안녕하세요! 오늘은 최근 발표된 오픈소스 텍스트 임베딩 모델 "노믹 임베드(Nomic Embed)"에 대해서 알아보겠습니다. 노믹 임베드는 텍스트 임베딩에 대한 새로운 접근 방식을 통해 긴 문맥에서 텍스트를 효과적으로 임베딩하고 새로운 아키텍처와 학습 전략을 도입하여 성능을 향상시킨 텍스트 임베딩 모델입니다. 이 블로그에서는 노믹 임베드의 특징, 구성요소, 동작원리에 대해 알아보고, Ollama와 노믹 임베드를 활용한 URL 문서검색 DEMO를 실행해 보겠습니다.
https://www.aitimes.com/news/articleView.html?idxno=157299
노믹 AI, 오픈AI 뛰어넘는 오픈 소스 최장 컨텍스트 임베딩 모델 출시 - AI타임스
현존 최고인 오픈AI의 ‘텍스트-임베딩-에이다-002(text-embedding-ada-002)’보다 성능이 뛰어나다는 오픈 소스 텍스트 임베딩 모델이 등장했다. 이를 통해 오픈 소스 대형언어모델(LLM)도 성능을 끌어
www.aitimes.com
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
노믹 임베드란?
노믹 임베드는 텍스트를 임베딩하는 모델로, 각 단어나 문장을 벡터로 변환합니다. 이러한 벡터는 텍스트의 다양한 특성을 나타내며, 예를 들어 단어의 의미, 문맥, 유사성 등을 포착할 수 있습니다. 이 모델은 64부터 768까지의 가변적인 임베딩 차원을 지원하며, 사용자는 자신의 요구에 맞게 적절한 차원을 선택할 수 있습니다. 노믹 임베드는 메모리, 저장 공간, 대역폭 요구 사항을 고려하여 개발되었으며, Flash Attention, Deepspeed를 통해 성능과 효율성을 극대화할 수 있습니다. 이 모델은 자연어 처리 작업에서 텍스트 데이터를 효과적으로 처리하고 이해하는 데에 사용됩니다.
노믹 임베드 특징
노믹 임베드는 8,192 토큰의 긴 문맥을 다룰 수 있는 능력을 갖추고 있습니다. 이 모델은 텍스트 문서나 문장을 저차원 벡터로 변환하여 의미론적 정보를 보존하는 데 사용됩니다. 노믹 임베드는 다음과 같은 특징을 갖추고 있습니다.
- 긴 문맥 처리: 노믹 임베드는 회전 위치 임베딩을 도입함으로써 입력 시퀀스의 길이에 상관없이 모델이 문맥을 파악할 수 있도록 하여, 긴 텍스트 문맥을 처리하는 능력을 가지고 있습니다. 이는 긴 문서나 대화에서 의미 있는 정보를 추출하는 데 유용합니다.
- 가변적인 임베딩 차원: 마트료시카 표현 학습(Matryoshka Representation Learning) 기법을 사용하여 임베딩 차원을 가변적으로 다양화함으로써 모델은 더 많은 정보를 포착하고 다양한 특성을 표현할 수 있습니다.
- 오픈소스: 노믹 임베드는 오픈소스로 제공되며, 누구나 모델의 구현과 성능을 검증할 수 있습니다.
- 효율성과 확장성: 모든 입력 토큰 간의 상호작용을 계산하는 대신 노믹 임베드는 일부 토큰 간의 상호작용만을 계산하는 Flash Attention을 적용하여 계산 비용을 크게 절약할 수 있습니다. 또한 딥러닝 모델 훈련을 가속화 오픈소스 라이브러리, Deepspeed를 통해 모델의 학습 속도와 효율성을 향상시킵니다.
다음은 노믹 임베드와 일반적인 텍스트 임베딩 모델의 비교표입니다.
| 특징 | 노믹 임베드 | 일반적인 텍스트 임베딩 모델 |
| 문맥 길이 | 8192 토큰 | 주로 512 토큰 이하 |
| 임베딩 차원 | 64~768차원, 가변적으로 조정 가능 | 고정된 차원 |
| 긴 문맥 처리 능력 | 뛰어남 | 제한적 |
| 마트료시카 표현 학습 | 사용 | 사용 안 함 |
| 특정 작업에 대한 최적화 여부 | 가능 | 일반적으로 가능하지 않음 |
| 모델 크기 및 복잡성 | 대체로 크고 복잡함 | 다양함 |
노믹 임베드 구성 요소와 동작 원리
노믹 임베드의 주요 구성요소와 동작원리는 다음과 같습니다:
- Transformer 아키텍처: 노믹 임베드는 Transformer 아키텍처를 기반으로 합니다. Transformer는 기계 학습 모델 중 하나로, 특히 자연어 처리 작업에 매우 효과적입니다. 이 아키텍처는 self-attention 메커니즘을 사용하여 문맥을 파악하고 텍스트를 처리합니다.
