안녕하세요! 오늘은 요즘 가장 인기 있는 언어 모델, LLAMA3로 AI 어시스턴트를 만들어 보겠습니다. 이 앱은 Groq과 Phidata를 이용해서 주어진 웹 사이트나 pdf를 기반으로 "원클릭" 보고서를 작성하고, 대화하는 어시스턴트를 만드는 RAG (Retrieval-Augmented Generation, 검색 증강 생성) 예제로, 20개 이상의 사이트에서 결과를 집계하여 검색결과를 제공하는 Tavily 웹 검색 API를 활용하여 완성도 높은 보고서를 10초 만에 만들 수 있습니다. 자, 그럼 시작해 볼까요?

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
프로그램 개요
이 프로그램은 Phidata와 언어 모델 추론속도 가속 솔루션인 Groq을 이용하여 구축된 LLM 애플리케이션으로, 언어 모델은 Groq에서 호스팅 하는 LLAMA3 8B와 70B, 그리고 Mixtral 8x7B 중에서 선택할 수 있고, 임베딩 모델은 로컬 언어 모델 관리 도구 Ollama에서 제공하는 "nomic embed"를 활용합니다.
프로그램의 주요 구성요소는 Phidata, Groq, Tavily, Streamlit, PostgreSQL, Docker, Nomic Embed이며, 각 구성요소에 대한 자세한 설명은 동일한 방식을 사용한 아래 포스트를 참고하시면 될 것 같습니다.
2024.04.24 - [AI 도구] - 🚀Phidata와 Groq을 활용한 LLAMA3 RAG 시스템 구현하기
🚀Phidata와 Groq을 활용한 LLAMA3 RAG 시스템 구현하기
안녕하세요! 오늘은 LLAMA3 RAG 시스템 구현 두 번째 시간으로, Phidata와 언어 모델 추론성능 가속 솔루션 Groq를 활용해서 RAG 시스템을 만들어 보겠습니다. Phidata는 언어 모델이 대화 내용을 저장하
fornewchallenge.tistory.com
이 프로그램의 주요 기능은 다음과 같습니다.
- RAG 리서치 기능 : URL, PDF, 웹 검색을 기반으로 사용자 입력 주제에 대한 원클릭 리포트 생성 기능
- RAG Chat 기능 : URL, PDF 기반으로 한 채팅 기능
- Groq API 연동 및 대형 언어 모델 선택 기능
- URL, PDF, 웹 검색 기반 지식 베이스 저장, 검색 및 초기화 기능
다음은 이 예제에서 사용된 Phidata와 Tavily 검색 API에 대한 설명입니다. Phidata는 언어 모델을 더 스마트하게 만들기 위해 메모리와 지식 저장 기능을 제공하며, 동시에 언어 모델을 자율적으로 만들기 위한 도구를 제공하는 AI 어시스턴트 구축 프레임워크로, 다음과 같은 기능을 제공합니다.
- 대화기록 저장: 대화 기록을 데이터베이스에 저장함으로써 LLM이 장기간 대화를 할 수 있도록 합니다.
- 지식 DB 제공: 정보를 벡터 데이터베이스에 저장함으로써 LLM에게 비즈니스 관련정보를 제공합니다.
- 다양한 도구: API에서 데이터를 추출하거나 이메일 발신, 데이터베이스 쿼리 등의 작업을 수행할 수 있도록 합니다.
웹사이트 검색 기능을 실행하는 Tavily 검색 API는 LLM 및 RAG를 위해 최적화된 검색 엔진으로, 다른 검색 API와 달리 단일 API 호출로 여러 온라인 소스에서 가장 관련성 높은 정보를 검색, 스크래핑, 필터링 및 추출하여 제공하며, 다음과 같은 특징을 가집니다.
- LLM 에이전트 특화: LLM 에이전트에 특화된 결과를 보장하며, 단일 API 호출당 20개 이상의 온라인 소스에서 정보를 검색하고, 스크래핑, 필터링 및 추출하여 검색 결과를 최적화해서 제공합니다.
- 검색 다양성: 사용자 정의 검색 깊이, 도메인 관리 및 HTML 콘텐츠 제어를 통해 검색을 다양하게 조절할 수 있습니다.
- 기존 설정과 통합: Python 라이브러리 또는 단순한 API 호출이나 Langchain, LLamaIndex와 같은 기존 설정과 통합을 지원하는 여러 파트너 중에서 선택할 수 있습니다.
https://docs.tavily.com/docs/tavily-api/introduction
Introduction | Tavily
Tavily Search API is a search engine optimized for LLMs and RAG, aimed at efficient, quick and persistent search results. Unlike other search APIs such as Serp or Google, Tavily focuses on optimizing search for AI developers and autonomous AI agents. We ta
docs.tavily.com
다음은 프로그램을 구현하기 위한 진행순서입니다.
