안녕하세요! 오늘은 최신 비전-언어 AI 모델인 DeepSeek-VL2에 대해 살펴보겠습니다. DeepSeek-VL2는 대규모 혼합 전문가(MoE) 아키텍처를 활용한 차세대 비전-언어 모델(VLM)로, 기존 DeepSeek-VL을 대폭 개선한 모델입니다. 이번 업데이트를 통해 시각적 질문 응답(VQA), 광학 문자 인식(OCR), 문서 및 표 이해, 시각적 접지(visual grounding) 등 다양한 작업에서 더욱 뛰어난 성능을 제공하며, Tiny, Small, Standard 세 가지 버전으로 출시되어 다양한 환경에서 활용할 수 있습니다. 특히 다이내믹 타일링 전략과 멀티 헤드 잠재 어텐션(MLA) 메커니즘을 도입하여 고해상도 이미지 처리와 추론 속도를 크게 개선했습니다. 이번 블로그에서는 DeepSeek-VL2의 핵심 기능, 성능 벤치마크, 주요 활용 사례를 상세히 살펴보고, 직접 성능을 테스트하며 그 가능성을 분석해 보겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
1. DeepSeek-VL2 개요
DeepSeek-VL2는 대규모 혼합 전문가(Mixture-of-Experts, MoE) 비전-언어 모델(Vision-Language Model, VLM) 시리즈로, 이전 모델인 DeepSeek-VL을 크게 개선한 모델입니다. DeepSeek-VL2는 시각적 질문 응답(Visual Question Answering, VQA), 광학 문자 인식(Optical Character Recognition, OCR), 문서/표/차트 이해, 시각적 접지(visual grounding) 등 다양한 작업에서 뛰어난 성능을 보여줍니다.
DeepSeek-VL2는 세 가지 주요 측면에서 개선되었습니다. 첫째, 다이내믹 타일링 비전 인코딩 전략을 통해 고해상도 이미지와 다양한 종횡비를 효율적으로 처리하여 시각적 이해도를 향상시킵니다. 둘째, 멀티 헤드 잠재 어텐션(Multi-head Latent Attention, MLA) 메커니즘을 갖춘 최적화된 언어 모델 아키텍처를 통해 학습 및 추론 효율성을 크게 향상시킵니다. 셋째, 개선된 비전-언어 데이터 구축 파이프라인을 통해 전반적인 성능을 향상시키고 이미지 내에서 특정 객체를 찾거나 식별하는 "시각적 접지"와 같은 새로운 영역으로 모델 기능을 확장합니다.
| 모델명 | 파라미터 수 | 활성화된 파라미터 수 | GPU 메모리 요구사항 |
| DeepSeek-VL2-Tiny | 3.37B | 1B | 10GB |
| DeepSeek-VL2-Small | 16.1B | 2.8B | 40GB |
| DeepSeek-VL2 | 27.5B | 4.5B | 80GB |
이 모델 시리즈는 DeepSeek-VL2-Tiny, DeepSeek-VL2-Small, DeepSeek-VL2 세 가지 변형으로 구성되어 있으며, 각각 10억, 28억, 45억 개의 활성화된 파라미터를 가지고 있습니다. DeepSeek-VL2는 기존의 오픈 소스 밀집 모델 및 MoE 기반 모델과 비교했을 때 유사하거나 더 적은 활성화 파라미터로 경쟁력 있거나 최첨단 성능을 달성합니다.
https://github.com/deepseek-ai/DeepSeek-VL2/tree/main
GitHub - deepseek-ai/DeepSeek-VL2: DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding - deepseek-ai/DeepSeek-VL2
github.com
2. DeepSeek-VL2 특징 및 주요 기능
DeepSeek-VL2의 주요 특징과 기능은 다음과 같습니다.
- 다이내믹 타일링 전략: DeepSeek-VL2는 기존의 고정 해상도 제한을 극복하기 위해 이미지의 종횡비와 해상도에 따라 이미지를 타일로 분할하여 처리하는 다이내믹 타일링 전략을 사용합니다. 이 전략은 다양한 종횡비를 가진 고해상도 이미지를 효율적으로 처리하며, 로컬 어텐션을 활용하여 풍부한 특징 추출을 가능하게 합니다. 구체적으로, 입력 이미지는 여러 개의 384x384 로컬 타일과 하나의 썸네일 타일로 분할되고 비전 인코더를 통해 특징을 추출합니다.

