안녕하세요! 오늘은 마이크로소프트의 최근 논문 중 얼굴 이미지 1장과 오디오 클립을 이용해서 말하는 얼굴 비디오를 생성하는 VASA-1 기술에 대해서 알아보겠습니다. VASA-1은 오디오와 정확하게 동기화된 입술 움직임을 생성할 뿐만 아니라 생동감을 높이는 다양한 얼굴 표정과 자연스러운 머리 움직임을 만들 수 있으며, 실시간으로 생성된 얼굴 비디오의 시선, 머리 움직임, 카메라와의 거리, 표정에 대한 제어가 가능합니다. 이 블로그에서는 VASA-1의 주요특징, 동작원리와 동작순서, 성능평가 결과 및 DEMO VIDEO를 살펴보겠습니다.

| VASA-1으로 생성한 영상 |
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문 개요
이 논문은 정지 이미지와 음성 오디오 입력으로부터 실제와 같은 얼굴 표정을 생성하는 시각적 감성 스킬(Visual Affective Skills, VAS)을 갖춘 VASA 프레임워크, 특히 그 첫 번째 모델인 VASA-1을 소개합니다. VASA-1은 오디오와 정확히 동기화된 입술 움직임을 생성할 뿐만 아니라, 사실감과 생동감을 더해주는 다양한 얼굴 표정과 자연스러운 머리 움직임을 가진 말하는 얼굴 비디오를 실시간으로 생성합니다.
- 논문제목: VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
- 논문저자: Microsoft Research Asia
- 논문게재 사이트: https://arxiv.org/abs/2404.10667
- 논문게재일: 2024년 4월 16일


논문의 연구내용 및 결과
이 논문에서 소개된 VASA-1 기술은 정지 이미지와 음성 오디오 클립을 사용하여 실시간으로 생생한 대화형 얼굴을 생성하는 프레임워크입니다. 이 모델의 핵심은 첫째로, 얼굴의 다양한 특징과 속성을 나타내는 잠재 공간을 개발하는 것입니다. 잠재 공간을 개발한다는 것은 얼굴의 다양한 특징과 속성을 포함하는 공간을 정의하고, 이를 활용하여 원하는 얼굴 특성을 조절하거나 생성하는 기술적인 방법을 연구하는 것을 의미합니다.
둘째로, 이러한 잠재 공간을 활용하여 얼굴의 전체적인 역학과 머리 움직임을 생성하는 확산 기반의 모델을 구축하는 것입니다. 즉, 얼굴의 특징과 속성을 잘 파악하고 효과적으로 제어하여 원하는 결과물을 생성하는 기술적인 방법을 연구하는 것이 이 모델의 핵심입니다.
VASA-1 기술의 주요 특징
VASA-1 기술은 입술 움직임과 음성 동기화로 사실적인 얼굴 생성이 가능하며, 자연스러운 머리 움직임과 다양한 제어 기능이 추가되어 최대 40FPS의 실시간 생성 속도로 혁신적인 대화형 얼굴을 구현합니다.
- 뛰어난 립싱크 및 얼굴 표정: 음성과 완벽하게 동기화된 입술 움직임을 생성합니다. 다양한 얼굴 표정과 미묘한 뉘앙스를 포착하여 사실감과 생동감을 더합니다.
- 자연스러운 머리 움직임: 단순히 얼굴 표정뿐만 아니라 자연스러운 머리 움직임도 생성하여 현실감을 높입니다. 기존 기술보다 훨씬 자연스러운 머리 움직임 패턴을 구현합니다.
- 효율적인 생성 속도: 512x512 해상도의 비디오를 최대 40FPS 속도로 실시간 생성합니다. 대화형 시스템에 필요한 낮은 지연 시간 요구 사항을 충족합니다.
- 폭넓은 제어 가능성: 주 시선 방향, 머리-카메라 거리, 감정 오프셋 등의 제어 신호를 통해 생성 결과를 조정할 수 있습니다. 다양한 상황과 요구에 맞게 맞춤 설정이 가능합니다.
- 강력한 잠재 공간 구성: 얼굴 표정, 머리 움직임, 신원 등 다양한 요소를 분리하면서도 풍부한 표현력을 가진 잠재 공간을 구성합니다. 이를 통해 다양한 얼굴과 표정을 사실적으로 생성할 수 있습니다.
