안녕하세요! 오늘은 일반 대화 능력과 코딩 작업을 통합한 DeepSeek-AI의 최신 모델 DeepSeek V2.5 모델에 대해 알아보겠습니다. DeepSeek V2.5는 이전 모델인 DeepSeek-V2-Chat과 DeepSeek-Coder-V2-Instruct의 강점을 결합한 인공지능 모델로, 일반 대화 능력과 코딩 능력을 동시에 강화한 것이 특징입니다. 다양한 벤치마크에서 향상된 성능을 보이며, 특히 Python과 C++ 같은 언어의 코딩 문제에서 높은 정확도를 기록하고 있습니다. 이 블로그에서는 DeepSeek V2.5의 개요, 특징 및 주요 기능, 벤치마크 결과에 대해 알아보고 코딩 및 수학 및 추론성능을 테스트해 보겠습니다.

https://huggingface.co/deepseek-ai/DeepSeek-V2.5
deepseek-ai/DeepSeek-V2.5 · Hugging Face
Paper Link👁️ DeepSeek-V2.5 1. Introduction DeepSeek-V2.5 is an upgraded version that combines DeepSeek-V2-Chat and DeepSeek-Coder-V2-Instruct. The new model integrates the general and coding abilities of the two previous versions. For model details, p
huggingface.co
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
DeepSeek-V2.5 개요
DeepSeek-V2.5는 DeepSeek-AI의 최신 모델로, 이전 버전인 DeepSeek-V2-Chat과 DeepSeek-Coder-V2-Instruct를 통합하여 업그레이드한 모델입니다. 이 새로운 모델은 일반 대화 기반 작업에서 사람과의 상호작용을 더 자연스럽고 정확하게 처리할 수 있으며, 코딩 작업에 있어서는 기존 모델들과 비교해 더 높은 수준의 문제 해결 능력과 코드를 작성하는 데 필요한 창의적 접근 방식을 보유하고 있습니다.
또한 DeepSeek V2.5는 성능, 비용 효율성, 추론 속도 사이의 균형을 위해 설계된 Mixture-of-Experts (MoE) 아키텍처를 기반으로 합니다. MoE 아키텍처는 대규모 모델의 효율성을 높이기 위해 여러 개의 전문가(expert) 모듈을 사용하여 특정 작업에 대한 처리를 분산시키는 방식으로, 이를 통해 모델의 성능을 유지하면서도 계산 비용을 줄일 수 있습니다. 이 모델은 총 2360억 개의 매개변수로 구성되어 있지만, 처리 과정에서 각 토큰마다 오직 210억 개의 매개변수만 활성화됩니다. 이는 다른 모델들과 비교했을 때 매우 효율적입니다.
위 이미지에 나타낸 DeepSeek V2의 이 아키텍처는 MLA(Multi-Head Latent Attention)와 DeepSeekMoE라는 두 가지 핵심 구성 요소를 기반으로 합니다. DeepSeek V2.5는 이를 기반으로 일반적인 대화 기능과 코딩 능력을 결합하였으며, 인간의 선호도에 더 잘 부합하고, 쓰기 과제와 지시 수행에 개선이 이루어졌다고 합니다.
- MLA (Multi-Head Latent Attention): 기존의 어텐션 메커니즘에서는 단어, 토큰, 키(Key)와 값(Value) 등 모든 이전 정보를 저장해야 했지만, MLA는 이 정보를 압축된 '잠재 벡터'로 저장합니다. 이렇게 하면 메모리 사용량이 크게 줄어들고, 더 빠른 처리가 가능해집니다. 이미지에서 보이는 'Latent c^Q'와 'Latent c^KV'가 이 압축된 정보를 나타냅니다.
- DeepSeekMoE (Mixture of Experts): MoE는 여러 '전문가' 네트워크를 활용하는 방식입니다. 이미지의 오른쪽 상단에서 볼 수 있듯이, 여러 개의 전문가(Expert) 모듈이 있습니다. 입력에 따라 '라우터(Router)'가 가장 적합한 전문가를 선택합니다. 이 방식을 통해 모델은 매우 크지만, 실제로는 일부만 사용하여 효율적으로 작동합니다.
DeepSeek-V2.5 특징
DeepSeek-V2.5는 DeepSeek-V2-Chat과 DeepSeek-Coder-V2-Instruct 모델을 통합하여 대화와 코딩 능력을 동시에 제공하는 다용도 AI 모델입니다. 향상된 인간 선호도 반영으로 자연스럽고 직관적인 상호작용을 통해 더 정확한 응답을 제공하며, 고난도의 추론 작업에서도 최적의 성능을 발휘합니다. Huggingface를 통해 쉽게 모델 사용이 가능하며, JSON 출력 모드를 지원해 다양한 작업에 활용할 수 있습니다. DeepSeek-V2.5의 특징은 다음과 같습니다.
