안녕하세요! 오늘은 벡터 데이터베이스와 대규모 언어 모델을 활용해서 자동으로 arXiv 논문을 검색하고 분석하는 방법에 대해 알아보겠습니다. 벡터 데이터베이스는 많은 숫자의 순서쌍으로 변환된 데이터를 효율적으로 저장하고 검색할 수 있는 데이터 저장소이며, 잘 알려진 솔루션으로는 Qdrant, ChromaDB, Milvus 등이 있습니다. 이 블로그에서는 벡터 데이터베이스의 개념과 구조, 원리 등에 대해서 알아보고, 활용예제 코드를 살펴보겠습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
벡터 데이터베이스 개요
벡터 데이터베이스는 딥 러닝 아키텍처와 같은 기계 학습 모델을 위한 추상적인 데이터 표현과 상호 작용하는 방법입니다. 벡터 데이터는 여러 개의 숫자로 이루어진 배열이며 특정 차원의 공간에서의 위치를 나타냅니다. 텍스트와 이미지 같은 복잡한 데이터는 임베딩(Embedding)이라고 불리는 기법을 통해 벡터데이터로 변환하게 되고, 벡터 데이터베이스는 이러한 벡터 데이터를 검색하고 관리할 수 있는 기능을 수행합니다. 벡터 데이터베이스는 시맨틱 검색 및 추천 시스템과 같은 응용 프로그램에 사용되며, 감정 분석, 음성 인식, 객체 검출 등과 같은 작업도 수행할 수 있습니다.
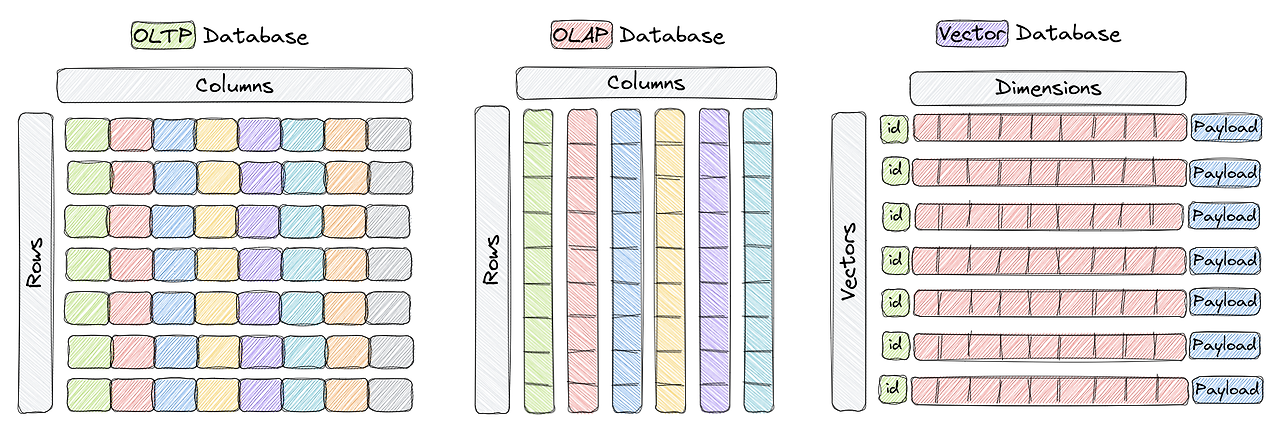
위 그림에서 보듯이 전통적인 온라인 트랜잭션(OLTP) 및 분석 처리(OLAP) 데이터베이스에서는 데이터가 행과 열로 구성되며 이를 테이블이라고 합니다. 이와 달리 이미지 인식, 자연어 처리 및 추천 시스템과 같은 응용 프로그램에서 데이터는 고차원 공간의 벡터로 표현됩니다. Qdrant는 이러한 벡터와 id와 추가적인 정보가 들어있는 페이로드를 포함한 벡터 데이터를 저장, 검색 및 관리하기 위한 벡터 유사성 검색 엔진입니다.
