안녕하세요! 오늘은 Command R+ 언어모델로 유명한 Cohere의 최신 다국어 지원 언어모델 Aya 23에 대해서 알아보겠습니다. Aya 23 모델은 23개 언어를 지원하는 다국어 언어 모델로, 높은 성능의 사전 학습 모델과 다국어 데이터 컬렉션을 결합하여 개발되었으며, 병렬 Attention, SwiGLU 활성화, RoPE 사용 등의 기술을 통해 효율성과 성능을 극대화하여, 다양한 벤치마크 테스트에서 우수한 성과를 보입니다. 이 블로그에서는 Aya 23의 논문을 통해 Aya 23의 개요, 아키텍처 및 성능을 알아보고, 논리 추론 테스트를 해보겠습니다.

https://www.aitimes.com/news/articleView.html?idxno=159977
코히어, 한국어 포함 23개 언어 지원 LLM 출시..."전작보다 강력한 성능" - AI타임스
코히어가 한국어를 포함, 23개 언어를 지원하는 강력한 성능의 대형언어모델(LLM)을 오픈 소스로 내놓았다. 지난 2월 출시한 \'아야 101(Aya 101)\'을 고도화한 것으로, 여기에는 전 세계 인구 절반이
www.aitimes.com
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문 개요
이 논문의 목적은 다국어 언어 모델인 Aya 23을 소개하고, 이를 통해 다국어 기술을 강화하려는 것입니다. Aya 23은 23개 언어를 지원하며, 다양한 벤치마크와 인간 평가에서 높은 성능을 보여줍니다. 이 논문은 다국어 언어 모델의 성능을 개선하고, 언어 기술이 다양한 언어로 확장되어 발전하는 데 중점을 둡니다.
- 논문 제목: Aya 23: 다국어 발전을 위한 공개 가중치 릴리즈
- 논문 저자: Viraat Aryabumi, John Dang 외
- 논문 게재 사이트: https://arxiv.org/abs/2405.15032?ref=cohere-ai.ghost.io
- 논문 게재일: 2024년 5월 27일


Cohere For AI Launches Aya 23, 8 and 35 Billion Parameter Open Weights Release
Today, Cohere For AI is excited to announce Aya 23, a new family of state-of-the-art, multilingual, generative large language research model (LLM) covering 23 different languages. We are releasing both the 8-billion and 35-billion parameter Aya 23 models a
cohere.com
논문의 연구 내용 및 결과
Aya 23은 최근 출시된 Aya 모델을 기반으로 한 다국어 언어 모델로, 높은 성능의 사전 학습 모델과 최근 발표된 다국어 명령 스타일 데이터셋인 Aya 컬렉션을 결합하여 아랍어, 중국어(간체 및 번체), 체코어, 네덜란드어, 영어, 프랑스어, 독일어, 그리스어, 히브리어, 힌디어, 인도네시아어, 이탈리아어, 일본어, 한국어, 페르시아어, 폴란드어, 포르투갈어, 루마니아어, 러시아어, 스페인어, 터키어, 우크라이나어, 베트남어의 23개 언어를 지원하며, 8B 및 35B 모델로 공개되었습니다.
| 모델 | 임베딩 차원 | 레이어 수 | 헤드 수 | KV 헤드 수 | Vocab 크기 | 비임베딩 파라미터 | 총 파라미터 수 |
| Aya-23-8B | 4096 | 32 | 32 | 8 | 128 | 1,048,576,000 | 6,979,457,024 |
| Aya-23-35B | 8012 | 40 | 64 | 64 | 128 | 2,097,152,000 | 32,883,679,232 |
Aya 23 아키텍처
Aya 23 모델은 표준 디코더 전용 Transformer 아키텍처를 사용합니다. 이 아키텍처는 특히 텍스트 생성 작업에서 높은 성능을 발휘합니다. 주요 구성 요소는 다음과 같습니다:
- 병렬 어텐션 및 FFN 레이어 (Parallel Attention and FFN Layers): 각 레이어에서 Attention 메커니즘과 피드포워드 신경망(FFN)을 병렬로 처리하여 훈련 효율성을 높이고, 모델 품질을 유지하면서 훈련 시간을 단축합니다.