- 1. 깃 허브 레포지토리 복제: Phidata 레포지토리를 로컬로 복제합니다.
- 2. 환경설정 및 모델 다운로드: 가상환경을 설정 및 활성화하고 임베딩 모델을 다운로드합니다.
- 3. Docker 컨테이너 벡터 데이터베이스 생성 : Docker를 이용해서 PostgreSQL 데이터베이스를 구성합니다.
- 4. 코드 실행 및 결과확인: URL과 PDF를 입력하고 보고서와 질문에 대한 답변을 확인합니다.
깃허브 레포지토리 복제
먼저, 아래 명령어로 깃 허브 레포지토리를 로컬로 복제하고, ai_apps 작업 디렉토리로 이동합니다.
git clone https://github.com/phidatahq/phidata.git
cd phidata\cookbook\llms\groq\ai_apps
https://github.com/phidatahq/phidata
GitHub - phidatahq/phidata: Add memory, knowledge and tools to LLMs
Add memory, knowledge and tools to LLMs. Contribute to phidatahq/phidata development by creating an account on GitHub.
github.com
ai_apps 디렉토리 내 파일의 주요 기능은 다음과 같습니다.
| 파일명 | 주요 기능 | |
| Home.py | - 이 코드는 Streamlit을 사용하여 Groq AI 애플리케이션을 빌드하는데 필요한 기본적인 구조를 설정합니다. - 사용자는 측면 표시줄에서 두 가지 AI 앱 중 하나를 선택할 수 있으며, 선택한 앱에 대한 설명이 표시됩니다. - 페이지 구성과 제목을 설정하여 사용자가 애플리케이션을 쉽게 식별할 수 있습니다. |
|
| assistant.py | - 이 코드는 RAG (Retrieval-Augmented Generation) 모델을 기반으로 한 두 가지 종류의 AI 어시스턴트를 만드는 함수를 제공합니다. - 하나는 사용자의 질문에 대답하기 위해 지식 베이스를 활용하는 챗봇 형태이고, 다른 하나는 주제 및 검색 결과를 기반으로 보고서를 작성하는 어시스턴트입니다. - 두 어시스턴트 모두 PostgreSQL 데이터베이스를 사용하여 지식을 저장하며, Groq 모델을 사용하여 LLAMA3 언어 모델을 활용합니다. |
|
| requirements.txt | 파이썬 프로젝트의 의존성을 명시하는 파일로, 프로젝트에 필요한 패키지 및 해당 버전이 명시되어 있으며, pip을 사용하여 이 파일을 기반으로 의성을 설치할 수 있습니다. | |
| README.MD | - Groq AI 앱을 설정하고 실행하는 방법을 단계별로 안내합니다. - 리서치 보조 및 채팅 애플리케이션을 구축하고 실행하는 방법을 설명하며, 필요한 라이브러리 설치, API 키 설정, 로컬 모델 설치, PostgreSQL 데이터베이스 실행 등의 단계를 포함합니다. |
|
환경설정 및 DB생성
이 블로그에서 사용한 프로그램의 실행환경은 Windows 11 Pro(23H2), 파이썬 버전 3.11, 코드 에디터는 비주얼 스튜디오 코드(이하 VSC)이며, 프로그램에 필요한 API Key는 두 가지로, Tavily 검색 API Key와 Groq API Key입니다.
먼저, Groq API Key는 https://console.groq.com/keys에 접속해서 "Create API Key" 버튼을 클릭해서 발급받습니다. 자세한 내용은 아래의 이전 포스트를 참고하시기 바랍니다.
2024.02.29 - [AI 도구] - Groq LPU : 논문 한편 요약하는데 입력-추론-응답까지 2.4초!
Groq LPU : 논문 한편 요약하는데 입력-추론-응답까지 2.4초!
안녕하세요! 오늘은 Groq이라는 회사의 대형 언어 모델 추론성능 가속장치, LPU(Language Processing Unit)에 대해서 알아보겠습니다. Groq은 2016년에 과거 구글 직원이었던 조나단 로스에 의해 설립된 AI
fornewchallenge.tistory.com
웹 검색에 필요한 Tavily 검색 API Key는 아래 링크에서 가입 후 발급받으시면 됩니다.