벡터 데이터베이스는 이미지, 음성, 텍스트 등 다양한 고차원 벡터를 효율적으로 저장하고 쿼리 할 수 있도록 최적화되어 있으며, 특수화된 데이터 구조 및 인덱싱 기술을 사용합니다. 이러한 데이터베이스는 사용자가 주어진 쿼리 벡터에 가장 가까운 벡터를 찾기 위해 코사인 유사도, 내적, 유클리드 거리 측정방식을 사용합니다.
- 코사인 유사도(Cosine Similarity): 코사인 유사도는 두 개체 사이의 유사성을 측정하는 방법입니다. 이것은 두 점 사이의 거리를 측정하는 자와 유사한 것으로 생각할 수 있지만, 거리를 측정하는 대신 두 개체 사이의 유사성을 측정합니다. 이는 주로 텍스트와 함께 사용되어 두 문서나 문장이 얼마나 비슷한지를 비교합니다. 코사인 유사도의 출력 범위는 -1부터 1까지이며, -1은 서로 완전히 다르다는 것을 의미하고, 1은 서로 정확히 동일하다는 것을 의미합니다.
- 내적(Dot Product): 내적 유사도 측정 항목은 코사인 유사도와 유사한 두 개체 사이의 유사성을 측정하는 다른 방법입니다. 이것은 숫자와 함께 작업할 때 주로 기계 학습 및 데이터 과학에서 사용됩니다. 내적 유사도는 두 개의 숫자 집합의 값을 곱한 다음 해당 곱셈을 합산하여 계산됩니다. 합이 높을수록 두 개의 숫자 집합이 더 유사합니다. 내적은 두 개의 숫자 집합이 얼마나 밀접하게 일치하는지를 알려주는 척도입니다.
- 유클리드 거리(Euclidean Distance): 유클리드 거리는 공간에서 두 점 사이의 거리를 측정하는 방법으로, 지도에서 두 장소 사이의 거리를 측정하는 것과 유사합니다. 이는 두 점의 좌표 간의 차이의 제곱의 합의 제곱근을 찾아 계산됩니다. 이 거리 측정 항목은 주로 기계 학습에서 두 데이터 포인트가 얼마나 유사하거나 다른지를 측정하거나 다시 말해 얼마나 떨어져 있는지를 이해하기 위해 사용됩니다.
벡터 데이터베이스는 추천 시스템, 콘텐츠 기반 이미지 검색 및 개인화된 검색과 같은 유사성 검색을 필요로 하는 다양한 응용 프로그램에서 중요한 역할을 합니다. 아래 그림은 Qdrant 벡터 데이터베이스의 아키텍처를 나타낸 그림입니다.

Qdrant 벡터 데이터베이스의 아키텍처 다이어그램에 등장하는 주요 용어는 다음과 같습니다.
- 컬렉션(Collections): 검색할 수 있는 포인트(페이로드를 가진 벡터)의 집합입니다. 동일한 컬렉션 내의 각 포인트의 벡터는 동일한 차원을 가져야 하며 하나의 메트릭으로 비교해야 합니다.
- 거리 메트릭(Distance Metrics): 이는 벡터 간 유사성을 측정하는 데 사용되며 컬렉션을 생성할 때 선택해야 합니다.
- 포인트(Points): 포인트는 Qdrant가 작업하는 중심 개체로 벡터, ID, 페이로드로 구성됩니다.
- 페이로드(Payload): 페이로드는 벡터에 추가할 수 있는 JSON 객체입니다.
- 클라이언트(Clients): Qdrant에 연결하기 위해 사용할 수 있는 프로그래밍 언어입니다.
환경설정 및 언어모델 설치
이 블로그의 모든 코드와 라이브러리 설치는 Ollama와의 호환성을 위하여 WSL(Windows Subsystem for Linux) 환경에서 실행되었습니다. 라이브러리의 설치는 WSL 프롬프트에서 "python3.11 -m venv myenv" 명령어로 가상환경을 만들고 "source myenv/bin/activate" 명령어로 가상환경을 활성화한 다음, 아래 명령어를 입력하면 됩니다.
pip install arxiv langchain_community langchain gpt4all qdrant-client gradio pypdf
이 코드에서 사용할 언어 모델은 Llama2이며 WSL 프롬프트상에서 "ollama pull llama2:7b-chat" 명령어를 사용해서 아래 화면과 같이 설치하면 됩니다.