| 구분 | 병렬 어텐션 | 전통적인 어텐션 |
| 계산 방식 | 병렬 계산 | 순차 계산 |
| 비재귀적(반복문, 자기 자신 참조 X) | 재귀적(함수가 자기 자신 호출) | |
| 아키텍처 | 멀티헤드 어텐션 활용 | 단일 어텐션 메커니즘 |
| 트랜스포머 아키텍처의 핵심 | RNN(순환 신경망) 기반 모델 | |
| 계산 효율성 | 병렬 연산 하드웨어 활용 가능 | 순차 계산으로 병렬화 어려움 |
| 긴 시퀀스 처리 능력 향상 | 긴 시퀀스 처리 능력 제한 |
- SwiGLU 활성화 (SwiGLU(Swish-Gated Linear Units) Activation): 입력 신호를 변환하여 다음 층으로 전달되는 신호를 결정하는 활성화 함수에 Swish 함수와 게이트 메커니즘을 결합하여 모델의 표현력을 극대화함으로써, 입력 값의 비선형 변환을 더 부드럽게 처리하여, 모델의 학습 및 추론 성능을 향상시킵니다.
- 바이어스 제거 (No Bias) 특정 레이어에서 뉴런이 활성화되는 기준 바이어스를 제거하여 모델 훈련의 안정성을 향상시키고, 모델의 복잡성과 계산량을 줄임으로써, 훈련 및 추론 과정의 효율성과 안정성을 높입니다.
- RoPE (Rotary Positional Embeddings) 회전 위치 임베딩을 통해 각 토큰에 위치 정보를 추가함으로써 더 나은 긴 문맥 처리를 제공하고, 기존의 위치 인코딩 방법보다 짧은 문맥 길이에서도 더 나은 성능을 발휘합니다.
- 토크나이저 (Tokenizer) 가장 자주 발생하는 문자 쌍을 반복하여 더 큰 단위(subword)를 형성하는 256k 크기의 BPE 토크나이저(Byte Pair Encoding Tokenizer)를 사용하여, 표준화된 문자 및 숫자를 개별 토큰으로 분리함으로써, 다양한 언어의 효율적인 표현을 보장합니다.
- 그룹화된 쿼리 어텐션 (Grouped Query Attention, GQA) 여러 쿼리(Query) 헤드가 하나의 키-값 헤드(Key-Value Head)를 공유하도록 하여 추론 시 메모리 사용량을 줄이는 기법입니다.
데이터 혼합 (Data Mixture)
Aya 23 모델의 성능을 극대화하기 위해, 사전 학습된 모델을 다양한 다국어 명령 데이터로 미세 조정(fine-tuning)합니다. 그러나 다국어 명령 데이터의 부족 때문에, 다국어 템플릿, 인간 주석, 번역된 데이터, 합성 데이터 등 여러 접근 방식을 결합하여 데이터의 가용성을 높이는 방법을 사용합니다. 이러한 데이터 혼합 과정은 다음과 같은 방법들을 포함합니다:
- 다국어 템플릿 (Multilingual Templates): 구조화된 텍스트를 사용하여 특정 자연어 처리(NLP) 데이터셋을 명령 및 응답 쌍으로 변환합니다. 사용된 데이터에는 대규모 다국어 자연어 처리(NLP) 모델의 학습 및 평가를 위해 사용되는 xP3x 데이터셋, 데이터 출처 수집, 그리고 Aya 컬렉션 등이 포함됩니다. 최종 수집된 데이터는 23개 언어와 161개의 다양한 데이터셋을 포함하며, 55.7M 예제를 제공합니다.
- 인간 주석 (Human Annotations): Aya 데이터셋에는 65개 언어로 작성된 인간이 작성한 주석 데이터 204K의 명령-응답 쌍이 포함되어 있습니다. 이 데이터를 23개 언어로 필터링하여 55K 샘플을 확보합니다.
