안녕하세요! 오늘은 대규모 언어 모델 Mixtral과 RAG(Retrieval-Augmented Generation, 검색 증강 생성) 기술을 활용해서 위키피디아 검색을 자동화하는 프로젝트에 도전해 보겠습니다. 검색 자동화는 직접 사이트에서 검색하는 방식에 비해 검색 시간을 단축하고 효율을 향상시키며, 사용자 정의 가능성과 시스템 통합의 용이성 등 여러 가지 장점을 제공합니다. 이 블로그에서는 이전에 다룬 Haystack-AI를 활용한 위키피디아 데이터 수집, 인덱싱, 파이프라인 구성, 그리고 자연어 처리 기반 RAG 구축 방법 등에 대해 자세히 살펴보겠습니다.

이 프로젝트의 출처는 유튜브 "Zephyr Wikipeda Chatbot Brings Knowledge to Life" 이며, HuggingFaceTGIGenerator 등 일부 코드는 원활한 프로젝트 실행을 위해 ChatGPT, 구글검색 등을 통해 수정하였습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
프로젝트 개요와 RAG
이 프로젝트는 위키피디아 라이브러리를 통해 가져온 페이지를 저장, 인덱싱 하고 Hugging Face의 Mixtral 8x7B 모델을 활용하여 문맥을 기반으로 한 질문에 자연어 답변을 생성하며, 관련 문서를 표시하는 파이프라인을 구현합니다.
이때 위키피디아 페이지는 외부 소스에 해당되며, 언어 모델은 학습 데이터가 아닌 이 정보를 활용하여 답변하게 됩니다. 이러한 구조를 RAG(Retrieval-Augmented Generation, 검색 증강 생성)이라고 하며, RAG은 외부 소스에서 가져온 정보로 생성형 AI 모델의 정확성과 신뢰성을 향상시키는 기술로, 질문에 대한 답변을 생성할 때 미리 검색된 정보를 활용하여 더욱 정확하고 의미적으로 풍부한 답변을 생성할 수 있습니다.
위키피디아 사이트에서 직접 검색하는 방식과 자동화된 검색방식은 다음과 같은 차이점을 가지고 있습니다.
- 효율성: 코드를 사용하는 경우, 미리 수집한 데이터를 기반으로 검색 및 답변 생성이 이루어집니다. 이는 반복적인 검색을 피하고 더 빠른 응답 시간을 제공할 수 있습니다. 반면, 위키피디아 사이트에서 직접 검색하는 경우 매번 새로운 검색이 이루어져야 하므로 속도가 느릴 수 있습니다.
- 사용자 정의 가능성: 코드를 사용하면 여러 구성 요소들을 조합하여 원하는 대로 파이프라인을 설계하고 사용자 정의할 수 있습니다. 예를 들어, 추가적인 전처리, 다양한 검색 및 답변 생성 방법을 적용할 수 있습니다. 직접 검색하는 경우에는 사용자에게 주어진 검색창을 통해서만 제한된 기능을 사용할 수 있습니다.
- 자동화 및 통합: 코드를 사용하는 경우에는 더 큰 시스템에 통합하거나 자동화하기가 쉽습니다. 예를 들어, 여러 데이터 소스를 통합하거나 다양한 모델을 테스트하는 것이 가능합니다. 직접 검색하는 경우에는 수동으로 작업해야 하거나 웹사이트와의 상호 작용을 자동화하기 위해 추가적인 노력이 필요합니다.
따라서 사용자의 목적에 따라 코드를 사용하거나 직접 검색하는 방법을 선택할 수 있습니다. 코드를 사용하면 더 많은 유연성과 효율성을 얻을 수 있지만, 직접 검색하는 것은 더 최신 정보를 얻을 수 있는 장점이 있습니다.
