안녕하세요! 오늘은 AI 업계에 큰 파장을 일으킨 중국의 AI 스타트업, DeepSeek의 "DeepSeek Open Source Week"와 혁신적인 기술들에 대해 살펴보겠습니다. DeepSeek은 5일 동안 자사의 핵심 AI 인프라 기술 5종을 오픈소스로 공개하며, AI 개발의 투명성, 커뮤니티 기여, 그리고 연구 개발 가속화에 대한 의지를 밝혔습니다. DeepSeek의 이러한 행보는 Meta, xAI 등 다른 기업들의 AI 오픈소스에 대한 수요 상승과 맞물려 더욱 주목받았으며, AI 업계에 투명성과 협력의 중요성을 환기시키는 계기가 되었습니다. 이 블로그에서는 DeepSeek Open Source Week의 배경과 공개된 각 기술의 원리 및 세부내용, AI 학계와 업계에 주는 메시지와 향후 발전방향 등에 대해 https://medium.com/의 기사를 바탕으로 알아보겠습니다.

DeepSeek Open Source Week: Technical Deep-Dive and Implications
- OpenAI DeepResearch와 Claude를 이용한 정리
medium.com
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
1. DeepSeek Open Source Week의 배경
DeepSeek Open Source Week는 DeepSeek-R1 모델 공개 성공에 힘입어 기획되었습니다. DeepSeek-R1은 MIT 라이선스로 공개된 추론 특화 언어 모델로, OpenAI GPT-4에 필적하는 성능을 보이면서도 훈련 비용은 훨씬 저렴하여 AI 업계에 큰 충격을 주었습니다. 특히 GPU 공급이 제한된 환경에서 효율성 혁신을 통해 돌파구를 마련한 사례로 주목받았습니다. DeepSeek 팀은 이러한 성과를 더 폭넓은 협업과 혁신으로 이어가기 위해 Open Source Week를 기획, 핵심 AI 인프라 기술 5종을 오픈소스로 공개했습니다.
DeepSeek는 "우리는 거창한 주장을 내세우는 대신, 작은 진전이라도 완전한 투명성으로 공유한다"면서, "공유되는 코드 한 줄 한 줄이 모여 집단적 추진력이 된다"고 강조했습니다. 또한 "상아탑(이론적이거나 고립된 환경)을 벗어나 차고(garage) 정신(실용적이고 창의적인 열정)과 커뮤니티 주도 혁신으로 함께 나아가자"고 언급하며, 거대 기업 중심의 폐쇄적 개발이 아닌 개방형 협업 생태계를 지향함을 분명히 했습니다. DeepSeek는 오픈소싱을 통해 더 광범위한 평가와 개선을 받겠다는 의지를 보였으며, AGI 개발을 모두와 함께 가속하겠다는 뜻을 밝혔습니다.
2. DeepSeek Open Source Week: 5일간의 기술 공개
DeepSeek Open Source Week 동안 매일 공개된 주요 기술은 다음과 같습니다:
- Day 1 — FlashMLA: Hopper GPU(NVIDIA H100/H800 등)용 고성능 디코딩 커널로, 가변 길이 시퀀스 처리를 최적화하여 대용량 언어 모델의 디코딩(텍스트 생성과정) 속도를 극대화하는 라이브러리입니다.
- Day 2 — DeepEP: Mixture-of-Experts(MoE) 모델을 위한 통신 라이브러리로, 대규모 MoE 훈련·추론 시 발생하는 전-노드(all-to-all) 통신을 고속화합니다.
- Day 3 — DeepGEMM: 딥러닝 모델의 훈련 및 추론 시 메모리 사용량을 줄이고 연산 속도를 향상시키는 데 사용되는 FP8(8비트 부동소수) 행렬 연산(GEMM, General Matrix Multiplication) 라이브러리로, Dense (밀집) 연산과 MoE용 그룹화 연산 모두를 지원하며, Hopper Tensor Core의 FP8 연산을 최대한 활용합니다.
- Day 4 — DualPipe & EPLB: 대규모 분산 훈련을 위한 병렬화 기법 2종으로, DualPipe는 순방향/역방향 계산과 통신을 겹쳐서 병렬 처리하여 기존 파이프라인 병렬화의 GPU 유휴 시간을 제거하고, EPLB(Expert-Parallel Load Balancer)는 MoE 모델의 게이팅(gating)을 동적으로 조정하여 전문가별 부하(Load)를 균형화합니다.