설치되는 라이브러리 중 LangChain은 언어 모델을 기반으로 한 애플리케이션을 개발하기 위한 프레임워크입니다. 이를 통해 다음과 같은 애플리케이션을 구축할 수 있습니다:
- 문맥 인식: 언어 모델을 프롬프트 지시사항, 기계학습용 데이터 예제, 응답 기반 콘텐츠 등 다양한 문맥 소스에 연결하여 문맥을 고려하는 애플리케이션을 구축할 수 있습니다.
- 추론: 언어 모델을 사용하여 주어진 문맥에 기반한 응답 방법, 취해야 할 조치 등을 추론하는 애플리케이션을 구축할 수 있습니다.
LangChain 라이브러리는 기본 추상화 및 LangChain 표현 언어가 포함된 langchain-core 패키지, 서드 파티 통합을 위한 langchain-community 패키지, 에이전트 및 검색 전략이 포함된 langchain 패키지로 구성됩니다.

파이썬 코드 분석
다음은 예제 코드 분석입니다. 이 코드의 출처는 유튜브 "How I created AI Research Assistant and it Costs 0$ to Run"이며, 이 코드는 arXiv 논문을 검색하고, 해당 논문들을 다운로드하여 벡터 데이터베이스에 저장한 후, 언어 모델을 이용해서 질문에 대한 답변을 생성하는 기능을 제공합니다. 아래는 코드의 각 부분과 그 기능에 대한 설명입니다.
- 1. 필요한 라이브러리 및 모듈 가져오기: `gradio`, `os`, `time`은 사용자 인터페이스 및 파일 시스템 관리를 위한 라이브러리이며, `arxiv`는 arXiv API를 사용하여 논문 검색 및 다운로드를 위한 라이브러리입니다.`langchain_community`, `langchain`는 언어 모델 및 관련 기능을 제공하는 langchain 및 관련 커뮤니티 라이브러리입니다.
- 2. `process_papers` 함수 정의: `query`, `question_text`를 입력으로 받아서 arXiv에서 논문을 검색하고 질문에 대한 답변을 생성하는 함수로서, 논문을 저장할 디렉터리를 생성하고, arXiv 클라이언트를 사용하여 논문 검색을 수행합니다. 검색된 각 논문에 대해 PDF를 다운로드하고 저장하며, 다운로드된 PDF를 읽어와 텍스트로 변환하여 논문 내용을 준비한 후, 논문 내용을 적절한 크기의 청크(조각)로 나누고, 이를 Qdrant를 사용하여 임베딩하여 검색을 위한 준비를 합니다. 사용자 질문을 템플릿에 맞추어 처리하고, ChatOllama 모델을 사용하여 답변을 생성하도록 합니다.
- 3. `iface` 인터페이스 설정: `gr.Interface`를 사용하여 함수 `process_papers`를 웹 인터페이스로 나타내며, 두 개의 텍스트 입력(검색어 및 질문)과 텍스트 출력(논문 처리 결과)을 정의하고 인터페이스 설명 텍스트를 추가합니다.
- 4. `iface.launch()` 호출: 웹 애플리케이션을 실행하여 사용자는 검색어와 질문을 입력하고, 해당 논문들을 처리하여 최종 결과를 확인할 수 있습니다.
위 프로세스 중 `process_papers` 함수는 다음과 같은 주요 단계로 구성됩니다:
- 1. 논문 다운로드 및 텍스트 추출: `arXiv` 모듈을 사용하여 주어진 쿼리에 따라 최대 10개의 논문을 검색하고, 각 논문의 PDF를 다운로드한 후, 다운로드한 PDF 파일들은 `PyPDFLoader`를 사용하여 읽어옵니다. 그리고 각 PDF의 내용을 추출하여 전체 텍스트를 구성합니다.
- 2. 텍스트 분할: 전체 텍스트를 적절한 크기의 조각으로 나누어 준비합니다. 이를 위해 `RecursiveCharacterTextSplitter`클래스를 사용합니다. 이는 텍스트를 재귀적( Recursive, 함수나 알고리즘이 자기 자신을 호출하는 것)으로 작은 조각으로 분할합니다.
