안녕하세요! 오늘은 구글에서 최근 발표한 비디오 생성 AI, 뤼미에르에 대해서 알아보겠습니다. 뤼미에르는 시공간 U-Net 아키텍처를 기반으로 텍스트에서 비디오로의 변환을 위한 혁신적인 확산 모델로, 공간 및 시간 다운샘플링, 업샘플링을 결합하여 전체 비디오를 한 번에 생성하는 기능을 제공합니다. 이 모델은 다양한 화질과 일관된 움직임을 보여주며 다른 T2V 모델과 비교했을 때 높은 품질의 비디오 생성을 실현합니다. 이 블로그에서는 시공간 U-Net 아키텍처가 무엇인지 알아보고 시공간 U-Net 아키텍처의 구성요소, 동작원리, 뤼미에르 모델 성능평가에 대해서 확인하실 수 있습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문 개요 및 목적
이 논문은 "Lumiere: A Space-Time Diffusion Model for Video Generation"이라는 제목으로 Google Research에 의해 2024년 2월에 발표되었습니다. 이 논문은 텍스트를 기반으로 비디오를 생성하는 혁신적인 방법을 제시하고 있습니다
- 논문제목: Lumiere: A Space-Time Diffusion Model for Video Generation n
- 논문저자 :GOOGLE RESEARCH
- 논문게재 사이트: https://arxiv.org/abs/2401.12945
- 논문게재일 : 2024.02


이 논문의 목적은 텍스트 입력에 대해 고품질 비디오를 생성하는 새로운 방법을 제시하는 것입니다. 이를 통해 기존의 비디오 생성 기술에 비해 더 나은 시공간 일관성과 시각적 품질을 달성할 수 있습니다.
논문의 연구내용 및 결과
이 논문에서는 시공간 확산 모델(Space-Time Diffusion Model)을 사용하여 텍스트를 기반으로 비디오를 생성하는 방법을 제안합니다. 이 모델은 텍스트 입력을 받아 공간적 및 시간적 일관성을 유지하면서 고품질의 비디오를 생성합니다.
시공간 U-Net 아키텍처 구성요소
논문에서 제안하는 기술은 시공간 U-Net 아키텍처를 기반으로 합니다. 이 아키텍처는 공간적 및 시간적 다운샘플링 및 업샘플링 모듈을 통해 비디오를 생성합니다. 다음은 뤼미에르의 시공간 U-Net 아키텍처 개념도입니다.
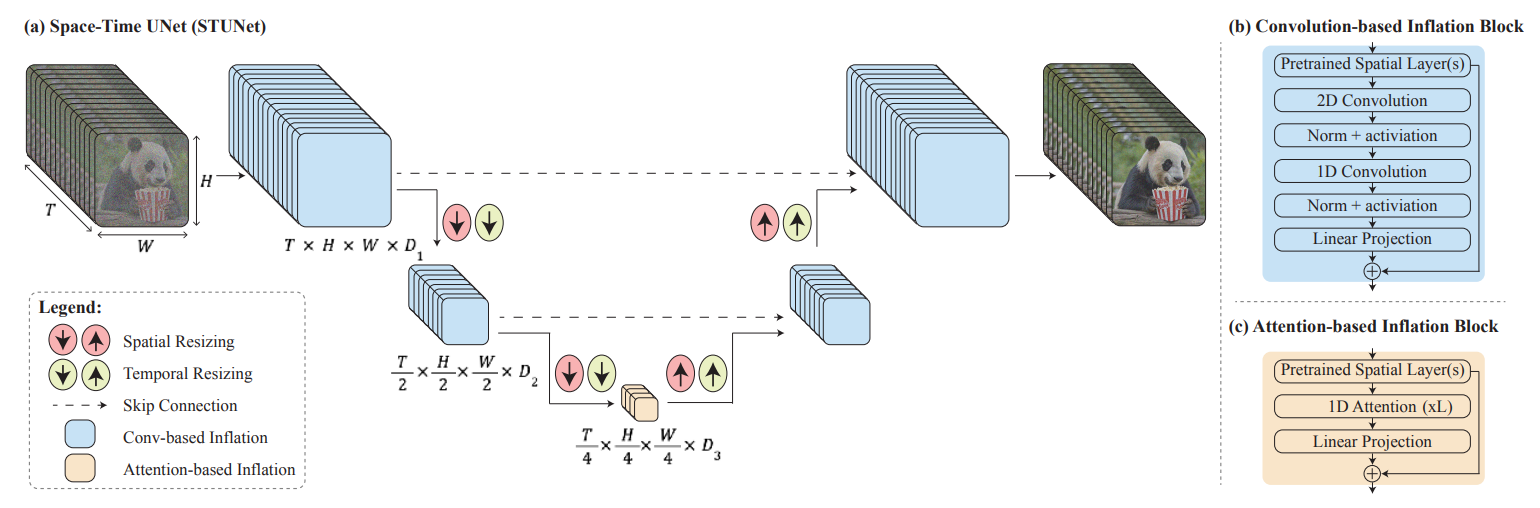
Space-Time U-Net (STUnet)은 비디오 생성에 사용되는 신경망 아키텍처입니다. 이 아키텍처는 기존의 이미지 생성 모델인 U-Net을 확장하여 공간 및 시간 차원에서 비디오를 처리할 수 있도록 설계되었습니다. STUnet은 비디오의 전체 시간적 지속성을 한 번에 생성하는 것이 특징입니다. STUnet은 다음과 같은 주요 구성 요소로 구성됩니다.