- 멀티 헤드 잠재 어텐션 (MLA) 메커니즘: DeepSeek-VL2는 언어 구성 요소에서 MLA 메커니즘을 활용합니다. MLA는 텍스트 생성 시 이전 단계에서 생성된 정보를 기억하는 키-값(Key-Value, KV) 캐시를 잠재 벡터로 압축하여 계산 비용을 줄이고, 더 빠른 추론과 높은 처리량을 가능하게 합니다.
- 향상된 학습 데이터: DeepSeek-VL2는 품질, 양, 다양성 측면에서 크게 향상된 비전-언어 학습 데이터를 사용합니다. 이 데이터셋은 시각적 질문 응답(VQA), 광학 문자 인식(OCR), 문서/표/차트 이해, 시각적 추론, 일반 챗봇 애플리케이션 등 광범위한 작업에서 더 나은 일반화와 성능을 가능하게 합니다. 또한 시각적 접지 및 그래픽 사용자 인터페이스(GUI) 인식과 같은 새로운 기능을 추가했습니다.
- 다양한 작업 지원: DeepSeek-VL2는 시각적 질문 응답, 광학 문자 인식, 문서 이해, 표 및 차트 이해, 시각적 추론, 시각적 접지, 일반 챗봇 애플리케이션 등 다양한 멀티모달 작업을 지원합니다.
DeepSeek-VL2의 아키텍처는 비전 인코더, 비전-언어 어댑터, MoE 기반 언어 모델 세 가지 핵심 모듈로 구성됩니다. 비전 인코더는 고해상도 이미지를 처리하기 위해 다이내믹 타일링 전략을 사용하며, 비전-언어 어댑터는 시각적 특징을 언어 모델의 임베딩 공간으로 투영합니다. 언어 모델은 MLA 메커니즘을 사용하는 DeepSeekMoE를 기반으로 합니다.

- Vision Encoder: 이미지에서 시각적 특징을 추출하는 역할을 합니다. DeepSeek-VL2는 고해상도 이미지를 효율적으로 처리하기 위해 dynamic tiling strategy를 도입했습니다.
- Vision-Language Adaptor: 시각적 특징과 언어적 특징을 연결해 주는 역할을 합니다. LLaVA 스타일 아키텍처에서 어댑터는 일반적으로 MLP(Multi-Layer Perceptron)로 구현됩니다. DeepSeek-VL2에서는 2-layer MLP를 사용하여 이미지 토큰을 언어 모델의 embedding space로 투영합니다.
- Language Model: 텍스트를 이해하고 생성하는 역할을 합니다. DeepSeek-VL2는 DeepSeekMoE 언어 모델을 사용하며, Multi-head Latent Attention (MLA) 메커니즘을 통해 inference 효율성을 높입니다. 또한 MoE(Mixture-of-Experts) 아키텍처를 통해 sparse computation을 수행하여 효율적인 inference가 가능합니다.
또한 DeepSeek-VL2에서는 다음과 같은 용도로 특수 토큰 |ref|, |det|, |grounding|을 사용합니다.
- |ref| 및 |/ref|: 이 토큰들은 특정 객체(object)를 지칭하기 위해 사용됩니다. 이미지 내에서 특정 객체를 언급할 때, 해당 객체를 |ref|와 |/ref|로 감싸서 모델에게 해당 부분이 객체를 지칭하는 부분임을 알려줍니다.
- |det| 및 |/det|: 이 토큰들은 객체의 위치 정보를 나타내는 bounding box 좌표를 감싸는 데 사용됩니다. bounding box는 이미지 내에서 객체의 위치를 사각형 형태로 표시하는 것을 의미합니다. bounding box 좌표는 |det|와 |/det| 사이에 위치하며, 모델은 이 정보를 통해 이미지 내에서 객체의 정확한 위치를 파악할 수 있습니다.
- |grounding|: 이 토큰은 "grounded captioning" 기능을 활성화하기 위해 프롬프트 시작 부분에 추가됩니다. "grounded captioning"은 객체 위치 정보와 추론(reasoning)을 모두 포함하는 응답을 생성하는 기능을 의미합니다. 이 토큰을 사용하면 모델은 이미지에 대한 설명과 함께 관련된 객체의 위치 정보를 제공할 수 있습니다.