- 3. 임베딩 및 색인화: 나눠진 텍스트 조각들을 `GPT4AllEmbeddings`를 사용하여 해당 텍스트에 대한 임베딩 벡터를 생성합니다. 임베딩된 텍스트 조각들은 벡터 데이터베이스인 Qdrant에 색인화되어 검색을 위한 준비가 됩니다. GPT4AllEmbeddings는 문장을 저차원 벡터(embedding)로 변환하는 기능을 수행하는 클래스입니다. 이러한 저차원 벡터는 각 단어나 문장의 의미적 특성을 잘 보존하면서도 고차원 텍스트 데이터를 효율적으로 표현합니다.
- 4. 질문 처리 및 답변 생성: 사용자가 제공한 질문을 받아들이고, 질문과 검색된 논문의 컨텍스트를 고려하여 답변을 생성하기 위해, 템플릿 기반의 챗봇 모델이 사용됩니다. `ChatPromptTemplate`클래스를 사용하여 질문과 컨텍스트를 템플릿에 맞게 구성하고, 이전 컨텍스트와 질문을 병렬로 처리하기 위해 `RunnableParallel`을 사용합니다. 이후 템플릿을 통해 질문을 처리하고, `ChatOllama` 클래스에 전달하면 최종적으로 생성된 답변은 문자열로 반환됩니다.
예제 코드는 아래와 같습니다.
import gradio as gr
import os
import time
import arxiv
from langchain_community.vectorstores import Qdrant
from langchain_community.document_loaders import PyPDFLoader, DirectoryLoader
from langchain_community.chat_models import ChatOllama
from langchain.prompts import ChatPromptTemplate
from langchain.pydantic_v1 import BaseModel
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import GPT4AllEmbeddings
def process_papers(query, question_text):
dirpath = "./arxiv_papers"
if not os.path.exists(dirpath):
os.makedirs(dirpath)
client = arxiv.Client()
search = arxiv.Search(
query=query,
max_results=10,
sort_order=arxiv.SortOrder.Descending
)
for result in client.results(search):
while True:
try:
result.download_pdf(dirpath=dirpath)
print(result)
print(f"-> Paper id {result.get_short_id()} with title '{result.title}' is downloaded.")
break
except (FileNotFoundError, ConnectionResetError) as e:
print("Error occurred:", e)
time.sleep(5)
papers = []
loader = DirectoryLoader(dirpath, glob="*.pdf", loader_cls=PyPDFLoader)
try:
papers = loader.load()
except Exception as e:
print(f"Error loading file: {e}")
full_text = ''
for paper in papers:
full_text += paper.page_content
full_text = " ".join(line for line in full_text.splitlines() if line)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
paper_chunks = text_splitter.create_documents([full_text])
qdrant = Qdrant.from_documents(
documents=paper_chunks,
embedding=GPT4AllEmbeddings(),
path="./tmp/local_qdrant",
collection_name="arxiv_papers",
)
retriever = qdrant.as_retriever()
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
ollama_llm = "llama2:7b-chat"
model = ChatOllama(model=ollama_llm)
chain = (
RunnableParallel({"context": retriever, "question": RunnablePassthrough()})
| prompt
| model
| StrOutputParser()
)
class Question(BaseModel):
__root__: str
chain = chain.with_types(input_type=Question)
result = chain.invoke(question_text)
return result
iface = gr.Interface(
fn=process_papers,
inputs=["text", "text"],
outputs="text",
description="Enter a search query and a question to process arXiv papers."
)
iface.launch()
코드 실행결과
다음은 예제 코드를 실행한 결과입니다. 코드를 실행하면 http://127.0.0.1:7860 주소에서 웹 브라우저가 열리게 됩니다.