- 통합 모델 아키텍처: 이전의 DeepSeek-V2-Chat 모델과 DeepSeek-Coder-V2-Instruct 모델의 통합 덕분에, DeepSeek-V2.5는 대화와 코딩 능력을 한꺼번에 제공할 수 있는 복합적이고 다용도의 인공지능 모델로서, 일반적인 대화 응답이나 코딩 문제 해결을 위한 모델을 따로 사용할 필요 없이, DeepSeek-V2.5 하나만으로 모든 작업을 해결할 수 있습니다.
- 향상된 인간 선호도 반영: DeepSeek-V2.5는 사용자와의 상호작용에서 더 인간적인 접근을 취합니다. 이전 버전보다 사람들의 선호에 더 잘 맞춘 응답을 제공하며, 특히 글쓰기나 명령 수행에서 그 차이가 두드러집니다. DeepSeek-V2.5는 자연스럽고 직관적인 상호작용을 통해 사용자의 요구를 더 정확히 파악하고 처리합니다.
- 추론 및 성능 최적화: DeepSeek-V2.5는 대규모의 코딩 작업이나 고난도의 연산 문제에서도 최적의 성능을 발휘합니다. 이 모델은 고속 추론과 경제적인 훈련 비용을 유지하면서도, 복잡한 문제 해결을 위한 강력한 추론 능력을 자랑합니다. 이는 코딩 및 엔지니어링 작업에서도 유용하게 사용할 수 있는 기능으로, 복잡한 문제를 효율적으로 해결하는 데 적합합니다.
- 다양한 활용 가능성: DeepSeek-V2.5는 기본적으로 Huggingface의 Transformers 라이브러리를 통해 쉽게 사용할 수 있습니다. 또한 JSON 출력 모드를 통해 응답을 JSON 형식으로 제한해 필요한 작업에 맞춤화할 수 있습니다. 이는 특히 데이터 분석이나 응답 자동화에서 유용하게 사용됩니다.
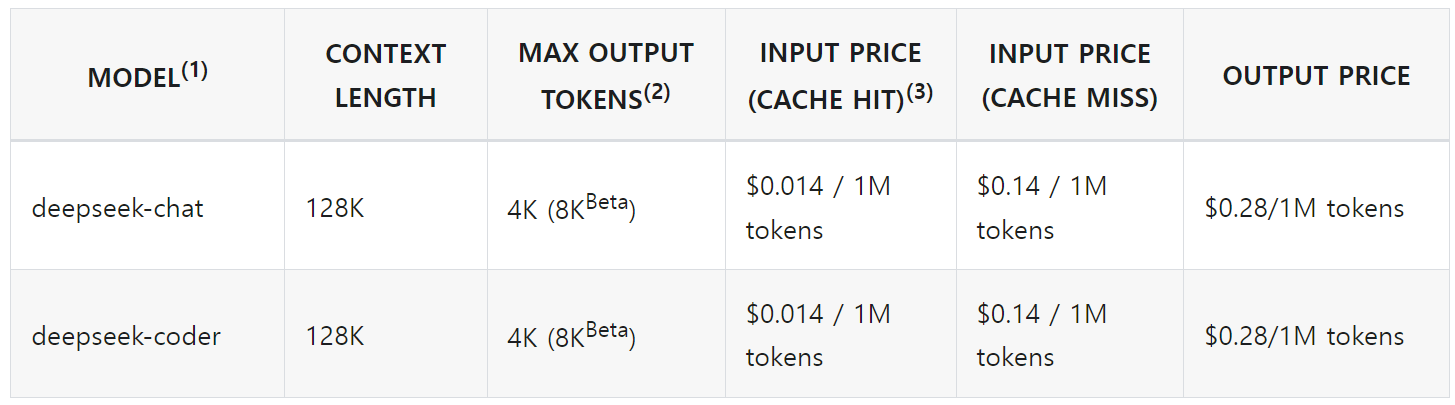
DeepSeek 모델의 API 사용가격은 다음과 같습니다. 캐시 미사용 시 입력은 백만 토큰당 $0.14이며, 출력은 백만 토큰당 $0.28로 저렴하지만, 자체 벤치마크 성능은 GPT-4o-mini 보다 더 우수한 것으로 제시하고 있습니다.
