안녕하세요! 오늘은 중국의 알리바바 그룹에서 발표한 오디오 기반 비디오 생성기술 "EMO: Emote Portrait Alive"에 대해 알아보겠습니다. EMO는 주어진 단일 캐릭터의 얼굴이미지를 바탕으로 음성 입력에 동기화된 비디오를 생성하는 인공지능 기술입니다. 이 기술은 캐릭터의 자연스러운 머리 움직임과 생동감 있는 표현이 입력된 음성의 음조 변화와 조화를 이루면서 깜짝 놀랄 만큼 사실적이고 일관된 인물의 모습을 유지합니다. 이 블로그에서는 EMO의 구성요소와 역할, 동작원리, 성능평가 등에 대해서 살펴보겠습니다. 자, 그럼 오드리 헵번을 만나러 가보실까요?

|
|
https://humanaigc.github.io/emote-portrait-alive/
EMO
EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
humanaigc.github.io
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문 개요
- 논문제목 : EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
- 논문저자 : Alibaba Group
- 논문게재 사이트 : https://arxiv.org/abs/2402.17485 -
- 논문게재일 : 2024.2


이 논문의 목적은 "EMO: Emote Portrait Alive"라는 오디오 기반 동영상 생성 인공지능을 제안하고, 이를 통해 목소리 입력에 따라 음성 신호와 얼굴 움직임 간의 동적이고 섬세한 연결관계를 구현하여, 표현력이 풍부한 인물 동영상을 생성하고 현실성과 표현력을 향상시키는 것을 목적으로 합니다.
논문의 연구내용 및 결과
이 논문에서 제시한 EMO는 "Emote Portrait Alive"의 약어로서, 캐릭터 초상화를 살아있게 만드는 기술 또는 프레임워크로서 Audio2Video 확산 모델을 기반으로 합니다. 이 모델은 오디오 입력을 받아들여 표정과 동작을 생성하는 데 사용되며, 오디오 신호를 통해 다이나믹한 표정과 동작을 만들어내기 위해 딥러닝 기술을 이용합니다. 다음 그림은 논문에서 제안한 EMO의 개요도입니다.
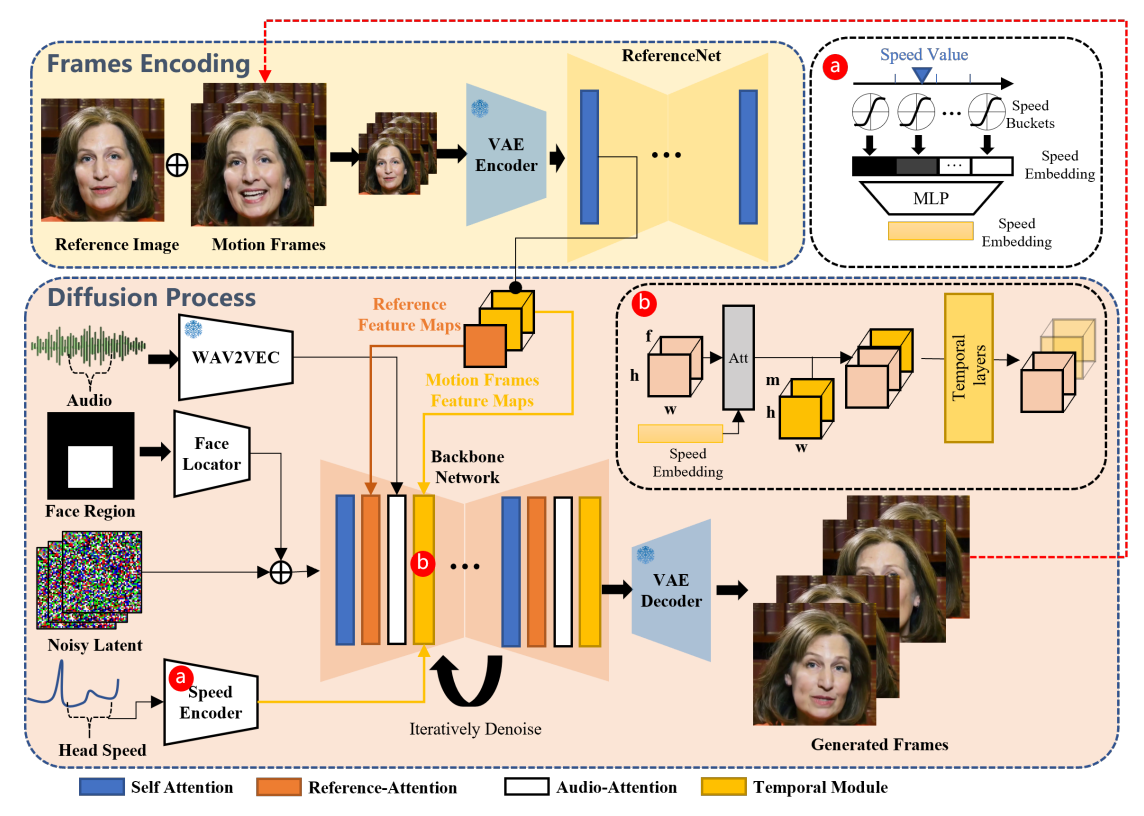
EMO의 구성 요소
위 개요도에서 나타낸 EMO의 주요 구성 요소와 역할은 다음과 같습니다:
- 1. 백본 네트워크(Backbone Network): EMO의 핵심 구성 요소 중 하나로, 초기 프레임을 기반으로 연속적인 비디오 프레임을 생성하고 노이즈를 제거하는 역할을 합니다. 주로 다중 프레임 노이즈를 처리하며, 참조 이미지와 오디오 특성을 통합하여 자연스러운 캐릭터 움직임을 생성합니다. 백본 네트워크는 SD 1.5 UNet 구조를 기반으로 하며, 참조 네트워크에서 추출한 특성을 통합하여 사용합니다.