아래 더 보기를 클릭하시면 U-Net에 대해서 더 확인하실 수 있습니다.
U-Net은 딥러닝에서 사용되는 네트워크 아키텍처 중 하나로, 이미지 세그멘테이션 및 영상 처리 작업에 주로 사용됩니다. U-Net은 2015년에 Olaf Ronneberger 등에 의해 처음으로 소개되었습니다.
U-Net은 그 형태가 U 모양을 띠어서 그렇게 불리며, 인코더와 디코더로 구성됩니다. 인코더는 입력 이미지를 점차적으로 다운샘플링하여 특징을 추출하는 역할을 합니다. 반면에 디코더는 다운샘플링된 특징을 업샘플링하여 입력 이미지의 크기와 동일한 크기로 복원하고 세그멘테이션을 수행합니다. 이때 인코더와 디코더 간에는 스킵 연결이 존재하여, 다운샘플링 과정에서 손실된 공간적 정보를 보존하고 디코더에서 복원하는 데 도움을 줍니다.
U-Net은 주로 의료 영상에서 종양 분할, 세포 감지 등과 같은 의미 있는 객체를 분할하는 작업에서 많이 사용되지만, 다른 영상 처리 작업에서도 효과적으로 적용될 수 있습니다.
- 공간-시간 다운샘플링 블록: 이 블록은 비디오의 공간적 차원(가로, 세로)과 시간적 차원(프레임)을 동시에 다운샘플링합니다. 즉, 비디오의 공간적 및 시간적 해상도를 줄여서 모델이 더 빠르고 효율적으로 처리할 수 있도록 돕습니다.
- 공간-시간 업샘플링 블록: 이 블록은 다운샘플링 된 비디오의 공간적 및 시간적 해상도를 다시 늘려줍니다. 이를 통해 모델은 더 높은 해상도의 비디오를 생성할 수 있습니다.
- 컨볼루션 및 어텐션 레이어: STUnet은 비디오의 공간적 및 시간적 특징을 추출하기 위해 컨볼루션 레이어와 어텐션 메커니즘을 사용합니다. 이러한 레이어는 비디오의 각 프레임에서 중요한 정보를 추출하여 모델이 비디오를 생성할 때 고려할 수 있도록 돕습니다. 아래 더 보기를 클릭하시면 컨볼루션 및 어텐션 레이어에 대해 확인하실 수 있습니다.
컨볼루션 레이어(Convolution Layer)는 딥러닝에서 주로 이미지 처리에 사용되는 레이어 중 하나입니다. 이 레이어는 입력 데이터에 대해 필터(커널)를 이용하여 특징 맵(feature map)을 만들어냅니다. 각 필터는 입력 이미지를 스캔하면서 특정한 특징을 감지하고, 이를 특징 맵에 반영합니다. 이 과정을 통해 이미지의 다양한 특징을 추출할 수 있습니다. 컨볼루션 레이어는 가중치(weight)를 공유하고, 입력 데이터를 지역적으로 연결하여 계산을 수행하므로, 일반적으로 연산량이 적고 효율적으로 특징을 추출할 수 있습니다.
