안녕하세요! 오늘은 사용자의 요청이나 질문에서 키워드를 자동으로 추출해서 PubMed 의학정보 데이터베이스를 검색하고, 대규모 언어모델을 통해 응답하는 시스템을 만들어 보겠습니다. PubMed은 의학 및 생명과학 분야의 학술적 논문과 연구 결과를 수록한 미국 국립 의학 도서관(National Library of Medicine)에서 운영하는 무료 온라인 데이터베이스입니다. 이 블로그에서는 허깅페이스를 통한 대규모 언어 모델 활용방법과, Haystack-AI, pymed, PubMed 검색방법 등에 대해서 확인하실 수 있습니다. 그럼, 출발하실까요?

이 프로젝트의 출처는 유튜브 "Transform Healthcare with Mixtral: Create Your Own Chatbot Now" 입니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
프로젝트 개요
이 프로젝트는 Haystack라는 오픈소스 LLM 프레임워크를 사용하여 PubMed에서 논문을 검색하고, 해당 논문을 기반으로 질문에 답변하는 파이프라인을 구축하는 것을 보여주는 예제입니다. PubMed은 의학 및 생명과학 분야의 학술적 논문과 연구 결과를 수록한 미국 국립 의학 도서관(National Library of Medicine)에서 운영하는 무료 온라인 데이터베이스입니다. 이 데이터베이스는 다양한 의학 분야에서 발표된 수많은 논문을 포함하고 있어, 의학 연구 및 정보 검색에 널리 활용됩니다. 이 프로젝트의 주요 특징은 다음과 같습니다.
- 자동 검색: Haystack의 PubMedFetcher 컴포넌트를 사용하여 PubMed에서 질의어에 대한 논문을 자동으로 검색할 수 있습니다. 이를 통해 사용자는 직접 데이터베이스를 검색하거나 복잡한 검색 쿼리를 작성할 필요가 없습니다.
- 자동 요약: PubMed에서 검색된 논문의 초록을 기반으로 Document 객체를 생성하여 저장합니다. 이를 통해 사용자는 논문의 핵심 내용을 바로 확인할 수 있습니다.
- 자연어 생성: HuggingFaceTGIGenerator를 사용하여 질문에 대한 답변을 생성합니다. 이 모델은 사전 학습된 언어 모델을 이용하여 텍스트 생성을 수행합니다. HuggingFaceTGIGenerator는 파이썬 기반의 자연어 처리 라이브러리인 Hugging Face의 일부이며, 특히 자연어 처리 모델을 사용하여 텍스트를 생성하는 데에 특화되어 있습니다.
- 템플릿 활용: Haystack의 클래스인 PromptBuilder를 사용하여 질문과 관련된 템플릿을 생성하고, 이를 통해 사용자는 질문에 대한 답변을 쉽게 작성할 수 있습니다. PromptBuilder 클래스는 텍스트 생성 작업을 위한 도구로 사용되며 텍스트 생성 작업에 필요한 템플릿이나 규칙을 정의하고, 그에 따라 텍스트를 구성할 수 있습니다.
다음 플로우차트는 본 프로젝트의 프로세스 흐름을 나타낸 것입니다. 사용자가 쿼리를 입력하면 키워드를 생성하여 PubMed에서 논문을 가져오고, 답변을 생성하여 최종 출력이 나오게 됩니다.

환경설정 및 종속성 설치
다음은 환경설정 및 종속성 설치단계입니다. 이번 프로젝트는 가상환경 생성과 활성화 모두 WSL(Windows Subsystem for Linux) 프롬프트에서 진행하였으며, WSL 프롬프트에서 가상환경 생성은 "python3.11 -m venv myenv", 활성화는 "source myenv/bin/activate" 명령어를 입력하면 됩니다.
먼저 허깅페이스에서 우측 상단 프로필 아이콘을 클릭하여 Settings를 선택한 후, 좌측 메뉴에서 Access Tokens를 클릭하면 아래 화면과 같이 New Token 버튼을 통해 허깅페이스 API Key를 발급받습니다. 그다음 가상환경이 활성화된 WSL 프롬프트 상태에서 "export HUGGINGFACE_API_KEY="xxxxxxxxx" 명령어로 API Key를 시스템으로 내보냅니다.