- 번역된 데이터 (Translated Data): 번역된 데이터는 기존 영어 명령 데이터셋을 여러 언어로 번역한 것으로, 각 언어당 최대 3,000개의 예제를 무작위로 샘플링하여, 총 1.1M 예제를 확보합니다.
- 합성 데이터 (Synthetic Data): 합성 데이터는 기계 번역 및 합성 데이터 생성 전략을 사용하여 생성됩니다. 인간 주석된 프롬프트를 기반으로 한 ShareGPT 및 Dolly-15k 데이터셋의 번역된 명령과 Cohere의 Command R+ 모델을 사용하여 23개 언어로 합성된 응답을 생성하여, 총 1.63M 예제를 확보합니다.
성능 평가 결과
Aya 23은 다양한 다국어 벤치마크와 인간 평가에서 높은 성능을 보여주었습니다. 아래 그래프는 유사한 크기의 가중치 공개 모델인 Gemma-1.1-7B-it, Mistral-7B-Inst-v0.2, Mistral-8x7B-Inst 및 BX-7B와 비교한 결과입니다.
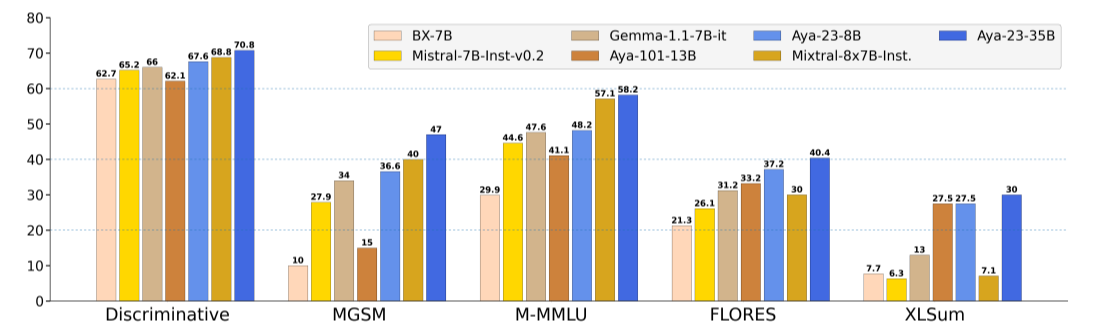
- Discriminative : 문장이나 문서의 의미적 유사성을 판별하는 작업. 이 범주에서 Aya-23-35B는 70.8의 점수로 가장 높은 성능을 보이고, 그다음은 Mistral-8x7B-Inst가 68.8을 기록했습니다.
- MGSM (Multilingual Grade School Math): 다양한 언어에서 초등학교 수준의 수학 문제를 해결하는 모델의 수학적 추론 성능을 평가. 이 범주에서 Aya-23-35B는 47의 점수로 가장 높고, Mistral-7B-Inst-v0.2(40)가 그 뒤를 따릅니다.
- M-MMLU (Multilingual Massive Multitask Language Understanding, 다국어 대규모 다중 작업 언어 이해): 다양한 언어 이해 작업을 포함하는 벤치마크. Aya-23-35B가 58.2점으로 가장 뛰어난 성능을 보이며, Mistral-8x7B-Inst(57.1)를 약간 앞섭니다.
- FLORES (FLuency-OReiented Evaluation of Sentence) 다국어 기계 번역 시스템의 성능을 평가하기 위해 개발된 FLORES 벤치마크는 특히 다양한 언어 쌍에 대한 기계 번역 품질을 평가. Aya-23-35B는 40.4의 점수로 다시 한번 우위를 차지하며, Aya-23-8B(37.2)가 그 뒤를 잇습니다.
- XLSum: 다양한 언어로 텍스트 요약 품질을 평가하는 벤치마크. 이 범주에서도 Aya-23-35B는 30점으로 가장 높은 성능을 보였으며 Aya-23-8B와 Aya-101-13B의 27.5점을 앞섭니다.
