안녕하세요! 오늘은 최근 공개된 ComfyUI의 IP-Adapter plus를 이용해서 오프라인 로컬 가상 피팅을 구현해 보겠습니다. 가상 피팅은 디지털 이미지나 가상의 모델을 사용하여 자신이 옷을 입은 모습을 시뮬레이션하여 미리 확인하는 것을 말하는데요, 온라인 쇼핑이나 의류 브랜드의 웹사이트에서 제공하고 있는 기능이지만 내 사진으로, 내가 원하는 포즈로, 내가 원하는 장소에서의 모습으로 자유롭게 미리 확인해 보는 것은 쉽지 않은데요. 이 블로그에서는 ComfyUI의 IPAdapter plus를 이용해서 내 컴퓨터에서 오프라인으로 가상 피팅을 체험해 보겠습니다.

아래 이미지들은 ComfyUI의 IPAdapter plus를 이용해서 생성한 가상 피팅 이미지들입니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
IP-Adapter 란?
IP-Adapter는 텍스트를 이미지로 변환하는 딥러닝 모델인 확산 모델(diffusion model)에 이미지 프롬프트(image prompt)를 적용하기 위한 어댑터입니다. 이 모델은 텍스트 입력에 대해 이미지를 생성하는 기존의 텍스트-이미지 확산 모델에 이미지를 조건으로 추가할 수 있는 기능을 제공합니다. 이를 통해 사용자는 이미지 프롬프트를 통해 특정 이미지 요소가 반영된 이미지를 생성할 수 있습니다. 아래 링크는 IP-Adapter에 대한 자세한 내용을 다룬 논문입니다.
https://arxiv.org/abs/2308.06721
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Recent years have witnessed the strong power of large text-to-image diffusion models for the impressive generative capability to create high-fidelity images. However, it is very tricky to generate desired images using only text prompt as it often involves
arxiv.org
IP-Adapter 구성 요소
IP-Adapter는 텍스트-이미지 확산 모델을 사용하여 이미지 프롬프트를 통해 이미지를 생성하는 데 사용됩니다. 이 모델은 두 가지 주요 구성 요소로 이루어져 있습니다.
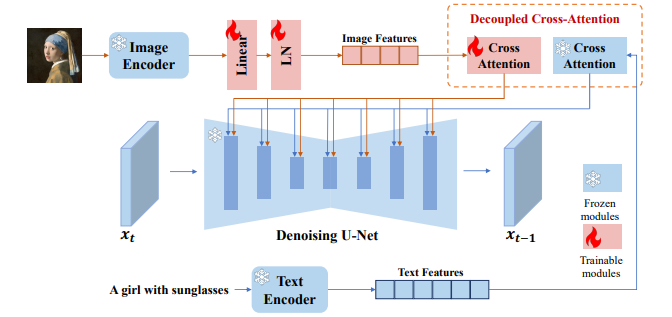
- 이미지 인코더(Image Encoder): 이 구성 요소는 이미지 프롬프트에서 이미지 특성을 추출하는 역할을 합니다. 일반적으로 사전 훈련된 CLIP 이미지 인코더 모델을 사용하여 이미지 특성을 추출합니다. 추출된 이미지 특성은 후속 과정에서 활용됩니다.
- 분리 교차-주의 모듈(Decoupled Cross-Attention Module): 이 모듈은 텍스트 및 이미지 특성을 결합하여 텍스트-이미지 확산 모델의 입력으로 제공합니다. 기존의 텍스트 특성과 함께 이미지 특성을 결합하기 위해 새로운 교차-주의 계층이 추가됩니다. 이때, 텍스트 특성 및 이미지 특성에 대한 교차-주의 계층은 분리되어 작동하여 이미지 프롬프트를 효과적으로 반영합니다.
이러한 구성 요소를 통해 IP-Adapter는 이미지 프롬프트를 사용하여 텍스트-이미지 확산 모델을 제어하고, 더욱 효율적으로 이미지 생성을 수행할 수 있습니다.
IP-Adapter 동작순서
IP-Adapter의 동 순서는 다음과 같습니다:
- 1. 이미지 특성 추출: 먼저, 이미지 프롬프트에서 이미지 특성을 추출합니다. 주로 사전 훈련된 CLIP 이미지 인코더 모델을 사용하여 이미지 특성을 추출합니다.
- 2. 이미지 특성의 분해: 추출된 이미지 특성을 CLIP 이미지 인코더에서 추출된 텍스트 특성과 동일한 차원의 특성으로 변환합니다. 이를 위해 작은 학습 가능한 프로젝션 네트워크를 사용하여 이미지 특성을 텍스트 특성과 동일한 차원으로 변환합니다.