예시:
- |ref|The giraffe at the back.|/ref|: "뒤쪽에 있는 기린"이라는 객체를 지칭합니다.
- |det|[[580, 270, 999, 900]]|/det|: 해당 객체의 위치 정보(bounding box 좌표)를 나타냅니다.
- |grounding|Can you describe the content of the image?: "grounded captioning" 기능을 사용하여 이미지 내용 설명과 함께 객체 위치 정보를 요청합니다.
3. DeepSeek-VL2 벤치마크 결과
DeepSeek-VL2는 다양한 벤치마크에서 뛰어난 성능을 보여줍니다.
- OCR 관련 벤치마크: DeepSeek-VL2는 DocVQA, ChartQA, InfoVQA, TextVQA, OCRBench에서 경쟁력 있는 성능을 보입니다. 특히 DeepSeek-VL2-Small 모델은 OCRBench에서 834점을 기록하며, 비슷한 규모의 모델 중 가장 높은 점수를 달성했습니다. DeepSeek-VL2 모델은 811점으로 역시 높은 점수를 보여줍니다.

- 일반 QA 및 수학 관련 벤치마크: DeepSeek-VL2는 MMStar, AI2D, MMMU, MME, MMBench, MMT-Bench, RealWorldQA, MathVista 등 다양한 벤치마크에서 우수한 성능을 나타냅니다. DeepSeek-VL2-Small 모델은 MMBench에서 80.3점, MMT-Bench에서 62.9점을 기록하며, DeepSeek-VL2 모델은 각각 79.6점과 63.6점을 달성했습니다. MathVista에서는 DeepSeek-VL2 모델이 62.8점으로 높은 성능을 보여줍니다.

- 시각적 접지 벤치마크: DeepSeek-VL2는 RefCOCO, RefCOCO+, RefCOCOg 벤치마크에서 다른 VLM보다 뛰어난 성능을 나타냅니다. DeepSeek-VL2 모델은 RefCOCO에서 95.1점, RefCOCO+에서 91.2점, RefCOCOg에서 92.8점을 기록하며, 최고 수준의 성능을 입증했습니다.

이러한 벤치마크 결과는 DeepSeek-VL2가 다양한 멀티모달 작업에서 높은 성능을 보이며, 특히 적은 파라미터로도 뛰어난 성능을 달성할 수 있음을 보여줍니다. 또한 DeepSeek-VL2는 MoE 아키텍처를 통해 유사하거나 더 적은 활성화 파라미터로 경쟁력 있는 성능을 달성하여 효율성 측면에서도 강점을 보입니다.
4. DeepSeek-VL2 테스트
다음은 DeepSeek-VL2-Small 모델을 직접 테스트해 보겠습니다. 이 모델을 직접 구동하려면 GPU 메모리가 40GB 정도 필요하기 때문에 클라우드 GPU를 이용해서 진행해 볼 텐데요. 여러 클라우드 GPU 중에 저는 하이퍼볼릭 AI를 사용해 보았습니다. DeepSeek-VL2-Small 모델의 정보는 아래 허깅페이스 링크에서 확인하실 수 있습니다.
https://huggingface.co/spaces/deepseek-ai/deepseek-vl2-small
Chat with DeepSeek-VL2-small - a Hugging Face Space by deepseek-ai
Running on Zero
huggingface.co
하이퍼볼릭 AI의 링크는 아래와 같습니다.
https://app.hyperbolic.xyz/compute
Hyperbolic AI Dashboard
app.hyperbolic.xyz
하이퍼볼릭 AI에 가입하고 5달러를 충전한 후 H100 SXM(GPU RAM 80GB)을 렌트하였습니다. 가입하면 기본으로 10달러를 충전해 주는데, 추가로 충전해야 GPU를 렌트할 수 있습니다. 시간당 0.99달러로 렌트 비용이 책정되어 있습니다.