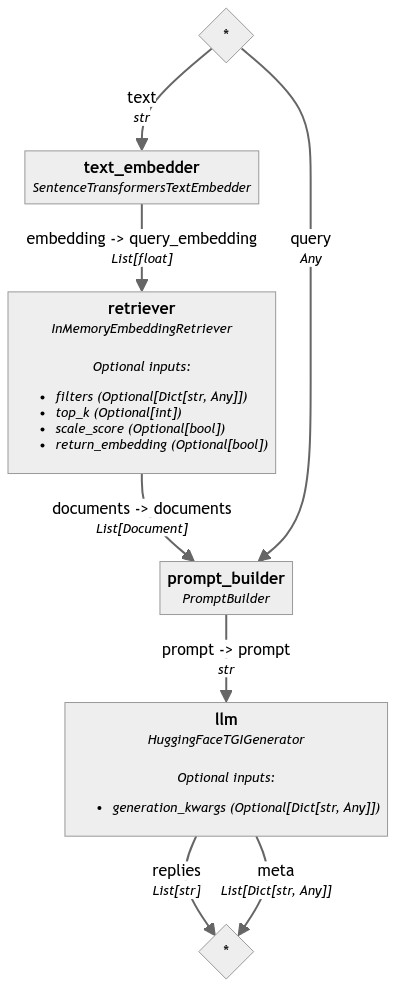
다음은 이 프로젝트의 동작순서를 표현한 플로우 차트와 각 구성요소에 대한 설명입니다.
- Text Embedder (텍스트 임베더): 검색을 위한 텍스트 문서를 임베딩하는 역할을 합니다. 문맥을 벡터 형태로 변환하여 유사성을 계산하는 데 사용됩니다. Haystack에서는 `SentenceTransformersTextEmbedder`가 사용됩니다.
- Retriever (검색기): 주어진 텍스트(질문 또는 키워드)에 대해 관련 있는 문서를 검색합니다. 검색된 문서는 텍스트 임베딩을 기반으로 순위가 매겨집니다. `InMemoryEmbeddingRetriever`와 같은 검색 엔진이 이 역할을 수행합니다.
- Prompt Builder (프롬프트 빌더): 검색된 문서와 질문을 결합하여 언어 모델에 입력으로 제공할 수 있는 형식으로 만듭니다. 템플릿을 사용하여 문서와 질문을 조합하고, 모델이 적절한 답변을 생성할 수 있도록 합니다.
- LLM (대규모 언어 모델): 검색된 문서와 질문에 대한 문맥을 바탕으로 Hugging Face의 Mixtral 8x7B 모델을 활용하여 자연어 답변을 생성하고, 생성된 문맥 기반으로 답변을 제공합니다.
환경설정 및 종속성 설치
다음은 환경설정 및 종속성 설치단계입니다. 이번 프로젝트는 가상환경 생성과 활성화 모두 WSL(Windows Subsystem for Linux) 프롬프트에서 진행하였으며, WSL 프롬프트에서 가상환경 생성은 "python3.11 -m venv myenv", 활성화는 "source myenv/bin/activate" 명령어를 입력하면 됩니다.
종속성 설치는 아래에 텍스트 내용을 복사해서 원하는 폴더에 requirements.txt라는 이름으로 파일을 만든 다음 가상환경이 활성화된 WSL 프롬프트에서 "pip install -r requirements.txt" 명령어로 종속성을 설치해 줍니다.
wikipedia
haystack-ai
transformers
sentence_transformers
rich
다음은 종속성 설치에 포함된 각 라이브러리에 대한 설명입니다.
- Wikipedia: Wikipedia는 온라인 백과사전으로, 다양한 주제에 대한 정보를 제공합니다. 이 라이브러리는 Wikipedia의 페이지를 가져오고, 관련 정보를 추출할 수 있도록 도와줍니다.
- Haystack-ai: 자연어 처리(NLP) 기반의 정보 검색 및 질의응답 프레임워크입니다. 문서 검색, 텍스트 분석, 추론 등의 기능을 제공하여 검색 기능을 개발할 때 유용하게 사용할 수 있습니다.
- Transformers: Hugging Face에서 개발한 자연어 처리를 위한 파이썬 라이브러리입니다. 사전 훈련된 언어 모델을 사용하여 텍스트 분류, 개체명 인식, 기계 번역 등 다양한 NLP 작업을 수행할 수 있습니다.