- 3. 텍스트-이미지 확산 모델에 대한 분해된 이미지 특성 삽입: 분해된 이미지 특성은 텍스트-이미지 확산 모델에 삽입됩니다. 이때, 삽입되는 방식은 분리된 크로스 어텐션 메커니즘을 사용합니다. 즉, 이미지 특성과 텍스트 특성을 개별적으로 처리하는 별도의 크로스 어텐션 레이어를 사용하여 이미지 특성을 적절하게 삽입합니다.
- 4. 이미지 생성: 삽입된 이미지 특성을 기반으로 텍스트-이미지 확산 모델에서 이미지를 생성합니다. 이 과정에서는 확산 모델이 텍스트 특성과 이미지 특성을 고려하여 이미지를 생성하게 됩니다.
- 5. 이미지 생성 결과 반환: 생성된 이미지가 반환되어 사용자에게 제공됩니다.
이렇게 IP-Adapter는 이미지 프롬프트를 활용하여 이미지를 생성하는 과정에서 이미지 특성을 효과적으로 삽입하여 제어 가능한 이미지 생성을 달성합니다.
IP-Adapter plus 설치
IP-Adapter plus를 설치하기 위해서는 먼저 피노키오 AI 브라우저와 ComfyUI를 설치해야 하는데요. 피노키오 AI 브라우저는 다양한 AI 도구들을 원클릭으로 설치하도록 지원하는 브라우저이며, 여기서 손쉽게 설치하실 수 있습니다.
ComfyUI 설치
다음은 피노키오 AI 브라우저를 이용해서 ComfyUI를 설치해 줍니다. 피노키오 AI를 다운로드 후 설치하면 Discover 메뉴에서 ComfyUI를 원클릭으로 쉽게 설치할 수 있습니다.


다음은 ComfyUI에서 사용할 기본 모델 "Juggernaut XL"을 아래 링크에서 다운로드하여
C:\Users\사용자이름\pinokio\api\comfyui.git\app\models\checkpoints 폴더에 복사합니다.
https://civitai.com/models/133005/juggernaut-xl
Juggernaut XL - V9 + RunDiffusionPhoto 2 | Stable Diffusion Checkpoint | Civitai
For business inquires, commercial licensing, custom models, and consultation contact me under juggernaut@rundiffusion.com Juggernaut is available o...
civitai.com
깃허브 레포지토리 복제 및 파일 다운로드
다음은 C:\Users\사용자명\pinokio\api\comfyui.git\app\custom_nodes 디렉토리에서 오른쪽 마우스 클릭 후 명령어 프롬프트를 실행한 후, ComfyUI Manager와 IP-Adapter plus 깃허브 레포지토리를 복제합니다.
git clone https://github.com/ltdrdata/ComfyUI-Manager.gitgit clone https://github.com/cubiq/ComfyUI_IPAdapter_plus.git
복제가 완료되었으면, 이제 IP-Adapter plus 파일을 다운로드할 차례입니다. 아래 깃허브 링크에 접속해서 밑에 표에 정리된 파일 12개를 다운로드하여 설명에 따라 이름을 변경하고 지정된 디렉토리에 저장합니다. "Deprecated"라고 표시된 파일은 다운로드하지 않습니다.
https://github.com/cubiq/ComfyUI_IPAdapter_plus?tab=readme-ov-file
GitHub - cubiq/ComfyUI_IPAdapter_plus
Contribute to cubiq/ComfyUI_IPAdapter_plus development by creating an account on GitHub.
github.com
다운로드하는 12개 파일의 파일명과 저장위치, 설명을 정리하면 다음과 같습니다.
