안녕하세요! 오늘은 Ollama API와 Instructor를 이용해서 대규모 언어모델과 상호작용하는 방법에 대해 알아보겠습니다. Instructor는 파이썬의 라이브러리로, OpenAI API를 호출하는 함수와 클라이언트를 제공하고, Pydantic 라이브러리와 함께 사용해서 데이터 모델을 정의하고 응답데이터를 파싱 합니다. 이 블로그에서는 Ollama API와 Instructor 및 Pydantic 라이브러리를 이용한 대규모 언어 모델과의 상호작용 방법에 대해서 확인하실 수 있습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Instructor란?
Instructor는 OpenAI API를 보다 쉽게 사용하고 관리할 수 있도록 도와주는 파이썬 라이브러리입니다. 데이터 추출, 유효성 검사, 재시도 등의 작업을 보다 효율적으로 처리할 수 있도록 지원합니다.
Instructor와 Pydantic
Instructor는 OpenAI API와 상호 작용하여 API를 보다 효율적으로 사용할 수 있도록 도와주는 도구이며, Instructor를 사용하면 OpenAI API의 응답을 Pydantic 모델과 연결할 수 있습니다. Instructor는 다음과 같은 주요 기능을 제공합니다.
- 효율적인 데이터 추출: Instructor를 사용하면 OpenAI API를 통해 얻은 데이터를 Pydantic 또는 기타 데이터 모델과 연결하여 효율적으로 추출할 수 있습니다. 이를 통해 언어 모델의 출력을 구조화된 데이터로 변환하고 쉽게 처리할 수 있습니다.
- 응답 모델 설정: Instructor를 사용하면 OpenAI API 호출에 응답 모델(response model)을 지정할 수 있습니다. 이를 통해 API 응답의 구조를 사전에 정의하고 유효성을 검사할 수 있습니다.
- 요청 재시도 설정: 요청이 실패할 경우 Instructor를 사용하여 자동으로 재시도할 횟수를 설정할 수 있습니다. 이를 통해 네트워크 문제 또는 API 서버 문제로 인해 발생할 수 있는 오류를 관리할 수 있습니다.
Pydantic은 Python에서 데이터 유효성 검사 및 직렬화를 위한 라이브러리입니다. 주로 데이터 모델의 정의와 데이터의 유효성을 검사하는 데 사용됩니다. Pydantic을 사용하면 데이터 모델의 일관성을 유지하기 위해 간단하고 선언적인 방식으로 코드를 작성할 수 있습니다. Pydantic의 주요 특징은 다음과 같습니다:
- 유형 힌트(Type Hints) 기반: Python 3.6부터 지원되는 유형 힌트를 기반으로 데이터 모델을 정의합니다. 이를 통해 데이터의 유형과 구조를 명시적으로 지정함으로써, 코드의 가독성을 높이고 유지 보수성을 개선할 수 있습니다.
- 자동 유효성 검사: Pydantic은 데이터 모델에 정의된 규칙에 따라 자동으로 입력 데이터의 유효성을 검사합니다. 이를 통해 잘못된 데이터가 모델에 들어가는 것을 방지할 수 있습니다.
- 직렬화 및 역직렬화(Serialization and Deserialization): Pydantic을 사용하여 데이터를 JSON 또는 다른 형식으로 직렬화하고 역직렬화할 수 있습니다. 이를 통해 데이터를 저장하고 전송하는 데 사용할 수 있습니다.
- 자동 문서화: Pydantic은 데이터 모델의 필드와 유효성 검사 규칙을 기반으로 자동으로 문서를 생성할 수 있습니다. 이를 통해 코드의 가독성을 높이고 유지 보수를 용이하게 할 수 있습니다.
Instructor 함수 호출방식의 장점
Ollama의 OpenAI 호환 API를 사용해서 Instructor 라이브러리에서 제공하는 함수를 호출하고 언어모델과 대화하는 "함수 호출방식"은 언어모델과 직접 대화하는 방식과 비교해서 다음과 같은 차이점이 있습니다.
- 편의성과 유연성: Instructor를 사용하면 OpenAI API를 더 쉽게 호출하고 관리할 수 있습니다. Instructor는 API 호출을 단순화하고 Python 코드 내에서 API 요청을 쉽게 구성할 수 있도록 도와줍니다. 이는 개발자가 코드를 더 빠르고 효율적으로 작성할 수 있게 해 줍니다.