- 사전 학습된 언어 모델: 노믹 임베드는 사전에 다양한 웹 사이트, 책, 뉴스 기사, 논문, 블로그 게시물 등에서 수집된 대규모 텍스트 코퍼스(corpus)를 사용하여 사전 학습된 언어 모델을 초기화합니다. 이 모델은 일반적인 언어 이해를 위해 텍스트 데이터의 패턴을 학습한 후, 이를 다양한 응용 프로그램에 적용할 수 있도록 합니다.
- 마스킹된 언어 모델 학습: 모델은 주어진 문장에서 일부 토큰을 숨기고 숨겨진 토큰을 예측하는 마스킹된 언어 모델 학습을 수행합니다. 이를 통해 모델은 문장의 문맥을 이해하고 다음 단어를 예측하는 능력을 향상시킵니다.
- 비지도 대조 사전 학습(Unsupervised Contrastive Pretraining): 모델은 대규모의 비지도 대조 사전 학습을 수행하여 문장의 의미를 파악하는 능력을 향상시킵니다. 이 단계에서 모델은 주어진 텍스트 데이터셋에서 유사한 문장 쌍을 찾고 이를 대조하여 문장의 의미를 더 잘 이해하도록 학습됩니다.
- 지도 대조 세밀 조정(Supervised Contrastive Fine-tuning): 마지막으로, 모델은 지도 대조 세밀 조정을 통해 특정 응용 프로그램에 맞게 조정됩니다. 이 단계에서는 레이블이 지정된 데이터셋을 사용하여 모델을 미세하게 조정하여 원하는 작업에 최적화된 모델을 만듭니다.
이러한 구성 요소들이 모여 노믹 임베드 모델을 형성하며, 텍스트의 의미를 효과적으로 파악하고 표현할 수 있는 강력한 텍스트 임베딩 기능을 제공합니다. 다음은 Nomic Embed의 동작원리에 대한 설명입니다.
- 2048 토큰 문맥길이 BERT 학습: 노믹 임베드는 2018년에 공개된 자연어 처리 사전 학습 모델, BERT 아키텍처를 기반으로 합니다. 일반적인 BERT 모델은 입력 시퀀스의 최대 길이가 512 토큰으로 제한되어 있지만 Nomic Embed는 더 긴 시퀀스를 처리하기 위해 2048 토큰의 문맥 길이를 갖는 BERT 모델인 nomic-bert-2048를 학습합니다.
- 회전 위치 임베딩 사용: 노믹 임베드는 입력 시퀀스의 위치정보를 나타낼 때, 절대적인 위치 임베딩 대신에 위치 정보를 회전시키는 회전 위치 임베딩을 사용하여 입력 시퀀스의 길이에 관계없이 더 긴 시퀀스를 처리할 수 있습니다. 이를 통해 모델은 8,192 토큰까지 더 긴 문맥을 처리할 수 있습니다.
- SwiGLU 활성화 함수 사용: 기존에 많은 딥러닝 모델에서 사용되는 GeLU(Gaussian Error Linear Unit) 활성화 함수 대신 SwiGLU(Switched Gated Linear Unit)를 사용하여 다양한 작업에 대해 더 나은 모델 성능을 제공합니다. 활성화 함수(Activation Function)는 인공 신경망에서 각 뉴런의 출력을 결정하는 함수입니다.
- 학습 최적화 및 최적화 기술 적용: 노믹 임베드는 Deepspeed 및 FlashAttention과 같은 학습 최적화 기술을 사용하여 모델을 효율적으로 학습합니다. 또한 16비트 정밀도 부동 소수점 표현방식을 사용하여 학습을 가속화하고 메모리 사용을 줄입니다. 또한 배치 크기를 크게 하여 학습 속도를 높입니다.
- 어휘 크기 증가: 모델의 어휘 크기를 64의 배수로 증가시킴으로써 모델의 표현력을 향상시킵니다.
이러한 변경 사항을 통해 노믹 임베드는 훨씬 더 긴 문맥을 처리할 수 있으며, 따라서 더 많은 정보를 고려하여 자연어 처리 작업을 수행할 수 있습니다.
마트료시카(Matryoshka) 표현 학습
또한 노믹 임베드는 "마트료시카 표현 학습"을 구현한 텍스트 임베딩 모델로 볼 수 있습니다. 이 모델은 다양한 크기와 복잡성의 임베딩을 생성하여 텍스트 데이터를 효과적으로 표현하고, 다양한 자연어 처리 작업에 적용할 수 있습니다.