- Sentence_transformers: 문장 임베딩을 위한 라이브러리로, 텍스트 문장을 고차원 벡터로 변환하여 유사도를 측정하거나 문장 간의 의미적 관계를 분석하는 데 사용됩니다.
- Rich: 터미널 환경에서 텍스트를 보다 풍부하고 다양한 스타일로 표현할 수 있는 파이썬 라이브러리입니다. 테이블, 그래프, 색상 등 다양한 기능을 제공하여 터미널 애플리케이션의 사용자 경험을 향상시킬 수 있습니다.
종속성 설치가 끝나면 허깅페이스에 접속한 다음 우측 상단 프로필 아이콘을 클릭하여 Settings를 선택한 후, 좌측 메뉴에서 Access Tokens를 클릭하고 New Token 버튼을 통해 허깅페이스 API Key를 발급받습니다. 그다음 가상환경이 활성화된 WSL 프롬프트 상태에서 "export HUGGINGFACE_API_KEY="xxxxxxxxx" 명령어로 API Key를 시스템으로 내보냅니다.
파이썬 코드 실행
이 코드는 파이썬을 사용하여 구현된 Haystack 라이브러리를 활용한 질문-응답 시스템으로, 다음과 같은 주요 단계로 구성되어 있습니다.
- 1. 라이브러리 및 모듈 임포트: 코드의 맨 처음에는 필요한 라이브러리와 모듈을 임포트 합니다. 이 코드에서는 `os`, `torch`, `rich`, `wikipedia`, `haystack-ai`, `transformers`, `sentence_transformers`, `rich` 등의 라이브러리를 임포트 합니다. 또한 Haystack 라이브러리의 여러 구성 요소 및 클래스도 임포트 합니다.
- 2. Hugging Face API 키 가져오기: Hugging Face API에 액세스 하기 위해 환경 변수에서 API 키를 가져옵니다.
- 3. Wikipedia 페이지 가져오기: `favourite_artists`에 나열된 여러 아티스트의 Wikipedia 페이지를 가져와 문서로 변환합니다. 다른 아티스트 또는 사용자가 원하는 주제로 변경할 수 있습니다.
- 4. 문서 저장소 생성: InMemoryDocumentStore를 사용하여 문서 저장소를 생성합니다. 이 저장소는 문서를 저장하고 검색하기 위해 사용됩니다.
- 5. 인덱싱 파이프라인: Haystack의 Pipeline을 사용하여 문서를 처리하고 인덱싱하는 파이프라인을 구성합니다. 이 파이프라인은 문서를 정제하고 분할하며, 문서를 임베딩하여 문서 저장소에 저장합니다.
- 6. Mixtral 8x7B 모델 초기화: HuggingFaceTGIGenerator를 사용하여 Hugging Face Mixtral 8x7B 모델을 초기화합니다. 이 모델은 질문에 대한 응답을 생성하는 데 사용됩니다.
- 7. 프롬프트 빌더: 질문과 문맥을 조합하여 RAG(Retrieval-Augmented Generation) 시스템에 입력으로 제공하기 위한 프롬프트를 구성합니다. 시스템, 사용자, 모델의 메시지 형식에 템플릿을 적용합니다.
- 8. RAG 파이프라인: Haystack의 Pipeline을 사용하여 RAG 파이프라인을 구성합니다. 이 파이프라인은 텍스트 임베딩, 문서 검색 및 프롬프트 빌딩 등의 작업을 수행하여 생성된 답변을 제공합니다.
- 9. 답변 얻기 함수: 사용자가 입력한 질문에 대한 응답을 생성하기 위한 함수를 정의합니다. 이 함수는 앞서 구성한 RAG 파이프라인을 실행하여 생성된 답변을 반환합니다. 저의 경우에는 max_new_tokens": 2000 설정을 추가하지 않으면 응답이 중간에서 끊기는 현상이 생겼습니다.
- 10. 질문하기: 사용자가 질문(제니퍼 로페즈의 가장 성공적인 싱글 중 일부는 어떤 것들이 있나요?)을 입력하면, 앞서 정의한 함수를 호출하여 해당 질문에 대한 답변을 표시합니다.
