안녕하세요! 오늘은 OpenAI가 새롭게 공개한 차세대 언어 모델, GPT-4.1 시리즈에 대해 알아보겠습니다. GPT-4.1은 GPT-4o의 뒤를 잇는 강력한 후속작으로, 무려 100만 토큰이라는 어마어마한 컨텍스트 길이를 자랑하며 언어 이해, 명령어 추종, 코딩, 멀티모달 처리 등 다양한 영역에서 눈에 띄는 성능 향상을 이뤄냈습니다. 특히 GPT-4.1 mini와 GPT-4.1 nano는 작고 빠르면서도 성능은 뛰어나, 다양한 개발 환경과 예산에 맞게 유연하게 활용할 수 있다는 점에서 주목받고 있습니다. 이번 블로그에서는 GPT-4.1 시리즈의 모델 구성과 특징, 성능 벤치마크, 실제 사용 사례, 그리고 테스트 결과까지 살펴보겠습니다.

1. GPT-4.1 개요
이번에 공개된 OpenAI의 차세대 GPT 모델 시리즈인 GPT-4.1는 GPT-4.1, GPT-4.1 미니 (mini), 그리고 새롭게 선보이는 가장 작고 빠르며 저렴한 모델인 GPT-4.1 나노 (nano)로 구성됩니다. GPT-4.1 모델 시리즈의 가장 큰 특징 중 하나는 100만 토큰의 긴 컨텍스트를 지원한다는 점입니다. 이는 이전 모델인 GPT-4o가 처리할 수 있었던 128,000 토큰의 8배에 달하는 용량으로, 방대한 양의 정보를 한 번의 상호작용으로 처리하고 이해할 수 있게 해 줍니다. 100만 토큰은 톨스토이의 '전쟁과 평화' 소설 분량보다 많은 75만 단어를 한 번에 처리할 수 있는 수준입니다.
| 구분 | 모델명 | 컨텍스트 용량 | 특징 |
| GPT-4.1 | gpt-4.1-2025-04-14 | 100만 토큰 | 높은 수준의 추론 능력과 정확성 |
| GPT-4.1 미니 | gpt-4.1-mini-2025-04-14 | 100만 토큰 | 균형 잡힌 성능과 효율성 |
| GPT-4.1 나노 | gpt-4.1-nano-2025-04-14 | 100만 토큰 | 가장 낮은 비용과 빠른 속도 |
2. GPT-4.1 특징 및 주요 기능
GPT-4.1은 이전 GPT-4o 모델 대비 코딩, 명령어 추종, 긴 컨텍스트 이해 능력이 전반적으로 향상되었습니다. OpenAI는 실제 개발자 피드백을 바탕으로 프론트엔드 코딩, 불필요한 편집 감소, 형식 안정성, 응답 구조 및 순서 준수, 일관된 도구 사용 등 실질적인 사용 사례에 최적화했습니다.

위 그래프에서 보면 동일한 모델 크기 카테고리에서 GPT-4o 시리즈보다 GPT-4.1 시리즈가 지능 측면에서 우수한 성능을 보여주고 있습니다. 특히, GPT-4.1 mini는 GPT-4o mini보다 훨씬 높은 지능 점수를 가지면서 지연시간 측면에서는 큰 차이가 없어 효율적인 선택으로 보입니다.
주요 특징 및 기능:
- 향상된 코딩 및 명령어 추종: GPT-4.1은 SWE-Bench 코딩 벤치마크에서 GPT-4o 대비 상당한 성능 향상을 보였습니다. 또한, 다국어 코딩 능력도 개선되었으며, 특히 diff 형식 처리 성능이 크게 향상되었습니다.
- 개선된 명령어 추종: GPT-4.1은 상세한 지침, 특히 여러 요청이 포함된 에이전트의 지침을 정확하게 따릅니다.
