오늘은 Alibaba가 새롭게 공개한 차세대 언어 모델, Qwen3 시리즈에 대해 알아보겠습니다. 이 모델들은 이전 세대 Qwen2.5를 뛰어넘는 진화된 AI 모델로, 단순한 언어 이해를 넘어선 하이브리드 추론 능력, 강화된 다국어 처리 성능, 그리고 유연한 에이전트 실행 능력까지 갖춘 것이 특징입니다. 특히 Qwen3-235B-A22B는 2350억 파라미터를 탑재한 초거대 모델임에도 추론 시에는 단 220억 파라미터만을 활성화하는 MoE(Mixture of Experts) 구조를 채택해 고성능과 고효율을 동시에 실현했습니다. 이번 블로그에서는 Qwen3 시리즈의 전체 라인업부터, 기술적 특징, 벤치마크 성능, 그리고 실제 테스트 결과까지 꼼꼼히 살펴보겠습니다.

1. Qwen3 개요
Qwen3는 알리바바 그룹이 개발한 Qwen 모델 제품군의 최신 세대입니다. 이 모델은 하이브리드 추론 능력, 다국어 이해 및 효율적인 확장에 최적화되어 있습니다. Qwen3 시리즈는 이전 Qwen 모델을 기반으로 확장되었으며, 밀집형(Dense) 모델과 MoE(Mixture of Experts) 아키텍처의 광범위한 포트폴리오를 제공합니다. 이러한 아키텍처 설계는 다양한 애플리케이션 시나리오에 맞는 유연한 옵션을 제공합니다.
https://qwenlm.github.io/blog/qwen3/
Qwen3: Think Deeper, Act Faster
QWEN CHAT GitHub Hugging Face ModelScope Kaggle DEMO DISCORD Introduction Today, we are excited to announce the release of Qwen3, the latest addition to the Qwen family of large language models. Our flagship model, Qwen3-235B-A22B, achieves competitive res
qwenlm.github.io
|
모델 종류
|
모델 이름/크기
|
컨텍스트 길이
|
총 파라미터 수/추론 활성
|
라이선스
|
|
밀집형(Dense) 모델
|
Qwen3-0.6B
|
32K
|
0.6억
|
Apache 2.0
|
|
밀집형(Dense) 모델
|
Qwen3-1.7B
|
32K
|
1.7억
|
Apache 2.0
|
|
밀집형(Dense) 모델
|
Qwen3-4B
|
32K
|
40억
|
Apache 2.0
|
|
밀집형(Dense) 모델
|
Qwen3-8B
|
128K
|
80억
|
Apache 2.0
|
|
밀집형(Dense) 모델
|
Qwen3-14B
|
128K
|
140억
|
Apache 2.0
|
|
밀집형(Dense) 모델
|
Qwen3-32B
|
128K
|
320억
|
Apache 2.0
|
|
MoE(Mixture of Experts) 모델
|
Qwen3-30B-A3B
|
128K
|
300억/30억
|
Apache 2.0
|
|
MoE(Mixture of Experts) 모델
|
Qwen3-235B-A22B
|
128K
|
2350억/220억
|
Apache 2.0
|
Qwen3 모델 제품군은 다양한 파라미터 규모를 포함합니다:
1) 밀집형(Dense) 모델: 0.6B, 1.7B, 4B, 8B, 14B, 32B 파라미터 모델이 있습니다. 이 모델들은 Apache 2.0 라이선스 하에 오픈 소스로 공개되었습니다.
2) MoE(Mixture of Experts) 모델: 30B-A3B와 235B-A22B 두 가지 모델이 있습니다.
- Qwen3-30B-A3B는 총 300억 개의 파라미터를 가지고 있지만, 추론 시에는 30억 개의 활성 파라미터만 사용합니다.
- Qwen3-235B-A22B는 총 2350억 개의 파라미터를 가지고 있으며, 추론 시에는 220억 개의 활성 파라미터만 사용합니다. MoE 아키텍처는 활성 파라미터를 여러 배 늘려 모델 능력을 크게 향상시키면서도 추론 효율성을 유지하는 장점이 있습니다.
Qwen3 모델들은 다양한 컨텍스트 길이(Context Length)를 지원합니다. 0.6B, 1.7B, 4B 모델은 32K 토큰의 컨텍스트 길이를 지원하며, 8B, 14B, 32B 밀집형 모델과 MoE 모델들은 최대 128K 토큰의 컨텍스트 길이를 지원합니다. 이처럼 광범위한 제품 라인업은 모바일 장치부터 클라우드 서버까지 다양한 배포 요구사항을 충족할 수 있게 해줍니다.