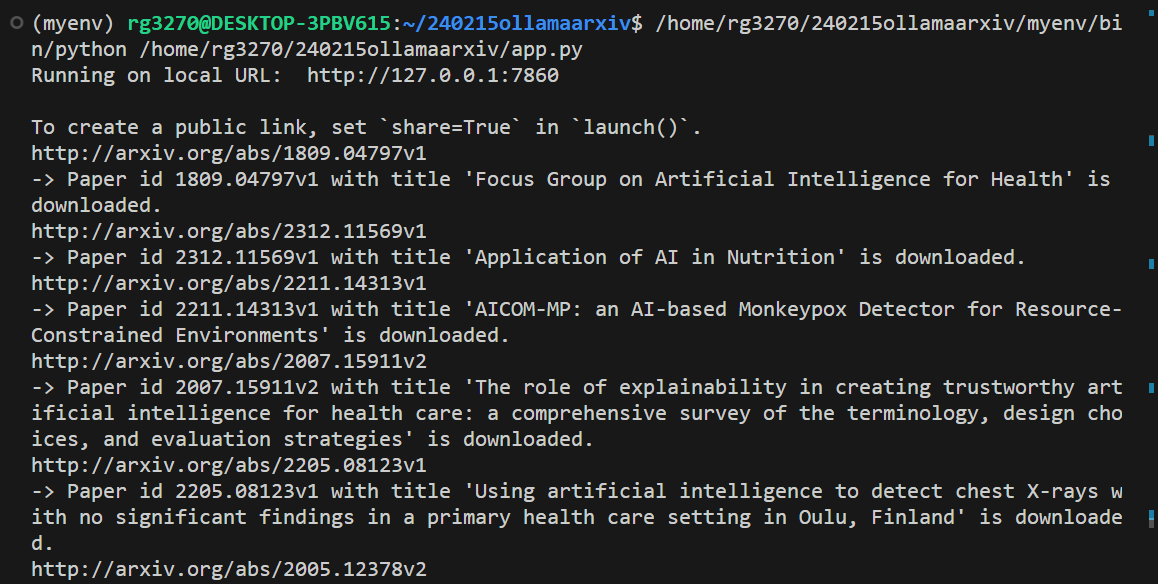
아래 화면은 웹 브라우저에서 코드가 실행된 모습입니다. 쿼리와 질문을 입력하면 ./arxiv_papers 디렉터리에 검색된 논문이 다운로드 되고, ./tmp/local_qdrant 디렉터리에 벡터 데이터베이스가 생성되고, 사용자 질문과 검색된 논문의 컨텍스트를 기반으로 Llama2 모델의 응답이 출력됩니다.
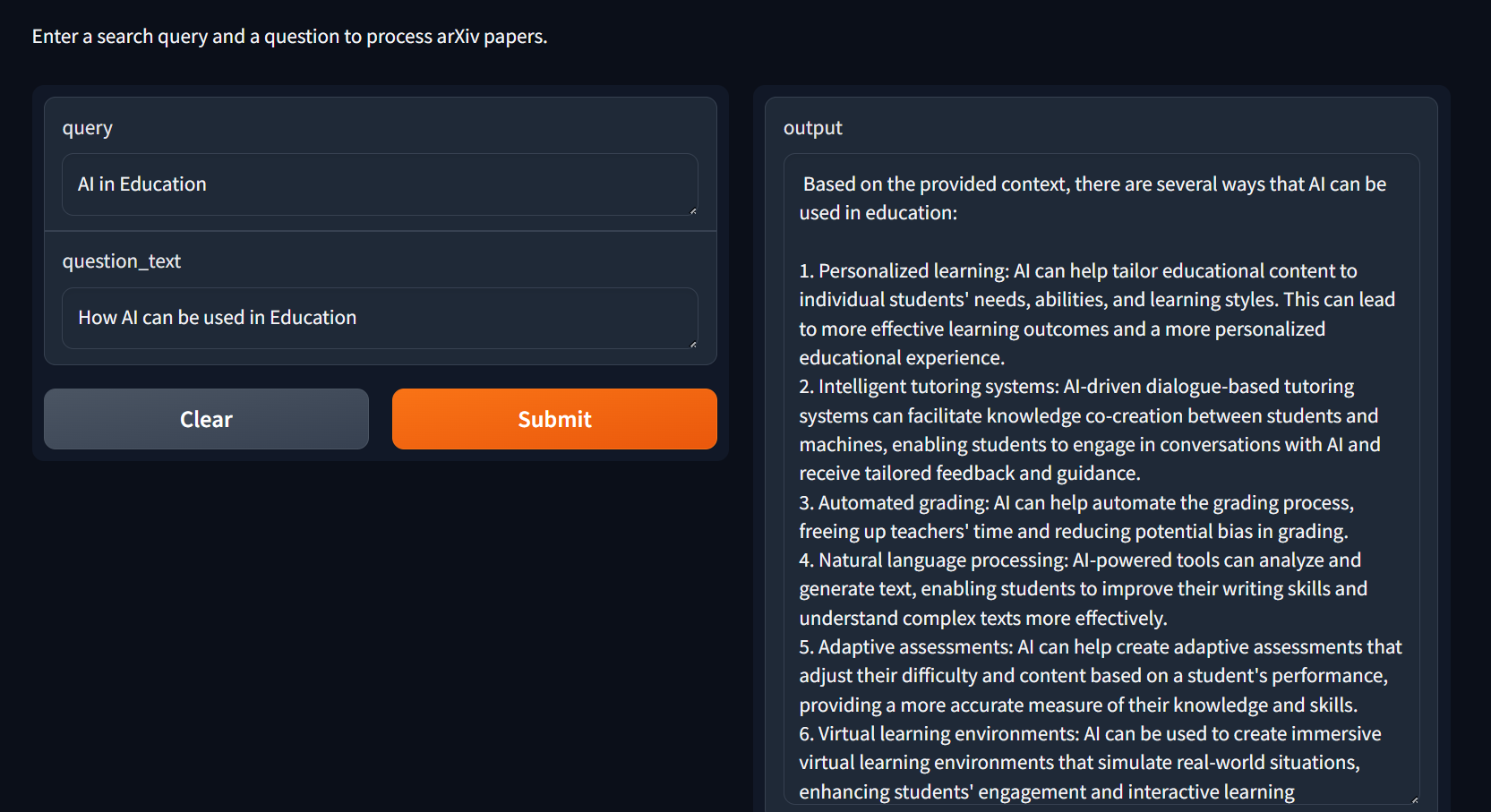
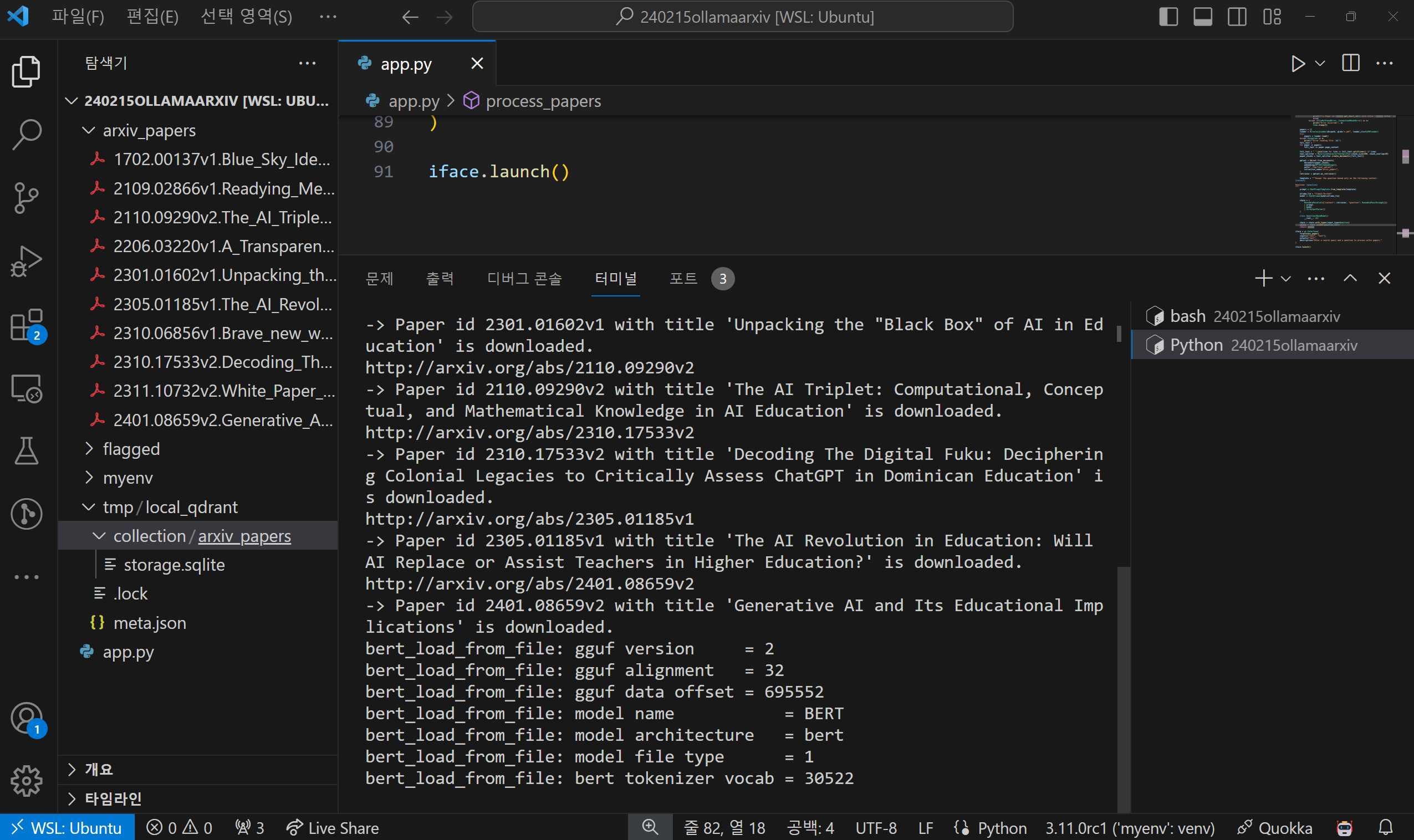
아래 더보기를 클릭하시면 코드 실행결과 Llama2가 응답한 내용을 확인하실 수 있습니다.
인공지능은 학습 결과를 향상시키고 효율성을 높이며 전반적인 교육 경험을 향상시키는 다양한 방법으로 교육에 활용될 수 있습니다. 다음은 교육에서 인공지능이 사용될 수 있는 잠재적인 방법 몇 가지입니다.