- 혁신적인 생성 모델: 기존 방법과 달리 입술 움직임, 표정, 시선, 눈 깜빡임 등 모든 얼굴 움직임을 하나의 잠재 변수로 간주하고 확률적 분포를 통합적으로 모델링합니다. 이를 통해 보다 일관되고 자연스러운 대화형 얼굴을 생성합니다.
- 다양한 입력 처리 가능: 사진 스타일의 이미지, 노래 오디오 클립, 영어 이외의 언어 등 다양한 입력을 처리할 수 있습니다.
기술 원리 및 동작 순서
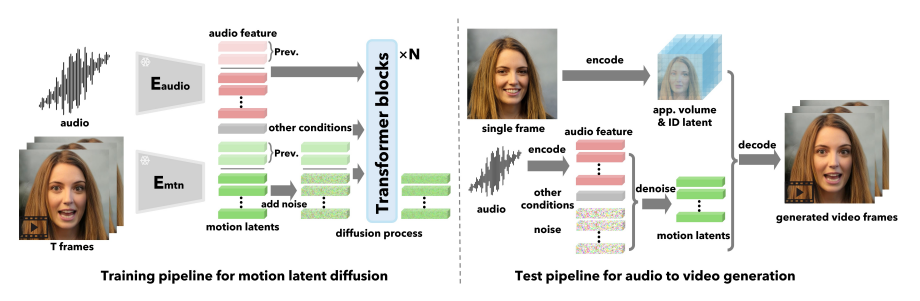
- 1. 얼굴 잠재 공간 구성: 대량의 얼굴 비디오 데이터를 사용하여 얼굴 인코더와 디코더를 훈련하여 주어진 이미지로부터 얼굴 동작, 머리 포즈, 3D 외모, 신원 등을 분리된 잠재 변수로 추출합니다. 잠재 변수로 추출한다는 것은 얼굴의 다양한 특징과 속성을 나타내는 얼굴 데이터를 잠재 변수라는 공간으로 매핑하여 해당 공간에서 특정한 패턴이나 속성을 표현하도록 하는 것입니다. 이 과정을 통해 얼굴의 다양한 특성을 효과적으로 분리해서 표현할 수 있게 됩니다. 잠재공간에 대한 설명은 더 보기를 클릭하시면 됩니다.
잠재 공간은 데이터를 효과적으로 표현하고 조작하기 위해 사용되는 고차원의 추상적인 공간입니다. 이 공간은 원래 데이터의 다양한 특징을 보존하면서 데이터를 더 간결하고 유용한 형태로 표현합니다. 잠재 공간은 주어진 데이터의 차원을 줄이고 중요한 특징을 강조하여 데이터를 더 효율적으로 다룰 수 있도록 해줍니다.
예를 들어, 얼굴 이미지의 잠재 공간에서 각 점은 얼굴 이미지의 특정 특징이나 속성을 나타냅니다. 예를 들어, 하나의 점은 얼굴의 웃음 표정을 나타내고, 다른 점은 머리의 회전 각도를 나타낼 수 있습니다. 이렇게 공간상의 각 점은 원래 데이터의 특정 변화를 나타내며, 이러한 변화는 데이터의 잠재적인 표현을 형성합니다.
- 2. 얼굴 동작과 머리 움직임 추출 : 훈련된 얼굴 인코더를 사용하여 이전에 수집된 대규모 얼굴 비디오 데이터셋으로부터 가져온 정보를 기반으로 얼굴 동작과 머리 움직임을 추출하고 Diffusion Transformer를 훈련합니다. Diffusion Transformer는 확산 기반 모델로, 시퀀스 데이터의 생성 및 처리에 사용되는 변환 모델입니다. 이 모델은 확산 과정을 통해 현재 시점의 데이터를 이전 시점의 데이터에 영향을 받도록 만들어 시퀀스의 연속성을 보존합니다. 이를 통해 주어진 시퀀스 데이터를 보다 일관되고 자연스럽게 처리하고 생성할 수 있습니다.
- 3. 3D 외모 볼륨 및 신원 코드 추출 : 임의의 얼굴 이미지와 오디오 클립이 주어지면, 얼굴 인코더를 사용하여 이미지의 얼굴 형상과 특징을 나타내는 3차원 외형 정보인 3D 외모 볼륨과 특정한 개인을 식별하는 데 사용되는 신원 코드를 추출합니다.
