안녕하세요! 오늘은 LLAMA3 RAG 시스템 구현 두 번째 시간으로, Phidata와 언어 모델 추론성능 가속 솔루션 Groq를 활용해서 RAG 시스템을 만들어 보겠습니다. Phidata는 언어 모델이 대화 내용을 저장하여 장기적인 대화를 가능하게 하고, 벡터 데이터베이스와 다양한 도구를 지원하는 AI 어시스턴트 구축 프레임워크입니다. 이 블로그에서는 Phidata와 Groq를 활용하여 URL과 PDF 문서내용을 검색해서 답변하는 LLAMA3 RAG 시스템을 구현해 보겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
프로그램 개요
이 프로그램은 Streamlit을 활용해서 웹 애플리케이션을 구현한 것으로, 사용자는 브라우저의 사이드바에서 웹사이트 URL이나 PDF를 지식베이스에 추가할 수 있으며, LLM 모델과 Embeddings 모델을 선택할 수 있고 채팅을 통해 지식베이스의 내용을 질문하고 LLAMA3 RAG 시스템을 통해 적절한 답변을 얻을 수 있습니다. 프로그램의 주요 구성요소인 Phidata, Streamlit, PostgreSQL, Docker, Nomic Embed에 대한 설명은 다음과 같습니다.
| 구성요소 | 주요 기능 |
| Phidata | 메모리, 지식 및 동작 수행을 위한 도구를 갖춘 AI 어시스턴트를 구축할수 있는 프레임워크입니다. |
| Streamlit | 데이터 과학 및 기계 학습을 위한 사용자 지정 웹 애플리케이션을 구축할 수 있는 Python 라이브러리입니다. |
| PostgreSQL | 데이터를 저장, 관리 및 쿼리할 수 있는 관계형 데이터베이스 관리 시스템입니다. |
| Docker | 응용 프로그램을 컨테이너로 패키지하고 배포하며 실행할 수 있는 컨테이너화 플랫폼입니다. |
| Nomic Embed | 가변적인 임베딩 차원을 지원하여 성능과 메모리 사용량 사이의 균형을 조절할 수 있는 임베딩 모델입니다. |
이 프로그램의 출처는 깃 허브 Phidata 레포지토리이며, 메인코드 app.py와 assistant.py의 주요 기능은 아래와 같습니다.
https://github.com/phidatahq/phidata
GitHub - phidatahq/phidata: Build AI Assistants with memory, knowledge and tools.
Build AI Assistants with memory, knowledge and tools. - phidatahq/phidata
github.com
| 코드 | 주요 기능 |
| app.py | Streamlit 애플리케이션의 주요 기능을 정의하고 실행합니다. 사용자가 선택한 LLM 및 Embeddings 모델에 따라 어시스턴트를 생성하고 사용자 인터페이스를 구성합니다. 또한 사용자 입력을 처리하고 AI 어시스턴트의 응답을 생성하여 화면에 표시합니다. 사용자가 업로드한 URL과 PDF를 처리하여 지식 베이스에 추가하고, 데이터베이스 관리 및 새로운 실행을 관리합니다. |
| assistant.py | 사용자가 선택한 LLM 및 Embeddings 모델에 따라 Groq RAG 어시스턴트를 생성합니다. 이 함수는 어시스턴트의 이름, 실행 ID, 사용자 ID, LLM, 저장소, 지식 베이스, 지시 사항 등을 설정하고 반환합니다. |
다음은 프로그램을 구현하기 위한 진행순서입니다.
- 1. 깃 허브 레포지토리 복제: Phidata 레포지토리를 로컬로 복제합니다.
- 2. 환경설정 및 모델 다운로드: 가상환경을 설정 및 활성화하고 임베딩 모델을 다운로드합니다.
- 3. Docker 컨테이너 벡터 데이터베이스 생성 : Docker를 이용해서 PostgreSQL 데이터베이스를 구성합니다.
- 4. 코드 실행 및 결과확인: URL과 PDF를 입력하고 질문에 대한 답변을 확인합니다.