다음은 conda를 이용한 가상환경 생성 및 활성화 단계입니다. VSC 명령프롬프트에서 아래 명령어를 입력하여 가상환경을 생성하고 활성화합니다. 아래 명령어에서 myenv는 본인이 원하는 가상환경 이름으로 변경할 수 있습니다.
conda create -n myenv python=3.11 -y
conda activate myenv
다음은 의존성 설치단계입니다. 작업 디렉토리 내에 있는 requirements.txt 파일에 명시된 라이브러리들을 아래 명령어를 통해 설치하고, 의존성 설치가 완료되면 위에서 발급받은 API Key를 아래와 같이 시스템에 설정합니다.
pip install -r requirements.txt
set GROQ_API_KEY=본인이 발급받은 Key
set TAVILY_API_KEY=본인이 발급받은 Key
다음은 사용자의 질문, 입력 또는 대화와 관련된 텍스트를 벡터형태로 변환하는 임베딩 모델을 다운로드하는 단계입니다. 아래 명령어와 같이 Ollama를 이용해서 "nomic-embed-txt" 임베딩 모델을 다운로드합니다. "nomic-embed-txt" 임베딩 모델은 가변적인 임베딩 차원을 지원하여 성능과 메모리 사용량 사이의 균형을 조절할 수 있는 모델입니다.
ollama pull nomic-embed-text
다음은 Docker를 이용하여 벡터 데이터베이스를 생성하는 단계입니다. Docker는 응용 프로그램을 컨테이너로 패키지하고 배포하며 실행할 수 있는 컨테이너화 플랫폼으로, 아래 링크를 통해 윈도우 버전을 설치하고 실행합니다.
