안녕하세요! 오늘은 구글의 단일 이미지 입력 및 오디오 기반 비디오 생성기술인 VLOGGER에 대해서 알아보겠습니다. VLOGGER는 인간의 얼굴과 몸의 다양한 표현을 사용하여 길이가 가변적인 고품질 비디오를 생성하는 과정에서 각 개인별로 별도의 훈련이 필요하지 않으며, 얼굴이나 입술뿐만 아니라 완전한 이미지를 생성하고, 다양한 상황에서 의사 소통하는 모습을 합성할 수 있습니다. 이 블로그에서는 VLOGGER의 파이프라인 구조과 동작원리, MENTOR 데이터셋 등에 대해서 살펴보겠습니다.
|
|
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문 개요
이 논문의 목적은 주어진 오디오와 단일 입력 이미지를 활용하여 사람의 현실적인 영상을 생성하는 새로운 프레임워크인 VLOGGER를 제안하는 것입니다.
- 논문제목 : VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
- 논문저자 : Google Research
- 논문게재 사이트 : https://arxiv.org/abs/2403.08764
- 논문게재일 : 2024. 3.

논문의 연구내용
VLOGGER는 단일 이미지와 음성을 기반으로 한 인간 비디오 생성을 위한 새로운 방법론입니다. 이를 위해 트랜스포머 아키텍처와 생성 확산 모델을 활용하여 중간 제어 표현(Intermediate Control Representation)을 추출하고, 이를 기반으로 고화질의 비디오를 생성합니다. 이를 통해 자연스러운 표정과 동작을 반영하는 인체 모션을 현실적으로 재현할 수 있습니다.
VLOGGER 파이프라인
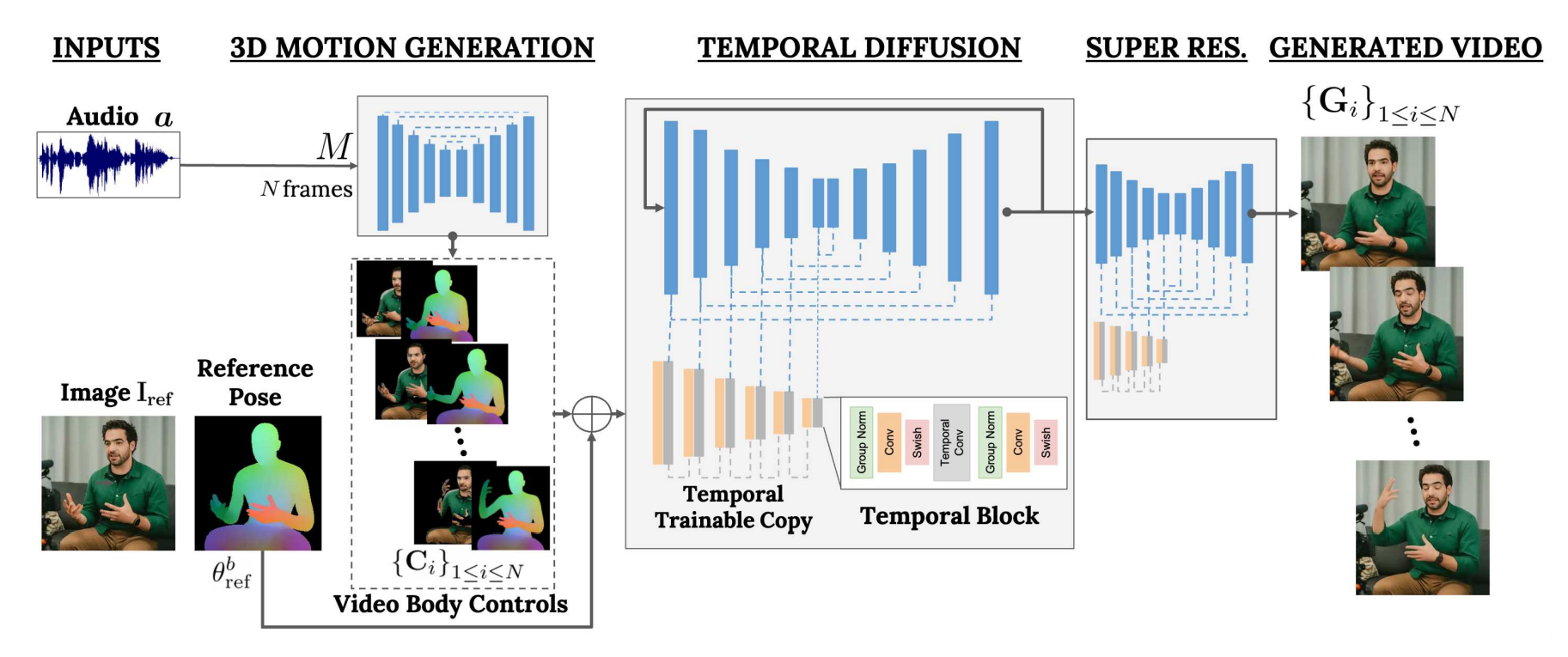
- 1. 음성 기반 동작 생성 단계: VLOGGER의 첫 번째 네트워크는 입력된 음성에 기초하여 동작을 생성합니다. 음성 신호를 분석하여 말하는 사람의 얼굴 표현, 시선, 표정, 그리고 몸의 자세 등을 포함한 동작을 예측하고, 이를 통해 모델은 음성에 따라 인간의 동작을 생성할 수 있으며, 이를 기반으로 비디오를 생성합니다. 이 네트워크는 트랜스포머 아키텍처를 기초로 하며, 음성 입력을 기반으로 표정, 자세, 시선 등과 같은 중요한 제어 변수를 추출하는 과정에서 중간 제어 표현을 생성하고, 이를 기반으로 움직임을 생성합니다.
