안녕하세요! 오늘은 Stability AI의 최신 텍스트-이미지 생성 모델인 Stable Diffusion 3.5에 대해 알아보겠습니다. 이 모델은 커뮤니티의 피드백을 반영하여 기존 모델보다 이미지 품질, 프롬프트의 정확성, 사용 편의성, 그리고 성능 효율성을 한층 높였습니다. Stable Diffusion 3.5는 세 가지 모델—Large, Large Turbo, Medium—로 구성되어 있으며, 각각의 모델은 서로 다른 하드웨어 환경과 사용 목적에 최적화되어 있습니다. 특히 Large 모델은 80억 개의 매개변수로 세밀한 이미지 표현이 가능하며, Turbo 모델은 4단계 만에 고품질 이미지를 생성할 수 있습니다. 또한, 무료로 사용할 수 있는 Stability AI 커뮤니티 라이선스를 제공하여 상업적, 비상업적 활용이 모두 가능합니다. 이 블로그에서는 Stable Diffusion 3.5의 특징과 주요 기능, 설치 및 테스트 방법에 대해 알아보겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Stable Diffusion 3.5 개요
Stable Diffusion 3.5는 Stability AI에서 2024년 10월 22일에 공개한 최첨단 텍스트-이미지 생성 모델입니다. 이전 버전인 Stable Diffusion 3 Medium의 단점을 보완하고 커뮤니티 피드백을 반영하여 이미지 품질, 프롬프트 준수, 사용자 정의 가능성, 효율성을 향상시켰습니다. Stable Diffusion 3.5는 세 가지 모델로 구성됩니다.
- Stable Diffusion 3.5 Large: 80억 개의 매개변수를 가진 가장 강력한 모델로, 1메가픽셀 해상도에서 뛰어난 이미지 품질과 정확한 프롬프트 준수를 제공하며, 전문적인 용도에 적합합니다.
- Stable Diffusion 3.5 Large Turbo: Large 모델을 증류하여 더 빠른 속도를 제공하고, 단 4단계 만에 고품질 이미지를 생성함으로써 크기에 비해 빠른 추론 시간을 제공합니다.
- Stable Diffusion 3.5 Medium: 26억 개의 매개변수를 가진 모델로, 0.25~2메가픽셀 해상도에서 견고한 성능을 제공하며 소비자 하드웨어에 최적화되어 있습니다. 10월 29일에 출시될 예정입니다.
Stable Diffusion 3.5는 Stability AI 커뮤니티 라이선스에 따라 상업적 및 비상업적 용도로 무료로 사용할 수 있습니다.
https://stability.ai/news/introducing-stable-diffusion-3-5
Stable Diffusion 3.5 — Stability AI
Today we are introducing Stable Diffusion 3.5. This open release includes multiple model variants, including Stable Diffusion 3.5 Large and Stable Diffusion 3.5 Large Turbo.
stability.ai
Stable Diffusion 3.5 특징
Stable Diffusion 3.5는 이전 버전에 비해 다음과 같은 점이 향상되었습니다.
- 향상된 이미지 품질 및 프롬프트 준수: 80억 개의 매개변수를 가진 Stable Diffusion 3.5 Large 모델은 이전 버전보다 뛰어난 이미지 품질과 프롬프트에 대한 정확한 준수를 제공하며, 1메가 픽셀 해상도에서 전문적인 작업에 적합합니다.
- 빠른 이미지 생성 속도: Stable Diffusion 3.5 Large Turbo 모델은 Large 모델의 핵심 기능을 유지하면서 적대적 확산 증류(ADD) 기술을 통해 4단계 만에 고품질 이미지를 생성하며, 기존 Large 모델보다 훨씬 빠른 속도를 자랑합니다.
- 소비자 하드웨어에 최적화된 모델: 10월 29일에 출시될 예정인 Stable Diffusion 3.5 Medium 모델은 26억 개의 매개변수를 가지고 있으며, 일반 소비자용 하드웨어에서도 원활하게 실행되도록 최적화되었습니다. 0.25~2메가픽셀 해상도의 이미지 생성이 가능하며, 품질과 사용자 정의 용이성 사이의 균형을 맞추도록 설계되었습니다.
- 향상된 사용자 정의 기능: Stable Diffusion 3.5 모델은 QK 정규화 기술을 통해 훈련 과정을 안정화시켜 사용자 정의 및 추가 개발을 용이하게 만들었습니다. 이는 특정 요구 사항에 맞게 모델을 미세 조정하거나 사용자 지정 워크플로우를 기반으로 애플리케이션을 구축할 때 유용합니다.
