안녕하세요! 오늘은 구글의 최신 언어 모델 Gemma 2에 대해서 알아보겠습니다. Gemma 2는 2B, 9B, 27B 매개변수 모델을 제공하며, 최신 기술인 로컬-글로벌 어텐션 교차와 그룹 쿼리 어텐션을 도입했습니다. 지식 증류 기법을 적용해 작은 모델의 성능을 높였고, 동급 모델들을 능가하는 성능을 보이며, 오픈 소스로 공개되어 누구나 사용하고 연구할 수 있어 AI 기술의 접근성을 향상시켰습니다. 이 블로그에서는 Gemma 2의 개요, 로컬-글로벌 어텐션 교차와 그룹 쿼리 어텐션, 지식 증류에 대해 알아보고, 추론/코딩성능 테스트 및 Ollama를 이용한 Gemma 2 챗봇을 만들어 보겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Gemma 2 개요 및 특징
Gemma 2는 기존 Gemma 모델군의 새로운 버전으로, 경량화되면서도 최첨단 성능을 갖춘 오픈 소스 언어 모델입니다. 이번 버전에서는 2억에서 270억 개의 매개변수를 가진 다양한 크기의 모델을 선보이고 있습니다. Gemma 2의 주요 특징은 다음과 같습니다:
- 다양한 모델 크기: 2B(20억), 9B(90억), 27B(270억) 매개변수 모델을 제공하여 다양한 용도와 컴퓨팅 환경에 맞춰 선택할 수 있습니다.
- 아키텍처 개선: 어텐션 메커니즘으로 로컬-글로벌 어텐션 교차(interleaving local-global attentions)와 그룹 쿼리 어텐션(group-query attention) 등 최신 기술을 도입했습니다. 어텐션 메커니즘에 대한 설명은 더 보기를 클릭하세요
어텐션 메커니즘(Attention Mechanism)은 인공지능과 자연어 처리 분야에서 사용되는 기술로, 모델이 입력 데이터의 중요한 부분에 집중할 수 있게 하는 방법입니다. 이 기술은 특히 시퀀스 데이터(예: 텍스트, 음성, 비디오) 작업에서 큰 성과를 거두고 있으며, 다음과 같은 주요 목적을 가지고 있습니다:
1. 중요한 정보에 집중: 입력 시퀀스의 모든 요소를 동일하게 처리하는 대신, 모델이 특정 요소에 더 집중할 수 있도록 합니다. 이를 통해 모델은 중요한 정보에 더 큰 가중치를 부여하고, 덜 중요한 정보는 무시할 수 있습니다.
2. 긴 종속성 캡처: 전통적인 RNN(Recurrent Neural Networks)과 같은 모델은 시퀀스의 긴 종속성을 캡처하는 데 어려움이 있지만, 어텐션 메커니즘은 이를 극복할 수 있도록 돕습니다.
어텐션 메커니즘의 주요 구성 요소는 다음과 같습니다.
1. 쿼리(Query): 모델이 입력 시퀀스의 각 위치에서 집중해야 할 정보를 나타내는 벡터입니다.
2. 키(Key): 입력 시퀀스의 각 요소를 나타내는 벡터로, 쿼리와 비교하여 해당 요소가 얼마나 중요한지 평가합니다.
3. 밸류(Value): 입력 시퀀스의 실제 정보로, 최종 어텐션 가중치를 통해 가중합을 계산합니다.
어텐션 메커니즘에는 여러 종류가 있으며, 그중 가장 많이 사용되는 것은 다음과 같습니다:
1. 셀프 어텐션(Self-Attention): 입력 시퀀스의 각 요소가 다른 모든 요소와 어텐션을 계산하는 방식입니다. Transformer 모델에서 주로 사용됩니다.
2. 로컬 어텐션(Local Attention): 특정 범위 내에서만 어텐션을 계산하여 효율성을 높이는 방법입니다.
3. 글로벌 어텐션(Global Attention): 시퀀스 전체에 대해 어텐션을 계산하는 방법으로, 모든 요소 간의 상호작용을 고려합니다.
어텐션 메커니즘은 다양한 AI 응용 분야에서 큰 성공을 거두었습니다. 그 예로는 다음과 같습니다:
- 자연어 처리(NLP): 기계 번역, 텍스트 요약, 질의응답 시스템 등에서 어텐션 메커니즘이 활용됩니다.
- 이미지 처리: 이미지 캡셔닝, 객체 검출 등에서도 어텐션 메커니즘이 사용됩니다.
- 음성 인식: 음성에서 중요한 부분을 강조하여 인식 성능을 높입니다.
어텐션 메커니즘은 복잡한 시퀀스 데이터의 중요한 부분에 집중함으로써 모델의 성능을 극대화하고, 다양한 AI 분야에서 혁신적인 성과를 이끌어내는 핵심 기술 중 하나입니다.
- 지식 증류 적용: 2B와 9B 모델은 다음 토큰 예측 대신 지식 증류(knowledge distillation) 방식으로 학습되었습니다.
- 높은 성능: 동일한 크기의 다른 오픈 소스 모델들을 능가하는 성능을 보이며, 심지어 2-3배 더 큰 모델들과도 경쟁력 있는 성능을 나타냅니다.
- 오픈 소스: 모든 모델은 커뮤니티에 공개되어 누구나 사용하고 연구할 수 있습니다.
로컬-글로벌 어텐션 교차
로컬-글로벌 어텐션 교차 (Interleaving Local-Global Attentions)는 텍스트, 음성, 비디오 등 긴 시퀀스의 데이터를 처리할 때, 근거리와 원거리 종속성을 모두 포착하기 위해 로컬 어텐션과 글로벌 어텐션을 번갈아가며 적용하는 방식으로, 효율성을 높이기 위한 전략으로도 사용됩니다
- 로컬 어텐션 (Local Attentions): 각 토큰이 자신의 주변 일정 범위 내의 토큰들에만 주목합니다. 계산 효율성이 높고 근접 문맥을 잘 포착합니다.
- 글로벌 어텐션 (Global Attentions): 각 토큰이 전체 시퀀스의 모든 토큰에 주목합니다. 장거리 의존성을 포착하는 데 유용하지만 계산 비용이 높습니다.
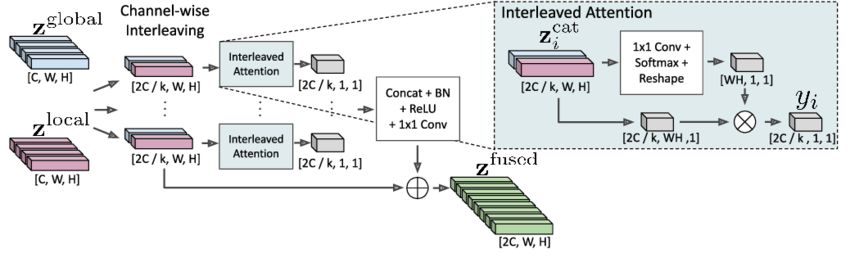
위 로컬-글로벌 어텐션 교차 구성도는 다음과 같은 방식으로 동작합니다:
- 1. 입력 특성 맵 분리: 입력 데이터가 두 부분으로 나뉩니다. z_global은 글로벌 컨텍스트 정보를, z_local은 로컬 컨텍스트 정보를 나타냅니다.