DeepSeek-V2.5 벤치마크 결과
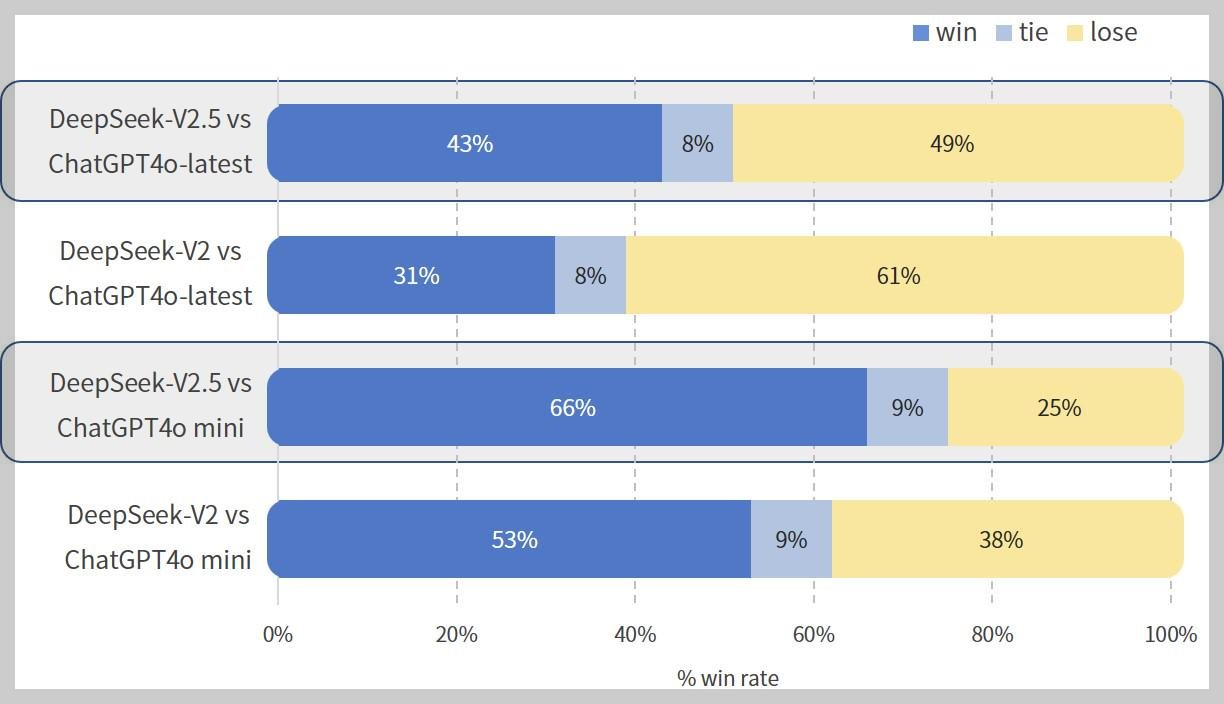
DeepSeek-V2.5는 AlpacaEval 2.0(지시 수행능력), ArenaHard(고난도 문제해결), AlignBench(인간 가치 정렬도), MT-Bench(대화 지속성) 벤치마크에서 다른 DeepSeek 모델과 비교했을 때, 전반적으로 우수한 성능을 입증했으며, 자체 내부 테스트에서는 ChatGPT4o-mini 모델을 능가하고, ChatGPT4o 최신 모델과도 견줄만한 성능을 보여줍니다.
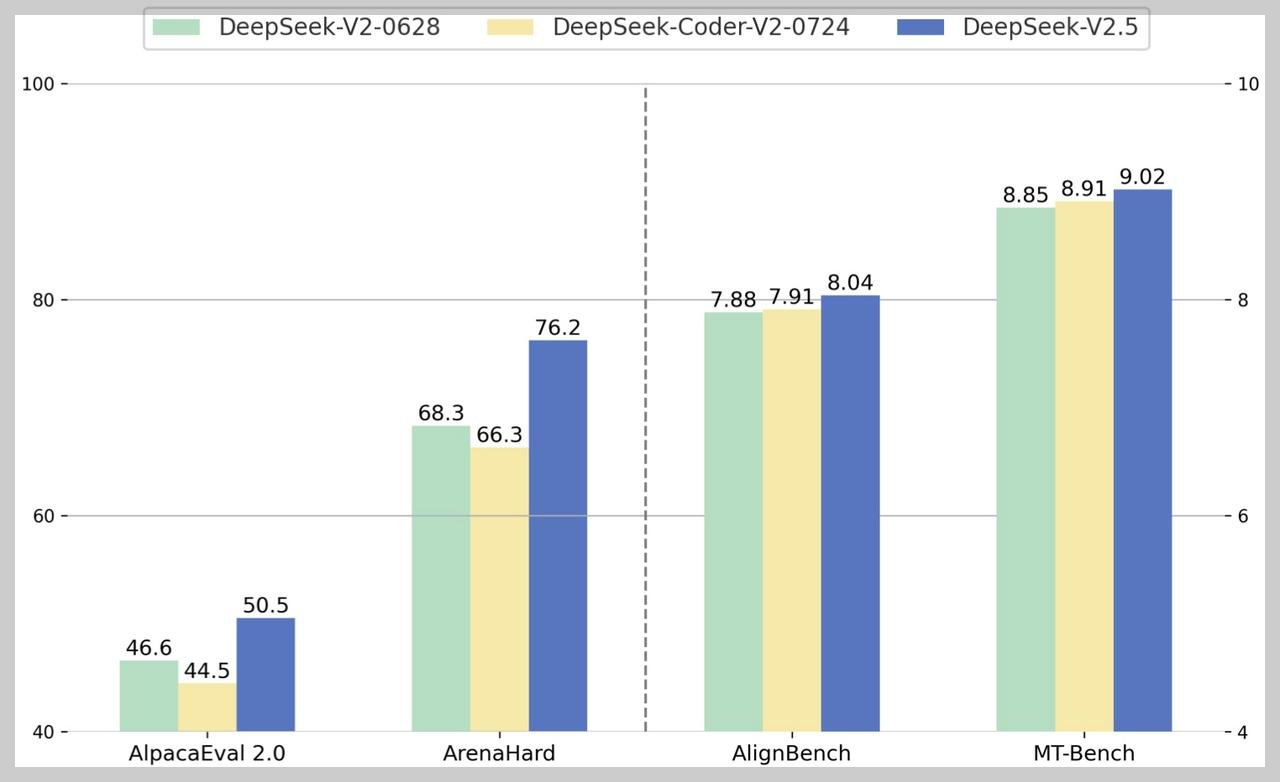
| Metric | DeepSeek-V2-0628 | DeepSeek-Coder-V2-0724 | DeepSeek-V2.5 |