https://www.docker.com/products/docker-desktop/
Docker Desktop: The #1 Containerization Tool for Developers | Docker
Docker Desktop is collaborative containerization software for developers. Get started and download Docker Desktop today on Mac, Windows, or Linux.
www.docker.com
Docker 설치가 완료되면 아래 명령어를 복사하여 명령어 프롬프트에 붙여 넣어 PostgreSQL 데이터베이스를 실행하고 DB명, 계정, 사용포트, 디렉토리 등을 구성합니다.
docker run -d ^
-e POSTGRES_DB=ai ^
-e POSTGRES_USER=ai ^
-e POSTGRES_PASSWORD=ai ^
-e PGDATA=/var/lib/postgresql/data/pgdata ^
-v pgvolume:/var/lib/postgresql/data ^
-p 5532:5432 ^
--name pgvector ^
phidata/pgvector:16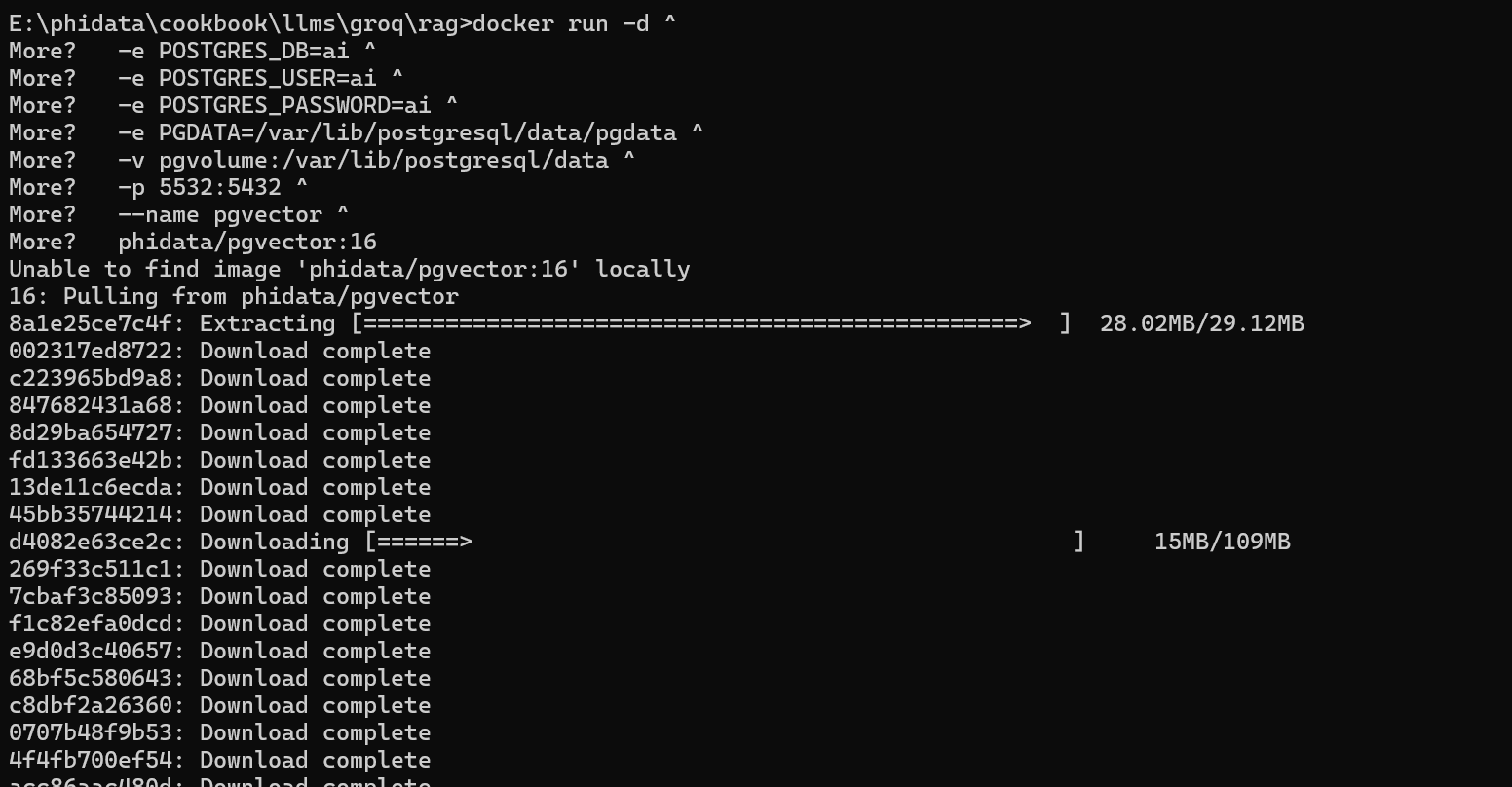
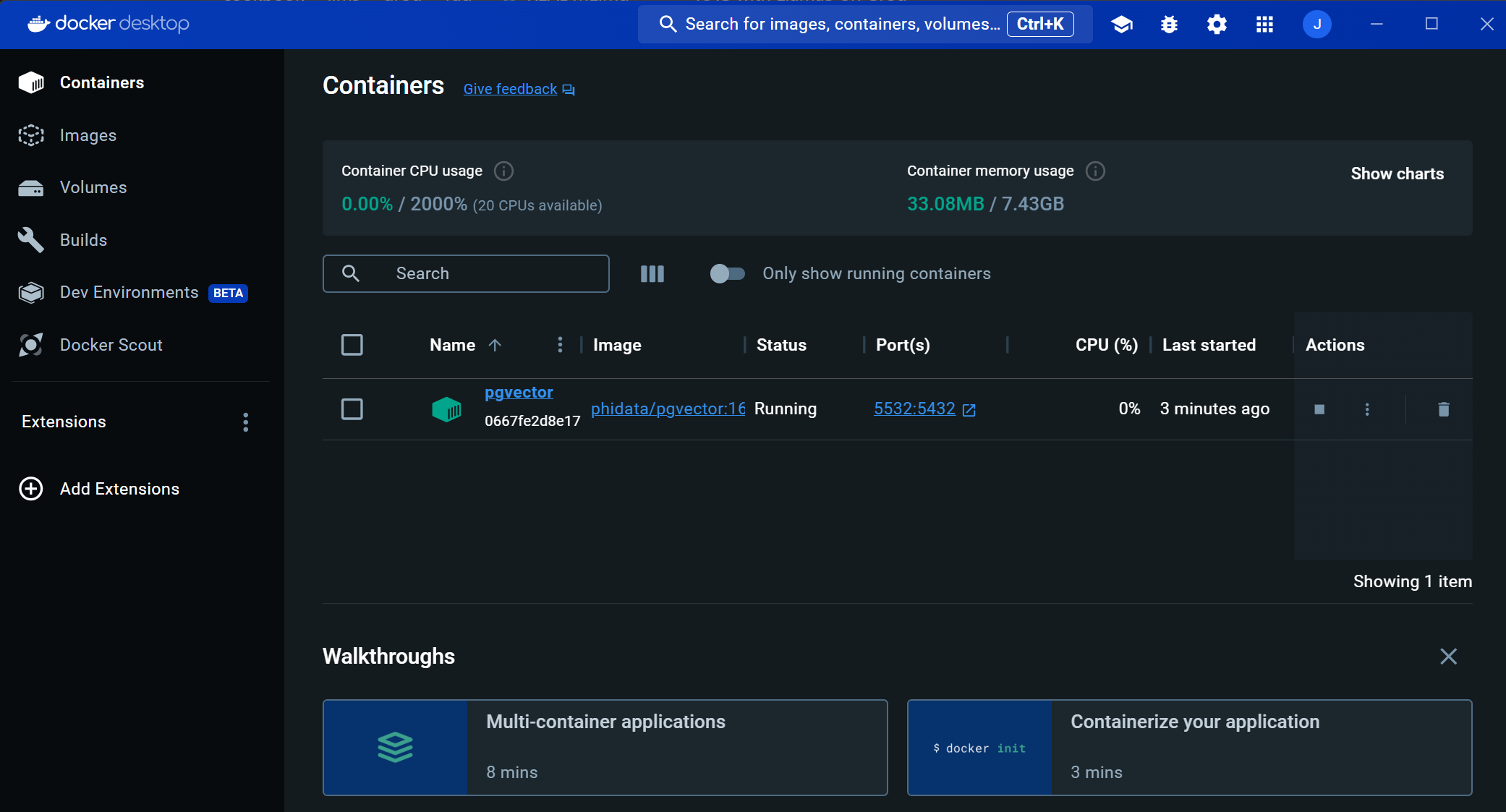
PostgreSQL 데이터베이스가 정상적으로 실행되면 아래 화면과 같이 Docker Desktop에서 벡터 임베딩과 대화기록 등이 저장되는 pgvector 컨테이너가 생성된 것을 확인할 수 있습니다.
