안녕하세요! 오늘은 메타가 어제 공개한 차세대 미디어 생성 AI 모델, Movie Gen에 대해서 알아보겠습니다. Movie Gen은 텍스트, 이미지, 비디오 및 오디오 입력을 기반으로 최대 1080p 해상도의 비디오와 자연스러운 오디오를 생성하며, 개인화 및 편집 기능을 지원합니다. 벤치마크에서 기존 모델들을 능가하는 성능을 보여, 특히 움직임의 자연스러움과 사실성, 사운드 효과에서 높은 평가를 받았습니다. 이 블로그에서는 Movie Gen의 개요, 주요 기능, 동작원리 및 벤치마크 결과에 대해 알아보겠습니다.

https://ai.meta.com/blog/movie-gen-media-foundation-models-generative-ai-video/
How Meta Movie Gen could usher in a new AI-enabled era for content creators
Whether a person is an aspiring filmmaker hoping to make it in Hollywood or a creator who enjoys making videos for their audience, we believe everyone should have access to tools that help enhance their creativity. Today, we’re excited to premiere Meta M
ai.meta.com
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Movie Gen 개요
Movie Gen은 텍스트 프롬프트, 이미지, 비디오 및 오디오를 포함한 다양한 입력을 기반으로 고품질 비디오와 오디오를 생성할 수 있습니다. Movie Gen은 크게 두 가지 기반 모델로 구성됩니다.
- Movie Gen Video: 텍스트-이미지 및 텍스트-비디오 생성을 위한 300억 개의 매개변수를 가진 기반 모델입니다. 이 모델은 최대 16초 길이의 고품질 HD 비디오를 생성하며, 다양한 화면비와 해상도, 길이를 자유롭게 설정할 수 있습니다. MovieGenVideo는 방대한 양의 이미지 및 비디오 데이터를 통해 훈련되어 객체의 움직임, 주체-객체 상호 작용, 기하학, 카메라 움직임 및 물리 법칙을 이해하고 다양한 개념에 대한 움직임을 학습합니다.
- Movie Gen Audio: 비디오 및 텍스트-오디오 생성을 위한 130억 개의 매개변수를 가진 기반 모델입니다. 입력 비디오와 동기화된 고품질의 영화 사운드 효과 및 음악을 생성하고 텍스트 프롬프트를 따를 수 있습니다. Movie Gen Audio는 다양한 길이의 오디오 생성을 자연스럽게 처리하며, 오디오 확장 기술을 통해 최대 수 분 길이의 비디오에 대한 장편의 일관된 오디오를 생성할 수 있습니다.
Movie Gen은 텍스트-비디오 생성, 비디오 개인화, 비디오 편집, 비디오-오디오 생성 및 텍스트-오디오 생성과 같은 다양한 미디어 생성 작업에서 최첨단 기술을 보여줍니다.
https://ai.meta.com/research/movie-gen/
Meta Movie Gen
Text input summary: A woman paints a canvas on an easel, in a wood-paneled room. The woman is wearing a white shirt. She has a calm expression as she concentrates on her work. A baby bear cub stands at her feet. The lighting is cool. Text input summary: Ma
ai.meta.com
Movie Gen 주요 기능
Movie Gen은 1080p HD 비디오 생성, 텍스트 기반 비디오 제작, 사용자 이미지를 통한 개인화된 비디오 생성, 오디오 생성과 같은 다양한 기능을 제공합니다.
- 고품질 비디오 생성: 1080p HD 해상도의 고품질 비디오를 생성할 수 있습니다. 다양한 화면비와 프레임 속도를 지원하며 최대 16초 길이의 비디오를 생성할 수 있습니다.
| Meta Movie Gen으로 생성한 동영상 |
- 텍스트 기반 비디오 생성: 텍스트 프롬프트를 기반으로 비디오를 생성할 수 있습니다.
| 텍스트 입력 요약: 한 소녀가 해변을 가로질러 달리고 연을 들고 있습니다. 그녀는 청바지 반바지와 노란색 티셔츠를 입고 있습니다. 태양이 내리쬐고 있습니다. |
- 비디오 개인화: 사용자의 이미지를 기반으로 개인화된 비디오를 생성할 수 있습니다. 예를 들어 사용자의 얼굴 이미지를 입력하면 해당 얼굴을 가진 인물이 등장하는 비디오를 생성합니다.
| 사용자의 이미지를 기반으로 개인화된 비디오 |
- 정밀한 비디오 편집: 사용자의 지시에 따라 비디오를 정밀하게 편집할 수 있습니다. 예를 들어 "비디오에 등장하는 자동차의 색상을 빨간색으로 변경"과 같은 지시를 통해 비디오를 편집할 수 있습니다.
| 텍스트 입력으로 비디오 편집 |
- 동기화된 오디오 생성: 비디오와 동기화된 오디오를 생성할 수 있습니다. Movie Gen Audio 모델은 비디오의 내용을 분석하여 그에 맞는 배경 음악, 효과음 등을 생성합니다.
| 비디오와 동기화된 오디오 생성 |
Movie Gen 동작 원리
Movie Gen은 딥러닝 기술, 특히 Transformer 기반 모델과 Flow Matching 기법을 사용하여 작동합니다. Flow Matching 기법에 대한 좀 더 자세한 설명은 아래 더 보기를 클릭하세요.