- 2. 채널 별 교차: 각 채널을 교차(interleaving)하여 결합된 특성 맵을 만듭니다. 이는 두 가지 종류의 정보를 혼합하여 풍부한 표현을 생성합니다.
- 3. 교차 어텐션: 교차된 각 채널에 대해 교차 어텐션 (Interleaved Attention)이 적용됩니다. 이 단계에서는 각 채널의 중요도를 평가하고, 중요한 정보에 가중치를 부여합니다.
- 4. 정규화 및 결합: 생성된 특성 맵은 정규화(Batch Normalization), ReLU 활성화 함수, 그리고 1x1 컨볼루션을 통해 결합되어 최종 출력 z_fused를 생성합니다. ReLU 활성화 함수에 대한 설명은 더 보기를 클릭하세요.
ReLU(정류된 선형 단위, Rectified Linear Unit) 활성화 함수는 신경망에서 널리 사용되는 함수로, 입력값이 양수일 경우 그대로 출력하고 음수일 경우 0을 출력합니다. 수식으로는 다음과 같습니다:
𝑓 ( 𝑥 ) = max ( 0 , 𝑥 ) f(x)=max(0,x)
주요 특징:
- 계산이 간단: 비선형성을 도입하면서도 계산이 간단합니다.
- 기울기 소실 문제 완화: 다른 활성화 함수들에 비해 기울기 소실 문제를 줄입니다.
- 효율적인 학습: 학습 속도를 빠르게 하고 깊은 신경망에서 효과적으로 작동합니다.
ReLU는 이러한 장점들 때문에 많은 딥러닝 모델에서 기본 활성화 함수로 사용됩니다.
- 5. 출력: 최종적으로, 이러한 과정을 통해 얻어진 z_fused는 로컬 및 글로벌 정보를 모두 반영한 특성 맵으로, 다양한 작업에 사용될 수 있습니다.
이러한 방식으로, Interleaving Local-Global Attentions는 입력 데이터의 로컬 및 글로벌 컨텍스트를 모두 효과적으로 활용하여 모델의 성능을 향상시킵니다. 이 방식의 장점은 계산 효율성과 장거리 의존성 포착 능력의 균형을 잡아줌으로써, 모델이 다양한 범위의 문맥을 효과적으로 처리할 수 있게 합니다.
그룹 쿼리 어텐션
그룹 쿼리 어텐션 (Group-query Attention) : 이 기법은 전통적인 어텐션 메커니즘에서 쿼리의 수가 많을 때 계산 복잡도가 크게 증가하는 문제를 해결하기 위해 여러 개의 쿼리를 그룹화하여 어텐션을 계산하는 방식으로 동작과정은 다음과 같습니다.
- 1. 쿼리들을 여러 그룹으로 나눕니다.
- 2. 각 그룹 내의 쿼리들이 동일한 키-값 쌍을 공유합니다.
- 3. 그룹별로 어텐션 점수를 계산합니다.
- 4. 각 쿼리는 자신이 속한 그룹의 어텐션 결과를 사용합니다.
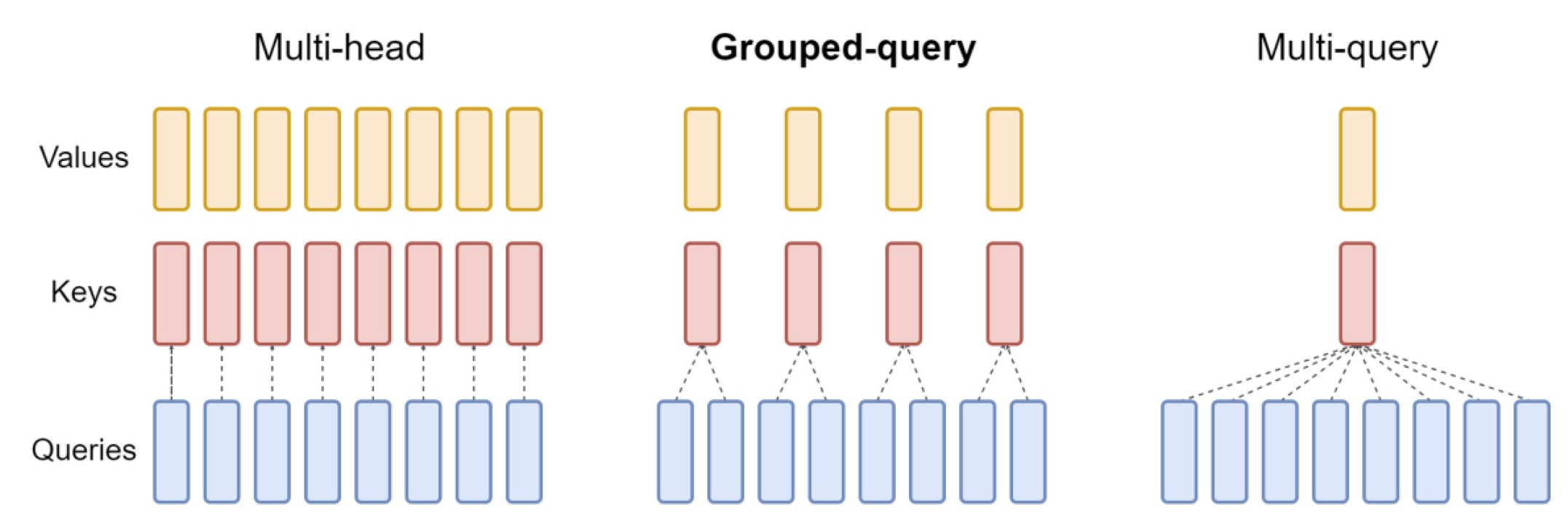
| 특성 | Multi-head Attention | Grouped-query Attention | Multi-query Attention |
| 쿼리 구조 | 각 쿼리마다 독립적인 헤드 | 쿼리들이 그룹으로 나뉨 | 모든 쿼리가 단일 헤드 공유 |
| 키/값 헤드 | 각 쿼리마다 고유한 키/값 헤드 | 각 그룹이 하나의 키/값 헤드 공유 | 단일 키/값 헤드를 모든 쿼리가 공유 |
| 유연성 | 가장 높음 | 중간 | 가장 낮음 |
| 계산 효율성 | 가장 낮음 | 중간 | 가장 높음 |
| 파라미터 수 | 가장 많음 | 중간 | 가장 적음 |
| 표현력 | 가장 높음 | 중간 | 가장 낮음 |
| 최적화 가능성 | 제한적 | 그룹 수 조절 가능 | 제한적 |
| 사용 사례 | 높은 성능이 필요한 경우 | 성능과 효율성 균형이 필요한 경우 | 계산 효율성이 중요한 경우 |
이 방식의 장점은 중복 계산을 줄여 메모리 사용량과 연산량을 감소시키고, 같은 그룹 내 쿼리들이 정보를 공유하여 더 풍부한 표현을 학습할 수 있으며, 파라미터 수를 크게 늘리지 않고도 모델의 표현력을 높일 수 있습니다.
Gemma 2는 위 두 가지 기법을 결합함으로써 효율적인 계산과 강력한 문맥 이해 능력을 동시에 달성할 수 있었습니다. 이는 작은 모델 크기로도 높은 성능을 달성하는 데 크게 기여했습니다.