"마트료시카 표현 학습"은 텍스트나 이미지 등의 데이터를 임베딩하는 데 사용되는 기술입니다. 이 기술은 다양한 크기와 복잡성의 임베딩을 생성할 수 있도록 모델을 설계하는 것을 목표로 합니다. 기존의 임베딩 기법은 보통 고정된 차원의 벡터를 생성합니다. 예를 들어, 텍스트를 처리하는 모델에서는 주어진 단어나 문장을 고정된 크기의 벡터로 표현합니다. 이러한 방식은 특정 작업에는 유용할 수 있지만, 모든 데이터에 적용하기에는 제약이 있습니다.
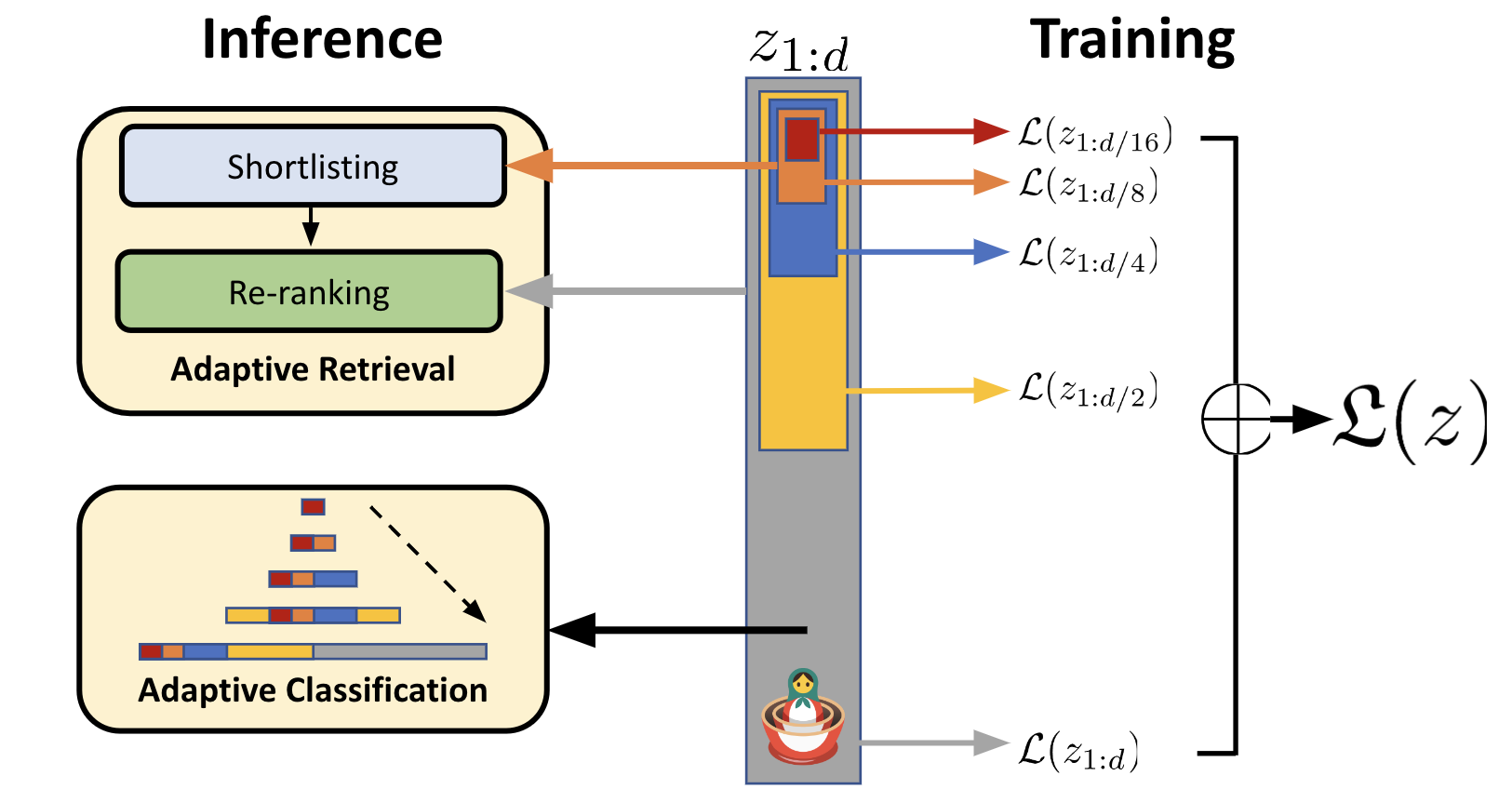
"마트료시카 표현 학습"은 이러한 제약을 극복하기 위해 개발되었습니다. 이 기술은 모델이 여러 단계의 임베딩을 생성하도록 허용합니다. 즉, 가장 바깥쪽에는 큰 차원의 임베딩이 있고, 그 안에는 이보다 작은 차원의 임베딩이 들어 있습니다. 이러한 구조는 마치 러시아의 전통적인 "마트료시카" 인형처럼 겹겹이 쌓인 모양을 가지고 있어서 이러한 이름이 붙여졌습니다. 이러한 다단계 임베딩 구조를 사용하면 모델이 데이터의 다양한 측면을 캡처할 수 있습니다.
