안녕하세요! 오늘은 알리바바 클라우드의 Qwen 팀에서 개발한 최첨단 시각적 추론 AI 모델인 QVQ-Max에 대해 자세히 알아보겠습니다. 2025년 3월 28일 공개된 이 모델은 무려 720억 개의 파라미터를 자랑하며, 단순 이미지와 비디오 분석을 넘어 심층적인 추론과 문제 해결 능력을 갖춘 혁신적인 시각적 추론 AI로 주목받고 있습니다. QVQ-Max는 복잡한 차트, 다이어그램, 일상 사진 등 다양한 시각적 입력을 세밀하게 분석하고, 이를 바탕으로 배경 지식과 통합하여 심층적인 이해와 추론을 수행할 수 있는 모델입니다. 이번 블로그에서는 QVQ-Max의 핵심 특징, 사용 방법 및 성능 테스트 결과를 상세히 살펴보겠습니다.

1. QVQ-Max 개요
알리바바의 Qwen 팀에서 개발한 QVQ-Max는 720억 개의 파라미터를 가진 최첨단 시각적 추론 AI 모델입니다. 2025년 3월 28일에 공식적으로 발표된 이 모델은 단순한 이미지 및 비디오 콘텐츠 이해를 넘어, 정보를 분석하고 추론하여 다양한 문제에 대한 해결책을 제시하는 것을 목표로 합니다.
| 모델명 | 파라미터 수 | 입력 | 출력 |
| QVQ-Max | 72B | 이미지, 비디오, 텍스트 | 텍스트 |
QVQ-Max는 수학 문제부터 일상적인 질문, 프로그래밍 코드, 예술 창작에 이르기까지 광범위한 분야에서 잠재력을 보여주고 있습니다. 이는 전통적인 AI 모델이 텍스트 입력에 주로 의존하는 한계를 넘어, 실생활의 풍부한 시각 정보를 이해하고 활용함으로써, 단순히 "보는" 것을 넘어 "이해하고 생각하는" 단계로 나아가는 진전이라고 할 수 있습니다.
2. QVQ-Max 특징 및 주요 기능
QVQ-Max의 핵심 기능은 크게 세 가지 영역, 즉 세밀한 관찰, 깊이 있는 추론, 유연한 응용으로 요약할 수 있습니다.
1) 세밀한 관찰: 모든 디테일 포착
- QVQ-Max는 복잡한 차트부터 일상적인 스냅사진까지 다양한 이미지를 세밀하게 분석합니다.
- 이미지 속 주요 객체는 물론 미묘한 요소까지 신속하게 식별할 수 있습니다. 예를 들어, 사진 속 사물의 종류, 텍스트 레이블의 존재 여부, 심지어 사용자가 간과할 수 있는 작은 디테일까지 정확하게 파악합니다.
2) 깊이 있는 추론: 단순히 보는 것을 넘어 생각하기
- 시각-맥락 분석을 통해 단순한 식별을 넘어 시각 데이터를 배경 지식과 통합하여 심층적인 분석을 수행하고 정보에 입각한 결론을 내립니다.
- 다이어그램 기반 문제 해결에 탁월한 능력을 보입니다. 예를 들어, 기하학 문제에서 제공된 다이어그램을 이해하고 이를 바탕으로 정답을 도출합니다.
- 다중 모달 통합 능력을 통해 시각적 입력과 개념에 대한 이해를 융합하여 다양한 시나리오에서 정교한 추론을 가능하게 합니다. 여러 이미지를 동시에 처리하고 분석하여 인간이 놓칠 수 있는 패턴을 감지할 수 있습니다. 의료 영상, 보안 영상, 산업 품질 관리 등에 유용하게 활용될 수 있습니다.
3) 유연한 응용: 문제 해결부터 창작까지
- 분석 및 추론 능력을 넘어, QVQ-Max는 일러스트레이션 디자인, 짧은 비디오 스크립트 생성, 사용자 요구 사항 기반 롤플레잉 콘텐츠 제작 등 흥미로운 작업도 수행할 수 있습니다.
- 내러티브(Narrative) 콘텐츠 생성 능력을 활용하여 짧은 비디오 스크립트, 롤플레잉 콘텐츠 또는 사용자 맞춤형 내러티브 자료를 생성할 수 있습니다.