Flow Matching 기법은 목표 데이터 분포에서 샘플을 생성하기 위해 사전 분포(예: 가우시안)에서 샘플을 반복적으로 변경하는 생성 모델링 프레임워크입니다.
- 쉽게 말해, Flow Matching은 가우시안 노이즈에서 시작하여 점진적으로 변화시켜서 원하는 데이터(이미지, 비디오, 오디오)를 생성하는 방식입니다.
- 이 기법은 훈련 과정에서 생성 모델이 순수 가우시안 노이즈 샘플을 받아 이에 대한 속도를 예측하도록 합니다.
Movie Gen은 Flow Matching 기법을 사용하여 비디오 및 오디오 생성 모델을 훈련합니다.
- Movie Gen Video는 훈련 과정에서 Flow Matching을 통해 잠재 공간에서 생성된 비디오 샘플, 시간 단계, 노이즈 샘플을 사용하여 훈련 샘플을 구성합니다.
- Movie Gen Audio 또한 Flow Matching 목표 함수를 사용하여 오디오 샘플을 생성합니다.
Flow Matching은 기존의 미디어 생성 모델에서 주로 사용되던 Diffusion Model에 비해 몇 가지 장점을 제공합니다.
- 단순성: Flow Matching은 Diffusion Model보다 구현이 간단하며 노이즈 스케줄의 선택에 덜 민감합니다.
- 성능: Flow Matching은 Diffusion Model보다 전반적인 품질과 텍스트 정렬 측면에서 더 나은 생성 결과를 보여줍니다.
- 효율성: Flow Matching은 훈련 및 추론 효율성 측면에서 Diffusion Model보다 우수합니다.
이러한 장점들로 인해 Movie Gen은 Diffusion Model 대신 Flow Matching을 채택하여 모델을 훈련합니다.
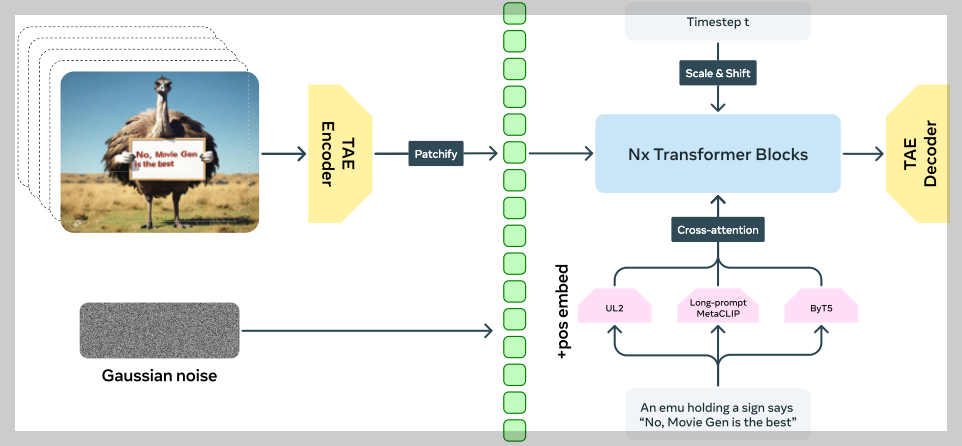
1. Movie Gen Video 동작 원리
- 입력: 사용자는 텍스트 프롬프트, 이미지 또는 비디오를 입력합니다.
- 텍스트/이미지 인코딩: 입력 텍스트는 사전 훈련된 텍스트 인코더(예: ByT5, UL2, Long-Prompt MetaCLIP)를 사용하여 특징 벡터로 변환되고, 입력 이미지는 Long-prompt MetaCLIP 비전 인코더를 사용하여 특징 벡터로 변환됩니다.
- 시공간 압축: 효율성을 위해 입력 비디오는 시공간적으로 압축된 잠재 공간으로 인코딩 됩니다. 이 과정은 TAE(Temporal Autoencoder) 인코더를 사용하여 수행됩니다.
