안녕하세요! 오늘은 제미나이 프로 비전 API를 활용해서 이미지를 업로드하고 대화하는 웹 챗봇을 만들어 보겠습니다. 제미나이 프로 비전은 구글이 출시한 멀티모달 AI 모델이며, 이미지, 텍스트, 코드 등 다양한 형태의 정보를 처리하고 이해할 수 있습니다. 이 포스트를 통해서 Gradio와 Vertex AI를 사용하여 Gemini Pro Vision 모델과 상호 작용하기 위한 제미나이 프로 비전 API의 활용법과 이를 위한 구글 클라우드 설정방법 등에 대해서 확인하실 수 있습니다. 자, 출발해 볼까요?

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
가상환경 만들기
먼저 아래 화면과 같이 아나콘다 파워쉘 프롬프트에서 "conda create -n name" 명령어로 새로운 가상환경을 만듭니다.

다음은 아래 화면과 같이 "conda activate name" 명령어로 가상환경을 활성화해 줍니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
구글 클라우드 설정 및 종속성 설치
다음은 구글 클라우드 프로젝트 설정입니다. 만약 구글 클라우드에 프로젝트가 없다면 아래 링크를 참조해서 신규로 생성합니다. 프로젝트가 생성되면 대시보드를 통해 프로젝트 ID를 확인하실 수 있습니다.
https://cloud.google.com/resource-manager/docs/creating-managing-projects?hl=ko
프로젝트 만들기 및 관리 | Resource Manager 문서 | Google Cloud
의견 보내기 프로젝트 만들기 및 관리 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. Google Cloud 프로젝트는 API를 관리하고 결제를 사용 설정하며 공동작업
cloud.google.com
구글 클라우드 빌링 계정이 없는 경우 아래 링크를 참조해서 신규로 생성합니다. 기능 테스트 수준의 API와 서비스로는 과금이 되지 않으니 부담 없이 빌링 계정을 만드시면 됩니다.