3. QVQ-Max 벤치마크 결과
QVQ-Max의 공식 벤치마크 결과는 아직 공개되지 않았습니다. 하지만, QVQ-Max의 이전 버전인 QVQ-72B-Preview는 MathVision mini에서 71.4%, MathVision full에서 35.9%의 점수를 기록했으며. MathVision 벤치마크에서 QVQ-Max모델의 사고 과정 최대 길이를 조정함에 따라 정확도가 지속적으로 향상되는 것이 확인되었습니다.
이 외에도 QVQ-72B-Preview는 MMMU 70.3%, OlympiadBench 20.4%의 점수를 기록하여 멀티모달 이해와 시각적 입력 기반 수학적 추론 능력의 우수성을 입증했습니다.
4. QVQ-Max 사용 방법
QVQ-Max는 현재 Qwen Chat 플랫폼과 데모 사이트를 통해 무료로 사용해 볼 수 있습니다.
1) Qwen Chat 플랫폼: https://chat.qwen.ai/
2) 데모 사이트: https://qvqmax.com/
데모 사이트는 Gradio 인터페이스로 제작되었으며, 텍스트와 이미지 프롬프트만 입력할 수 있고, 모델에 대한 설명과 예제 프롬프트, FAQ를 확인할 수 있습니다.
5. QVQ-Max 성능 테스트
다음은 QVQ-Max의 성능을 테스트해 보겠습니다. 테스트는 Qwen Chat 플랫폼과 데모 사이트에서 진행하였습니다.