- Day 5–3FS (Fire-Flyer File System) & Smallpond: 대규모 AI 데이터 처리용 분산 파일 시스템인 3FS와 그 위의 경량 데이터 처리 프레임워크 Smallpond를 공개했습니다. 3FS는 NVMe 기반 고속 저장 장치의 높은 초당 입출력 작업수와 RDMA(Remote Direct Memory Access, 원격 직접 메모리 접근) 네트워크 대역을 최대한 활용하도록 설계된 병렬 파일 시스템이며, Smallpond는 DuckDB 데이터 분석 엔진에 기반한 데이터 처리 프레임워크로, 3FS와 연동하여 대규모 학습 데이터셋 전처리부터 분산 저장까지 일원화된 워크플로우를 제공합니다.
DeepSeek는 실제로 온라인 서비스(모델 V3/R1)에 사용 중인 검증된 코드를 공개했다는 점을 강조했습니다.
3. 기술 심층 분석
DeepSeek Open Source Week에서 공개된 기술들은 각각 핵심 원리, 구현 세부 사항, 성능 벤치마크, 그리고 기존 기술 대비 차별점을 가지고 있습니다.
1) FlashMLA: 고효율 MLA 디코딩 커널
FlashMLA는 입력된 문장을 바탕으로 새로운 문장을 생성하는 Transformer 디코딩 단계에서 Multi-Head Latent Attention(MLA)를 가속하는 커널입니다. 기존 방식 (MHA)은 모든 책꽂이(Key-Value)를 하나하나 다 뒤져보면서 필요한 책을 찾기 때문에 시간이 오래 걸리고, 많은 에너지를 소모합니다. 반면에 MLA 방식은 먼저 각 책꽂이에 어떤 종류의 책들이 있는지 요약 정보(Latent)를 만들고 이 요약 정보를 바탕으로 필요한 책이 있을 만한 책꽂이만 골라서 찾아보기 때문에 훨씬 빠르고 효율적으로 책을 찾을 수 있습니다. DeepSeek의 모델은 이러한 방법을 통해 추론 시 메모리 사용량과 연산 비용을 줄였습니다.
DeepSeek가 제공한 위 벤치마크에 따르면, FlashMLA는 H800 GPU에서 메모리 바운드 설정 시 초당 3000GB의 데이터 처리량을, 연산 바운드 설정에서는 580TFLOPS의 연산 처리를 달성했습니다. 이는 Hopper GPU의 이론적 메모리 대역폭 및 연산 성능에 근접하는 수치입니다. FlashMLA는 변수 길이 텍스트 생성 작업에서 기존 PyTorch 디코더나 단순 Xformers 커널 대비 상당한 지연 감소를 보여, 실시간 응답이 중요한 서비스에 유리합니다.
Deepseek Open Source Week Kicked off with FlashMLA(Github Codebase Included!)
Deepseek kicks off its Open Source Week with a major release — FlashMLA. As a developer, I’m excited...
dev.to
2) DeepEP: MoE 전문가 병렬 통신 최적화
DeepEP는 Mixture-of-Experts 모델에서 모든 전문가 파티션 간의 통신을 전담하는 라이브러리입니다. MoE에서는 토큰별로 할당된 전문가로 데이터를 라우팅(dispatch)하고, 각 전문가의 출력을 다시 합치는(combine) 과정에서 다대다(all-to-all) 통신이 필수적입니다. DeepEP는 이 dispatch/combination 통신을 GPU에서 직접 실행하는 고성능 커널을 제공합니다.
구현 측면에서, 노드 내 통신은 NVIDIA의 GPU 간 초고속 연결 기술, NVLink를, 노드 간 통신은 CPU의 개입 없이 네트워크 인터페이스 카드(NIC)에서 직접 메모리에 접근하여 데이터를 전송하는 InfiniBand RDMA (Remote Direct Memory Access)를 사용하며, 두 경로를 모두 최적화했습니다. 특히 FP8 정밀 통신을 지원하여, 동일 양의 토큰이라도 데이터 전송량을 2배 이상 줄였습니다.

