안녕하세요! 오늘은 LG AI 연구원에서 공개한 최신 오픈소스 추론 모델, EXAONE-DEEP에 대해 알아보겠습니다. 이번에 공개된 EXAONE Deep 모델은 2.4B, 7.8B, 32B 모델이며, 이 모델들은 EXAONE 3.5를 기반으로 추론 능력에 특화하여 미세 조정(fine-tuning)된 버전입니다. 이 모델들을 최신 학습 기법을 활용하여 학습되었으며, LG AI 연구원이 공개한 평가 결과에서 주요 공개 모델들과 경쟁적인 성능을 보입니다. 이 블로그에서는 EXAONE-DEEP 모델의 특징, 벤치마크 결과와 사용방법에 대해 살펴보겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
1. EXAONE Deep 개요
EXAONE Deep은 LG AI 연구원에서 개발한 추론 능력 강화에 초점을 맞춘 언어 모델 시리즈입니다. 모델의 핵심 사양 및 종류는 다음과 같습니다:
|
모델 이름
|
파라미터 수
|
컨텍스트 길이
|
트랜스포머 레이어
|
|
EXAONE Deep 2.4B
|
24억
|
32,768 토큰
|
30
|
|
EXAONE Deep 7.8B
|
78억
|
32,768 토큰
|
32
|
|
EXAONE Deep 32B
|
320억
|
32,768 토큰
|
64
|
- 기반 모델: EXAONE 3.5 Instruct 모델을 기반으로 합니다. 이 기반 모델들은 명령어 이해 및 수행 능력을 갖추고 있습니다. EXAONE 3.5에 대한 내용은 아래 포스트를 참고하세요
2024.12.10 - [AI 언어 모델] - 🤖EXAONE-3.5: 한국어와 영어를 지원하는 LG의 최신 대규모 언어 모델
🤖EXAONE-3.5: 한국어와 영어를 지원하는 LG의 최신 대규모 언어 모델
안녕하세요! 오늘은 LG AI Research에서 개발한 최신 AI 모델 EXAONE 3.5에 대해 소개해드리겠습니다. EXAONE 3.5는 Instruction-tuned 대규모 언어 모델로, 세 가지 크기로 제공되며, 긴 맥락 이해 능력과 명령
fornewchallenge.tistory.com
- 주요 학습 데이터: 긴 생각 프로세스 스트림을 통합한 추론 특화 데이터셋을 활용하여 학습되었습니다. SFT를 위해 160만 개의 인스턴스(약 120억 개의 토큰 포함), DPO를 위해 2만 개의 선호도 데이터 인스턴스, 그리고 Online RL을 위해 추가적으로 1만 개의 인스턴스가 사용되었습니다.
- 공개 및 라이선스: 모든 EXAONE Deep 모델은 연구 목적으로 공개되어 있으며, 비상업적 연구 목적의 EXAONE AI 모델 라이선스 계약 1.1 - NC에 따라 이용 가능합니다.
2. EXAONE Deep 특징
EXAONE Deep의 특징은 다음과 같습니다.
1) 추론 특화 모델: 긴 thought process (사고 과정)를 포함하는 추론 전문 데이터셋을 중심으로 학습하여 모델이 복잡한 문제에 대한 단계별 사고 능력을 기르도록 설계되었습니다. 확장된 Chain-of-Thought (CoT) 방법론을 통해 모델이 추론을 수행하도록 유도합니다.
2) 학습 방식:
- SFT (Supervised Fine-Tuning): 고품질의 추론 데이터로 모델을 학습시켜 기본적인 추론 능력을 가지며, <thought>와 </thought> 태그 내에서 단계별 논리적 추론, 반성, 자체 검토 및 수정 과정을 수행하도록 학습되었습니다.
- DPO (Direct Preference Optimization): 인간의 선호도 데이터를 활용하여 모델의 답변 품질을 향상시킵니다.
- Online RL (Online Reinforcement Learning): 모델이 실시간으로 상호작용하며 보상을 통해 추론 능력을 최적화합니다. Online RL 학습에는 LG AI 연구원에서 설계한 알고리즘이 사용되었습니다.
3) 학습 환경: Google Cloud Platform 및 NVIDIA NeMo Framework에서 제공하는 NVIDIA H100 GPU 클러스터를 활용하여 모델을 학습했습니다.
