안녕하세요! 오늘은 유명한 언어 모델 도구 LM Studio의 CLI(Command Line Interface, 명령줄 인터페이스) 업데이트에 대해서 알아보겠습니다. LM Studio는 로컬 컴퓨터에서 로컬 LLM을 실행할 수 있는 데스크톱 애플리케이션으로, 언어 모델 검색/다운로드/관리, 로컬 추론 HTTP서버, OpenAI API 엔드포인트 등 언어 모델을 효율적으로 사용할 수 있는 다양한 기능을 제공하며, 이번에 업데이트된 CLI 기능을 통해서는 주요 기능의 명령줄 인터페이스 수행, 원격작업 및 자동화 등 여러 가지 장점을 제공할 수 있게 되었습니다. 이 블로그에서는 LM Studio의 개요와 CLI 업데이트 적용방법, 로컬 추론 서버와 Chainlit을 활용한 EEVE 챗봇 인터페이스를 만들어 보겠습니다.
Introducing `lms` - LM Studio's companion cli tool | LM Studio
Today, alongside LM Studio 0.2.22, we're releasing the first version of lms — LM Studio's companion cli tool.
lmstudio.ai
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
LM Studio 개요
LM Studio는 로컬 호스트에서 실행 중인 LLM 서버를 통해 텍스트 임베딩 생성 및 자연어 처리 작업을 수행할 수 있으며, OpenAI 호환 방식으로 /v1/chat/completions, /v1/completions, /v1/embeddings와 같은 엔드포인트 요청을 보내거나, JavaScript/TypeScript/Node.js에서 LM Studio의 LLM을 프로그래밍 방식으로 사용할 수 있습니다.
- OpenAI-like 서버: 이 기능을 사용하면 로컬 호스트에서 실행 중인 LLM 서버를 통해 /v1/chat/completions, /v1/completions, /v1/embeddings와 같은 엔드포인트로 요청을 보낼 수 있습니다. 이를 통해 아래 코드와 같이 OpenAI와 유사한 방식으로 로컬 LLM을 사용할 수 있습니다.
# Chat with an intelligent assistant in your terminal
from openai import OpenAI
# Point to the local server
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
history = [
{"role": "system", "content": "You are an intelligent assistant. You always provide well-reasoned answers that are both correct and helpful."},
{"role": "user", "content": "Hello, introduce yourself to someone opening this program for the first time. Be concise."},
]
while True:
completion = client.chat.completions.create(
model="heegyu/EEVE-Korean-Instruct-10.8B-v1.0-GGUF",
messages=history,
temperature=0.7,
stream=True,
)
new_message = {"role": "assistant", "content": ""}
for chunk in completion:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
new_message["content"] += chunk.choices[0].delta.content
history.append(new_message)
print()
history.append({"role": "user", "content": input("> ")})- 텍스트 임베딩 생성: 텍스트를 숫자 벡터로 나타내는 방법으로 LM Studio의 임베딩 서버를 사용하여 로컬에서 텍스트 임베딩을 생성할 수 있습니다. 이는 Retrieval Augmented Generation (RAG) 애플리케이션과 같은 다양한 응용 프로그램에 유용합니다.

- 프로그래밍 방식 지원: JavaScript/TypeScript/Node.js에서 LM Studio의 LLM을 프로그래밍 방식으로 로드하고 사용할 수 있으며, 자신의 코드에 LLM을 활용함으로써 로컬 환경에서 텍스트 생성, 분류, 텍스트 임베딩 생성 등 다양한 자연어 처리 작업을 수행할 수 있습니다.