| 디렉토리 및 파일명 | 설명 |
| C:\Users\사용자명\pinokio\api\comfyui.git\app\models\clip_vision | |
| CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors | 다운로드 및 이름 변경 필요 |
| CLIP-ViT-bigG-14-laion2B-39B-b160k.safetensors | 다운로드 및 이름 변경 필요 |
| C:\Users\사용자명\pinokio\api\comfyui.git\app\models\ipadapter | 디렉토리가 없을 경우 생성 |
| ip-adapter_sd15.safetensors | 기본 모델, 평균적인 세기 |
| ip-adapter_sd15_light_v11.bin | 경량 모델 |
| ip-adapter-plus_sd15.safetensors | Plus 모델, 매우 강함 |
| ip-adapter-plus-face_sd15.safetensors | 얼굴 모델, 초상화 |
| ip-adapter-full-face_sd15.safetensors | 더 강력한 얼굴 모델, 반드시 더 나은 것은 아님 |
| ip-adapter_sd15_vit-G.safetensors | 기본 모델, bigG 클립 비전 인코더 필요 |
| ip-adapter_sdxl_vit-h.safetensors | SDXL 모델 |
| ip-adapter-plus_sdxl_vit-h.safetensors | SDXL Plus 모델 |
| ip-adapter-plus-face_sdxl_vit-h.safetensors | SDXL 얼굴 모델 |
| ip-adapter_sdxl.safetensors | vit-G SDXL 모델, bigG 클립 비전 인코더 필요 |
ComfyUI 가상 피팅
모든 파일의 저장이 완료되면 ComfyUI를 실행하는 단계입니다. ComfyUI 실행은 피노키오 AI 브라우저에서 ComfyUI 아이콘을 클릭하고 화면 좌측의 Start를 클릭하면 http://127.0.0.1:8188/ 주소에서 ComfyUI 메인 화면이 열립니다. 다음은 ComfyUI에서 사용할 워크플로우를 아래 파일을 클릭하여 다운로드하고 화면 우측의 ComfyUI Manager 메뉴에서 Load를 클릭하여 불러옵니다.
워크플로우를 불러온 후, 가상으로 피팅할 옷의 이미지를 워크플로우 아래 좌측 이미지를 저장하여 불러옵니다. 각 노드들의 값을 그림을 참조하여 설정하고, 우측 상단의 "Queue Prompt"를 클릭하시면 프로세스가 시작됩니다.
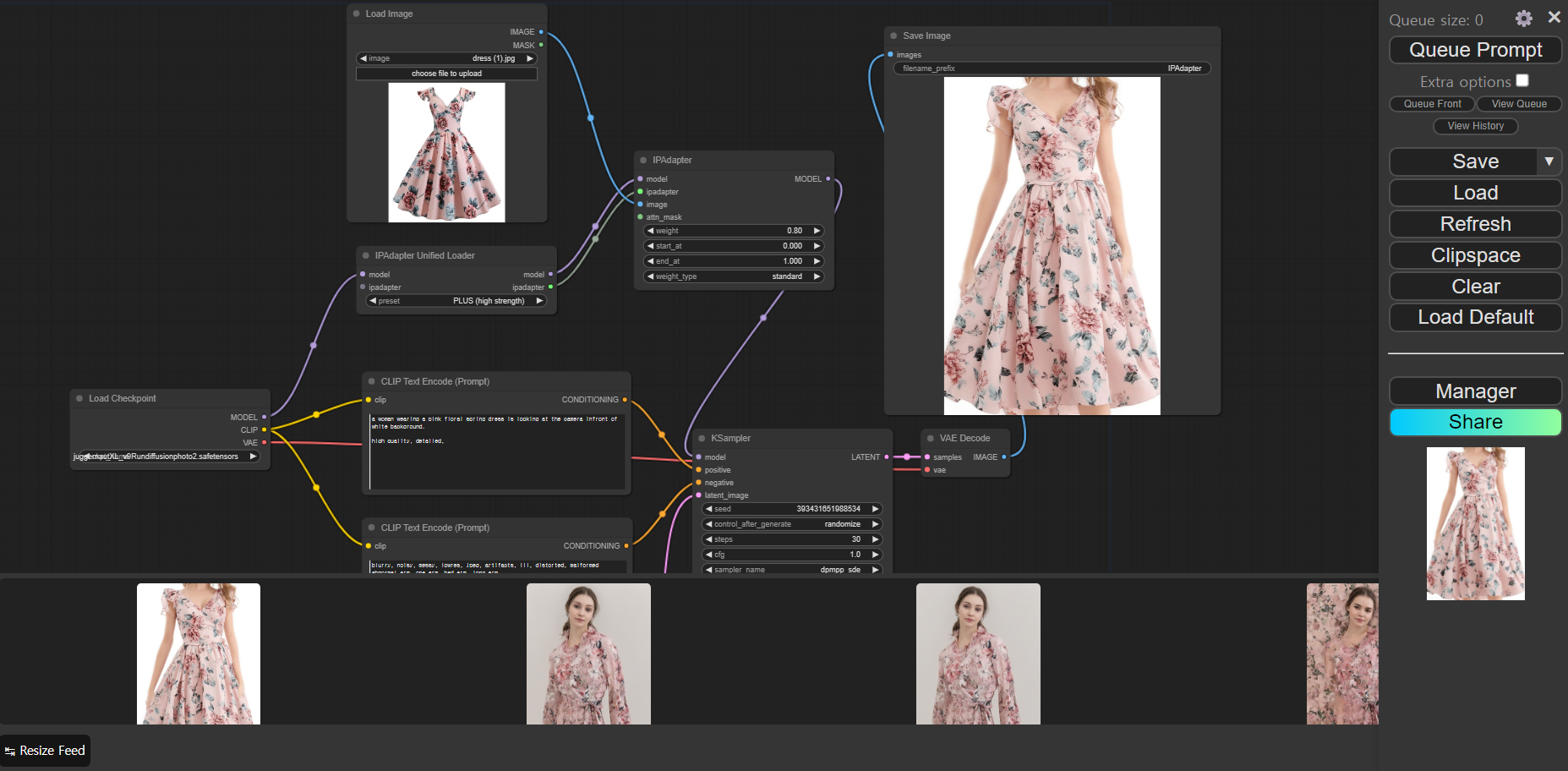
아래 우측 이미지는 IPAdapterplus.json 워크플로우의 실행결과입니다.