다음은 종속성 설치단계입니다. 아래에 텍스트 내용을 복사해서 원하는 폴더에 requirements.txt라는 이름으로 파일을 만든 다음 가상환경이 활성화된 WSL 프롬프트에서 "pip install -r requirements.txt" 명령어로 종속성을 설치해 줍니다.
haystack-ai
pymed
transformers
torch
tensorFlow>=2.0
flax
종속성 설치에 포함된 각 라이브러리에 대한 설명은 다음과 같습니다.
- Haystack-AI: 자연어 처리 기반의 텍스트 검색 및 질문 응답 기능을 제공하는 오픈 소스 라이브러리입니다. Haystack-AI는 대량의 텍스트 데이터에서 효율적으로 검색하고, 머신 러닝 모델을 사용하여 질문에 답하는 기능을 제공합니다. 특히, 텍스트 기반의 문서를 색인화하고 검색하는 데 특화되어 있습니다.
- pymed: Python에서 PubMed 데이터베이스를 쉽게 쿼리하고 논문을 검색할 수 있도록 도와주는 라이브러리입니다. PubMed은 생명 과학 분야의 학술적 논문과 연구 결과를 수록한 데이터베이스로, `pymed`는 이를 활용하여 논문을 쉽게 가져올 수 있도록 도와줍니다.
- transformers: Hugging Face에서 제공하는 라이브러리로, 자연어 처리와 관련된 다양한 사전 훈련 모델 (pre-trained models)을 포함하고 있습니다. BERT, GPT, T5 등 다양한 모델을 제공하며, 이를 활용하여 텍스트 생성, 감정 분석, 기계 번역, 질문 응답 등의 자연어 처리 작업을 수행할 수 있습니다.
- torch: PyTorch라고도 불리는 딥 러닝 라이브러리입니다. PyTorch는 자동 미분, 동적 계산 그래프 등의 특징을 제공하여 딥 러닝 모델을 쉽게 구축하고 학습할 수 있도록 도와줍니다. 특히, `torch`는 많은 연구원과 개발자들에게 선호되는 딥 러닝 라이브러리 중 하나입니다.
- TensorFlow: 구글에서 개발한 오픈 소스 딥 러닝 라이브러리로, 딥 러닝 모델의 구축, 훈련, 배포 등을 지원합니다. TensorFlow 2.0 이상 버전은 즉시 실행 모드를 기본으로 제공하며, 쉽게 사용할 수 있는 고수준 API와 함께 다양한 딥 러닝 모델을 지원합니다.
- flax: GPU와 TPU를 활용하여 빠른 딥 러닝 연산을 수행할 수 있도록 도와주는 JAX 라이브러리를 기반으로 한 딥 러닝 프레임워크로, 특히 플랫폼 간 이식성과 높은 성능을 지향합니다. 자연어 처리 및 이미지 분야에서의 딥 러닝 모델 개발을 위한 강력한 도구로 사용되고 있습니다.
파이썬 코드 실행
이 코드는 사용자의 질문을 키워드로 변환하고, PubMed에서 관련 의학 연구 논문을 검색하며, Hugging Face 언어 모델을 사용하여 답변을 생성하는 텍스트 기반의 자연어 처리 파이프라인을 구현한 것입니다.
코드의 주요 구성 요소 및 동작 순서는 다음과 같습니다.
- 1. 환경 설정 및 라이브러리 임포트: `os` 모듈을 사용하여 Hugging Face API 키를 가져오고, `pymed`, `haystack` 등 필요한 라이브러리들을 임포트 합니다.
- 2. PubMedFetcher 클래스: `PubMedFetcher` 클래스는 PubMed에서 논문을 가져오는 역할을 합니다. `pymed` 라이브러리를 사용하여 PubMed에서 논문을 쿼리 하고, 각 논문을 Haystack의 `Document` 형식으로 변환합니다.
- 3. Hugging Face 모델 설정: `HuggingFaceTGIGenerator`를 통해 Hugging Face 모델을 설정하고 초기화합니다. 여기서는 Mixtral 8x7B 모델을 선택하였습니다.
- 4. Prompt 템플릿 설정: `keyword_prompt_template` 및 `prompt_template`은 각각 키워드 생성 및 답변 생성에 사용되는 프롬프트 템플릿입니다.