환경설정 및 벡터 DB 구성
이 블로그에서 사용한 프로그램의 실행환경은 Windows 11 Pro(23H2), 파이썬 버전 3.11, 코드 에디터는 비주얼 스튜디오 코드(이하 VSC)입니다. 프로그램에 필요한 Groq API Key는 https://console.groq.com/keys에 접속해서 "Create API Key" 버튼을 클릭해서 발급받습니다. 자세한 내용은 이전 포스트를 참고하시기 바랍니다.
2024.02.29 - [AI 도구] - Groq LPU : 논문 한편 요약하는데 입력-추론-응답까지 2.4초!
Groq LPU : 논문 한편 요약하는데 입력-추론-응답까지 2.4초!
안녕하세요! 오늘은 Groq이라는 회사의 대형 언어 모델 추론성능 가속장치, LPU(Language Processing Unit)에 대해서 알아보겠습니다. Groq은 2016년에 과거 구글 직원이었던 조나단 로스에 의해 설립된 AI
fornewchallenge.tistory.com
먼저, 아래 명령어를 실행하여 깃 허브 레포지토리를 로컬로 복제하고 작업 디렉토리로 이동한 후, "ollama pull nomic-embed-text" 명령어를 통해 임베딩 모델을 다운로드합니다.
git clone https://github.com/phidatahq/phidata
cd phidata/cookbook/llms/groq/rag
다음은 윈도우 명령프롬프트에서 "conda create -n llama3phidata python=3.11 -y" 명령으로 가상환경을 생성하고 "conda activate llama3phidata" 명령으로 활성화합니다. llama3phidata 가상환경 이름은 원하는 이름으로 수정할 수 있습니다. 가상환경이 활성화된 상태에서 "pip install -r requirements.txt" 명령어를 통해 의존성을 설치해 줍니다.

