안녕하세요! 오늘은 NVIDIA가 개발한 대규모 언어 모델(LLM), Llama-3.1-nemotron-70b-instruct 모델에 대해 알아보겠습니다. Llama-3.1-nemotron-70b-instruct는 2024년 10월 1일 기준 Arena Hard, AlpacaEval 2 LC, MT Bench (GPT-4-Turbo)와 같은 벤치마크에서 모두 1위를 차지하며 GPT-4o, Claude 3.5 Sonnet과 같은 강력한 모델들을 능가하는 성능을 보여줍니다. Llama-3.1-nemotron-70b-instruct는 사용자의 질문에 대해 더욱 도움이 되고, 정확하며, 일관성 있는 답변을 생성하도록 훈련되어, "How many r in strawberry?"와 같은 질문에도 특별한 프롬프트 없이 정확하게 답변할 수 있습니다. 이 블로그에서는 Llama-3.1-nemotron-70b-instruct의 개요 및 특징과 벤치마크 결과에 대해 알아보고, 다양한 테스트를 통해 성능을 분석해 보도록 하겠습니다.

https://build.nvidia.com/nvidia/llama-3_1-nemotron-70b-instruct/modelcard
llama-3_1-nemotron-70b-instruct | NVIDIA NIM
Experience the leading models to build enterprise generative AI apps now.
build.nvidia.com
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Llama-3.1-nemotron-70b-instruct 개요
Llama-3.1-nemotron-70b-instruct는 NVIDIA에서 개발한 대규모 언어 모델(LLM)로, 사용자 쿼리에 대한 LLM 생성 응답의 유용성을 향상하도록 사용자 정의되었습니다. 이 모델은 상업적 사용이 가능하며, LLama 3 라이선스 약관, 허용 가능한 사용 정책 및 Meta의 개인정보 보호정책에 동의하는 조건으로 이용할 수 있습니다.
Llama-3.1-nemotron-70b-instruct는 트랜스포머 아키텍처를 기반으로 텍스트 입력을 받아 텍스트 출력을 생성하며, 최대 128k 토큰까지 입력이 가능하고 최대 4k 토큰까지 출력할 수 있습니다.
- 향상된 유용성: Llama-3.1-nemotron-70b-instruct는 사용자 쿼리에 더 유용하게 응답할 수 있도록 설계되었으며, 정확하고 일관된 답변을 제공하는 동시에, 사용자의 요구에 맞게 복잡성을 조정할 수 있도록 훈련되었습니다.
- RLHF(Reinforcement Learning from Human Feedback) 훈련: 이 모델은 에이전트가 시행착오를 통해 환경과 상호작용하며, 경험을 바탕으로 행동을 조정하고 개선하는 방식인 강화 학습을 통한 인간 피드백을 사용하여 훈련되었으며, 특히 에이전트가 행동을 취하고 그에 대한 보상을 받으면, 그 보상에 따라 확률적으로 행동을 강화하거나 약화시키는 REINFORCE 알고리즘이 사용되었습니다.
- HelpSteer2-Preference 데이터셋 활용: 이 모델이 훈련에는 사람이 선호하는 답변을 언어 모델이 더 잘 구분하도록 훈련시키기 위한 데이터셋으로, 사람이 직접 답변들을 비교하여 어떤 답변을 더 선호하는지와 그 이유는 무엇인지에 대한 정보를 추가한 21,362개의 프롬프트-응답 쌍으로 구성됩니다.
- 뛰어난 벤치마크 결과: Arena Hard 85.0점, AlpacaEval 2 LC 57.6점, GPT-4-Turbo MT-Bench 8.98점을 기록하며, 2024년 10월 1일 기준 세 가지 자동 정렬 벤치마크에서 모두 1위를 차지했습니다.
https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct
nvidia/Llama-3.1-Nemotron-70B-Instruct · Hugging Face
Inference API (serverless) has been turned off for this model.
huggingface.co
Llama-3.1-nemotron-70b-instruct 벤치마크 결과
Llama-3.1-nemotron-70b-instruct는 다양한 벤치마크에서 뛰어난 성능을 보여주었습니다.
- Arena Hard: 85.0점으로 GPT-4o, Claude 3.5 Sonnet과 같은 강력한 모델들을 제치고 1위를 기록했습니다.
- AlpacaEval 2 LC: 57.6점을 기록하며, 검증된 탭에서 1위를 차지했습니다.
- GPT-4-Turbo MT-Bench: 8.98점으로 1위를 차지했습니다.
아래 표는 Llama-3.1-nemotron-70b-instruct와 다른 모델들의 벤치마크 점수를 비교한 것입니다.
| 모델 | Arena Hard | AlpacaEval 2 LC | MT-Bench | 평균 응답 길이 |
| Llama-3.1-Nemotron-70B-Instruct | 85.0 | 57.6 | 8.98 | 2199.8 |
| Llama-3.1-70B-Instruct | 55.7 | 38.1 | 8.22 | 1728.6 |
| Llama-3.1-405B-Instruct | 69.3 | 39.3 | 8.49 | 1664.7 |
| Claude-3-5-Sonnet-20240620 | 79.2 | 52.4 | 8.81 | 1619.9 |
| GPT-4o-2024-05-13 | 79.3 | 57.5 | 8.74 | 1752.2 |
벤치마크 결과에 대한 상세한 내용은 다음과 같습니다.
- Arena Hard: Arena Hard는 Chat Arena에서 수집된 까다로운 사용자 쿼리로 구성된 벤치마크입니다. Llama-3.1-nemotron-70b-instruct 모델은 Arena Hard에서 85.0의 높은 점수를 기록했습니다. 이는 복잡하고 특수한 지식, 문제 해결 능력, 창의성, 기술적 정확성을 요구하는 쿼리에 대해서도 뛰어난 성능을 보여준다는 것을 의미합니다.