https://cloud.google.com/billing/docs/how-to/create-billing-account?hl=ko
새 셀프 서비스 Cloud Billing 계정 만들기 | Google Cloud
의견 보내기 새 셀프 서비스 Cloud Billing 계정 만들기 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. 이 주제에서는 Google Cloud 및 Google Maps Platform 사용 비용을
cloud.google.com
빌링 계정 설정과 프로젝트 생성이 완료되면 대시보드를 통해 프로젝트 ID를 확인한 후, 빠른 액세스에 표시된 "API 및 서비스"를 클릭해서 "Vertex AI API"를 검색한 후, "사용 설정"합니다.

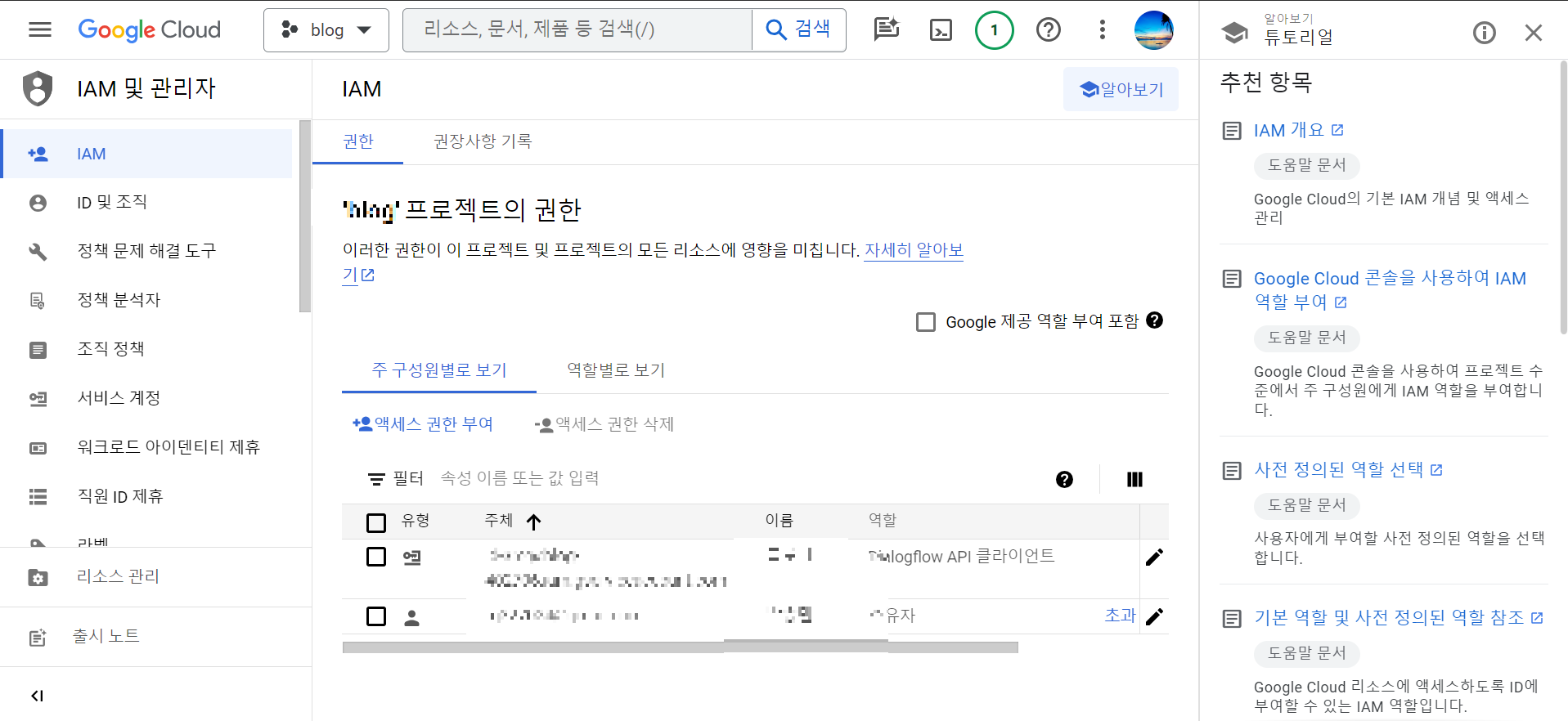
다음은 IAM 및 관리자 메뉴로 이동해서, 화면 중앙에 "액세스 권한 부여"를 클릭하고 이메일 주소를 입력한 후, 역할 지정에 "Vertex AI 관리자"와 "AI 플랫폼 관리자"를 선택합니다.
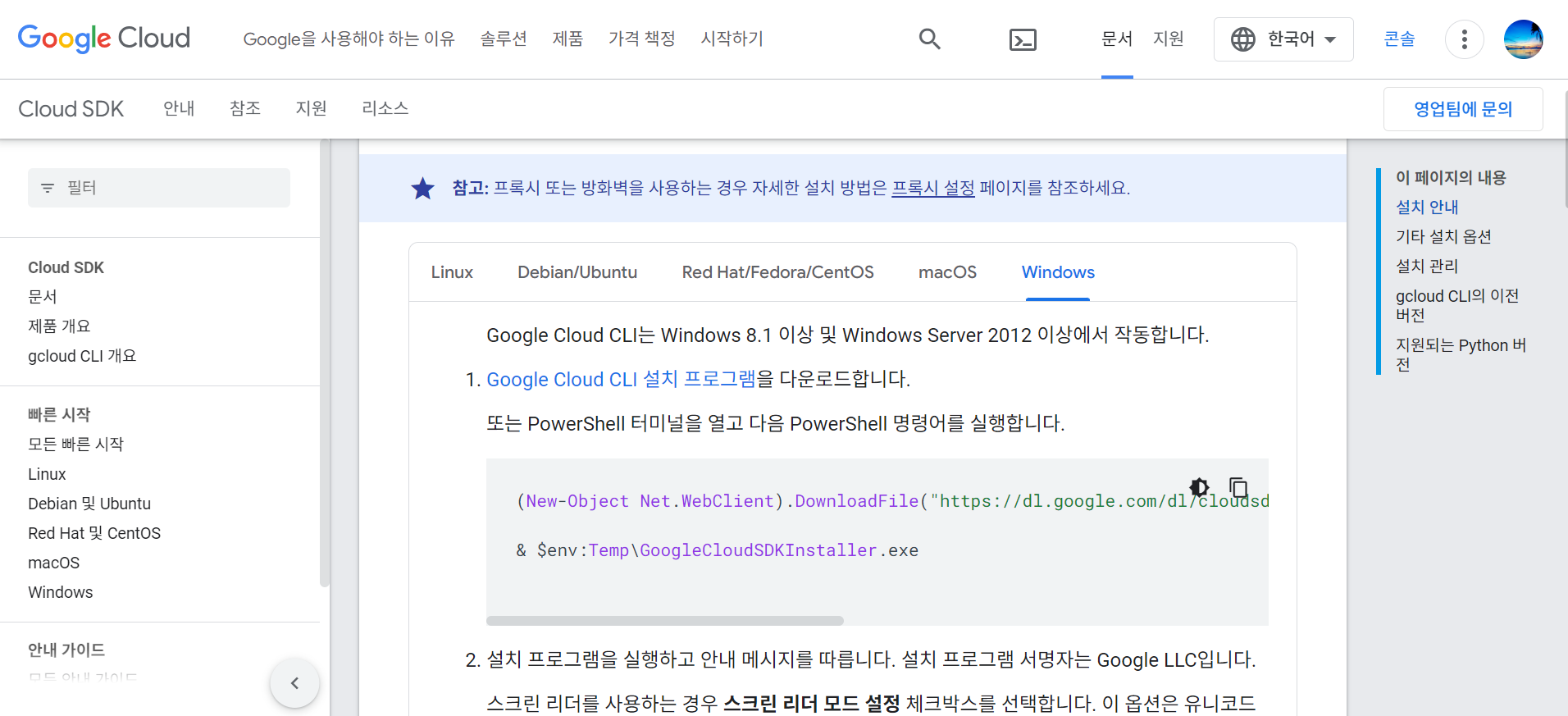
다음은 구글 클라우드 CLI 설치입니다. 아래 링크와 화면을 참조하여 구글 클라우드 CLI를 설치합니다. Google Cloud CLI (Command-Line Interface)는 Google Cloud 플랫폼과 상호 작용하기 위한 명령줄 도구입니다.
https://cloud.google.com/sdk/docs/install?hl=ko
구글 클라우드 CLI 설치가 완료되면 구글 클라우드 애플리케이션 사용을 위한 기본 사용자 인증정보인 adc.json파일의 경로를 확인해 놓아야 합니다. JSON형태 로컬 인증정보 파일의 경로는 아래 링크와 화면을 클릭해서 확인하실 수 있습니다.
https://cloud.google.com/docs/authentication/provide-credentials-adc?hl=ko#how-to
애플리케이션 기본 사용자 인증 정보 설정 | Google Cloud
Cloud Client Libraries, Google API Client Libraries, 기타 환경에 대해 애플리케이션 기본 사용자 인증 정보를 설정하는 방법을 알아봅니다.
