안녕하세요! 오늘은 구글 딥마인드에서 개발한 Mobility VLA 로봇시스템에 대해 알아보겠습니다. Mobility VLA는 멀티모달 지시 내비게이션을 위한 로봇 시스템으로, 텍스트, 이미지, 음성 등 다양한 형태의 입력을 이해하고 처리할 수 있으며, 실제 환경에서의 시연 투어를 통해 학습하며, 복잡한 내비게이션 작업을 수행할 수 있습니다. 예를 들어, 사용자가 "이것을 어디에 반납해야 하나요?"라고 묻고 플라스틱 통을 보여주면, 로봇은 해당 물건을 반납할 수 있는 선반으로 안내할 수 있습니다. 이 블로그에서는 Mobility VLA의 개요, 특징 및 주요 기능, 동작원리 등에 대해 알아보겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문 개요
Mobility VLA(Vision-Language-Action)는 Google DeepMind에서 개발한 혁신적인 로봇 내비게이션 시스템으로 사전에 녹화된 데모 투어 영상을 통해 환경 정보를 제공받고, 텍스트, 이미지, 음성 등의 멀티모달 명령어를 이해하고 내비게이션을 실행할 수 있는 지능형 에이전트를 구축하는 것을 목표로 합니다.
- 논문제목: Mobility VLA: Multimodal Instruction Navigation with Long-Context VLMs and Topological Graphs
- 논문저자: Hao-Tien Lewis Chiang 등, Google DeepMind
- 논문게재 사이트: https://arxiv.org/abs/2407.07775
- 논문게재일: 2024년 7월 10일
Mobility VLA란?
이 시스템은 최근 Vision Language Models(VLMs)의 발전에 힘입어 개발되었으며, 기존의 VLM은 멀티모달 입력을 인식하고 추론하는 능력을 보여주었지만, 내비게이션 작업에 직접 활용하기에는 한계가 있었으나, Mobility VLA는 이러한 VLM의 장점을 활용하면서도 한계를 극복하기 위해 '상위 수준정책'(high-level policy)과 '하위 수준 정책'(low-level policy)으로 구분되는 계층적 구조를 채택했습니다.
- 상위 수준 정책: 사람의 뇌와 비슷한 역할을 하며, 사용자의 명령(텍스트, 음성, 이미지 등)을 이해하고, 미리 녹화된 '데모 투어 비디오' 분석을 통해 로봇이 가야 할 최종 목적지를 결정합니다.
- 하위 수준 정책: 사람의 운동 신경과 비슷한 역할을 담당하여, 로봇이 이동할 수 있는 경로를 미리 정리해 놓은 '위상 그래프'라는 일종의 지도를 사용하여, 상위 정책이 정한 목적지로 가기 위한 구체적인 움직임을 계획합니다.
Mobility VLA의 작동 과정은 다음과 같습니다.
- 사용자가 명령을 내리면, 상위 정책이 이를 이해하고 목적지를 결정합니다.
- 그 다음 하위 정책이 위상 그래프를 참고하여 구체적인 이동 경로를 계획합니다.
- 로봇은 이 계획에 따라 한 걸음씩 움직이며 목적지로 향합니다.
이렇게 Mobility VLA는 인공지능의 이해력과 로봇의 정밀한 움직임을 결합하여, 복잡한 환경에서도 사용자의 명령을 정확히 수행할 수 있습니다. Mobility VLA는 836m² 규모의 실제 사무실 환경에서 평가되었으며, "이것을 어디에 반납해야 하나요?"와 같은 이전에는 해결하기 어려웠던 복잡한 추론이 필요한 멀티모달 명령어에 대해 높은 성공률을 보여주었습니다.

Mobility VLA 특징 및 주요 기능
Mobility VLA는 멀티모달 명령어를 처리하고 데모 투어를 활용하여 환경을 이해하며, 장문 맥락 VLM으로 복잡한 추론을 수행하고, 위상 그래프로 효율적인 내비게이션을 구현합니다. 유연한 목표 지정과 실시간 적응 능력을 갖추고 있으며, 개인화된 안내도 가능하고, 자연어와 이미지를 통한 복잡한 명령을 이해하고 실행할 수 있어, 다양한 환경에서 지능적으로 작동합니다.
Mobility VLA의 주요 특징과 기능은 다음과 같습니다.
- 멀티모달 명령어 처리: Mobility VLA는 자연어와 이미지를 동시에 포함하는 멀티모달 명령어를 이해하고 처리할 수 있습니다. 예를 들어, 사용자가 "이것을 어디에 반납해야 하나요?"라고 묻고 플라스틱 통을 들고 있는 이미지를 보여주면, 로봇은 해당 물건을 반납할 수 있는 선반으로 안내할 수 있습니다.
- 데모 투어 활용: 환경에 대한 사전 정보를 얻기 위해 데모 투어 비디오를 활용합니다. 이 접근 방식은 새로운 홈 로봇을 구입했을 때 집 안을 보여주는 것처럼 사용자가 로봇을 원격 조종하거나 스마트폰으로 영상을 녹화하는 것만으로도 충분하며, 필요한 경우 로봇의 이동 범위를 제한할 수 있습니다.