예를 들어, 가장 바깥쪽에 있는 큰 차원의 임베딩은 전체적인 데이터의 특성을 나타내고, 내부에 있는 작은 차원의 임베딩은 세부적인 특성을 나타냅니다. 이를 통해 모델은 데이터의 다양한 측면을 포착하고, 다양한 작업에 적용될 수 있는 범용적인 임베딩을 생성할 수 있습니다.
종합하면, "마트료시카 표현 학습"은 다양한 크기와 복잡성의 임베딩을 생성하기 위해 다단계 임베딩 구조를 사용하는 기술입니다. 이를 통해 모델은 데이터의 다양한 측면을 포착하고, 범용적인 임베딩을 생성할 수 있습니다.
노믹 임베드 성능평가 결과
아래 표는 노믹 임베드와 다른 모델을 성능비교한 결과입니다.
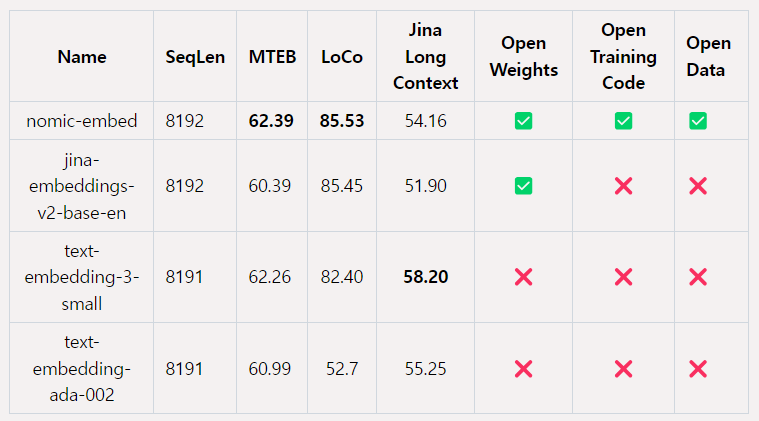
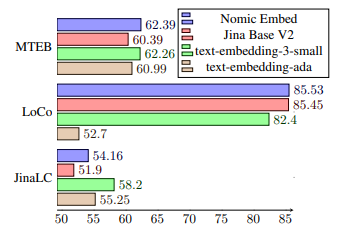
위 표는 노믹 임베드가 대규모 텍스트 임베딩 모델의 성능을 평가하는 벤치마크인 대규모 텍스트 임베딩 벤치마크인 Massive Text Embedding Benchmark(MTEB)에서 OpenAI의 text-embedding-ada-002 및 jina-embeddings-v2-base-en 모델보다 성능이 우수하다는 것을 나타냅니다.
또한, LoCo(Long Context) 벤치마크에서 노믹 임베드는 100M 파라미터 클래스의 비지도 학습 모델 중에서 성능이 가장 우수한 모델로 나타났습니다. 또한, 7B 파라미터 클래스 및 LoCo 벤치마크를 위해 특별히 학습된 지도 학습 모델과 경쟁력 있는 성능을 보여주고 있습니다. Jina 장문맥 벤치마크에서는 노믹 임베드가 jina-embeddings-v2-base-en 모델보다 종합적으로 우수한 성능을 보여줍니다. 그러나 이 벤치마크에서 OpenAI ada-002 또는 text-embedding-3-small을 능가하지 못했습니다.
노믹 임베드는 최신 텍스트 임베딩 기술로, 기존 모델들을 뛰어넘는 성능을 보입니다. 이 모델은 장문 텍스트를 포함한 긴 문맥을 처리하는데 특히 효과적입니다. 여러 실험 및 벤치마크 결과에 따르면 노믹 임베드는 다음과 같은 성능을 보입니다:
- 텍스트 임베딩 품질: 노믹 임베드는 텍스트를 의미론적으로 잘 이해하고, 이를 저차원 벡터로 효과적으로 표현합니다. 이는 다양한 자연어 처리 작업에서 뛰어난 성능을 보이는 데 기여합니다.
- 장문 문맥 처리: 기존 모델들과 비교하여 노믹 임베드는 더 긴 문맥을 처리할 수 있습니다. 이는 긴 문서나 긴 대화와 같은 실제 응용 프로그램에서 더 나은 이해와 결과를 도출하는 데 도움이 됩니다.
- 비교적 낮은 요구 사항: 노믹 임베드는 뛰어난 성능을 발휘하면서도 상대적으로 적은 계산 자원을 필요로 합니다. 이는 실제 환경에서 모델을 배포하고 사용할 때 효율적인 선택으로 작용합니다.
