안녕하세요! 오늘은 중국 알리바바 클라우드에서 개발한 최신 오픈소스 인공지능 모델 Qwen2.5에 대해 알아보겠습니다. Qwen2.5는 대화 응대, 자연어 처리, 그리고 코딩 능력에서 뛰어난 성능을 자랑하는 다목적 AI 모델로, 향상된 자연어 처리 능력과 멀티태스크 학습 성능으로 복잡한 질문이나 추론을 더욱 정확하고 신속하게 처리하며, 코딩 문제 해결에서도 고도의 알고리즘 추론 능력을 발휘합니다. 또한, 효율적인 메모리 관리로 더 적은 자원으로도 복잡한 작업을 수행할 수 있습니다. 이 블로그에서는 Qwen2.5의 주요 기능과 성능, 벤치마크 결과를 살펴보고, 코딩 및 추론 테스트를 해보겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Qwen2.5 개요
Qwen2.5는 Qwen 시리즈의 최신 인공지능 모델로, 이전 모델인 Qwen2.0에 비해 개선된 자연어 처리(NLP) 성능을 통해 사용자와의 상호작용에서 더 나은 이해력과 정확한 답변을 제공합니다. 또한 Qwen2.5는 확장된 데이터셋과 새로운 알고리즘 최적화를 통해 다양한 작업에서의 효율성을 높이고 응답 시간을 줄임으로써, 고도화된 자연어 추론, 대화 응대, 복잡한 질문 처리에서 두각을 나타내며, 이전 모델들과 비교해 실시간 처리 능력이 크게 향상되었습니다.
방대한 데이터셋을 기반으로 학습된 Qwen2.5는 기본 언어 모델 이외에도 코딩 특화 모델인 Qwen2.5-Coder, 수학 특화 모델인 Qwen2.5-Math를 포함하여 다양한 종류의 모델을 제공합니다. 각 모델은 0.5B부터 72B까지 다양한 크기의 파라미터를 가지고 있어 사용 목적에 따라 적합한 모델을 선택할 수 있습니다. 다음 표는 Qwen2.5 모델의 종류와 매개변수, 용도를 나타냅니다.
| 모델명 | 매개변수 | 학습데이터 | 용도 |
| Qwen2.5 | 0.5B, 1.5B, 3B, 7B, 14B, 32B, 72B | 18조 개 토큰 | 다양한 기능 제공 |
| Qwen2.5-Coder | 1.5B, 7B, (32B) | 5.5조 개 토큰 | 코딩 전용 모델 |
| Qwen2.5-Math | 1.5B, 7B, 72B | >Qwen2-Math | 수학 전용 모델 |
Qwen 2.5는 대부분 32K 또는 128K의 컨텍스트 길이를 지원하며, 0.5B, 1.5B, 3B 매개변수를 가진 작은 모델들은 주로 입출력 임베딩을 공유하는 Tie Embedding 기법을 사용합니다. 이 모델들은 주로 Apache 2.0 라이선스를 따르며, 72B 모델은 Qwen 라이선스를, 3B 모델은 Qwen Research 라이선스를 채택하고 있습니다. Qwen 시리즈는 다양한 크기와 특화된 버전으로 제공되어, 여러 응용 분야와 컴퓨팅 환경에 맞춘 유연한 선택지를 제공합니다.

Qwen2.5 특징
Qwen 2.5의 가장 두드러진 특징은 향상된 자연어 처리 능력, 멀티태스크 학습 성능, 그리고 효율적인 메모리 관리의 세 가지로 나눌 수 있습니다
- 자연어 처리 능력: Qwen 2.5는 자연어의 의미를 더 깊이 이해하는 데 초점을 맞춘 새로운 아키텍처 개선을 통해, 복잡한 문맥이나 다의적 표현을 처리하는 능력을 한층 강화했습니다. 이 모델은 다중 의미를 가지는 단어나 문장을 해석할 때, 문맥과 관련된 적절한 해석을 찾아냅니다.
- 멀티태스크 학습 성능: Qwen 2.5는 여러 작업을 동시에 처리할 수 있는 멀티태스크 학습 능력을 자랑합니다. 이 기능은 하나의 모델이 질문 응답뿐만 아니라, 번역, 요약, 코딩 문제 해결 등 다양한 작업을 동시에 수행할 수 있다는 것을 의미합니다. 멀티태스크 능력을 통해 시간 절약과 생산성 향상을 기대할 수 있습니다.

- 효율적인 메모리 관리: Qwen 2.5는 메모리 관리에서 혁신적인 최적화를 이루어냈습니다. 이로 인해 고사양 하드웨어가 없어도 많은 양의 데이터를 효율적으로 처리할 수 있으며, 경량화된 구조 덕분에 더 많은 작업을 더 적은 자원으로 실행할 수 있습니다.
Qwen2.5-Coder 모델의 주요 특징은 다음과 같습니다.
- 코딩에 특화된 모델: Qwen2.5-Coder는 코드 관련 작업을 위해 특별히 설계되었습니다. 디버깅, 코딩 관련 질문 답변, 코드 제안과 같은 다양한 코딩 작업에 활용될 수 있습니다.
- 대규모 코드 데이터 학습: 5.5조 토큰의 코드 관련 데이터를 학습하여, 더 작은 코딩 특화 모델도 다양한 프로그래밍 언어 및 작업에서 우수한 성능을 발휘합니다.
- 다양한 프로그래밍 언어 및 작업 지원: 여러 벤치마크에서 더 큰 언어 모델보다 우수한 성능을 보이며, 92개의 프로그래밍 언어를 지원하고 코드 생성, 다중 프로그래밍 코드 생성, 코드 완성, 코드 수정을 포함한 다양한 코드 관련 평가 작업에서 상당한 개선을 이루었습니다.
Qwen2.5-Math 모델의 주요 특징은 다음과 같습니다.
- 수학 문제 해결에 특화: Qwen2.5-Math는 수학 문제 해결을 위해 특별히 제작된 모델입니다.
- 중국어 및 영어 지원: 이전 버전과 달리, 중국어와 영어 모두를 지원하여 수학 문제를 해결할 수 있습니다.
- 다양한 추론 방법 활용: CoT (Chain-of-Thought), PoT (Program-of-Thought), TIR (Tool-Integrated Reasoning) 등 다양한 추론 방법을 통합하여 문제 해결 능력을 강화했습니다.
- 대규모 수학 데이터셋: Qwen2-Math에서 생성된 합성 데이터를 포함하여 이전 모델보다 더 큰 규모의 수학 관련 데이터셋으로 학습되었습니다.
Qwen 2.5 벤치마크 결과
Qwen 2.5는 다양한 벤치마크에서 뛰어난 성능을 보였습니다. Qwen 2.5는 최대 18조 개의 토큰을 포함하는 대규모 데이터셋을 기반으로 학습되었으며, 이전 버전인 Qwen2와 비교하여 다음과 같은 향상된 기능을 제공합니다.
- 향상된 지식: MMLU(Massive Multitask Language Understanding) 벤치마크에서 85점 이상을 기록하며, 이전 버전 대비 훨씬 더 많은 지식을 습득했습니다.
- 강력한 코딩 성능: HumanEval 벤치마크에서 85점 이상을 기록하며 코딩 능력이 크게 향상되었습니다. 특히, 코드 관련 데이터 5.5조 개 토큰으로 학습된 Qwen2.5-Coder는 더 작은 모델 크기로도 기존 대형 언어 모델에 필적하는 코딩 성능을 보여줍니다.
- 뛰어난 수학적 능력: MATH 벤치마크에서 80점 이상을 기록하며 수학적 능력이 크게 향상되었습니다. Qwen2.5-Math는 한국어와 영어를 모두 지원하며, CoT, PoT, TIR 등 다양한 추론 방법을 통합하여 추론 능력을 강화했습니다.