| AlpacaEval 2.0 | 46.6 | 44.5 | 50.5 |
| ArenaHard | 68.3 | 66.3 | 76.2 |
| AlignBench | 7.88 | 7.91 | 8.04 |
| MT-Bench | 8.85 | 8.91 | 9.02 |
| HumanEval python | 84.5 | 87.2 | 89 |
| HumanEval Multi | 73.8 | 74.8 | 73.8 |
| LiveCodeBench (01-09) | 36.6 | 39.7 | 41.8 |
| Aider | 69.9 | 72.9 | 72.2 |
| SWE-verified | N/A | 19 | 16.8 |
| DS-FIM-Eval | N/A | 73.2 | 78.3 |
| DS-Arena-Code | N/A | 49.5 | 63.1 |
위 벤치마크 결과에서 볼 수 있듯이, DeepSeek-V2.5는 특히 AlpacaEval 2.0(50.5), ArenaHard(76.2), MT-Bench(9.02) 등에서 벤치마크에서 큰 성과를 이루었으며, 코딩 관련 지표인 HumanEval python(89)과 LiveCodeBench(41.8)에서도 높은 점수를 기록하며, 코딩 작업에 대한 탁월한 성능을 보여주고 있습니다. 또한 DS-FIM-Eval(78.3)과 DS-Arena-Code(63.1)에서도 뛰어난 성능을 보여, 일반적인 언어 이해와 코딩 능력 모두에서 균형 잡힌 발전을 이루었음을 알 수 있습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
DeepSeek-V2.5 성능 테스트