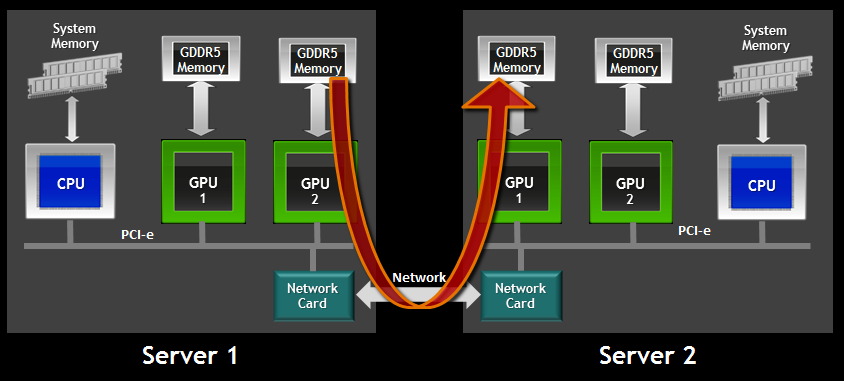
https://dev.to/apilover/deepseek-open-source-week-day-2-unpacking-deepep-24od
✨Deepseek Open Source Week Day 2: Unpacking DeepEP👍
DeepSeek's Open Source Week continues with Day 2, introducing DeepEP — an open-source library...
dev.to
DeepSeek은 DeepEP의 성능을 H800 GPU 클러스터에서 측정했습니다. 각 GPU당 NVLink 대역폭 ~160GB/s, RDMA(400Gb/s) ~50GB/s 환경에서, 8개 전문가를 노드 내 통신 시 약 153~158GB/s의 실효 대역폭을 달성했고, 16~32개 전문가를 노드 간 통신 시에는 43~47GB/s로 RDMA 물리 속도에 거의 근접했습니다.
3) DeepGEMM: FP8 GEMM 라이브러리
DeepGEMM은 FP8(Floating Point 8bit, 8비트 부동소수점 숫자 표현 방식) 지원 행렬 곱셈(GEMM, General Matrix Multiplications) 소프트웨어 라이브러리입니다. FP8은 기존의 32비트 또는 16비트 부동 소수점 형식보다 정밀도가 낮지만, 딥러닝 모델에서 충분한 표현력을 유지하면서 메모리 대역폭과 연산량을 크게 줄여 주기 때문에 딥러닝 모델의 훈련 및 추론 속도를 가속화하는 데 사용됩니다.
DeepSeek에 따르면 DeepGEMM은 전문가급으로 튜닝된 라이브러리들과 대등하거나 우수한 성능을 대부분의 매트릭스 크기에서 달성했습니다. 특히 Hopper GPU(필수 환경)에서 1350 TFLOPS 이상의 처리량을 보였습니다.
기존에 FP8 GEMM을 다루는 공개 도구는 거의 없었습니다. DeepGEMM은 FP8 연산 스택을 처음으로 공개함으로써 FP8 활용의 대중화에 기여합니다. 또한 MIT 라이선스이므로, PyTorch나 JAX 커뮤니티가 통합할 수도 있습니다.
https://dev.to/apilover/deepseek-open-source-week-day-3-deepgemm-1h0
DeepSeek Open Source Week Day 3: DeepGEMM
If you’re passionate about AI innovation and cutting-edge tools, DeepSeek’s Day 3 of Open Source Week...
dev.to
4) DualPipe: 양방향 파이프라인 병렬화, EPLB: MoE 전문가 부하 분산기
DualPipe는 대규모 모델 훈련 시 흔히 쓰이는 Forward(예측)/Backward(학습) 파이프라인 병렬화(Pipeline Parallelism)의 효율을 극대화하는 알고리즘입니다. 일반적인 파이프라인 병렬화 방식과의 차이는 아래와 같습니다.
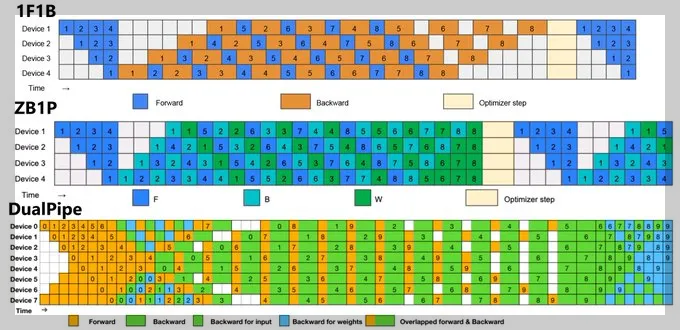
- 1F1B (One Forward, One Backward): 각 장치(Device)는 먼저 순전파(Forward, 파란색) 연산을 수행한 후, 역전파(Backward, 주황색) 연산을 진행합니다. 최적화(Optimizer Step, 베이지색)는 모든 역전파 단계가 완료된 후 수행됩니다. 이 방식은 단순하지만, 장치들이 일부 대기하는 시간이 길어 자원 활용이 비효율적일 수 있습니다.