렌트를 클릭하면 안내 문구에 따라 ssh 접속방식을 위한 공개키를 저장한 후, 표시되는 명령어로 원격접속하면 됩니다.
ssh -i "C:\Users\User\.ssh\id_ed25519" ubuntu@parallel-delphinium-panther.1.cricket.hyperbolic.xyz -p 31447
하이퍼볼릭 AI에 Secure Shell 접속이 완료되면, 아래 명령어로 DeepSeek-VL2 깃 허브 레포지토리를 복제하고 종속성을 설치한 후, web_demo.py를 실행하면 됩니다. 렌트한 GPU와 호환되는 PyTorch를 설치하시고, 스토리지는 deepseek-vl2-small 모델의 경우 약 40GB 정도 차지합니다. H100 GPU에서 동작을 확인한 패키지의 버전은 다음을 참고하세요
git clone https://github.com/deepseek-ai/DeepSeek-VL2.git
cd DeepSeek-VL2
pip install -r requirements.txt
python3 web_demo.py --model_name deepseek-ai/deepseek-vl2-small --port 7860
##동작을 확인한 패키지 버전##
torch==2.1.1
torchvision==0.16.1
xformers==0.0.23
triton==2.1.0
nvidia-cudnn-cu12==8.9.2.26
nvidia-nccl-cu12==2.18.1
web_demo.py를 실행하고 gradio 공개 주소에 접속하면 아래와 같은 초기 화면이 표시됩니다. (gradio 서버가 장애인 경우 ssh 터널링으로 접속할 수 있습니다.)

- 일반 시각적 질문 응답: DeepSeek-VL2는 이미지에 대한 상세한 설명을 제공하고, 일반적인 랜드마크, 일반 시각 지식, 영어와 중국어 모두에서 텍스트를 인식하는 능력이 뛰어납니다. 또한 밈을 이해하고 맥락을 정확하게 설명하고 의미 있는 문화적 배경을 통해 유머를 해석합니다. 아래 화면은 중국의 인터넷 용어인 "친절한 언니"를 이미지에서 찾아 박스 표시한 예시입니다.
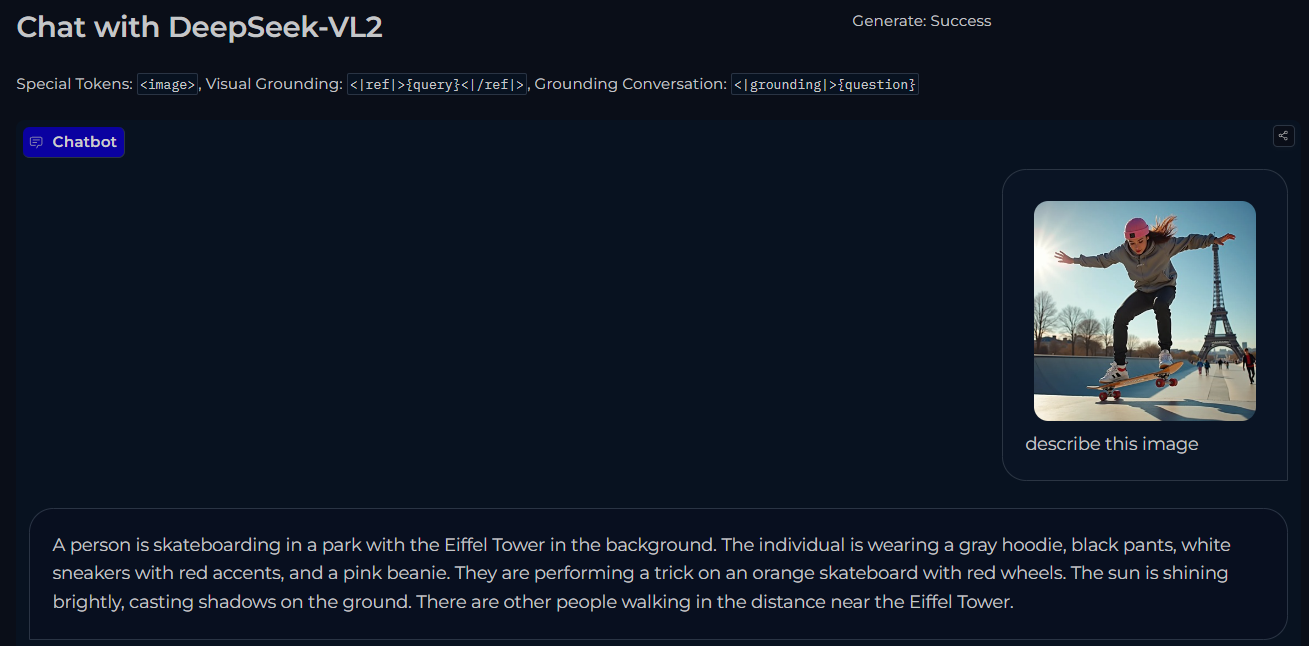
한 사람이 에펠탑이 보이는 공원에서 스케이트보드를 타고 있습니다. 이 개인은 회색 후드티, 검은 바지, 빨간색 악센트가 있는 흰색 운동화, 분홍색 비니를 착용하고 있습니다. 그들은 빨간색 바퀴가 달린 주황색 스케이트보드에서 트릭을 수행하고 있습니다. 태양은 밝게 빛나고 있으며, 그림자가 땅에 드리워져 있습니다. 에펠탑 근처에는 다른 사람들이 걷고 있습니다.
위 화면에서 deepseek-vl2-small 모델은 각 층의 입체구조와 큐브에 새겨진 숫자를 정확하게 인식하였습니다.