Qwen Chat
Current System does not Support Qwen is actively working to ensure compatibility with the current system.
chat.qwen.ai
2. Qwen3 특징 및 주요 기능
Qwen3는 이전 세대 모델 대비 여러 가지 주요 특징과 기능을 통해 차별화됩니다.
1) 하이브리드 사고 모드 (Hybrid Thinking Modes): Qwen3 모델의 핵심 혁신 중 하나는 동적으로 "사고(thinking)" 모드와 "비사고(non-thinking)" 모드를 전환할 수 있는 능력입니다.
- 사고 모드: 이 모드에서 모델은 최종 답변을 제공하기 전에 단계별 논리적 추론을 수행하는 데 시간을 할애합니다. 이는 수학 증명, 복잡한 코딩 또는 과학적 분석과 같이 더 깊은 사고가 필요한 복잡한 문제에 이상적입니다.
- 비사고 모드: 이 모드는 간단한 질문에 대해 빠르고 거의 즉각적인 답변을 제공하여, 속도가 정확성보다 중요할 때 효율성을 최적화합니다. 이러한 유연성을 통해 사용자는 당면한 작업에 따라 모델이 수행하는 "사고"의 양을 제어할 수 있습니다. 하드 스위치(enable_thinking=False)를 통해 사고 기능을 완전히 비활성화하거나, 소프트 스위치(/think 및 /no_think)를 사용자 프롬프트나 시스템 메시지에 추가하여 다중 턴 대화에서 모델의 사고 모드를 턴별로 전환할 수도 있습니다.

이러한 두 모드의 통합은 안정적이고 효율적인 사고 예산 제어를 구현하는 모델의 능력을 크게 향상시킵니다. 할당된 컴퓨팅 추론 예산과 직접적으로 연관된 확장 가능하고 부드러운 성능 향상을 보여주며, 사용자가 작업별 예산을 쉽게 구성하여 비용 효율성과 추론 품질 간의 최적 균형을 달성할 수 있게 합니다.
2) 확장된 다국어 지원 (Extended Multilingual Coverage): Qwen3는 119개 이상의 언어 및 방언을 지원하여 다국어 능력을 크게 확장했습니다. 이는 다양한 언어적 맥락에서 접근성과 정확성을 향상시킵니다. 총 36조 토큰에 달하는 방대한 양의 훈련 데이터셋은 웹뿐만 아니라 PDF와 같은 문서에서도 수집되었으며, STEM, 프로그래밍, 추론 등 전문 분야의 고품질 데이터를 광범위하게 채택하여 전문 영역에서의 성능을 향상시켰습니다.
3) 개선된 에이전트 능력 (Improved Agentic Capabilities): Qwen3 모델은 코딩 및 에이전트 능력에 최적화되었으며, MCP(Model Context Protocol) 지원도 강화되었습니다. Qwen-Agent를 사용하면 도구 호출 템플릿 및 파서를 내부적으로 캡슐화하여 코딩 복잡성을 크게 줄여 Qwen3의 에이전트 능력을 활용할 수 있습니다.
4) 기술 혁신 및 아키텍처 최적화: Qwen3는 모델 성능 향상을 위해 여러 기술 혁신을 도입했습니다. qk-layernorm는 어텐션 메커니즘을 최적화하여 모델 안정성을 개선합니다. 점진적 장문 훈련(Progressive Long-Text Training)은 장문 이해 능력을 향상시키고, 스케일링 법칙 하이퍼파라미터 튜닝(Scaling Law Hyperparameter Tuning)은 모델 훈련 효율성과 효과를 최적화합니다.
3. Qwen3 벤치마크 결과
다음은 Qwen3의 벤치마크 결과를 알아보겠습니다.