- 2. WAV2VEC: 음성 신호를 처리하기 위한 사전 훈련된 모델로, 음성을 임베딩하는 데 사용됩니다. 이 모델은 음성 신호의 특징을 추출하여 해당 신호를 벡터 형태로 표현합니다. 이러한 임베딩은 음성 신호의 발음, 억양, 발성 속도 등과 같은 특성을 포함하고 있어서 음성 기반 작업에 유용하게 활용될 수 있습니다.
- 3. 참조 네트워크(ReferenceNet): 백본 네트워크와 유사한 구조를 갖추고 있으며, 입력 이미지에서 자세한 특성을 추출합니다. 이 네트워크는 주어진 이미지에 대해 자세한 정보를 파악하고, 이 정보를 이후의 과정에서 활용하여 캐릭터의 특징을 유지하고 움직임을 생성합니다. 기본적으로 백본 네트워크와 동일한 구조를 가지며, 이미지에서 중요한 부분을 식별하고 추출하는 데 사용됩니다.
- 4. 시간적 모듈(Temporal Modules): 시간적 모듈은 동영상 생성 과정에서 사용되는 기술로, 연속적인 비디오 프레임 간의 시간적 관계를 이해하고 인코딩합니다. 이 모듈은 각각의 프레임이 이전 및 다음 프레임과 어떻게 연결되는지를 파악하여 자연스러운 동영상을 생성하는 데 도움이 됩니다. 이를 통해 생성된 비디오는 시간에 따라 일관되고 부드럽게 이어지며 품질이 향상됩니다.
- 5. 얼굴위치 탐지기(Face Locator): 캐릭터의 얼굴 위치를 자동으로 감지하여 정확한 위치에 얼굴을 생성하는 시스템입니다. 이미지나 비디오에서 얼굴을 탐지하고 해당 위치를 식별하여 캐릭터의 얼굴이 올바르게 배치되도록 보장합니다. 이를 통해 캐릭터의 외관 및 표정이 자연스럽게 생성될 수 있습니다.
- 6. 속도 인코더(Speed encoder): 속도 인코더는 주어진 입력에서 특정 속도 정보를 추출하는 역할을 합니다. 이것은 주로 생성된 캐릭터의 동적인 속도 정보를 인코딩하는 데 사용되며, 캐릭터의 머리가 움직이는 속도를 추출하여 캐릭터의 동작을 조절하는 데 활용될 수 있습니다.
EMO는 입력 음성 및 참조 이미지로부터 캐릭터의 움직임을 생성하고 제어하기 위해 백본 네트워크, WAV2VEC 등 여러 가지 요소를 통합하고, 이를 통해 음성 및 이미지 정보가 결합된 자연스러운 캐릭터 움직임을 생성할 수 있습니다.
|
|
| Character: AI Lady from SORA Vocal Source: Dua Lipa - Don't Start Now |
EMO의 동작원리
이러한 구성요소들의 동작은 입력으로 들어온 참조 이미지와 오디오 데이터를 처리하여 초기 프레임의 특성을 결정하는 "프레임 인코딩(Frames Encoding)" 단계와 초기 프레임을 기반으로 실제 동영상을 생성하는 "확산 과정(Diffusion Process)" 단계로 나누어집니다.