- 다양한 스타일 생성: Stable Diffusion 3.5는 3D, 사진, 그림, 라인 아트 등 상상할 수 있는 거의 모든 시각적 스타일을 생성할 수 있습니다.
이러한 개선 사항을 통해 Stable Diffusion 3.5는 전문가와 일반 사용자 모두에게 더욱 강력하고 다재다능한 도구가 되었으며, 이미지 품질과 프롬프트 준수 측면에서 경쟁력을 유지하면서도 효율적이고 고품질의 성능을 제공합니다.
https://huggingface.co/collections/stabilityai/stable-diffusion-35-671785cca799084f71fa2838
Stable Diffusion 3.5 - a stabilityai Collection
Running on Zero
huggingface.co
Stable Diffusion 3.5 성능
다음은 Stable Diffusion 3.5의 성능에 대해 알아보겠습니다. 아래 그래프는 Stable Diffusion 3.5와 다양한 이미지 생성 모델의 프롬프트 준수도와 미적 품질을 Elo 점수로 비교한 것입니다. Elo 점수의 개념은 아래 더 보기를 참고하세요.
Elo 점수는 헝가리 출신의 물리학자 아르파드 엘로(Arpad Elo)가 개발한 이 점수 체계는 플레이어 간 실력 차이를 예측하여 승리 확률을 계산하는 방식으로, 두 플레이어가 대결하면 결과에 따라 점수가 증감합니다. 예를 들어, 강한 상대에게 이기면 많은 점수를 얻지만, 약한 상대에게 이기면 점수 상승 폭이 적고, 반대로 강한 상대에게 패배할 때는 점수 감소가 적습니다.
- SD 3.5 Large (8.1B): SD 3.5 Large 모델은 프롬프트 준수(1024점)와 미적 품질(1026점)에서 높은 점수를 기록하며, 사용자의 요구를 정확히 반영하고 시각적으로 뛰어난 이미지를 생성합니다.
- SD 3.5 Large Turbo (8.1B): Turbo 버전은 속도에 중점을 두어 SD 3.5 Large보다 미적 품질(1012점)과 프롬프트 준수(1009점) 점수가 약간 낮지만, 여전히 높은 수준을 유지합니다.
- SD 3.5 Medium (2.5B): Medium 버전은 용량이 작아 Large 버전보다 성능은 낮지만, 프롬프트 준수(1006점)와 미적 품질(1008점)에서 여전히 좋은 점수를 유지하며 뛰어난 이미지 생성 능력을 보입니다.
Stable Diffusion 3.5는 전반적으로 매우 뛰어난 프롬프트 준수도와 미적 품질을 보여줍니다. 특히 Large 버전은 다른 모델들과 비교했을 때 가장 높은 점수를 기록하며, 사용자의 요구를 충족하는 고품질 이미지를 생성하는 데 탁월한 성능을 발휘합니다. Turbo 버전은 속도를 우선시하는 경우 좋은 선택이며, Medium 버전은 용량 제한이 있는 환경에서도 훌륭한 성능을 제공합니다.
Stable Diffusion 3.5 설치 방법
다음은 Stable Diffusion 3.5 설치방법입니다. Stable Diffusion 3.5는 Hugging Face에서 모델 가중치를 다운로드하여 자체 호스팅할 수 있으며, 또한 다음 플랫폼을 통해 모델에 액세스 할 수도 있습니다.
- Stability AI API: https://stability.ai/news/introducing-stable-diffusion-3-5
- Replicate: https://replicate.com/blog/stable-diffusion-3-5-is-here
- ComfyUI: https://blog.comfy.org/sd3-5-comfyui/
- DeepInfra: https://deepinfra.com/stabilityai/sd3.5
ComfyUI를 사용한 설치방법은 다음과 같습니다.
- ComfyUI를 최신 버전으로 업데이트합니다.
- Stable Diffusion 3.5 Large 또는 Stable Diffusion 3.5 Large Turbo를 models/checkpoint 폴더에 다운로드합니다.
- clip_g.safetensors, clip_l.safetensors, t5xxl_fp16.safetensors를 models/clip 폴더에 다운로드합니다.
- 워크플로우를 드래그하여 생성합니다.(Stable Diffusion 3.5 Large Turbo 워크플로우: 4단계 이미지 생성)
낮은 RAM 솔루션은 다음 내용을 참고하세요
- 생성 중에 충돌이 발생하면 RAM이 부족한 것일 수 있습니다.