다음은 얼굴이미지와 함께 가상으로 옷을 피팅해 보는 워크플로우인데요, 자신의 얼굴사진을 이용해서 옷을 입었을 때의 모습을 시뮬레이션해 볼 수 있습니다. 위에서 진행한 방법과 동일하게 아래 링크에서 demo.json 파일을 저장하여 불러옵니다. 아래 화면을 참고하여 얼굴 이미지와 옷의 이미지를 불러오고 설정값을 참조하여 프로세스를 실행합니다.

위에서 실행해 본 두 가지 워크플로우에서 사용한 Positive, Negative 텍스트 프롬프트는 아래와 같습니다.
A woman wearing a long deep pink v-neck flared short cap sleeve floral pleats dress is standing in front of white back ground.
full body shot, high quality, detailed.blurry, noisy, messy, lowres, jpeg, artifacts, ill, distorted, malformed,
bad fingers, many fingers, bad legs, three arms


맺음말
오늘은 ComfyUI의 IPAdapter plus를 이용해서 오프라인으로 로컬 가상 피팅을 구현해 보는 방법을 알아보았습니다. IPAdapter plus는 텍스트 프롬프트와 이미지를 활용하여 이미지를 생성하는 강력한 도구이며, 이를 통해 우리는 내 사진, 내가 원하는 포즈, 내가 원하는 장소에서의 모습으로 자유롭게 가상 피팅을 해볼 수 있습니다.
블로그에서 소개된 두 가지 워크플로우를 통해 기본적인 가상 피팅과 얼굴 이미지를 활용한 가상 피팅까지 활용방법을 알아보았습니다. 여러분도 직접 ComfyUI와 IPAdapter plus를 사용해서 자신만의 가상 피팅을 경험해 보시면 어떨까요? 오늘 블로그는 여기까지입니다. 저는 그럼 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.02.23 - [AI 논문 분석] - 🚀 SDXL-Lightning: 스테이블 디퓨전 기반 초고속 이미지 생성 기술 심층 분석
🚀 SDXL-Lightning: 스테이블 디퓨전 기반 초고속 이미지 생성 기술 심층 분석
안녕하세요! 오늘은 틱톡으로 유명한 중국의 IT기업, ByteDance에서 개발한 SDXL-Lightning이라는 이미지 생성모델에 대한 논문을 살펴보겠습니다. SDXL-Lightning은 " 점진적 적대적 확산 증류(Progressive Adve
fornewchallenge.tistory.com
'AI 도구' 카테고리의 다른 글
| [AI 논문] VASA-1: 마이크로소프트의 초실감 얼굴 생성 기술 (0) | 2024.04.20 |
|---|---|
| [초보 필수] 제미나이 1.5 프로 API 활용 가이드: 40분 오디오 분석 1분 완료! (0) | 2024.04.16 |
| 🤯허깅챗 어시스턴트 영어 뉴스 번역 챗봇 만들기! URL만 입력하면 끝! (1) | 2024.04.03 |
| PraisonAI: 명령어 1줄! 코드 없이 AI 에이전트로 영화 대본 만들기 (0) | 2024.03.28 |
| 오픈소스 AI 엔지니어 Devika 체험: 계획-검색-코딩 자동화 성공! (0) | 2024.03.24 |