프레임 인코딩(Frames Encoding) 단계는 EMO의 초기 단계로, 참조 이미지와 모션 프레임에서 특징을 추출하여 초기 프레임의 특성을 결정하며, 다음과 같은 순서로 진행됩니다:
- 1. 참조 이미지 특성 추출: 참조 이미지는 ReferenceNet을 통해 상세한 특성을 추출 합니다. ReferenceNet은 Backbone Network와 동일한 구조를 가지며, 이미지의 중요한 부분을 식별하고 추출하는 데 사용됩니다.
- 2. 모션 프레임 특성 추출: 이전에 생성된 동영상 클립에서 가져온 마지막 n개의 프레임에서 모션에 관한 특성 맵을 추출합니다. 이전 클립에서의 움직임을 캡처하여 이후 클립과의 일관성을 유지하는 데 사용됩니다.
- 3. VAE Encoder를 통한 특성 결합: 참조 이미지와 모션 프레임에서 추출된 특성을 VAE Encoder를 통해 저 차원의 잠재 공간으로 인코딩합니다. 이러한 잠재 변수는 캐릭터의 특성을 더 쉽게 처리하고 분석하는 데 사용됩니다.
- 4. 초기 프레임의 특성 결정: 참조 이미지, 모션 프레임, VAE Encoder를 통해 결합된 특성을 통합하여 초기 프레임의 특성을 결정합니다. 이를 통해 캐릭터의 초기 상태와 동작을 설정하고 이후의 동영상 생성 과정을 준비합니다.
프레임 인코딩 단계를 통해 초기 프레임의 특성이 결정되고, 이후의 단계에서 이를 기반으로 캐릭터의 움직임을 생성하고 노이즈를 제거하는 작업이 진행됩니다.
확산 과정(Diffusion Process)은 EMO의 두 번째 단계로, 초기 프레임을 기반으로 캐릭터의 움직임을 생성하고 노이즈를 제거하여 비디오를 완성하는 과정이며, 다음과 같은 순서로 진행됩니다:
- 1. 오디오 특성 추출(WAV2VEC): 오디오 입력은 사전 훈련된 WAV2VEC 모델을 통해 특성으로 변환됩니다. 이 특성은 음성의 발음, 음조 등의 정보를 포함하고 있습니다.
- 2. 얼굴 위치 결정(Face Locator): 얼굴 위치 탐지기를 사용하여 캐릭터의 얼굴이 생성될 위치를 결정합니다. 이를 통해 캐릭터의 얼굴이 올바른 위치에 생성되도록 합니다.
- 3. 노이즈 추가 및 참조 특성 통합(Noisy Latent, Reference Feature Maps): 초기 프레임에 노이즈를 추가하고, 참조 이미지의 특성을 통합합니다. 이를 통해 캐릭터의 움직임을 더 자연스럽게 만들고, 참조 이미지의 특성을 적절히 반영합니다.
- 4. 속도 인코더 사용(Speed Encoder): 캐릭터의 머리 움직임 속도를 추출하기 위해 속도 인코더를 사용합니다. 이를 통해 캐릭터의 머리가 자연스럽게 움직이도록 합니다.
- 5. 백본 네트워크를 통한 노이즈 제거(Backbone Network): 백본 네트워크를 사용하여 노이즈를 제거하고, 캐릭터의 움직임을 부드럽게 만듭니다.
- 6. 참조 특성과 모션 프레임 특성 통합: 참조 특성과 모션 프레임 특성을 통합하여 캐릭터의 움직임을 조절하고, 시간에 따른 일관성을 유지합니다.
이러한 확산 과정을 통해 EMO는 초기 프레임을 기반으로 캐릭터의 움직임을 생성하고 노이즈를 제거하여 완성된 비디오를 생성합니다.
|
|
| Character: AI Girl generated by ChilloutMix Vocal Source: David Tao - Melody. Covered by NINGNING (mandarin) |
EMO의 성능평가
논문에서는 제안된 기술의 성능을 다양한 방법으로 평가했습니다. 이러한 평가 결과에 따르면 제안된 기술은 기존의 방법보다 더 나은 표정과 동작을 생성할 수 있으며, 다양한 조건에서도 안정적으로 동작함을 확인할 수 있습니다.
EMO의 성능을 정량적 측면과 정성적 측면에서 평가한 내용은 아래와 같습니다.