- fp8_scaled 워크플로우(실험적) 및 fp8 scaled 모델을 낮은 VRAM 옵션으로 사용합니다.
- 메모리 사용량을 줄이려면 t5xxl_fp16 대신 t5xxl_fp8_e4m3fn_scaled.safetensors 또는 t5xxl_fp8_e4m3fn.safetensors를 사용해 볼 수 있습니다. (scaled는 실험적인 체크포인트입니다.)
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Stable Diffusion 3.5 이미지 생성기 만들기
다음은 Stability.ai API를 이용해서 Stable Diffusion 3.5 이미지 생성기를 만들어 보겠습니다. 작업환경은
Windows 11 Pro, WSL2, 파이썬 3.11, Visual Studio Code(이하 VSC)이며, VSC를 실행하여 "WSL 연결"을 통해 Windows Subsystem for Linux(WSL) 환경에 액세스 하도록 하였습니다.
1. API Key 발급: 먼저 다음 사이트에 접속해서 가입한 후, Stability API Key를 발급합니다.
https://platform.stability.ai/account/keys
Stability AI - Developer Platform
platform.stability.ai
2. 의존성 패키지 설치 및 API Key 설정: 다음은 VSC 터미널 작업 디렉토리에서 가상환경을 생성한 후, 가상환경이 활성화된 상태에서 GRADIO 의존성 패키지를 설치하고, Stability API Key를 설정합니다.
python3.11 -m venv myenv
source myenv/bin/activate
pip install gradio
export STABILITY_KEY=발급받은 API Key3. 코드 작성: VSC에서 새 파이썬 파일을 만들고 아래 코드를 복사해서 app.py 이름으로 저장합니다. 코드는 사용자 입력 프롬프트를 기반으로 Stability AI의 API를 이용해서 Stable Diffusion 3.5 Large 모델의 이미지를 생성하는 Gradio 인터페이스입니다.
import requests
import gradio as gr
from PIL import Image
import io
# Stability AI API 키 입력
STABILITY_KEY = "발급받은 API Key"
# API 엔드포인트
host = "https://api.stability.ai/v2beta/stable-image/generate/sd3"
# 이미지 생성을 위한 REST 요청 기능
def send_generation_request(host, params):
headers = {
"Accept": "image/*",
"Authorization": f"Bearer {STABILITY_KEY}"
}
# 파라미터 인코딩
files = {}
image = params.pop("image", None)
mask = params.pop("mask", None)
if image is not None and image != '':
files["image"] = open(image, 'rb')
if mask is not None and mask != '':
files["mask"] = open(mask, 'rb')
if len(files) == 0:
files["none"] = ''
# 요청 보내기
print(f"Sending REST request to {host}...")
response = requests.post(host, headers=headers, files=files, data=params)
if not response.ok:
raise Exception(f"HTTP {response.status_code}: {response.text}")
return response
# 이미지를 생성하는 함수
def generate_image(prompt):
params = {
"prompt": prompt,
"negative_prompt": "",
"aspect_ratio": "1:1",
"seed": 0,
"output_format": "jpeg",
"model": "sd3.5-large",
"mode": "text-to-image"
}
# 요청을 보내고 이미지 응답 받기
response = send_generation_request(host, params)
image_data = response.content
# 이미지를 PIL 형식으로 변환
image = Image.open(io.BytesIO(image_data))
return image
# Gradio 인터페이스 설정
iface = gr.Interface(
fn=generate_image,
inputs=gr.Textbox(lines=2, placeholder="여기에 프롬프트를 입력하세요..."),
outputs=gr.Image(type="pil"),
title="Stable Diffusion 3.5 이미지 생성기",
description="프롬프트를 입력하면 이미지를 생성합니다. 예: '가을 나뭇잎 사이에서 스케이트보드를 타는 고양이'"
)
# Gradio 인터페이스 실행
iface.launch()4. 코드실행: app.py를 실행하면 http://127.0.0.1:7860/ 주소에서 Gradio 인터페이스의 이미지 생성기가 열립니다.