지식 증류
지식 증류(Knowledge Distillation)는 머신 러닝과 딥러닝 모델을 효율적으로 압축하는 기술 중 하나로, 큰 모델(교사 모델, Teacher Model)로부터 작은 모델(학생 모델, Student Model)이 학습하도록 하는 방법입니다. 이 과정에서 작은 모델은 큰 모델의 예측을 모방함으로써 높은 성능을 유지하면서도 더 적은 계산 자원을 사용하도록 합니다.
지식 증류의 목적은 다음과 같습니다.
- 모델 압축: 큰 모델의 성능을 유지하면서도 더 작은 모델로 압축하여 효율성을 높입니다.
- 배포 용이성: 작은 모델은 리소스가 제한된 환경(예: 모바일 기기, 임베디드 시스템)에서 실행하기에 더 적합합니다.
- 추론 속도 향상: 작은 모델은 추론 속도가 더 빠르기 때문에 실시간 응용 프로그램에서 유리합니다.
지식 증류는 다음과 같은 단계로 이루어집니다:
1. 교사 모델 훈련: 먼저, 대규모 데이터셋을 사용하여 높은 성능을 가진 큰 모델(교사 모델)을 훈련시킵니다.
2. 학생 모델 초기화: 작은 모델(학생 모델)을 초기화합니다. 이 모델은 교사 모델보다 적은 매개변수를 가지고 있습니다.
3. 지식 전이: 교사 모델의 출력(로짓, logits)과 학생 모델의 출력 간의 차이를 최소화하는 방식으로 학생 모델을 훈련시킵니다. 이를 위해 일반적으로 다음 두 가지 손실 함수를 사용합니다:
- 소프트 타겟 손실(Soft Target Loss): 교사 모델의 소프트맥스 출력을 학생 모델이 모방하도록 합니다. 이때 온도 파라미터(Temperature Parameter) T 를 사용하여 소프트맥스 출력을 부드럽게 만듭니다.
- 하드 타겟 손실(Hard Target Loss): 원래의 라벨(정답)을 사용하여 학생 모델을 훈련시킵니다. 이는 일반적인 크로스 엔트로피 손실을 사용합니다.
지식 증류에서 중요한 개념 중 하나는 소프트맥스 함수와 온도 파라미터 T 입니다. 소프트맥스 함수는 교사 모델의 출력 로짓을 확률로 변환하는 함수입니다. 온도 파라미터를 도입하면 소프트맥스 출력이 더 부드럽게 되어, 교사 모델의 출력 분포를 학생 모델이 더 잘 모방할 수 있게 됩니다. 지식 증류의 이점은 다음과 같습니다.
- 효율성: 작은 모델이 큰 모델의 성능을 모방함으로써 더 적은 계산 자원으로 높은 성능을 유지합니다.
- 범용성: 다양한 모델 구조에 적용 가능하며, 특정 도메인에 종속되지 않습니다.
- 성능 향상: 종종 학생 모델이 원래의 작은 모델보다 더 나은 성능을 보일 수 있습니다. 이는 교사 모델이 더 많은 정보(단순한 정답뿐 아니라 각 클래스에 대한 확률 분포를 제공)를 제공하기 때문입니다.
지식 증류는 머신 러닝 및 딥러닝 모델을 보다 효율적으로 만들기 위한 강력한 기술로, 모델의 성능을 유지하면서도 계산 자원을 절약할 수 있는 방법을 제공합니다. 이를 통해 모바일 및 임베디드 시스템, 실시간 응용 프로그램, 모델 압축 및 최적화 등 다양한 응용 분야에서 AI 모델을 보다 효과적으로 사용할 수 있게 됩니다.
Gemma 2 주요 성능
Gemma 2 모델들은 다양한 벤치마크와 평가에서 동일한 규모의 다른 오픈 소스 모델들을 능가하는 성능을 보여주며, 일부 영역에서는 2-3배 큰 모델들과도 경쟁력 있는 결과를 나타냈습니다.
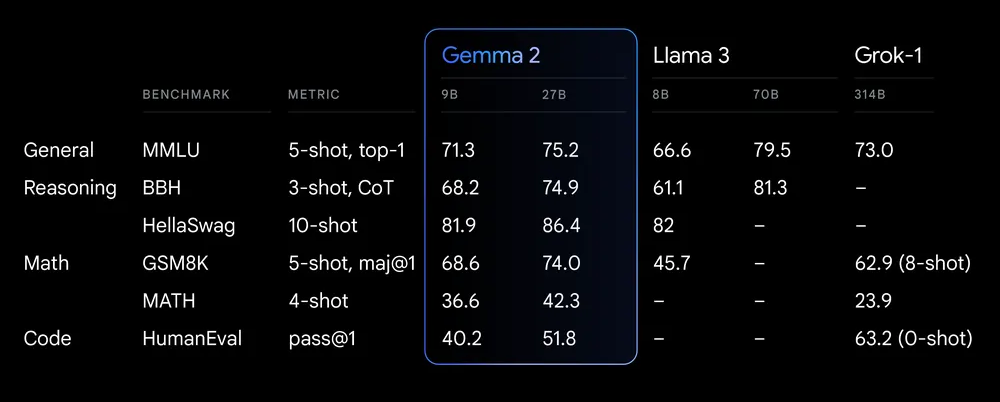
위 표에서 Gemma 2는 9B와 27B 두 가지 크기의 모델로 평가되었습니다. 전반적으로 우수한 성능을 보여주고 있으며, 27B 모델이 특히 몇 가지 영역에서 강점을 보입니다:
- 일반 언어 이해(MMLU): 75.2점으로 높은 점수를 기록했습니다.
- 추론 능력: BBH에서 74.9점, HellaSwag에서는 86.4점으로 매우 우수한 성과를 보였습니다.
- 수학 능력: GSM8K에서 74.0점, MATH에서 42.3점으로 준수한 성적을 냈습니다.
- 코딩: HumanEval에서 51.8점을 받아 coding 능력도 갖추고 있음을 보여줍니다.
Gemma 2는 대부분의 테스트에서 9B 모델보다 27B 모델이 더 나은 성능을 보여, 모델 크기가 성능 향상에 기여함을 알 수 있습니다. 일부 영역에서는 경쟁 모델들보다 낮은 점수를 받았지만, 전반적으로 균형 잡힌 성능을 보여주고 있습니다. 특히 HellaSwag 테스트에서 86.4점으로 매우 높은 점수를 받아, 문맥 이해와 상식적 추론 능력이 뛰어남을 입증했습니다.