- 긴 텍스트 생성: 최대 8,000개의 토큰까지 생성할 수 있어 긴 글 작성에 유용합니다.
- 다국어 지원: 한국어, 영어, 프랑스어, 스페인어, 포르투갈어, 독일어, 이탈리아어, 러시아어, 일본어, 베트남어, 태국어, 아랍어 등 29개 이상의 언어를 지원합니다.
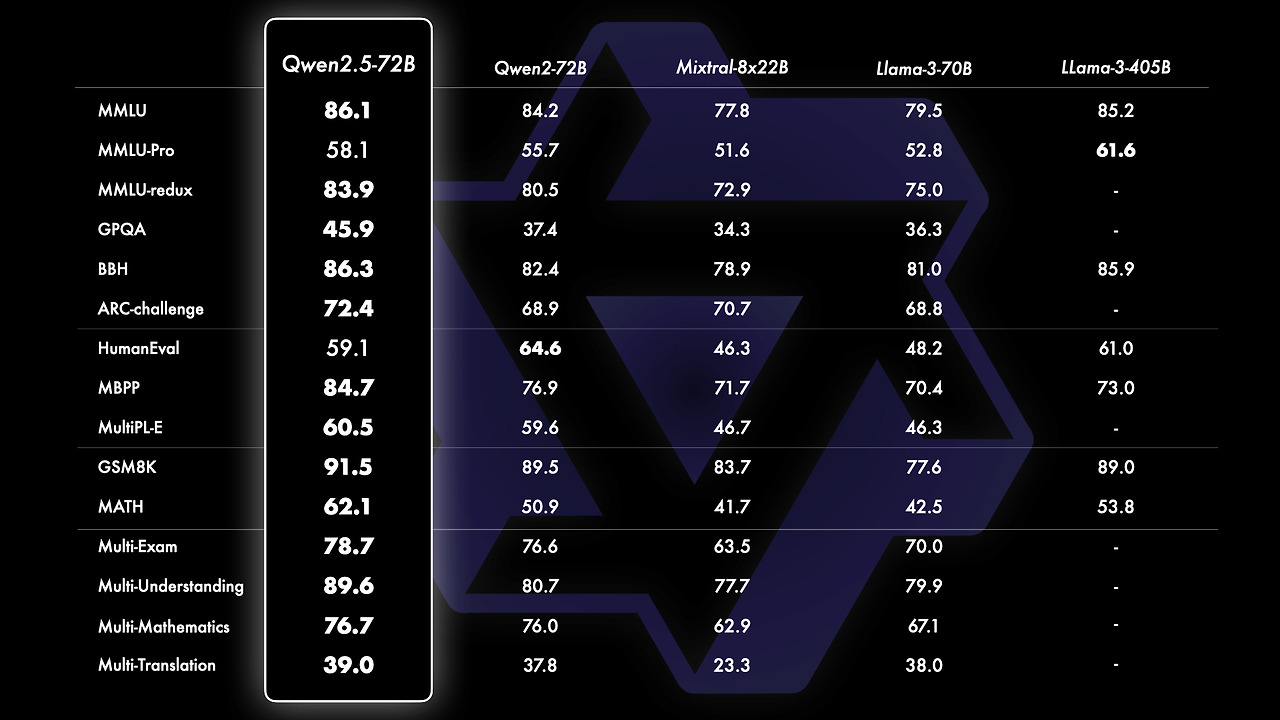
Qwen2.5-72B 모델은 다양한 벤치마크에서 매우 뛰어난 성능을 보여줍니다. 특히 MMLU, BBH, GSM8K, Multi-Understanding 등 여러 영역에서 다른 모델들과 비교하여 최상위권의 점수를 기록했습니다.
- 뛰어난 언어 이해 능력: MMLU(86.1), MMLU-redux (83.9)에서 높은 점수를 기록하며 광범위한 지식과 추론 능력을 보여줍니다.
- 상식 추론 및 질의응답: BBH(Big Bench Hard) (86.3)에서도 높은 점수를 기록하며 상식 추론과 질의응답 능력이 뛰어남을 알 수 있습니다.
- 요약 능력: GSM8K (91.5)에서 매우 높은 점수를 기록하며 긴 텍스트를 요약하는 능력이 탁월합니다.
- 복잡한 추론 및 문제 해결: Multi-Understanding (89.6)에서도 높은 점수를 기록하며 복잡한 추론과 문제 해결 능력을 보여줍니다.
Qwen2.5-Math는 다양한 크기(1.5B, 7B, 72B)로 제공되며, 대체로 매개변수 크기가 클수록 높은 성능을 보여줍니다. 특히, 72B 모델은 MATH 벤치마크에서 85.9의 Zero-shot@1(모델이 이전에 보지 못한 문제에 대해 한 번의 시도로 정답을 맞출 확률) 정확도를 달성하여, 최고 성능을 기록했습니다.
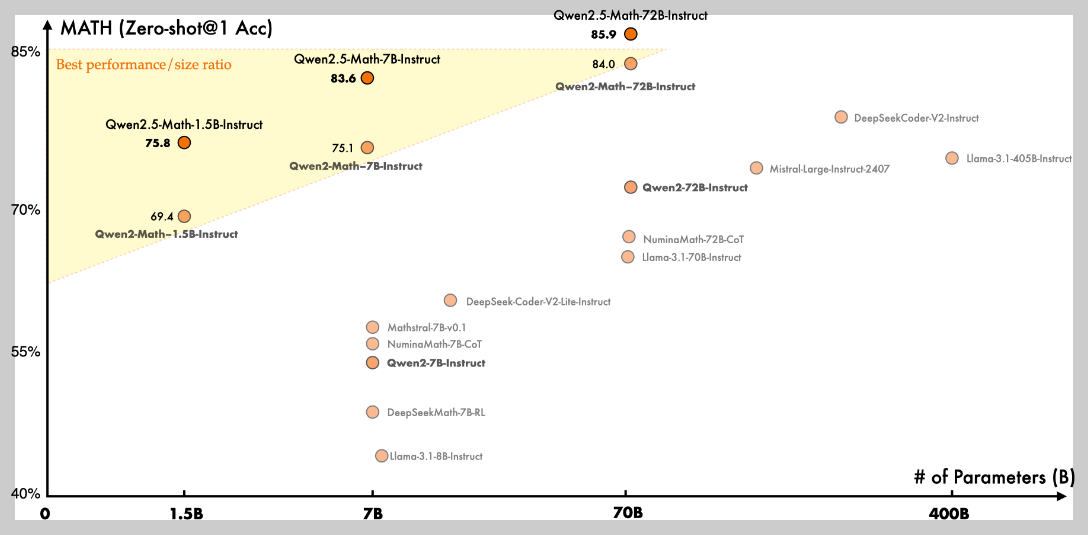
Qwen2.5-Math-1.5B-Instruct는 비교적 작은 크기에도 불구하고 75.8의 정확도를 달성하여, 효율적인 성능을 보여줍니다. 위 그래프에서 노란색 영역은 "최적 성능/크기 비율" 영역을 나타냅니다. Qwen2.5-Math-1.5B는 이 영역에 포함되어, 크기 대비 우수한 성능을 가짐을 알 수 있습니다. Qwen2.5-Math-72B는 DeepSeekCoderV2-Instruct, Mistral-Large-Instruct-2407, Llama-3.1-405B-Instruct 등 다른 대규모 모델들보다 높은 정확도를 기록했으며, Qwen2.5-Math-7B 모델의 경우, Mathstral-7B-v0.1, NuminaMath-7B-CoT 등 보다 더 높은 정확도를 달성했습니다.