- 긴 컨텍스트 모델: GPT-4.1은 100만 토큰의 입력을 지원하여, 단일 상호작용에서 광범위한 컨텍스트를 처리하고 이해할 수 있습니다. 이는 상세하고 미묘한 이해가 필요한 작업과 작동하면서 컨텍스트가 증가하는 다단계 에이전트에 특히 유용합니다. '바
- 파인튜닝 지원: GPT-4.1 및 GPT-4.1 미니 모델에 대한 감독 학습 기반 파인튜닝 (supervised fine-tuning)이 곧 지원될 예정입니다. 이를 통해 개발자는 자체 데이터셋을 사용하여 기본 모델을 안전하게 사용자 정의하고, 조직의 특정 어조, 도메인 용어, 작업 흐름에 맞춰 응답을 조정할 수 있습니다. 파인튜닝된 모델은 Azure AI Foundry를 통해 관리 및 배포됩니다.
- 멀티모달 이해 능력: GPT-4.1은 텍스트뿐만 아니라 비디오와 같은 다양한 미디어를 이해하는 능력도 향상되었습니다. 비디오 MME 벤치마크에서 최첨단 성능을 달성하여, 자막 없이 30~60분 길이의 비디오를 이해하고 관련 질문에 답하는 능력이 크게 향상되었음을 입증했습니다. 여기서 주의해야 할 점은 GPT-4.1 모델이 비디오를 직접 이해한 것이 아니라, 비디오 내용을 요약한 텍스트를 처리한 것입니다.
- 지식 컷오프: GPT-4.1의 지식 컷오프는 2024년 6월입니다.
3. GPT-4.1 벤치마크 결과
다음은 GPT-4.1의 코딩, 명령어 추종, 장문맥 처리, 멀티모달 분야 벤치마크 결과에 대해 알아보겠습니다.
1) 코딩 능력:

- SWE-Bench: 파이썬 코드 생성 및 문제 해결 능력을 평가하는 SWE-Bench 벤치마크에서 GPT-4.1은 55%의 정확도를 달성하여 이전 GPT-4o 모델의 33% 대비 상당한 향상을 보였습니다. 이는 추론 모델이 아닌 모델로서는 매우 인상적인 결과이며, 이전의 GPT-4 및 01, 03 미니 모델보다도 우수한 성능입니다.
- Ader Polyglot: 다양한 프로그래밍 언어 코딩 능력을 평가하는 Ader Polyglot 벤치마크에서 GPT-4.1은 전체 (whole) 코드 생성뿐만 아니라 변경 사항 (diff) 생성 성능에서도 이전 모델 대비 크게 향상되었습니다. 특히 diff 성능은 GPT-4o 대비 두 배 향상되었습니다. GPT-4.1 미니 또한 GPT-4o 미니 대비 상당한 성능 향상을 보였습니다.
2) 명령어 추종 능력:

- 내부 명령어 추종 평가: OpenAI에서 자체적으로 개발한 내부 명령어 추종 평가에서 GPT-4.1은 포맷팅, 순위 지정, 순서 지정된 명령어 처리, 과신 방지 등 다양한 측면에서 이전 GPT-4o 모델 대비 월등한 성능을 보였습니다. 특히 어려운 명령어 세트에서도 뛰어난 처리 능력을 보여주었습니다.
- Sales Multi-challenge Eval: 다중 턴 대화에서 명령어 추종 능력을 평가하는 외부 벤치마크인 Sales Multi-challenge Eval에서도 GPT-4.1은 뛰어난 성능을 나타내며, 오래된 지침도 기억하고 일관성 있게 따르는 능력을 입증했습니다.
3) 장문맥 처리 능력:

- Needle in a Haystack: 최대 100만 토큰 길이의 문서 내에서 특정 정보를 찾는 능력을 평가하는 Needle in a Haystack 평가에서 GPT-4.1, GPT-4.1 미니, GPT-4.1 나노 모두 문서의 어느 위치에 정보가 있든 정확하게 찾아내는 완벽한 성능을 보였습니다.
- OpenAI MRCR: 더욱 복잡한 장문맥 이해 및 추론 능력을 평가하는 OpenAI MRCR 평가에서 GPT-4.1은 최대 128,000 토큰까지 GPT-4o 대비 상당히 우수한 성능을 보였으며, 100만 토큰까지도 비교적 안정적인 성능을 유지했습니다.