3. EXAONE Deep 벤치마크 결과
LG AI 연구원에서 공개한 EXAONE Deep 모델의 벤치마크 결과는 수학, 과학, 코딩, 일반 지식의 네 가지 주요 범주에서 실행되었으며, 주요 벤치마크 결과는 다음과 같습니다.
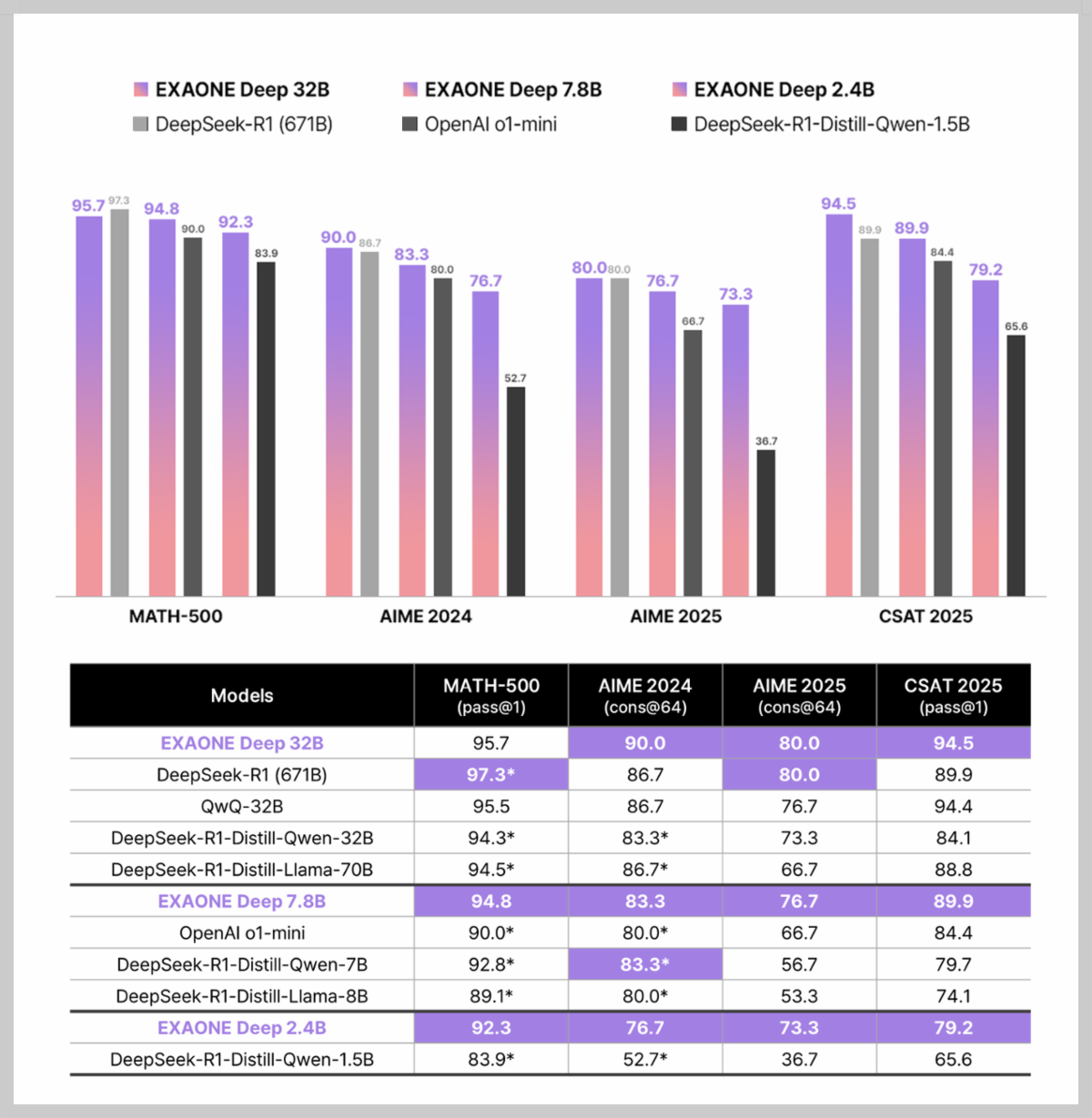
벤치마크 결과에서는 EXAONE Deep 시리즈(32B, 7.8B, 2.4B)가 다양한 분야에서 공개 및 독점 모델들과 경쟁적 성능을 보였습니다. 수학 분야에서는 MATH-500, AIME, CSAT 2025에서 평가되었고, 특히 32B 모델이 DeepSeek-R1-Distill 계열보다 우수했습니다. 7.8B 모델은 OpenAI o1-mini를 능가했으며, 과학(GPQA Diamond), 코딩(LiveCodeBench), 일반 지식(MMLU, MMLU-Pro) 분야에서도 모든 모델이 각 규모에 맞는 경쟁력 있는 성능을 보입니다.