Qwen2.5-14B 및 Qwen2.5-32B: GPT4-o mini 및 Gemma2-27B-IT와 같은 유사하거나 더 큰 크기의 기준 모델보다 다양한 작업에서 우수한 성능을 보여줍니다. 모델 크기와 기능 사이의 최적의 균형을 달성하여 일부 대형 모델과 일치하거나 능가하는 성능을 제공합니다. API 기반 모델인 Qwen-Turbo도 GPT4-o mini 및 Gemma2-27B-IT 모델에 비해 매우 경쟁력 있는 성능을 제공하는 동시에 비용 효율적이고 빠른 서비스를 제공합니다.
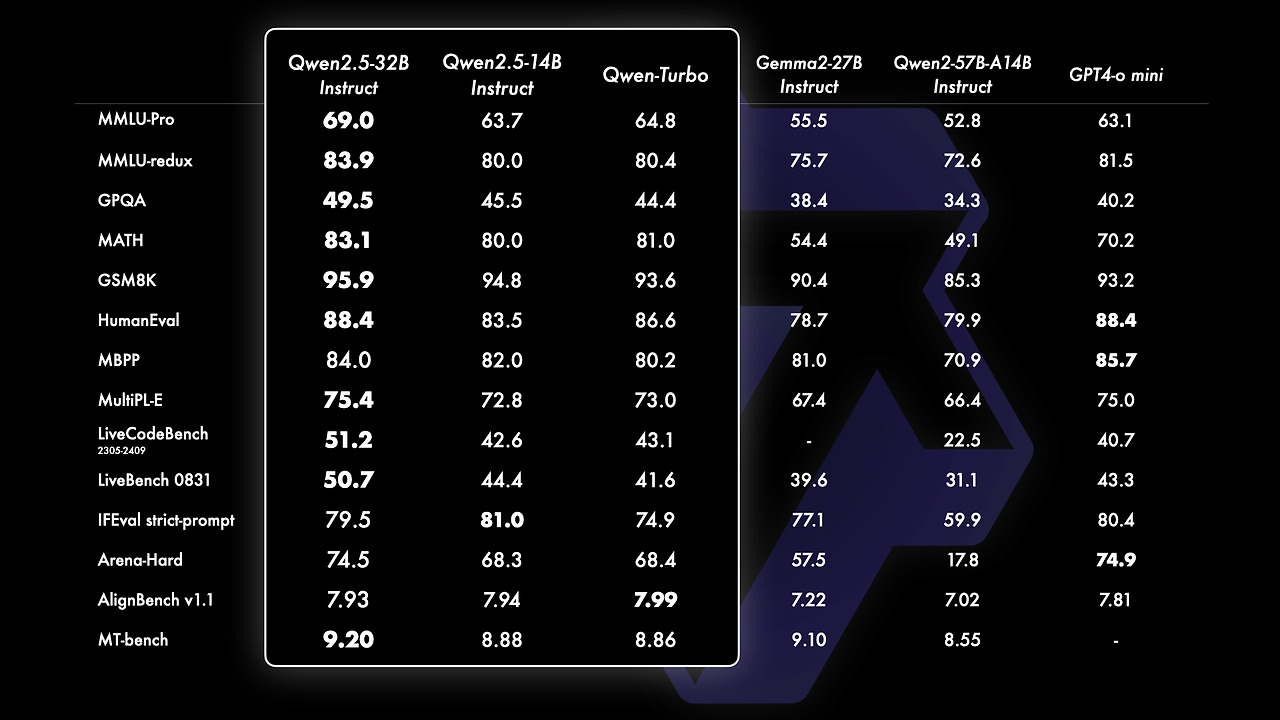
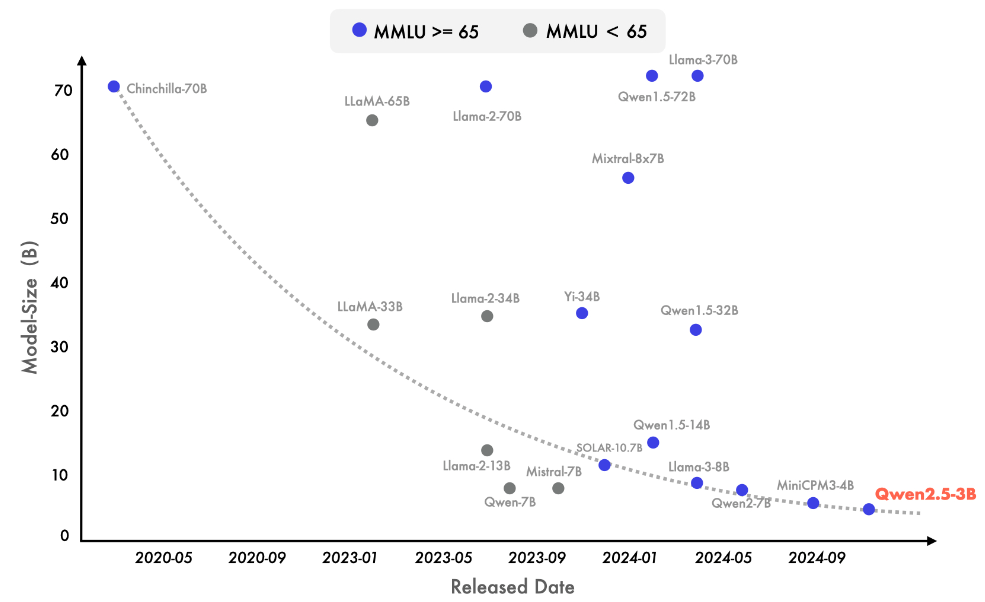
위 그래프에서 보는 바와 같이 MMLU에서 65점 이상을 달성하는 최신 모델은 점점 더 작아지는 추세이며, 이는 언어 모델의 지식 밀도가 빠르게 성장하고 있음을 의미합니다. Qwen2.5-3B는 약 30억 개의 매개변수만으로도 MMLU에서 65점 이상을 달성하여 모델 크기 대비 높은 성능을 보여줍니다.