황혼이나 밤에 도시 거리로 보이는 곳에 서 있는 개인. 이 사람은 프레임의 왼쪽으로 약간 치우쳐 있습니다. 그들은 양쪽 어깨에 떨어지는 긴 어두운 머리카락을 가지고 있으며 이마 일부를 덮는 모자를 포함한 어두운 옷을 입고 있습니다.
그들의 눈은 카메라 렌즈를 직접 응시하여 교통 신호, 상점 전면 및 아마도 광고판과 같은 다양한 소스의 다채로운 조명으로 채워진 흐릿한 배경에 대해 두드러집니다. 이러한 빛 보케 효과는 장면 내의 다양한 지점에 활기찬 원을 만들어 깊이를 더하는 동시에 여기에서 사용되는 얕은 심도 사진 기술로 인해 주로 피사체의 얼굴에 초점을 유지합니다.
또한 그녀 뒤에서 지나가는 차량이나 예술적 효과를 위해 노출 시간 동안 캡처된 약간의 움직임으로 인해 움직임이 있음을 나타내는 약간의 모션 블러가 있습니다. 전반적으로 그것은 선명도 대 부드러운 배경 요소 사이에 우아하게 병치된 도시 생활 분위기를 전달하여 구성 전체에 역동적인 시각적 관심을 불러일으킵니다.다음 화면은 특수토큰 |ref| 사용 예시입니다. 화면의 뒤쪽에 있는 기린을 특정하여 박스를 표시하였습니다.

- 접지된 대화: DeepSeek-VL2는 특수 토큰 <|grounding|>을 사용하여 응답에서 정확한 위치를 가진 핵심 객체를 참조할 수 있는 접지된 대화 기능을 활용합니다. 이를 통해 모델은 실제 세계와 더 잘 상호 작용할 수 있으며, 실체화된 AI 및 컴퓨터/전화 에이전트와 같은 분야에서 더 큰 역할을 할 수 있는 기회를 창출합니다.