LM Studio CLI 설치
다음은 CLI 업데이트 방법에 대해 알아보겠습니다. LM Studio의 CLI기능은 사용 편의성, 자동화 및 스크립팅 기능, 유연성, 그리고 최신 기능과 업데이트 제공을 통해 사용자와 LLM간의 효율적인 상호작용을 가능케 합니다. LM Studio CLI의 주요 장점은 다음과 같습니다:
- 편리한 사용: CLI(Command Line Interface)를 통해 간편하게 LM Studio와 상호 작용할 수 있습니다. 명령어를 통해 모델 다운로드, 서버 시작 등의 작업을 쉽게 수행할 수 있습니다.
- 자동화 및 스크립팅: CLI를 사용하면 자동화 및 스크립팅 작업을 수행할 수 있습니다. 자동화를 통해 반복적인 작업을 자동으로 처리하고, 스크립팅을 통해 자신의 작업 흐름에 맞게 LM Studio를 사용할 수 있습니다.
- 유연성: CLI를 사용하면 여러 환경에서 LM Studio를 사용할 수 있습니다. 터미널 또는 스크립트를 통해 원격 서버에서도 LM Studio를 제어할 수 있습니다.
- 새로운 기능 및 업데이트: LM Studio의 새로운 기능과 업데이트는 주로 CLI를 통해 제공됩니다. CLI를 통해 최신 기능을 빠르게 받아볼 수 있습니다.
Introducing `lms` - LM Studio's companion cli tool | LM Studio
Today, alongside LM Studio 0.2.22, we're releasing the first version of lms — LM Studio's companion cli tool.
lmstudio.ai
LM Studio CLI의 설치방법은 다음과 같습니다.
LM Studio CLI를 설치하는 방법은 다음과 같습니다:
- 1. 먼저, LM Studio를 실행하여 최소 한 번 이상 사용합니다. 이 단계를 건너뛰면 lms를 설치할 수 없습니다.
- 2. 터미널을 열고 운영체제에 따라 다음 명령어를 실행하여 lms를 부트스트랩(초기화 및 설정 로드 단계)합니다.
Mac / Linux: ~/.cache/lm-studio/bin/lms bootstrap
Windows: cmd /c %USERPROFILE%/.cache/lm-studio/bin/lms.exe bootstrap
- 3. 새 터미널 창을 열고 아래 화면과 같이 `lms` 명령어를 실행하여 설치가 올바르게 되었는지 확인합니다.

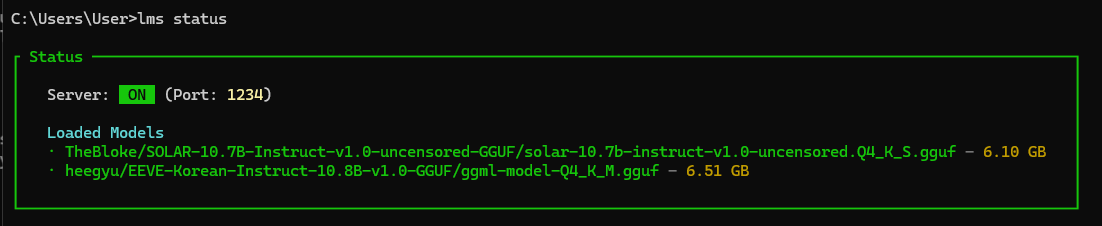
이제 LM Studio CLI(lms)를 사용하여 모델을 로드하고 언로드 하며, 서버를 시작하고 중지하는 등의 작업을 수행할 수 있습니다. 자세한 내용은 `lms --help` 명령을 사용하여 확인할 수 있습니다. 아래 화면은 `lms tatus` 명령어 실행결과로, 추론 HTTP 서버의 실행상태와, 로드된 언어 모델을 확인할 수 있습니다.
`lms ls` 명령어는 다운로드된 모델의 목록을 보여주는 명령어이며, 모델명, 크기, 아키텍처 등이 표시되고, 처음 실행하면 아래 화면과 같이 서버 자동시작 여부에 대해 확인을 물어봅니다.

`lms server start/stop` 명령어는 로컬 추론 HTTP 서버 프로세스를 시작/종료하는 명령어이며, 실행결과는 아래 화면과 같으며, 추론 HTTP 서비스 주소는 http://localhost:1234/v1 입니다.

아래 화면은 로컬 언어 모델을 로드하는 명령어로, `lms load 모델명 --옵션' 형태이며, --gpu 옵션은 LM Studio CLI를 사용하여 모델을 실행할 때 GPU를 이용하는 비율을 지정하는 옵션입니다. 이 옵션을 사용하면 모델이 GPU를 얼마나 활용할지를 설정할 수 있습니다.

아래 화면은 `lms log stream` 명령어 실행화면으로 LM Studio에서 발생하는 이벤트에 대한 실시간 로그가 표시됩니다.