4) 멀티모달 능력:

- Video-MME: 자막 없이 제공된 긴 비디오를 설명한 텍스트를 이해하고 질문에 답하는 능력을 평가하는 Video MME 벤치마크에서 GPT-4.1은 최첨단 성능인 72%를 달성했습니다. 특히 GPT-4.1 미니 모델은 멀티모달 추론 및 이해 능력에서 뛰어난 성능을 보여주어 이미지 처리 관련 작업에 매우 유용할 것으로 기대됩니다.
- Windsurf 내부 벤치마크: 에이전트 기반 코딩 IDE인 Windsurf의 내부 벤치마크에서 GPT-4.1은 엔드투엔드 소프트웨어 성능 면에서 GPT-4o 대비 60% 향상된 성능을 보여 놀라움을 안겼습니다.
4. GPT-4.1 성능 테스트
다음은 GPT-4.1의 성능을 실제로 테스트해 보겠습니다. 테스트는 Windsurf에서 프리미엄 모델 중 한정 기간 무료로 제공하는 GPT-4.1 모델을 선택해서 진행하였습니다.

- 웹사이트 생성 데모: GPT-4.1에게 pdf 파일을 기반으로 질문에 답변할 수 있는 웹사이트 생성을 요청했습니다. Windsurf에서 입력한 요청 프롬프트는 아래와 같습니다. 간단한 프롬프트를 입력하고 2~3번의 코드수정을 거쳐서, 약 10분 만에 아래 화면과 같은 DeepSeek-R1 기반 QnA 사이트를 완성했습니다.
서울대학교_2026학년도_대학입학전형계획.pdf 이 파일을 기반으로 질문하고 답변할수 있는 사이트를 만들어줘
- 구면 내에서 튀는 100개의 노란색 공 생성 스크립트: GPT-4.1은 천천히 회전하는 구 내에서 노란색 공이 머무르면서 충돌 감지를 처리하는 스크립트를 p5.js로 구현하는 데 성공하였습니다.
write a script for 100 bouncing yellow balls within a sphere, make sure to handle collision detection properly. make the sphere slowly rotate. make sure balls stays within the sphere. implement it in p5.js
구면 내에서 100개의 튀는 노란색 공에 대한 스크립트를 작성해줘, 충돌 감지를 제대로 처리해야 해. 구가 천천히 회전하도록 해줘. 공이 구 안에 머무르도록 해줘. p5.js로 구현해줘- 3D 인터랙티브 태양계 애니메이션: 사용자가 자유롭게 확대, 축소, 회전하며 탐색할 수 있는 태양계를 만들고, 각 행성의 공전 애니메이션을 구현하도록 요청한 결과, GPT-4.1은 한 번에 성공하지 못했으나, 여러 번의 피드백과 에러 수정을 통해 아래와 같이 구현에 성공하였습니다.
요청 프롬프트
Create a single-page, interactive, fully 3D solar system exploration web app using pure HTML, CSS, SVG, and JavaScript, enhanced with WebGL
Real-time interactive Solar System animation with Sun and eight planets (Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, Neptune).
User should be able to smoothly navigate by zooming and rotating around the solar system. When a user zooms in or moves close to a planet, a simple informational popup appears automatically next to the planet displaying concise planet details (name, orbit, rotation period, moons, unique features).
No external textures/images allowed—use purely procedural shading, gradients, SVG-based visuals and animations, or fully procedural/WebGL shaders for visuals.
Maintain clean and optimized code for smooth performance.
Prioritize interactivity, visual appeal, smooth animations, and an intuitive user interface.
Additionally, implement planetary orbits with accurate relative speeds around the Sun, ensuring that each planet follows its elliptical trajectory at a speed proportional to its actual orbital period.
- Rubik's 큐브 시뮬레이터: 크기 조정이 가능한 정육면체 큐브의 색을 섞은 후, 전체 면의 색을 다시 맞추는 시뮬레이터 구현에서는 GPT-4.1은 큐브의 각 면을 생성하는 것에 성공하였지만, 회전과 색상을 맞추는 기능을 완전하게 구현하지 못하였습니다.