1) 이미지 이해 테스트: Grok이 생성한 테스트 이미지를 입력하고 설명을 요청하였습니다.
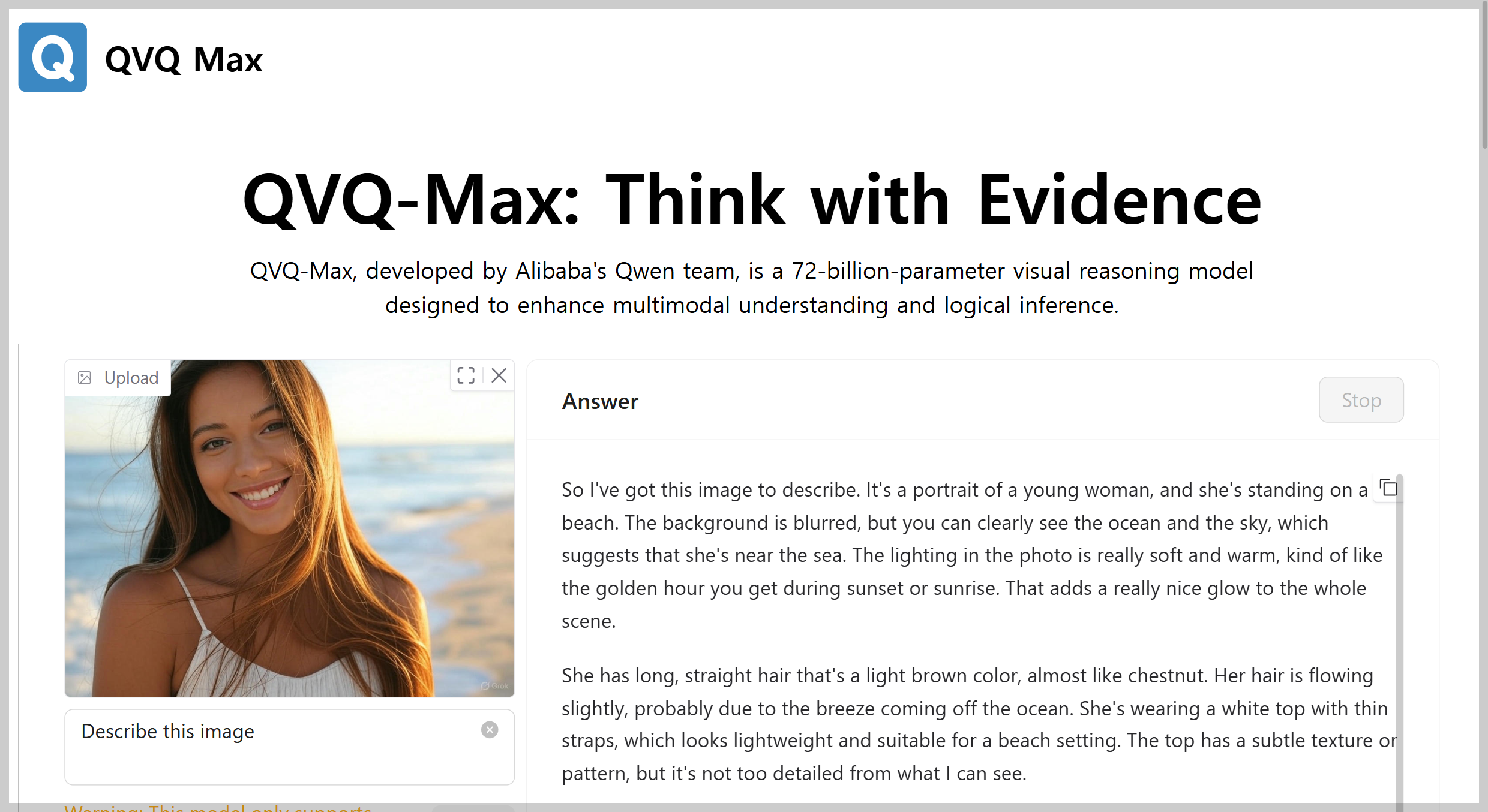
QVQ-Max는 이미지를 상세하게 묘사하고 우측 하단의 "Grok" 워터마크도 잘 관찰하였습니다만, 목에 실버 액세서리가 보인다는 표현은 머리카락과 혼동한 거 같습니다.
이미지는 해변에서 촬영된 젊은 여성의 모습을 담고 있습니다.
* 주인공 :
- 긴 갈색 머리카락이 바람에 흩날리며 자연스러운 움직임을 보여줍니다.
- 밝은 미소와 반짝이는 눈빛으로 활기찬 분위기를 자아냅니다.
- 흰색 스파게티 스트랩 상의를 입고 있으며, 목에는 가느다란 실버 액세서리가 보입니다.
* 배경 :
- 맑은 하늘과 잔잔한 파도가 보이는 해변 풍경입니다.
- 모래사장과 물결이 흐릿하게 블러 처리되어 주인공을 강조합니다.
* 빛과 색감 :
- 따뜻한 황금빛 조명(일몰 또는 석양 분위기)이 피부와 머리카락에 부드럽게 비치며 포근하고 평화로운 느낌을 줍니다.
* 전체적인 분위기 :
- 여유롭고 경쾌한 여름휴가의 순간을 연상시키며, 자연과의 조화 속에서의 행복감이 잘 표현되었습니다.
(오른쪽 하단에 "Grok"이라는 워터마크가 표시되어 있습니다.)
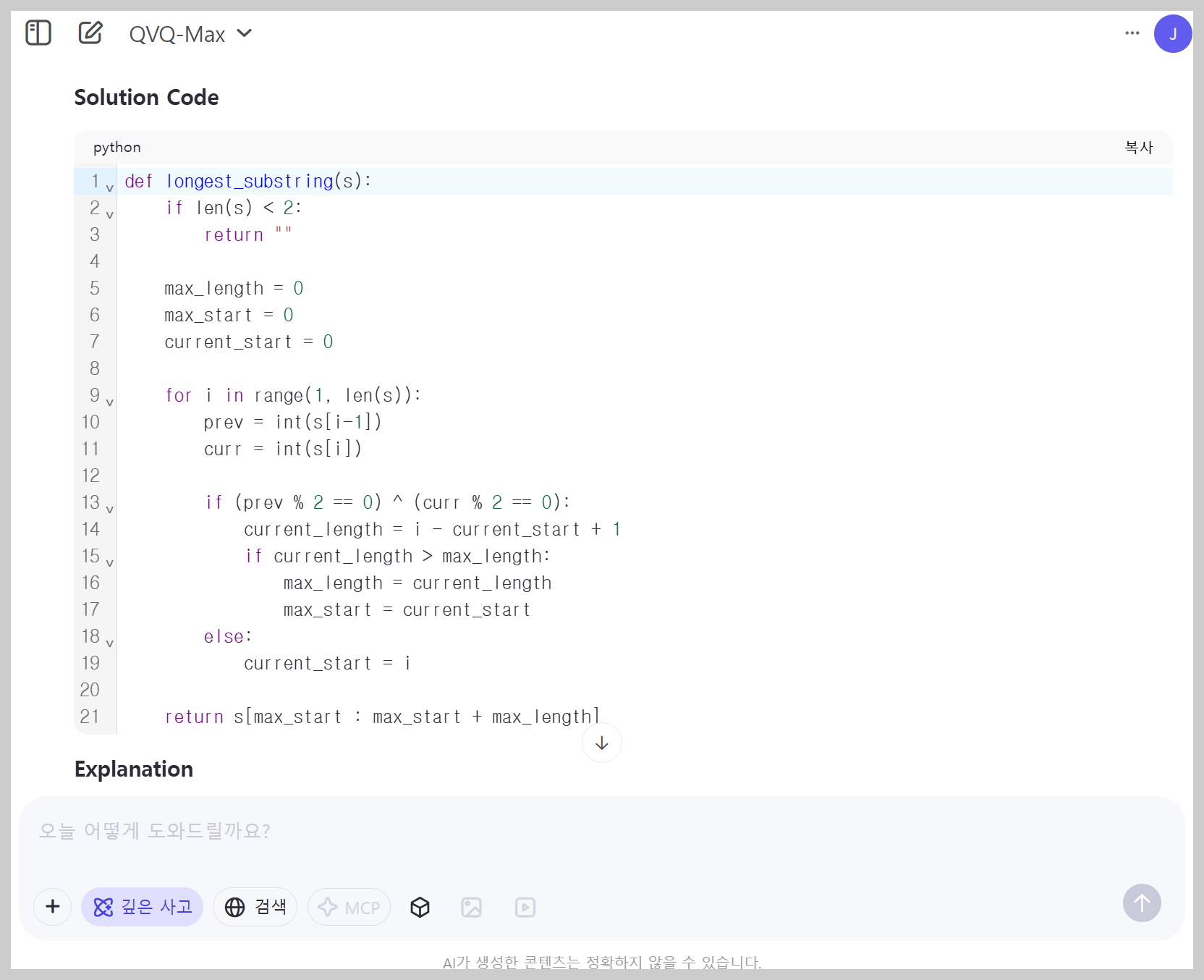