cloud.google.com
다음은 코드 실행을 위한 종속성 설치입니다. 아래에 텍스트 내용을 복사해서 원하는 폴더에 requirements.txt라는 이름으로 파일을 만든 다음 가상환경이 활성화된 아나콘다 파워쉘 프롬프트에서 "pip install -r requirements.txt" 명령어로 종속성을 설치해 줍니다.
google-generativeai==0.3.2
gradio==4.12.0
vertexai==0.0.1
google-cloud-aiplatform==1.38.1파이썬 코드 실행하기
다음은 파이썬 코드를 실행하는 단계입니다. 이 Python 코드는 Gradio 라이브러리를 사용하여 Vertex AI Generative Models API와 상호 작용하는 간단한 웹 인터페이스를 만듭니다. 특히, Gemini Pro Vision 모델을 사용하여 입력 이미지와 텍스트에 기반한 콘텐츠를 생성합니다. 코드를 간단히 설명하면 다음과 같습니다:
- 1. 라이브러리 가져오기: `gr`: UI 인터페이스를 만들기 위한 Gradio 라이브러리. `base64`: base64 데이터를 인코딩 및 디코딩하기 위한 모듈. `vertexai`: Google Cloud의 기계 학습 서비스를 다루기 위한 Vertex AI 라이브러리. `webbrowser`: 기본 웹 브라우저에서 웹 페이지를 열기 위한 모듈. `os`: 운영 체제 별 기능을 제공하는 라이브러리. `io`: 입출력 작업을 위한 라이브러리.
- 2. Vertex AI 초기화: `vertexai.init(project="프로젝트 ID")`: 지정된 본인의 프로젝트 ID로 Vertex AI를 초기화합니다.
- 3. Google Cloud 자격 증명 설정: `os.environ["GOOGLE_APPLICATION_CREDENTIALS"]`: Google Cloud 서비스에 액세스 하는 데 사용되는 자격 증명 파일의 경로를 설정합니다. 이는 Google Cloud 서비스에 액세스 하기 위한 자격 증명이 담긴 JSON 파일을 가리키며, 본인의 컴퓨터에 저장된 경로를 설정해야 합니다.
