이미지 생성에 관련된 블록을 특히 강조하여 스타일을 보존하는 데 사용합니다.

InstantStyle 구성요소
InstantStyle은 다음과 같은 구성 요소로 이루어져 있으며, 각 구성요소는 동작 구성도 그림과 같이 연결됩니다.
- CLIP 모델: 이미지와 텍스트 간의 상호 작용을 이해하는 데 사용됩니다. CLIP 모델은 대규모의 텍스트-이미지 쌍에 대한 대조 손실을 사용하여 이미지와 텍스트를 공유 임베딩 공간에 통합하고 유사성을 학습합니다.
- 이미지 특성 추출기: CLIP 모델의 이미지 인코더를 사용하여 참조 이미지의 특성을 추출합니다.
- Image-Content embedding: 이미지와 해당 이미지의 콘텐츠를 나타내는 임베딩 벡터입니다. 이 임베딩은 이미지의 주요 콘텐츠 특성을 포함하며, 이미지의 내용을 잘 대표하는 특징을 캡처합니다.
- 텍스트 특성 추출기: CLIP 모델의 텍스트 인코더를 사용하여 텍스트 프롬프트의 특성을 추출합니다.
- Text embedding: 자연어 텍스트를 숫자로 된 벡터 형태로 변환하는 기술을 말합니다.
- 이미지 및 텍스트 특성의 상호작용: 이미지와 텍스트 특성 간의 상호작용을 통해 스타일 및 콘텐츠를 분리합니다.
- SDXL(Unet) 구조: 이미지 생성을 위해 SDXL(Unet) 구조를 사용합니다. 이 구조는 이미지 스타일 변환 작업에서 새로운 이미지를 생성하는 데 사용됩니다.
- IP-Adapter: SDXL(Unet)에서 4번째와 6번째 블록을 가리키며, 스타일과 레이아웃을 캡처하는 데 사용됩니다.
- Cross Attention: 주어진 두 시퀀스 간의 상호작용을 계산하는 메커니즘으로 자연어 처리에서는 번역, 요약, 질문 응답 등과 같은 작업에 활용될 수 있으며, 이미지와 텍스트 사이의 상호작용 모델링 등 다양한 시각-언어 작업에 적용될 수 있습니다
위 구성도에서 CLIP 모델은 참조 이미지의 스타일(구성 요소나 시각적인 내용, 파란 하늘, 빨간 비행기 등)을 나타내는 이미지-콘텐츠 임베딩과, 텍스트 프롬프트에 대한 특성을 나타내는 텍스트 임베딩을 생성하고, Cross attention을 사용하여 텍스트와 이미지 간의 상호 작용을 모델링하며, 이를 통해 이미지의 특성을 추출합니다. 이렇게 추출된 이미지 특성을 SDXL 모델의 스타일 블록에 주입하여 해당 블록이 이미지의 시각적 스타일을 보존하면서 새로운 이미지가 생성됩니다.
SDXL 모델의 블록 구조
SDXL 모델의 블록 구조는 이미지 생성을 위한 텍스트-이미지 모델에서 사용되는 구조이며, 이 모델은 일련의 트랜스포머 블록을 사용하여 구성됩니다. 위 구성도와 같이 SDXL에는 총 11개의 트랜스포머 블록이 있으며, 이 중 4개는 다운샘플 블록, 1개는 중간 블록, 6개는 업샘플 블록입니다. 논문은 4번째와 6번째 블록이 각각 Layout과 Style에 해당하는 것을 발견했습니다. 각 블록은 입력된 텍스트와 이미지 정보를 기반으로 다음 단계에서 이미지를 생성하는 데 사용됩니다. 일반적으로 SDXL 모델은 다음과 같은 주요 블록을 포함할 수 있습니다.
- 다운샘플 블록 (Downsample Blocks): 입력 이미지의 해상도를 줄이는 데 사용됩니다. 이러한 블록은 입력 이미지의 크기를 줄이고 추상화된 특징을 추출하는 데 중요합니다.
- 중간 블록 (Middle Block): 다운샘플 블록 이후에 입력 이미지의 특성을 보다 상세하게 다룹니다. 중간 블록은 이미지의 고수준 특징을 캡처하고 복원하는 데 중요한 역할을 합니다.
- 업샘플 블록 (Upsample Blocks): 입력 이미지의 해상도를 증가시키는 데 사용됩니다. 업샘플 블록은 이미지를 더 자세하게 생성하는 데 도움이 됩니다.