이 코드는 Wikipedia 페이지를 검색하여 문서를 인덱싱 하고, Hugging Face 모델을 사용하여 질문에 대한 응답을 생성하는 기능을 제공합니다. 사용자는 특정 주제에 대한 정보를 검색하고, 해당 주제에 대한 질문을 할 수 있습니다.
import os
import torch
import rich
import random
import wikipedia
from pprint import pprint
from haystack.dataclasses import Document
from haystack.components.builders import PromptBuilder
from haystack.components.retrievers import InMemoryEmbeddingRetriever
from haystack.components.generators import HuggingFaceTGIGenerator
# Hugging Face API 키 가져오기
huggingface_token = os.environ.get('HUGGINGFACE_API_KEY')
# Wikipedia 페이지 가져오기
favourite_artists="""Britney Spears
Ricky Martin
Madonna
Justin Timberlake
Christina Aguilera
Jennifer Lopez
Shakira
Enrique Iglesias
Mariah Carey
Beyoncé""".split("\n")
raw_docs = []
for title in favourite_artists:
page = wikipedia.page(title=title, auto_suggest=False)
doc = Document(content=page.content, meta={"title": page.title, "url":page.url})
raw_docs.append(doc)
from haystack import Pipeline
from haystack.document_stores import InMemoryDocumentStore
from haystack.components.preprocessors import DocumentCleaner, DocumentSplitter
from haystack.components.embedders import SentenceTransformersTextEmbedder, SentenceTransformersDocumentEmbedder
from haystack.components.writers import DocumentWriter
from haystack.components.writers.document_writer import DuplicatePolicy
# 문서 저장소 생성
document_store = InMemoryDocumentStore(embedding_similarity_function="cosine")
# 인덱싱 파이프라인
indexing = Pipeline()
indexing.add_component("cleaner", DocumentCleaner())
indexing.add_component("splitter", DocumentSplitter(split_by='sentence', split_length=2))
indexing.add_component("doc_embedder", SentenceTransformersDocumentEmbedder(model_name_or_path="thenlper/gte-large", device="cuda:0", meta_fields_to_embed=["title"]))
indexing.add_component("writer", DocumentWriter(document_store=document_store, policy=DuplicatePolicy.OVERWRITE))
indexing.connect("cleaner", "splitter")
indexing.connect("splitter", "doc_embedder")
indexing.connect("doc_embedder", "writer")
indexing.draw("indexing.png")
indexing.run({"cleaner": {"documents": raw_docs}})
# Hugging Face 모델 초기화
generator = HuggingFaceTGIGenerator("mistralai/Mixtral-8x7B-Instruct-v0.1", token=huggingface_token)
generator.warm_up()
# 질문과 문맥을 템플릿에 적용하는 프롬프트 빌더
prompt_template = """<|system|>Using the information contained in the context, give a comprehensive answer to the question.
If the answer is contained in the context, also report the source URL.
If the answer cannot be deduced from the context, do not give an answer.</s>
<|user|>
Context:
{% for doc in documents %}
{{ doc.content }} URL:{{ doc.meta['url'] }}
{% endfor %};
Question: {{query}}
</s>
<|assistant|>
"""
prompt_builder = PromptBuilder(template=prompt_template)
# RAG(Retriever-Aided Generator) 파이프라인
rag = Pipeline()
rag.add_component("text_embedder", SentenceTransformersTextEmbedder(model_name_or_path="thenlper/gte-large", device="cuda:0"))
rag.add_component("retriever", InMemoryEmbeddingRetriever(document_store=document_store, top_k=5))
rag.add_component("prompt_builder", prompt_builder)
rag.add_component("llm", generator)
rag.connect("text_embedder", "retriever")
rag.connect("retriever.documents", "prompt_builder.documents")
rag.connect("prompt_builder.prompt", "llm.prompt")
rag.draw("rag.png")
# 질문에 대한 생성된 답변 얻기 함수
def get_generative_answer(query):
results = rag.run({
"text_embedder": {"text": query},
"prompt_builder": {"query": query},
"llm": {"generation_kwargs": {"max_new_tokens": 2000}} # Adjust max_new_tokens as needed
}
)
answer = results["llm"]["replies"][0]
rich.print(answer)
# 질문하기
get_generative_answer("What are some of Jennifer Lopez's most successful singles?")