4. EXAONE Deep 사용방법
1) 로컬 다운로드 방법
EXAONE-DeeP 2.4B(1.6GB), 7.8B(4.8GB) 모델은 PC에 다운로드해서 사용해 보실 수 있습니다. 모델은 아래 Ollama.com 링크에서 다운로드하실 수 있습니다.
https://ollama.com/library/exaone-deep
exaone-deep
EXAONE Deep exhibits superior capabilities in various reasoning tasks including math and coding benchmarks, ranging from 2.4B to 32B parameters developed and released by LG AI Research.
ollama.com
모델을 다운로드하면, Open WebUI와 같은 인터페이스를 활용해서 모델을 사용해 보실 수 있습니다.


2) 클라우드 GPU 활용 방법
EXAONE Deep 32B 모델은 클라우드 GPU인 Lightning AI를 통해 허깅페이스에서 EXAONE-Deep-32B-Q4_K_M.gguf를 다운로드하여 streamlit 웹 채팅 인터페이스를 만들어서 사용해 보실 수 있습니다. Lightning AI에서 L40S(48GB) 머신을 사용하시면 아래 코드를 실행해서 EXAONE Deep 32B 모델과 채팅을 하실 수 있습니다
import streamlit as st
from llama_cpp import Llama
# Streamlit app title
st.title("Chat with EXAONE-Deep-32B-GGUF on L40S")
# Initialize the model in session state
if "model" not in st.session_state:
with st.spinner("Loading GGUF model... This may take a few minutes."):
model_path = "/teamspace/studios/this_studio/EXAONE-DEEP/EXAONE-Deep-32B-Q4_K_M.gguf"
st.session_state.model = Llama(
model_path=model_path,
n_gpu_layers=-1, # GPU 전층 사용 (L40S 48GB 활용)
n_ctx=4096, # 컨텍스트 길이 증가
n_threads=8 # CPU 스레드 수
)
st.success("Model loaded successfully!")
# Initialize chat history and continuation flag
if "chat_history" not in st.session_state:
st.session_state.chat_history = []
if "continuation_needed" not in st.session_state:
st.session_state.continuation_needed = False
if "last_prompt" not in st.session_state:
st.session_state.last_prompt = ""
# Function to generate response with context and continuation
def generate_response(prompt, is_continuation=False):
model = st.session_state.model
response = ""
# Continuation이면 이전 응답을 이어서 시작
if is_continuation and st.session_state.chat_history:
response = st.session_state.chat_history[-1]["content"]
else:
# Build context from chat history (최대 3000 토큰 내로 제한)
context = ""
for msg in st.session_state.chat_history[:-1]: # 마지막 사용자 입력 제외
role = "User" if msg["role"] == "user" else "Assistant"
context += f"{role}: {msg['content']}\n"
full_prompt = f"{context}\nUser: 다음 문제를 단계별로 논리적으로 풀고, 최종 답을 명확히 제시해: {prompt}"
# 토큰 초과 방지
if len(full_prompt.split()) > 3000: # 대략적인 토큰 수 체크
st.warning("대화 맥락이 너무 길어 일부만 사용합니다.")
context = context[-2000:] # 최근 2000 단어로 자름
full_prompt = f"{context}\nUser: 다음 문제를 단계별로 논리적으로 풀고, 최종 답을 명확히 제시해: {prompt}"
# Generate response
try:
for chunk in model(full_prompt, max_tokens=2048, temperature=0.6, top_p=0.95, stream=True):
response += chunk["choices"][0]["text"]
yield response
except ValueError as e:
st.error(f"Error: {str(e)}. 컨텍스트를 줄이고 다시 시도하세요.")
return
# 응답이 끝났는지 확인
if len(response.split()) >= 2048:
st.session_state.continuation_needed = True
st.session_state.last_prompt = full_prompt
else:
st.session_state.continuation_needed = False
# Display chat history
for message in st.session_state.chat_history:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Chat input
user_input = st.chat_input("Type your message here...")