- 4. 오디오 특징 추출 및 분할: 오디오 클립에서 오디오 특징을 추출하고 일정 길이의 세그먼트로 분할합니다.
- 5. 머리 및 얼굴 움직임 시퀀스 생성: 훈련된 Diffusion Transformer를 사용하여 오디오 특징과 눈의 시선 방향, 카메라와의 거리, 그리고 감정 변화와 같은 조건부 신호를 기반으로 머리 및 얼굴 움직임 시퀀스를 생성합니다.
- 6. 비디오 생성: 훈련된 디코더를 사용하여 생성된 움직임 시퀀스와 3D 외모 볼륨, 신원 코드를 입력으로 받아 최종 말하는 얼굴 비디오를 생성합니다.
성능 평가 결과
1. 질적 평가
VASA-1은 오디오-입술 동기화, 오디오-포즈 정렬, 포즈 변화 강도 및 비디오 품질 측면에서 기존 방법보다 뛰어난 결과를 보였습니다. 특히, CAPP (Contrastive Audio and Pose Pretraining)이라는 새로운 데이터 기반 오디오-포즈 동기화 지표를 제안하여 기존 지표의 한계를 극복하고 오디오와 생성된 포즈 사이의 정렬 정도를 더욱 정확하게 평가할 수 있었습니다.
아래 이미지에서 생성 모델은 눈의 시선 방향, 카메라와의 거리, 그리고 감정 변화와 같은 제어 신호를 잘 해석하고 지정된 매개변수를 엄격하게 따르는 일관되고 자연스러운 말하는 얼굴 결과물을 생성할 수 있는 것으로 나타났습니다.

VASA-1은 얼굴 움직임과 신원 간의 분리를 성공적으로 달성합니다. 동일한 머리와 얼굴 움직임 시퀀스가 서로 다른 얼굴 이미지에 적용될 수 있고, 서로 다른 머리 자세와 동일한 얼굴 움직임이 적용되었을 때, 이미지는 의도한 머리와 얼굴 움직임을 충실히 반영할 수 있으며, 훈련 데이터셋에 없는 다양한 입력 유형에 대한 처리 능력을 보여줍니다.
2. 양적 평가
VASA-1 얼굴 생성 모델의 성능을 평가하기 위해 OneMin-32와 VoxCeleb2 데이터셋 벤치마크를 사용하였으며, 여기서 SC, SD, CAPP, ∆P 및 FVD25는 다음과 같은 평가 지표를 나타냅니다:
- SC (Speech-to-Visual Consistency): 오디오와 비주얼 (입술 움직임) 간의 일관성을 측정하는 메트릭입니다. SC 점수는 높을수록 음성과 입술 움직임이 잘 일치함을 나타냅니다.
- SD (Speech-to-Distance Consistency): 오디오와 헤드의 거리 간의 일관성을 측정하는 메트릭입니다. SD 점수는 낮을수록 음성과 헤드의 거리가 일치함을 나타냅니다.
- CAPP (Contrastive Audio and Pose Pretraining): 오디오와 포즈 간의 정렬을 측정하는 지표입니다. 이것은 실제 생활에서 오디오와 포즈 시퀀스를 사용하여 모델을 훈련시킨 후에 오디오 입력과 생성된 포즈 간의 동기화를 평가하는 데 사용됩니다. CAPP 점수가 높을수록 생성된 포즈가 실제 오디오와 가깝다는 것을 의미합니다.
- ∆P (Pose Intensity): 생성된 헤드 포즈의 강도를 측정합니다. ∆P 값은 높을수록 생성된 헤드 움직임이 강렬함을 나타냅니다.
- FVD25 (Fréchet Video Distance with 25 Frame Samples): 실제 비디오와 생성된 비디오 간의 유사성을 측정하는 메트릭입니다. FVD는 두 비디오 분포 간의 Fréchet 거리를 계산하여 비디오의 질과 현실성을 평가합니다. FVD25는 비디오를 25프레임 샘플링하여 계산된 Fréchet 거리입니다. FVD25 값이 낮을수록 생성된 비디오가 실제 비디오와 유사하다는 것을 의미합니다.
 |
 |
| OneMin-32 benchmark 결과 | VoxCeleb2 benchmark 결과 |
벤치마크에 사용된 OneMin-32와 VoxCeleb2 데이터셋에 대한 설명입니다.