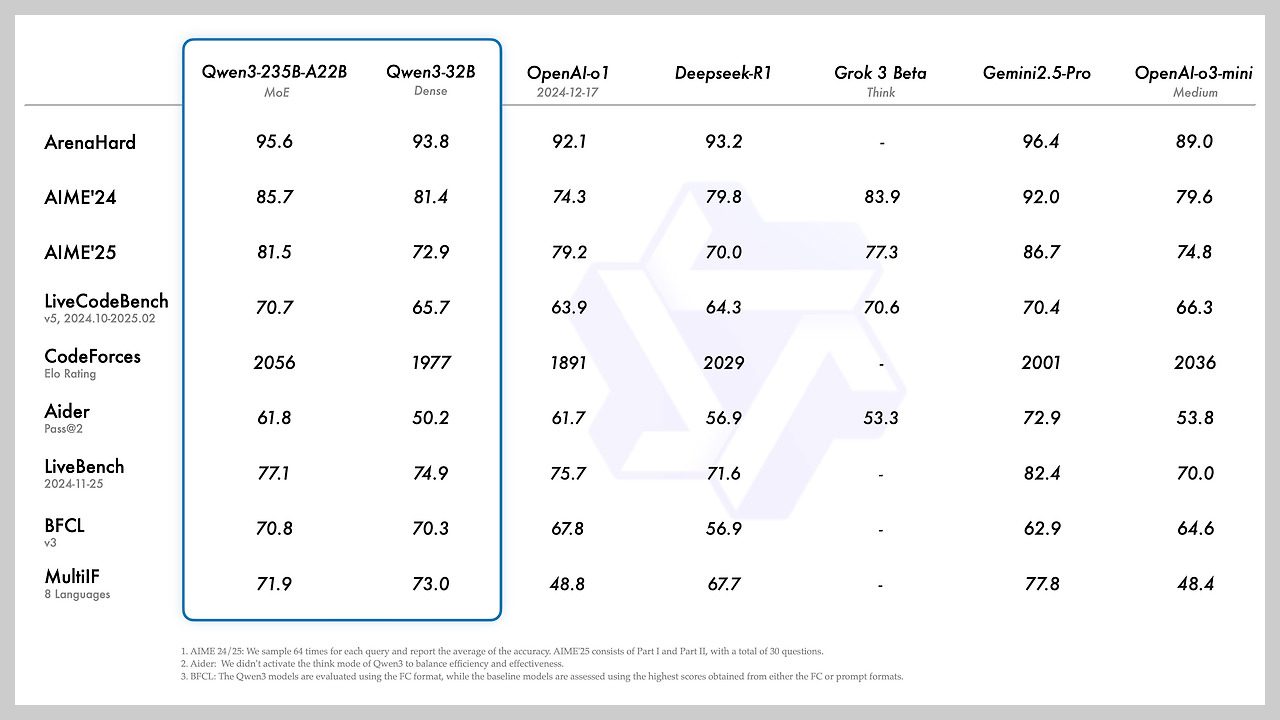
- Qwen3-235B-A22B 모델은 코딩(HumanEval, MBPP), 수학 추론(GSM8K, MATH) 및 일반 지식 벤치마크에서 DeepSeek-R1, o1, o3-mini, Grok-3 및 Gemini-2.5-Pro와 같은 다른 최고 수준 모델과 경쟁하는 결과를 달성했습니다.
- 더 작은 MoE 모델인 Qwen3-30B-A3B는 QwQ-32B보다 더 나은 성능을 보입니다.
- Qwen3-4B와 같은 작은 모델조차 Qwen2.5-72B-Instruct와 같은 이전 세대 대규모 모델의 성능에 필적할 수 있습니다.
- Qwen3 밀집형 기본 모델의 전반적인 성능은 더 많은 파라미터를 가진 Qwen2.5 기본 모델의 성능과 일치합니다. 특히 STEM, 코딩, 추론과 같은 영역에서는 Qwen3 밀집형 기본 모델이 더 큰 Qwen2.5 모델보다 뛰어난 성능을 보이며, Qwen3-MoE 기본 모델은 활성 파라미터의 10%만 사용하면서도 Qwen2.5 밀집형 기본 모델과 유사한 성능을 달성하여 훈련 및 추론 비용을 크게 절감합니다.
- 추론 시 사고 모드를 활성화했을 때 상당한 성능 향상이 관찰됩니다. 아래 이미지에서와 같이 네 가지 테스트 세트(AIME24, AIME25, LiveCodeBench, GPQA Diamond)에서 "Non-thinking Mode"와 "Thinking Mode"의 성능을 비교한 그래프에서 "Thinking Mode"는 Thinking Budget이 증가함에 따라 정답률이 크게 향상되었으며, "Non-thinking Mode"는 정답률이 일정하게 유지되는 것을 볼 수 있습니다.