어텐션 메커니즘(Attention Mechanism)은 딥러닝 모델에서 입력의 특정 부분에 더 집중하도록 하는 메커니즘입니다. 주로 시퀀스 데이터(예: 자연어 문장)를 처리할 때 사용되며, 입력의 각 부분에 대한 중요성을 동적으로 학습하여 해당 부분에 가중치를 부여합니다. 이를 통해 모델이 입력의 중요한 부분에 집중하여 더 정확한 예측을 할 수 있게 됩니다. 어텐션 메커니즘은 주로 Seq2Seq(Sequence-to-Sequence) 모델에서 사용되며, 번역, 요약, 질문 응답 등의 작업에서 성능을 향상시키는 데에 효과적으로 활용됩니다. 최근에는 이미지 처리에서도 어텐션 메커니즘이 활용되고 있으며, 이미지의 특정 부분에 더 집중하여 작업을 수행하는 데에 활용됩니다.
- 잔차 연결: STUnet은 잔차 연결을 사용하여 입력과 출력 간의 차이를 나타내는 잔차(Residual)를 학습하여 학습의 안정성과 성능을 향상시킵니다. 잔차 연결(Residual Connection)은 딥러닝 네트워크의 여러 층을 연결하는 방법 중 하나로 네트워크가 깊어질수록 발생하는 그래디언트(각 파라미터 손실 함수의 기울기) 소실 문제를 해결합니다.
이러한 구성 요소들을 조합하여 STUnet은 공간적 및 시간적으로 일관된 비디오를 생성하는 강력한 모델로 작동합니다. 이 모델은 전체 비디오를 한 번에 생성하기 때문에 기존의 시간적 캐스케이드 설계에 비해 더 좋은 전체적인 시간적 일관성을 제공합니다. 다음은 시간적 캐스케이드 설계와 STUnet의 비교표입니다.
| 요소 | 시간적 캐스케이드 설계 | Space-Time U-Net (STUnet) |
| 설계 방식 | 여러 모델의 연속적인 적용으로 구성됨 | 단일 모델 내에서 전체적으로 처리 |
| 시간적 일관성 | 전체적인 일관성이 낮을 수 있음 | 더 높은 전체적인 일관성을 가짐 |
| 처리 방식 | 연속적인 특징 추출 후 보간 | 공간 및 시간 다운샘플링 및 보간 |
| 계산 효율성 | 병렬적이지 않을 수 있음 | 병렬적인 처리 가능 |
시공간 U-Net 아키텍처 원리 및 동작순서
사용자가 텍스트를 입력하여 비디오를 생성하는 일련의 과정은 다음과 같습니다:
- 1. 텍스트 입력: 사용자는 생성하고자 하는 비디오의 내용을 텍스트로 입력합니다. 이 텍스트는 뤼미에르 모델의 입력 신호가 됩니다.
- 2. 텍스트 처리: 입력된 텍스트는 먼저 모델 내부에서 처리됩니다. 이 처리 과정은 텍스트를 이해하고 비디오로 변환하는 데 필요한 정보를 추출하는 단계입니다. 이 단계에서는 텍스트의 의미를 이해하고 해당 내용에 대한 비디오를 생성할 수 있는 방향으로 가이드합니다.
- 3. 텍스트를 비디오로 변환: 처리된 텍스트 정보는 시공간 U-Net 아키텍처를 통해 비디오로 변환됩니다. 이 아키텍처는 입력된 텍스트에 기반하여 비디오의 각 프레임을 생성합니다. 시공간 U-Net은 텍스트에 대한 이해를 바탕으로 각각의 프레임을 생성하고 비디오로 연결하여 전체 비디오를 생성합니다.
- 4. 비디오 생성 및 출력: 시공간 U-Net을 통해 생성된 비디오는 모델의 출력으로 제공됩니다. 이 비디오는 입력된 텍스트에 따라 생성된 내용을 시각적으로 보여주는 것입니다.
이와 같은 과정을 통해 사용자가 입력한 텍스트를 기반으로 비디오가 생성되어 출력됩니다. 위 과정 중에서 시공간 U-Net 아키텍처의 동작순서는 다음과 같습니다.
- 1. 입력 데이터 준비: STUnet의 입력은 비디오 프레임 시퀀스로 구성됩니다. 각 프레임은 이미지로 표현되며, 비디오의 시간적 흐름을 나타냅니다. 입력된 비디오 프레임 시퀀스는 모델에 의해 공간 및 시간 차원으로 처리되어 비디오를 생성합니다.
