안녕하세요! 오늘은 알리바바에서 공개한 Qwen 시리즈의 최신 모델, QwQ-Max-Preview에 대해 살펴보겠습니다. QwQ-Max-Preview는 기존 Qwen2.5-Max를 기반으로 더욱 강화된 추론 능력과 다재다능한 문제 해결 능력을 갖춘 AI 모델입니다. 특히 수학, 코딩, 추론 작업에서 뛰어난 성능을 보이며, Agent 관련 워크플로우에서도 강력한 성능을 자랑하는 QwQ-Max-Preview는 향후 Apache 2.0 라이선스 오픈 소스로 공개될 예정이라고 합니다. 이번 블로그에서는 QwQ-Max-Preview의 특징과 주요 기능, 벤치마크 결과를 분석하고, 여러 가지 성능을 테스트해 보겠습니다. 그럼, 함께 떠나볼까요?

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
1. QwQ-Max-Preview 개요
QwQ-Max-Preview는 Qwen 시리즈의 최신 모델로서, 심층 추론과 다재다능한 문제 해결 능력을 향상시키는 데 중점을 두고 설계되었습니다. Qwen2.5-Max의 견고한 기반 위에 구축된 이 프리뷰 모델은 수학, 코딩, 일반적인 작업에서 뛰어난 성능을 제공하며, 특히 Agent 관련 워크플로우에서 두각을 나타냅니다. 향후 출시될 QwQ-Max의 기능을 미리 엿볼 수 있는 버전으로, 지속적인 개선 작업을 거쳐 Apache 2.0 라이선스로 오픈 소스 출시될 예정이라고 합니다.
https://qwenlm.github.io/blog/qwq-max-preview/
<think>...</think> QwQ-Max-Preview
QWEN CHAT DISCORD This is a blog created by QwQ-Max-Preview. We hope you enjoy it! Introduction <think> Okay, the user wants me to create a title and introduction for their blog announcing the release of QwQ-Max-Preview. Let me start by understanding the k
qwenlm.github.io
QwQ-Max-Preview 모델의 주요 사양은 다음과 같습니다.
|
사양 구분
|
내 용
|
|
기반 아키텍처
|
수정된 Transformer 아키텍처
|
|
Attention Heads
|
64개
|
|
Layer
|
48-layer deep network
|
|
Embedding 차원
|
4096-dimensional embeddings
|
|
학습 데이터
|
3.2조 개 토큰(영어 78%, 중국어 15%, 기타 언어 7%, 코드, 수학, 과학 논문 기술 콘텐츠 34%)
|
|
하드웨어 요구 사항
|
최소: 4×A100 GPUs (80GB VRAM), 권장: 8×H100 nodes (full capabilities) |
2. QwQ-Max-Preview 특징 및 주요 기능
- 심층 추론 능력: QwQ-Max-Preview는 복잡한 문제를 해결하고 논리적인 추론을 수행하는 데 탁월합니다.
- 다양한 분야에서의 활용: 수학, 코딩, 일반적인 작업 등 다양한 분야에서 뛰어난 성능을 보입니다.
-
수학 능력: 정리 증명 - IMO Shortlist 문제의 85% 성공적으로 검증, 응용 수학 - 전산 물리학 과제에서 94% 정확도, 통계적 추론 - Bayesian 추론 작업에서 89% 성공률
- Agent 관련 워크플로우: 개방형 환경에서 83% 작업 완료율, 이전 버전에 비해 4.7배 빠른 응답 시간, 다단계 워크플로우 실행에서 91% 정확도 등 Agent와 관련된 작업에서 뛰어난 성능을 제공합니다.
- Qwen Chat 앱: Qwen Chat 전용 앱을 통해 사용자는 문제 해결, 코드 생성, 논리적 추론과 같은 작업을 원활하게 수행할 수 있습니다. 이 앱은 기술적인 전문 지식이 없어도 AI를 활용할 수 있도록 직관적인 인터페이스를 제공하며, 실시간 응답성과 생산성 도구와의 통합을 우선시하여 전 세계 사용자가 쉽게 접근할 수 있도록 지원합니다.