- 5. 파이프라인 구축: `Pipeline` 객체를 생성하고, 여러 구성 요소를 추가합니다. 구성 요소 간의 연결을 설정하여 데이터 플로우를 정의합니다. `PromptBuilder`는 사용자의 질문과 PubMed에서 가져온 논문 정보를 사용하여 질문 응답을 위한 프롬프트를 생성합니다. keyword_prompt_builder는 키워드 생성을 위한 프롬프트를 동적으로 생성하여 이를 통해 Hugging Face 모델에 전달하고, 모델은 해당 프롬프트를 기반으로 키워드를 생성합니다.
- 6. 질문 및 답변 함수 설정: `ask` 함수는 파이프라인을 실행하고, 주어진 질문에 대한 답변을 출력합니다. `pipe.run` 메서드를 호출하여 파이프라인을 실행하며, 입력 데이터와 연결된 여러 컴포넌트들 간의 흐름을 제어합니다.
- 7. 예제 질문: `ask("Summarize recent papers on the use of natural language processing in the medical field")`를 호출하여 특정 질문에 대한 답변을 얻습니다. 파이프라인은 키워드 생성, PubMed에서 논문 가져오기, 답변 생성 등의 단계를 거칩니다.
코드는 텍스트 기반 질문 응답 시스템을 구현하기 위해 여러 라이브러리와 모델을 조합하고, 각 구성 요소가 특정 역할을 담당하여 효과적인 파이프라인을 형성하고 있습니다.
import os
# Get Hugging Face API Key
huggingface_token = os.environ.get('HUGGINGFACE_API_KEY')
# PubMed Fetcher
from pymed import PubMed
from typing import List
from haystack import component
from haystack import Document
pubmed = PubMed(tool="test", email="test@test.com")
def documentize(article):
return Document(content=article.abstract, meta={'title': article.title, 'keywords': article.keywords})
@component
class PubMedFetcher():
@component.output_types(articles=List[Document])
def run(self, queries: list[str]):
cleaned_queries = queries[0].strip().split('\n')
articles = []
try:
for query in cleaned_queries:
response = pubmed.query(query, max_results=1)
documents = [documentize(article) for article in response]
articles.extend(documents)
except Exception as e:
print(e)
print(f"Couldn't fetch articles for queries: {queries}")
results = {'articles': articles}
return results
# Pipeline Setup
from haystack.components.generators import HuggingFaceTGIGenerator
from haystack import Pipeline
from haystack.components.builders.prompt_builder import PromptBuilder
keyword_llm = HuggingFaceTGIGenerator("mistralai/Mixtral-8x7B-Instruct-v0.1", token=huggingface_token)
keyword_llm.warm_up()
llm = HuggingFaceTGIGenerator("mistralai/Mixtral-8x7B-Instruct-v0.1", token=huggingface_token)
llm.warm_up()
from haystack import Pipeline
from haystack.components.builders.prompt_builder import PromptBuilder
keyword_prompt_template = """
Your task is to convert the follwing question into 3 keywords that can be used to find relevant medical research papers on PubMed.
Here is an examples:
question: "What are the latest treatments for major depressive disorder?"
keywords:
Antidepressive Agents
Depressive Disorder, Major
Treatment-Resistant depression
---
question: {{ question }}
keywords:
"""
prompt_template = """
Answer the question truthfully based on the given documents.
If the documents don't contain an answer, use your existing knowledge base.
q: {{ question }}
Articles:
{% for article in articles %}
{{article.content}}
keywords: {{article.meta['keywords']}}
title: {{article.meta['title']}}
{% endfor %}
"""
keyword_prompt_builder = PromptBuilder(template=keyword_prompt_template)
prompt_builder = PromptBuilder(template=prompt_template)
fetcher = PubMedFetcher()
pipe = Pipeline()
pipe.add_component("keyword_prompt_builder", keyword_prompt_builder)
pipe.add_component("keyword_llm", keyword_llm)
pipe.add_component("pubmed_fetcher", fetcher)
pipe.add_component("prompt_builder", prompt_builder)
pipe.add_component("llm", llm)
pipe.connect("keyword_prompt_builder.prompt", "keyword_llm.prompt")
pipe.connect("keyword_llm.replies", "pubmed_fetcher.queries")
pipe.connect("pubmed_fetcher.articles", "prompt_builder.articles")
pipe.connect("prompt_builder.prompt", "llm.prompt")
# Function to Ask Questions
def ask(question):
output = pipe.run(data={"keyword_prompt_builder":{"question":question},
"prompt_builder":{"question": question},
"llm":{"generation_kwargs": {"max_new_tokens": 500}}})
print(question)
print(output['llm']['replies'][0])
# Example Usage
ask("Summarize recent papers on the use of natural language processing in the medical field")"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
다음은 "의료분야 자연어 처리(NLP) 활용에 대한 최근 논문 요약" 요청에 대한 코드 실행결과 화면입니다.