- 비디오 생성: 인코딩 된 텍스트 및 이미지 특징과 잠재 공간의 샘플링된 가우시안 노이즈를 입력으로 받아 Transformer 기반 생성 모델이 잠재 공간에서 비디오를 생성합니다.
- 디코딩: 생성된 잠재 공간의 비디오는 TAE(Temporal Autoencoder) 디코더를 사용하여 다시 원래의 픽셀 공간으로 디코딩됩니다.
- 출력: 최종적으로 생성된 비디오가 출력됩니다.
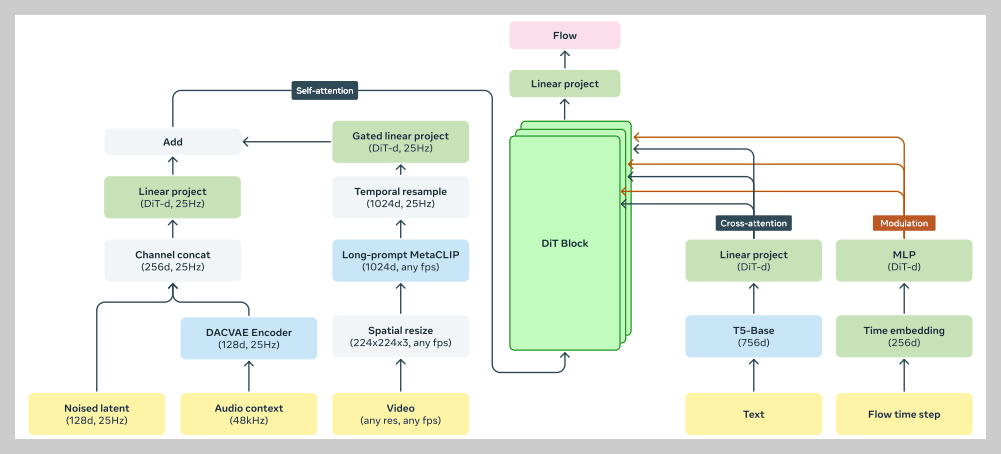
2. Movie Gen Audio 동작 원리
- 입력: Movie Gen Audio 모델은 비디오, 오디오 캡션, 그리고 부분적으로 생성된 오디오(오디오 확장의 경우)를 입력으로 받습니다.
- 특징 추출: 입력 비디오에서 Long-prompt MetaCLIP을 사용하여 시각적 특징을 추출하고, 입력 오디오(전체 또는 일부)는 DAC-VAE를 사용하여 잠재 특징으로 변환합니다. 오디오 캡션은 T5 모델을 사용하여 인코딩 됩니다.
- Difussion Transformer: 추출된 특징들은 Difussion Transformer 모델의 여러 계층에 걸쳐 입력되어 시간적 흐름에 따라 오디오 잠재 표현을 생성합니다.
- 오디오 생성/확장: 모델은 입력 오디오 컨텍스트를 기반으로 다음 오디오 프레임을 예측하며, 이전 생성된 오디오 세그먼트를 활용하여 자연스럽게 연결된 오디오를 생성합니다.
- 출력: 최종적으로 입력 비디오와 텍스트 프롬프트에 맞춰 생성된 고품질 오디오를 출력합니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Movie Gen 벤치마크 결과
Movie Gen은 다양한 벤치마크에서 SOTA(최신 기술 수준의) 성능을 달성했습니다.
- 텍스트-비디오 생성: Movie Gen Video는 Runway Gen3, LumaLabs, OpenAI Sora, Kling1.5 등의 기존 모델들을 능가하는 성능을 보였습니다. 특히, 움직임의 자연스러움, 프레임 일관성, 사실성, 미적 요소에서 높은 평가를 받았습니다.

- 비디오 개인화: 개인화된 Movie Gen Video는 ID-Animator를 포함한 이전 연구들보다 월등한 성능을 보였습니다. 특히, ID 일관성, 비디오 품질, 텍스트 정렬 측면에서 뛰어난 평가를 받았습니다.

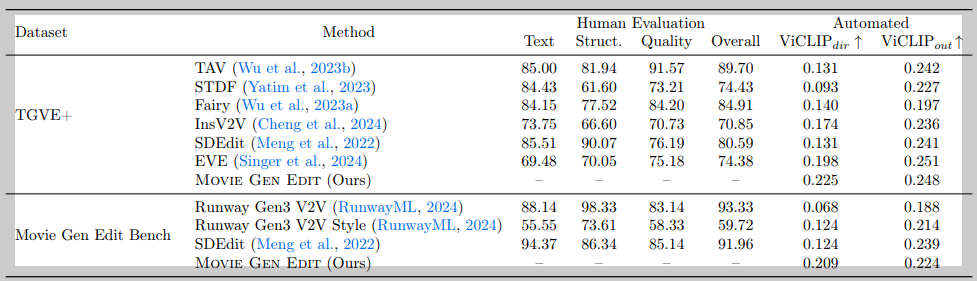
- 비디오 편집: Movie Gen Edit은 TGVE+ 벤치마크에서 EVE를 포함한 이전의 최첨단 기술보다 74% 더 선호되었습니다. 또한 Movie Gen Edit Bench에서 Runway Gen3 V2V 및 Runway Gen3 V2V Style 설정보다 선호되었습니다.