다음은 GPT-4.1의 코딩, 수학, 추론 성능을 테스트해 보겠습니다. 코딩 성능은 코딩 교육 사이트 edabit.com의 Python, JavaScript, C++ 문제를 통해 테스트하고, 수학 문제는 기하학, 확률, 수열, 최적화, 복합 문제 등으로 구성된 6개의 문제를 사용했습니다. 모든 평가 항목은 재시도 없이 첫 번째 시도의 채점 결과를 그대로 반영하였습니다.
1) 코딩 테스트




| GPT-4.1 | Medium | Hard | Very Hard | Expert |
| Python | Pass | Pass | Pass | Pass |
| JavaScript | Pass | Pass | Pass | Pass |
| C++ | Pass | Pass | Pass | Fail |
코딩 테스트 결과, GPT-4.1은 C++ Expert 난이도 문제를 제외하고 모두 성공하였습니다.
2) 수학 테스트
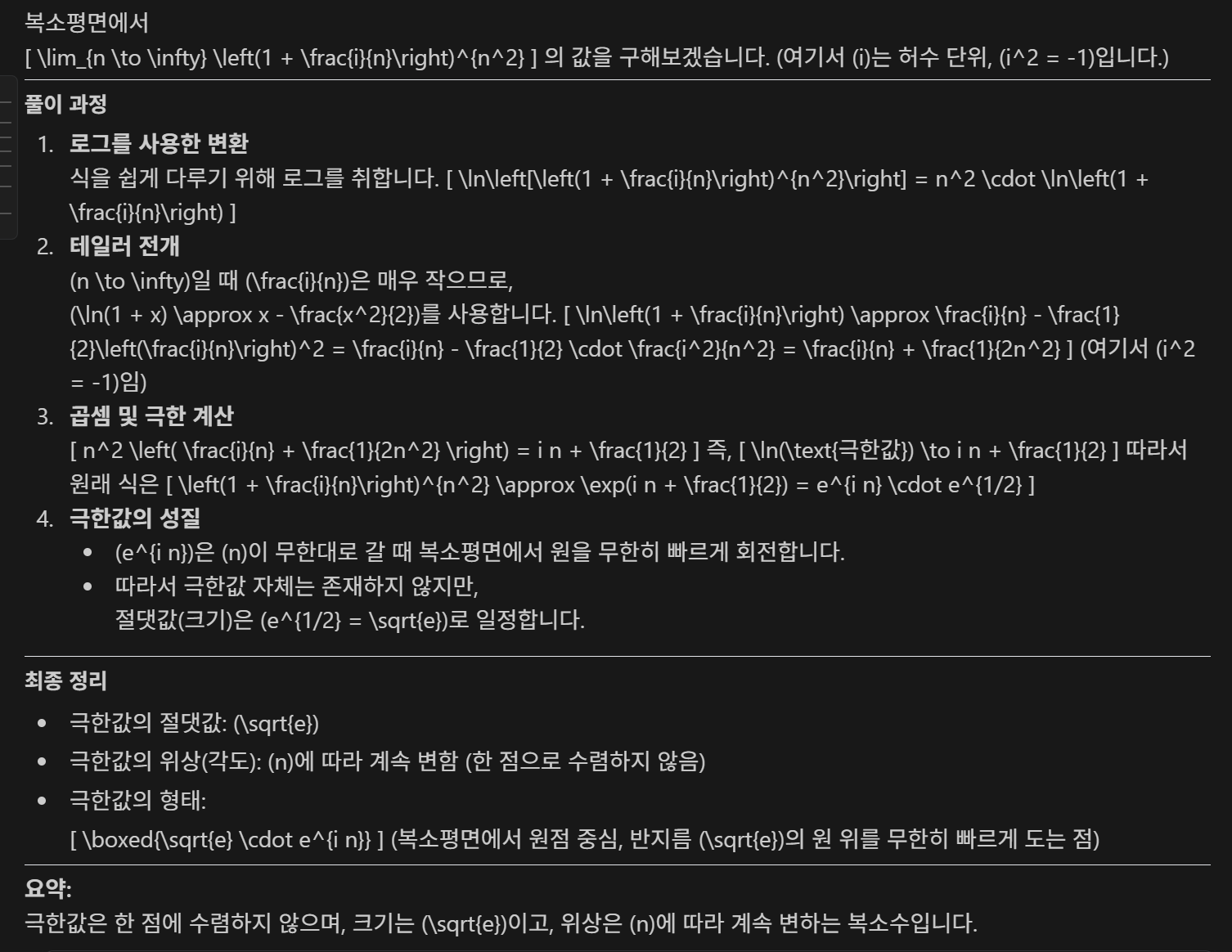
| No. | 문제 구분 | 문제 | GPT-4.1 |
| 1 | 기초 대수 문제 | 두 숫자 𝑥 x와 𝑦 y가 있습니다. 이들이 만족하는 식은 3 𝑥 + 4 𝑦 = 12 3x+4y=12이며, 𝑥 − 2 𝑦 = 1 x−2y=1입니다. 𝑥 x와 𝑦 y의 값을 구하세요 | Pass |
| 2 | 기하학 문제 | 반지름이 7cm인 원의 넓이를 구하세요. 𝜋 = 3.14159 π=3.14159로 계산하세요. | Pass |
| 3 | 확률 문제 | 주사위를 두 번 던졌을 때, 두 숫자의 합이 7이 될 확률을 구하세요. | Pass |
| 4 | 수열 문제 | 첫 번째 항이 3이고, 공차가 5인 등차수열의 10번째 항을 구하세요. | Pass |
| 5 | 최적화 문제 | 어떤 직사각형의 둘레가 36cm입니다. 이 직사각형의 넓이를 최대화하려면 가로와 세로의 길이는 각각 얼마여야 하나요? | Pass |
| 6 | 복합 문제 | 복소평면에서 다음 극한값을 구하시오. lim[n→∞] (1 + i/n)^(n^2) 여기서 i는 허수단위 (i^2 = -1)입니다. | Pass |
수학 테스트에서는 기초 대수, 기하학, 확률, 수열, 최적화, 복합문제 등 여섯 문제를 모두 성공하였습니다.
3) 추론 테스트

| No. | 문제 | GPT-4.1 |