Chainlit 인터페이스 실행
Chainlit은 대화형 AI를 구축하기 위한 오픈 소스 Python 패키지입니다. 기존 코드에 쉽게 통합되며 데이터 수집, 다단계 추론 시각화, 프롬프트 디버깅 등의 기능을 제공하고, OpenAI, LangChain, Autogen 등의 라이브러리와 통합되어 있으며, 사용자 정의 프론트엔드와 함께 사용할 수 있습니다.
https://docs.chainlit.io/get-started/overview
Overview - Chainlit
Build Conversational AI with Chainlit
docs.chainlit.io
다음은 LM Studio 로컬 추론 서버와 Chainlit을 활용해서 EEVE 챗봇 인터페이스를 만들어 보겠습니다. EEVE는 야놀자의 대형 언어 모델로, 파라미터 동결, 서브워드 기반 임베딩 초기화, 다단계 학습과 같은 접근방법을 통해 기존의 영어 언어 모델을 한국어 모델로 확장하고 새로운 언어 토큰을 통합한 모델입니다. 자세한 내용은 아래 포스트를 참고하시기 바랍니다.
2024.04.13 - [AI 언어 모델] - [AI 논문] 올해의 한국어 LLM에 선정된 야놀자 언어 모델, EEVE
[AI 논문] 올해의 한국어 LLM에 선정된 야놀자 언어 모델, EEVE
안녕하세요! 오늘은 최근 "올해의 한국어 LLM"으로 선정된 야놀자의 대형 언어 모델, EEVE에 대해 살펴보겠습니다. EEVE모델은 Efficient and Effective Vocabulary Expansion의 약자로, 효율적이고 효과적인 어
fornewchallenge.tistory.com
예제코드의 실행환경은 Windows 11 Pro(23H2), 파이썬 버전 3.11, 비주얼 스튜디오 코드 1.39이며, 작업순서는 다음과 같습니다.
- 1. LM Studio 서버 시작
- 2. EEVE 언어 모델 다운로드 및 로딩
- 3. 파이썬 가상환경 생성 및 활성화
- 4. 의존성 라이브러리 설치
- 5. 코드 작성 및 Chainlit 실행
먼저 LM Studio 서버 시작단계입니다. 다음 화면과 같이 위에서 설치한 LM Studio CLI 명령어를 통해 서버를 시작합니다.
lms server start
다음은 EEVE 언어 모델 다운로드 및 로딩단계로, LM Studio 좌측 돋보기 메뉴를 클릭하고 "heegyu/EEVE-Korean-Instruct-10.8B-v1.0-GGUF" 모델을 검색하여 우측화면에서 컴퓨터 사양에 맞는 적절한 크기의 모델을 다운로드합니다.