다음은 Docker를 이용하여 벡터 데이터베이스를 생성하는 단계입니다. Docker는 응용 프로그램을 컨테이너로 패키지하고 배포하며 실행할 수 있는 컨테이너화 플랫폼으로, 아래 링크를 통해 윈도우 버전을 설치하고 실행합니다.
https://www.docker.com/products/docker-desktop/
Docker Desktop: The #1 Containerization Tool for Developers | Docker
Docker Desktop is collaborative containerization software for developers. Get started and download Docker Desktop today on Mac, Windows, or Linux.
www.docker.com
Docker 설치가 완료되면 아래 명령어를 복사하여 명령어 프롬프트에 붙여 넣어 PostgreSQL 데이터베이스를 실행하고 DB명, 계정, 사용포트, 디렉토리 등을 구성합니다.
docker run -d ^
-e POSTGRES_DB=ai ^
-e POSTGRES_USER=ai ^
-e POSTGRES_PASSWORD=ai ^
-e PGDATA=/var/lib/postgresql/data/pgdata ^
-v pgvolume:/var/lib/postgresql/data ^
-p 5532:5432 ^
--name pgvector ^
phidata/pgvector:16
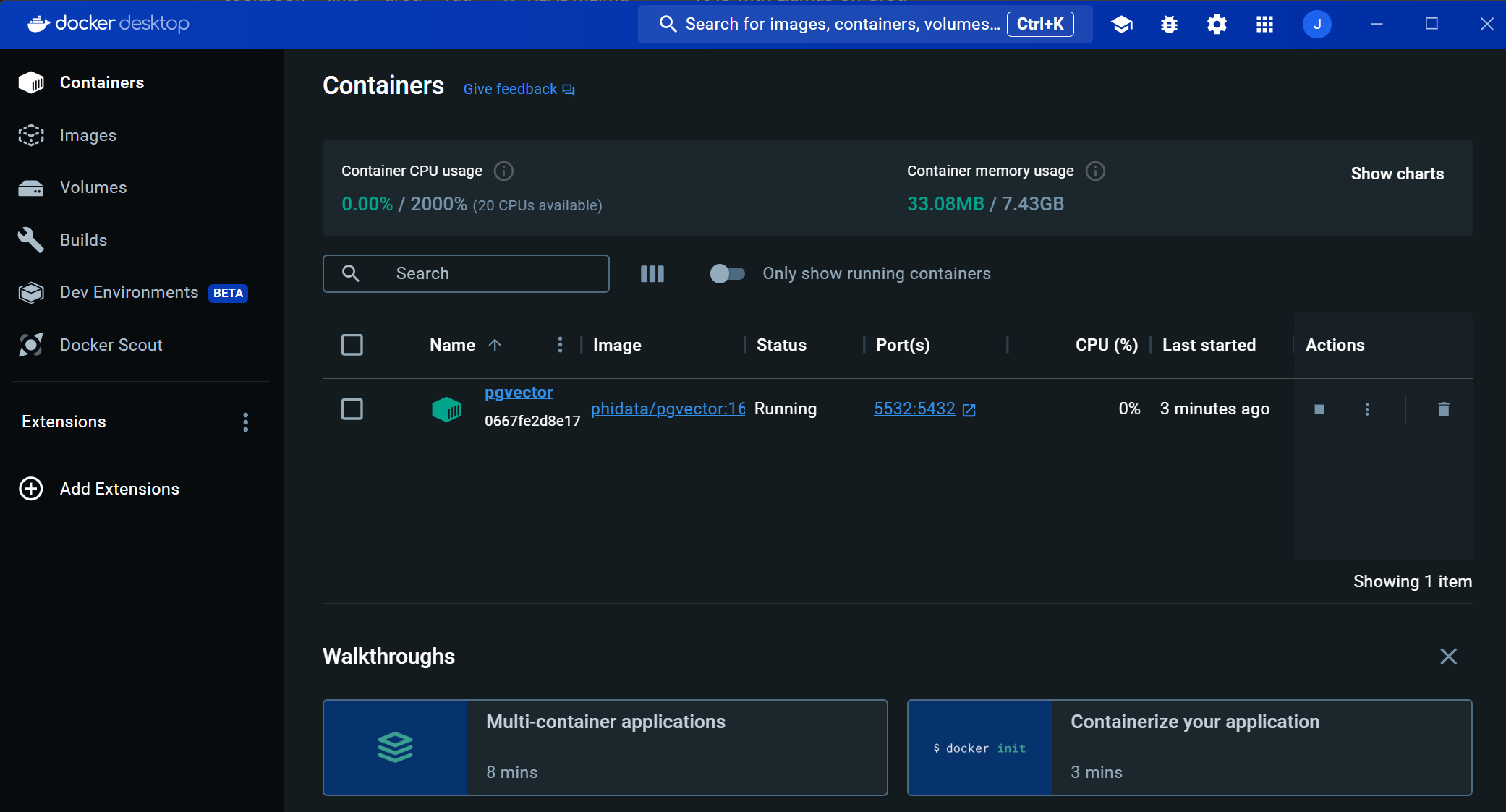
PostgreSQL 데이터베이스가 정상적으로 실행되면 아래 화면과 같이 Docker Desktop에서 벡터 임베딩과 대화기록 등이 저장되는 pgvector 컨테이너가 생성된 것을 확인할 수 있습니다.