| 1 | 5학년과 6학년 학생 160명이 나무 심기에 참가하였습니다. 6학년 학생들이 각각 평균5그루,5학년 학생들이 각각 평균 3그루씩 심은 결과 모두 560그루를 심었습니다. 나무심기에 참가한 5,6학년 학생은 각각 몇명일까요? |
Pass |
| 2 | 베티는 새 지갑을 위해 돈을 모으고 있습니다. 새 지갑의 가격은 $100입니다. 베티는 필요한 돈의 절반만 가지고 있습니다. 그녀의 부모는 그 목적을 위해 $15를 주기로 결정했고, 할아버지와 할머니는 그녀의 부모들의 두 배를 줍니다. 베티가 지갑을 사기 위해 더 얼마나 많은 돈이 필요한가요? | Pass |
| 3 | 전국 초등학생 수학경시대회가 열렸는데 영희,철수,진호 세사람이 참가했습니다. 그들은 서울,부산,인천에서 온 학생이고 각각 1등,2등,3등 상을 받았습니다. 다음과 같은 사항을 알고 있을때 진호는 어디에서 온 학생이고 몇등을 했습니까? 1) 영희는 서울의 선수가 아닙니다. 2) 철수는 부산의 선수가 아닙니다. 3)서울의 선수는 1등이 아닙니다. 4) 부산의 선수는 2등을 했습니다. 5)철수는 3등이 아닙니다. | Pass |
| 4 | 방 안에는 살인자가 세 명 있습니다. 어떤 사람이 방에 들어와 그중 한 명을 죽입니다. 아무도 방을 나가지 않습니다. 방에 남아 있는 살인자는 몇 명입니까? 단계별로 추론 과정을 설명하세요. | Pass |
| 5 | A marble is put in a glass. The glass is then turned upside down and put on a table. Then the glass is picked up and put in a microwave. Where's the marble? Explain your reasoning step by step. | Pass |
| 6 | 도로에 5대의 큰 버스가 차례로 세워져 있는데 각 차의 뒤에 모두 차의 목적지가 적혀져 있습니다. 기사들은 이 5대 차 중 2대는 A시로 가고, 나머지 3대는 B시로 간다는 사실을 알고 있지만 앞의 차의 목적지만 볼 수 있습니다. 안내원은 이 몇 분의 기사들이 모두 총명할 것으로 생각하고 그들의 차가 어느 도시로 가야 하는지 목적지를 알려 주지 않고 그들에게 맞혀 보라고 하였습니다. 먼저 세번째 기사에게 자신의 목적지를 맞혀 보라고 하였더니 그는 앞의 두 차에 붙여 놓은 표시를 보고 말하기를 "모르겠습니다." 라고 말하였습니다. 이것을 들은 두번째 기사도 곰곰히 생각해 보더니 "모르겠습니다." 라고 말하였습니다. 두명의 기사의 이야기를 들은 첫번째 기사는 곰곰히 생각하더니 자신의 목적지를 정확하게 말하였습니다. 첫번째 기사가 말한 목적지는 어디입니까? | Pass |