- 데이터 모델 구조화: Instructor를 사용하면 Pydantic를 통해 응답 데이터의 구조를 더욱 명확하게 정의할 수 있습니다. 이를 통해 응답 데이터를 자동으로 파싱 하여 Python 객체로 변환하고, 데이터 모델의 유효성을 검사할 수 있습니다. 이는 코드의 안정성과 가독성을 향상시키고, 디버깅을 용이하게 만듭니다.
- API 호출 및 관리: Ollama와 Instructor를 함께 사용하면 로컬 환경에서 OpenAI API를 더 효율적으로 활용할 수 있습니다. Ollama는 OpenAI API의 호환성을 제공하고, Instructor는 API 호출을 통합하여 관리를 용이하게 합니다.
- 기능 확장성: Instructor를 사용하면 추가적인 기능 확장이 용이합니다. 예를 들어, Instructor를 사용하여 API 요청에 대한 로깅, 에러 처리, 또는 사용자 정의 래퍼 기능을 구현할 수 있습니다. 이는 애플리케이션의 요구에 맞게 API 호출을 더욱 유연하게 조정할 수 있게 해 줍니다.
Ollama를 이용하여 언어 모델과 직접 대화하는 것은 더 간단하지만, Instructor의 함수를 사용하여 대화하는 것은 코드의 유지보수성과 확장성을 향상시키고, API 호출을 보다 효율적으로 관리할 수 있게 해 줍니다.
환경설정 및 라이브러리 설치
다음은 환경설정 및 라이브러리 설치 단계입니다. 이 블로그의 모든 코드와 라이브러리 설치는 Ollama와의 호환성을 위하여 WSL(Windows Subsystem for Linux) 환경에서 실행되었습니다. 라이브러리의 설치는 WSL 프롬프트에서 "python3.11 -m venv myenv" 명령어로 가상환경을 만들고 "source myenv/bin/activate" 명령어로 가상환경을 활성화한 다음, 아래 명령어를 입력하면 됩니다.
pip install yfinance pydantic instructor openai
위에서 설치한 각 라이브러리의 용도는 다음과 같습니다.
- yfinance: Yahoo Finance 데이터를 쉽게 가져오고 조작할 수 있도록 도와주는 라이브러리입니다. 이를 통해 사용자는 주식 시장 데이터를 가져와서 분석하거나 시각화할 수 있습니다.
- Pydantic: 데이터 검증과 구조화를 위한 파이썬 라이브러리입니다. Pydantic은 데이터 모델을 정의하고 이를 통해 입력 데이터를 유효성 검사하고 구조화할 수 있습니다. 주로 데이터 유효성 검사, JSON 직렬화 및 역직렬화, 데이터 모델링 등에 사용됩니다.
- Instructor: OpenAI API와 상호작용하기 위한 Python 래퍼 라이브러리입니다. Instructor는 OpenAI API를 간편하게 사용할 수 있는 인터페이스를 제공하며, 요청의 세부 사항을 쉽게 조절할 수 있도록 도와줍니다. 주로 자연어 처리 작업에 사용됩니다.
- OpenAI: 인공지능 및 자연어 처리 기술을 개발하고 제공하는 기업인 OpenAI의 Python 클라이언트 라이브러리입니다. OpenAI API를 사용하여 자연어 생성, 번역, 요약, 질의응답 등 다양한 자연어 처리 작업을 수행할 수 있습니다
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
파이썬 코드 실행
이 코드의 출처는 유튜브 "Ollama Function Calling Advanced: Make your Application Future Proof!"이며, Ollama의 OpenAI 호환 API와 Instructor 라이브러리를 사용하여 대화를 생성하고, 언어 모델을 통해 주어진 회사의 티커 심볼을 반환한 후, 해당 주식의 최신 가격을 가져와 출력하는 기능을 수행하는 예제입니다.
아래는 이 코드에서 사용되는 Ollama와 Instructor 라이브러리, Pydantic 라이브러리의 역할에 대한 설명입니다.
| 기능 | Ollama | Instructor | Pydantic |
| 역할 | 로컬에서 OpenAI 호환 API 서비스 제공, 언어 모델과 대화 생성과 처리 | OpenAI API와 상호 작용하는 클라이언트 제공 및 언어 모델 지정 | 데이터 모델 정의와 검증을 위한 라이브러리 제공, 응답 데이터 파싱 및 검증 |
위 코드의 전체적인 동작 순서를 요약하면 다음과 같습니다:
- 1. 필요한 라이브러리와 모듈을 임포트 합니다. 이 코드에서는 warnings, OpenAI, BaseModel, Field, List 및 yfinance 모듈을 임포트 합니다. `warnings.filterwarnings("ignore")`: 라이브러리의 버전 변경과 같은 경고 메시지를 무시하도록 설정합니다. `from pydantic import BaseModel, Field`: Pydantic 라이브러리에서 BaseModel 및 Field 클래스를 가져옵니다. 이는 데이터 모델을 정의하는 데 사용됩니다.