1. 맞춤형 학습: 인공지능은 개별 학생의 필요, 능력 및 선호도에 맞게 학습 자료와 활동을 맞춤화하는 데 도움을 줄 수 있습니다. 학생 데이터를 분석하여 인공지능은 학생이 개선이 필요한 영역을 식별하고 효과적으로 학습하기 위한 맞춤형 수업, 연습 또는 게임을 제공할 수 있습니다.
2. 지능형 지도 시스템: 인공지능은 학생에게 개인화된 지도 및 피드백을 제공하는 지능형 지도 시스템을 생성하는 데 사용될 수 있습니다. 이러한 시스템은 학생 성적에 대한 실시간 피드백을 제공하고 학생이 개선이 필요한 영역을 식별하며 학생이 성공하기 위한 추가 지원이나 자료를 제공할 수 있습니다.
3. 적응형 평가: 인공지능은 학생의 성적에 따라 난이도와 내용을 조정하는 적응형 평가를 생성하는 데 사용될 수 있습니다. 이를 통해 학생의 지식과 기술을 더 정확하게 평가할 수 있으며 교사는 학생이 개선이 필요한 영역을 식별하는 데 유용한 데이터를 얻을 수 있습니다.
4. 자연어 처리: 자연어 처리(NLP)를 사용하는 인공지능 도구는 언어 학습 결과를 개선하는 데 도움을 줄 수 있습니다. NLP는 학생의 글쓰기를 분석하고 피드백을 제공하며 문법 및 구문을 도와주며 비영어 원어민을 위한 실시간 번역 지원을 제공할 수 있습니다.
5. 학습 분석: 인공지능은 출석, 성적 및 시험 점수와 관련된 대량의 데이터를 분석하는 데 사용될 수 있습니다. 이 데이터의 패턴과 트렌드를 식별함으로써 교사와 관리자는 교육 결과를 개선하기 위한 더 나은 결정을 내릴 수 있습니다.
6. 콘텐츠 생성: 인공지능은 개별 학생의 필요와 능력에 맞추어 맞춤형 학습 콘텐츠를 생성하는 데 도움을 줄 수 있습니다. 이는 맞춤형 수업 계획, 대화식 시뮬레이션 및 기타 교육 자료를 포함할 수 있습니다.