- 2. 고화질 비디오 생성 단계: VLOGGER의 두 번째 네트워크는 생성된 움직임을 기반으로 입력 이미지를 애니메이션화합니다. 이 네트워크는 훈련 데이터의 확률 분포를 학습하고, 이 분포에서 샘플링하여 새로운 이미지를 생성하는 최신 생성 확산 모델을 기반으로 하며, 비디오에서 시간적인 관계를 모델링하기 위해 1차원 컨볼루션 레이어를 사용합니다. 모델은 입력 제어와 이전 프레임의 정보를 사용하여 새로운 프레임을 생성하고 시간에 따라 연속적으로 이미지를 생성합니다. 학습은 MENTOR 데이터셋과 같은 대규모 비디오 데이터셋에서 이루어지며, 생성된 이미지는 원하는 해상도로 업샘플링되어 슈퍼 해상도가 적용되어 더 높은 품질의 비디오로 확장될 수 있습니다.
비디오 생성순서
VLOGGER의 동작순서는 다음과 같습니다:
- 1. 입력 제어: 음성 또는 텍스트 입력을 모델에 제공하여 표정, 자세, 시선 등과 같은 중요한 제어 변수를 추출합니다.
- 2. 중간 제어 표현 생성: 입력 제어를 기반으로 중간 제어 표현을 생성합니다. 이는 얼굴 표현과 몸의 움직임을 포함하며, 각 프레임에 대한 변화를 예측하여 입력 이미지를 기준으로 해당 매개변수를 조정하여 애니메이션을 생성합니다.
- 3. 시간적 확산을 통한 이미지 생성: 중간 제어 표현과 입력 이미지를 기반으로 시간적 확산(Temporal diffusion) 모델을 사용하여 이미지를 생성합니다. 이 모델은 시간적인 변화를 고려하여 이미지를 동적으로 생성하고, 입력 이미지와 중간 제어 표현을 조합하여 원하는 결과물을 생성합니다.
- 4. 슈퍼 해상도 적용: 생성된 이미지에 슈퍼 해상도를 적용하여 원하는 해상도로 높은 품질의 이미지를 생성합니다.
- 5. 3D Motion 생성: 생성된 이미지를 기반으로 3D 모션을 생성합니다. 각 프레임에 대한 변화를 예측하고, 목표 주제의 이미지를 애니메이션화하기 위해 해당 매개변수를 조정합니다.
- 6. 애니메이션 생성: 생성된 3D 모션을 기반으로 입력 이미지를 애니메이션화합니다. 시간적인 변화를 고려하여 이미지를 동적으로 생성하고, 입력 이미지와 중간 제어 표현을 조합하여 실제 같은 애니메이션을 생성합니다.