- 2. 공간-시간 다운샘플링: STUnet은 공간적 및 시간적 차원에서 다운샘플링을 수행하여 입력된 비디오를 처리합니다. 이는 모델이 보다 효율적으로 비디오를 다룰 수 있도록 합니다.
- 3. 컨볼루션 및 어텐션 레이어: 다운샘플링된 비디오는 컨볼루션 및 어텐션 레이어를 통해 특징을 추출하고 처리합니다. 이 과정에서 비디오의 공간적 및 시간적 특성이 모델에 반영됩니다.
- 4. 공간-시간 업샘플링: 추출된 특징은 공간적 및 시간적 업샘플링을 거쳐 다시 높은 해상도의 비디오로 변환됩니다. 이 과정에서 비디오의 세부 정보가 복원되고 강화됩니다. 업샘플링 과정에서 다중확산(Multidiffusion)을 적용합니다. 다중확산은 아래 더 보기를 클릭하시면 더 자세하게 확인하실 수 있습니다.
다중확산(Multidiffusion)은 고해상도에 대한 효과적인 해결책으로 제안되었습니다. 일반적으로 SSR (Spatial Super-Resolution) 모델은 비디오를 고해상도로 업샘플링하기 위해 사용됩니다. 그러나 SSR 모델은 전체 비디오에 대한 연산을 수행하기에는 메모리 요구 사항이 매우 높기 때문에 일반적으로 시간적 창을 이용하여 입력 비디오를 작은 세그먼트로 나누고 각 세그먼트에 SSR 모델을 적용합니다. 이것은 세그먼트 간의 경계에서 일관성 문제를 일으킬 수 있습니다. 다중확산은 이러한 문제를 해결하기 위해 제안된 방법입니다.
다중확산은 고해상도에 대한 일관성을 유지하기 위해 비디오를 다시 구성하는 과정에서 사용됩니다. 이 방법은 공간적으로 연속된 프레임의 세그먼트를 고려하여 공간적 SSR을 적용합니다. 그런 다음 이러한 SSR 세그먼트를 시간적으로 조합하여 비디오의 전체적인 해상도를 향상시킵니다. 따라서 다중확산은 SSR 모델을 적용할 때 세그먼트 간의 일관성 문제를 완화하고 고해상도 비디오의 일관된 외관을 유지하기 위해 사용됩니다. 이를 통해 뤼미에르 모델은 고해상도 비디오를 생성하는 과정에서 보다 일관된 결과를 달성할 수 있습니다.
- 5. 잔차 연결: STUnet은 잔차 연결을 사용하여 입력과 출력 간의 잔차를 학습합니다. 이를 통해 모델의 학습이 안정화되고 성능이 향상됩니다.
- 6. 출력 생성: 최종적으로, 업샘플링된 공간 및 시간 특징을 기반으로 STUnet은 전체 비디오를 한 번에 생성합니다. 이렇게 생성된 비디오는 입력된 비디오 프레임 시퀀스의 공간적 및 시간적 특성을 고려하여 일관된 시간적 흐름을 보여줍니다.
이러한 방식으로 STUnet은 공간 및 시간 차원에서 비디오를 처리하고 생성하는 데 사용됩니다. 이는 전체 비디오를 한 번에 생성하기 때문에 기존의 시간적 캐스케이드 설계에 비해 더 좋은 전체적인 시간적 일관성을 제공합니다.
뤼미에르 모델 성능평가 결과
다음 표는 뤼미에르 모델을 ImagenVideo, AnimateDiff, ZeroScope 등 기준 모델과 성능을 비교 평가한 결과입니다.

위 성능평가 방법은 두 가지 대안 강제 선택 프로토콜을 채택하였으며, 이 프로토콜에서 참가자들은 무작위로 선택된 두 개의 비디오 중 하나를 뤼미에르 모델이 생성한 것과 다른 기준 모델 중 하나를 선택하도록 요청되었습니다. 참가자들은 시각적 품질과 움직임 측면에서 더 우수한 비디오를 선택하고, 또한 주어진 텍스트 프롬프트와 더 일치하는 비디오를 선택하도록 요청되었습니다. 각 기준 모델과 질문당 약 400개의 사용자 판단을 수집했으며, 위 결과에서 볼 수 있듯이, 사용자들은 뤼미에르를 기준 모델보다 선호했으며 텍스트 프롬프트와의 더 나은 일치를 보여주었습니다.