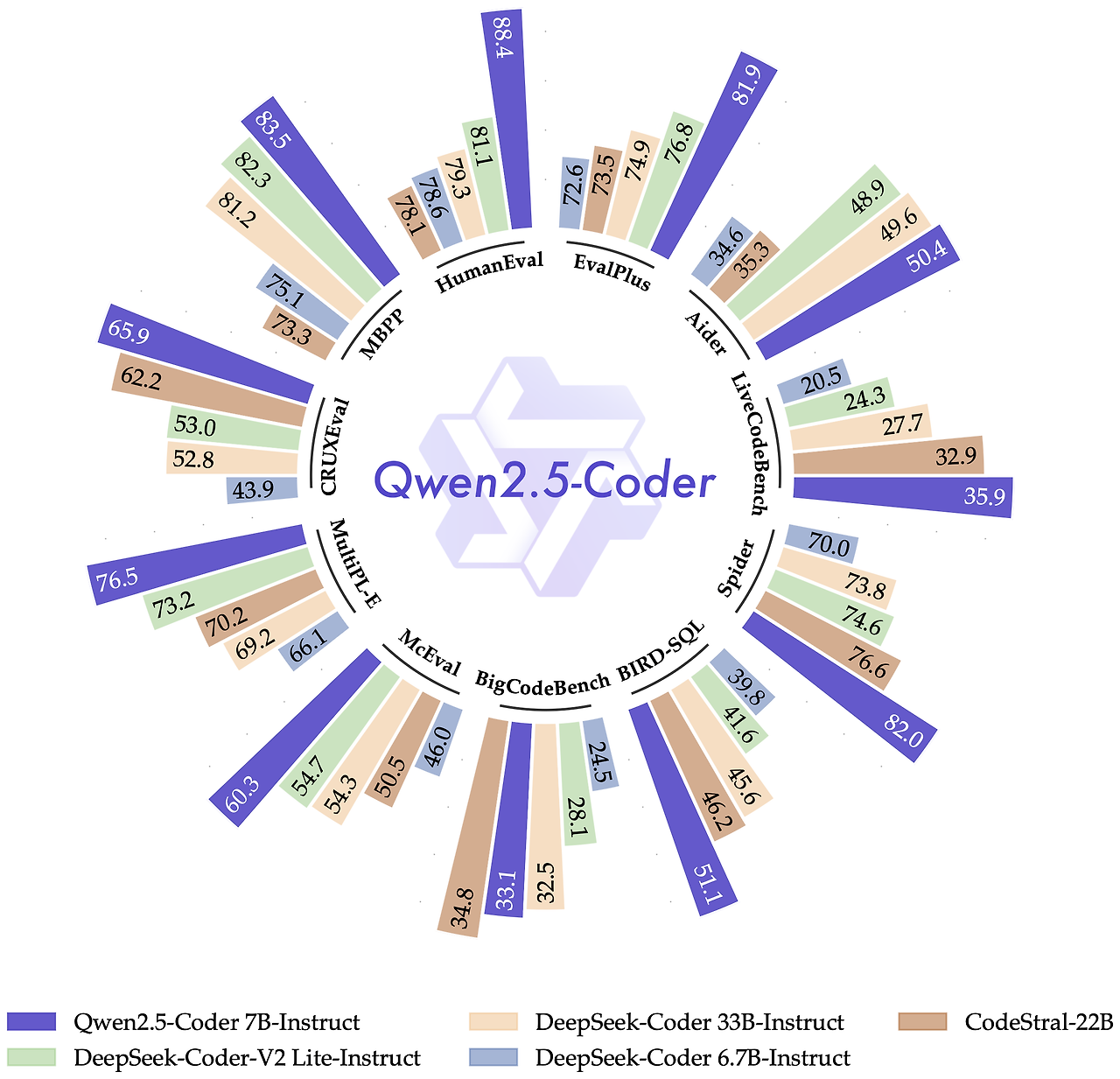
Qwen2.5-Coder는 위 그래프에서 보듯이 다양한 코드 생성 벤치마크에서 전반적으로 높은 성능을 보여줍니다. 특히 HumanEval, MBPP, EvalPlus 등의 벤치마크에서 최고 수준의 성능을 기록했습니다.
- HumanEval: Qwen2.5-Coder 7B-Instruct 모델은 88.4의 점수를 기록하여, DeepSeek-Coder-V2 Lite-Instruct 모델(81.1)을 넘어섰습니다. 이는 Qwen2.5-Coder가 인간 수준의 코드 생성 능력을 갖추고 있음을 시사합니다.
- MBPP: Qwen2.5-Coder는 83.5의 점수로, DeepSeek-Coder-V2 Lite-Instruct (82.3)와 DeepSeek-Coder 33B-Instruct(81.2)를 능가하는 뛰어난 성능을 보여주었습니다.
- EvalPlus: Qwen2.5-Coder는 EvalPlus에서도 73.5의 점수로 높은 성능을 기록하며, 다양한 프로그래밍 언어 및 작업에 대한 뛰어난 이해도를 보여주었습니다.