코드 실행 및 결과확인
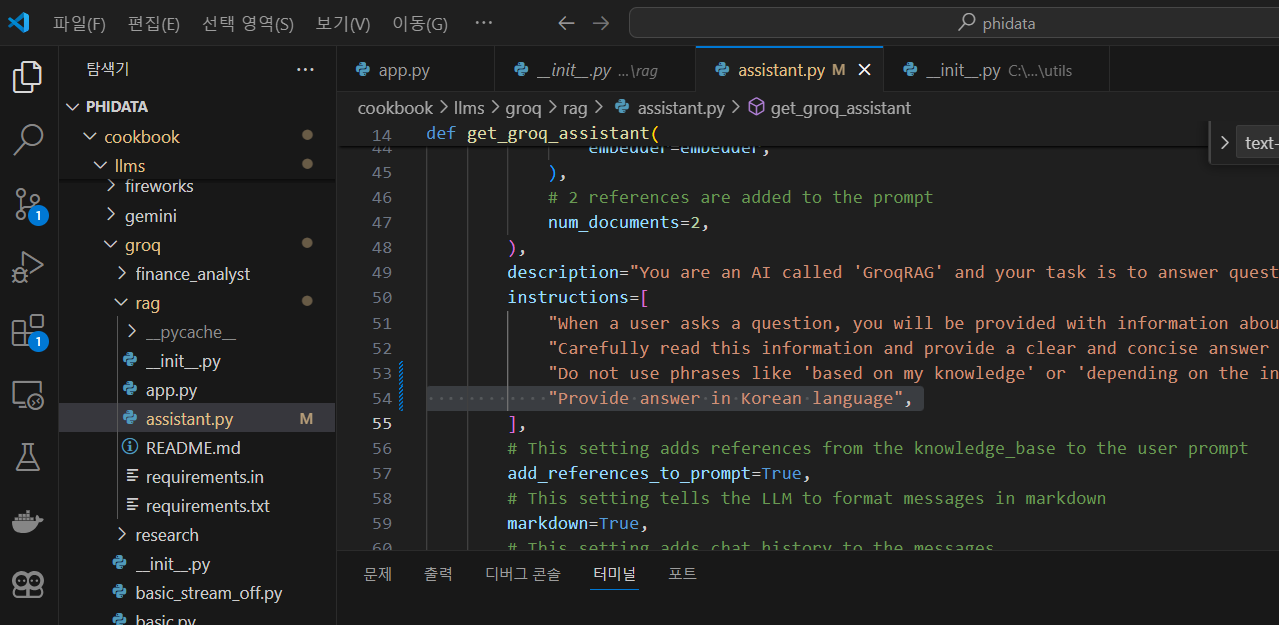
다음은 코드 실행 및 결과확인 단계입니다. 코드를 실행하기 전에 phidata\cookbook\llms\groq\rag\assistant.py 파일을 수정하여 한국어로 응답하도록 아래 화면과 같이 "Provide answer in Korean language" 명령 프롬프트를 추가합니다.
assistant.py 코드는 Groq 기반의 RAG Assistant를 구성하는 데 사용되며, 다음과 같은 주요 기능이 포함되어 있습니다:
- 모델 및 임베딩 설정: 지식 검색을 위해 사용되는 LLM(Longformer) 및 임베딩 모델 설정이 포함됩니다. `llm_model` 및 `embeddings_model` 매개변수를 통해 설정됩니다.
- 지식 저장: 대화 기록과 함께 사용자 지식베이스를 포함한 PostgreSQL 데이터베이스에 저장됩니다. 이를 통해 대화의 문맥과 이해를 유지하고 개선할 수 있습니다.
- 문장 처리 및 답변 생성: 사용자가 질문을 하면, LLM을 통해 문맥을 이해하고 지식 베이스를 검색하여 적절한 답변을 생성합니다.
- 명령 처리 및 디버깅: `debug_mode` 설정을 통해 디버그 메시지를 활성화하고 대화 기록을 통해 이전 메시지를 참조하여 사용자와의 상호 작용을 관리합니다.
- 사용자 지시사항: 사용자에게 명확한 지시사항을 제공하여 적절한 답변을 생성하고 제공하는 방법에 대한 가이드를 제공합니다.
phidata\cookbook\llms\groq\rag\app.py 코드의 주요 기능은 다음과 같습니다:
- LLM 모델 선택: 사용자는 측면 바에서 사용할 LLM(Language Model) 모델을 선택할 수 있습니다. 이는 llama3-70b-8192, llama3-8b-8192, mixtral-8x7b-32768 중에서 선택할 수 있습니다.
- Embeddings 모델 선택: 사용자는 Embeddings 모델을 선택할 수 있습니다. 이는 "nomic-embed-text", "text-embedding-3-small" 중에서 선택할 수 있습니다.
- Assistant 생성 및 초기화: `get_groq_assistant` 함수를 사용하여 Groq Assistant를 생성하고 초기화합니다. 이 함수는 선택한 LLM 모델과 Embeddings 모델을 사용하여 Assistant를 생성합니다.
- Chat UI 및 대화 처리: 사용자는 채팅 입력란에 질문을 입력할 수 있습니다. 질문이 입력되면 Assistant에 전달되고, Assistant는 해당 질문에 대한 응답을 생성하고 UI에 표시합니다.