- AlpacaEval 2.0 LC: AlpacaEval 2.0 LC는 추천, 질의응답, 자유 형식 글쓰기와 같은 간단한 작업과 관련된 805개의 단일턴 대화로 구성된 벤치마크입니다. Llama-3.1-nemotron-70b-instruct 모델은 AlpacaEval 2.0 LC에서 57.6점을 기록하여 벤치마크 상단에 위치하고 있습니다.
- MT Bench (GPT-4-Turbo): MT Bench는 글쓰기, 역할극, 정보 추출, 추론, 수학, 코딩, STEM, 인문/사회과학 등 8개 범주에서 수집된 80개의 다중 턴 질문으로 구성된 벤치마크입니다. Llama-3.1-nemotron-70b-instruct 모델은 MT Bench에서 8.98점을 기록하였으며, 특히 코딩, 수학, 추론 범주의 질문에서 높은 정확도를 보여줍니다.
- 평균 응답길이: Llama-3.1-Nemotron-70B-Instruct 모델이 2199.8로 가장 긴 응답을 제공하며, 이는 다른 모델들에 비해 훨씬 길다는 것을 알 수 있습니다. 이는 해당 모델이 더 상세하고 긴 설명을 제공하는 경향이 있음을 시사합니다.
Llama-3.1-nemotron-70b-instruct 테스트
다음은 Llama-3.1-nemotron-70b-instruct 모델의 코딩, 수학 및 추론성능을 테스트해 보겠습니다. 테스트는 허깅페이스 HuggingChat에 접속해서 진행하였으며, 코딩테스트는 edabit.com의 Python, C++, JavaScript 문제로 테스트하고, 첫 번째 시도의 채점결과를 그대로 반영하였습니다.
Hugging Face – The AI community building the future.
The Home of Machine Learning Create, discover and collaborate on ML better. We provide paid Compute and Enterprise solutions. We are building the foundation of ML tooling with the community.
huggingface.co.

1. 코딩 테스트: 파이썬, JavaScript, C++ 언어에 대해 각각 Medium, Hard, Very Hard, Expert 문제를 테스트하였습니다.