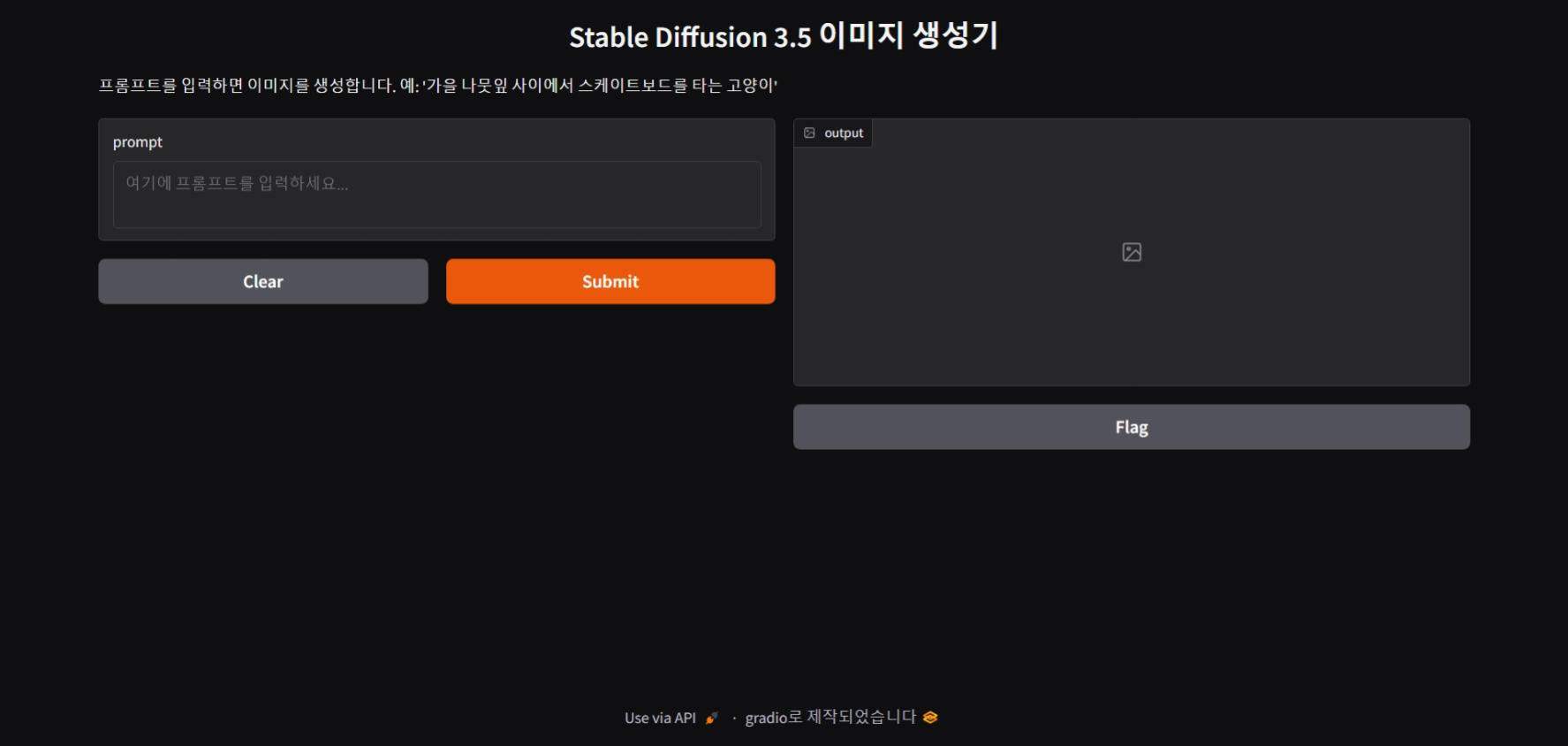
Stable Diffusion 3.5 테스트
다음은 위 이미지 생성기로 Stable Diffusion 3.5 Large 모델을 테스트를 해볼 텐데요, 이전에 포스트 한 Flux 1.1 Pro 모델에 사용했던 동일한 프롬프트를 입력하고 두 이미지를 비교하였습니다. Flux 1.1 Pro 모델에 대한 포스팅은 아래 링크를 참고하세요.
2024.10.07 - [AI 언어 모델] - 🚀Flux 1.1 Pro: 6배 더 빨라진 고품질 이미지 생성 모델🎨
🚀Flux 1.1 Pro: 6배 더 빨라진 고품질 이미지 생성 모델🎨
안녕하세요! 오늘은 Black Forest Labs에서 발표한 최신 이미지 생성 모델인 Flux 1.1 Pro에 대해 알아보겠습니다. Flux 1.1 Pro는 이전 버전인 Flux 1.0 Pro보다 6배 더 빠른 속도를 자랑하며, 이미지 품질, 프
fornewchallenge.tistory.com
텍스트 프롬프트 1: Create a serene woman practicing yoga on a beach at sunrise, with long, wavy hair and a peaceful expression, as ocean waves gently lap at her feet.