2) 시각정보 기반 코딩 테스트: Python Expert 난이도 문제 이미지 파일을 업로드하고, 문제를 풀도록 요청하였습니다.

3) 다이아그램 이해 테스트: Qwen2.5-Omni 모델 아키텍처 다이아그램의 동작설명을 요청하였습니다.
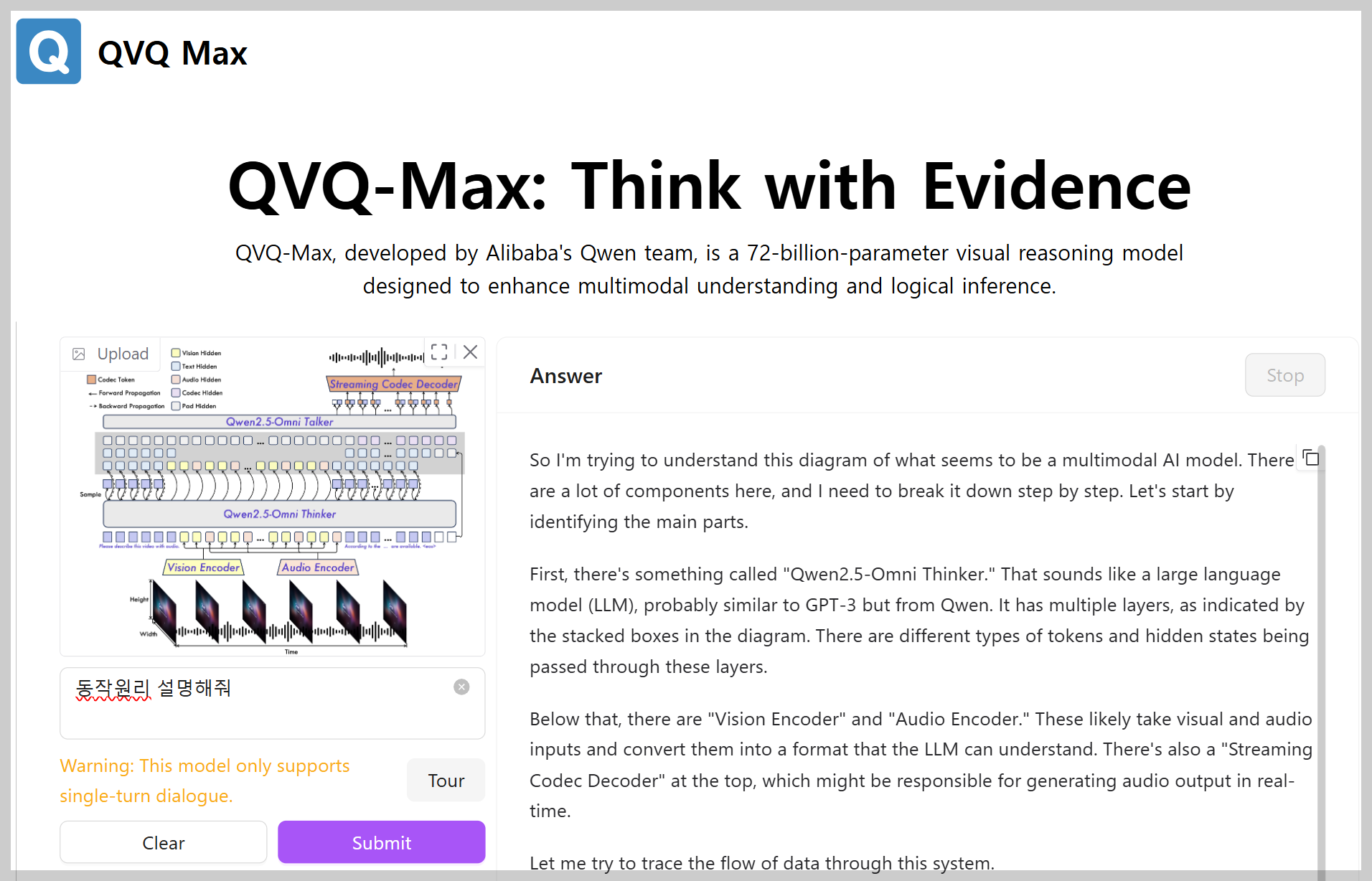
QVQ-Max는 아키텍처의 다이아그램을 참조하여, 동작을 잘 설명하였습니다.
| QVQ-Max 답변 |
 |
| QVQ-Max 답변 번역 | 최종 답변 해당 시스템이 어떻게 작동하는지에 대한 질문에 대답하기 위해서는 제공된 다이어그램을 이해해야 합니다. 다이어그램은 시각적 데이터와 오디오 데이터를 모두 처리하여 비디오의 오디오 설명을 생성하는 다중 모달 AI 모델을 나타내는 것으로 보입니다. 다음은 시스템의 아키텍처와 데이터 흐름에 대한 단계별 설명입니다: 1. 입력 인코딩: - 비전 인코더: 이 구성 요소는 시간 경과에 따른 이미지 시퀀스(높이와 너비 차원이 있는 타임라인으로 표시됨)를 가져와 시각적 표현으로 인코딩합니다. - 오디오 인코더: 이 구성 요소는 시간 경과에 따른 오디오 신호를 가져와 오디오 표현으로 인코딩합니다. 2. 언어 모델 처리: - Qwen2.5-Omni Thinker: 이 대규모 언어 모델(LLM)은 비전 및 오디오 인코더의 특징을 처리합니다. 