코드실행 및 결과
다음은 아래 명령어를 복사하여 메인 코드 Home.py를 실행합니다. 명령을 실행하면 http://localhost:8501/ 주소에서 메인화면이 열리며 브라우저의 번역기능을 이용하시면 다음 화면과 같이 한글로 이용하실 수 있습니다. 하지만 한글로 표시된 상태에서 기능을 실행하지 마시고, 기능이 실행된 다음 한국어로 번역하셔야 에러가 발생하지 않습니다.
streamlit run Home.py
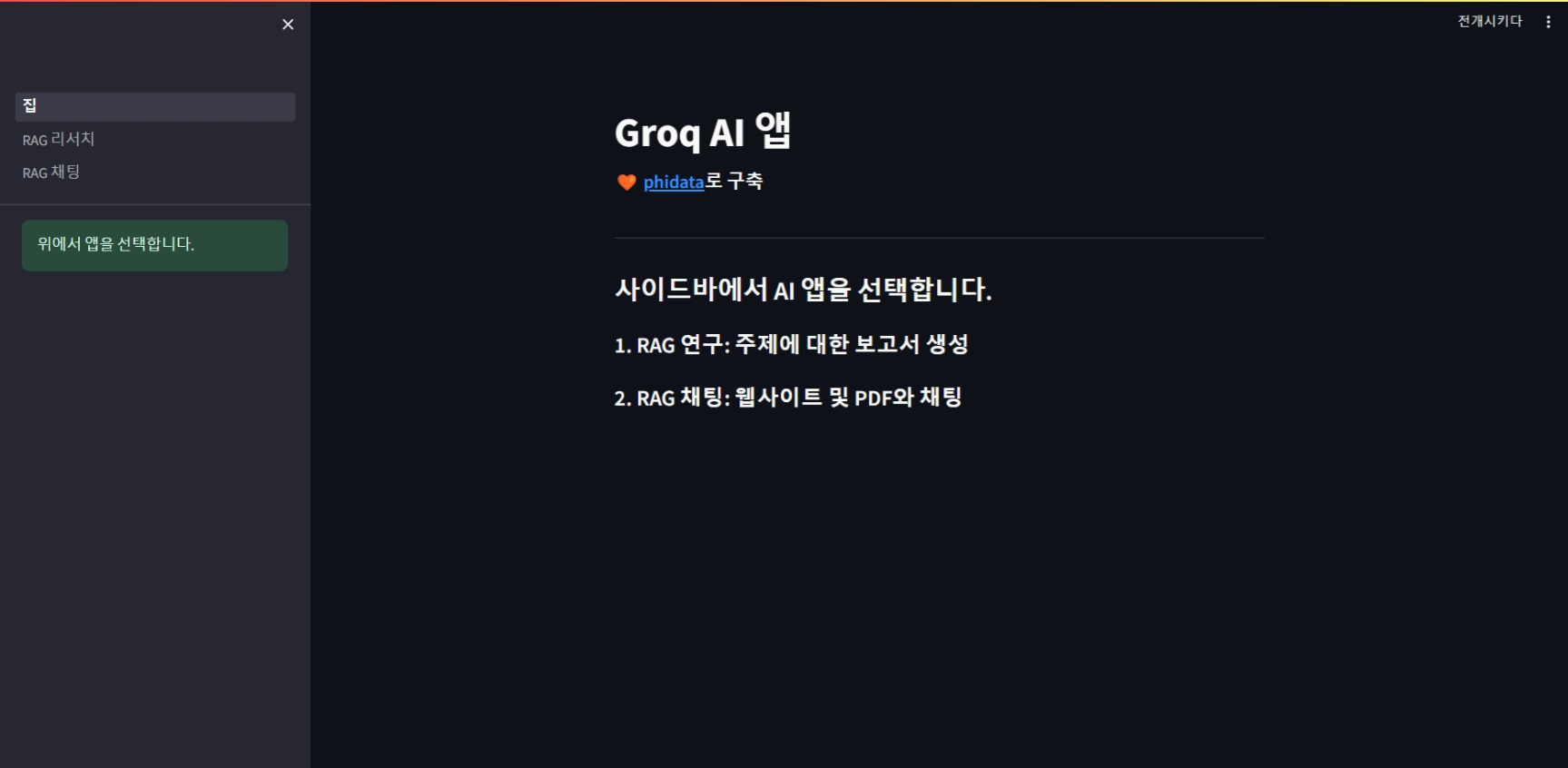
메인 좌측을 보면 RAG Research와 RAG Chat의 선택할 수 있으며, 먼저 RAG Research 기능을 살펴보겠습니다.