- ZB1P (Zero Buffer 1 Pipeline): 각 장치가 Forward(파란색)와 Backward(녹색) 연산을 보다 효율적으로 배치하여 실행합니다. 중간 단계에서 일부 장치들이 대기하는 시간이 줄어들어, 1F1B보다 더 나은 성능을 제공합니다.
- DualPipe: 순전파(Forward)와 역전파(Backward)를 겹쳐서 수행하는 방식입니다. 추가적으로 입력 데이터에 대한 역전파(연두색)와 가중치에 대한 역전파(진한 녹색)를 분리하여 더욱 세밀하게 나눕니다. 순방향과 역방향 계산을 동시에 진행함으로써 Forward와 Backward가 중첩되어 실행(노란색) 되기 때문에, 장치들이 더 효율적으로 사용됩니다. 따라서 가장 높은 성능과 자원 활용도를 제공하는 방식입니다.
DualPipe의 독특한 점은 노드 간 파이프라인에도 신경 썼다는 것입니다. DualPipe 알고리즘은 각 스테이지의 통신을 연산과 동시 진행하여, 통신이 별도로 기다리게 하지 않습니다. DualPipe를 통해 DeepSeek은 모델 GPU 사용률을 90% 이상으로 끌어올렸다고 추정됩니다. 개발자들은 DualPipe와 EPLB 도구를 활용하면 수개월 걸리던 훈련을 수주~수일로 단축할 수 있다고 강조했습니다.

EPLB(Expert Parallel Load Balancer, 전문가 병렬 부하 분산기)는 Mixture-of-Experts 모형의 토큰-전문가 할당을 동적으로 최적화하는 툴입니다. 위 이미지의 각 칸에 있는 숫자 쌍은 해당 GPU에 배치된 각 층의 전문가 ID를 나타냅니다. EPLB는 전문가의 계산 부하를 고려하여 최적의 방식으로 전문가들을 GPU에 분산 배치합니다. 이렇게 함으로써 특정 GPU에 계산 부하가 집중되는 것을 방지하고, 전체 시스템의 처리량을 향상시킵니다. EPLB를 사용하면 전문가 미활용으로 낭비되는 연산 능력을 회복할 수 있습니다.
https://dev.to/apilover/deepseek-open-source-week-day-3-dualpipe-and-eplb-17l4
DeepSeek Open Source Week Day 4: DualPipe and EPLB
Welcome back to DeepSeek’s Open Source Week! Today, we're diving into Day 4, where the focus is on...
dev.to
5) 3FS & Smallpond: 대규모 AI 데이터 처리 시스템
3FS (Fire-Flyer File System)는 대규모 AI 데이터 처리용 분산 파일 시스템으로, NVMe 기반 고속 저장 장치의 높은 초당 입출력 작업수와 RDMA(Remote Direct Memory Access, 원격 직접 메모리 접근) 네트워크 대역을 풀 활용 하도록 설계되었습니다. Smallpond는 DuckDB에 기반한 데이터 처리 프레임워크로, 3FS와 연동하여 대규모 학습 데이터셋 전처리부터 분산 저장까지 일원화된 워크플로우를 제공합니다. 3FS는 180노드 클러스터에서 초당 6.6TiB 읽기 처리량을 달성했고 25노드에서 GraySort 벤치마크 분당 3.66TiB 정렬 성능을 보였습니다.