- 소규모 추론 모델 오픈 소싱: 경량의 리소스 효율적인 솔루션의 필요성을 인식하여 로컬 장치 배포를 위해 QwQ-32B와 같은 일련의 소규모 QwQ 변형을 출시할 예정입니다
- 커뮤니티 중심 혁신: QwQ-Max, Qwen2.5-Max 및 소규모 모델을 오픈 소싱함으로써 개발자, 연구원 및 취미 개발자 간의 협력을 촉진합니다. 커뮤니티는 이러한 모델을 실험하고, 미세 조정하고, 교육 도구에서 자율 에이전트에 이르기까지 특정 사용 사례에 맞게 확장할 수 있습니다.
3. QwQ-Max-Preview 벤치마크 결과
|
벤치마크
|
QwQ-Max-Preview
|
GPT-4
|
Claude 3
|
CodeLlama-70B
|
DeepSeek-Coder
|
Mixtral 8x22B
|
|
GSM8K (Grade School Math)
|
94.7%
|
92.3%
|
89.1%
|
-
|
-
|
- |
|
HumanEval (Python Coding)
|
82.4%
|
-
|
-
|
76.8%
|
79.2%
|
- |
|
MMLU (Massive Multitask Language Understanding)
|
83.1
|
86.4%
|
-
|
-
|
- |
77.6%
|
|
Task
|
QwQ-Max-Preview
|
Human Developer
|
|
코드 생성(파이썬)
|
함수 당 4.2s
|
함수 당 15min
|
|
버그 탐지
|
98% 정확도
|
82% 정확도
|
|
알고리즘 최적화
|
73% 효율성 향상
|
41% 효율성 향상
|
QwQ-Max-Preview는 다양한 벤치마크에서 뛰어난 성능을 보입니다. GSM8K에서 94.7%로 GPT-4(92.3%)와 Claude 3(89.1%)를 능가하며, HumanEval 파이썬 코딩에서 82.4%로 CodeLlama-70B(76.8%)와 DeepSeek-Coder(79.2%) 보다 높은 성능을 나타냅니다. 또한 QwQ-Max-Preview는 코드 생성(파이썬)에서 함수 당 4.2초, 버그 탐지에서 98% 정확도, 알고리즘 최적화에서 73% 효율성 향상을 보이며 인간 개발자보다 우수한 결과를 보여줍니다
QwQ-Max-Preview: A Deep Dive into the Next Generation of AI Reasoning Models
Introduction: The Evolution of Qwen Models
medium.com
4. QwQ-Max-Preview 성능 테스트
다음은 QwQ-Max-Preview의 성능을 테스트해 볼 텐데요. 먼저 모델 소개 블로그의 테스트 문제를 그대로 가져와서 추론 능력을 테스트해 보겠습니다.
- 구면 내에서 튀는 100개의 노란색 공 생성 스크립트: 천천히 회전하는 구 내에서 노란색 공이 머무르면서 충돌 감지를 처리하는 스크립트를 p5.js로 구현하기
write a script for 100 bouncing yellow balls within a sphere, make sure to handle collision detection properly. make the sphere slowly rotate. make sure balls stays within the sphere. implement it in p5.js
구면 내에서 100개의 튀는 노란색 공에 대한 스크립트를 작성해줘, 충돌 감지를 제대로 처리해야 해. 구가 천천히 회전하도록 해줘. 공이 구 안에 머무르도록 해줘. p5.js로 구현해줘

| QwQ가 생성한 구면 내 100개의 노란공 생성 스크립트 실행결과 동영상 |
- 지구-화성 탐사궤도 애니메이션 생성: 우주선이 지구에서 출발해서 화성까지 갔다가 돌아오는 애니메이션 구현
Generate code for an animated 3D plot of a launch from earth landing on mars and then back to earth at the next launch window
지구에서 화성에 착륙한 후 다음 발사 창에서 지구로 돌아오는 애니메이션 3D 플롯에 대한 코드를 생성해줘
Claude-3.7-Sonnet를 활용해서 동일한 프롬프트로 Grok3가 생성했던 코드와 비교해 본 결과, QwQ-Max-Preview가 물리적으로 더 정확한 구현을 했다고 답하였습니다.