- 4. 이미지 및 텍스트 처리 함수 정의: `process_image_and_text(image, text)`: 이미지와 텍스트를 입력으로 받아 이미지를 base64로 인코딩하고 Gemini Pro Vision 모델을 사용하여 이미지와 텍스트에 기반한 콘텐츠를 생성합니다. 생성된 콘텐츠가 반환됩니다.
- 5. Gradio 인터페이스 생성: `gr.Interface(...)`: 지정된 입력, 출력, 제목 및 설명과 함께 Gradio 인터페이스를 정의합니다. "pil" 타입의 이미지 입력은 `gr.Image`를 사용하며 레이블은 "이미지 업로드"입니다. 텍스트 입력은 `gr.Textbox`를 사용하며 레이블은 "텍스트 입력"입니다. 텍스트 출력은 `gr.Text`를 사용하며 레이블은 "출력 텍스트"입니다.
- 6. 인터페이스 시작: `webbrowser.open_new_tab('http://127.0.0.1:7860')`: 지정된 로컬 주소를 가리키는 새로운 브라우저 탭을 엽니다.
- 7. Gradio 인터페이스 시작: `iface.launch()`: Gradio 인터페이스를 시작하여 사용자가 이미지를 업로드하고 텍스트를 입력하며 Gemini Pro Vision 모델에 의해 생성된 텍스트 출력을 확인할 수 있습니다.
이 스크립트는 Gradio와 Vertex AI를 사용하여 Gemini Pro Vision 모델과 상호 작용할 수 있는 사용자 친화적인 웹 인터페이스를 만듭니다. 사용자는 이미지를 업로드하고 텍스트를 입력하며 입력에 기반한 생성된 콘텐츠를 확인할 수 있습니다. 웹 인터페이스는 새 브라우저 탭에서 열립니다.
import gradio as gr
import base64
import vertexai
from vertexai.preview.generative_models import GenerativeModel, Part
import webbrowser
import os
import io
vertexai.init(project="구글 클라우드 프로젝트 ID")
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = r"C:\Users\....본인 컴퓨터 경로...@gmail.com\adc.json"
def process_image_and_text(image, text):
buffer = io.BytesIO()
image.save(buffer, format="JPEG")
image_bytes = buffer.getvalue()
encode_image = base64.b64encode(image_bytes).decode('utf-8')
image1 = Part.from_data(data=base64.b64decode(encode_image), mime_type="image/jpeg")
model = GenerativeModel("gemini-pro-vision")
# `stream=False`를 사용하여 완전한 응답 개체를 얻습니다.
response = model.generate_content(
[image1, text],
generation_config={
"max_output_tokens": 2048,
"temperature": 0.4,
"top_p": 1,
"top_k": 32
},
stream=False # `False`로 변경합니다.
)
return response.candidates[0].content.parts[0].text
iface = gr.Interface(
fn=process_image_and_text,
inputs=[
gr.Image(type="pil", label="이미지 업로드"),
gr.Textbox(label="텍스트 입력")
],
outputs=gr.Text(label="출력 텍스트"),
title="Gemini Pro Vision API",
description="Gemini Pro Vision API를 사용하여 이미지를 업로드하고 텍스트를 처리하세요."
)
# Launch the interface in a new browser tab
webbrowser.open_new_tab('http://127.0.0.1:7860')
iface.launch()"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
제미나이 프로 비전과 대화하기
코드를 실행하면 자동으로 http://127.0.0.1:7860/ 의 주소로 웹 브라우저가 열리며 제미나이 프로 비전과 대화할 수 있는 챗봇을 만나실 수 있습니다. 아래 화면은 비행기 시간표 사진에서 장소와 출발시간을 자동으로 인식하고, 피자 사진을 분석하여 레시피를 제공하거나, 파이썬 코드와 인물사진을 해석하여 설명하는 이미지 인식 테스트 결과입니다. 제미나이 프로 비전이 해당 이미지들을 정확하게 인식해서 대답하였습니다.