URL 입력란에 원하는 URL(https://docs.tavily.com/docs/tavily-api/introduction)을 입력하고, "Add URL" 버튼을 클릭하면 아래 화면과 같이 지식베이스에 정보가 추가되고, 오른쪽 토픽 입력란에 원하는 단어(Tavily Search API)를 작성한 후, "Generate Report" 버튼을 클릭하면 보고서가 생성됩니다.
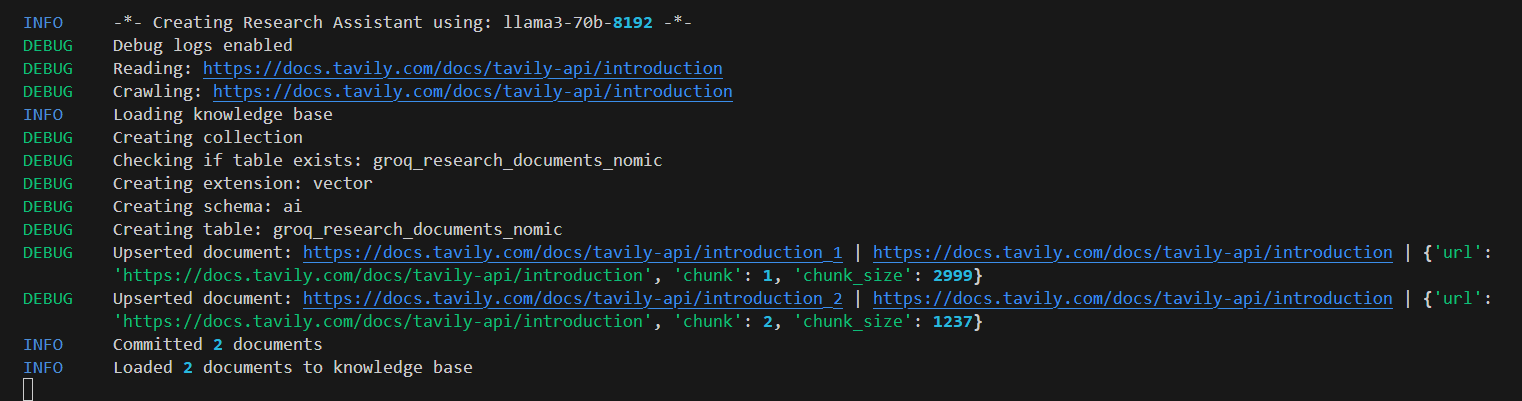
아래 화면은 보고서 생성결과입니다. Tavily 검색 API에 대하여 잘 정리해 주었습니다.