- 기타 벤치마크: Qwen2.5-Coder는 MultiPL-E, CRUXEVA 등 다양한 벤치마크에서 DeepSeek-Coder-V2 Lite-Instruct, DeepSeek-Coder 6.7B-Instruct, CodeStral-22B와 대등하거나 더 높은 성능을 기록했습니다.
Qwen2.5 코딩 추론 테스트
다음은 Qwen2.5 모델의 코딩, 수학 및 추론성능을 테스트해 보겠습니다. 코딩 테스트는 허깅페이스 스페이스 데모사이트에 접속해서 edabit.com의 Python, C++, JavaScript 문제로 테스트하였으며, 첫 번째 시도의 채점결과를 그대로 반영하였습니다.
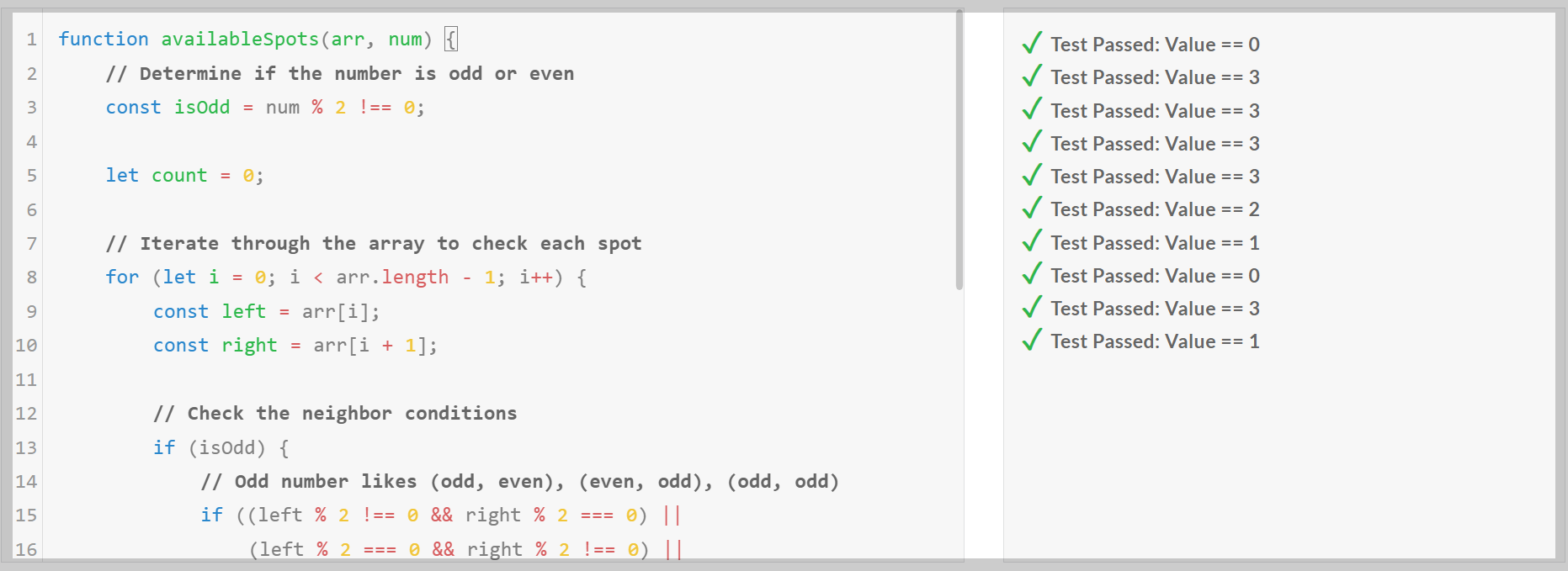
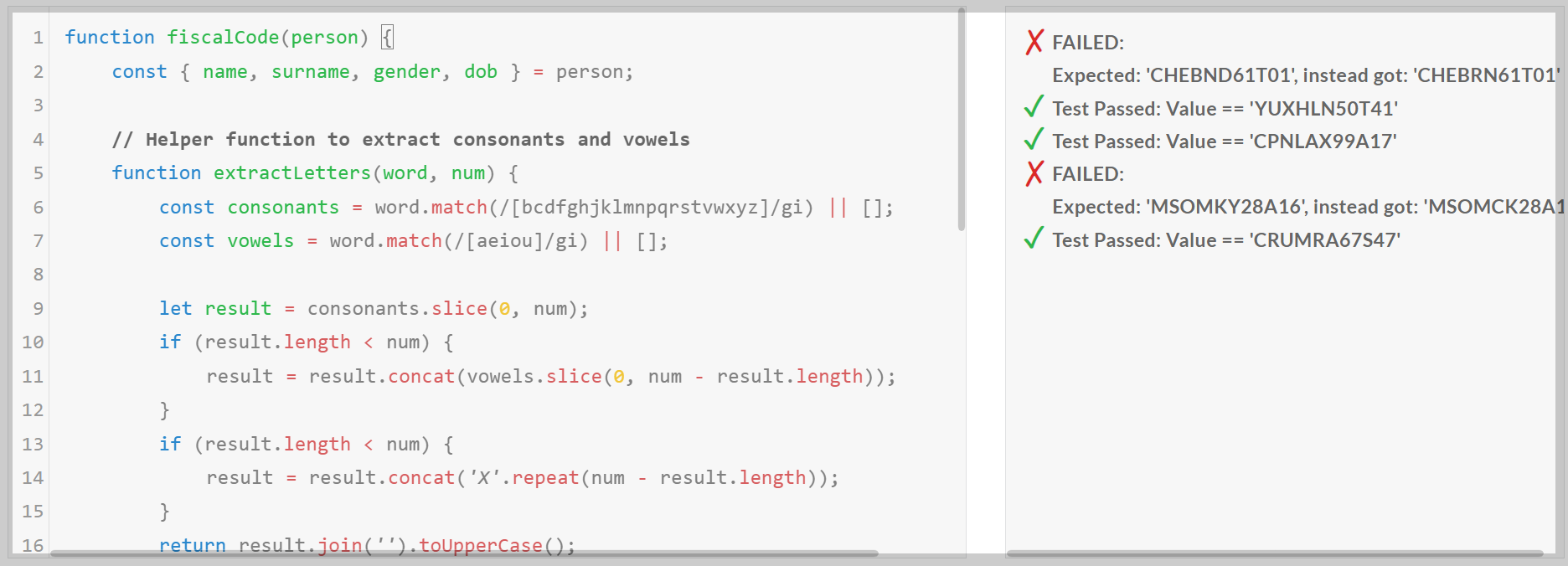
1. 코딩 테스트: 테스트 모델은 Qwen2.5-Coder-7B-Instruct입니다.
https://huggingface.co/spaces/Qwen/Qwen2.5-Coder-7B-Instruct