다음은 DeepSeek-V2.5 모델의 성능을 테스트해 보겠습니다. 테스트는 https://chat.deepseek.com/ 사이트에서 진행하였으며, 코딩과 수학 및 추론에 대해 진해하였습니다. 코딩 테스트는 edabit.com 코딩 교육 사이트 Python, C++에 대하여 테스트하였으며, 재시도 없이 첫 번째 시도의 채점결과를 그대로 반영하였습니다.
1. 코딩성능 테스트
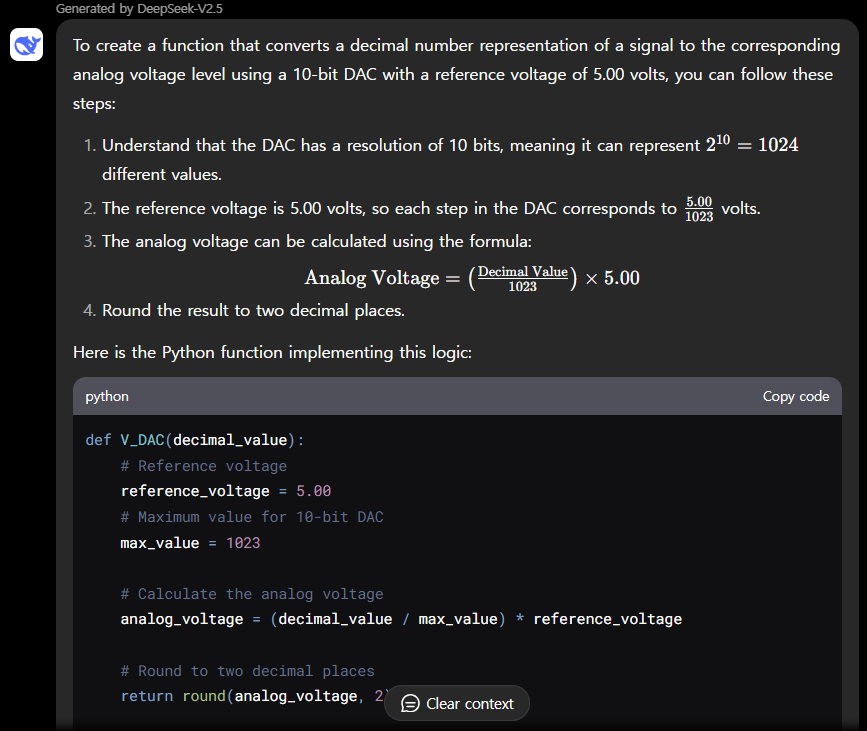
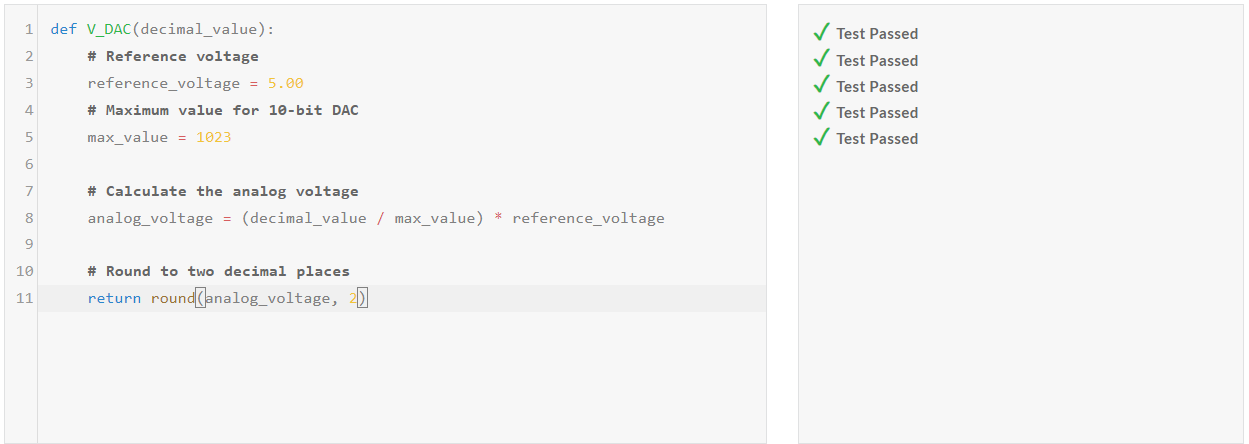
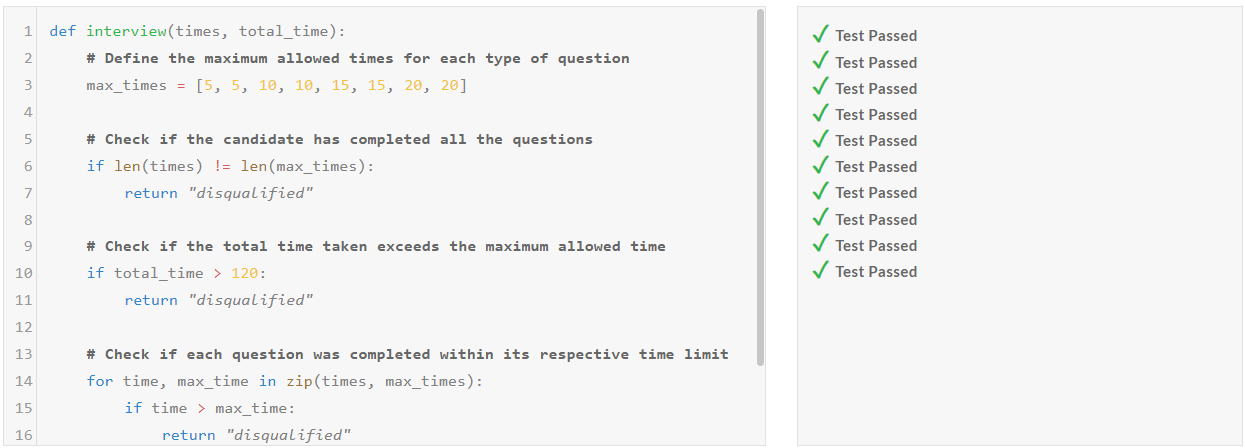

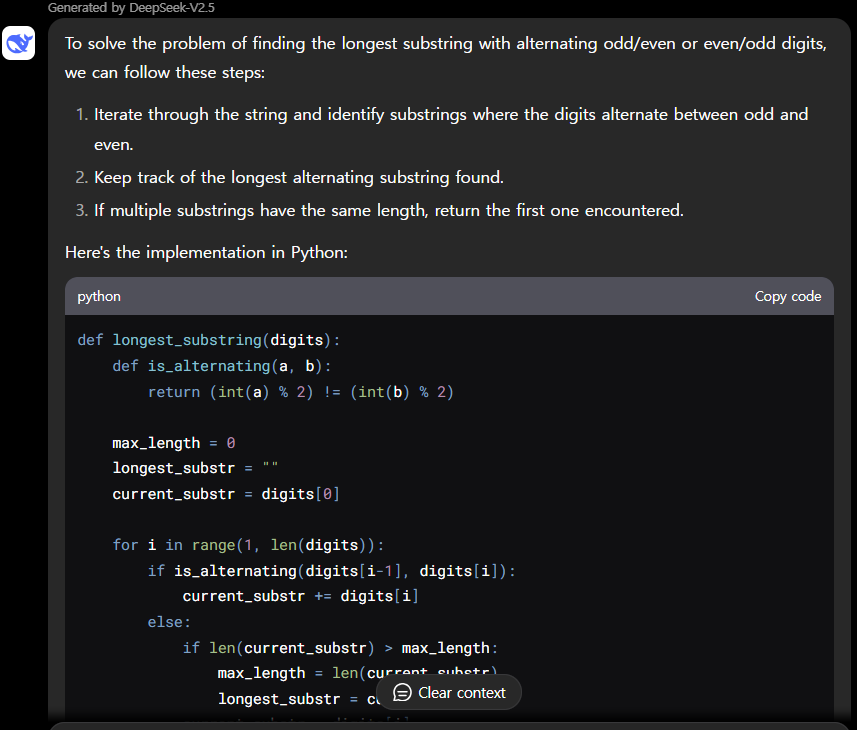