- 7. 시간적 아웃페인팅: 이미지 생성 단계 이후에 시간적 아웃페인팅 기술을 적용하여 비디오의 길이를 확장합니다. 이를 통해 추가적인 프레임을 생성하여 원하는 비디오 길이를 얻습니다.
이러한 과정을 통해 VLOGGER는 입력 이미지를 기반으로 실제 같은 애니메이션을 생성합니다.
MENTOR 데이터셋
VLOGGER 연구를 위해 다양한 사람들의 다양한 특성과 표현을 담고 있는 대규모 비디오 데이터셋으로, VLOGGER 모델의 훈련과 성능 평가에 사용되었습니다. 주로 카메라에 얼굴이나 상반신이 비춰지는 형태의 비디오를 수집한 이 데이터셋은 VLOGGER가 다양한 인간 특성과 표현을 적절히 학습하고 다양성을 반영할 수 있도록 도와주었습니다. MENTOR 데이터셋은 다음과 같은 주요 특징을 가지고 있습니다.
- 비디오 길이: 각 비디오 클립은 10초 길이로, 240프레임으로 구성되어 있습니다.
- 음성 정보: 비디오에는 16kHz의 음성 정보가 포함되어 있습니다.
- 인체 모델링: 데이터셋은 3D 인체 모델을 기반으로 한 인체 모델링 결과를 포함합니다. 이를 통해 각 프레임에서 얼굴과 몸의 포즈, 제스처 등의 정보를 얻을 수 있습니다.
- 필터링: 데이터셋은 배경이 크게 변하는 비디오나 얼굴 또는 몸이 부분적으로 감지되거나 흔들리는 경우와 같이 품질이 낮은 영상을 필터링하여 제공합니다.
- 다양성: 데이터셋은 피부 톤, 나이, 시각 등의 다양한 속성을 가진 주체들의 다양한 영상을 포함하고 있습니다.
MENTOR 데이터셋은 영상 생성 및 인체 모델링과 같은 다양한 연구 분야에서 사용될 수 있으며, 연구자들에게 다양한 시나리오에서의 실험과 모델 평가에 활용할 수 있는 유용한 자료를 제공합니다.
 |
|
 |
|
| Input Image | Generated Video | Input Image | Generated Video |
 |
|
 |
|
| Input Image | Generated Video | Input Image | Generated Video |
성능평가 결과
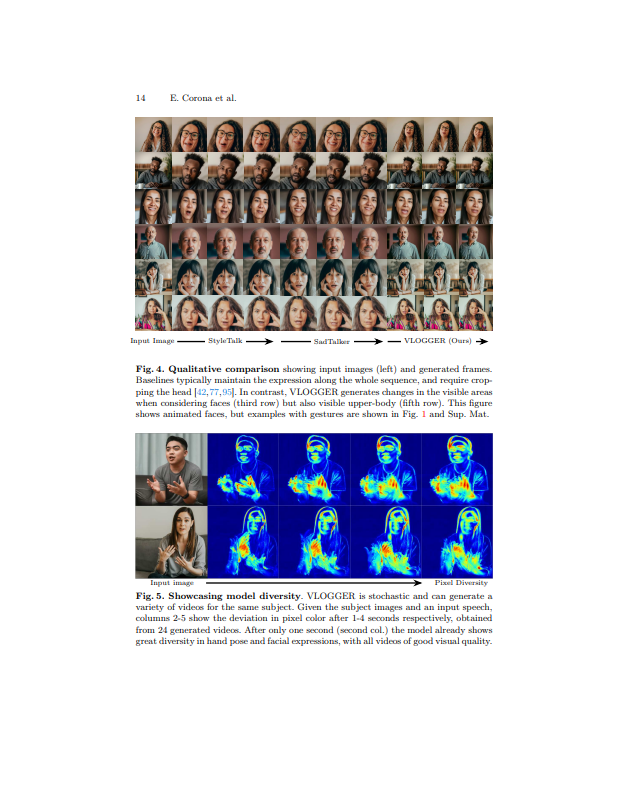
- 질적평가(Qualitative Evaluation): VLOGGER는 다른 기법과 비교하여 다양한 표현과 움직임을 잘 캡처하며, 참조 이미지에서 가려진 부분을 올바르게 보정할 수 있습니다. 예를 들어, 입력 이미지에 이빨이 입 안을 가리는 경우라도 우리 모델은 이를 올바르게 보정하여 생성된 비디오를 생성합니다. 또한, VLOGGER 모델은 다양한 표현을 생성하며, 주체의 머리카락, 시선, 몸의 움직임 등에 변화를 줄 수 있습니다. 이러한 결과는 모델이 실제 같은 애니메이션을 생성하는 데 효과적임을 보여줍니다.