Layout 블록과 Style 블록은 InstantStyle에서 언급된 개념으로, 이들은 특정 어텐션 레이어를 가리키며 이미지의 레이아웃과 스타일 정보를 캡처합니다. Layout 블록은 이미지의 구조와 배치에 관련된 정보를 다루는 데 중점을 두며, Style 블록은 이미지의 시각적 스타일과 특징을 다룹니다. 이러한 블록들은 각각 이미지 생성 과정에서 중요한 역할을 수행하여 최종적으로 텍스트 입력에 따라 스타일을 보존한 이미지를 생성합니다.

InstantStyle 동작순서
InstantStyle의 동작순서는 다음과 같습니다:
- 1. 참조 이미지 및 텍스트 입력: InstantStyle은 먼저 사용자로부터 참조 이미지와 생성하고자 하는 이미지에 대한 텍스트 입력을 받습니다.
- 2. 이미지 특성 추출: 참조 이미지는 CLIP의 이미지 인코더를 사용하여 이미지 특성을 추출합니다. 이때, 이미지의 콘텐츠 특성과 스타일 특성이 함께 추출됩니다. 예를 들면 사람의 얼굴과 주변 배경은 콘텐츠 특성을 나타내며, 사진의 필터, 색조, 밝기 등은 스타일 특성을 나타냅니다.
- 3. 콘텐츠 특성 분리: CLIP의 텍스트 인코더를 사용하여 추출된 이미지 특성 중에서 텍스트 입력에 해당하는 콘텐츠 특성을 분리합니다. 이를 통해 이미지의 콘텐츠와 스타일이 명확히 분리되고, 남는 것은 주로 사진의 필터, 색조, 밝기와 같은 시각적인 스타일이나 모양에 대한 정보입니다.
- 4. 스타일 블록 식별: 이미지 특성 중에서 스타일을 나타내는 특정 어텐션 블록을 식별합니다. 이 블록은 이미지 생성 시 스타일을 적용하는 데 사용됩니다.
- 5. 이미지 생성: 분리된 콘텐츠 특성과 식별된 스타일 블록을 사용하여 새로운 이미지를 생성합니다. 콘텐츠 특성은 새로운 이미지의 기본 구조를 결정하고, 스타일 블록은 참조 이미지의 스타일을 적용합니다.
- 6. 콘텐츠와 스타일 결합: 생성된 이미지에는 콘텐츠와 스타일이 분리되어 적용되었으며, 이들을 결합하여 최종 이미지를 생성합니다.
이와 같은 동작순서를 통해 InstantStyle은 참조 이미지의 스타일을 보존하면서 텍스트 입력에 따라 새로운 이미지를 생성합니다.
성능평가 결과
InstantStyle은 다양한 스타일과 콘텐츠에 대한 실험을 통해 뛰어난 성능을 입증하였습니다. 원본 이미지와 스타일이 유사하게 유지되는 문제를 완화하면서 복잡한 가중치 조정이 필요하지 않습니다. 또한, 주어진 스타일 이미지와 사용자가 제공하는 프롬프트를 활용하여 이미지의 스타일을 조절하고 수정하는 ControlNet을 통해 공간 제어 기반 이미지 스타일링도 가능하다는 점을 확인했습니다.
공간 제어 기반 이미지 스타일링 방식이란 사진을 스타일링할 때, 사용자는 이미지의 특정 부분에만 스타일을 적용할 수 있습니다. 예를 들어, 어떤 사진에서는 하늘의 색상을 변경하거나 구름의 질감을 바꾸고 싶을 수 있습니다. 이를 위해 사용자는 이미지의 해당 부분을 선택하고 원하는 스타일을 적용할 수 있습니다. 이러한 방식으로, 사용자는 이미지의 각 부분을 세밀하게 제어하여 원하는 스타일을 적용하고 원하는 대로 이미지를 수정할 수 있습니다.


DEMO
다음은 DEMO 사이트를 통해서 직접 스타일 전이 이미지 생성을 해보겠습니다. 아래 주소를 통해서 InstantStyle를 체험해 보실 수 있습니다. 사이트는 참조 이미지를 입력하고 프롬프트를 입력하여 이미지를 생성하는 기능이 구현되어 있습니다.