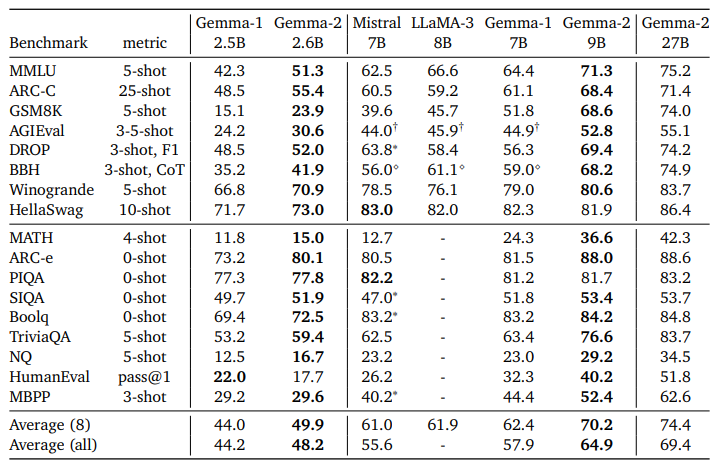
위 벤치마크 결과에서 보듯이 Gemma 2 2.6B, 9B, 27B 모델은 MMLU(언어이해), ARC-C(과학 질문), GSM8K(수학 문제) 등에서 높은 점수를 기록하며, 모델 크기가 클수록 성능이 향상되는 경향을 보이고, 27B 모델은 대부분의 벤치마크에서 우수한 결과를 나타내며, 경쟁 모델들과 비교하여 전반적으로 높은 성능을 유지하고 있습니다.
Gemma 2는 아키텍처 개선, 지식 증류, 대규모 데이터 활용으로 성능이 향상되었습니다. 로컬-글로벌 어텐션과 GQA를 도입해 긴 문맥 처리와 추론 속도를 개선했고, 큰 모델의 지식을 작은 모델로 효과적으로 전달했습니다. 또한 방대한 학습 데이터로 이해도를 높이고, Google TPU를 활용한 분산 학습으로 효율성을 극대화했습니다.
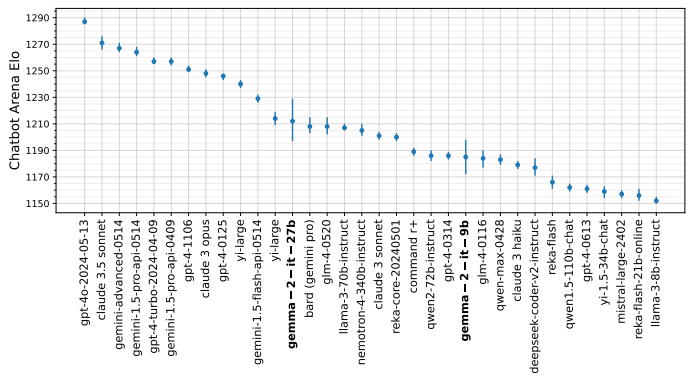
Gemma 2 모델은 Chatbot Arena에서 평가된 여러 버전 중 27B 모델이 가장 높은 성능을 보입니다. 'gemma-2-7b-it'와 'gemma-2-7b'가 약 1230 Elo 점수로 상위권에 위치하고 있으며, 다른 모델들에 비해 넓은 신뢰구간을 보이고 있습니다. 현재 평가가 진행 중이며, 더 많은 데이터가 쌓이면 순위나 신뢰구간이 변할 수 있습니다. 전반적으로 Gemma 2 모델들은 준수한 성능을 보여주고 있습니다.
추론 및 코딩 테스트
다음은 Gemma 2 모델에 대한 추론 및 코딩 테스트입니다. 테스트는 구글 AI 스튜디오에서 진행하였으며, 테스트 모델은 gemma 2-27b-it입니다.
코딩테스트는 스네이크 게임 작성과 edabit.com 코딩 교육 사이트의 파이썬, 자바 스크립트 시험문제로 테스트하였으며, 난이도 단계별로 1문제당 2회 시도하고, 첫 번째 시도에서 성공하면 테스트를 종료하고, 두 번째 시도까지 실패하면 최종실패로 처리하였습니다.(*는 두 번째 시도 성공)
1. 추론성능 테스트
| 추론 문제 |
결과 |
||
| Claude 3.5 Sonnet | Gemma2 | ||
| 5장의 셔츠를 햇빛에 건조하는데 4시간이 걸린다고 해보자. 그렇다면 20장의 셔츠를 건조하는 데는 얼마나 걸릴까요? 각 단계를 차근차근 설명해 주세요. 여러 셔츠를 동시에 건조할 수 있습니다. 정답: 4시간 | Pass | Pass | |
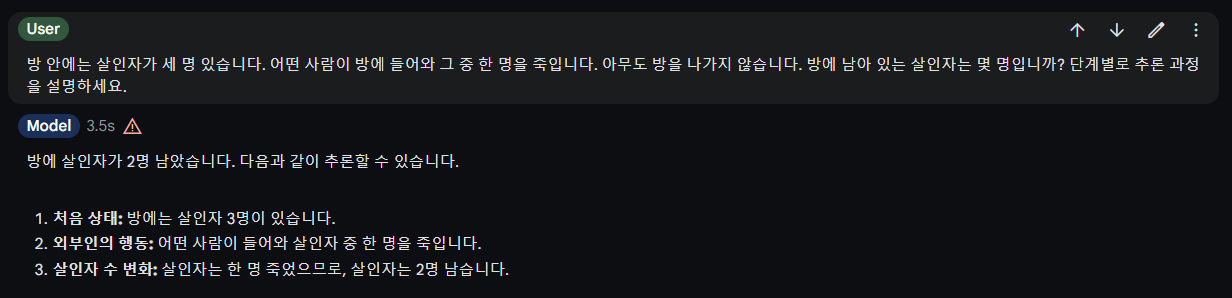
| 방 안에는 살인자가 세 명 있습니다. 어떤 사람이 방에 들어와 그 중 한 명을 죽입니다. 아무도 방을 나가지 않습니다. 방에 남아 있는 살인자는 몇 명입니까? 단계별로 추론 과정을 설명하세요. 정답 : 3명 | Pass | Fail | |
| 베티는 새 지갑을 위해 돈을 모으고 있습니다. 새 지갑의 가격은 $100입니다. 베티는 필요한 돈의 절반만 가지고 있습니다. 그녀의 부모는 그 목적을 위해 $15를 주기로 결정했고, 할아버지와 할머니는 그녀의 부모들의 두 배를 줍니다. 베티가 지갑을 사기 위해 더 얼마나 많은 돈이 필요한가요? 정답 : 5$ | Pass | Pass | |
| 제인이 조 보다 빠르고, 조가 샘보다 빠르다. 그렇다면 샘은 제인보다 빠른가요? 각 단계를 차근차근 설명해 주세요. 정답 : 빠르지 않다. | Pass | Pass | |
살인자 문제 추론테스트에서 Gemma 2 모델은 방에 들어와서 살인한 새로운 살인자를 살인자수에 포함하지 않았습니다.