Qwen2.5-Coder-7B-Instruct - a Hugging Face Space by Qwen
huggingface.co
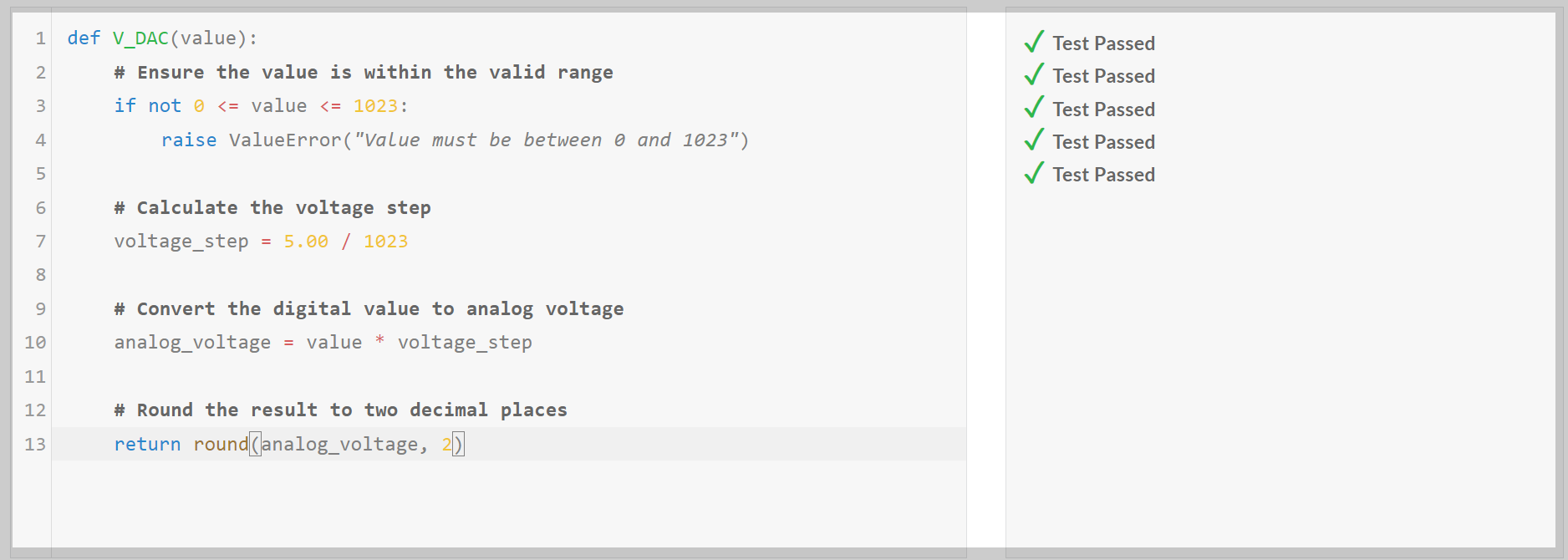


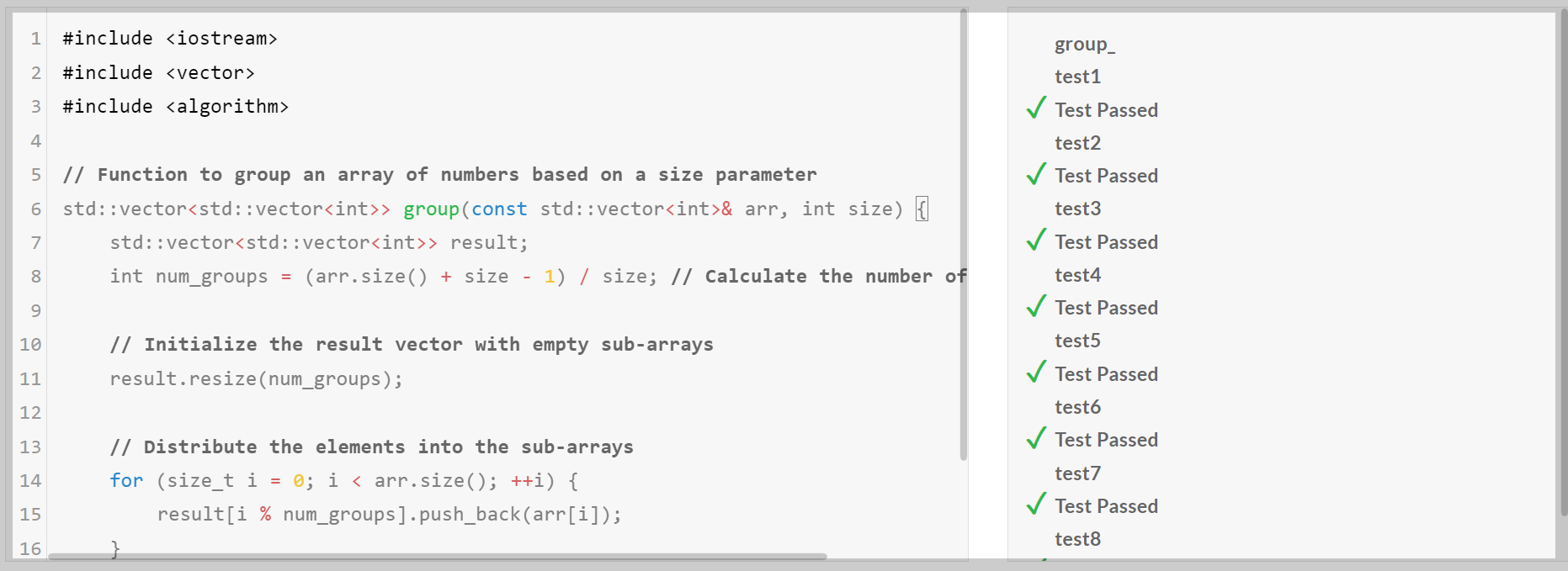
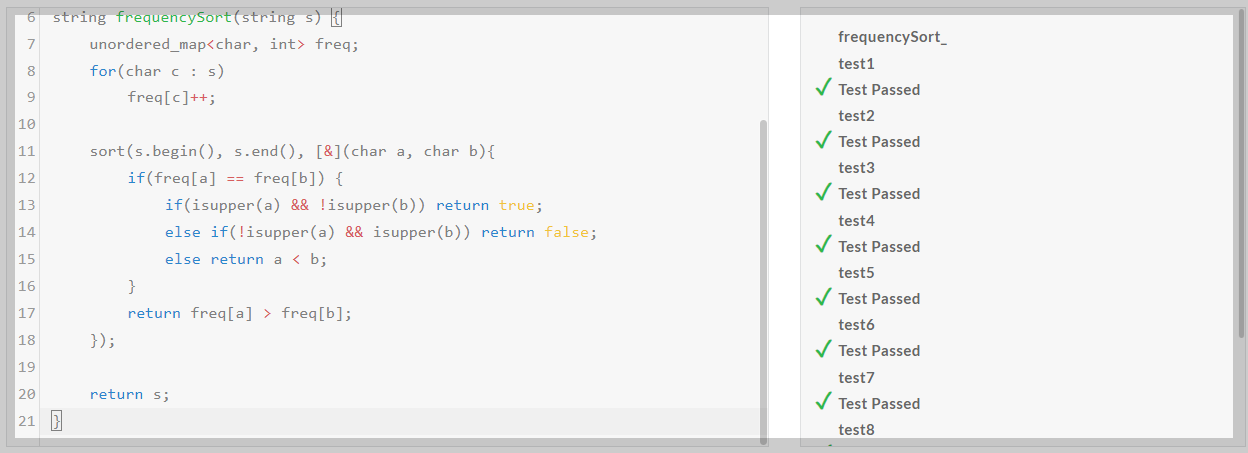
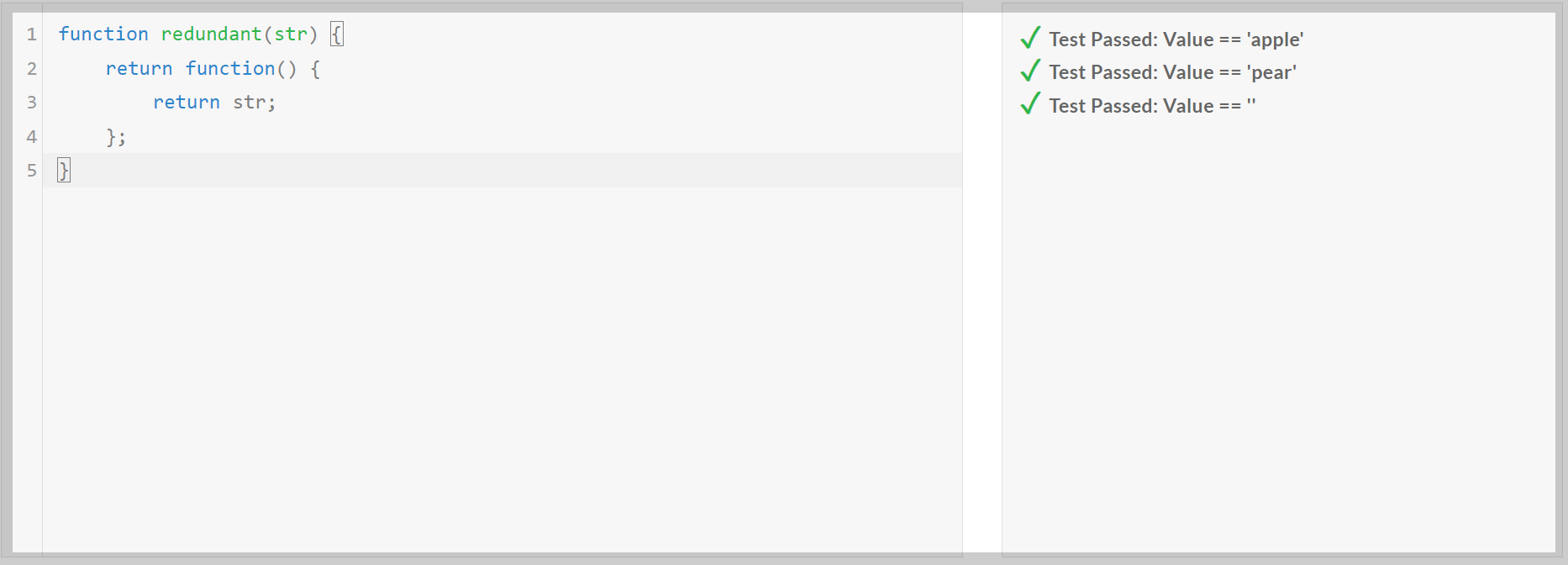
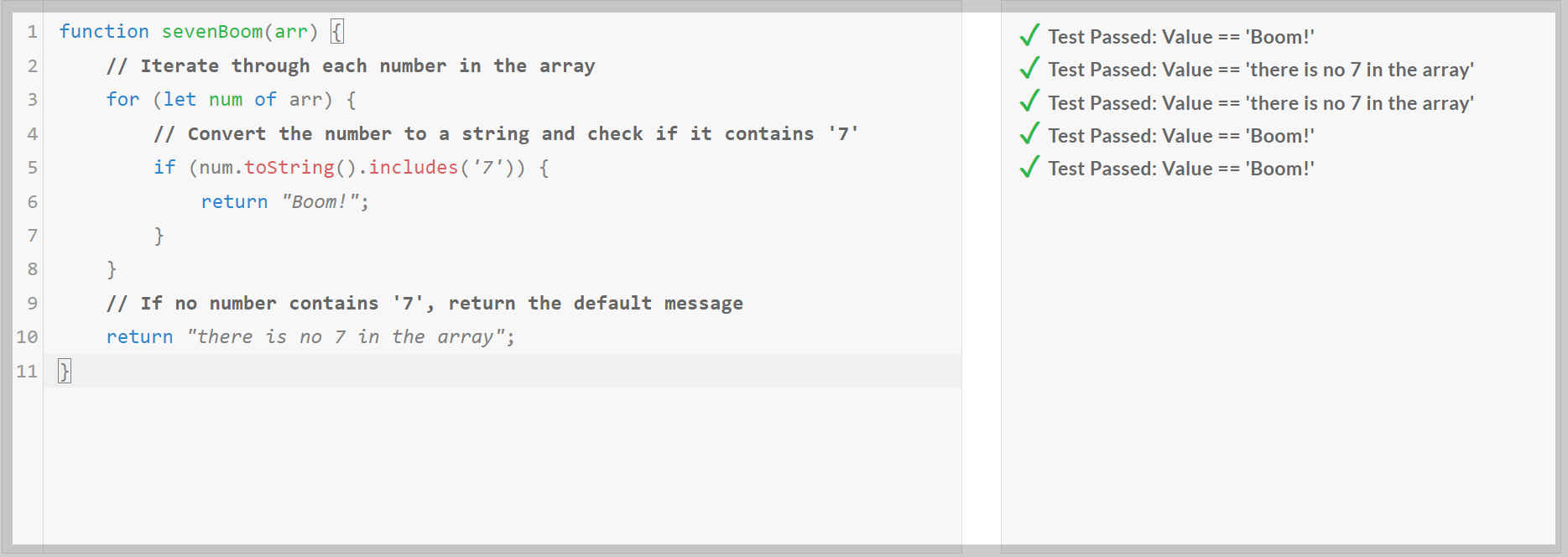
| Qwen 2.5-Coder-7B/Pass@1 | Medium | Hard | Very Hard | Expert |
| Python | Pass | Pass | Pass | Pass |
| C++ | Pass | Pass | Pass | Pass |
| JavaScript | Pass | Pass | Pass | Fail |
코딩 테스트 결과, Qwen2.5-Coder-7B는 Python, C++의 모든 난이도의 문제를 첫 번째 시도에 모두 맞혔으며, JavaScript의 최고 난이도 Expert 문제는 맞히지 못하였습니다.