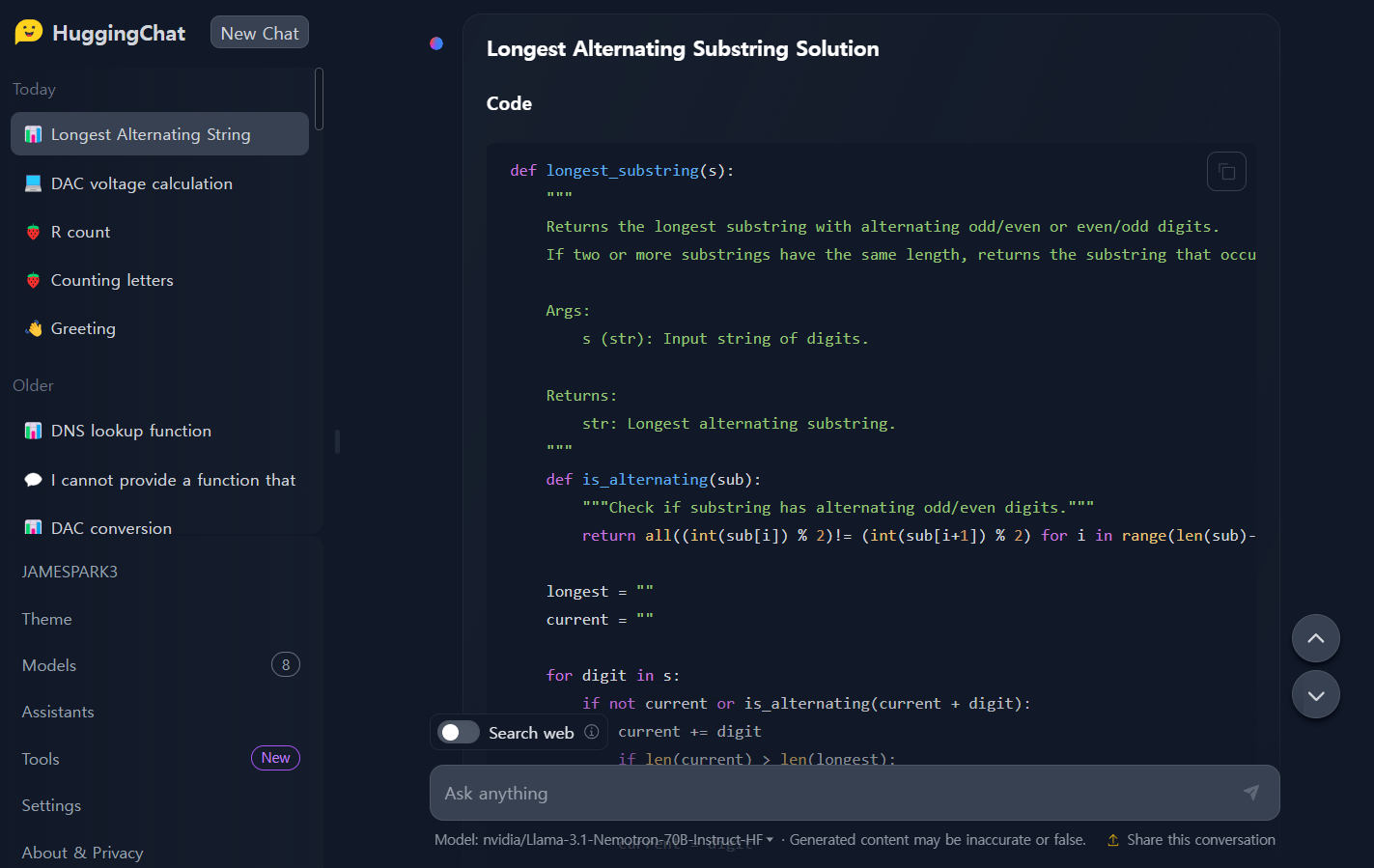
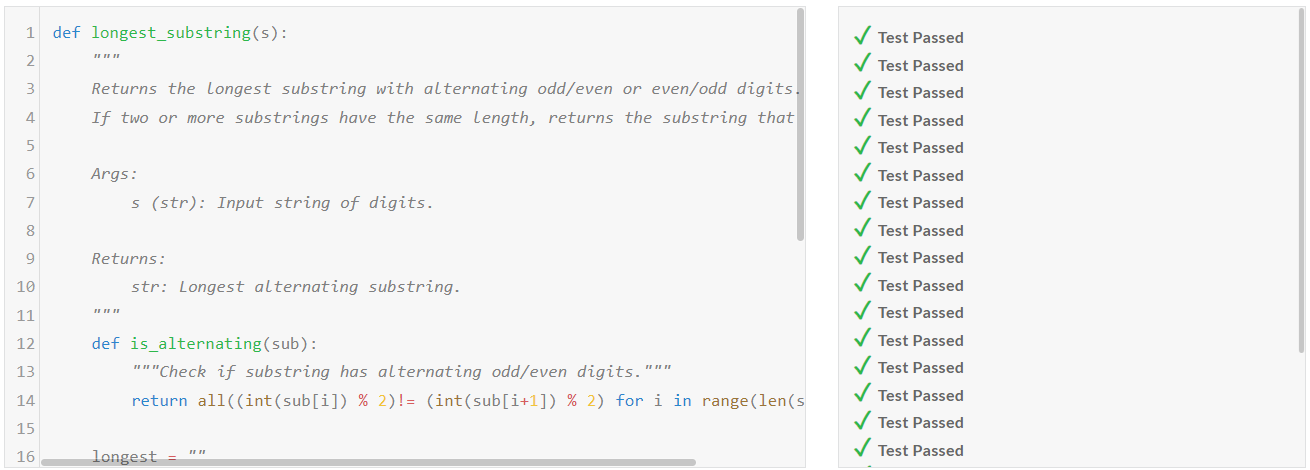

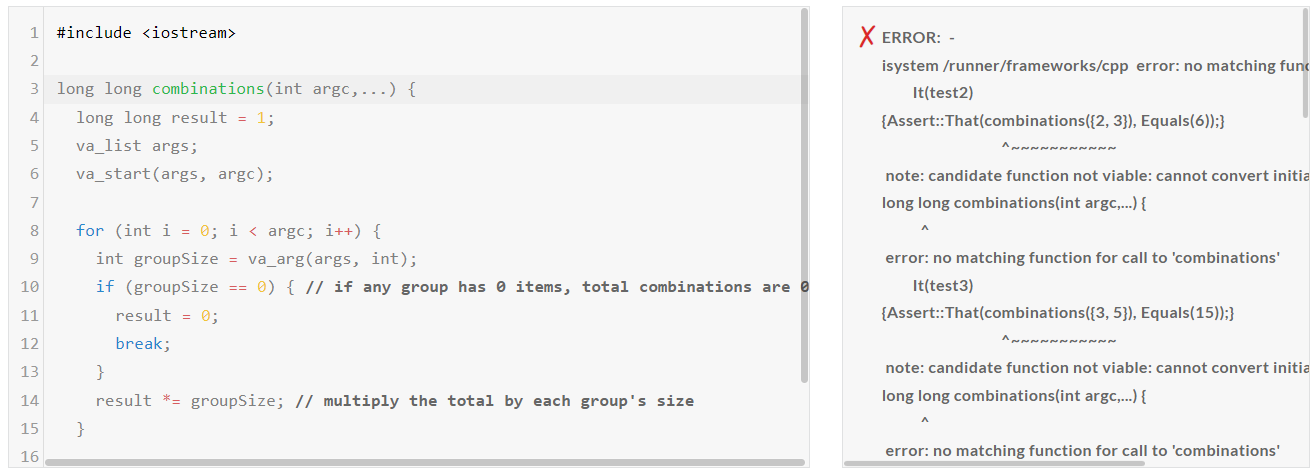
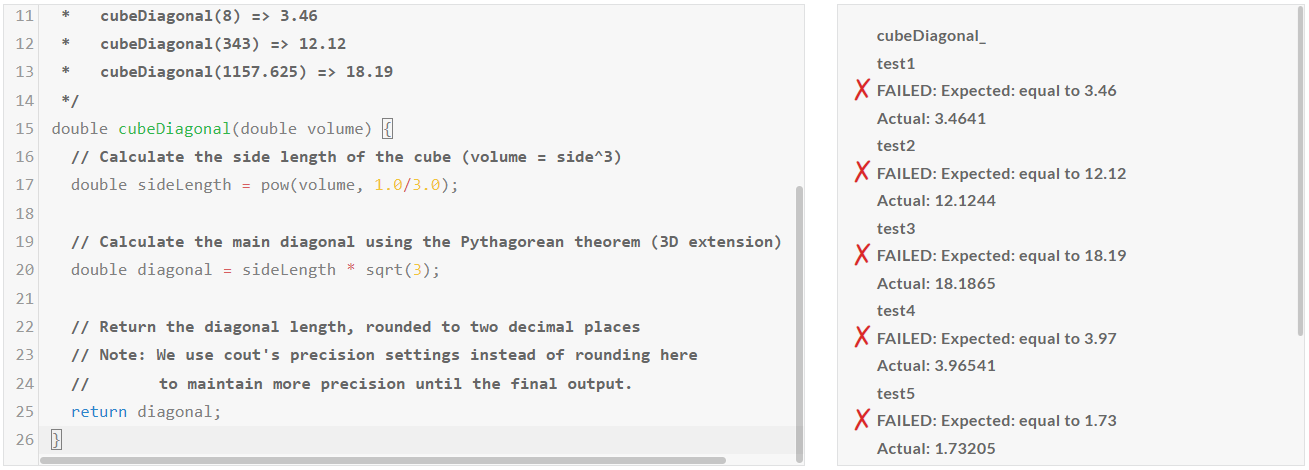
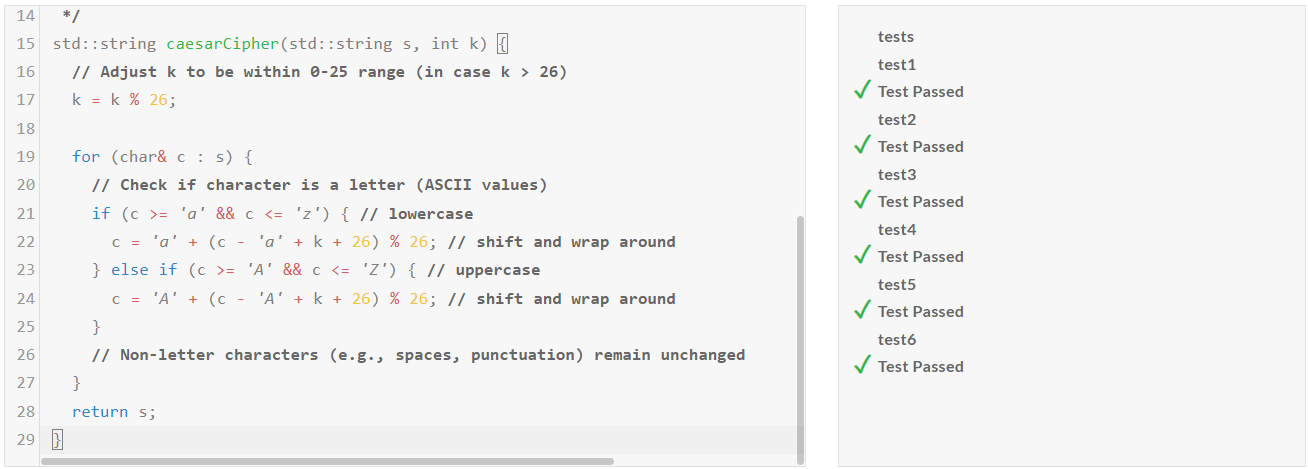
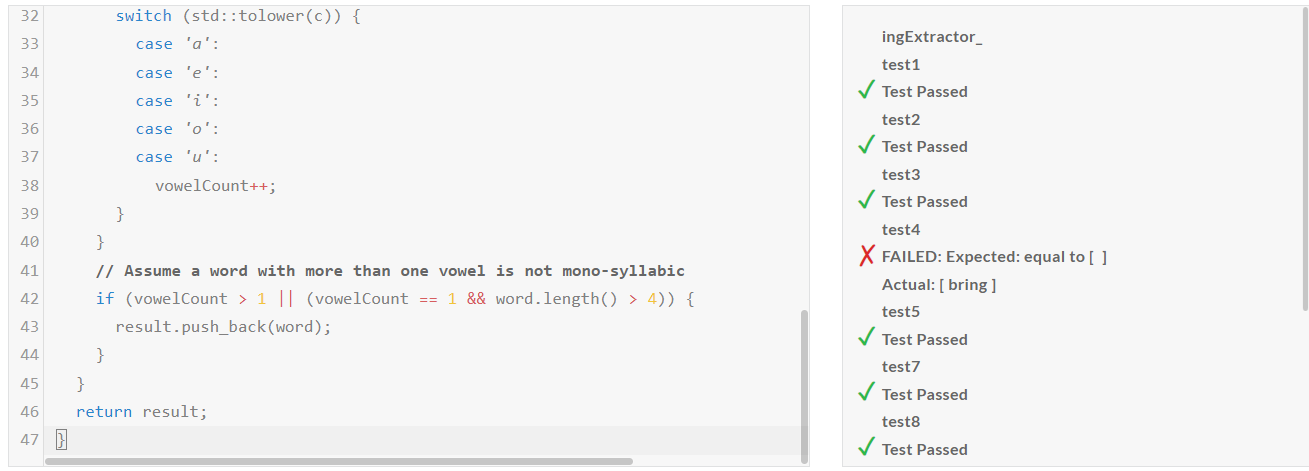
| Llama-3.1-nemotron-70b-instruct/Pass@1 | Medium | Hard | Very Hard | Expert |
| Python | Pass | Fail | Pass | Pass |
| JavaScript | Pass | Pass | Pass | Fail |
| C++ | Fail | Fail | Pass | Fail |
코딩 테스트 결과, Llama-3.1-nemotron-70b-instruct의 코딩 성능은 개선이 필요한것 같습니다.
2. 수학 및 추론 테스트: 기하, 확률 등 수학 6문제, 논리적 추론 5문제를 테스트하였습니다.