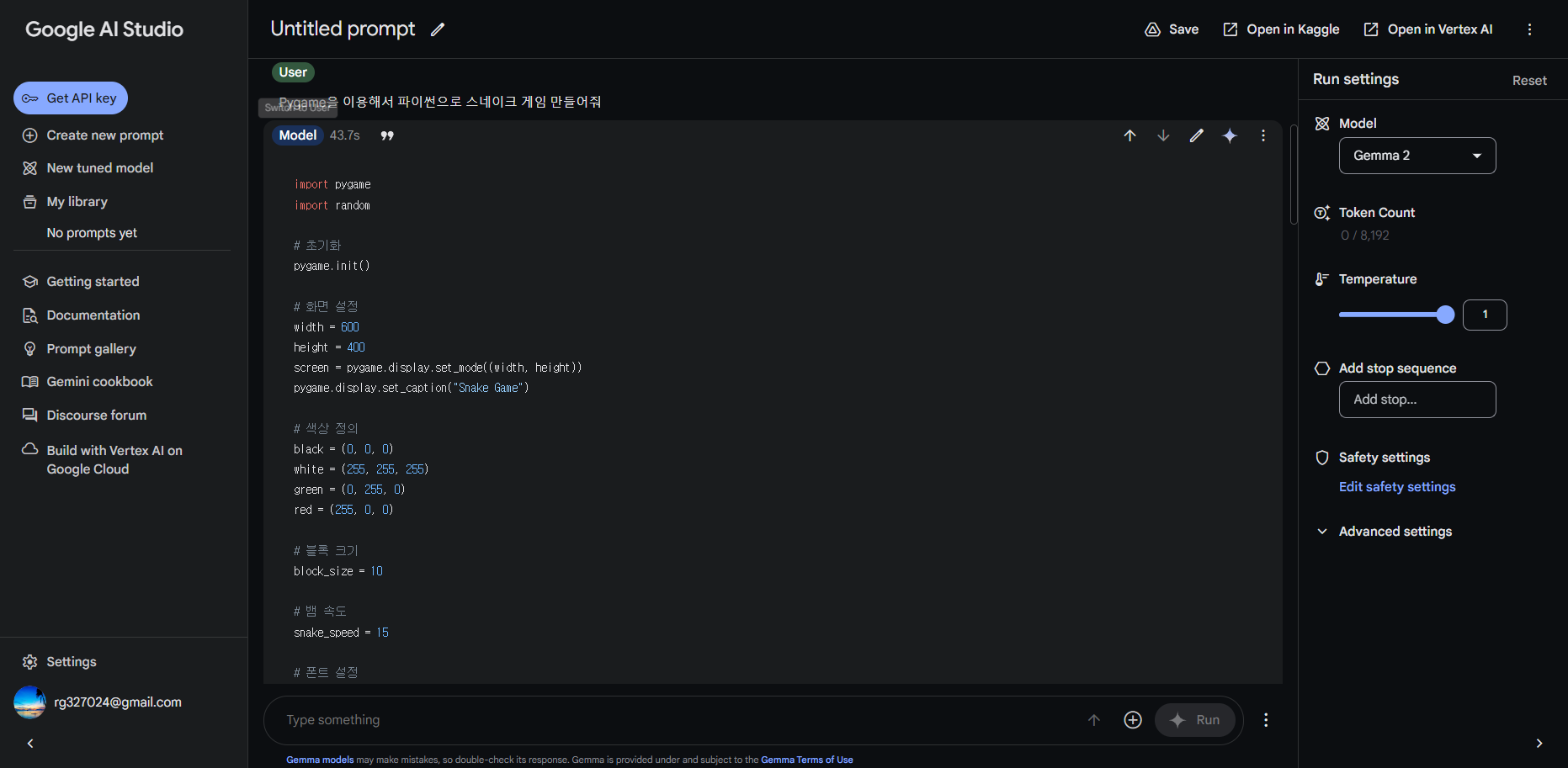
다음은 Gemma 2의 코딩 성능 테스트 결과입니다. "Pygame을 이용해서 파이썬으로 스네이크 게임 만들어줘"라고 요청하였는데, 아래 화면과 같이 첫 번째 시도에서 성공하였습니다.