논리 추론 테스트
다음은 Aya 23 모델의 논리 추론 성능을 테스트해 보겠습니다. 테스트는 Cohere의 플레이그라운드에서 실행하였습니다.
https://dashboard.cohere.com/playground
Login | Cohere
Cohere provides access to advanced Large Language Models and NLP tools through one easy-to-use API. Get started for free.
dashboard.cohere.com
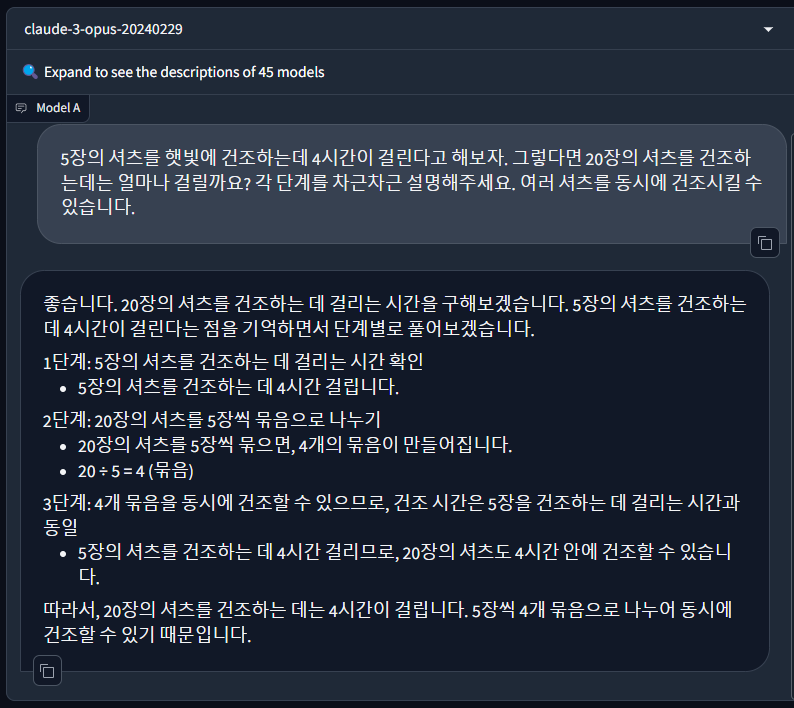
첫 번째 문제는 셔츠 건조시간 문제입니다.
"5장의 셔츠를 햇빛에 건조하는데 4시간이 걸린다고 해보자. 그렇다면 20장의 셔츠를 건조하는 데는 얼마나 걸릴까요? 각 단계를 차근차근 설명해 주세요. 여러 셔츠를 동시에 건조할 수 있습니다. " - 정답 : 4시간
아래 화면과 같이 Claude3 Opus는 정답을 맞혔지만, Aya 23은 틀린 답을 제시하였습니다.

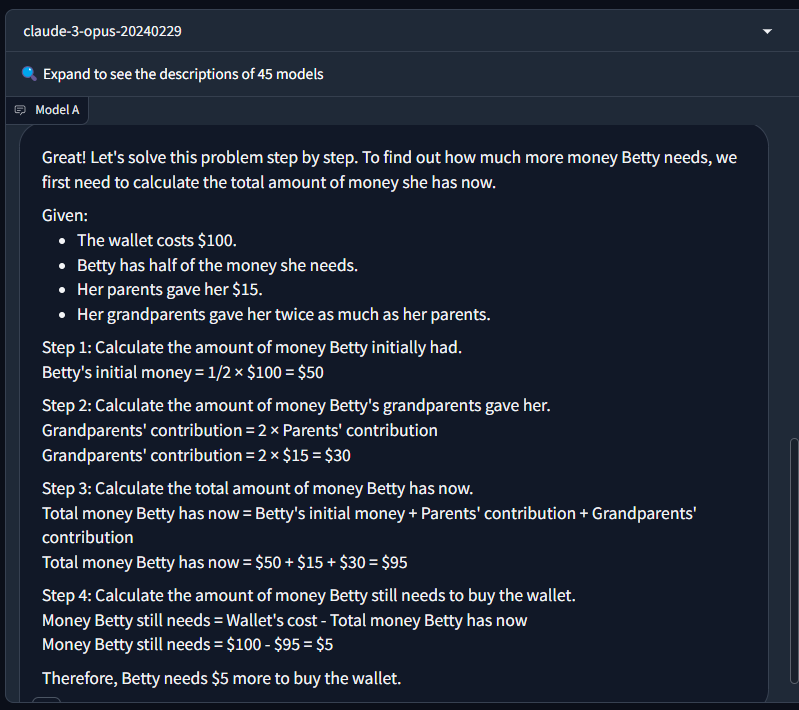
다음 추론문제는 GSM8K (Grade School Math 8K, 8,500개의 다양한 초등학교 수학 서술형 문제 데이터셋)입니다.