이러한 모달리티를 결합하여 비디오의 내용을 이해하는 것으로 보입니다. - Qwen2.5-Omni Talker: 이 구성 요소는 Omni Thinker의 출력을 기반으로 텍스트 또는 오디오 설명을 생성합니다. 3. 출력 생성: - 스트리밍 코덱 디코더: 이 구성 요소는 Omni Talker의 출력을 가져와 실시간으로 재생할 수 있는 오디오 스트림으로 변환합니다. 또한, 다이어그램에는 Text Token, Pad Token, Codec Token, Vision Hidden, Text Hidden, Audio Hidden, Codec Hidden 및 Pad Hidden과 같은 다양한 유형의 토큰과 숨겨진 상태가 포함되어 있습니다. 이들은 입력 및 출력 모달리티의 다양한 측면과 시퀀스 정렬을 위한 패딩을 처리하는 것으로 보입니다. 하단의 샘플 입력은 컨텍스트를 제공합니다. 모델은 제공된 시각적 및 오디오 입력을 기반으로 오디오가 포함된 비디오를 설명하도록 프롬프트됩니다. 시스템은 인코더, LLM 계층을 통해 이러한 입력을 처리하고 마지막으로 디코더를 통해 오디오 설명을 생성합니다. 요약하면, 이는 비전, 오디오 및 언어 처리를 통합하여 비디오의 실시간 오디오 설명을 생성하는 정교한 다중 모달 시스템입니다. |
4) 시각정보 기반 수학 테스트: 고3 수학 기하문제를 풀도록 요청하였습니다.