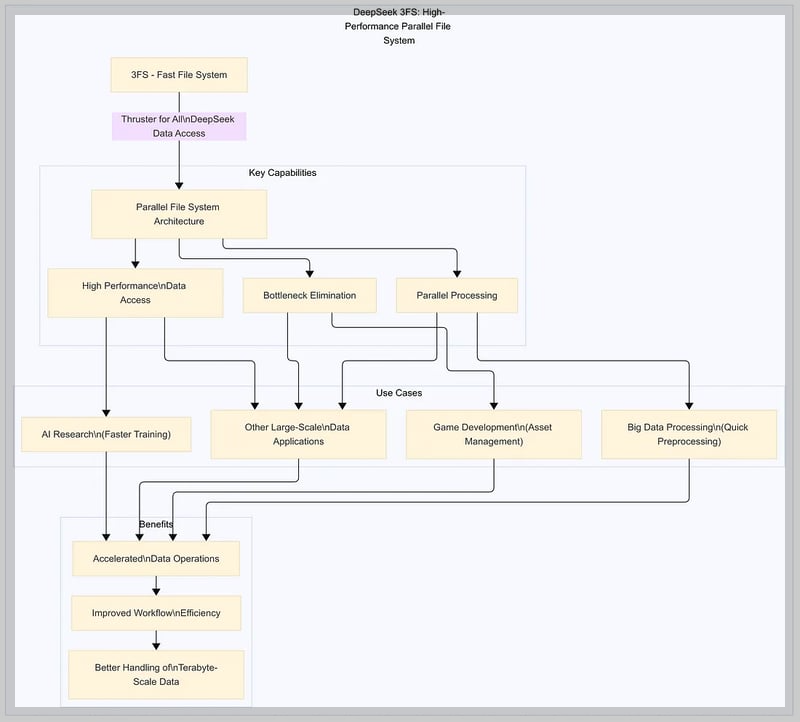
3FS는 고성능 데이터 접근, 병목 현상 제거, 병렬 처리를 통해 가속화된 데이터 작업과 작업 흐름 효율성 향상, 페타바이트(1PB=1000TB) 단위 데이터 처리 개선이 가능하며, AI 연구, 대규모 데이터 애플리케이션, 게임 개발, 대용량 데이터 처리 및 가공등에 활용할 수 있습니다.
쉽게 비유하자면 3FS는 마치 "초고속 물류 창고" 같은 시스템으로, 물건(데이터)을 빠르게 저장하고 꺼내는 데 특화되어 있고, 여러 로봇(병렬 처리)이 동시에 움직여서 병목 현상 없이 효율적으로 일합니다. Smallpond는 이 창고에서 물건을 정리하고 가공하는 "스마트 로봇" 역할을 해서, AI 연구나 게임 개발 같은 작업을 더 빠르고 효율적으로 만들어줍니다.
https://dev.to/apilover/deepseek-open-source-week-day-5-3fs-jkj
DeepSeek Open Source Week Day 5: 3FS
As developers, we’re constantly on the lookout for tools and technologies that can streamline our...
dev.to
4. 공개 기술의 의미와 응용 가능성
DeepSeek가 공개한 기술들은 AI 인프라 전반을 혁신할 빌딩 블록으로서 큰 의미를 지닙니다. 연구자와 개발자들은 이를 활용하여 보다 적은 자원으로 더 높은 성능을 달성하거나, 새로운 아이디어를 실험하는데 소요되는 구현 노력을 절감할 수 있습니다.
- 대규모 모델 연구 가속: DeepEP와 EPLB를 활용하여 Mixture-of-Experts 기반의 새로운 Transformer 구조를 제안하고 아이디어 검증 사이클을 획기적으로 단축할 수 있습니다.
- 실전 시스템 통합: FlashMLA와 DeepGEMM을 통합하여 추론 스루풋을 높이고 지연을 줄일 수 있습니다.
- 협업을 통한 개선: 오픈소스 개발자들이 성능 튜닝에 참여하여 라이브러리를 향상시킬 수 있습니다.
- 새로운 연구 주제 창출: 공개된 기술들은 그 자체로도 연구 소재가 됩니다.
- AI 개발 교육 및 학습 자료로 활용: DeepSeek 코드베이스는 실무 수준 고성능 코드이기에, 이를 학습 자료로 삼아 최적화 기법을 배울 수 있습니다.
5. 비즈니스 가능성 및 기업 활용 방안
DeepSeek가 공개한 기술들은 기업의 AI 전략에도 직접적인 영향을 미칠 수 있는 강력한 도구들입니다.
- 자체 AI 인프라 구축/개선: 클라우드 기업이 LLM 서비스 응답 지연을 줄이고 동시 처리량을 높이거나, 스타트업이 새로운 모델을 훈련할 때 GPU 자원 활용을 최대화할 수 있습니다.
- AI 서비스 및 제품 개발: R1 모델을 기반으로 기업이 자사 도메인에 특화된 챗봇을 만들어 상용화하거나, 스토리지 기업이 "AI 트레이닝 전용 스토리지 솔루션"을 출시할 기회를 얻을 수 있습니다.
- AI 아웃소싱/컨설팅 비즈니스: IT 서비스 기업들이 DeepSeek 인프라 세트를 활용한 턴키 솔루션을 제안할 수 있습니다.