- 장문 맥락 VLM 활용: Mobility VLA는 10M(10,000,000개)의 긴 맥락을 처리할 수 있는 VLM을 사용하여 환경에 대한 깊이 있는 이해와 복잡한 추론을 가능하게 합니다. 이를 통해 단순한 객체 인식이나 위치 찾기를 넘어선 고급 추론 작업을 수행할 수 있습니다.
- 위상 그래프 기반 내비게이션: 하위 수준 정책은 데모 투어에서 생성된 위상 그래프를 사용하여 효율적이고 안정적인 경로 계획 및 실행을 수행하며, 이는 VLM의 출력을 실제 로봇 동작으로 변환하는 데 중요한 역할을 합니다.
- 유연한 목표 지정: 사용자는 구체적인 물체나 위치를 언급하지 않고도 복잡한 요구사항을 표현할 수 있습니다. 예를 들어, "공공장소에서 보이지 않는 곳에 물건을 보관하고 싶어요. 어디로 가야 할까요?"와 같은 추상적인 명령도 처리할 수 있습니다.
- 실시간 적응: Mobility VLA는 실시간으로 현재 환경을 인식하고 적응합니다. 이를 통해 데모 투어 이후 변경된 환경에서도 안정적으로 작동할 수 있습니다.
- 개인화 기능: 데모 투어 중 추가된 내레이션을 활용하여 개인화된 내비게이션을 제공할 수 있습니다. 예를 들어, 특정 사용자의 책상이나 임시 작업 공간을 구분하여 안내할 수 있습니다.

Mobility VLA 동작원리
Mobility VLA는 오프라인과 온라인 두 단계로 작동합니다. 오프라인에서는 데모 투어를 통해 환경 정보를 수집하고, 구조-모션 분석으로 3D 위치를 파악하여 위상 지도를 생성하며, 온라인에서는 사용자의 멀티모달 명령을 받아 장-문맥 VLM으로 목표를 찾고, 위상 지도를 이용해 경로를 계산합니다. 이를 통해 로봇은 복잡한 환경에서도 효율적으로 사용자 명령을 수행할 수 있습니다.
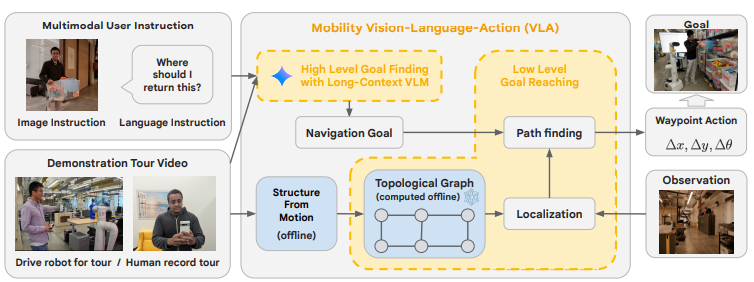
위 개념도에 나타낸 Mobility VLA 동작원리에 대한 설명은 다음과 같습니다.
1. 오프라인 단계: 환경 정보 구축 (이미지 하단)
- 데모 투어 (Drive robot for tour / Human record tour): 사용자가 로봇을 직접 조종하거나 스마트폰으로 영상을 촬영하여 환경 곳곳을 보여주는 데모 투어를 수행합니다.
- 구조-모션 (Structure from motion): 촬영된 데모 투어 영상에서 각 프레임의 3차원 위치 정보를 추출하여 공간 정보를 파악합니다.
- 위상 지도 생성 (Topological Graph): 추출된 공간 정보를 바탕으로 각 프레임의 연결 관계를 나타내는 위상 지도를 생성합니다. 각 프레임은 노드가 되고, 서로 가까운 프레임들은 연결되어 이동 가능한 경로를 나타냅니다.
2. 온라인 단계: 사용자 명령 수행 (이미지 상단)
- 멀티모달 사용자 명령 (Multimodal User Instruction): 사용자는 음성 ("Where should I return this?") 또는 이미지 (사용자가 가리키는 곳의 사진) 또는 둘 다를 사용하여 로봇에게 명령을 내립니다.
- 고수준 목표 찾기(High Level Goal Finding with Long-Context VLM): 장문 맥락 멀티모달 VLM을 사용하여 데모 투어 영상과 사용자 멀티모달 명령을 입력으로 받아 사용자의 의도를 파악하고, 환경에 대한 이해와 상식적 추론을 수행하여 위상 지도에서 목표 위치에 해당하는 프레임 (Goal frame)을 찾아냅니다.
- 저수준 목표 도달 (Low Level Goal Reaching): 로봇의 현재 위치 (Observation)와 목표 프레임 (Goal frame)을 위상 지도 상에서 찾습니다. 최단 경로 알고리즘 (Path finding)을 사용하여 현재 위치에서 목표 프레임까지의 경로를 계산합니다. 계산된 경로를 따라 로봇에게 이동 명령 (Waypoint Action)을 전달합니다.
- 실시간 적응: 로봇은 지속적으로 현재 환경을 관찰하고 위치를 추정하며, 필요에 따라 경로를 조정합니다. 이를 통해 동적 환경이나 예기치 못한 장애물에 대응할 수 있습니다.