- OneMin-32: 17명의 다양한 개인들로부터 1분 길이의 비디오 클립을 수집하여 구성되었습니다. 이 데이터셋은 온라인 강의나 교육 강의 등에서 얻은 다양한 말뭉치를 포함하고 있으며, 음성 변화의 폭과 다양성이 VoxCeleb2보다 더 넓습니다.
- VoxCeleb2: 대규모의 음성 및 영상 데이터셋으로, 전 세계에서 유명한 연예인, 저명한 인물 및 일반 사람들의 음성과 얼굴 데이터를 수집하고 있습니다. 이 데이터셋은 다양한 환경에서 다양한 말과 표정을 담고 있으며, 얼굴 생성 모델의 성능을 평가하는 데 사용됩니다.
두 벤치마크의 결과를 통해 모델이 다양한 환경에서 얼마나 일반화되고 유연하게 작동하는지를 평가할 수 있습니다.
DEMO VIDEO
| 실시간 말하는 얼굴 생성 DEMO 영상 |
논문의 결론 및 전망
VASA-1은 실시간으로 생생한 말하는 얼굴을 생성하는 데 있어 다양한 특징을 효과적으로 분리하여 제어할 수 있으며, 실제 음성과의 동기화 및 신뢰성 측면에서 우수한 성과와 혁신적인 발전을 이루었으며, 제시된 기술은 커뮤니케이션, 교육, 헬스케어 등 다양한 분야에서 인간-인간 및 인간-AI 상호 작용을 혁신할 잠재력을 가지고 있습니다.
향후 연구에서는 현재는 몸통까지만 처리하지만, 전신을 모델링하여 더 다양한 표현 가능성을 확보하고, 얼굴의 형태와 특징을 더 명확하게 표현하는 3D 얼굴 모델 사용이나, 머리카락과 옷과 같은 얼굴 이외의 부분을 모델링하여 더욱 사실적인 결과를 얻고, 더 다양한 말하기 스타일과 감정을 통합하여 표현력과 제어 가능성을 향상시킬 수 있을 것으로 전망합니다.
VASA-1 기술은 커뮤니케이션, 교육 및 의료 분야에서의 인간-인공지능 상호작용을 혁신적으로 개선할 수 있는 가능성을 제시하였으며, 앞으로, 보다 다양한 대화 스타일과 감정을 포함하여 모델의 표현력과 제어 가능성을 더욱 향상시킴으로써 AI 아바타가 실제 인간과 같은 자연스럽고 직관적인 방식으로 상호 작용할 수 있는 미래를 열어줄 것으로 기대됩니다.
오늘 블로그는 여기까지입니다. 저는 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.02.28 - [AI 논문 분석] - [AI 논문] EMO: 사진 1장과 음성으로 되살린 오드리 헵번의 생생한 표정!
[AI 논문] EMO: 사진 1장과 음성으로 되살린 오드리 헵번의 생생한 표정!
안녕하세요! 오늘은 중국의 알리바바 그룹에서 발표한 오디오 기반 비디오 생성기술 "EMO: Emote Portrait Alive"에 대해 알아보겠습니다. EMO는 주어진 단일 캐릭터의 얼굴이미지를 바탕으로 음성 입력
fornewchallenge.tistory.com
'AI 도구' 카테고리의 다른 글
| 🚀Phidata와 Groq을 활용한 LLAMA3 RAG 시스템 구현하기 (0) | 2024.04.24 |
|---|---|
| 🦙Ollama를 활용한 LLAMA3 RAG 시스템 구현하기 (2) | 2024.04.22 |
| [초보 필수] 제미나이 1.5 프로 API 활용 가이드: 40분 오디오 분석 1분 완료! (0) | 2024.04.16 |
| ComfyUI와 IP-Adapter plus를 활용한 오프라인 가상 피팅 가이드 (0) | 2024.04.14 |
| 🤯허깅챗 어시스턴트 영어 뉴스 번역 챗봇 만들기! URL만 입력하면 끝! (1) | 2024.04.03 |