https://huggingface.co/spaces/ameerazam08/InstantStyle-GPU-Demo
InstantStyle GPU-Demo - a Hugging Face Space by ameerazam08
Running on Zero
huggingface.co
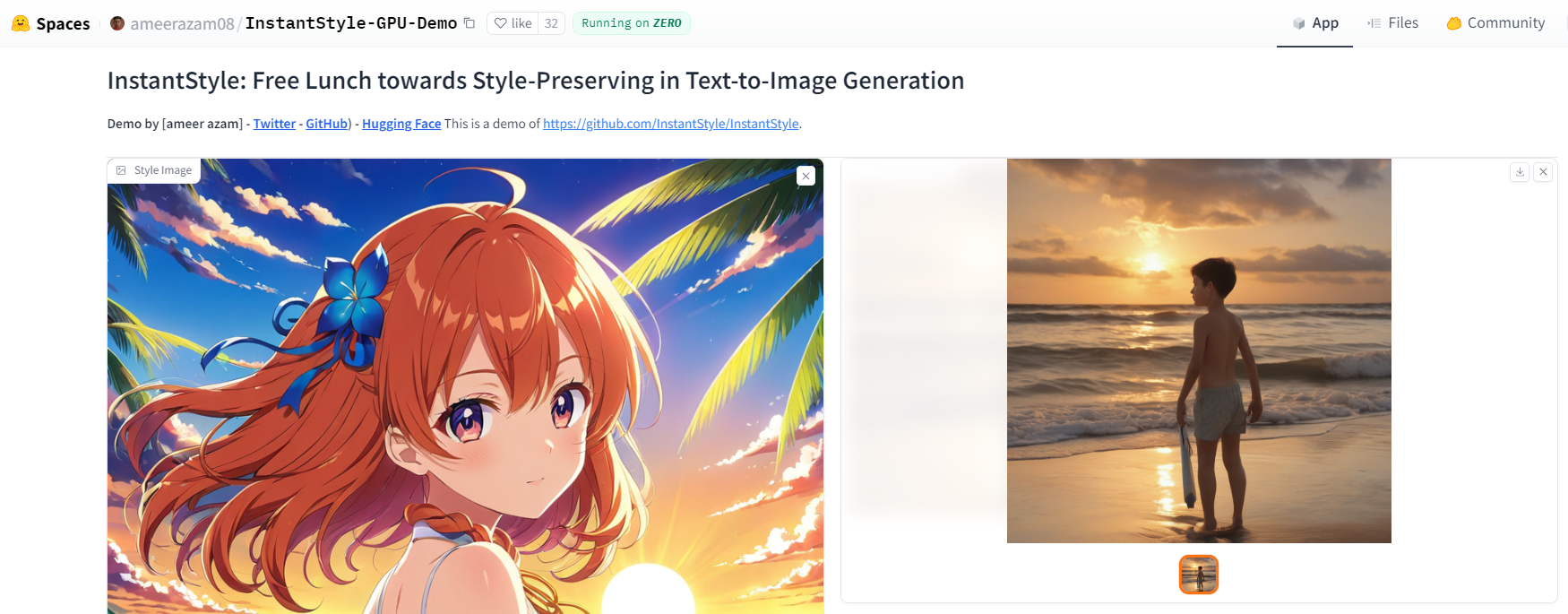
아래 화면을 보시면 왼쪽 이미지는 제가 입력한 참조 이미지이고, 오른쪽은 스타일을 유지하면서 제가 입력한 텍스트 프롬프트 "a man on the beach"를 반영하여 새로 생성된 이미지입니다. 머리색깔, 배경, 인물 자세 등의 스타일이 보존되어 프롬프트에 따라 이미지가 생성되었습니다.