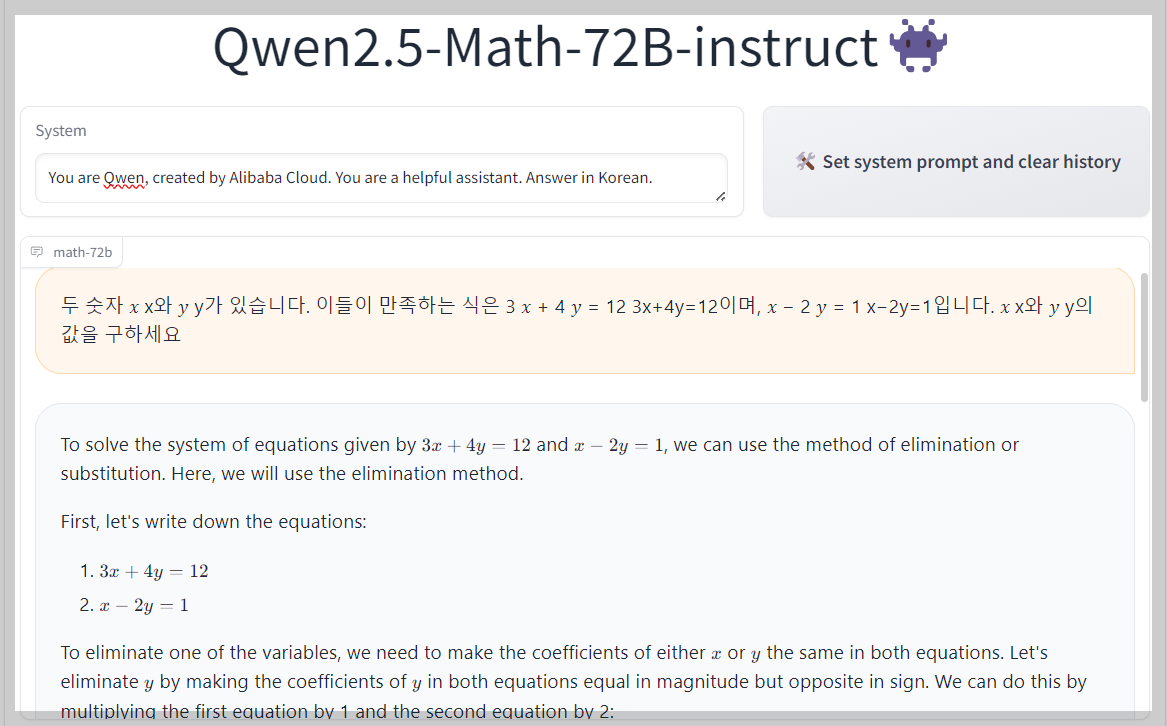
2. 수학테스트: 테스트 모델은 Qwen2.5-Math-72B-instruct입니다.
| No. | 문제 구분 | 문제 | Qwen2.5-Math-72B | GPT-4o-mini |
| 1 | 기초 대수 문제 | 두 숫자 𝑥 x와 𝑦 y가 있습니다. 이들이 만족하는 식은 3 𝑥 + 4 𝑦 = 12 3x+4y=12이며, 𝑥 − 2 𝑦 = 1 x−2y=1입니다. 𝑥 x와 𝑦 y의 값을 구하세요 | Pass | Pass |
| 2 | 기하학 문제 | 반지름이 7cm인 원의 넓이를 구하세요. 𝜋 = 3.14159 π=3.14159로 계산하세요. | Pass | Pass |
| 3 | 확률 문제 | 주사위를 두 번 던졌을 때, 두 숫자의 합이 7이 될 확률을 구하세요. | Pass | Pass |
| 4 | 수열 문제 | 첫 번째 항이 3이고, 공차가 5인 등차수열의 10번째 항을 구하세요. | Pass | Pass |
| 5 | 최적화 문제 | 어떤 직사각형의 둘레가 36cm입니다. 이 직사각형의 넓이를 최대화하려면 가로와 세로의 길이는 각각 얼마여야 하나요? | Pass | Pass |
| 6 | 복합 문제 | 복소평면에서 다음 극한값을 구하시오. lim[n→∞] (1 + i/n)^(n^2) 여기서 i는 허수단위 (i^2 = -1)입니다. | Pass | Pass |
수학 테스트 결과에서 Qwen2.5-Math-72B는 6문제 모두를 맞히며, 128B 파라미터의 GPT-4o-mini와 유사한 성능을 보였습니다.
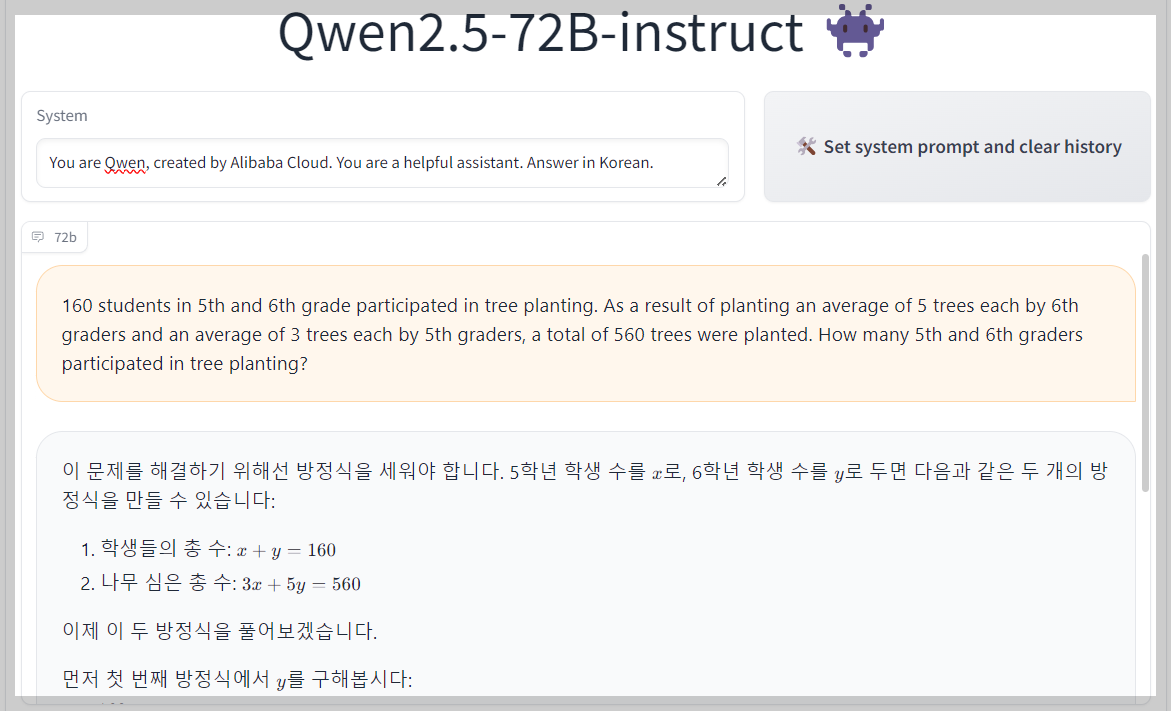
3. 추론 성능 테스트: 테스트 모델은 Qwen2.5-72B-instruct입니다.