텍스트 프롬프트 2: Create a high-resolution image of a young woman with long hair, wearing an ornate golden crown. The woman is looking directly at the camera with a serious expression. She is holding up both hands in front of her, with each hand displaying a peace sign. The background is artistically textured with shades of teal and gold, adding a regal and dramatic effect to the scene. The lighting should be soft but dramatic, emphasizing the details of the crown and the woman's facial features.


텍스트 프롬프트 3: A girl is standing on the beach wearing sun glasses.


텍스트 프롬프트 4: A beautiful woman holding a sign that says "This is an example of long text to test Stable Diffusion 3.5" with bold text


텍스트 프롬프트 5: Create a high-resolution image of a modern kitchen with wooden cabinets and stainless steel appliances, featuring a clear glass bottle on a wooden table that contains a vibrant galaxy with swirling nebulae and stars.


텍스트 프롬프트 6: black forest gateau cake spelling out the words "Stable Diffusion 3.5", tasty, food photography, dynamic shot


텍스트 프롬프트 7: A beautiful woman with green hair takes a selfie in front of a mirror


텍스트 프롬프트 8: photo of a man giving a TED talk, behind him is a big neon sign with the text "TEDx AI Search", spotlight style lighting, soft shadows, sharp focus, shallow depth of field


텍스트 프롬프트 9: A woman is showing her hands with fingers spread.


테스트 결과 Stable Diffusion 3.5 Large 모델은 대부분의 프롬프트에서 우수한 품질의 이미지를 생성해 주었습니다. 하지만, 아직 손가락 이미지 생성은 개선이 더 필요해 보입니다.
다음은 ComfyUI에서 Stable Diffusion 3.5 Large Turbo 모델로 이미지를 생성해 보겠습니다. 워크플로우와 모델 파일은 블로그 설치방법에 소개된 링크에서 다운로드하시면 됩니다.