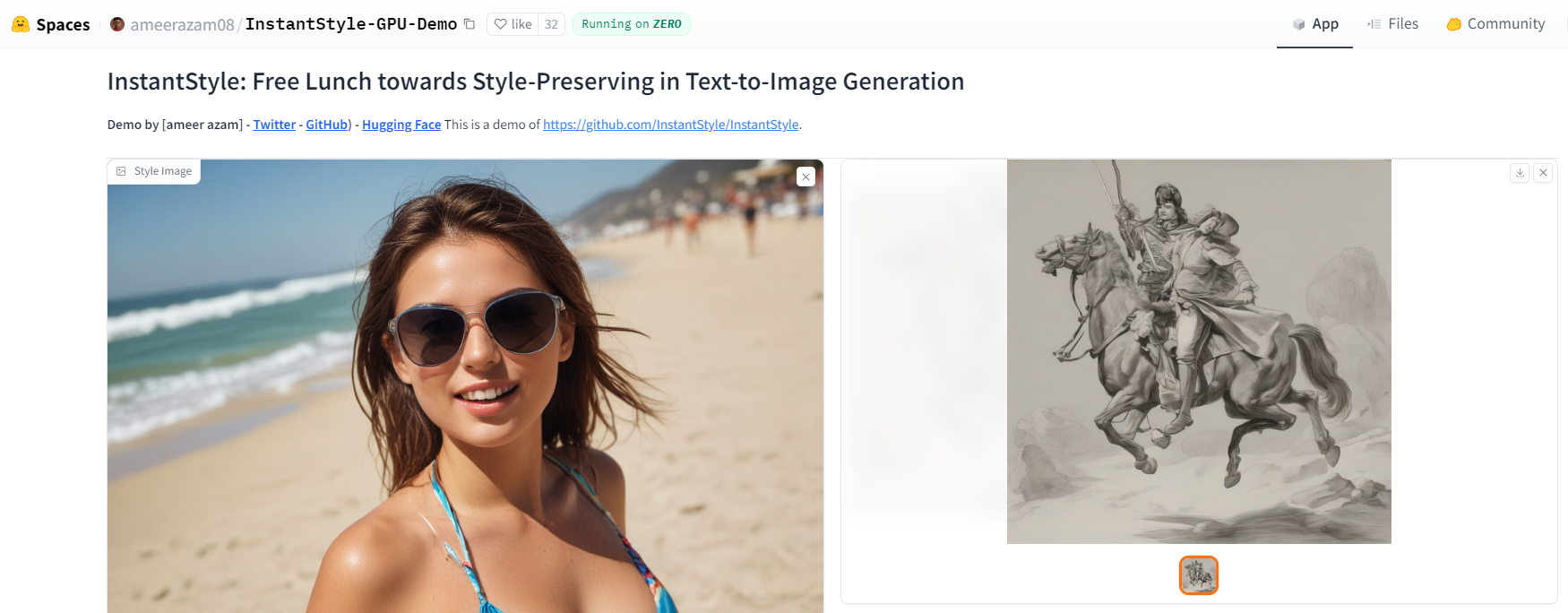
다음 이미지도 장소, 구도, 색감 등 참조 이미지의 스타일이 보존되며 새로운 이미지가 생성되었습니다.


하지만, DEMO 사이트에서 생성해 본 이미지 중 몇몇 이미지는 아래 화면과 같이 참조 이미지의 스타일과 전혀 유사하지 않은것도 있었으며, 참조 이미지의 스타일 이전이 만족할 만한 수준에 미치지 못하였습니다.
논문의 결론 및 전망
이 연구에서는 InstantStyle이라는 참조 이미지에서 스타일과 콘텐츠를 효과적으로 분리하기 위한 범용 프레임워크를 제안하였습니다. 제안된 방법은 추가 학습 없이 다양한 어텐션 기반 이미지 편집 작업에 적용 가능하며, 우수한 스타일 전이 성능을 보여줍니다. 본 연구는 이미지의 레이아웃과 스타일에 관련된 특정 트랜스포머 블록의 고유한 특성을 밝혀내었고, 모든 레이어가 동등하게 기여하지 않음을 보여주었습니다.
InstantStyle은 스타일 보존 이미지 생성 분야에서 새로운 방향을 제시하였습니다. 하지만, DEMO 이미지 생성을 통해 확인한 것처럼 참조 이미지의 스타일이 전혀 이전되지 않는 경우도 존재했는데요, 이런 부분은 향후 연구를 통해 보다 정교하고 확장된 기능을 갖추게 되기를 기대해 봅니다.
오늘 블로그는 여기까지입니다. 저는 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.02.02 - [AI 논문 분석] - [AI 논문] InstantID: 얼굴 사진 한장으로 딥페이크 생성
[AI 논문] InstantID: 얼굴 사진 한장으로 딥페이크 생성
안녕하세요! 오늘은 베이징의 스타트업 인스턴트 X가 개발한 얼굴 사진 한 장으로 원본에 충실한 딥페이크를 생성하는 InstantID라는 기술에 대해서 알아보겠습니다. InstantID의 핵심은 IdentityNet이
fornewchallenge.tistory.com
'AI 논문 분석' 카테고리의 다른 글
| [AI 논문] AutoCoder: GPT-4o를 능가한 코드 생성 대형 언어 모델 (0) | 2024.05.28 |
|---|---|
| 알파폴드 3, 생명의 신비를 밝히다! 단백질, DNA, RNA까지 예측하는 혁신 인공지능 (1) | 2024.05.11 |
| 스테이블 디퓨전보다 28배 빠른 DMD 기술, 1장당 0.05초! (2) | 2024.03.29 |
| 구글 VLOGGER: 이미지 1장과 음성으로 움직이는 아바타를 만드는 방법 (0) | 2024.03.27 |
| LATTE3D: 엔비디아의 새로운 텍스트 기반 3D 생성 기술 (0) | 2024.03.25 |