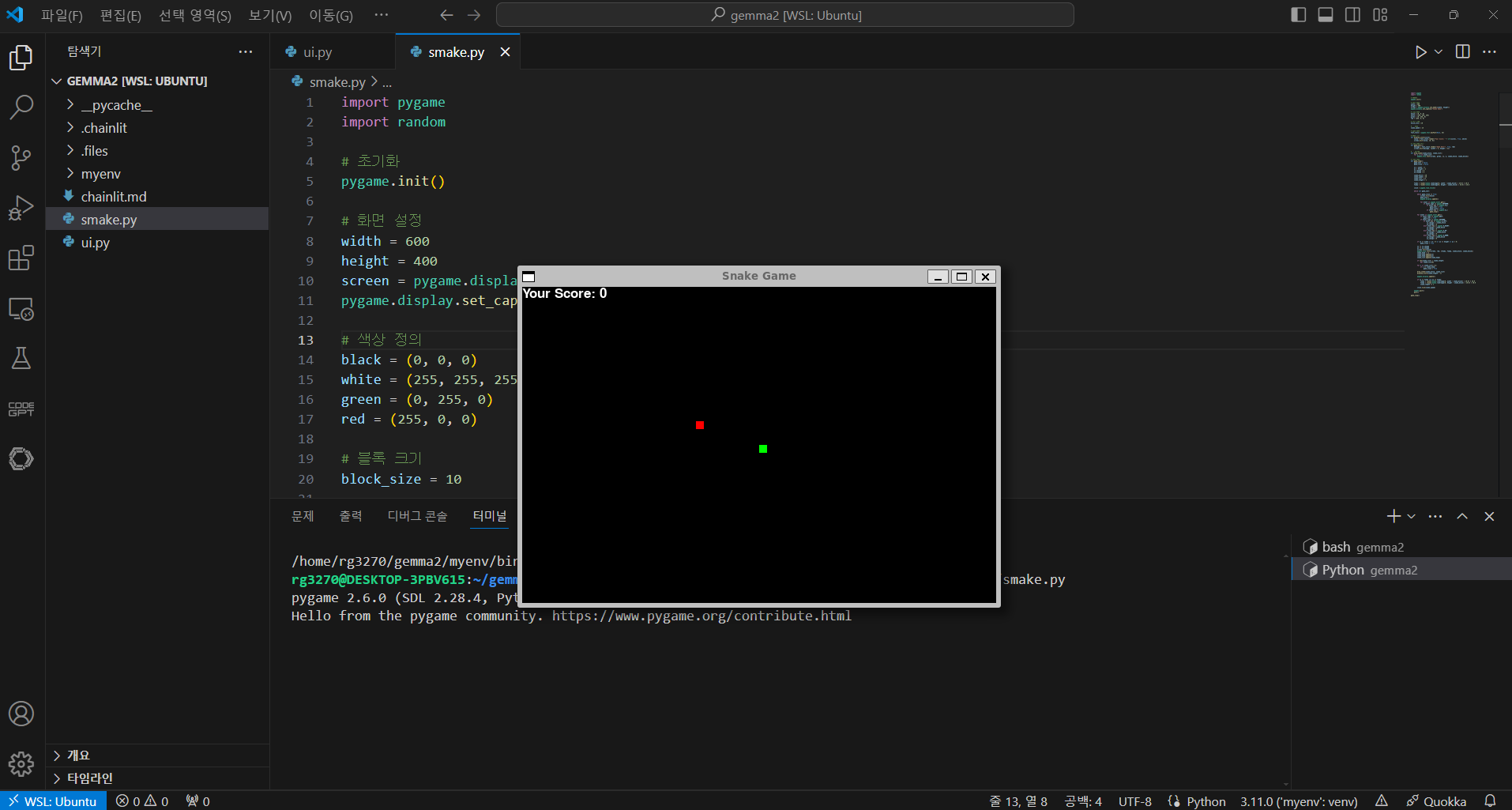
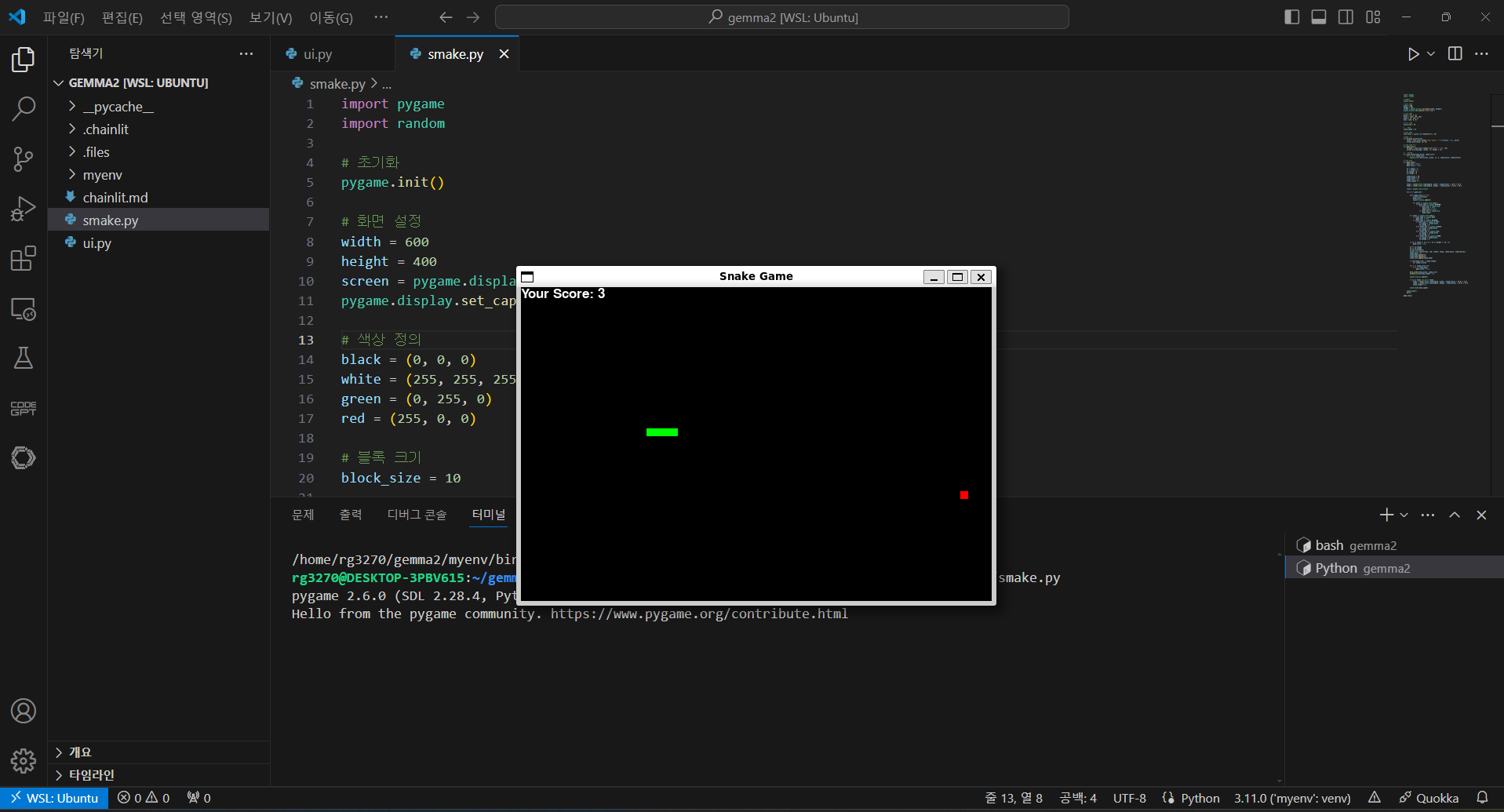
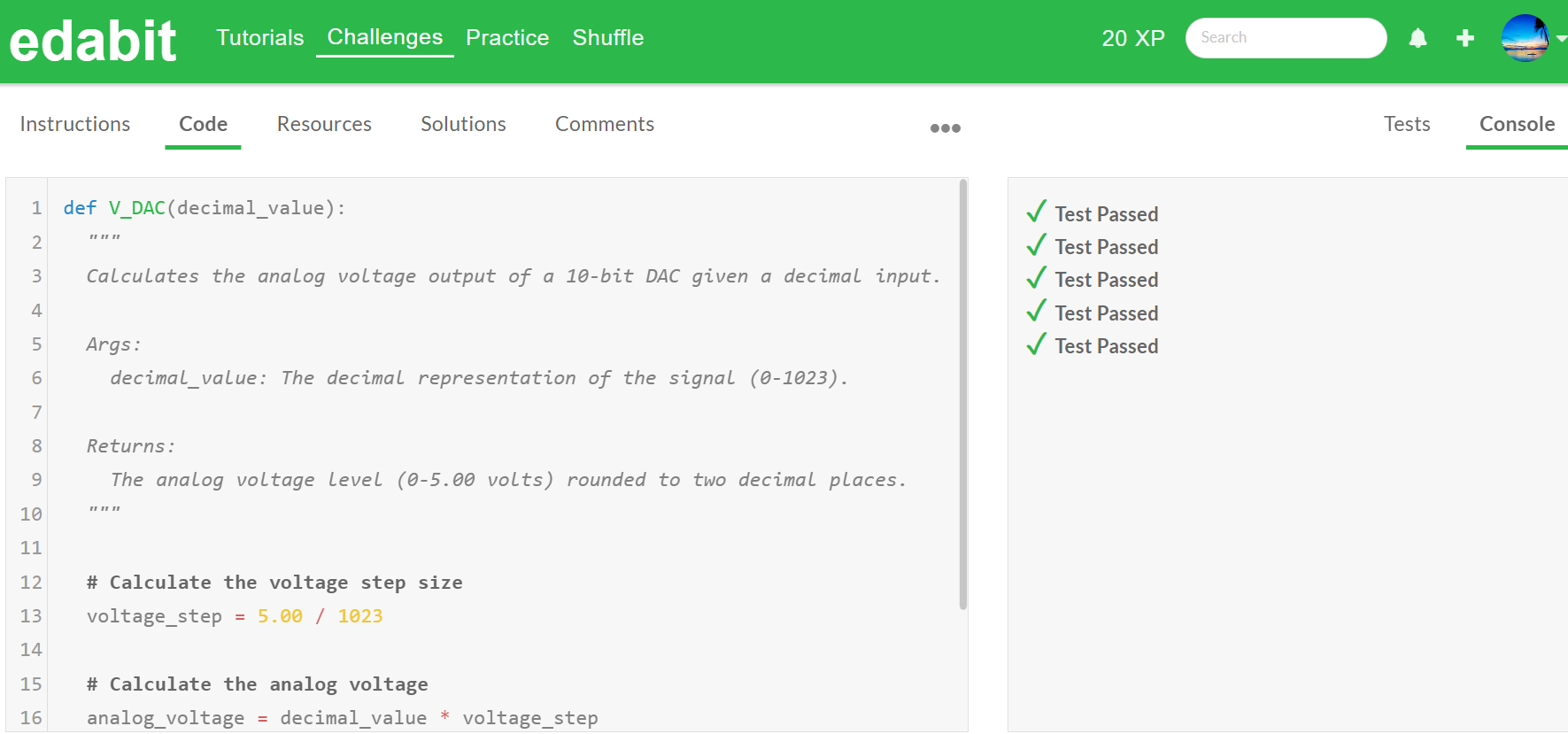