- 클라우드 플랫폼 경쟁력 제고: 클라우드 플랫폼에 DeepSeek의 기술을 통합하면 고객이 별도 노력 없이 성능 혜택을 누리게 할 수 있습니다.
- 국내 기업 활용: 국내 IT 대기업들이 초거대 AI를 개발할 때 DeepSeek 오픈소스를 참고하여 학습 비용을 절약하거나, 스타트업들이 Llama2 등 공개 모델을 fine-tune하여 서비스하는 대신 R1 모델을 채택하여 더 나은 성능의 한국어/도메인 특화 모델을 만들 수 있습니다.
DeepSeek의 전략은 자사 코드 공개로 생태계를 키우고 간접적 이득을 취하려는 면이 있습니다. 많은 기업들이 DeepSeek 기술을 쓰면 자연히 DeepSeek의 브랜드와 전문성이 부각되어, 향후 DeepSeek가 내놓는 유료 서비스 이용 가능성이 높아집니다.
6. AI 학계와 업계에 주는 메시지
DeepSeek Open Source Week와 그 기술 공개는 AI 연구계와 산업계 모두에 몇 가지 중요한 메시지를 던집니다:
- 효율이 곧 경쟁력: 동일 자원으로 더 많은 성과를 내는 법도 연구의 핵심임을 상기시킵니다.
- 개방과 협업의 힘: AI 발전은 더 이상 폐쇄 연구소의 전유물이 아니며, 커뮤니티 지성의 집합체로 가속된다는 점을 보여줍니다.
- AGI 개발에 있어 인프라 연구의 중요성: 인프라 혁신 없이는 AGI도 비현실적임을 상기시켰습니다.
- AI 개발의 평준화와 지역 분산: AI 역량이 특정 지역이나 기업에 독점되지 않고 분산될 수 있음을 보여줍니다.
- 책임과 안전에 대한 집단 토론 촉발: AI 오남용에 대한 실험장이 된 셈입니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
7. 마치며
DeepSeek는 차기 모델(R2)을 염두에 두고 있으며, 2025년 내 특정 이벤트에서 발표할 수 있습니다. R2는 더 큰 모달리티(예: 멀티모달)나 더 긴 컨텍스트를 지원할 수도 있습니다. 또한, HaiScale(대규모 학습 스케줄러)이나 HAI-Platform (통합 학습 플랫폼) 등을 오픈소스로 공개할 가능성도 있습니다.
DeepSeek Open Source Week를 통해 DeepSeek 기술의 인지도와 활용도가 높아질 것으로 예상되며, 더 많은 개발자들이 DeepSeek 프로젝트에 참여하고, 다양한 분야에서 DeepSeek 기술을 활용한 애플리케이션이 등장할 가능성이 있습니다. 중장기적으로 DeepSeek의 오픈소스 전략은 AI 산업 전반에 긍정적인 영향을 미칠 것으로 보이며, 기술 공유와 협력을 통해 AI 기술 발전이 가속화되고, 더 많은 사람들이 AI 기술의 혜택을 누릴 수 있게 될 것입니다.
오늘 블로그는 여기까지입니다. 이번에 공개된 DeepSeek AI기술이 우리에게 많은 도움과 혜택을 가져다주길 기대하면서 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2025.01.23 - [AI 언어 모델] - 🐋DeepSeek-R1: OpenAI-o1 뛰어넘은 오픈소스 추론 모델이 무료!
🐋DeepSeek-R1: OpenAI-o1 뛰어넘은 오픈소스 추론 모델이 무료!
안녕하세요! 오늘은 DeepSeek AI에서 개발한 최신 추론 모델 DeepSeek-R1에 대해 알아보겠습니다. DeepSeek-R1은 순수 강화 학습(Pure Reinforcement Learning)을 통해 언어 모델의 추론 능력을 혁신적으로 향상시
fornewchallenge.tistory.com
'AI 인사이트' 카테고리의 다른 글
| 생성형 AI가 바꾸는 광고의 미래! 영향 분석 및 최신 동향 (0) | 2024.04.02 |
|---|---|
| GenAI를 사용할 때 사용자 경험 문제를 어떻게 해결할 수 있을까? (3) | 2023.10.26 |
| AI가 과연 똑똑할까요? eXplainable AI로 알아보자! (1) | 2023.10.24 |
| AI가 알려주는 자녀와 소통할 수 있는 3가지 비법 (4) | 2023.10.18 |
| 학폭피해 유튜버의 극단적 선택, AI가 해결할 수 있을까? (1) | 2023.10.11 |