- 오픈소스 및 검증 가능성: 노믹 임베드는 오픈소스로 제공되며, 훈련 데이터와 코드를 공개함으로써 검증 가능합니다. 이는 모델의 투명성과 안전한 사용을 보장하는 데 중요한 역할을 합니다.
- 여러 벤치마크에서 우수한 성능: 다양한 벤치마크와 실험에서 노믹 임베드는 다른 유사한 모델들보다 우수한 성능을 보이고 있습니다. 특히, OpenAI의 text-embedding-ada와 text-embedding-3-small, 그리고 jina-embedding-base-v2와 비교하여 더 나은 결과를 도출합니다.
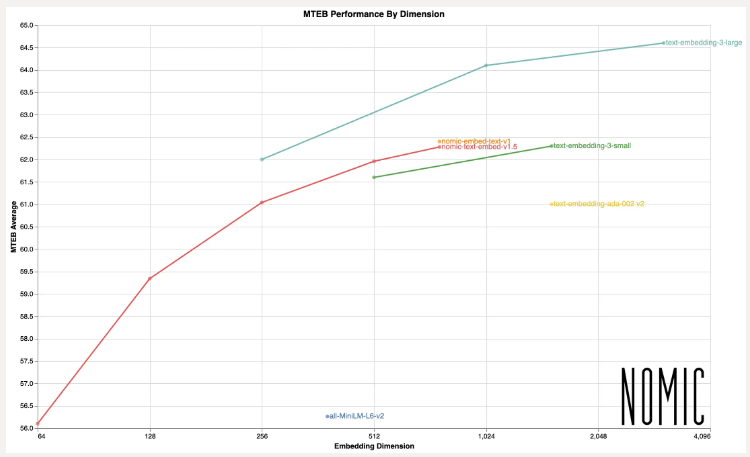
요약하면, 노믹 임베드는 최신 텍스트 임베딩 기술로서 뛰어난 텍스트 이해 및 처리 능력을 갖추고 있으며, 다양한 실제 응용 분야에서 효과적으로 활용될 수 있는 모델입니다.
https://blog.nomic.ai/posts/nomic-embed-matryoshka
Unboxing Nomic Embed v1.5: Resizable Production Embeddings with Matryoshka Representation Learning
Nomic introduces a truly open text embedding model with resizable embeddings.
blog.nomic.ai
노믹 임베드 DEMO
다음은 노믹 엠베드의 기능을 체험해 보기 위한 파이썬 DEMO 코드를 실행해 보겠습니다.
환경설정 및 모델 설치
먼저 파이썬 가상환경이 활성화된 윈도우 명령어 프롬프트 상에서 아래 화면과 같이 "ollama pull nomic-embed-txt" 명령을 실행하여 노믹 임베드 모델을 다운로드합니다. ollama의 윈도우 버전 설치는 아래 링크를 참고하시면 됩니다.
2024.02.21 - [AI 도구] - 💥핵꿀팁! 스마트폰에서 Ollama WebUI를 만나는 방법 (ngrok 활용)
다음은 DEMO 파이썬 코드 실행에 필요한 라이브러리 설치입니다. 아래 코드를 복사하여 requirements.txt로 저장하고 가상환경이 활성화된 상태에서 "pip install -r requirements.txt" 명령어로 라이브러리를 설치합니다.
langchain
langchain-community
langchain-core
beautifulsoup4
gradio
tiktoken
chromadb
위 명령어로 설치되는 라이브러리에 대한 용도는 다음과 같습니다.
| 라이브러리 | 용도 |
| langchain | 자연어 처리 작업에 다양한 기능을 제공하는 핵심 라이브러리입니다. |
| langchain-community | langchain 라이브러리의 커뮤니티 기반 확장판으로, 추가적인 기능과 모델을 제공합니다. |
| langchain-core | langchain 라이브러리의 핵심 구성 요소로, 실행 가능한 구성 요소, 출력 파서 및 프롬프트 등이 포함되어 있습니다. |
| beautifulsoup4 | 웹 스크래핑 및 HTML/XML 문서 파싱을 위한 라이브러리입니다. |
| gradio | 머신러닝 모델을 위한 사용자 인터페이스(UI)를 생성하기 위한 라이브러리로, 모델을 쉽게 접근하고 상호 작용할 수 있도록 합니다. |
| tiktoken | 텍스트 데이터의 토큰화 및 토큰 수 계산을 위한 라이브러리입니다. |
| chromadb | 임베딩을 기반으로 문서를 인덱싱하고 검색하기 위한 벡터 스토어(ChromaDB)를 생성하고 관리하는 라이브러리입니다 |
파이썬 코드 설명 및 실행결과
이 코드의 출처는 유튜브 "Ollama Embedding: How to Feed Data to AI for Better Response?"이며, Gradio를 사용하여 웹에서 가져온 문서를 쿼리 하는 간단한 인터페이스를 생성합니다. 이 인터페이스를 통해 사용자는 URL 목록과 질문을 입력하고, 해당 문서에 대한 답변을 얻을 수 있습니다.