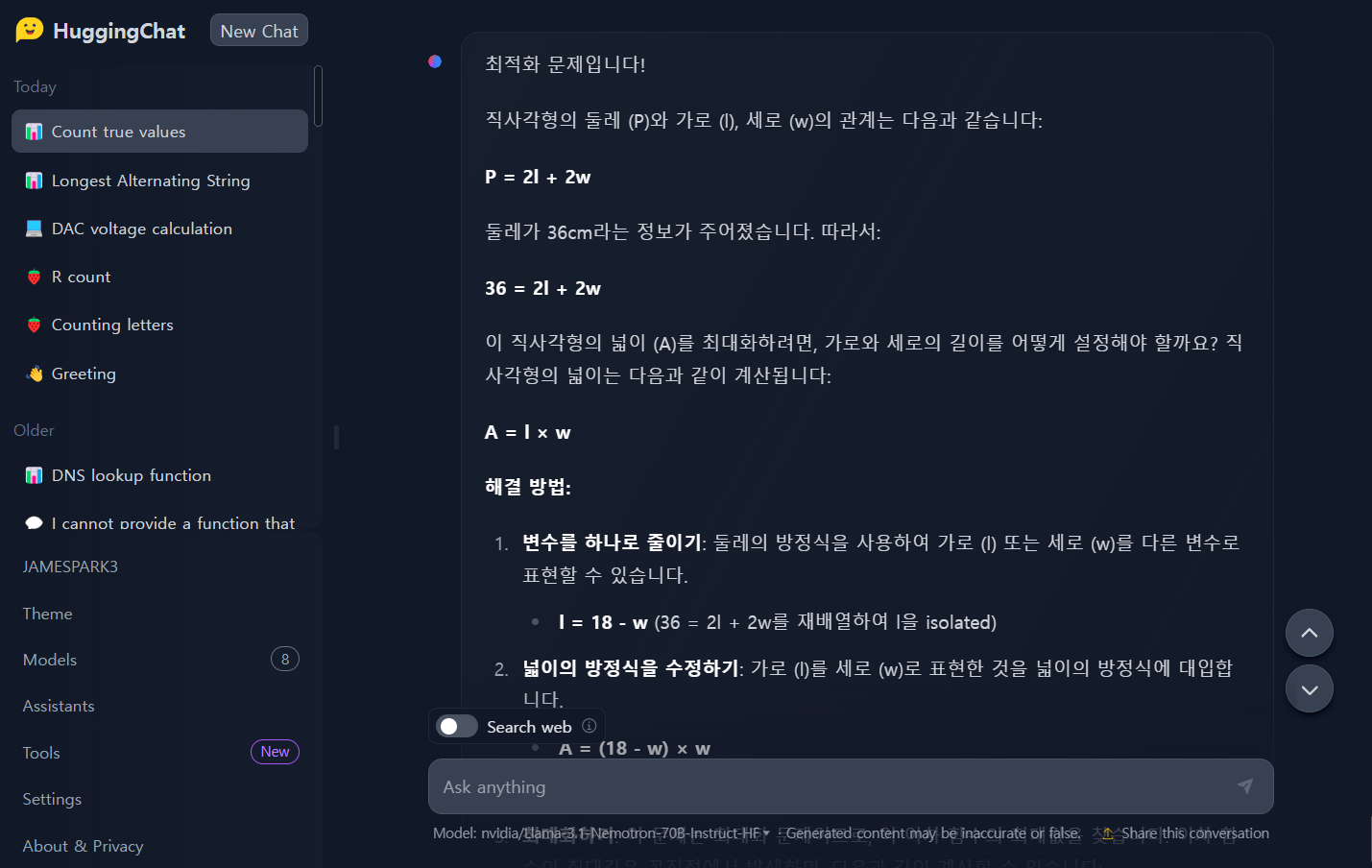
| No. | 문제 구분 | 문제 | Llama-3.1- nemotron -70b | GPT-4o-mini |
| 1 | 기초 대수 문제 | 두 숫자 𝑥 x와 𝑦 y가 있습니다. 이들이 만족하는 식은 3 𝑥 + 4 𝑦 = 12 3x+4y=12이며, 𝑥 − 2 𝑦 = 1 x−2y=1입니다. 𝑥 x와 𝑦 y의 값을 구하세요 | Pass | Pass |
| 2 | 기하학 문제 | 반지름이 7cm인 원의 넓이를 구하세요. 𝜋 = 3.14159로 계산하세요. | Pass | Pass |
| 3 | 확률 문제 | 주사위를 두 번 던졌을 때, 두 숫자의 합이 7이 될 확률을 구하세요. | Pass | Pass |
| 4 | 수열 문제 | 첫 번째 항이 3이고, 공차가 5인 등차수열의 10번째 항을 구하세요. | Pass | Pass |
| 5 | 최적화 문제 | 어떤 직사각형의 둘레가 36cm입니다. 이 직사각형의 넓이를 최대화하려면 가로와 세로의 길이는 각각 얼마여야 하나요? | Pass | Pass |
| 6 | 복합 문제 | 복소평면에서 다음 극한값을 구하시오. lim[n→∞] (1 + i/n)^(n^2) 여기서 i는 허수단위 (i^2 = -1)입니다. | Fail | Pass |
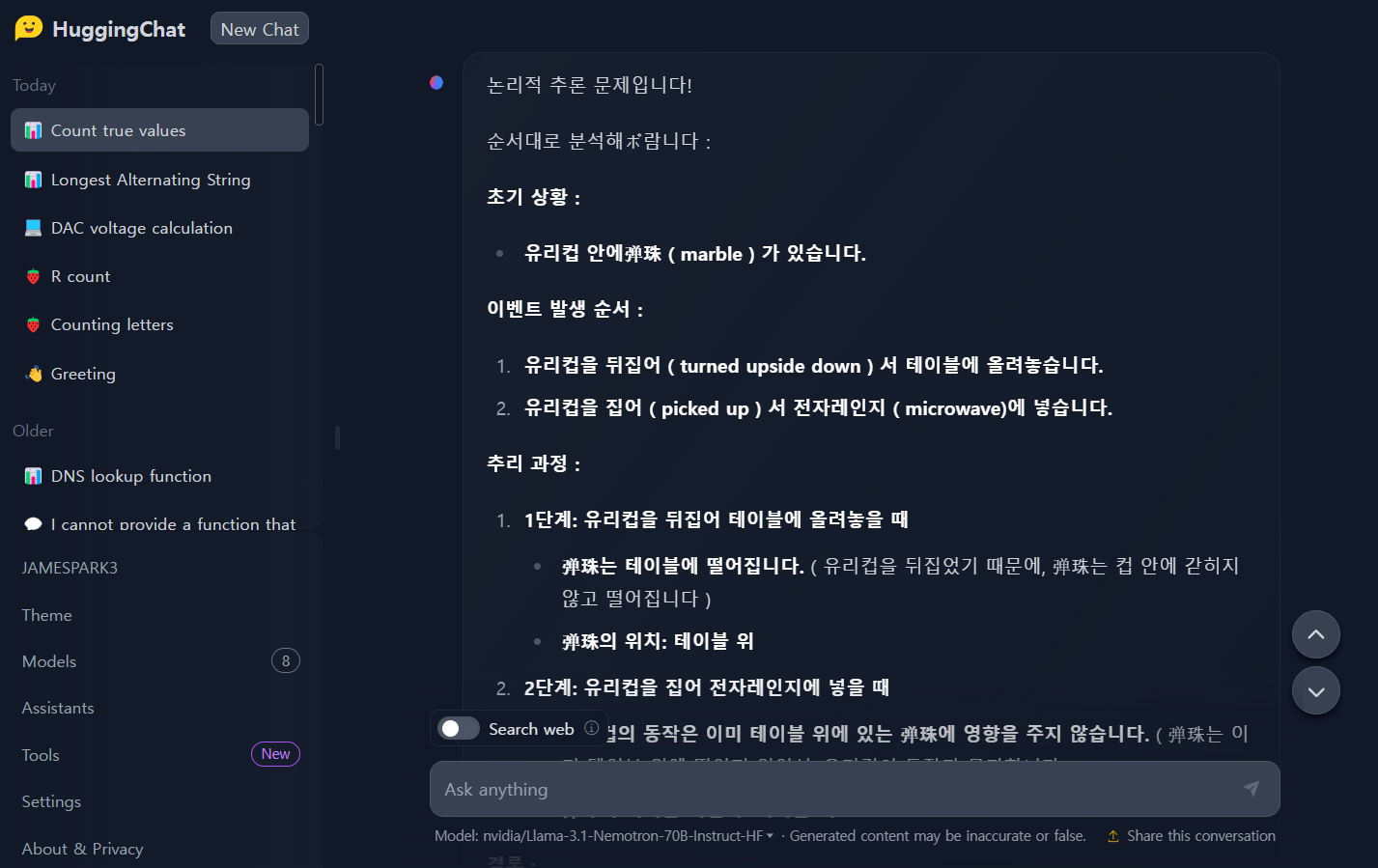
| No. | 문제 | Llama-3.1- nemotron -70b | GPT-4o-mini |
| 1 | 160 students in 5th and 6th grade participated in tree planting. As a result of planting an average of 5 trees each by 6th graders and an average of 3 trees each by 5th graders, a total of 560 trees were planted. How many 5th and 6th graders participated in tree planting? | Pass | Pass |