7. 자동 채점: 인공지능 도구를 사용하여 채점 프로세스를 자동화할 수 있습니다. 이 도구는 학생 성적을 정확하게 평가하고 실시간 피드백을 제공하며 채점에서 편향을 줄일 수 있습니다.
8. 가상 학습 환경: 인공지능은 현실적인 상황을 시뮬레이션하고 대화식 학습 경험을 제공하는 가상 학습 환경을 생성하는 데 사용될 수 있습니다.
9. 교사 지원: 인공지능은 교사가 교육에 더 많은 시간을 할애할 수 있도록 관리적 작업을 자동화하고 학생 성적에 대한 실시간 피드백을 제공하는 데 도움을 줄 수 있습니다.
10. 접근성: 인공지능은 시각 또는 청각 장애가 있는 학생들을 위해 교육 자료를 더 접근 가능하게 만드는 데 사용될 수 있습니다. 예를 들어, 인공지능 도구는 강의의 실시간 필기를 제공하거나 쓰여진 자료를 점자로 번역할 수 있습니다.
전반적으로, 인공지능은 개인화된 학습 경험을 제공하고 교수 방법을 개선하며 교육 결과를 향상시킴으로써 교육을 혁신할 수 있는 잠재력을 가지고 있습니다. 그러나 인공지능은 인간 교사를 대체하는 것이 아니라 학습 과정을 보완하고 향상시키는 도구로 사용되어야 함을 인식하는 것이 중요합니다.

마치며
오늘은 벡터 데이터베이스와 대규모 언어 모델을 활용하여 arXiv 논문을 검색하고 분석하는 방법에 대해 살펴보았습니다. 벡터 데이터베이스는 딥 러닝 아키텍처와 같은 기계 학습 모델을 위한 추상적인 데이터 표현과 상호 작용하는 방법으로, 주어진 쿼리에 대해 벡터 데이터를 검색하고 관리할 수 있는 기능을 제공함으로써, 추천 시스템, 콘텐츠 기반 이미지 검색 및 개인화된 검색과 같은 유사성 검색을 필요로 하는 다양한 응용 프로그램에서 중요한 역할을 합니다.
우리는 벡터 데이터베이스의 개념, 구조, 원리를 자세히 살펴보고, 실제로 벡터 데이터를 검색하고 관리하는 과정을 코드를 통해 확인했습니다. arXiv API를 사용하여 논문을 검색하고 다운로드한 후, 텍스트를 추출하여 벡터 데이터베이스에 저장하고 사용자의 질문에 대한 답변을 생성하기 위해 언어 모델을 활용하는 방법을 알아보았습니다. 이 블로그를 통해 벡터 데이터베이스와 언어 모델의 활용에 대해 도움이 되셨기를 바라면서, 저는 다음시간에 더 유익한 자료를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2024.02.15 - [AI 도구] - 🚀Ollama와 Instructor를 활용한 대규모 언어 모델과의 상호 작용 가이드
🚀Ollama와 Instructor를 활용한 대규모 언어 모델과의 상호 작용 가이드
안녕하세요! 오늘은 Ollama API와 Instructor를 이용해서 대규모 언어모델과 상호작용하는 방법에 대해 알아보겠습니다. Instructor는 파이썬의 라이브러리로, OpenAI API를 호출하는 함수와 클라이언트를
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| [Ollama 활용] 허깅페이스 Solar를 나만의 커스텀 언어 모델로 바꾸기 (5) | 2024.03.05 |
|---|---|
| Sora: 현실 세계를 시뮬레이션하는 OpenAI 비디오 생성 모델 (0) | 2024.02.17 |
| 구글 제미나이 울트라 1.0, 과연 진정한 AI 혁신인가? 솔직 후기 공개! (6) | 2024.02.12 |
| LLaVA NeXT: 제미나이 프로를 뛰어넘는 오픈소스 멀티모달 AI! (4) | 2024.02.08 |
| 메타의 새로운 코딩용 대규모 언어 모델 : Code Llama 70B (0) | 2024.01.31 |