- 1. `process_input` 함수: 이 함수는 Gradio 인터페이스의 입력을 처리하고, 문서를 쿼리 하고, 사용자의 질문에 답변을 반환합니다. `urls` 매개변수는 사용자가 입력한 URL 목록을 포함하고, `question` 매개변수는 사용자가 입력한 질문을 포함합니다. `ChatOllama`을 사용하여 모델을 초기화하고, `mistral` 모델을 기반으로 합니다. URL 목록에서 각 URL을 가져와 `WebBaseLoader`를 사용하여 웹에서 문서를 로드하고, `CharacterTextSplitter`를 사용하여 문서를 적절한 크기의 청크로 분할합니다. `Chroma.from_documents`를 사용하여 문서의 벡터 표현을 생성하며, 이때 Ollama에서 불러온 `Nomic Embed ` 모델을 사용하여 문서를 임베딩합니다. 다음 문서 검색을 위한 retriever를 설정하고, 사용자의 질문에 대한 적절한 응답을 생성하기 위해 모델과 함께 사용되는 체인을 설정합니다.
- 2. Gradio 인터페이스 생성: `gr.Interface`를 사용하여 Gradio 인터페이스를 설정합니다. 입력은 두 개의 텍스트 상자로 구성됨, 하나는 URL을 입력하고, 다른 하나는 질문을 입력합니다. 출력은 텍스트 형식으로 설정되어 있으며, 제목과 설명도 포함되어 있습니다.
- 3. Gradio 인터페이스 실행: `iface.launch()`는 Gradio 인터페이스를 시작하여 사용자가 인터페이스를 사용할 수 있도록 합니다.
import gradio as gr
from langchain_community.document_loaders import WebBaseLoader, PyPDFLoader
from langchain_community.vectorstores import Chroma
from langchain_community import embeddings
from langchain_community.chat_models import ChatOllama
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain.output_parsers import PydanticOutputParser
from langchain.text_splitter import CharacterTextSplitter
def process_input(urls, question):
model_local = ChatOllama(model="mistral")
# Convert string of URLs to list
urls_list = urls.split("\n")
docs = [WebBaseLoader(url).load() for url in urls_list]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=7500, chunk_overlap=100)
doc_splits = text_splitter.split_documents(docs_list)