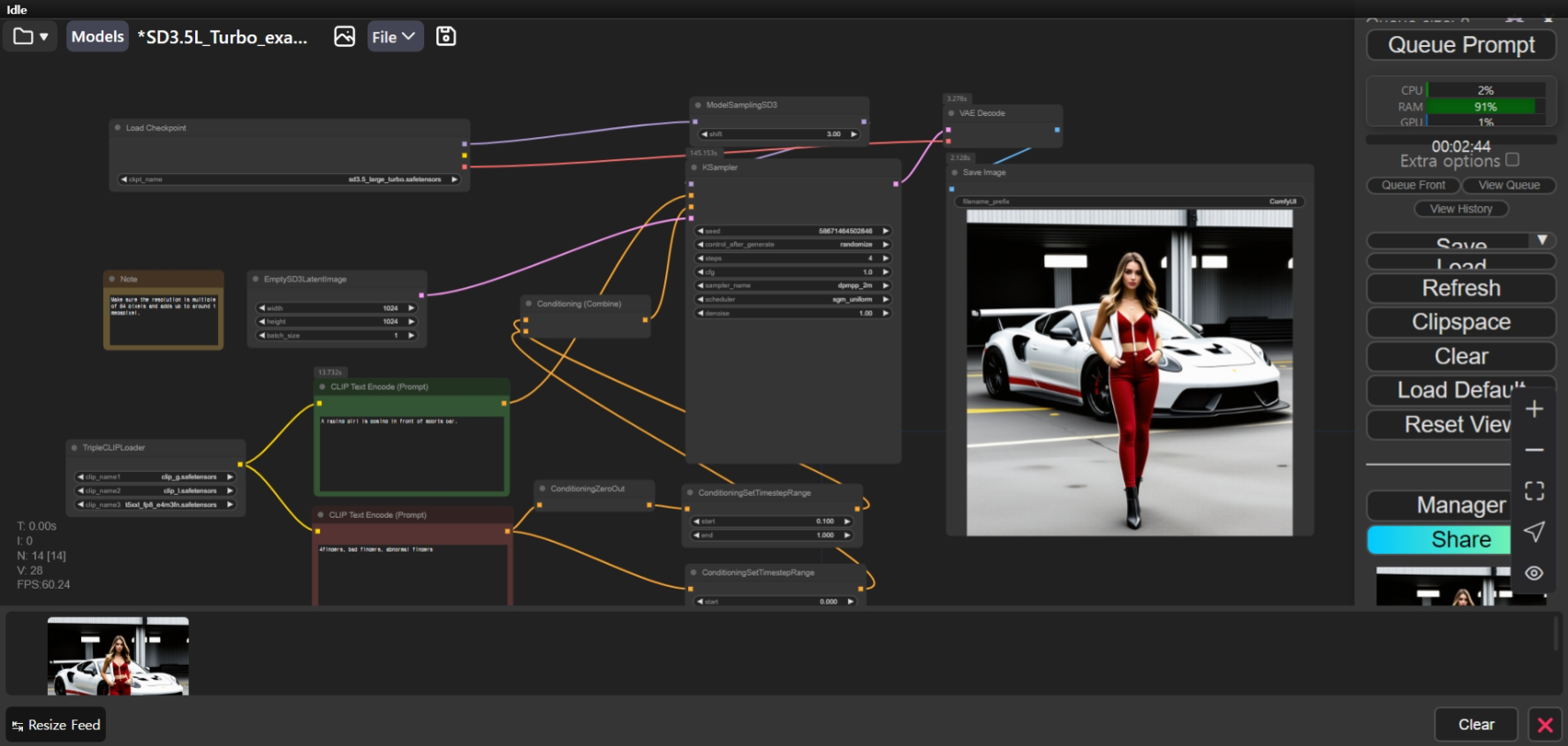






Stable Diffusion 3.5 Large Turbo 모델로 이미지를 생성하는 데 걸린 시간은 RTX 4060 VRAM 8GB에서 1장당 약 2분 정도 걸렸으며, 이미지 품질이 우수하고, 프롬프트를 잘 준수하였지만, 여전히 텍스트 렌더링 정확도와 손가락 이미지 생성은 개선이 필요해 보입니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
맺음말
오늘 포스팅에서는 Stability AI의 최신 텍스트-이미지 생성 모델인 Stable Diffusion 3.5의 개선된 기능과 설치 방법을 함께 살펴보았습니다. Stable Diffusion 3.5는 이전 버전에 비해 이미지 품질, 프롬프트 준수, 사용자 정의 가능성, 효율성이 크게 향상되었으며, 다양한 모델 크기와 다양한 플랫폼에서의 접근성을 제공하여 전문가, 취미 개발자, 연구자 모두에게 적합한 도구입니다. 특히, 무료 라이선스를 통해 상업적, 비상업적 용도로도 부담 없이 사용할 수 있다는 점이 큰 장점입니다.
Stable Diffusion 3.5를 테스트해 본 후기는 다음과 같습니다.
- 이미지 품질과 텍스트 렌더링이 이전보다 개선되었다.
- Large Turbo 모델의 4단계 이미지 생성은 매우 인상적이다.
- 손가락 이미지 생성은 아직 개선이 필요하다.
Stable Diffusion 3.5의 출시는 인공 지능을 통한 이미지 생성 분야에서 더욱 창의적인 표현과 혁신을 위한 새로운 가능성을 열어줄 것으로 기대됩니다. 여러분도 직접 Stable Diffusion 3.5 모델을 활용하여 다양한 이미지를 생성해 보시면 좋은 경험이 될 것 같습니다. 저는 그럼 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.06.15 - [AI 언어 모델] - Stable Diffusion 3 Medium: 최신 T2I 모델 설치와 활용법(SwarmUI)
Stable Diffusion 3 Medium: 최신 T2I 모델 설치와 활용법(SwarmUI)
안녕하세요! 오늘은 Stability AI가 최근 출시한 Stable Diffusion 3 Medium에 대해 알아보겠습니다. 이 모델은 작년에 출시된 SDXL의 후속 모델로, 다중모달 확산 변환기(MMDiT, Multimodal Diffusion Transformer) 기반
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 💡Ollama 로컬 멀티모달 AI: Llama 3.2 Vision 설치 및 활용 가이드 (14) | 2024.11.10 |
|---|---|
| ✨Claude 3.5 Haiku: Anthropic 최고 가성비 AI 모델 분석 및 테스트 (19) | 2024.11.07 |
| 🎙️Spirit LM: 풍부한 감정을 표현하는 Meta의 최신 음성 모델 (33) | 2024.10.23 |
| 🏆NVIDIA Llama-3.1-nemotron-70B: GPT-4o를 뛰어넘은 오픈소스 모델 (36) | 2024.10.20 |
| 🌟Aria: 최신 오픈소스 멀티모달 네이티브 MoE 모델 (25) | 2024.10.14 |