EEVE 언어 모델 로딩은 아래의 명령어를 사용해서 실행할 수 있습니다.
lms load heegyu/EEVE-Korean-Instruct-10.8B-v1.0-GGUF --gpu=max
다음은 파이썬 가상환경 생성 및 활성화단계입니다. 아래 명령어 중 myenv는 원하는 이름으로 설정할 수 있습니다.
conda create -n myenv python=3.11
conda activate myenv
다음은 의존성 라이브러리 설치단계인데요. 아래 명령어를 통해 openai와 chainlit 라이브러리를 설치해 줍니다.
pip install openai chainlit
다음은 코드 작성단계입니다. 코드의 출처는 유튜브 "LM Studio CLI: Speed Up Your AI App Development (100% Local + UI)"이며, 모델명, 프롬프트 등을 수정하였습니다. 이 코드는 Chainlit 및 OpenAI의 AsyncOpenAI 클라이언트를 사용하여 대화형 챗봇을 구축하는 예시이며, 동작 순서와 기능 설명은 다음과 같습니다.
- 1. `AsyncOpenAI` 클라이언트를 구성하고 로컬 LM Studio API 서버에 연결합니다.
- 2. 챗봇의 설정을 지정합니다. LM Studio 모델과 대화 생성을 제어하는 여러 매개변수가 포함됩니다.
- 3. `@cl.on_chat_start` 데코레이터를 사용하여 챗봇 대화의 시작 부분에서 실행될 함수를 정의합니다. 이 함수는 챗봇이 초기화될 때 메시지 히스토리를 설정합니다.
- 4. `@cl.on_message` 데코레이터를 사용하여 메시지가 수신되었을 때 실행될 함수를 정의합니다. 이 함수는 사용자로부터 메시지를 받고, LM Studio 모델에 이전 대화 내용을 제공하여 새로운 응답을 생성합니다.
- 5. 메시지 히스토리를 업데이트하고 LM Studio 모델을 사용하여 챗봇 응답을 생성합니다. 이때, `streaming`을 사용하여 부분적인 응답을 처리합니다.
- 6. 생성된 부분적인 응답을 사용자에게 전송하고, 대화 히스토리에 새로운 메시지와 챗봇의 응답을 추가합니다.
이 코드는 사용자와 챗봇 간의 대화를 처리하고, LM Studio를 통해 생성된 응답을 받아 사용자에게 제공하는 과정을 자동화하는 예제입니다. 아래 코드를 복사하여 가상환경이 활성화된 상태의 VSCode에서 새 파이썬 파일 생성 후 붙여 넣습니다.
import chainlit as cl
from openai import AsyncOpenAI
# Configure the async OpenAI client
client = AsyncOpenAI(api_key="lm-studio", base_url="http://localhost:1234/v1")
settings = {
"model": "heegyu/EEVE-Korean-Instruct-10.8B-v1.0-GGUF/ggml-model-Q4_K_M.gguf",
"temperature": 0.7,
"max_tokens": 4096,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0
}
@cl.on_chat_start
def start_chat():
# Initialize message history
cl.user_session.set("message_history", [{"role": "system", "content": "You are a helpful chatbot. Answer only in Korean language"}])
@cl.on_message
async def main(message: cl.Message):
# Retrieve the message history from the session
message_history = cl.user_session.get("message_history")
message_history.append({"role": "user", "content": message.content})
# Ensure message history contains valid message objects
valid_messages = [{"role": msg["role"], "content": msg["content"]} for msg in message_history if msg.get("content")]
# Create an initial empty message to send back to the user
msg = cl.Message(content="")
await msg.send()
# Use streaming to handle partial responses
stream = await client.chat.completions.create(messages=valid_messages, stream=True, **settings)
async for part in stream:
if token := part.choices[0].delta.content or "":
await msg.stream_token(token)
# Append the assistant's last response to the history
message_history.append({"role": "assistant", "content": msg.content})
cl.user_session.set("message_history", message_history)
# Update the message after streaming completion
await msg.update()
다음은 아래 명령어를 통해 Chainlit 인터페이스를 실행합니다.
chainlit run ui.py
다음은 블랙홀에 대한 질문에 EEVE 모델이 응답한 화면입니다.


맺음말
오늘은 LM Studio CLI를 활용하여 EEVE 챗봇 인터페이스를 구축하는 방법을 알아보았습니다. LM Studio는 로컬 컴퓨터에서 로컬 LLM을 실행할 수 있는 데스크톱 애플리케이션이며, CLI는 주요 기능의 명령줄 인터페이스 수행, 원격 작업 및 자동화 등 여러 가지 장점을 제공합니다.
블로그에서는 LM Studio 개요 및 CLI 설치 방법과 EEVE 언어 모델 다운로드, Chainlit 인터페이스 구축 등에 대해 알아보고 로컬 컴퓨터에서 간편하게 챗봇 인터페이스를 구축해 보았습니다. 이 블로그가 LM Studio CLI와 Chainlit을 활용하시는 데 도움이 되었기를 바라면서 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.04.17 - [AI 언어 모델] - 야놀자 한국어 언어 모델 EEVE와 Ollama로 구현하는 로컬 RAG
야놀자 한국어 언어 모델 EEVE와 Ollama로 구현하는 로컬 RAG
안녕하세요! 오늘은 한국어 언어 모델 EEVE를 활용해서 로컬 RAG을 구현해 보겠습니다. RAG(Retrieval-Augmented Generation, 검색 강화 생성)는 외부 지식소스 검색을 통해 정보를 얻고, 이를 바탕으로 답변
fornewchallenge.tistory.com
'AI 도구' 카테고리의 다른 글
| Librechat: 온라인, 오프라인 AI 모델을 통합한 오픈소스 챗봇 플랫폼 (2) | 2024.05.15 |
|---|---|
| 엑셀과 대화: PandasAI와 Ollama활용 6줄 코드로 Llama3 챗봇 만들기 (0) | 2024.05.12 |
| Ollama 기반 인공지능 노트 앱 Reor: 한국어 모델 EEVE 적용 및 설정 가이드 (0) | 2024.05.10 |
| Msty와 Open WebUI: 직관적인 UI와 로컬 RAG까지 지원하는 언어 모델 활용 도구 (0) | 2024.05.07 |
| 누구나 할 수 있는 AI 코딩! Llama3와 Claude3로 벽돌깨기 게임 1분 컷! (0) | 2024.05.04 |