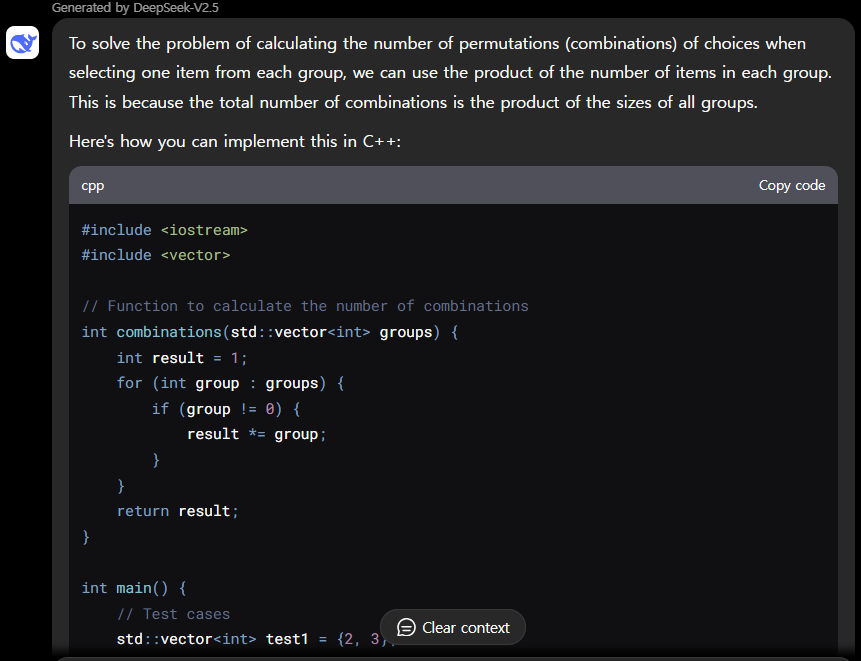
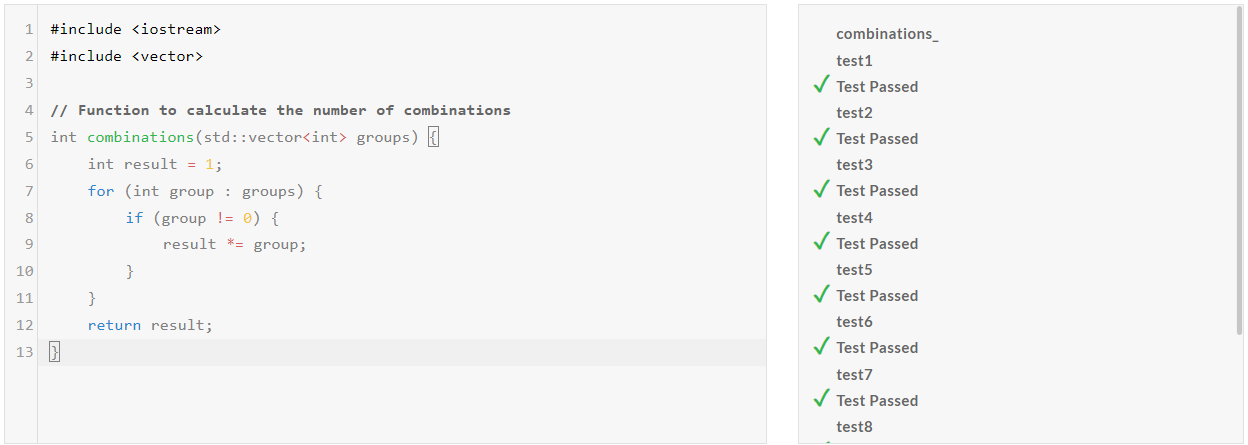
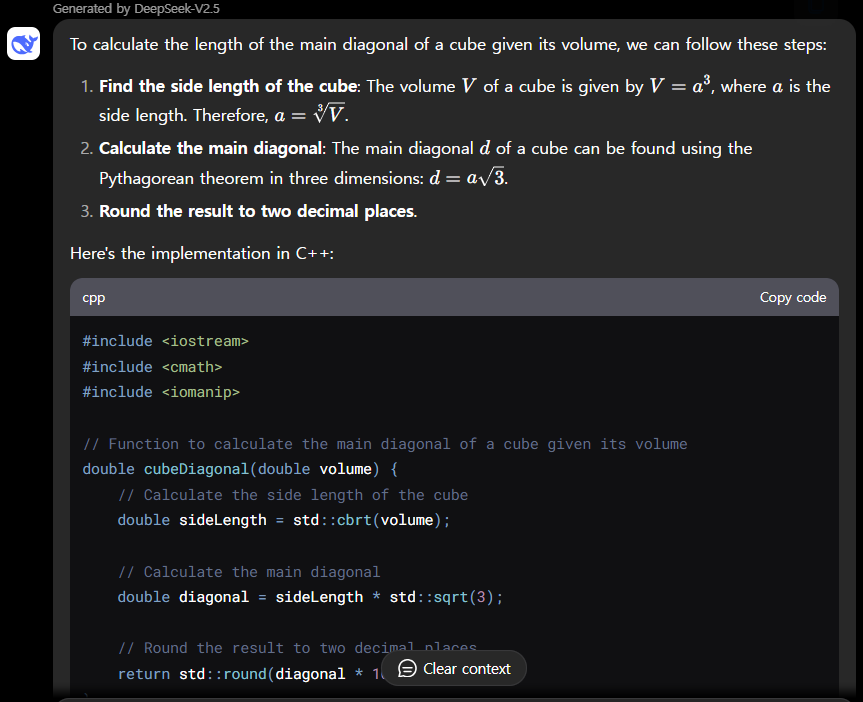
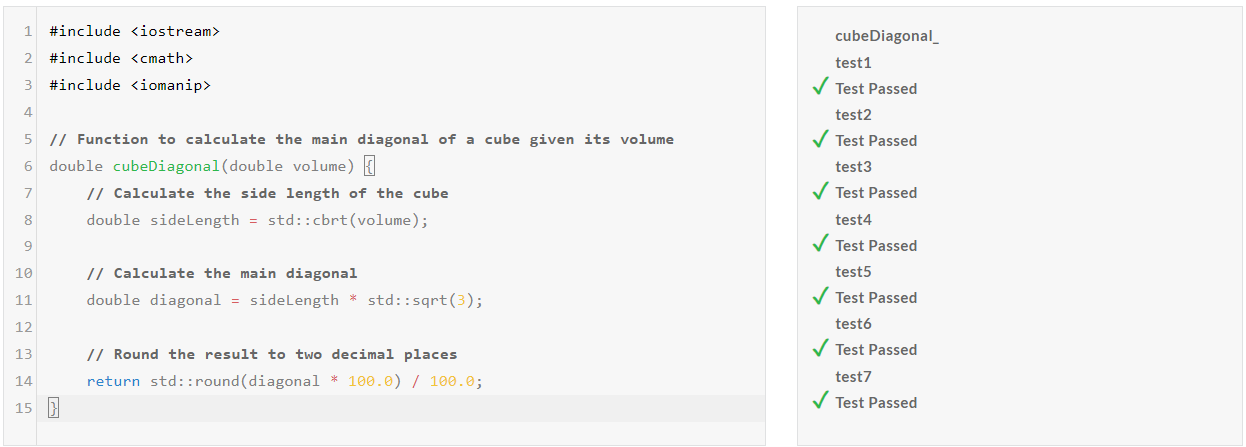

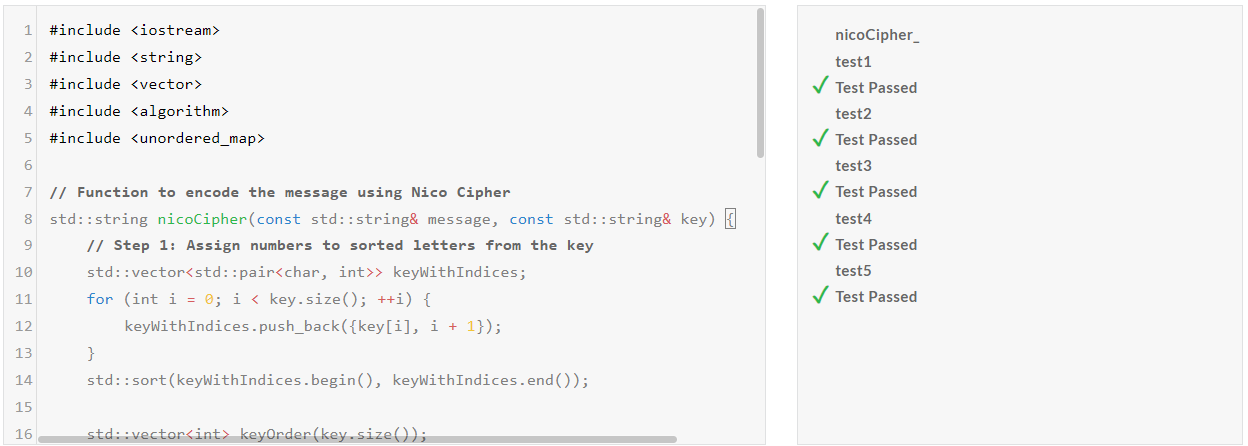
| DeepSeek-V2.5/Pass@1 | Medium | Hard | Very Hard | Expert |
| Python | Pass | Pass | Pass | Pass |
| C++ | Pass | Pass | Pass | Pass |
DeepSeek-V2.5 코딩성능 테스트 결과, Python과 C++의 모든 난이도 문제를 첫 번째 시도에서 성공하였습니다.