"베티는 새 지갑을 위해 돈을 모으고 있습니다. 새 지갑의 가격은 $100입니다. 베티는 필요한 돈의 절반만 가지고 있습니다. 그녀의 부모는 그 목적을 위해 $15를 주기로 결정했고, 할아버지와 할머니는 그녀의 부모들의 두 배를 줍니다. 베티가 지갑을 사기 위해 더 얼마나 많은 돈이 필요한가요?" - 정답 : 5달러
이번 문제도 아래 화면과 같이 Claude3 Opus는 정답을 맞혔지만, Aya 23은 틀린 답을 제시하였습니다.

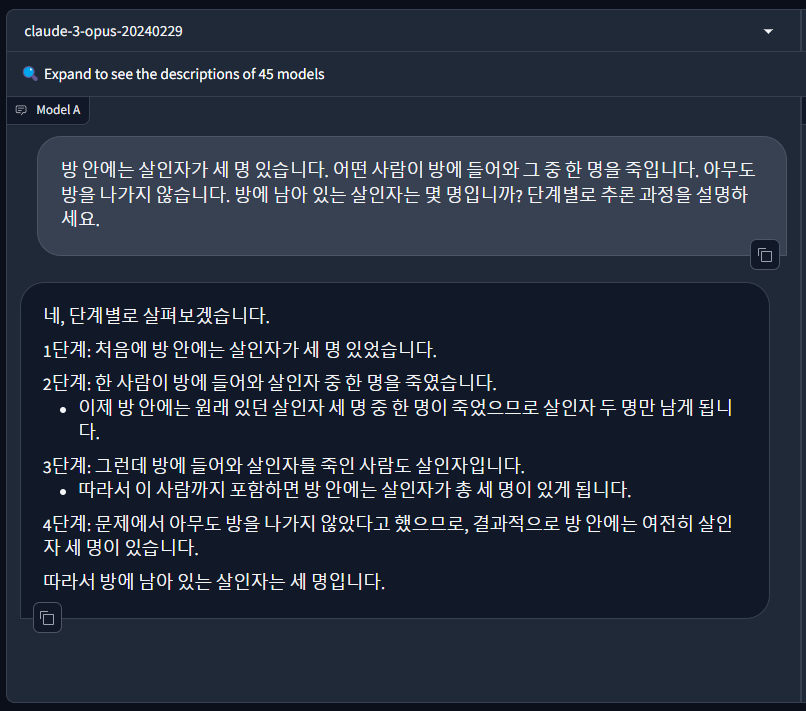
다음 추론 테스트는 살인자 문제입니다.
"방 안에는 살인자가 세 명 있습니다. 어떤 사람이 방에 들어와 그중 한 명을 죽입니다. 아무도 방을 나가지 않습니다. 방에 남아 있는 살인자는 몇 명입니까? 단계별로 추론 과정을 설명하세요." - 정답 : 3명
마찬가지로 Claude3 Opus는 정답을 맞혔지만, Aya 23은 정답을 맞히지 못하였습니다.