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=embeddings.ollama.OllamaEmbeddings(model='nomic-embed-text'),
)
retriever = vectorstore.as_retriever()
after_rag_template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
after_rag_prompt = ChatPromptTemplate.from_template(after_rag_template)
after_rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| after_rag_prompt
| model_local
| StrOutputParser()
)
return after_rag_chain.invoke(question)
# Define Gradio interface
iface = gr.Interface(fn=process_input,
inputs=[gr.Textbox(label="Enter URLs separated by new lines"), gr.Textbox(label="Question")],
outputs="text",
title="Document Query with Ollama",
description="Enter URLs and a question to query the documents.")
iface.launch()
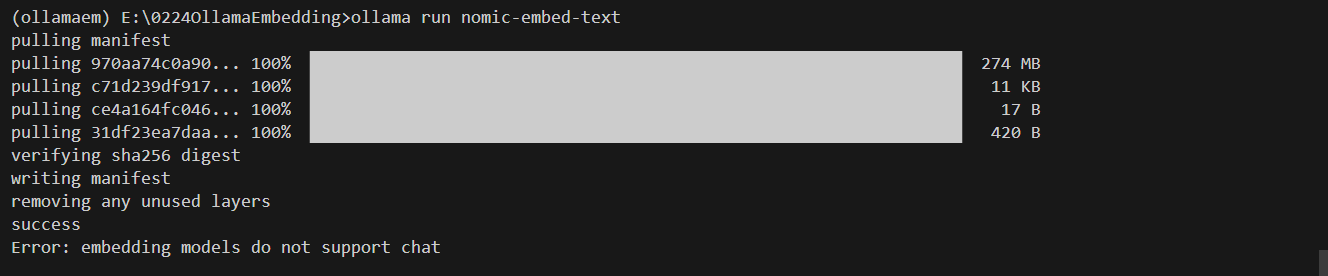
위 코드의 실행결과는 다음과 같습니다. 코드 실행 중에 "AttributeError: 'Textbox' object has no attribute 'is_rendered'"와 같은 에러가 발생하면 "ollama rm nomic-embed-text"로 모델을 삭제한 후, "ollama pull nomic-embed-text" 명령으로 모델을 다시 설치하면 에러가 해소됩니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
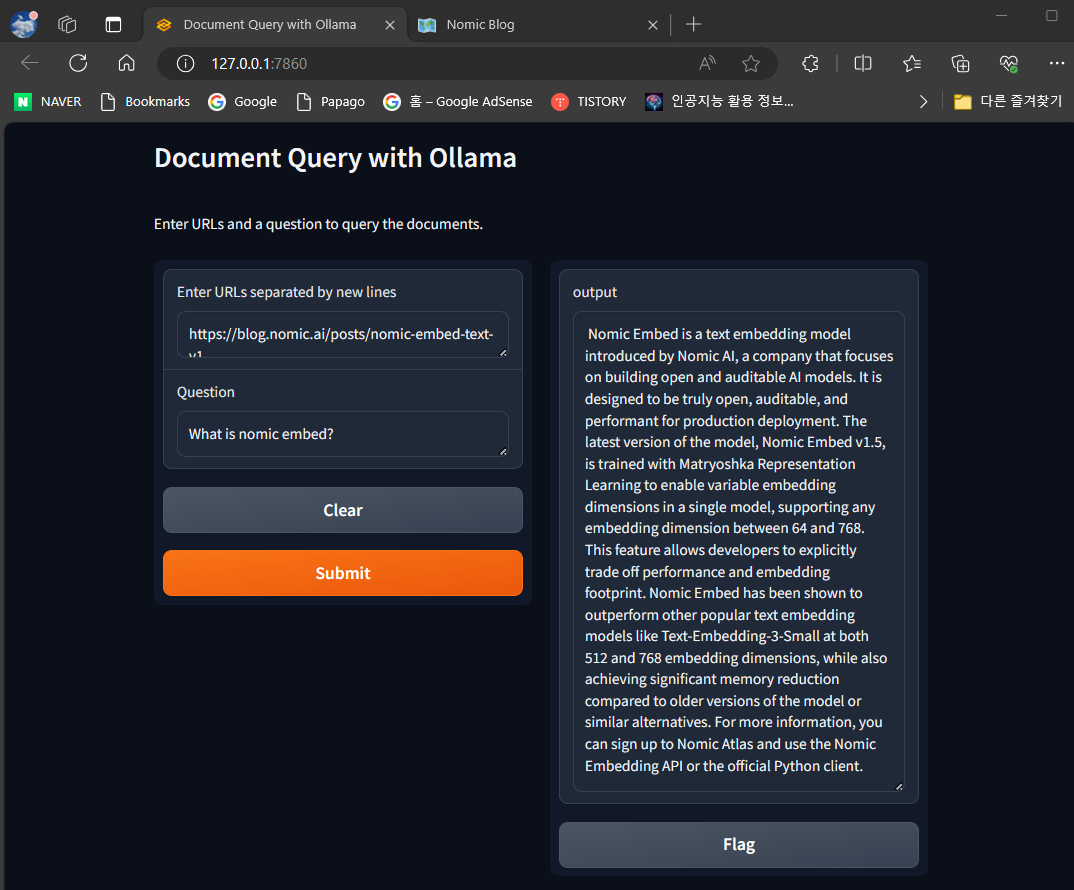
질문:Nomic Embed가 뭐야?
응답:Nomic Embed은 Nomic AI가 소개한 텍스트 임베딩 모델입니다. Nomic AI는 개방적이고 감사(auditable)
가능한 AI 모델을 구축하는 데 중점을 두는 회사입니다. 이 모델은 실제로 개방적이고 감사 가능하며 제작 환경에
대한 성능을 목표로 설계되었습니다. 최신 버전인 Nomic Embed v1.5는 Matryoshka Representation
Learning으로 훈련되어 단일 모델에서 가변적인 임베딩 차원을 가능하게 합니다. 이는 64에서 768 사이의
임베딩 차원을 지원합니다. 이 기능을 통해 개발자들은 성능과 임베딩 풋프린트를 명시적으로 교환할 수