- 양적평가(Quantitative Evaluation): FID(Fréchet Inception Distance) 점수와 LME(Landmark Error) 등을 포함한 다양한 지표를 사용하여 VLOGGER의 이미지 품질, 표현 다양성, 목소리 동기화 품질 및 시간적 일관성 등을 평가합니다. 결과적으로, VLOGGER는 우수한 시각적 품질과 신원 보존력을 보여주며, 표현 다양성 및 시간적 일관성은 실제 현실비디오와 거의 유사한 수준을 달성합니다. 입술 동기화 품질에 대해서는 다른 방법과 유사한 점수를 얻습니다.
DEMO 사이트
https://enriccorona.github.io/vlogger/
VLOGGER
We propose VLOGGER, a method for text and audio-driven talking human video generation from a single input image of a person, which builds on the success of recent generative diffusion models. Our method consists of 1) a stochastic human-to-3d-motion diffus
enriccorona.github.io
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문의 결론 및 전망
논문에서는 VLOGGER라는 새로운 모델을 소개하고, 이 모델이 음성 및 텍스트 입력을 기반으로 사실적인 애니메이션 비디오를 생성하는 능력을 증명하였습니다. 실험 결과는 VLOGGER가 기존 방법보다 더 높은 품질의 비디오를 생성한다는 것을 보여주었으며, 표현 다양성 및 시간적 일관성 면에서도 우수한 성과를 달성했습니다.
또한 개인화 및 비디오 편집과 같은 응용 분야에서도 뛰어난 성능을 보였습니다. 이러한 결과는 VLOGGER가 음성 기반 인체 애니메이션 생성 분야에서 새로운 지평을 열 수 있음을 시사하며, 미래에는 VLOGGER의 적용 범위를 확장하여 더 많은 응용 분야에서 활용할 수 있을 것으로 기대됩니다.
오늘 내용은 여기까지입니다. 저는 얼마 전 알리바바 그룹에서 발표한 오디오 기반 비디오 생성기술 EMO가 VLOGGER보다 감정표현이나 립싱크 부분이 더 정교하다는 느낌이 들었는데 여러분은 어떠신가요? 그럼 저는 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.02.28 - [AI 논문 분석] - [AI 논문] EMO: 사진 1장과 음성으로 되살린 오드리 헵번의 생생한 표정!
[AI 논문] EMO: 사진 1장과 음성으로 되살린 오드리 헵번의 생생한 표정!
안녕하세요! 오늘은 중국의 알리바바 그룹에서 발표한 오디오 기반 비디오 생성기술 "EMO: Emote Portrait Alive"에 대해 알아보겠습니다. EMO는 주어진 단일 캐릭터의 얼굴이미지를 바탕으로 음성 입력
fornewchallenge.tistory.com
'AI 논문 분석' 카테고리의 다른 글
| [AI 논문] InstantStyle: 같은 스타일을 가진 새로운 이미지 만들기 (0) | 2024.04.09 |
|---|---|
| 스테이블 디퓨전보다 28배 빠른 DMD 기술, 1장당 0.05초! (2) | 2024.03.29 |
| LATTE3D: 엔비디아의 새로운 텍스트 기반 3D 생성 기술 (0) | 2024.03.25 |
| MM1: 애플의 새로운 멀티모달 언어 모델 (0) | 2024.03.21 |
| [AI 논문] EMO: 사진 1장과 음성으로 되살린 오드리 헵번의 생생한 표정! (2) | 2024.02.28 |