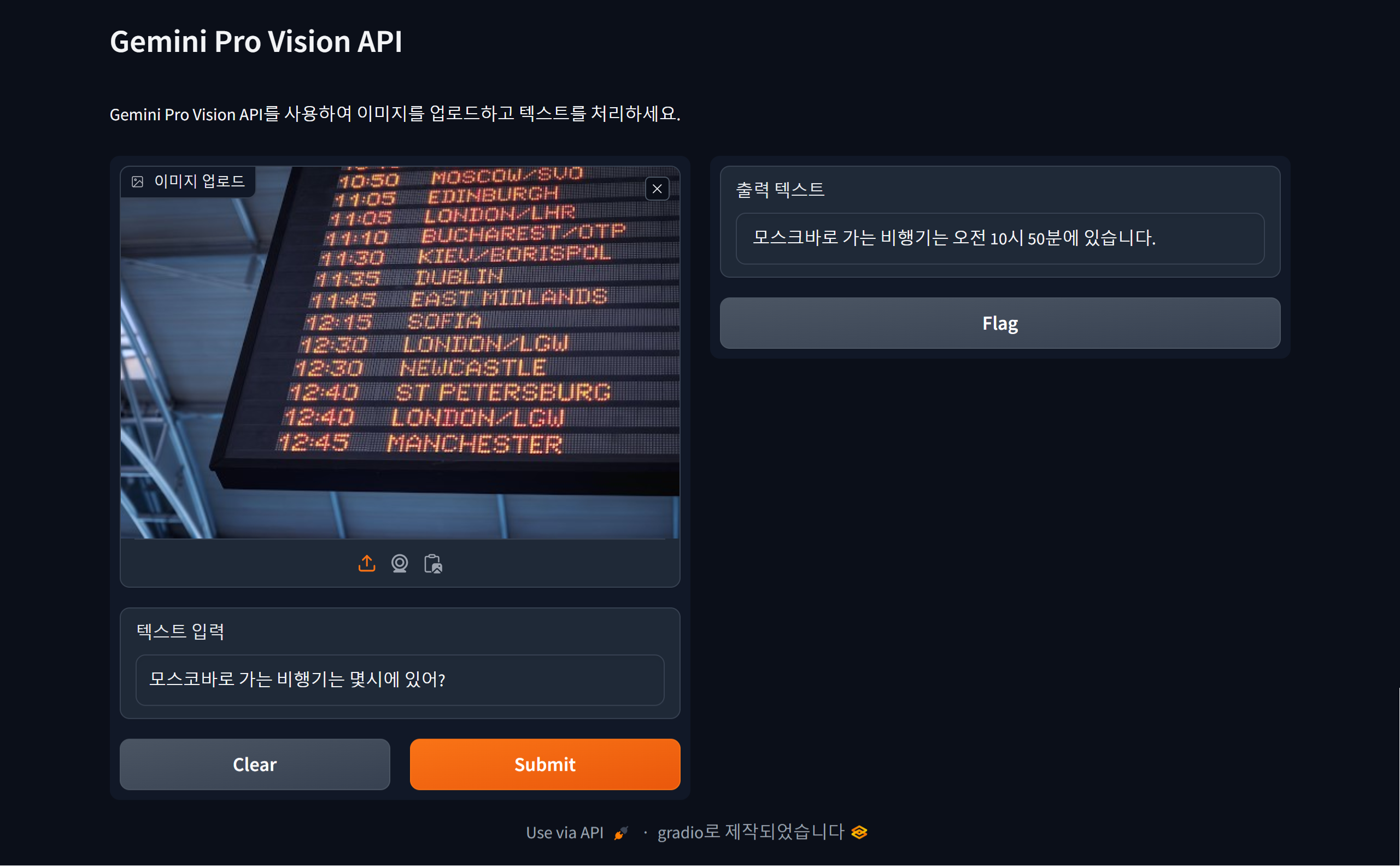
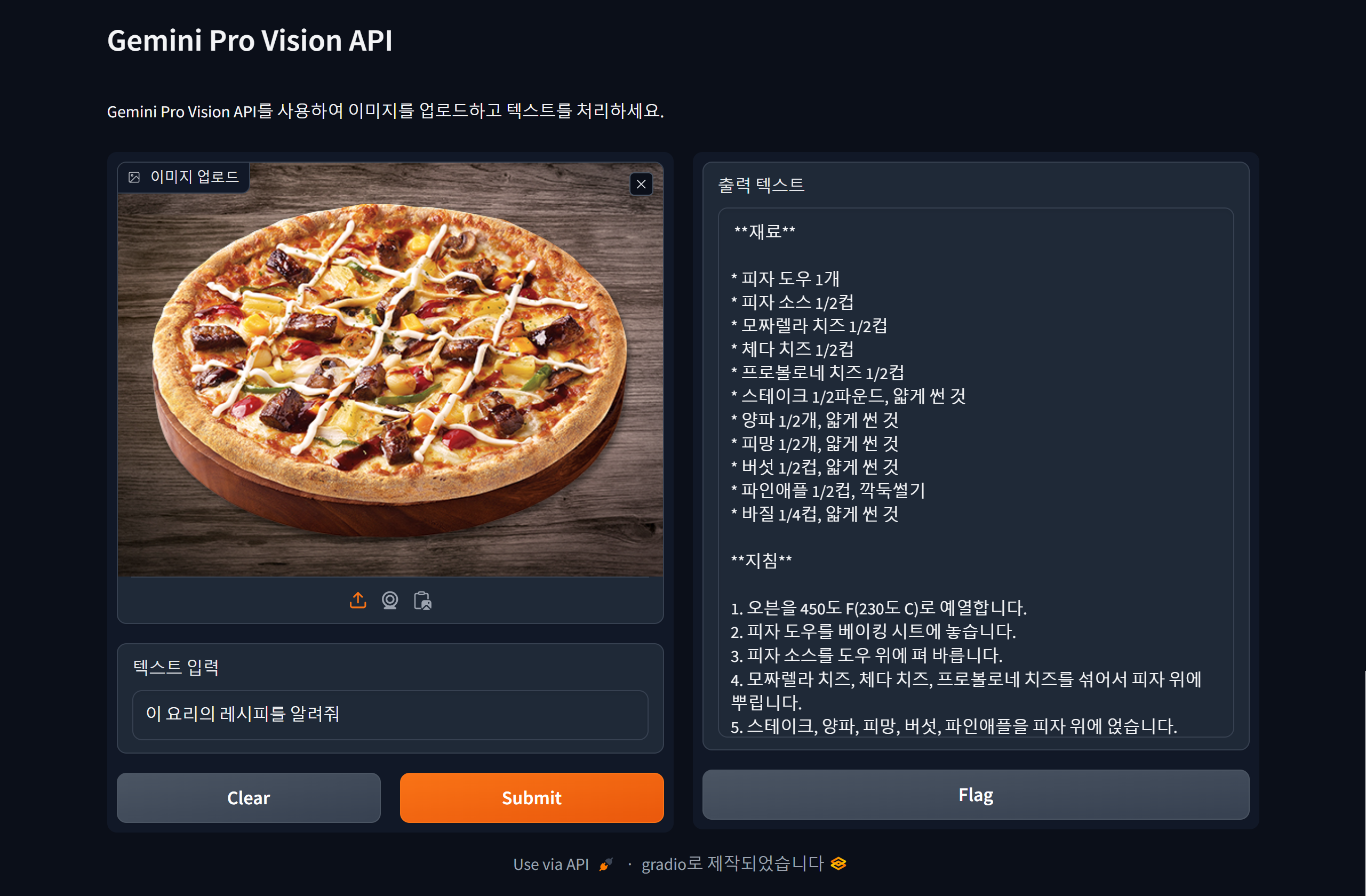
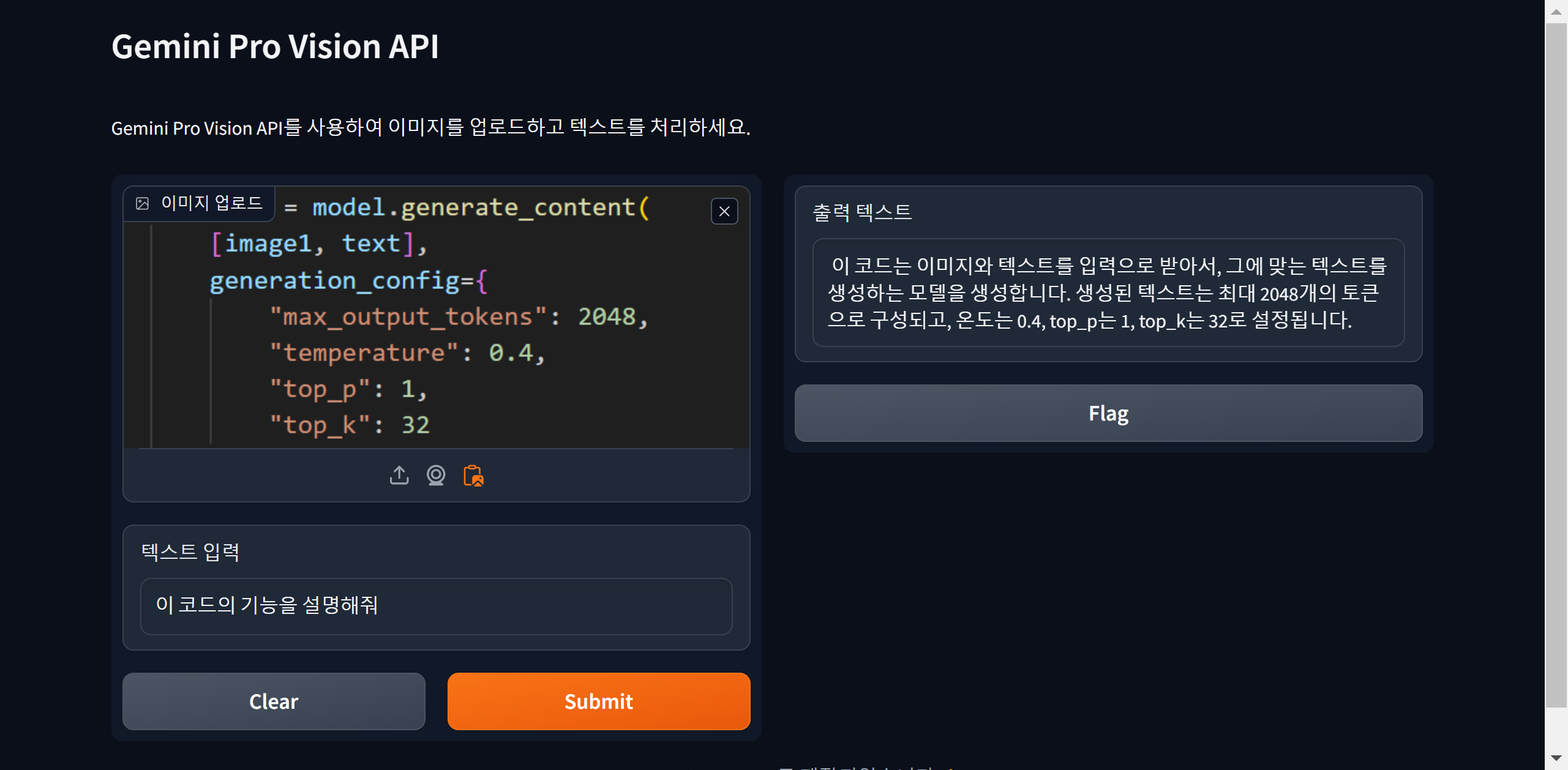
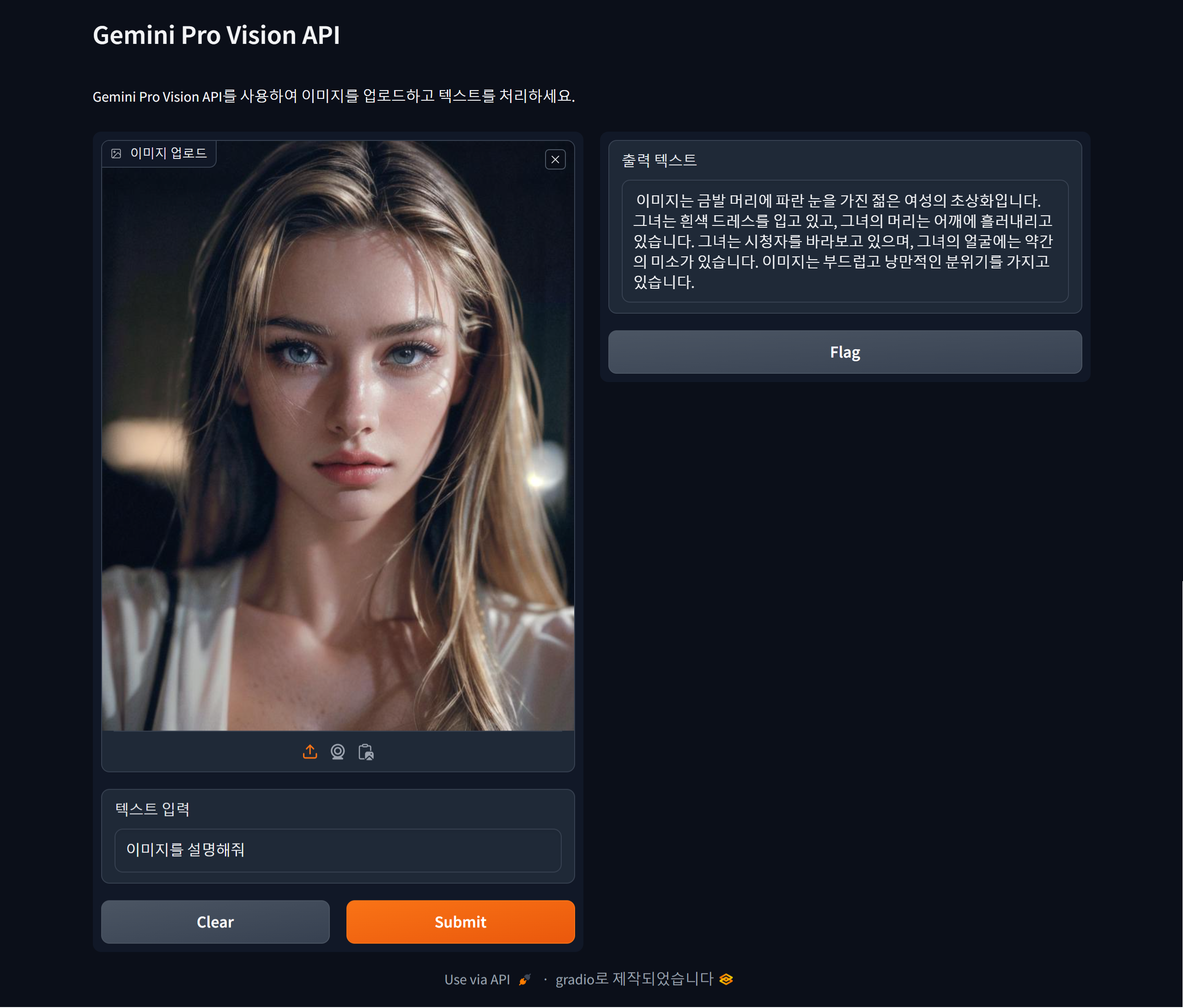

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
마치며
오늘은 Gradio와 Vertex AI를 활용하여 제미나이 프로 비전 API를 이용한 이미지 처리 웹 챗봇을 만들어보았습니다. 