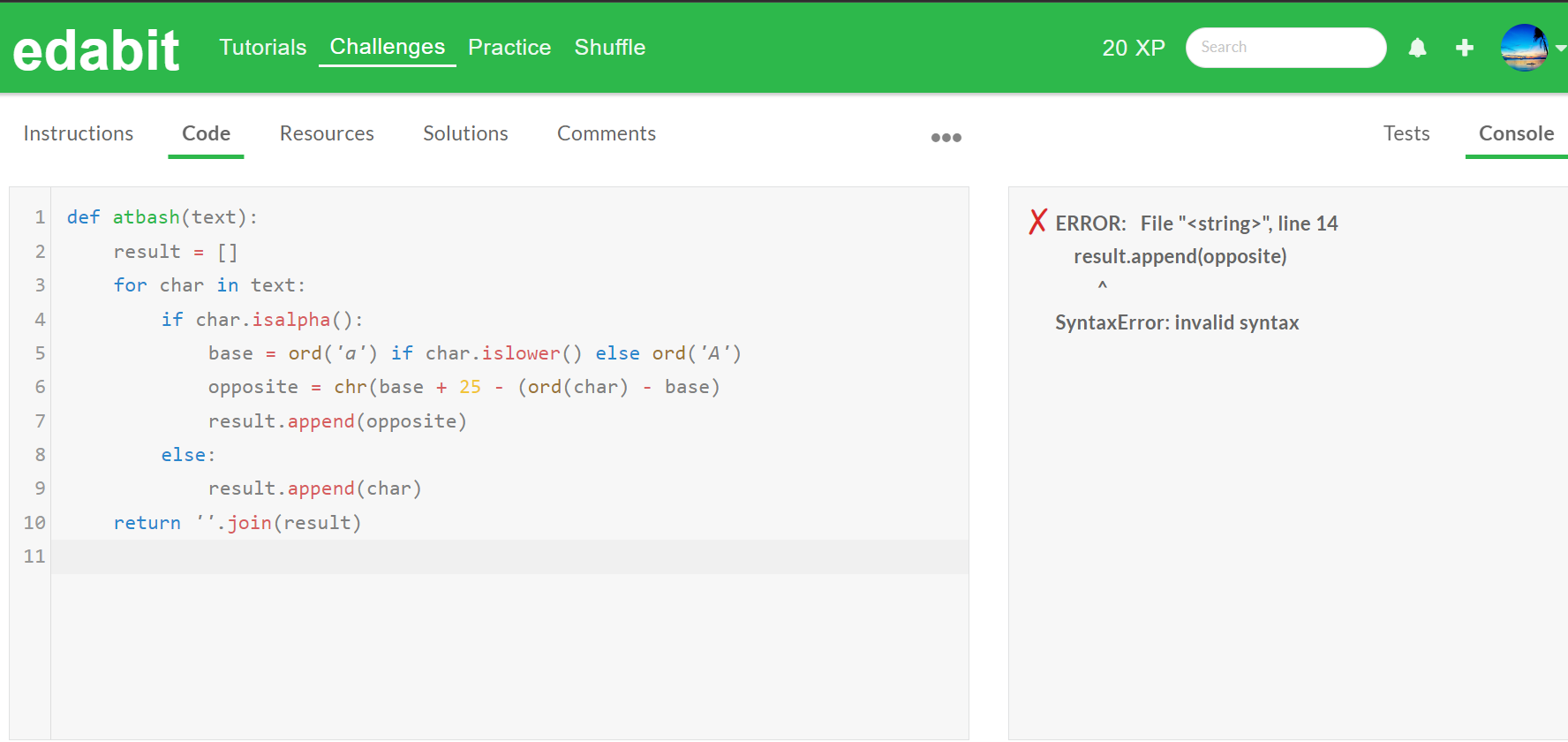
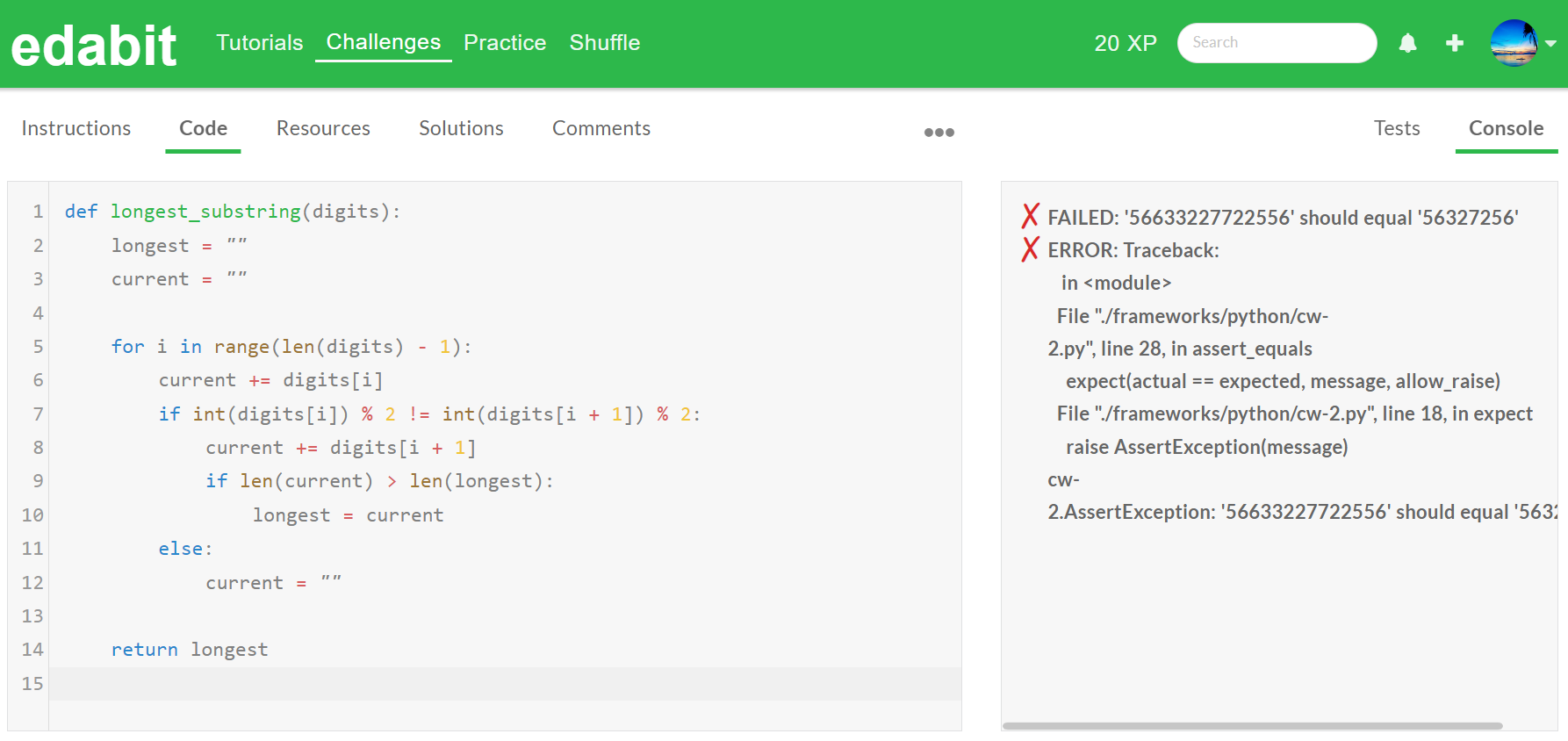
하지만, Gemma 2는 파이썬과 자바스크립트 문제 난이도 Very Hard와 Expert 단계에서 두 번의 시도에서 모두 문제를 풀지 못했습니다.