다음은 QwQ-Max-Preview의 코딩, 수학, 추론 성능을 테스트해 보겠습니다.
1) 코딩 테스트


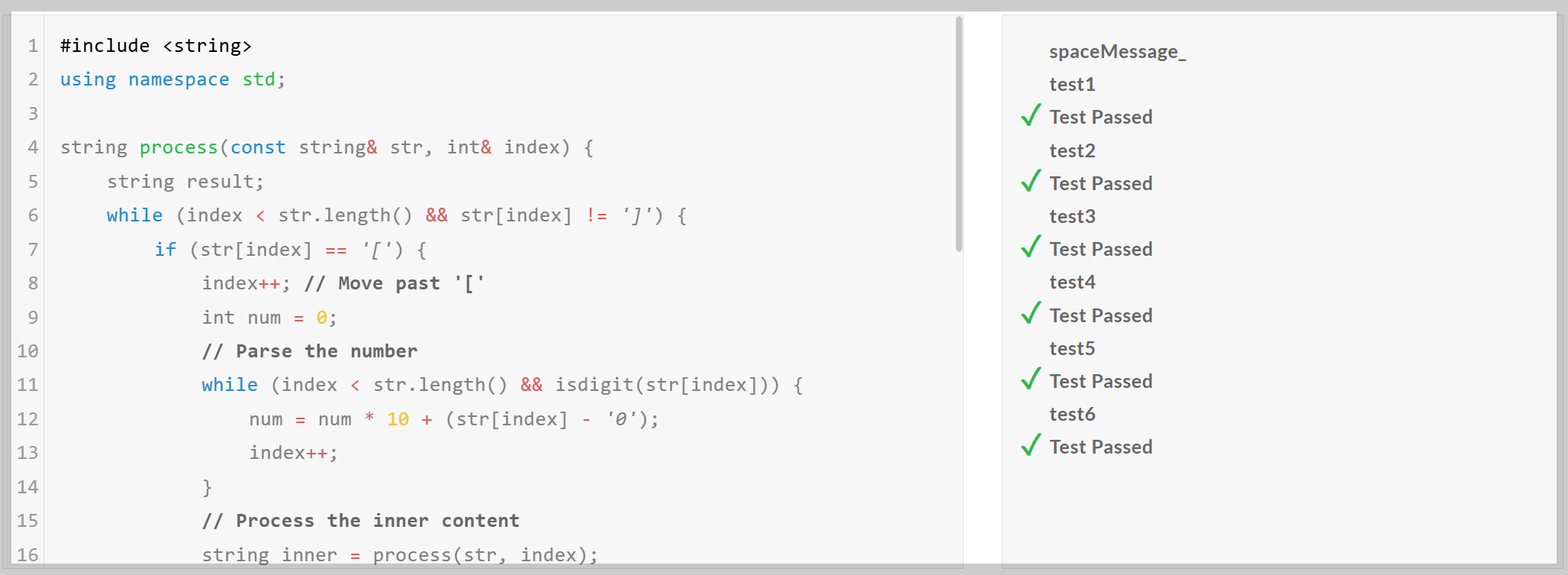
| QwQ | Medium | Hard | Very Hard | Expert |
| Python | Pass | Pass | Pass | Pass |
| JavaScript | Pass | Pass | Pass | Pass |
| C++ | Pass | Pass | Pass | Pass |
코딩 테스트 결과 QwQ-Max-Preview는 모든 난이도 문제를 성공하였지만, C++ Expert 난이도 문제를 해결하는 과정에서 추론 토큰을 약 4만 자 가까이 출력하였습니다.