아래 그림은 뤼미에르 모델과 Pika, ImagenVideo 등 기준 모델들 간의 품질 비교입니다.

Gen-2(RunwayML, 2023)와 Pika(Pika labs, 2023)는 프레임 당 시각적 품질이 높지만, 그들의 출력물은 매우 제한된 움직임을 보이며 종종 정지된 비디오로 나타납니다. ImagenVideo(Ho et al., 2022a)는 합리적인 움직임을 보이지만 전반적인 시각적 품질은 낮습니다. AnimateDiff(Guo et al., 2023)와 ZeroScope(Wang et al., 2023a)는 뚜렷한 움직임을 보이지만 시각적인 아티팩트에 취약합니다. 더구나, 그들은 각각 2초와 3.6초의 짧은 기간의 비디오를 생성합니다. 이에 비해, 뤼미에르는 시간적 일관성과 전반적인 품질을 유지하면서 더 높은 움직임 강도를 갖는 5초짜리 비디오를 생성합니다.
논문에서는 위 성능평가 결과에서 제안된 방법이 다른 비디오 생성 기술에 비해 높은 품질의 비디오를 생성한다는 것을 실험적으로 입증합니다. 성능평가 결과는 다양한 지표를 사용하여 제안된 방법이 우수한 성능을 보인다는 것을 보여줍니다.

논문의 결론 및 전망
이 논문은 사전 훈련된 텍스트-이미지 확산 모델을 활용한 새로운 텍스트에서 비디오로의 변환 프레임워크를 제시했습니다. 기존의 접근법의 한계를 해결하기 위해 공간 및 시간 다운샘플링 및 업샘플링 모듈을 모두 통합한 시공간 U-Net 아키텍처를 소개합니다. 이러한 방법을 통해 최첨단 생성 결과를 증명하고, 이미지에서 비디오로, 비디오 인페인팅, 스타일화된 생성 등 다양한 응용 분야에 적용될 수 있는 가능성을 입증하였습니다.
그러나 뤼미에르는 여러 샷으로 이루어진 비디오나 장면 간 전환을 포함하는 비디오 생성에는 아직 한계가 있으며, 픽셀 공간에서 작동하는 T2I 모델을 기반으로 하고 있어 고해상도 이미지를 생성하기 위해 공간 초고해상도 모듈을 필요로 합니다. 뤼미에르 모델에 적용된 아키텍처는 잠재적 비디오 확산 모델에도 적용이 가능하며, 이를 통해 텍스트에서 비디오로의 모델 설계에 대한 추가 연구를 촉진할 수 있습니다.
오늘은 구글에서 발표한 비디오 생성 AI, 뤼미에르에 적용한 시공간 U-Net 아키텍처가 무엇인지 알아보고 시공간 U-Net 아키텍처의 구성요소, 동작원리, 뤼미에르 모델 성능평가에 대해서 알아보았습니다. 앞으로 뤼미에르와 같은 혁신적인 기술이 비디오 생성 및 관련 응용 분야에서 더 많은 발전을 이끌어내기를 기대하면서 저는 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2024.02.04 - [AI 논문 분석] - OLMo(Open Language Model) : 완전한 오픈소스 대형 언어 모델
OLMo(Open Language Model) : 완전한 오픈소스 대형 언어 모델
안녕하세요! 최근 언어 모델이 자연어 처리 연구와 상업 제품에서 더욱 보편화되면서, 모델의 편향과 잠재적인 위험을 이해하기 위한 훈련 데이터와 아키텍처 및 개발에 대한 세부 정보가 중요
fornewchallenge.tistory.com
'AI 논문 분석' 카테고리의 다른 글
| [AI 논문] EMO: 사진 1장과 음성으로 되살린 오드리 헵번의 생생한 표정! (2) | 2024.02.28 |
|---|---|
| 🚀 SDXL-Lightning: 스테이블 디퓨전 기반 초고속 이미지 생성 기술 심층 분석 (2) | 2024.02.23 |
| OLMo(Open Language Model) : 완전한 오픈소스 대형 언어 모델 (0) | 2024.02.04 |
| [AI 논문] InstantID: 얼굴 사진 한장으로 딥페이크 생성 (0) | 2024.02.02 |
| 코드생성 AI AlphaCodium: 프롬프트 엔지니어링에서 플로우 엔지니어링으로 (0) | 2024.02.01 |