| No. | 문제 | Qwen2.5-72B | GPT-4o-mini |
| 1 | 160 students in 5th and 6th grade participated in tree planting. As a result of planting an average of 5 trees each by 6th graders and an average of 3 trees each by 5th graders, a total of 560 trees were planted. How many 5th and 6th graders participated in tree planting? | Pass | Pass |
| 2 | Betty is saving money for a new purse. The purse costs $100. Betty only has half the money she needs. Her parents decide to give her $15 for that purpose, and her grandparents give her twice as much as her parents. How much more money does Betty need to buy the purse? | Pass | Pass |
| 3 | A national elementary school math competition was held, and three people, Young-hee, Chul-soo, and Jin-ho, participated. They are students from Seoul, Busan, and Incheon, and they received first, second, and third place awards, respectively. When you know the following, where is Jin-ho from and what place did he get? 1) Young-hee is not a player from Seoul. 2) Chul-soo is not a player from Busan. 3) The player from Seoul is not first place. 4) The player from Busan got second place. 5) Chul-soo is not third place. | Pass | Fail |
| 4 | There are three murderers in a room. A person enters the room and kills one of them. No one leaves the room. How many murderers are left in the room? Explain the reasoning process step by step. | Pass | Pass |
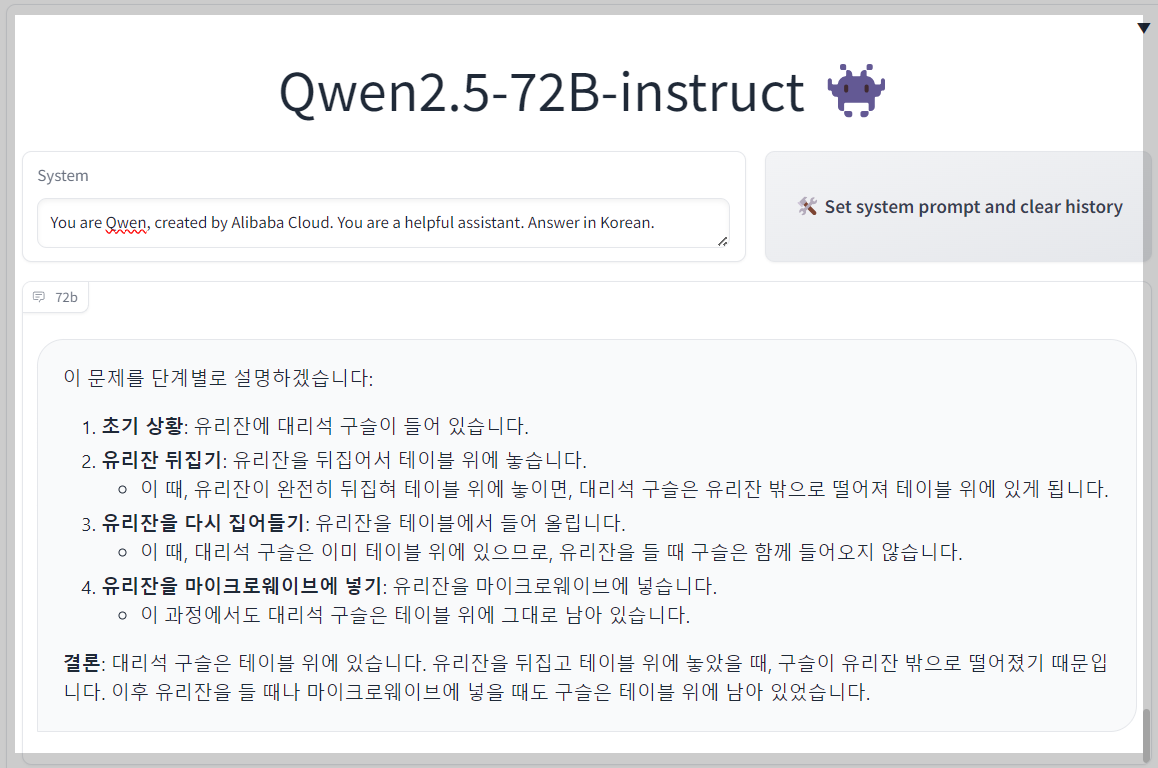
| 5 | A marble is put in a glass. The glass is then turned upside down and put on a table. Then the glass is picked up and put in a microwave. Where's the marble? Explain your reasoning step by step. | Pass | Pass |
추론 테스트에서 Qwen2.5-72B-instruct는 5문제 모두를 맞히며 우수한 추론 성능을 보였습니다. 특히 5번 문제는 최근 테스트한 모델 중 가장 명쾌하게 정답을 설명하였습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
마치며
Qwen2.5는 자연어 처리, 코딩, 수학 문제 해결 능력에서 탁월한 성과를 보이는 다목적 AI 모델로, 다양한 작업을 처리할 수 있는 강력한 도구입니다. 이 모델은 최신 벤치마크에서 우수한 결과를 기록하며, 특히 복잡한 추론과 멀티태스킹, 효율적인 메모리 관리 면에서 눈에 띄는 발전을 이루었습니다.
Qwen2.5 모델을 테스트해 본 느낌은 아래와 같습니다.
- 뛰어난 언어 이해 능력, 요약능력을 가지고 있다.
- 7B 코딩 모델은 적은 크기로 매우 우수한 성능을 보인다.
- 오픈소스 언어 모델 중 가장 명쾌한 추론 해결능력을 가지고 있다.
오늘 블로그는 여기까지입니다. 여러분도 Qwen2.5 모델을 한번 활용해보실길 추천드리면서, 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.06.08 - [AI 언어 모델] - Qwen-2:🌐27개 언어 구사, 알리바바의 자바스크립트 천재 언어 모델 💻
Qwen-2:🌐27개 언어 구사, 알리바바의 자바스크립트 천재 언어 모델 💻
안녕하세요! 오늘은 알리바바가 공개한 대형 언어 모델인 Qwen-2에 대해 알아보겠습니다. Qwen-2는 Qwen2-0.5B에서 1.5B, 7B, 57B, 72B까지 다섯 가지 크기의 사전 학습 및 명령어 조정 모델을 제공하며, 영
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 🎬Movie Gen: 메타의 차세대 미디어 생성 AI 모델🤖 (30) | 2024.10.05 |
|---|---|
| 👁️🤖Llama 3.2: 에지 컴퓨팅과 비전까지 확장한 Meta의 AI 모델 (36) | 2024.09.28 |
| 🧠GRIN MoE: 6.6B 활성 파라미터로 GPT-4o를 뒤쫓는 코딩 천재 모델 (0) | 2024.09.23 |
| 🖼️Pixtral 12B: 추론과 코딩에 강한 Mistral AI의 첫번째 멀티모달 모델 (28) | 2024.09.18 |
| 🌟업스테이지 Solar Pro Preview 분석: 단일 GPU 최강 AI 모델 (27) | 2024.09.16 |