- 지식 베이스 및 저장소 관리: 사용자는 지식 베이스에 웹 사이트 URL이나 PDF 문서를 추가할 수 있습니다. 추가된 문서는 Assistant가 질문에 답변할 때 참조될 수 있습니다. 또한 사용자는 Assistant의 실행 ID를 선택하여 과거 실행 내용을 검토할 수 있습니다.
- Assistant 재시작 및 초기화: 사용자는 Assistant를 재시작하고 초기화할 수 있습니다. 이렇게 하면 모든 상태가 초기화되고 Assistant가 새로운 실행으로 다시 시작됩니다.
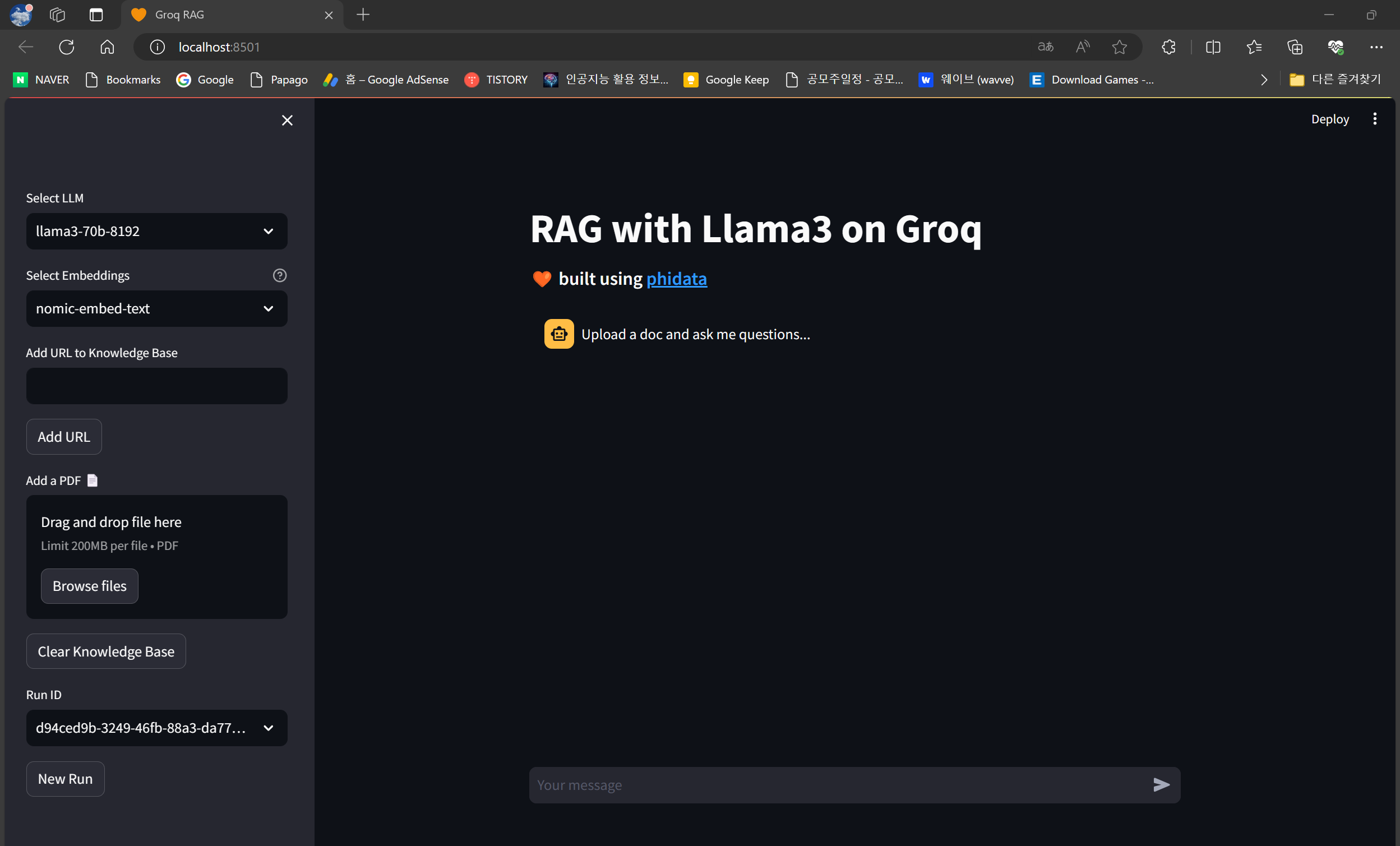
다음은 명령어 프롬프트에 "set GROQ_API_KEY=발급받은 API KEY" 명령을 입력하여 Groq API Key를 설정한 후, "streamlit run app.py" 명령을 실행하면 http://localhost:8501/ 주소에서 아래 화면과 같이 LLAMA3 RAG 시스템 초기화면이 표시됩니다. 좌측 메뉴에서 언어 모델과 임베딩 모델을 선택하고 URL 또는 PDF 문서를 입력할 수 있으며, 우측 채팅창을 통해 질문을 입력할 수 있습니다.