| 2 | Betty is saving money for a new purse. The purse costs $100. Betty only has half the money she needs. Her parents decide to give her $15 for that purpose, and her grandparents give her twice as much as her parents. How much more money does Betty need to buy the purse? | Pass | Pass |
| 3 | A national elementary school math competition was held, and three people, Young-hee, Chul-soo, and Jin-ho, participated. They are students from Seoul, Busan, and Incheon, and they received first, second, and third place awards, respectively. When you know the following, where is Jin-ho from and what place did he get? 1) Young-hee is not a player from Seoul. 2) Chul-soo is not a player from Busan. 3) The player from Seoul is not first place. 4) The player from Busan got second place. 5) Chul-soo is not third place. | Pass | Pass |
| 4 | There are three murderers in a room. A person enters the room and kills one of them. No one leaves the room. How many murderers are left in the room? Explain the reasoning process step by step. | Pass | Pass |
| 5 | A marble is put in a glass. The glass is then turned upside down and put on a table. Then the glass is picked up and put in a microwave. Where's the marble? Explain your reasoning step by step. | Pass | Pass |
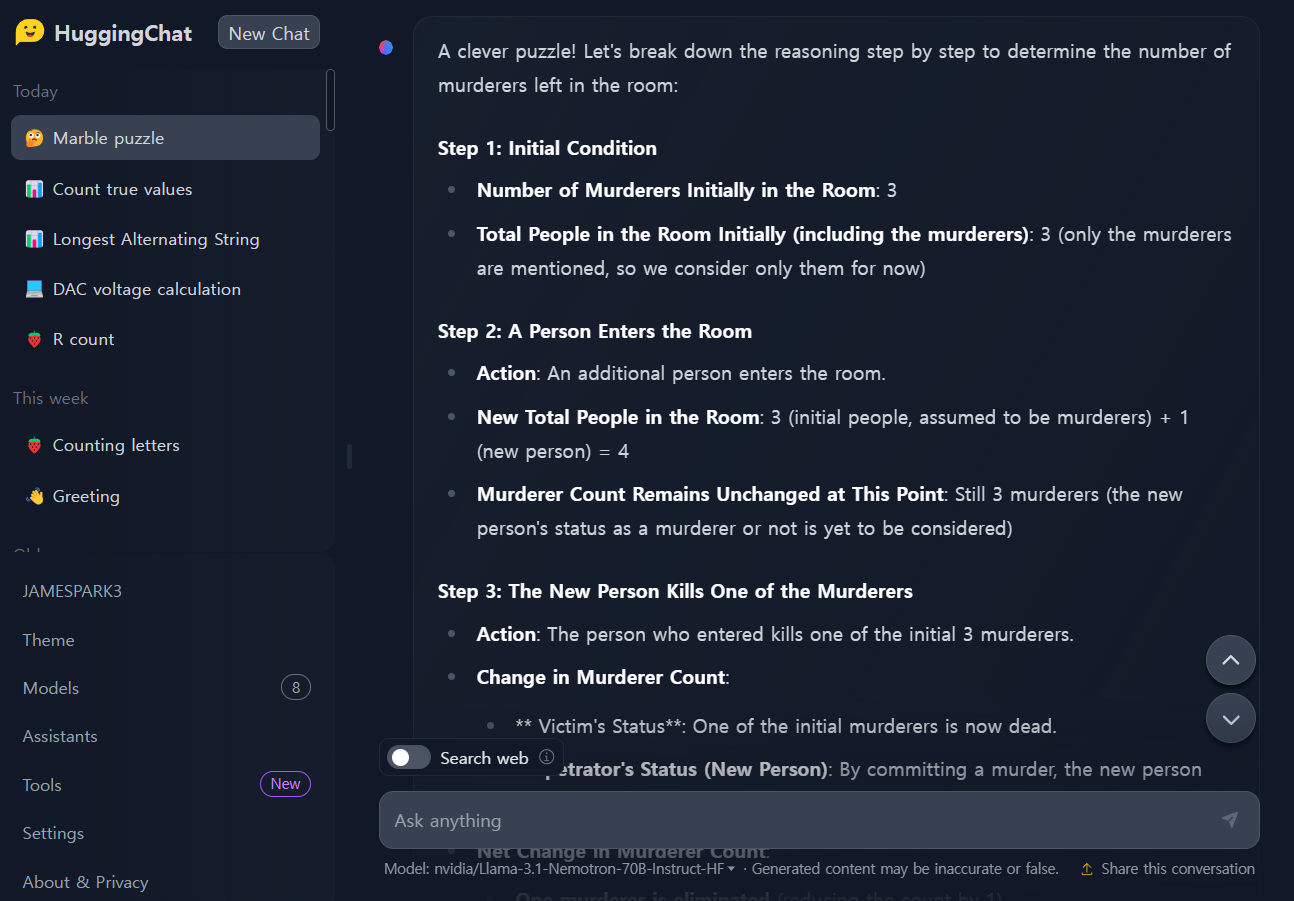
3. 기타 문제: ChatGPT, Claude 등 대부분의 언어모델이 답을 맞히지 못하는 문제인 "How many r in strawberry?"입니다.
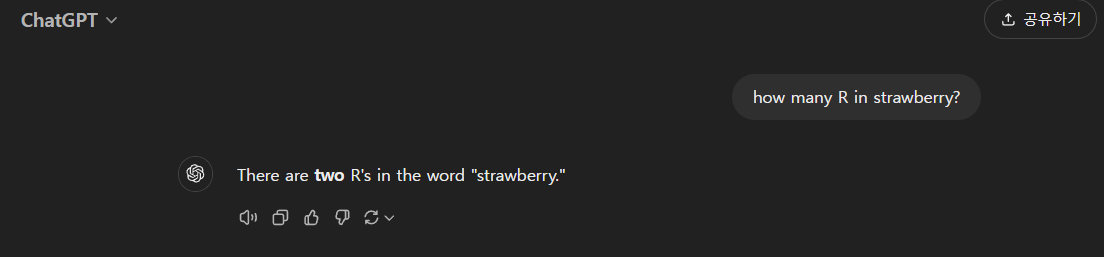
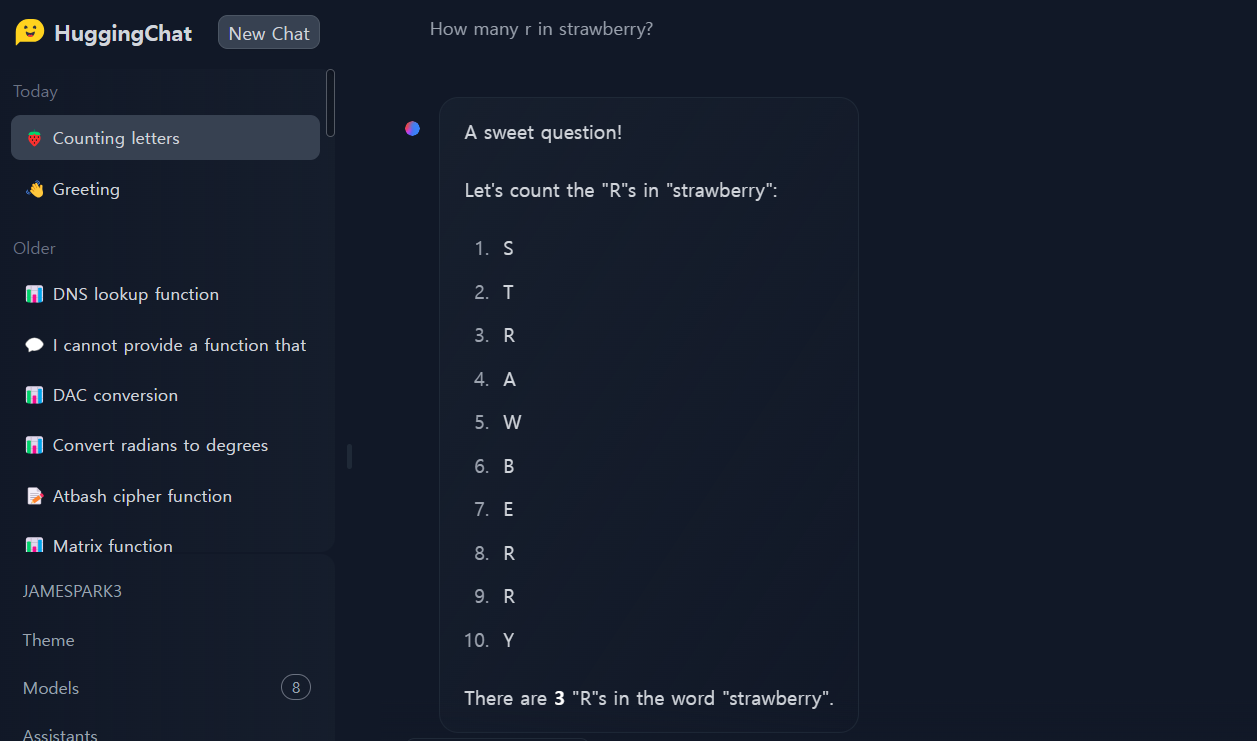
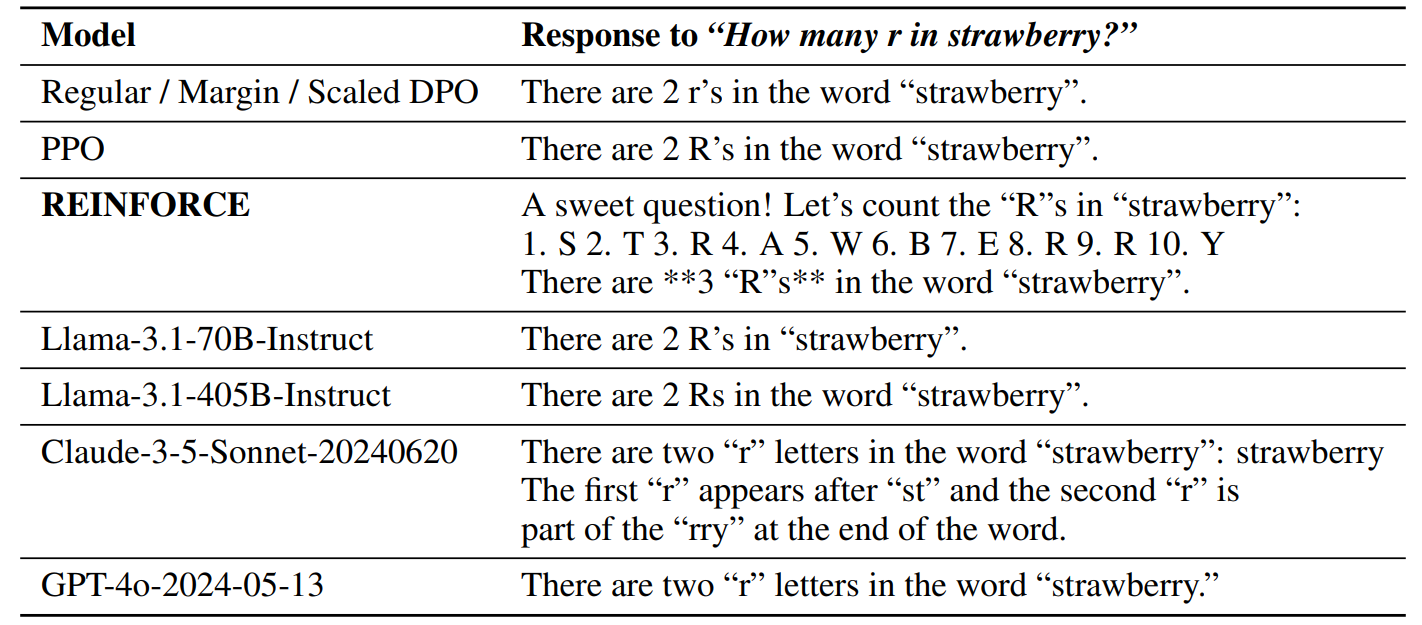
수학과 논리적 추론 테스트 결과, Llama-3.1-nemotron-70b-instruct은 대부분의 문제를 아주 상세한 설명과 정답을 제시하였으며, 특히, 단계별 설명은 초등학생도 이해할수 있을정도로 아주 자세히 설명하는 모습을 보였습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
맺음말
Llama-3.1-nemotron-70b-instruct는 GPT-4o와 Claude 3.5 Sonnet과 같은 강력한 모델들을 능가하며, 다양한 벤치마크에서 뛰어난 성능을 보여줬습니다. 특히, 사용자 쿼리에 대한 정교하고 상세한 응답을 생성하는 능력이 돋보이며, 수학, 추론 등 다양한 테스트에서도 탁월한 결과를 기록했습니다.