2) 수학 테스트
| No. | 문제 구분 | 문제 | QwQ |
| 1 | 기초 대수 문제 | 두 숫자 𝑥 x와 𝑦 y가 있습니다. 이들이 만족하는 식은 3 𝑥 + 4 𝑦 = 12 3x+4y=12이며, 𝑥 − 2 𝑦 = 1 x−2y=1입니다. 𝑥 x와 𝑦 y의 값을 구하세요 | Pass |
| 2 | 기하학 문제 | 반지름이 7cm인 원의 넓이를 구하세요. 𝜋 = 3.14159 π=3.14159로 계산하세요. | Pass |
| 3 | 확률 문제 | 주사위를 두 번 던졌을 때, 두 숫자의 합이 7이 될 확률을 구하세요. | Pass |
| 4 | 수열 문제 | 첫 번째 항이 3이고, 공차가 5인 등차수열의 10번째 항을 구하세요. | Pass |
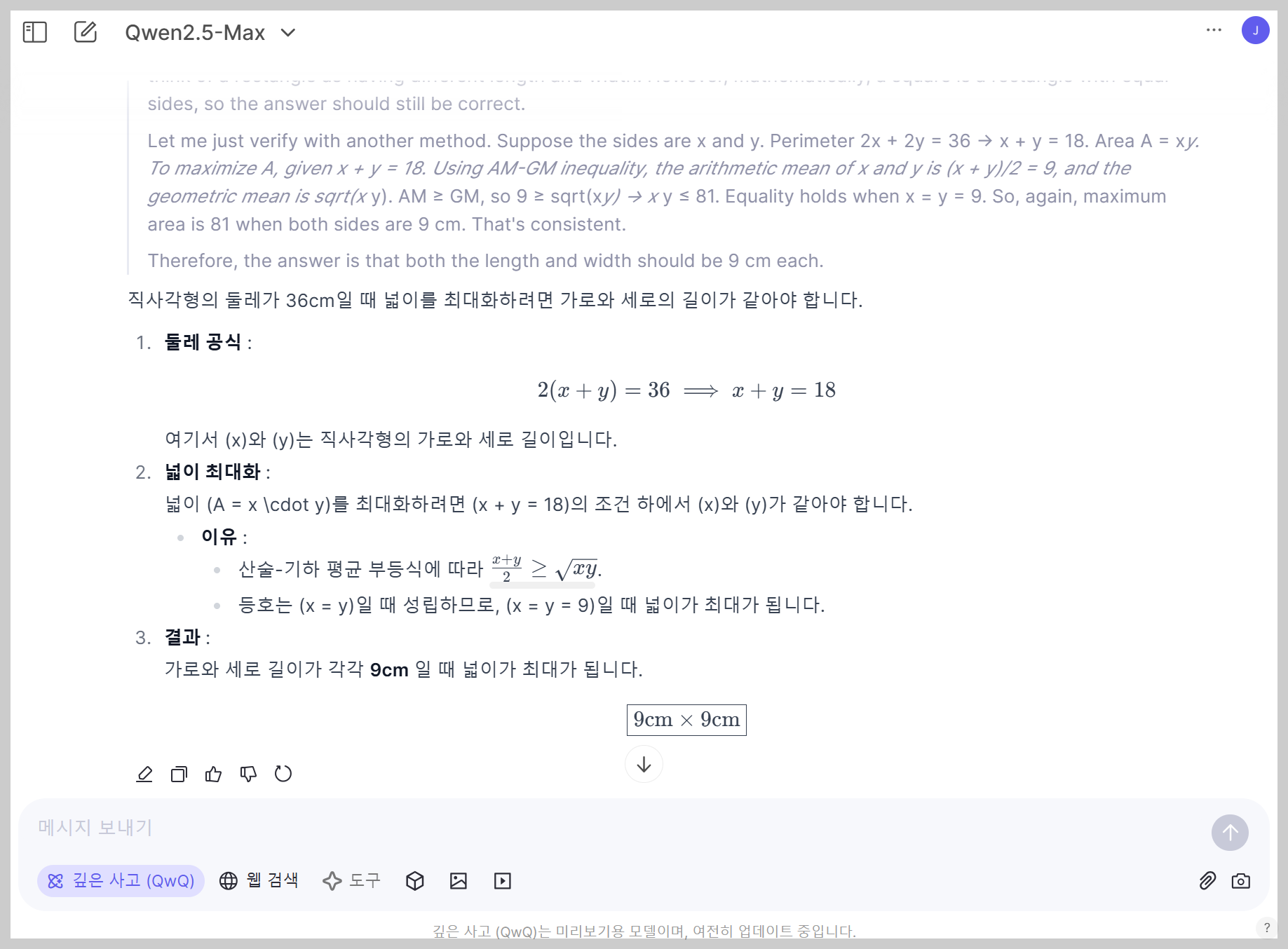
| 5 | 최적화 문제 | 어떤 직사각형의 둘레가 36cm입니다. 이 직사각형의 넓이를 최대화하려면 가로와 세로의 길이는 각각 얼마여야 하나요? | Pass |
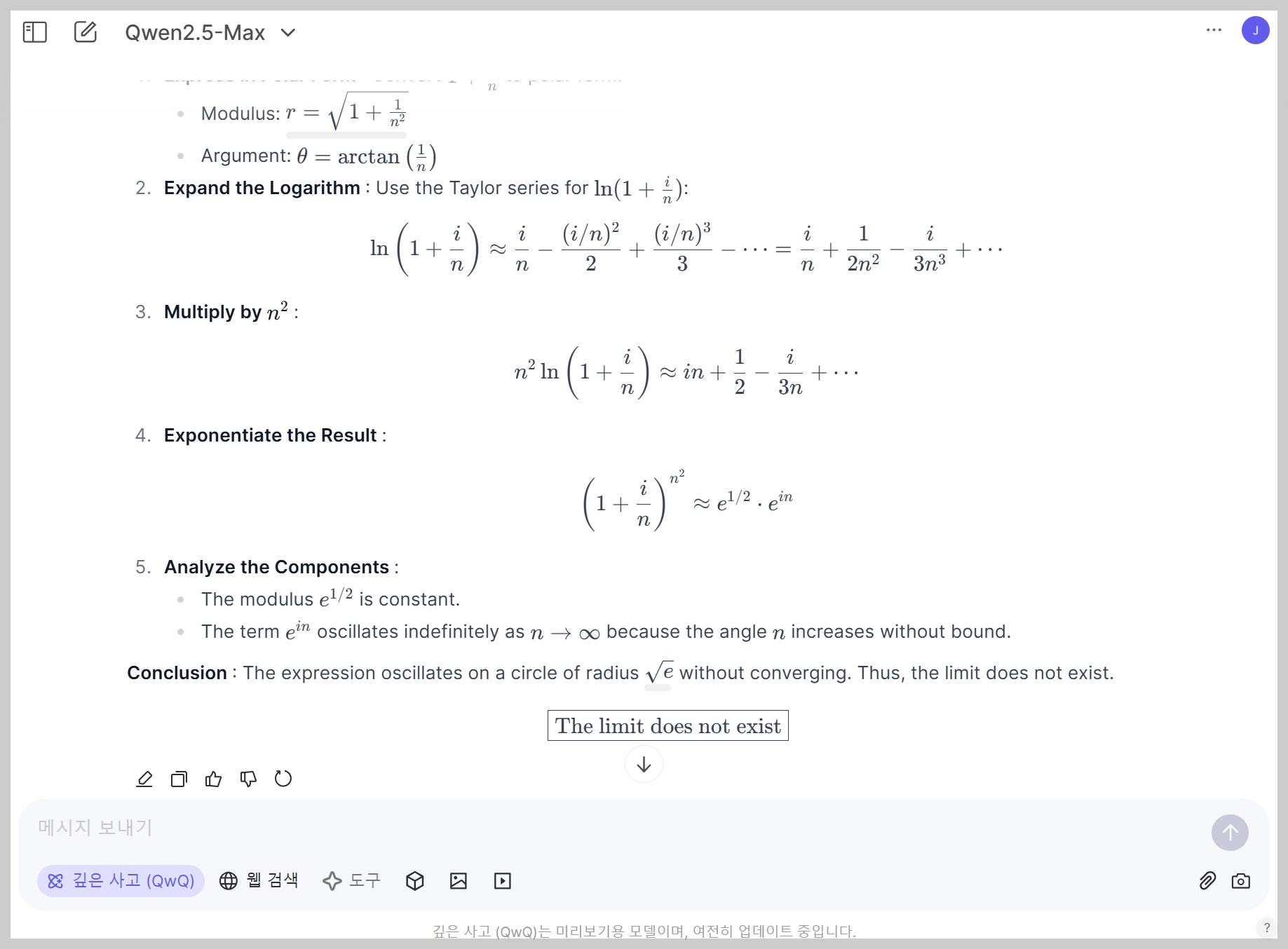