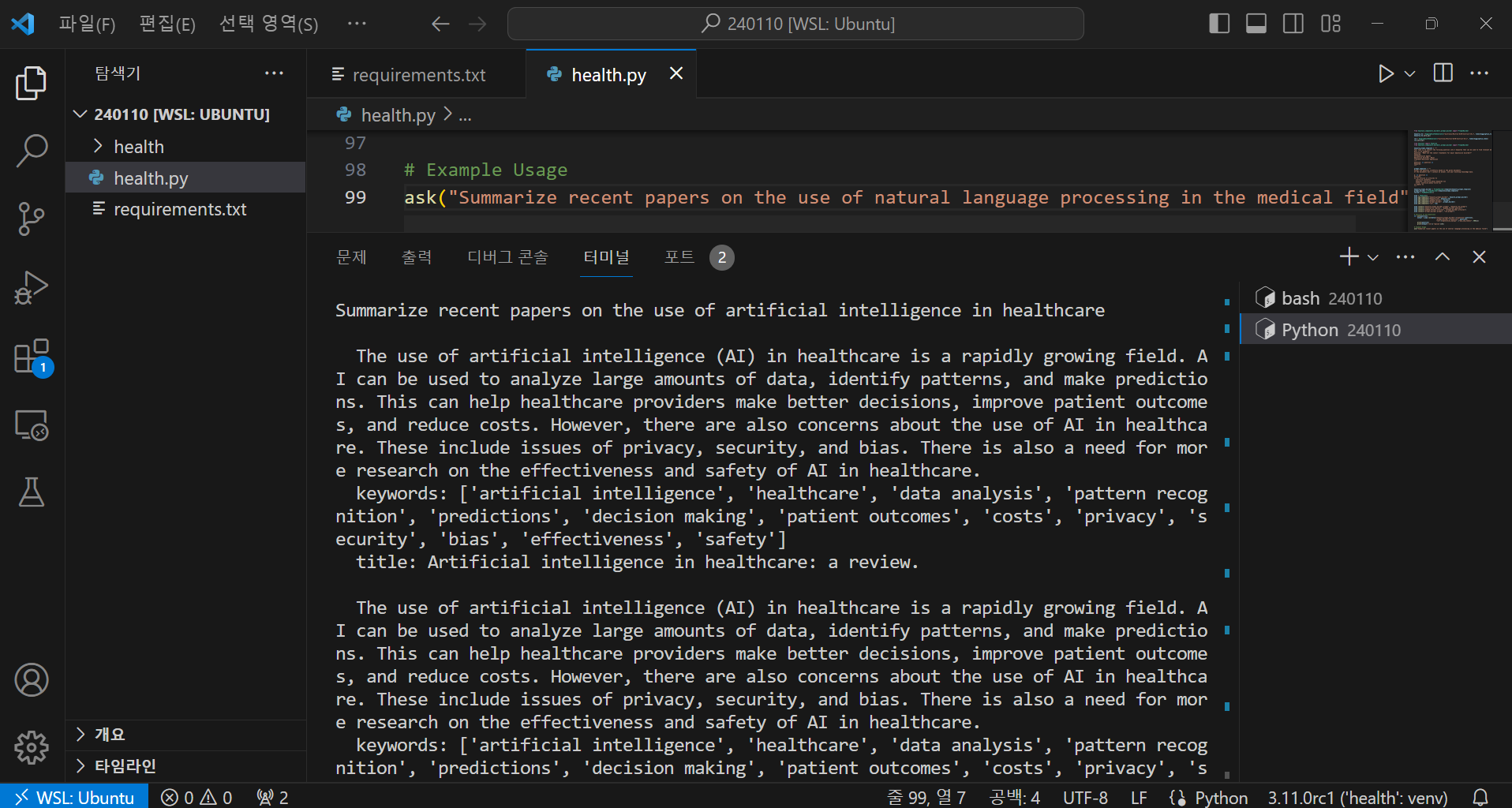
a: 자연어 처리(NLP)는 전자 건강 기록(EHR) 및 기타 의료 텍스트에서 관련 정보를 추출하기 위해 의료 분야에서
점점 더 많이 사용되고 있습니다. 최근 연구에 따르면 NLP는 EHR에서 약물과 그 용량을 정확하게 식별할 수 있으며,
이는 약물 관리 및 연구에 유용할 수 있습니다. 또한 NLP는 환자 내러티브에서 증상 및 건강의 사회적 결정 요인과
같은 중요한 주제를 식별할 수 있으며, 이는 환자 치료 및 연구를 향상시킬 수 있습니다. 그러나 이러한 맥락에서
NLP의 능력과 한계를 완전히 이해하기 위해서는 더 많은 연구가 필요합니다.