4. Qwen3-8B 성능 로컬 테스트
다음은 Qwen3 모델 중 8B 모델을 로컬에서 테스트해 보겠습니다. 여러분도 Qwen3-8B 모델을 ollama.com에서 PC에 다운로드 하신 후, https://github.com/jmpark333/ollama-qwen3-demo 리포지토리를 복제하시면 Qwen3-8B 모델의 추론 테스트 데모를 통해 답변 내용을 자세히 확인하실 수 있습니다.
Ollama Qwen3-8B 테스트 데모 이용방법
1. 코드 다운로드: 아래 명령어로 소스코드를 본인 PC에 복제하세요.
git clone https://github.com/jmpark333/ollama-qwen3-demo.git
2. Python 환경 준비: (Python 3.8 이상 권장)
cd qwen3 && pip install -r requirements.txt
3. Ollama 설치 및 모델 다운로드:
Ollama 공식 다운로드에서 설치 후, 터미널에서
ollama pull qwen3
4. FastAPI 서버 실행:
uvicorn main:app --host 0.0.0.0 --port 10000(변경가능)
5. 웹 브라우저에서 접속:
http://localhost:10000 으로 접속하여 데모 사용
(질문 클릭 시 Ollama가 답변을 생성합니다)

아래는 Qwen3-8B 모델의 추론 테스트 결과입니다.
| No. | 문제 | Qwen3-8B |
| 1 | 5학년과 6학년 학생 160명이 나무 심기에 참가하였습니다. 6학년 학생들이 각각 평균5그루,5학년 학생들이 각각 평균 3그루씩 심은 결과 모두 560그루를 심었습니다. 나무심기에 참가한 5,6학년 학생은 각각 몇명일까요? | Pass |
| 2 | 베티는 새 지갑을 위해 돈을 모으고 있습니다. 새 지갑의 가격은 $100입니다. 베티는 필요한 돈의 절반만 가지고 있습니다. 그녀의 부모는 그 목적을 위해 $15를 주기로 결정했고, 할아버지와 할머니는 그녀의 부모들의 두 배를 줍니다. 베티가 지갑을 사기 위해 더 얼마나 많은 돈이 필요한가요? | Pass |
| 3 | 전국 초등학생 수학경시대회가 열렸는데 영희,철수,진호 세사람이 참가했습니다. 그들은 서울,부산,인천에서 온 학생이고 각각 1등,2등,3등 상을 받았습니다. 다음과 같은 사항을 알고 있을때 진호는 어디에서 온 학생이고 몇등을 했습니까? 1) 영희는 서울의 선수가 아닙니다. 2) 철수는 부산의 선수가 아닙니다. 3)서울의 선수는 1등이 아닙니다. 4) 부산의 선수는 2등을 했습니다. 5)철수는 3등이 아닙니다. | Pass |
| 4 | 방 안에는 살인자가 세 명 있습니다. 어떤 사람이 방에 들어와 그중 한 명을 죽입니다. 아무도 방을 나가지 않습니다. 방에 남아 있는 살인자는 몇 명입니까? 단계별로 추론 과정을 설명하세요. | Pass |
| 5 | A marble is put in a glass. The glass is then turned upside down and put on a table. Then the glass is picked up and put in a microwave. Where's the marble? Explain your reasoning step by step. | Pass |
| 6 | 도로에 5대의 큰 버스가 차례로 세워져 있는데 각 차의 뒤에 모두 차의 목적지가 적혀져 있습니다. 기사들은 이 5대 차 중 2대는 A시로 가고, 나머지 3대는 B시로 간다는 사실을 알고 있지만 앞의 차의 목적지만 볼 수 있습니다. 안내원은 이 몇 분의 기사들이 모두 총명할 것으로 생각하고 그들의 차가 어느 도시로 가야 하는지 목적지를 알려 주지 않고 그들에게 맞혀 보라고 하였습니다. 먼저 세번째 기사에게 자신의 목적지를 맞혀 보라고 하였더니 그는 앞의 두 차에 붙여 놓은 표시를 보고 말하기를 "모르겠습니다." 라고 말하였습니다. 이것을 들은 두번째 기사도 곰곰히 생각해 보더니 "모르겠습니다." 라고 말하였습니다. 두명의 기사의 이야기를 들은 첫번째 기사는 곰곰히 생각하더니 자신의 목적지를 정확하게 말하였습니다. 첫번째 기사가 말한 목적지는 어디입니까? | Fail |
Qwen3-8B 모델은 버스 문제를 제외한 추론 문제를 성공하였습니다.