- 목표 도달 확인: 로봇이 목표 프레임에 도달했는지 지속적으로 확인하며, 도달 시 내비게이션을 종료합니다.
이러한 계층적 접근 방식을 통해 Mobility VLA는 VLM의 높은 수준의 이해 능력과 로봇 제어를 위한 정밀한 동작 생성을 효과적으로 결합합니다.
논문의 결론
논문의 저자들은 Mobility VLA를 통해 다음과 같은 주요 결론을 도출했습니다:
- 멀티모달 명령어 내비게이션 작업: Mobility VLA는 이전에는 해결하기 어려웠던 복잡한 추론이 필요한 멀티모달 명령어에 대해 높은 성공률을 보여주었으며, 실제 836m² 규모의 사무실 환경에서 진행된 실험에서 Reasoning-Free, Reasoning-Required, Multimodal 카테고리의 작업에서 86-90%의 성공률을 달성했습니다.
- 장문 맥락 VLM의 중요성: 긴 맥락을 처리할 수 있는 VLM의 사용이 성능 향상에 크게 기여했습니다. 이는 환경에 대한 더 깊은 이해와 복잡한 추론을 가능하게 했습니다.
- 위상 그래프의 효과: VLM의 출력을 로봇 동작으로 변환하는 데 있어 위상 그래프 기반의 접근 방식이 효과적이었습니다. 이는 VLM만으로는 해결하기 어려운 실제 로봇 제어의 어려움을 해결하는데 중요한 역할을 했습니다.
- 실세계 적용 가능성: Mobility VLA는 실제 환경에서 높은 성공률을 보여주었으며, 환경 변화에도 강건한 성능을 유지했습니다. 이는 실제 응용 가능성이 높음을 시사합니다.
- 사용자 경험 개선: 멀티모달 명령어 처리 능력과 데모 투어 활용을 통해 사용자와 로봇 간의 상호작용을 더욱 자연스럽고 직관적으로 만들었습니다.
- 한계점 인식: 작은 물체 카테고리에서는 상대적으로 낮은 성공률을 보였는데, 이는 투어 비디오의 해상도 한계 때문인 것으로 분석되었습니다. 이는 향후 개선이 필요한 부분으로 지적되었습니다.
- 미래 연구 방향: 저자들은 이 연구가 로봇 내비게이션 분야에서 새로운 패러다임을 제시했으며, 향후 더 복잡한 환경과 작업에 대한 연구가 필요함을 강조했습니다.
맺음말
오늘은 Google DeepMind에서 개발한 Mobility VLA 로봇 시스템에 대해 살펴보았습니다. 이 혁신적인 시스템은 텍스트, 이미지, 음성 등 다양한 형태의 입력을 이해하고 처리할 수 있는 능력을 갖추고 있어 복잡한 내비게이션 작업을 수행하는 데 탁월한 성능을 보여주며, 데모 투어를 통해 환경을 학습하여, 실제 사무실 환경에서 높은 성공률을 기록했습니다.
상위 수준 정책과 하위 수준 정책으로 나누어진 계층적 구조를 채택하여, 고급 추론 능력과 정밀한 이동을 결합함으로써, 단순히 지정된 위치로 이동하는 것을 넘어, 사용자의 복잡하고 때로는 모호한 요구사항을 이해하고 실행할 수 있는 로봇 내비게이션 분야에 새로운 패러다임을 제시하며, 향후 더욱 복잡한 환경과 작업에 대한 연구 가능성을 열어줍니다.
인공지능과 로보틱스 분야의 융합이 가져올 수 있는 혁신적인 결과를 보여주는 이 기술이 앞으로 우리 일상생활에 어떻게 적용될지 기대해 보면서, 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다!

2024.01.08 - [AI 논문 분석] - Mobile ALOHA: 저렴한 전신 원격운전 양손 조작 학습 로봇
Mobile ALOHA: 저렴한 전신 원격운전 양손 조작 학습 로봇
안녕하세요! 오늘은 저렴한 비용으로 전신(Whole-Body) 원격운전을 통해 인간의 복잡한 동작을 학습하여 스스로 양손 조작이 가능한 움직이는 로봇, Mobile ALOHA를 만나보겠습니다. 가사, 요리, 인간-
fornewchallenge.tistory.com
'AI 논문 분석' 카테고리의 다른 글
| [AI 논문] AutoCoder: GPT-4o를 능가한 코드 생성 대형 언어 모델 (0) | 2024.05.28 |
|---|---|
| 알파폴드 3, 생명의 신비를 밝히다! 단백질, DNA, RNA까지 예측하는 혁신 인공지능 (1) | 2024.05.11 |
| [AI 논문] InstantStyle: 같은 스타일을 가진 새로운 이미지 만들기 (0) | 2024.04.09 |
| 스테이블 디퓨전보다 28배 빠른 DMD 기술, 1장당 0.05초! (2) | 2024.03.29 |
| 구글 VLOGGER: 이미지 1장과 음성으로 움직이는 아바타를 만드는 방법 (0) | 2024.03.27 |