Llama-3.1-nemotron-70b-instruct를 테스트해본 후기는 다음과 같습니다.
- 지나칠 만큼 답변이 상세하고 많은 토큰을 소비한다.
- 코딩성능은 더 개선이 필요하다.
- 오픈소스이지만 NVIDIA의 NIM사용 크레디트는 제한이 있다.
LLM(대규모 언어 모델)에 관심이 있는 분들에게 NVIDIA의 Llama-3.1-nemotron-70b-instruct는 충분히 탐구할 가치가 있는 모델입니다. 여러분도 한번 모델을 테스트해보시면 좋은 경험이 될것 같습니다. 그럼 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.06.06 - [AI 도구] - NVIDIA 최신 소프트웨어 기술 NIM: AI 애플리케이션 간편하게 구축하기
NVIDIA 최신 소프트웨어 기술 NIM: AI 애플리케이션 간편하게 구축하기
안녕하세요! 오늘은 Nvidia의 최신 소프트웨어 기술 NIM(Nvidia Inference Microservices)에 대해 알아보겠습니다. 최근 AI 기술이 급속도로 발전하면서, 대형 언어 모델(LLMs)을 활용한 다양한 애플리케이션
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 🎨Stable Diffusion 3.5: 향상된 이미지 품질과 프롬프트 정확도로 업그레이드된 최신 텍스트-이미지 AI (14) | 2024.10.27 |
|---|---|
| 🎙️Spirit LM: 풍부한 감정을 표현하는 Meta의 최신 음성 모델 (33) | 2024.10.23 |
| 🌟Aria: 최신 오픈소스 멀티모달 네이티브 MoE 모델 (25) | 2024.10.14 |
| 🚀Flux 1.1 Pro: 6배 더 빨라진 고품질 이미지 생성 모델🎨 (22) | 2024.10.07 |
| 🎬Movie Gen: 메타의 차세대 미디어 생성 AI 모델🤖 (30) | 2024.10.05 |