| 구 분 | Easy | Medium | Hard | Very Hard | Expert |
| Python | Pass | Pass | Pass | Fail | Fail |
| JavaScript | Pass | Pass | Pass | Fail | Fail |


Gemma 2 역사 챗봇 만들기
다음은 Ollama를 이용해서 Gemma 2 역사 챗봇을 만들어 보겠습니다. 이 블로그의 작업 환경은 Windows 11 Pro(23H2), WSL2, 파이썬 버전 3.11, 비주얼 스튜디오 코드(이하 VSC) 1.90.2이며, VSC를 실행하여 "WSL 연결"을 통해 Windows Subsystem for Linux(WSL) Linux 환경에 액세스 하도록 구성하였습니다. 작업순서는 다음과 같습니다.
1. Ollama 설치 및 Gemma 2 모델 다운로드: WSL 프롬프트 상에서 아래 명령어로 Ollama 리눅스 버전을 설치하고 Gemma 2 9B모델을 다운로드합니다.
curl -fsSL https://ollama.com/install.sh | sh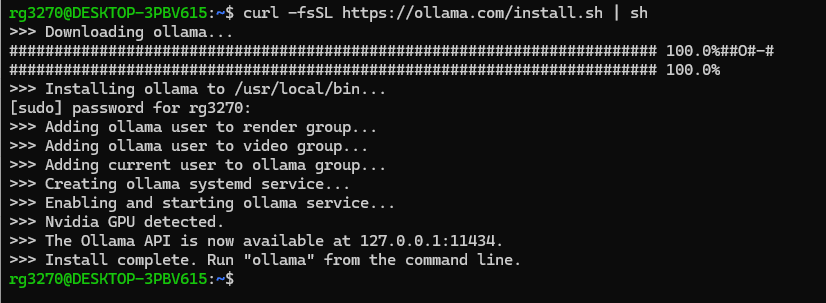
2. 가상환경 생성 및 활성화: 다음 명령어를 통해 VSC에서 가상환경 생성 후 활성화 합니다.
python3.11 -m venv myenv
source myenv/bin/activate
3. 의존성 설치: 가상환경을 활성화한 후, 아래 명령어로 의존성 라이브러리와 패키지를 설치합니다.
pip install langchain_community chainlit accelerate sentencepiece git+https://github.com/huggingface/transformers
4. 파이썬 코드 실행: VSC에서 새 파이썬 파일을 생성하고 아래 코드를 복사해서 붙여 넣습니다. 이 코드는 Gemma 2 모델을 이용해 역사 관련 질문에 대답하는 대화형 인터페이스를 제공하며, Chainlit을 통해 웹 기반 UI를 구현합니다.
from langchain_community.llms import Ollama
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser
from langchain.schema.runnable import Runnable
from langchain.schema.runnable.config import RunnableConfig
import chainlit as cl
@cl.on_chat_start
async def on_chat_start():
await cl.Message(content="Hello there, I am Gemma. How can I help you ?").send()
model = Ollama(model="gemma2")
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You're a very knowledgeable historian who provides accurate and eloquent answers to historical questions.",
),
("human", "{question}"),
]
)
runnable = prompt | model | StrOutputParser()
cl.user_session.set("runnable", runnable)
@cl.on_message
async def on_message(message: cl.Message):
runnable = cl.user_session.get("runnable") # type: Runnable
msg = cl.Message(content="")
async for chunk in runnable.astream(
{"question": message.content},
config=RunnableConfig(callbacks=[cl.LangchainCallbackHandler()]),
):
await msg.stream_token(chunk)
await msg.send()아래 명령어로 파이썬 코드를 실행하면 http://localhost:8000/ 주소에서 채팅 인터페이스가 열립니다.
chainlit run ui.py
맺음말
오늘 블로그에서는 강력한 오픈 소스 언어 모델, Gemma 2를 소개하고, 그 성능과 다양한 기능을 자세히 살펴보았습니다. 로컬-글로벌 어텐션 교차와 그룹 쿼리 어텐션을 통해 효율적인 계산과 강력한 문맥 이해 능력을 동시에 달성한 Gemma 2는 작은 모델 크기로도 높은 성능을 보여줍니다. 또한 지식 증류를 통해 큰 모델의 지식을 효율적으로 전달하여 성능 향상을 이루었으며, 코딩 능력까지 갖추고 있어 다양한 분야에서 활용 가능성을 보여줍니다.
이번 블로그에서는 Gemma 2를 활용하여 역사 챗봇을 구축하는 과정을 소개하며, Ollama를 활용한 간편한 구현 방법을 보여주었습니다. Gemma 2는 오픈 소스로 공개되어 누구나 쉽게 접근하고 활용할 수 있습니다. 이는 AI 기술의 접근성을 높이고, 더 나아가 혁신적인 아이디어를 현실로 만들 수 있는 기회를 제공합니다.
오늘 블로그 내용은 여기까지입니다. 구글의 오픈 소스 언어 모델, Gemma 2에 대해 이해하시는데 도움이 되셨기를 바라면서 저는 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.04.16 - [AI 도구] - [초보 필수] 제미나이 1.5 프로 API 활용 가이드: 40분 오디오 분석 1분 완료!
[초보 필수] 제미나이 1.5 프로 API 활용 가이드: 40분 오디오 분석 1분 완료!
안녕하세요! 오늘은 구글의 제미나이 1.5 프로 모델을 API를 이용해서 만나보겠습니다. 제미나이 1.5 프로는 최대 100만 토큰의 매우 긴 문맥을 이해하고 처리할 수 있으며, 텍스트, 코드, 이미지,
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 🚀 GPT-4o mini: OpenAI의 최첨단 고성능 저비용 AI 모델 (0) | 2024.07.20 |
|---|---|
| 미스트랄 Codestral Mamba:🐍Mamba 아키텍처로 무장한 코드 생성 AI (2) | 2024.07.18 |
| 🖥️마이크로소프트 Florence-2 리뷰: 0.7B 비전 모델의 혁신🚀 (0) | 2024.06.28 |
| CoLLaVO: 카이스트의 최첨단 시각-언어 모델 분석 및 테스트👀💬🔍 (0) | 2024.06.25 |
| Claude 3.5 Sonnet: GPT-4o를 뛰어넘은 성능 및 새로운 인터페이스 Artifacts 리뷰 (0) | 2024.06.22 |