- 2. Pydantic 라이브러리의 BaseModel 클래스를 사용 대화 생성을 위해 필요한 데이터의 형식을 정의합니다. 여기서 StockInfo 모델은 Pydantic의 BaseModel 클래스를 상속받아 정의된 데이터 모델입니다. 이 모델은 응답 데이터의 구조를 정의하고 있으며, 응답으로 받은 JSON 데이터를 파싱 하여 실제 주식 정보를 담고 있는 객체로 변환합니다.
- 3. Instructor를 사용하여 OpenAI API와 통신하기 위한 클라이언트 객체를 생성합니다. 이때 Instructor의 patch 함수를 사용하여 클라이언트 객체를 생성하고 설정합니다. 이때 mode 옵션을 JSON으로 설정하여 JSON 형식의 데이터를 사용하도록 합니다.
- 4. Instructor의 chat completions 함수를 호출하여 대화를 생성합니다. 이때 create 함수를 사용하며, 필요한 인자들을 전달합니다. 여기서는 대화 내용을 입력하고, 이를 Ollama 모델에 전달하여 처리하도록 합니다.
- 5. 이전 단계에서 생성된 대화의 결과를 처리합니다. 이때는 반환된 데이터를 적절히 가공하거나 분석하여 사용자에게 제공합니다. 이 코드에서는 반환된 티커 심볼을 사용하여 주식 정보를 가져오고, 해당 주식의 가격을 출력합니다.
이렇게 전체적인 동작 순서는 필요한 데이터 모델을 정의하고, Ollama의 chat completions 기능을 호출하여 대화를 생성하며, 결과를 처리하는 과정으로 이루어집니다. 주요 코드의 기능은 아래와 같습니다.
- `class StockInfo(BaseModel):`: StockInfo라는 Pydantic 모델을 정의합니다. 이 모델은 주식회사의 이름(company)과 티커 심볼(ticker)을 나타내는 두 개의 필드로 구성되어 있습니다.
- `client = instructor.patch(...)`: Instructor를 사용하여 OpenAI API와의 통신을 도와주는 클라이언트 객체를 생성합니다. 이 클라이언트 객체는 OpenAI API와의 통신을 담당하고, 데이터를 주고받는 역할을 합니다.
- `resp = client.chat.completions.create(...)`: OpenAI API에 쿼리를 보냅니다. 사용자로부터 주식회사의 이름을 입력받아, 그에 대한 티커 심볼과 함께 Pydantic 모델에서 정의한 대로 응답을 받습니다.
- `client.chat.completions.create(...)`: Ollama의 대화 생성 기능을 수행하는 함수를 호출하여 OpenAI API의 chat completions 엔드포인트를 사용해서 대화 내용을 생성합니다. messages=[{"role": "user", "content": f"Return the company name and the ticker symbol of the {company}."}]는 사용자 역할의 메시지를 지정하여 회사 이름과 티커 심볼을 반환하도록 요청합니다.
- `response_model=StockInfo`: 를 사용하면 Instructor 패키지는 OpenAI API로부터 받은 응답 데이터를 StockInfo 모델에 따라 구조화된 형태로 변환하여 제공합니다. 이를 통해 데이터의 일관성을 유지하고, 코드의 가독성을 향상시키며, 데이터의 유효성을 검사할 수 있습니다.
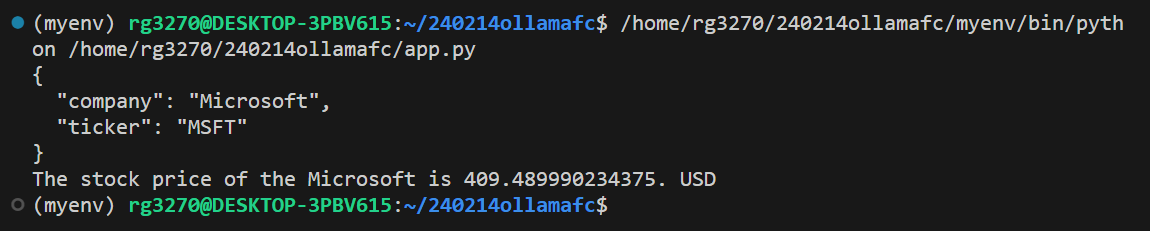
- `print(resp.model_dump_json(indent=2))`: 주식회사의 이름과 티커 심볼을 출력합니다.