| 6 | 복합 문제 | 복소평면에서 다음 극한값을 구하시오. lim[n→∞] (1 + i/n)^(n^2) 여기서 i는 허수단위 (i^2 = -1)입니다. | Pass |
수학 테스트에서 QwQ-Max-Preview는 기초 대수, 기하학, 확률, 수열, 최적화, 복합문제 등 6문제를 모두 성공하였습니다.
3) 추론 테스트
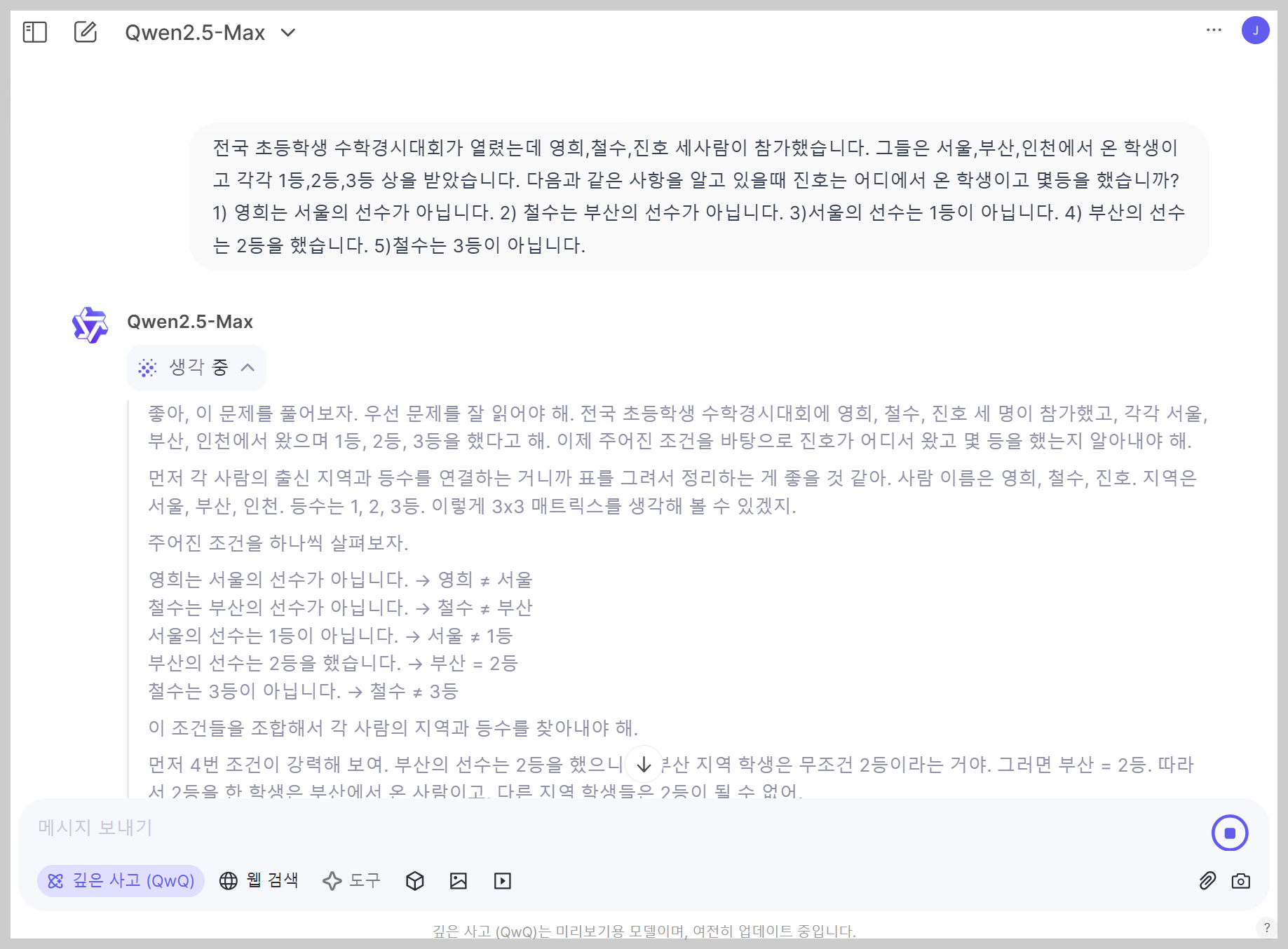

| No. | 문제 | QwQ |
| 1 | 5학년과 6학년 학생 160명이 나무 심기에 참가하였습니다. 6학년 학생들이 각각 평균5그루,5학년 학생들이 각각 평균 3그루씩 심은 결과 모두 560그루를 심었습니다. 나무심기에 참가한 5,6학년 학생은 각각 몇명일까요? |
Pass |
| 2 | 베티는 새 지갑을 위해 돈을 모으고 있습니다. 새 지갑의 가격은 $100입니다. 베티는 필요한 돈의 절반만 가지고 있습니다. 그녀의 부모는 그 목적을 위해 $15를 주기로 결정했고, 할아버지와 할머니는 그녀의 부모들의 두 배를 줍니다. 베티가 지갑을 사기 위해 더 얼마나 많은 돈이 필요한가요? | Pass |