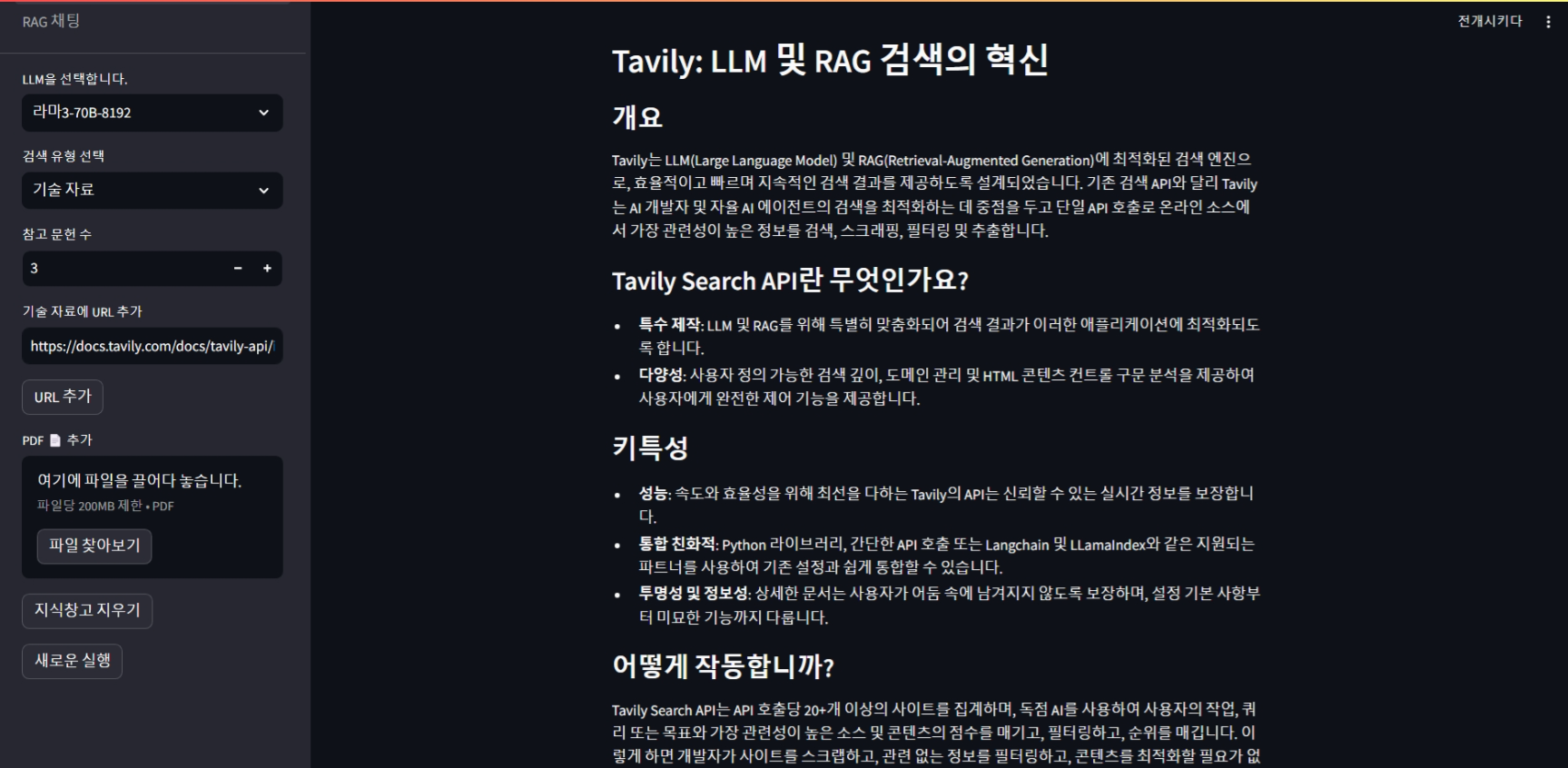

다음 화면은 "OpenELM" 논문 pdf 파일을 입력하고, 토픽에 OpenELM을 입력하여 생성된 보고서입니다.

아래화면은 Tavily 웹 검색을 선택하고 OpenELM 토픽을 입력하여 리포트를 생성한 화면입니다.


아래 화면은 Tavily 웹 검색을 선택하고 2024년 AI에 대한 리포트를 생성한 결과입니다.


URL과 PDF 내용을 기반으로 채팅을 하기 위해서는 화면 좌측 메뉴에서 RAG Chat을 선택하면 됩니다.