코드를 실행하면 문서를 인덱싱 하고 RAG 모델을 초기화하는 작업의 진행 상황이 나오고, 이후 Mixtral 8x7B의 응답이 해당 위키피디아 문서의 사이트 주소와 함께 표시됩니다.
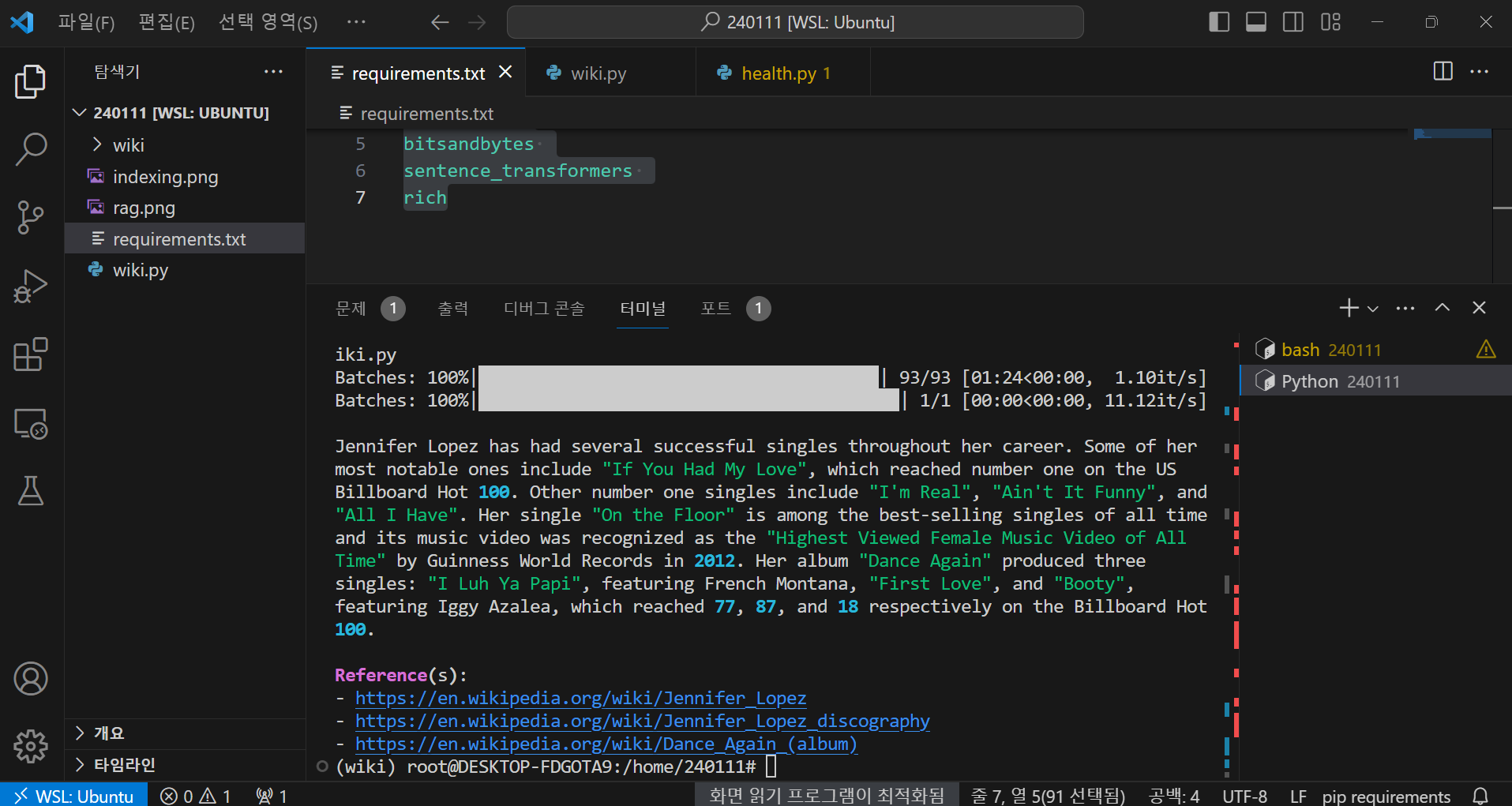
제니퍼 로페즈는 그녀의 경력 동안 여러 성공적인 싱글을 가지고 있습니다. 그 중 가장 주목할 만한 것 중 하나는
"If You Had My Love"입니다. 이 싱글은 미국 빌보드 핫 100에서 1위를 차지했습니다. 다른 1위 싱글로는 "I'm Real",
"Ain't It Funny", 그리고 "All I Have"가 있습니다. 그녀의 싱글 "On the Floor"는 무려 대표적인 싱글 중 하나로,
이 곡은 역사적으로 최고의 판매 싱글 중 하나이며 2012년에는 해당 뮤직 비디오가 기네스 월드 레코드에서 "최다
조회수의 여성 뮤직 비디오"로 인정받았습니다. 그녀의 앨범 "Dance Again"은 세 개의 싱글을 배출했습니다.
"I Luh Ya Papi"는 프렌치 몽타나와 함께한 곡으로, 빌보드 핫 100에서 77위를 기록했고, "First Love"와 "Booty"는
각각 87위와 18위를 차지했습니다. "Booty"에는 이기 아자리아가 참여했습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
마치며
오늘은 대규모 언어 모델을 이용하여 자동화된 위키피디아 검색 및 질문-응답 시스템을 구축하는 방법에 대해 살펴보았습니다. Haystack 라이브러리를 사용하여 데이터 수집, 문서 인덱싱, 그리고 RAG(Retrieval-Augmented Generation) 기술을 활용하여 자연어 답변을 생성하는 흐름을 구성했습니다. 이러한 접근 방식은 검색 시간의 단축, 효율성 향상, 사용자 정의 가능성, 시스템 통합의 장점을 제공합니다.