| 3 | 전국 초등학생 수학경시대회가 열렸는데 영희,철수,진호 세사람이 참가했습니다. 그들은 서울,부산,인천에서 온 학생이고 각각 1등,2등,3등 상을 받았습니다. 다음과 같은 사항을 알고 있을때 진호는 어디에서 온 학생이고 몇등을 했습니까? 1) 영희는 서울의 선수가 아닙니다. 2) 철수는 부산의 선수가 아닙니다. 3)서울의 선수는 1등이 아닙니다. 4) 부산의 선수는 2등을 했습니다. 5)철수는 3등이 아닙니다. | Pass |
| 4 | 방 안에는 살인자가 세 명 있습니다. 어떤 사람이 방에 들어와 그중 한 명을 죽입니다. 아무도 방을 나가지 않습니다. 방에 남아 있는 살인자는 몇 명입니까? 단계별로 추론 과정을 설명하세요. | Pass |
| 5 | A marble is put in a glass. The glass is then turned upside down and put on a table. Then the glass is picked up and put in a microwave. Where's the marble? Explain your reasoning step by step. | Pass |
| 도로에 5대의 큰 버스가 차례로 세워져 있는데 각 차의 뒤에 모두 차의 목적지가 적혀져 있습니다. 기사들은 이 5대 차 중 2대는 A시로 가고, 나머지 3대는 B시로 간다는 사실을 알고 있지만 앞의 차의 목적지만 볼 수 있습니다. 안내원은 이 몇 분의 기사들이 모두 총명할 것으로 생각하고 그들의 차가 어느 도시로 가야 하는지 목적지를 알려 주지 않고 그들에게 맞혀 보라고 하였습니다. 먼저 세번째 기사에게 자신의 목적지를 맞혀 보라고 하였더니 그는 앞의 두 차에 붙여 놓은 표시를 보고 말하기를 "모르겠습니다." 라고 말하였습니다. 이것을 들은 두번째 기사도 곰곰히 생각해 보더니 "모르겠습니다." 라고 말하였습니다. 두명의 기사의 이야기를 들은 첫번째 기사는 곰곰히 생각하더니 자신의 목적지를 정확하게 말하였습니다. 첫번째 기사가 말한 목적지는 어디입니까? | Pass |
QwQ-Max-Preview는 이 블로그의 코딩, 수학, 추론테스트를 모두 통과하였습니다.