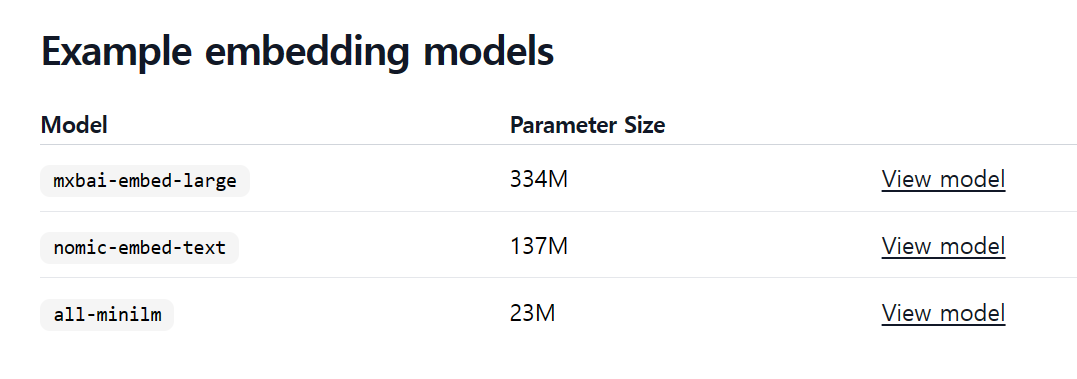
저는 URL에 "https://ollama.com/blog/embedding-models"을 입력하고 "mxbai-embed-large" 모델의 매개변수 크기를 질문해 보았는데요, 아래 실행 로그를 살펴보면 입력한 URL 주소를 읽어서 지식 베이스에 추가하는 동작을 확인할 수 있으며, 매개변수의 크기도 "334M"로 정확하게 답변하는 것을 확인할 수 있었습니다.


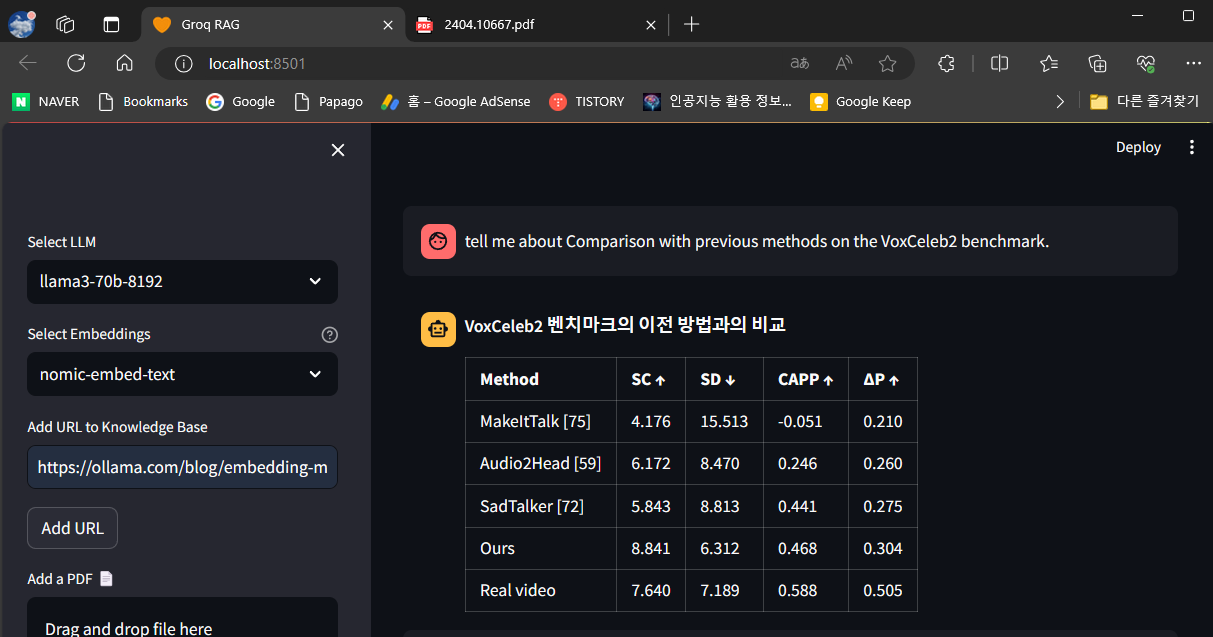
다음은 마이크로소프트의 최근 논문 "VASA-1"에 대한 PDF 문서를 입력하고 벤치마크 결과를 질문해 보았습니다. PDF 문서를 입력하면 아래 화면과 같이 문서가 분할되고 지식 베이스에 추가되는 것을 확인할 수 있습니다.

VASA-1의 벤치마크 결과 질문에 대해서도 아래 화면과 같이 표형태로 정확하게 대답하였습니다.


맺음말
오늘은 Phidata와 Groq을 활용하여 LLAMA3 RAG 시스템을 구현하는 방법을 소개했습니다. Phidata는 AI 어시스턴트를 구축하는 프레임워크로, 대화 내용을 저장하고 지식을 관리하는 도구를 제공하며, Groq은 추론 성능을 가속화하는 솔루션으로, 대형 언어 모델을 효율적으로 활용할 수 있도록 도와줍니다.
우리는 Streamlit을 사용하여 웹 애플리케이션을 개발하고, 사용자가 웹 인터페이스를 통해 URL이나 PDF를 추가하는 기능을 구현하였으며, 또한 Docker를 사용하여 PostgreSQL 데이터베이스를 구성하고, 코드를 실행하여 결과를 확인해 보았습니다. 많은 분량의 문서내용 중에서 정확한 데이터를 찾아 빠르게 제공하는 Groq RAG 시스템은 언어 모델의 성능을 더욱 향상시켜주었습니다.