- `stock = yf.Ticker(resp.ticker)`: Yahoo Finance API를 사용하여 주식 객체를 가져옵니다. 이때 사용한 티커 심볼은 이전에 받은 응답에서 가져옵니다.
- `hist = stock.history(period="1d")`: Yahoo Finance API를 통해 해당 주식의 최근 일일 주가 이력을 가져옵니다.
- `stock_price = hist['Close'].iloc[-1]`: 최근 일일 주가 이력에서 마지막 종가를 가져와서 주식 가격을 지정합니다.
- `print(f"The stock price of the {resp.company} is {stock_price}. USD")`: 주식의 회사 이름과 함께 주식 가격을 출력합니다.
이 코드는 Ollama의 API를 통해 llama2 모델로부터 회사의 티커 심볼 정보를 가져오고, 가져온 정보를 사용하여 Yahoo Finance API로 해당 주식의 가격을 받아서 원하는 데이터 구조와 형식으로 출력하는 과정을 보여줍니다.
import warnings
warnings.filterwarnings("ignore")
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
import yfinance as yf
import instructor
company = "Google"
class StockInfo(BaseModel):
company: str = Field(..., description="Name of the company")
ticker: str = Field(..., description="Ticker symbol of the company")
# enables `response_model` in create call
client = instructor.patch(
OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama",
),
mode=instructor.Mode.JSON,
)
resp = client.chat.completions.create(
model="llama2",
messages=[
{
"role": "user",
"content": f"Return the ticker symbol of the {company}."
}
],
response_model=StockInfo,
max_retries=10
)
print(resp.model_dump_json(indent=2))
stock = yf.Ticker(resp.ticker)
hist = stock.history(period="1d")
stock_price = hist['Close'].iloc[-1]
print(f"The stock price of the {resp.company} is {stock_price}. USD")

마치며
오늘은 Ollama의 OpenAI 호환 API를 이용하여 언어 모델과 대화하는 함수를 호출하고, 응답 메시지를 원하는 구조로 변환하여 출력하는 방법에 대해 살펴보았습니다. Instructor는 OpenAI API와의 효율적인 상호 작용을 도와주는 라이브러리로, Pydantic과 함께 사용하여 응답 데이터를 구조화하고 검증하는데 활용됩니다. Pydantic은 데이터 모델의 정의와 검증을 위한 라이브러리로, 데이터의 유효성을 검사하고 직렬화하여 처리하는 데 사용됩니다.
이 블로그를 통해 Ollama OpenAI 호환 API의 호환성을 실제 코드로 확인하였으며, 대규모 언어 모델과 상호작용하는 방법에 대해 알아보았습니다. 오늘 내용은 여기까지입니다. 여러분이 AI 도구를 활용하시는데 블로그 내용이 도움이 되셨기를 바라면서 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2024.02.12 - [AI 도구] - Ollama 업데이트! 이제 OpenAI API를 무료로 즐기세요!
Ollama 업데이트! 이제 OpenAI API를 무료로 즐기세요!
안녕하세요! 오늘은 대규모 언어 모델 활용도구인 Ollama의 OpenAI API 호환성 업데이트 소식을 전해드리겠습니다. ChatGPT를 만든 OpenAI의 API는 현재 1,000 토큰 당 $0.03(GPT-4)의 가격에 유료로 제공되고
fornewchallenge.tistory.com
'AI 도구' 카테고리의 다른 글
| LangChain과 CrewAI를 활용한 News 검색-분석-요약 자동화 (2) | 2024.02.20 |
|---|---|
| 엔비디아의 최신 DEMO: Chat with RTX 설치 및 사용후기 (2) | 2024.02.18 |
| AutoGen: 토큰 과금 없는 100% 무료 대규모 언어 모델 협업 자동화 (2) | 2024.02.13 |
| Ollama 업데이트! 이제 OpenAI API를 무료로 즐기세요! (1) | 2024.02.12 |
| 무료로 즐기는 유튜브 요약 AI 'Corely': 최신 콘텐츠부터 나만의 컬렉션까지 (4) | 2024.02.03 |