구글 클라우드의 서비스를 활용하면서 설정하고 실행할 수 있는 방법과, 제미나이 프로 비전의 멀티모달 기능으로 다양한 형태의 정보를 처리하는 AI의 가능성을 확인해 볼 수 있었던 것 같습니다.
이 블로그에서는 가상환경 설정, 구글 클라우드 프로젝트 및 빌링 계정 설정, 그리고 Python 코드 실행을 통해 멀티모달 AI 모델을 활용하여 이미지와 텍스트에 기반한 다양한 작업을 수행하는 웹 인터페이스를 구현하고, 최종적으로 제미나이 프로 비전이 정확한 결과를 제공하는 예시를 제시하였습니다.
2024년 새해 첫 포스트는 여기까지입니다. 그럼 여러분 모두 2024년 힘차게 시작하시고, 원하시는 일이 모두 이루어지시길 기원하면서 저는 다음에 더욱 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2023.12.23 - [분류 전체보기] - 제미나이 API로 실시간 주식정보 가져오기 : 초보 탈출?
제미나이 API로 실시간 주식정보 가져오기 : 초보 탈출?
안녕하세요. 오늘은 구글 제미나이 API와 함수 호출기능을 활용해서 실시간 주식정보를 가져오는 프로젝트에 도전해 보겠습니다. 제미나이는 실시간 주식정보를 대답할 수 있는 기능이 없지만,
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| Mixtral 8x7B 대규모 언어 모델로 온라인 의학 정보를 쉽게 확인해보세요. (0) | 2024.01.10 |
|---|---|
| CrewAI를 이용한 대규모 언어 모델 Solar와 Hermes의 협업 프로젝트 (4) | 2024.01.07 |
| 허깅페이스 1위 Solar 10.7B와 Autogen으로 대화하기 : feat. Mistral 7B (4) | 2023.12.30 |
| LiteLLM으로 Mistral 7B와 대화하는 웹 챗봇 만들기 (2) | 2023.12.28 |
| 제미나이 웹 챗봇 만들기 : 주식 정보 검색도 쌉가능 (2) | 2023.12.26 |