https://github.com/jmpark333/ollama-qwen3-demo
GitHub - jmpark333/ollama-qwen3-demo
Contribute to jmpark333/ollama-qwen3-demo development by creating an account on GitHub.
github.com
다음은 수학 성능 테스트 결과입니다.
| No. | 문제 구분 | 문제 | Qwen3-8B |
| 1 | 기초 대수 문제 | 두 숫자 𝑥 x와 𝑦 y가 있습니다. 이들이 만족하는 식은 3 𝑥 + 4 𝑦 = 12 3x+4y=12이며, 𝑥 − 2 𝑦 = 1 x−2y=1입니다. 𝑥 x와 𝑦 y의 값을 구하세요 | Pass |
| 2 | 기하학 문제 | 반지름이 7cm인 원의 넓이를 구하세요. 𝜋 = 3.14159 π=3.14159로 계산하세요. | Pass |
| 3 | 확률 문제 | 주사위를 두 번 던졌을 때, 두 숫자의 합이 7이 될 확률을 구하세요. | Pass |
| 4 | 수열 문제 | 첫 번째 항이 3이고, 공차가 5인 등차수열의 10번째 항을 구하세요. | Pass |
| 5 | 최적화 문제 | 어떤 직사각형의 둘레가 36cm입니다. 이 직사각형의 넓이를 최대화하려면 가로와 세로의 길이는 각각 얼마여야 하나요? | Pass |
| 6 | 복합 문제 | 복소평면에서 다음 극한값을 구하시오. lim[n→∞] (1 + i/n)^(n^2) 여기서 i는 허수단위 (i^2 = -1)입니다. | Fail |
수학 테스트에서 Qwen3-8B는 복합 문제를 제외하고 기초 대수, 기하학, 확률, 수열, 최적화 등 여섯 문제를 모두 성공하였습니다.

5. 맺음말
Qwen3 시리즈는 하이브리드 사고 모드, 확장된 다국어 능력, 에이전트 최적화 기능까지 "Think Deeper, Act Faster"라는 슬로건이 과장이 아니라는 걸 실감하게 합니다. Qwen3는 경쟁력 있는 성능, 다양한 모델 크기 및 광범위한 다국어 지원으로 효율적인 AI 솔루션을 제공하며, 오픈 소스로 공개되어 더욱 접근성을 높였습니다.
특히 블로그에서 테스트한 8B 모델은 수학과 추론 테스트에서 기존의 오픈소스 동급 모델보다 정교하고 정확한 답변을 보여주었습니다. 일부 복잡한 문제에서는 오답을 제시하거나 시스템 프롬프트를 지키지 못하기도 하였지만, 중급이상 성능의 노트북에서 사용가능한 로컬 추론 모델 중에서는 우수한 수준을 보여주었습니다.
오늘 블로그는 여기까지입니다. 여러분도 ollama에서 Qwen3 모델을 다운로드하셔서 한 번씩 경험해 보시기를 추천드리면서 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2025.03.08 - [AI 언어 모델] - 🎯QwQ-32B: 20배 작은 모델로 DeepSeek-R1 따라잡은 강화 학습 모델
🎯QwQ-32B: 20배 작은 모델로 DeepSeek-R1 따라잡은 강화 학습 모델
안녕하세요! 오늘은 알리바바에서 공개한 Qwen 시리즈의 최신 모델, QwQ-32B에 대해 알아보겠습니다. QwQ-32B는 기존의 지도 학습 모델과 차별화된 추론 중심 AI 모델로, 생각하고 분석하는 능력을 갖
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 🏆Claude 4: Gemini 2.5 Pro를 능가하는 앤트로픽의 차세대 언어 모델 (22) | 2025.05.25 |
|---|---|
| 🐘📊샤오미 MiMo-7B: 작은 거인이 AI 추론 능력을 재정의하다 (4) | 2025.05.06 |
| 🧠💰Gemini 2.5 Flash: 생각 모드 및 추론 예산 제어하는 차세대 AI (7) | 2025.04.21 |
| 🔍🧬📊o3, o4-mini: GPT-4o에 이은 OpenAI의 차세대 추론 모델 (6) | 2025.04.18 |
| ✨📈🦾GPT-4.1: 100만 토큰 지원하는 OpenAI의 차세대 언어 모델 (6) | 2025.04.16 |