- 정량적 비교: 정량적 비교에서는 FID(Fréchet Inception Distance), SyncNet, F-SIM(Facial Similarity Index Metric), FVD(Frechet Video Distance), E-FID(Extended FID)와 같은 다양한 지표를 사용합니다. 아래 표에서는 EMO를 다른 토킹 헤드 생성 모델과 비교한 결과를 보여줍니다. EMO는 FID 및 SyncNet 점수에서는 높은 품질의 결과를 보이지 않지만, FVD 및 E-FID 점수에서 상당한 우위를 보입니다. 특히, 낮은 FVD 점수는 비디오 품질 평가에서 우수함을 나타냅니다. 아래 더 보기를 클릭하시면 각 지표에 대한 설명을 보실 수 있습니다.
* FID (Fréchet Inception Distance): 생성된 이미지와 실제 이미지 간의 차이를 측정하는 지표입니다. 고해상도 이미지의 품질을 평가할 때 주로 사용됩니다.
* SyncNet: 음성과 비디오의 동기화 정확도를 측정하는 지표입니다. 음성과 비디오 간의 일치 정도를 평가합니다.
* F-SIM (Facial Similarity Index Metric): 얼굴 이미지의 유사성을 측정하는 지표입니다. 생성된 얼굴 이미지와 실제 얼굴 이미지 간의 유사성을 평가합니다.
* FVD (Frechet Video Distance): 생성된 비디오와 실제 비디오 간의 차이를 측정하는 지표입니다. 비디오 품질의 객관적인 측정을 제공합니다.
* E-FID (Extended FID): FID를 확장하여 생성된 비디오나 이미지의 품질을 평가하는 지표입니다. 특히, 비디오 생성 모델에 적합한 지표로서 사용됩니다.

- 정성적 비교: 정성적 비교에서는 생성된 비디오 및 이미지의 시각적 품질과 실제성을 평가합니다. EMO의 결과물을 다른 토킹 헤드 생성 모델과 비교한 시각적 결과를 보면, EMO는 다이나믹한 얼굴 표정 및 더 많은 머리 움직임을 생성할 수 있으며, 다양한 얼굴 스타일에 대한 생성 성능을 보입니다. 이와 같이, 정량적 비교와 정성적 비교를 통해 EMO의 탁월한 성능을 확인할 수 있습니다.
|
|
| Character: Audrey Kathleen Hepburn-Ruston Vocal Source: Ed Sheeran - Perfect. Covered by Samantha Harvey |
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문의 결론 및 전망
이 논문은 EMO라는 새로운 접근 방식을 통해 오디오를 기반으로 인물의 동영상을 생성하는 기술을 제시하였습니다. 실험 결과, EMO는 기존의 다른 방법에 비해 더 다양한 얼굴 움직임과 동적인 표정을 생성할 수 있음을 입증했습니다. 또한, 다양한 캐릭터 스타일에 대한 유연성을 갖추고 있으며, 주어진 음성에 따라 적절한 동작을 생성함으로써 더욱 자연스러운 대화 시나리오를 구현할 수 있는 기술임을 확인하였습니다.
향후에는 이러한 기술을 활용하여 가상 캐릭터 기반의 상호 작용 및 컨텐츠 생성과 음성 기반 피드백을 통한 인간과 AI의 자연스러운 상호 작용이 가능하게 될 것으로 전망됩니다. 저도 데모 동영상을 보면서 소름이 몇 번 돋았는데요, 정말 AI 기술의 발전은 우리의 상상을 모두 현실로 가능하게 만들 수 있을 것 같습니다.
오늘 내용은 여기까지입니다. 저는 그럼 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.02.23 - [AI 논문 분석] - 🚀 SDXL-Lightning: 스테이블 디퓨전 기반 초고속 이미지 생성 기술 심층 분석
🚀 SDXL-Lightning: 스테이블 디퓨전 기반 초고속 이미지 생성 기술 심층 분석
안녕하세요! 오늘은 틱톡으로 유명한 중국의 IT기업, ByteDance에서 개발한 SDXL-Lightning이라는 이미지 생성모델에 대한 논문을 살펴보겠습니다. SDXL-Lightning은 " 점진적 적대적 확산 증류(Progressive Adve
fornewchallenge.tistory.com
'AI 논문 분석' 카테고리의 다른 글
| LATTE3D: 엔비디아의 새로운 텍스트 기반 3D 생성 기술 (0) | 2024.03.25 |
|---|---|
| MM1: 애플의 새로운 멀티모달 언어 모델 (0) | 2024.03.21 |
| 🚀 SDXL-Lightning: 스테이블 디퓨전 기반 초고속 이미지 생성 기술 심층 분석 (2) | 2024.02.23 |
| 뤼미에르: 구글의 텍스트 기반 비디오 생성의 새로운 기준 (4) | 2024.02.08 |
| OLMo(Open Language Model) : 완전한 오픈소스 대형 언어 모델 (0) | 2024.02.04 |