- 시각적 스토리텔링: DeepSeek-VL2는 여러 이미지를 입력으로 받아 중국어 또는 영어로 이야기를 창의적으로 작성할 수 있습니다. 스토리텔링은 랜드마크 인식 및 OCR과 같은 강력한 일반 시각적 기능을 기반으로 합니다.

위 OCR 테스트 이미지를 업로드하고, 텍스트 추출을 요청한 결과 모든 텍스트를 정확하게 추출하였습니다.

- 시각적 접지: DeepSeek-VL2는 객체의 범주 이름, 설명 또는 추상적인 개념을 기반으로 객체를 찾을 수 있습니다. 특정 유명인이나 추상적인 개념도 인식할 수 있습니다. 또한, DeepSeek-VL2는 컨텍스트 내에서 시각적 접지 능력을 보여줍니다. 시각적 프롬프트가 있거나 없는 첫 번째 이미지에서 모델은 두 번째 이미지에서 동일한 범주의 객체를 찾을 수 있습니다.


일몰이나 일출 때 모래사장에 다리를 꼬고 앉아 있는 개인. 그 사람은 어깨 위로 떨어지는 긴 물결 모양의 머리카락을 가지고 있으며, 브래지어 탑과 일치하는 바지로 구성된 흰색 레이스 란제리를 입고 있습니다. 그녀의 눈은 부드럽게 파도가 해안으로 밀려오는 배경에 대해 평화롭게 명상하면서 감겨 있습니다. 떠오르는 태양이나 지는 태양에서 나오는 따뜻한 색조가 장면 전체에 부드러운 빛을 비추며 고요한 분위기를 조성합니다.
그녀는 자연의 평온한 아름다움 속에서 마음챙김 연습처럼 보이는 동안 편안하면서도 집중된 것처럼 보입니다.- 다중 이미지 대화: DeepSeek-VL2는 여러 이미지 간의 관계를 분석하고 차이점을 식별하는 데 뛰어납니다. 또한 여러 이미지의 내용을 통합하여 간단한 추론을 수행합니다. 예를 들어, 특정 재료의 이미지를 기반으로 요리를 준비하는 방법을 이해할 수 있습니다.