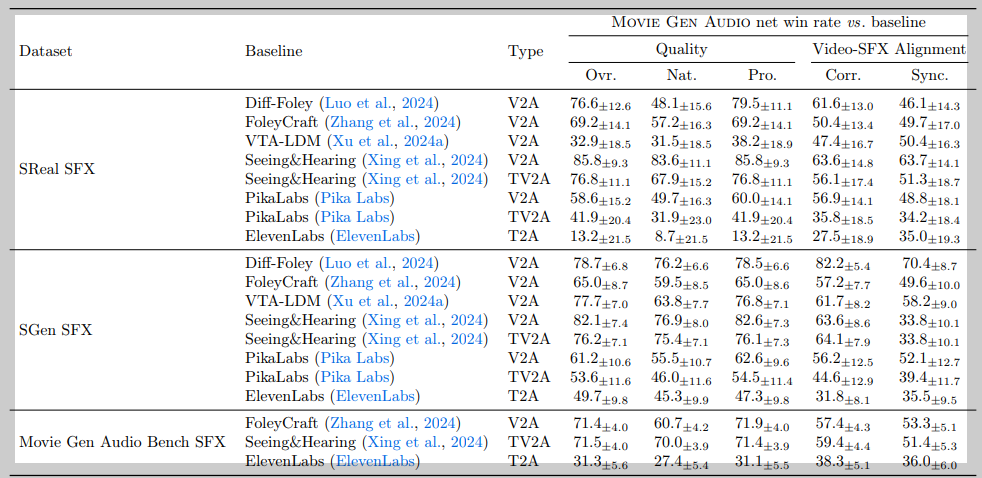
- 오디오 생성: Movie Gen Audio는 Diff-Foley, FoleyCraft, VTA-LDM, Seeing&Hearing, PikaLabs, ElevenLabs 등의 기존 오디오 생성 모델들보다 전반적으로 뛰어난 성능을 보였습니다. 특히, 사운드 효과 생성, 사운드 효과 및 음악 공동 생성, 오디오 확장을 사용한 장편 생성 작업에서 좋은 결과를 얻었습니다.
마치며
메타의 Movie Gen은 고품질 비디오 및 오디오 생성, 비디오 개인화 및 편집 기능을 제공하는 강력한 미디어 생성 AI 모델입니다. Movie Gen은 텍스트-비디오 합성, 비디오 개인화, 비디오 편집, 비디오-오디오 생성, 텍스트-오디오 생성 등 다양한 분야에 혁신을 가져올 것으로 기대됩니다. 아직 공개적으로 사용할 수는 없지만, 다양한 분야에서 활용될 수 있는 큰 잠재력을 가진 모델입니다.
오늘 블로그를 통해서 메타의 차세대 미디어 생성 AI 모델 Movie Gen에 대해 이해하시는데 도움이 되었기를 바라면서 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.02.17 - [AI 언어 모델] - Sora: 현실 세계를 시뮬레이션하는 OpenAI 비디오 생성 모델
Sora: 현실 세계를 시뮬레이션하는 OpenAI 비디오 생성 모델
안녕하세요! 오늘은 OpenAI에서 어제 공개한 새로운 생성형 AI 모델 Sora에 대해서 알아보겠습니다. Sora는 다양한 길이, 종횡비 및 해상도를 가진 비디오 및 이미지를 생성할 수 있는 시각 데이터 모
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 🌟Aria: 최신 오픈소스 멀티모달 네이티브 MoE 모델 (25) | 2024.10.14 |
|---|---|
| 🚀Flux 1.1 Pro: 6배 더 빨라진 고품질 이미지 생성 모델🎨 (22) | 2024.10.07 |
| 👁️🤖Llama 3.2: 에지 컴퓨팅과 비전까지 확장한 Meta의 AI 모델 (36) | 2024.09.28 |
| 🚀Qwen2.5: 오픈소스 모델 최고 성능! MMLU 86.1% HumanEval 88.4% 달성! (29) | 2024.09.26 |
| 🧠GRIN MoE: 6.6B 활성 파라미터로 GPT-4o를 뒤쫓는 코딩 천재 모델 (0) | 2024.09.23 |