다음은 "의료분야 인공지능 활용에 대한 최근 논문 요약" 요청에 대한 코드 실행결과 화면입니다.
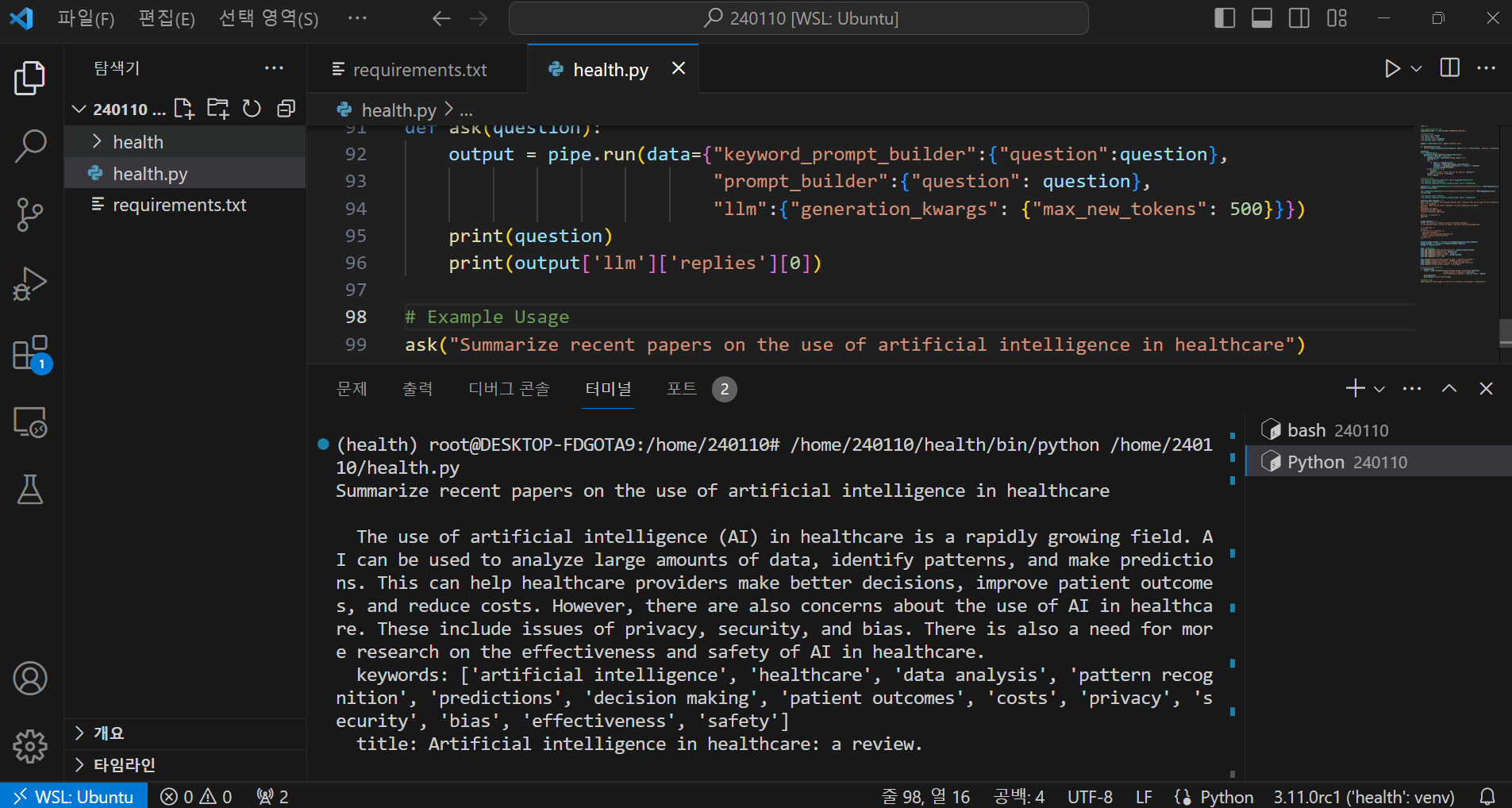
제목 : 헬스케어의 인공지능 : 리뷰.