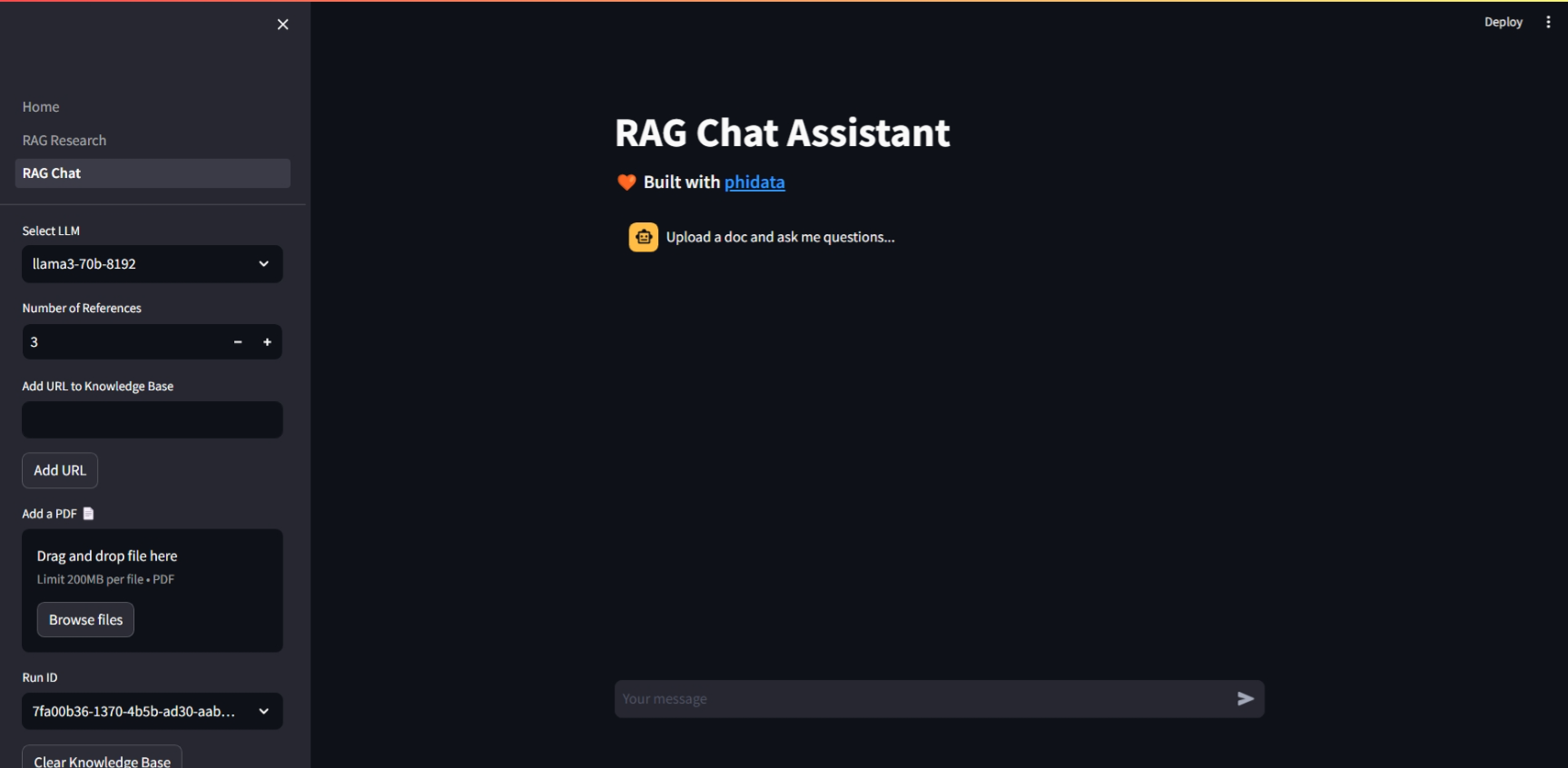
아래 화면은 RAG Chat을 통한 OpenELM 논문 pdf에 대한 질문과 답변화면입니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
맺음말
이 블로그에서는 Phidata와 Groq을 이용하여 LLAMA3 RAG 시스템을 구현하는 방법에 대해 상세히 알아보았습니다. 사용자의 질문에 원클릭 보고서를 작성하고 대화하는 AI 어시스턴트를 만드는 과정에서 Phidata와 Groq, Tavily 웹 검색 API를 이용하여 보고서를 완성해 보았습니다.
블로그를 통해 Phidata, Groq, Tavily와 같은 다양한 AI도구를 활용하시는데 도움이 되었기를 바랍니다. 여러분도 Phidata와 Groq을 이용해서 원하는 보고서를 한번 만들어보시면 어떨까요? 그럼 저는 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.04.22 - [AI 도구] - 🦙Ollama를 활용한 LLAMA3 RAG 시스템 구현하기
🦙Ollama를 활용한 LLAMA3 RAG 시스템 구현하기
안녕하세요! 오늘은 새로운 오픈소스 언어 모델의 최강자 LLAMA 3를 활용한 RAG 시스템을 구현해 보겠습니다. RAG(Retrieval-Augmented Generation, 검색 강화 생성)는 외부 지식소스 검색을 통해 정보를 얻고
fornewchallenge.tistory.com
'AI 도구' 카테고리의 다른 글
| 누구나 할 수 있는 AI 코딩! Llama3와 Claude3로 벽돌깨기 게임 1분 컷! (0) | 2024.05.04 |
|---|---|
| [LLAMA3 활용] ComfyUI 프롬프트 자동 작성 및 유튜브 동영상 요약 10초 완료! (6) | 2024.05.01 |
| 🚀Phidata와 Groq을 활용한 LLAMA3 RAG 시스템 구현하기 (0) | 2024.04.24 |
| 🦙Ollama를 활용한 LLAMA3 RAG 시스템 구현하기 (2) | 2024.04.22 |
| [AI 논문] VASA-1: 마이크로소프트의 초실감 얼굴 생성 기술 (0) | 2024.04.20 |