물론이죠! 당근, 옥수수, 돼지 갈비를 사용한 푸짐한 채소와 고기 스튜 레시피를 알려드릴게요:
재료:
당근: 2개, 껍질을 벗기고 얇게 썬다
옥수수: 1개, 알갱이를 떼어낸다
돼지 갈비: 500g, 조각으로 자른다
양파: 2개, 다진다
마늘: 3쪽, 다진다
토마토: 4개, 다진다
올리브 오일: 2큰술
소금: 맛에 맞게
후추: 맛에 맞게
월계수 잎: 2장
물: 모든 재료를 덮을 만큼
허브 (선택 사항): 신선한 파슬리 또는 타임으로 장식
만드는 방법:
준비:
오븐을 375°F (190°C)로 예열합니다.
큰 냄비에 올리브 오일을 두르고 중간 불에서 양파와 마늘을 볶아 부드러워질 때까지 약 5분간 볶습니다.
돼지 갈비 요리:
돼지 갈비를 냄비에 넣고 양파 혼합물과 함께 고루 섞어줍니다.
예열된 오븐에서 약 30분간 구워 갈비가 갈색으로 변하고 부드러워질 때까지 굽습니다.
채소 추가:
구운 갈비를 오븐에서 꺼내어 접시에 옮겨 놓습니다.
같은 냄비에 얇게 썬 당근과 옥수수 알갱이를 넣고 5분간 더 볶아 약간 부드러워질 때까지 볶습니다.
다진 토마토를 넣고 5분간 더 볶습니다.
양념과 끓이기:
돼지 갈비를 냄비에 다시 넣습니다.
모든 재료를 덮을 만큼의 물을 부은 후, 월계수 잎, 소금, 후추를 넣습니다.
스튜를 끓인 후, 불을 약하게 줄입니다.
냄비를 덮고 약 1.5~2시간 동안 끓여 채소가 부드러워지고 고기가 매우 부드러워질 때까지 끓입니다.
마무리:
스튜의 맛을 보고 양념을 조절합니다.
서빙하기 전에 신선한 허브로 장식합니다.
서빙:
뜨겁게 제공하며, 바삭한 빵이나 밥과 함께 즐기세요.
맛있는 수제 채소와 고기 스튜를 즐겨보세요!
그래프는 꼭짓점이 원점 (0, -1)에 있는 포물선을 보여줍니다. x축은 -2에서 2까지 표시되어 있고, y축은 -1에서 4까지 범위가 있습니다. 포물선은 위로 열리므로 (y = ax^2 + bx + c) 형태의 이차 함수임을 알 수 있습니다. 음영 처리된 영역은 곡선 아래의 다른 영역을 나타냅니다. x축의 왼쪽에 있는 녹색 영역은 적분 (\int_{-2}^{0} f(x), dx)에 해당하며, 여기서 (f(x))는 빨간색 곡선으로 표현된 함수입니다.
마찬가지로, x축 아래의 파란색 영역은 (\int_{0}^{2} f(x), dx)를 나타내고, x축 위의 분홍색 영역은 (\int_{2}^{1} f(x), dx)를 나타냅니다. 이러한 적분은 지정된 한계 사이의 곡선 아래의 면적을 계산합니다."이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
5. 맺음말
DeepSeek-VL2는 MoE 기반 비전-언어 모델의 고급 버전으로, 총 30억, 160억, 270억 개의 파라미터와 10억, 28억, 45억 개의 활성화된 파라미터를 각각 가지고 있습니다. 이러한 구성은 학습 및 추론 단계에서 효율적인 계산을 가능하게 합니다. 특히, 30억, 160억, 270억 개의 파라미터를 가진 모델은 각각 10GB, 40GB, 80GB 메모리를 가진 단일 GPU에서 배포할 수 있습니다.
DeepSeek-VL2는 다이내믹 타일링 비전 인코딩 전략을 사용하여 다양한 종횡비를 가진 고해상도 이미지를 효율적으로 처리합니다. 또한 MLA 메커니즘이 적용된 DeepSeekMoE 언어 모델을 활용하여 효율성과 추론 속도를 높이면서, 오픈 소스 커뮤니티에 더 나은 접근성과 유연성을 제공하며, 학술 및 상업 연구에서 모두 사용될 수 있습니다.
DeepSeek-VL2는 다양한 비전-언어 작업에서 뛰어난 성능을 제공하며, 사용자에게 보다 효율적이고 강력한 도구를 제공할 것으로 기대됩니다. 오늘 블로그를 통해 DeepSeek-VL2를 이해하시는데 도움이 되셨기를 바라면서 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.12.08 - [AI 언어 모델] - 👁️PaliGemma 2: 구글의 최신 오픈소스 비전-언어 모델(VLM)
👁️PaliGemma 2: 구글의 최신 오픈소스 비전-언어 모델(VLM)
안녕하세요! 오늘은 Google DeepMind가 개발한 최신 비전-언어 모델(VLM) PaliGemma 2에 대해 살펴보겠습니다. PaliGemma 2는 이미지와 텍스트를 동시에 이해하고 처리할 수 있는 첨단 AI 모델로, 기존의 PaliGe
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 🌍🚀세계 최초 하이브리드 추론 모델 Claude 3.7 Sonnet과 Claude Code 분석 (4) | 2025.02.26 |
|---|---|
| 🔍🤖 Grok-3: 일론 머스크가 극찬한 "지구에서 가장 똑똑한 AI 챗봇" (4) | 2025.02.19 |
| ✨Gemini 2.0 패밀리: 최대 200만 토큰 지원하는 구글의 최신 AI 모델군 (4) | 2025.02.07 |
| 🔓Mistral Small 3: GPT-4o-mini를 대체할 오픈소스 언어 모델 (12) | 2025.02.06 |
| 🤖⚡o3-mini: DeepSeek-R1과 경쟁할 OpenAI의 최신 추론 모델 (5) | 2025.02.01 |