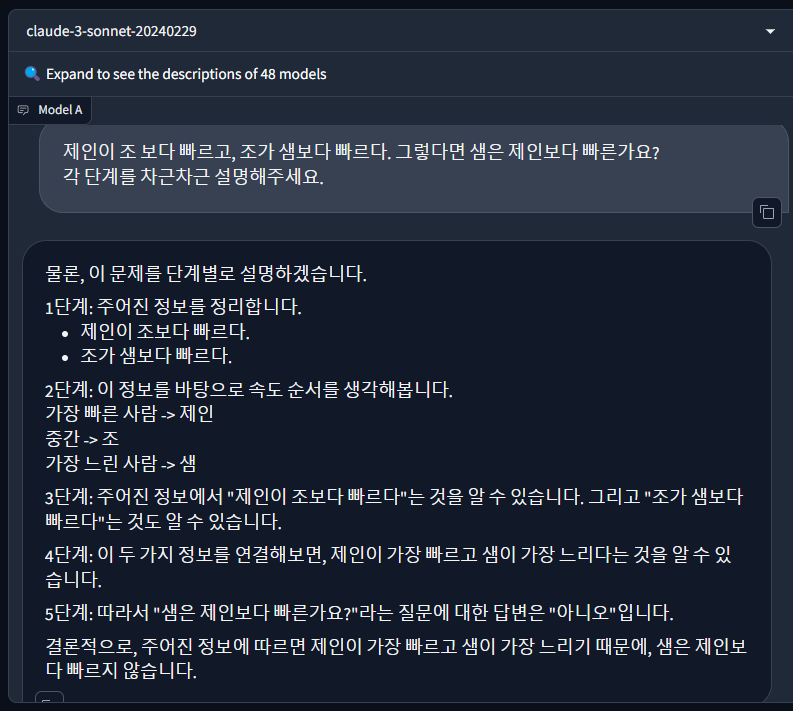
마지막 추론 테스트는 빠르기 문제입니다.
"제인이 조 보다 빠르고, 조가 샘보다 빠르다. 그렇다면 샘은 제인보다 빠른가요? 각 단계를 차근차근 설명해 주세요."
- 정답 : 샘은 제인보다 빠르지 않다.
이번 문제는 두 모델 다 정답을 맞혔습니다.

맺음말
논문에서 제시한 Aya 23 모델은 23개 언어를 지원하며, 다양한 다국어 벤치마크와 인간 평가에서 높은 성능을 보여주었습니다. 이러한 모델 가중치의 공개를 통해 향후 다국어 언어 모델 연구와 발전에 기여할 것이며, 다양한 언어 사용자가 더 공평하게 언어 기술의 혜택을 누릴 수 있을 것입니다.
Aya 23 모델을 테스트하면서 느낀 점은 다음과 같습니다.
- 테스트 결과 추론 성능이 아주 우수하진 않다.
- Page Assist에 사용해 본 결과 한국어 웹 브라우저 Co-pilot으로 적당하다.
- 외국어 공부에 활용하기 편리하다.
오늘 블로그는 여기까지입니다. 저는 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.05.30 - [AI 도구] - 🌐✨Page Assist: Ollama 기반 웹 브라우저 AI Co-pilot 설치 및 사용법
🌐✨Page Assist: Ollama 기반 웹 브라우저 AI Co-pilot 설치 및 사용법
안녕하세요!! 오늘은 Ollama를 활용해서 웹 브라우저 Co-pilot으로 사용할 수 있는 Page Assist라는 크롬 확장 프로그램을 소개해 드리겠습니다. Page Assist는 로컬 AI 모델과 상호 작용할 수 있는 사이드
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| Stable Diffusion 3 Medium: 최신 T2I 모델 설치와 활용법(SwarmUI) (2) | 2024.06.15 |
|---|---|
| Qwen-2:🌐27개 언어 구사, 알리바바의 자바스크립트 천재 언어 모델 💻 (2) | 2024.06.08 |
| 🌟코딩 혁신: Codestral - 미스트랄이 만든 AI 코드 생성 끝판왕!🚀 (0) | 2024.05.31 |
| GPT-4o: 자연스러운 음성 대화와 뛰어난 코딩 성능을 갖춘 멀티모달 언어 모델 (0) | 2024.05.17 |
| DeepSeek-V2: 오픈소스 최고 성능과 가성비를 자랑하는 혁신 MoE 언어 모델 (0) | 2024.05.11 |