| 문제 이미지 |
 |
| QVQ-Max 답변 |
 |
| Gemini-2.5-Pro-Exp 평가 | 제시된 풀이의 최종 답은 맞습니다. 다만, 첫 번째 단계에서 변의 길이를 구하는 논리적 과정 설명이 생략되어 있어 완전한 풀이라고 보기는 어렵습니다. 하지만 계산된 값 자체는 정확하여 이후 과정과 최종 답에는 문제가 없습니다. |
QVQ-Max의 답은 맞았지만, Gemini 2.5-Pro-Exp는 일부 설명이 누락되었다고 평가하였습니다.
5) 비디오 이해 테스트: 아래 동영상에서 큐브가 총 몇 번 회전했는지 물어보았습니다.
 |
아쉽게도, QVQ-Max는 Rubik's 큐브의 회전 횟수를 맞히지 못했습니다.
테스트 결과, QVQ-Max는 이미지의 경우, 상세한 부분까지 잘 파악하였으며, 이미지 속 다이아그램이나 수식, 도형, 코드 및 텍스트를 정확하게 인식하는 반면, 동영상 이해성능은 좀 더 개선이 필요해 보였습니다.
6. 맺음말
QVQ-Max는 단순한 이미지 인식 모델을 넘어, 시각적 정보를 기반으로 깊이 있는 추론과 다양한 응용이 가능한 AI 모델로서, 업무 효율성을 높이고, 학습을 용이하게 하며, 일상생활에 편리함과 창의성을 더할 수 있는 다재다능한 도구로서의 가능성을 보여줍니다.
그동안 오픈 소스 분야에서 부족했던 비전 능력을 채워줄 QVQ-Max의 혁신적인 기능을 여러분도 Qwen Chat 플랫폼에서 직접 확인해 보시길 추천드리면서, 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2025.02.09 - [AI 언어 모델] - 🐋DeepSeek-VL2: 고급 멀티모달 이해를 위한 MoE 비전-언어 모델
🐋DeepSeek-VL2: 고급 멀티모달 이해를 위한 MoE 비전-언어 모델
안녕하세요! 오늘은 최신 비전-언어 AI 모델인 DeepSeek-VL2에 대해 살펴보겠습니다. DeepSeek-VL2는 대규모 혼합 전문가(MoE) 아키텍처를 활용한 차세대 비전-언어 모델(VLM)로, 기존 DeepSeek-VL을 대폭 개선
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 🐪🖼️ Llama 4: Meta 최초의 MoE 기반 개방형 멀티모달 AI (4) | 2025.04.06 |
|---|---|
| 👀👂🗣️✍️Qwen2.5-Omni: 보고, 듣고, 말하고, 쓰는 차세대 멀티모달 모델! (1) | 2025.03.30 |
| 🔥♊Gemini 2.5 Pro-Exp: LMArena 1위! 구글의 최신 플래그십 AI 모델 (12) | 2025.03.29 |
| 🐳 DeepSeek V3-0324 공개! 오픈소스 LLM의 새로운 강자 등장 (8) | 2025.03.25 |
| 🏯🧠Hunyuan-T1: GPT 4.5 뛰어넘은 세계 최초 Hybrid-Transformer-Mamba MoE 모델 (8) | 2025.03.23 |