오늘 블로그내용이 AI 활용과 학습에 도움이 되시기를 바라면서, 저는 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.04.22 - [AI 도구] - 🦙Ollama를 활용한 LLAMA3 RAG 시스템 구현하기
🦙Ollama를 활용한 LLAMA3 RAG 시스템 구현하기
안녕하세요! 오늘은 새로운 오픈소스 언어 모델의 최강자 LLAMA 3를 활용한 RAG 시스템을 구현해 보겠습니다. RAG(Retrieval-Augmented Generation, 검색 강화 생성)는 외부 지식소스 검색을 통해 정보를 얻고
fornewchallenge.tistory.com
'AI 도구' 카테고리의 다른 글
| [LLAMA3 활용] ComfyUI 프롬프트 자동 작성 및 유튜브 동영상 요약 10초 완료! (6) | 2024.05.01 |
|---|---|
| LLAMA3 RAG 시스템: AI 어시스턴트로 10초만에 자동 보고서 만들기 (30) | 2024.04.30 |
| 🦙Ollama를 활용한 LLAMA3 RAG 시스템 구현하기 (2) | 2024.04.22 |
| [AI 논문] VASA-1: 마이크로소프트의 초실감 얼굴 생성 기술 (0) | 2024.04.20 |
| [초보 필수] 제미나이 1.5 프로 API 활용 가이드: 40분 오디오 분석 1분 완료! (0) | 2024.04.16 |