있습니다. Nomic Embed은 512 및 768 임베딩 차원에서 Text-Embedding-3-Small과 같은 인기있는 텍스트
임베딩 모델보다 우수한 성능을 보여주었으며, 또한 이전 버전의 모델이나 유사한 대안들과 비교하여 상당한
메모리 절감을 달성했습니다. 자세한 정보는 Nomic Atlas에 가입하여 Nomic Embedding API 또는 공식 Python
클라이언트를 사용하실 수 있습니다.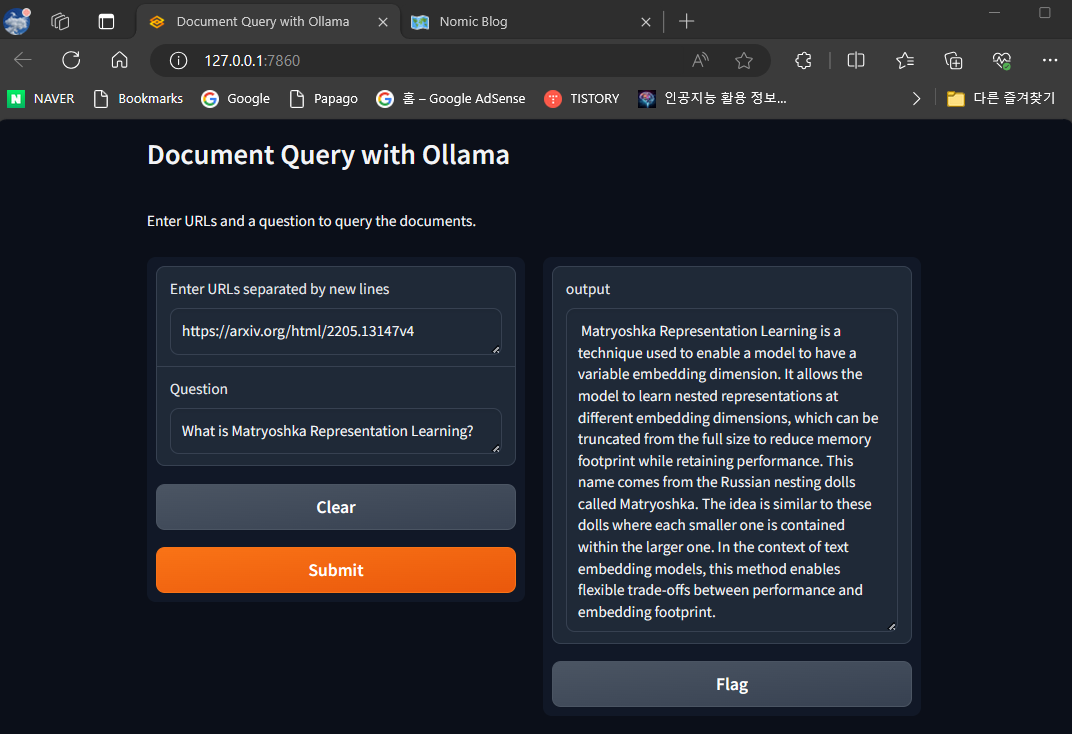
질문 : 마트료시카 표현 학습이 뭐야?
응답 : 마트료시카 표현 학습은 모델이 가변적인 임베딩 차원을 가질 수 있도록 하는 기술입니다.
이 기술은 모델이 서로 다른 임베딩 차원에서 중첩된 표현을 학습할 수 있도록하여 전체 크기에서 잘라내어
메모리 사용량을 줄이면서 성능을 유지할 수 있습니다. 이 이름은 마트료시카라고 불리는 러시아 인형에서
옵니다. 이 아이디어는 각각의 작은 인형이 더 큰 인형 안에 포함되어 있는 것과 비슷합니다.
텍스트 임베딩 모델의 맥락에서 이 방법은 성능과 임베딩 풋프린트 간의 유연한 교환을 가능하게 합니다.

마치며
오늘은 최근 발표된 오픈 소스 텍스트 임베딩 모델 "노믹 임베드"에 대해 알아보았습니다. 노믹 임베드는 긴 문맥 처리, 가변적인 임베딩 차원, 효율성과 확장성, 마트료시카 표현 학습 등의 특징을 갖춘 강력한 텍스트 임베딩 모델입니다. 또한, 노믹 임베드의 성능 평가 결과와 Ollama를 활용한 URL 문서 검색 DEMO를 통해 노믹 임베드의 실제 활용 가능성을 확인했습니다.
오늘의 블로그가 텍스트 임베딩 기술에 대한 이해를 높이는데 도움이 되었기를 바라면서 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2024.02.16 - [대규모 언어모델] - 벡터 데이터베이스와 Llama2를 활용한 arXiv 논문 자동검색 및 분석
벡터 데이터베이스와 Llama2를 활용한 arXiv 논문 자동검색 및 분석
안녕하세요! 오늘은 벡터 데이터베이스와 대규모 언어 모델을 활용해서 자동으로 arXiv 논문을 검색하고 분석하는 방법에 대해 알아보겠습니다. 벡터 데이터베이스는 많은 숫자의 순서쌍으로 변
fornewchallenge.tistory.com
'AI 도구' 카테고리의 다른 글
| Groq LPU : 논문 한편 요약하는데 입력-추론-응답까지 2.4초! (4) | 2024.02.29 |
|---|---|
| 🤯 파이데이터(Phidata) : 5줄 코드로 토큰 과금없는 AI 어시스턴트 만들기 (2) | 2024.02.27 |
| 💥핵꿀팁! 스마트폰에서 Ollama WebUI를 만나는 방법 (ngrok 활용) (1) | 2024.02.21 |
| LangChain과 CrewAI를 활용한 News 검색-분석-요약 자동화 (2) | 2024.02.20 |
| 엔비디아의 최신 DEMO: Chat with RTX 설치 및 사용후기 (2) | 2024.02.18 |