| 구분 | 코딩 테스트 결과 | 수학 테스트 결과 | 추론 테스트 결과 | 평균 |
| QwQ | 100 | 100 | 100 | 100 |
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
5. 맺음말
지금까지 QwQ-Max-Preview의 주요 특징과 성능을 살펴보았습니다. 이 모델은 수학, 코딩, 추론 능력에서 뛰어난 성과를 보였으며, 특히 우주선 탐사궤도 애니메이션 코드 생성은 최신 모델인 Grok-3보다도 정확한 코딩 성능을 보여주었습니다. 벤치마크 결과에서도 GPT-4o, Claude 3.5 Sonnet과 어깨를 나란히 하며 경쟁력을 입증했으며, 향후 정식 버전에서는 더욱 향상된 기능을 기대해 볼 수 있을 것 같습니다.
또한, QwQ-Max-Preview는 오픈 소스로 제공될 예정이기 때문에 개발자와 연구자들이 직접 실험하고 개선할 수 있는 기회를 가질 수 있습니다. 여러분도 모델을 직접 테스트해 보시고, AI의 발전을 함께 경험해 보시는 건 어떨까요? 오늘의 리뷰는 여기까지입니다. 다음에도 더 유익하고 흥미로운 AI 소식으로 찾아뵙겠습니다! 감사합니다.

2025.01.31 - [AI 언어 모델] - 🔥Qwen2.5 Max: DeepSeek-V3를 앞선 알리바바의 대규모 MoE 모델
🔥Qwen2.5 Max: DeepSeek-V3를 앞선 알리바바의 대규모 MoE 모델
안녕하세요! 오늘은 알리바바 클라우드가 새롭게 공개한 대규모 MoE(Mixture-of-Experts) 모델, Qwen2.5-Max에 대해 살펴보겠습니다. Qwen2.5-Max는 20조 개 이상의 토큰으로 학습된 거대한 언어 모델로, MoE 아
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 🤖MS의 첫 멀티모달 AI, Phi-4-multimodal과 Phi-4-mini-3.8B 분석 (4) | 2025.03.09 |
|---|---|
| 🎯QwQ-32B: 20배 작은 모델로 DeepSeek-R1 따라잡은 강화 학습 모델 (10) | 2025.03.08 |
| 📹🚀🔓Wan2.1: Sora보다 강력한 알리바바의 최강 오픈소스 비디오 AI (7) | 2025.03.03 |
| 🌍🚀세계 최초 하이브리드 추론 모델 Claude 3.7 Sonnet과 Claude Code 분석 (4) | 2025.02.26 |
| 🔍🤖 Grok-3: 일론 머스크가 극찬한 "지구에서 가장 똑똑한 AI 챗봇" (4) | 2025.02.19 |