사용자가 특정 주제에 대한 정보를 검색하고, 해당 주제에 대한 질문을 적절한 문맥을 기반으로 답하는 기능을 자동화 함으로써 대규모 언어 모델의 활용도를 향상 시킬수 있으며, 다양한 구성 요소를 활용하여 파이프라인을 사용자 정의할 수 있는 유연성도 갖출 수 있습니다.
대규모 언어 모델의 정확성과 활용도를 높이는 도구들의 혁신적인 활용을 통해, 앞으로도 대화형 정보 검색과 자연어 처리 분야에서 많은 발전이 이루어지길 기대하면서 저는 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2024.01.10 - [AI 도구] - 대규모 언어 모델을 활용한 고객리뷰 분석(feat. Solar, Mistral)
대규모 언어 모델을 활용한 고객리뷰 분석(feat. Solar, Mistral)
안녕하세요! 최근 자연어 처리(NLP)와 정보 검색 분야에서의 진화 속에서 대규모 언어 모델과 효율적인 데이터 저장기술이 만나면서 많은 발전이 이뤄지고 있는데요. 오늘은 대규모 언어 모델 Sol
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 메타의 새로운 코딩용 대규모 언어 모델 : Code Llama 70B (0) | 2024.01.31 |
|---|---|
| Ollama와 대규모 언어 모델 Llama2-uncensored를 활용한 PDF 요약과 음성변환 (3) | 2024.01.13 |
| Mixtral 8x7B 대규모 언어 모델로 온라인 의학 정보를 쉽게 확인해보세요. (0) | 2024.01.10 |
| CrewAI를 이용한 대규모 언어 모델 Solar와 Hermes의 협업 프로젝트 (2) | 2024.01.07 |
| 제미나이 프로 비전과 이미지로 대화하는 웹 챗봇 만들기 (4) | 2024.01.01 |