if user_input:
st.session_state.chat_history.append({"role": "user", "content": user_input})
with st.chat_message("user"):
st.markdown(user_input)
with st.chat_message("assistant"):
with st.spinner("Generating response..."):
response_placeholder = st.empty()
full_response = ""
for text in generate_response(user_input):
full_response = text
response_placeholder.markdown(full_response)
st.session_state.chat_history.append({"role": "assistant", "content": full_response})
# Continue if response was truncated
if st.session_state.continuation_needed:
with st.chat_message("assistant"):
with st.spinner("Continuing response..."):
response_placeholder = st.empty()
full_response = st.session_state.chat_history[-1]["content"]
for text in generate_response(st.session_state.last_prompt, is_continuation=True):
full_response = text
response_placeholder.markdown(full_response)
st.session_state.chat_history[-1]["content"] = full_response
# Clear chat history button
if st.button("Clear Chat History"):
st.session_state.chat_history = []
st.session_state.continuation_needed = False
st.session_state.last_prompt = ""
st.rerun()# GGUF 다운로드
wget https://huggingface.co/LGAI-EXAONE/EXAONE-Deep-32B-GGUF/resolve/main/EXAONE-Deep-32B-Q4_K_M.gguf
# 종속성 설치
pip install streamlit llama-cpp-python --extra-index-url https://jllllll.github.io/llama-cpp-python-cuBLAS-wheels/AVX2/cu121 --force-reinstall
# App실행
streamlit run app.py

블로그 자체 성능테스트 결과 생략: 안타깝지만 EXAONE Deep 7.8B, 32B 모델은 제가 테스트한 결과, 매우 긴 추론 과정은 문제의 맥락에 부합하지 않았고, 논리적으로 오류가 많았습니다. 또한, 추론 과정에서 엉뚱한 변수를 도입하여 문제를 왜곡하거나 원래 조건을 반영하지 않았으며, 반복적인 문장으로 핵심을 파악하기 어려웠습니다. 그로 인해 최종 답변이 문제의 요구 사항을 충족하지 못한 경우가 많았고, 다른 모델들과 동일한 방식으로 성능 테스트를 진행할 수 없었습니다. 따라서 EXAONE Deep 모델에 대한 블로그 자체 성능 테스트 결과는 생략하도록 하겠습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
5. 맺음말
이번 블로그에서는 LG AI 연구원에서 공개한 EXAONE Deep 모델의 특성과 성능을 살펴보았습니다. 추론에 특화된 EXAONE Deep 모델은 연구 목적으로 공개되어 연구자들이나 개발자들이 손쉽게 활용할 수 있도록 다양한 사용 방법을 제공하고 있으며, 클라우드 GPU나 로컬 환경에서 손쉽게 모델을 다운로드하고 사용할 수 있습니다.
하지만, EXAONE Deep 시리즈는 공개된 벤치마크 결과와 달리 실제 테스트에서는 긴 추론 과정에서의 오류나 논리적 불일치, 문제 왜곡, 무관한 문장의 반복 등으로 정상적인 테스트가 어려웠습니다. 앞으로 EXAONE Deep 모델의 성능이 지속적으로 개선되어, 우리나라의 언어 모델이 세계적인 수준으로 발전하기를 기대하면서 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다!

2024.08.11 - [AI 언어 모델] - 🚀EXAONE 3.0 7.8B 리뷰: LG AI 연구소의 혁신적인 언어 모델
🚀EXAONE 3.0 7.8B 리뷰: LG AI 연구소의 혁신적인 언어 모델
안녕하세요! 오늘은 LG AI 연구소에서 개발한 최첨단 대형 언어 모델, EXAONE 3.0에 대해 알아보겠습니다. EXAONE은 "EXpert AI for EveryONE"이라는 비전을 가지고 인공지능 기술을 통해 전문가 수준의 능력
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 🐳 DeepSeek V3-0324 공개! 오픈소스 LLM의 새로운 강자 등장 (8) | 2025.03.25 |
|---|---|
| 🏯🧠Hunyuan-T1: GPT 4.5 뛰어넘은 세계 최초 Hybrid-Transformer-Mamba MoE 모델 (8) | 2025.03.23 |
| 🤖✨ Gemma 3 모델 심층 분석: 구글의 차세대 개방형 멀티모달 AI (2) | 2025.03.15 |
| 🤖MS의 첫 멀티모달 AI, Phi-4-multimodal과 Phi-4-mini-3.8B 분석 (4) | 2025.03.09 |
| 🎯QwQ-32B: 20배 작은 모델로 DeepSeek-R1 따라잡은 강화 학습 모델 (10) | 2025.03.08 |