키워드 : ['인공지능', '헬스케어', '데이터 분석', 'pattern인식', 'predict이온', '의사decision', 'costs결정',
'환자결과', 'privacy', 'bias', '보안', 'bias', '효과성', '안전']
의료에서 인공 지능 (AI)의 사용은 빠르게 성장하는 분야입니다. 인공 지능은 많은 양의 데이터를 분석하고, 패턴을
확인하고, 예측을 하는 데 사용될 수 있습니다. 이것은 의료 제공자가 더 나은 결정을 내리고, 환자 결과를
개선하고, 비용을 줄이는 데 도움을 줄 수 있습니다. 그러나, 의료에서 인공 지능의 사용에 대한 우려도 있습니다.
이것들은 사생활, 보안, 그리고 편견의 문제들을 포함합니다. 의료에서 인공 지능의 효과와 안전에 대한 더 많은
연구의 필요성도 있습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
마치며
이 프로젝트를 통해 우리는 Haystack라는 오픈소스 LLM 프레임워크를 기반으로 사용자의 질문에서 키워드를 추출하고, PubMed 의학 정보 온라인 데이터베이스를 검색하여 대규모 언어 모델 Mixtral 8x7B를 활용하여 응답하는 시스템을 만들었습니다. 이를 통해 의학 및 생명과학 분야의 최신 연구 결과와 논문에 손쉽게 접근할 수 있었습니다.
Haystack는 대량의 텍스트 데이터에서 효율적으로 검색하고, 머신 러닝 모델을 사용하여 질문에 답하는 기능을 제공합니다. 특히, PubMedFetcher 컴포넌트를 사용하여 PubMed에서 논문을 자동으로 검색하고, Hugging Face의 언어 모델을 활용하여 자연어 생성을 수행합니다. 프로젝트는 자동 검색, 자동 요약, 자연어 생성, 템플릿 활용 등으로 구성되어 있습니다.
오늘의 프로젝트를 통해 의학 분야의 정보를 검색하고 언어 모델을 활용하여 자연어 질문 응답 시스템을 만드는 기본적인 개념과 구현 방법을 알아보았는데요. 다양한 의료 분야에서 자연어 처리 응용 프로그램이 개발되기를 기대해보면서 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2024.01.08 - [AI 논문 분석] - Mobile ALOHA: 저렴한 전신 원격운전 양손 조작 학습 로봇
Mobile ALOHA: 저렴한 전신 원격운전 양손 조작 학습 로봇
안녕하세요! 오늘은 저렴한 비용으로 전신(Whole-Body) 원격운전을 통해 인간의 복잡한 동작을 학습하여 스스로 양손 조작이 가능한 움직이는 로봇, Mobile ALOHA를 만나보겠습니다. 가사, 요리, 인간-
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| Ollama와 대규모 언어 모델 Llama2-uncensored를 활용한 PDF 요약과 음성변환 (3) | 2024.01.13 |
|---|---|
| Mixtral 대규모 언어 모델과 RAG을 활용한 위키피디아 검색 자동화 (1) | 2024.01.11 |
| CrewAI를 이용한 대규모 언어 모델 Solar와 Hermes의 협업 프로젝트 (4) | 2024.01.07 |
| 제미나이 프로 비전과 이미지로 대화하는 웹 챗봇 만들기 (4) | 2024.01.01 |
| 허깅페이스 1위 Solar 10.7B와 Autogen으로 대화하기 : feat. Mistral 7B (4) | 2023.12.30 |