GPT-4.1은 추론 성능 테스트 6문제 모두 성공하였습니다.
4) 이미지 인식 테스트
 |
 |
5. 맺음말
GPT-4.1 모델 시리즈는 향상된 코딩 능력, 명령어 추종 능력, 긴 컨텍스트 이해 능력, 그리고 비용 효율성까지 갖춘 차세대 AI 모델로서 개발자들에게 혁신적인 가능성을 제시합니다. 특히 100만 토큰에 달하는 긴 컨텍스트 지원은 이전에는 불가능했던 복잡하고 방대한 규모의 작업을 수행할 수 있도록 지원하며, 다양한 벤치마크 결과에서 뛰어난 성능을 보여줍니다.
GPT-4.1은 이전 모델인 GPT-4o 대비 26% 저렴한 비용으로 제공되며, 긴 컨텍스트 사용에 따른 추가 비용이 없어 개발자들이 더욱 부담 없이 애플리케이션을 구축할 수 있도록 지원합니다. 또한, 가장 작고 빠르며 저렴한 모델인 GPT-4.1-nano는 자동 완성, 분류, 긴 문서에서 정보 추출 등 다양한 애플리케이션에서 뛰어난 성능을 발휘할 것으로 기대됩니다.

2024.07.20 - [AI 언어 모델] - 🚀 GPT-4o mini: OpenAI의 최첨단 고성능 저비용 AI 모델
🚀 GPT-4o mini: OpenAI의 최첨단 고성능 저비용 AI 모델
안녕하세요! 오늘은 OpenAI의 가장 비용 효율적인 소형 모델, GPT-4o mini에 대해서 알아보겠습니다. GPT-4o mini는 입력 토큰 백만 개당 15센트, 출력 토큰 백만 개당 60센트로 가격이 책정되어 있으며,
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 🧠💰Gemini 2.5 Flash: 생각 모드 및 추론 예산 제어하는 차세대 AI (6) | 2025.04.21 |
|---|---|
| 🔍🧬📊o3, o4-mini: GPT-4o에 이은 OpenAI의 차세대 추론 모델 (6) | 2025.04.18 |
| 🐪🖼️ Llama 4: Meta 최초의 MoE 기반 개방형 멀티모달 AI (4) | 2025.04.06 |
| 🤖🔍QVQ-Max: 생각하고 이해하는 알리바바의 최첨단 시각적 추론 AI (6) | 2025.03.31 |
| 👀👂🗣️✍️Qwen2.5-Omni: 보고, 듣고, 말하고, 쓰는 차세대 멀티모달 모델! (1) | 2025.03.30 |