2. 수학성능 테스트
| No. | 문제 구분 | 문제 | DeepSeek-V2.5 | GPT-4o-mini |
| 1 | 기초 대수 문제 | 두 숫자 𝑥 x와 𝑦 y가 있습니다. 이들이 만족하는 식은 3 𝑥 + 4 𝑦 = 12 3x+4y=12이며, 𝑥 − 2 𝑦 = 1 x−2y=1입니다. 𝑥 x와 𝑦 y의 값을 구하세요 | Pass | Pass |
| 2 | 기하학 문제 | 반지름이 7cm인 원의 넓이를 구하세요. 𝜋 = 3.14159 π=3.14159로 계산하세요. | Pass | Pass |
| 3 | 확률 문제 | 주사위를 두 번 던졌을 때, 두 숫자의 합이 7이 될 확률을 구하세요. | Pass | Pass |
| 4 | 수열 문제 | 첫 번째 항이 3이고, 공차가 5인 등차수열의 10번째 항을 구하세요. | Pass | Pass |
| 5 | 최적화 문제 | 어떤 직사각형의 둘레가 36cm입니다. 이 직사각형의 넓이를 최대화하려면 가로와 세로의 길이는 각각 얼마여야 하나요? | Pass | Pass |
| 6 | 복합 문제 | 복소평면에서 다음 극한값을 구하시오. lim[n→∞] (1 + i/n)^(n^2) 여기서 i는 허수단위 (i^2 = -1)입니다. | Fail | Pass |






DeepSeek-V2.5는 기초 대수, 기하학, 확률, 수열, 삼각함수/극 복합문제 등 6개의 수학문제 중에서 5문제를 정확하게 풀었습니다.
3. 추론성능 테스트
| No. | 문제 | 정답 | DeepSeek-V2.5 | GPT-4o-mini |
| 1 | 5학년과 6학년 학생 160명이 나무 심기에 참가하였습니다. 6학년 학생들이 각각 평균5그루,5학년 학생들이 각각 평균 3그루씩 심은 결과 모두 560그루를 심었습니다. 나무심기에 참가한 5,6학년 학생은 각각 몇명일까요? |
5,6학년 학생 모두 평균 3그루씩을 심는 경우 160 * 3 = 480 그루를 심었을 것입니다. 모두 560그루를 심었기 때문에 80그루를 더 심었습니다. 따라서 6학년 학생들이 2그루씩 더 많이 심었기 때문에 6학년 학생들은 80/2 = 40 명입니다. 5학년 학생은 160 - 40 = 120 명입니다. |
Pass | Pass |
| 2 | 베티는 새 지갑을 위해 돈을 모으고 있습니다. 새 지갑의 가격은 $100입니다. 베티는 필요한 돈의 절반만 가지고 있습니다. 그녀의 부모는 그 목적을 위해 $15를 주기로 결정했고, 할아버지와 할머니는 그녀의 부모들의 두 배를 줍니다. 베티가 지갑을 사기 위해 더 얼마나 많은 돈이 필요한가요? | $100/2-($15+$30)=$5 | Pass | Pass |
| 3 | 전국 초등학생 수학경시대회가 열렸는데 영희,철수,진호 세사람이 참가했습니다. 그들은 서울,부산,인천에서 온 학생이고 각각 1등,2등,3등 상을 받았습니다. 다음과 같은 사항을 알고 있을때 진호는 어디에서 온 학생이고 몇등을 했습니까? 1) 영희는 서울의 선수가 아닙니다. 2) 철수는 부산의 선수가 아닙니다. 3)서울의 선수는 1등이 아닙니다. 4) 부산의 선수는 2등을 했습니다. 5)철수는 3등이 아닙니다. | 1. 서울의 선수: 조건 3에 따르면, 서울의 선수는 1등이 아닙니다. 영희는 조건 1에서 서울의 선수가 아니므로, 진호가 서울의 선수입니다. 2. 부산의 선수: 조건 4에 따르면, 부산의 선수는 2등을 했습니다. 철수는 조건 2에 따라 부산의 선수가 아니므로, 영희가 부산의 선수이며 2등을 했습니다. 3. 철수의 순위: 조건 5에 따르면, 철수는 3등이 아닙니다. 따라서 철수는 1등이고, 남은 도시는 인천이므로 철수는 인천의 선수입니다. 4. 진호의 순위: 철수가 1등이고 영희가 2등이므로, 진호는 3등입니다. 최종 결론: 진호는 서울에서 온 선수이고, 3등을 했습니다. | Pass | Pass |
| 4 | 방 안에는 살인자가 세 명 있습니다. 어떤 사람이 방에 들어와 그중 한 명을 죽입니다. 아무도 방을 나가지 않습니다. 방에 남아 있는 살인자는 몇 명입니까? 단계별로 추론 과정을 설명하세요. | 세 명 | Pass | Pass |
| 5 | A marble is put in a glass. The glass is then turned upside down and put on a table. Then the glass is picked up and put in a microwave. Where's the marble? Explain your reasoning step by step. | 테이블 위 | Fail | Pass |




5번 추론 문제는 유리잔의 밀폐여부에 대한 특별한 조건이 주어 지지 않았기 때문에, 기본적으로 유리잔이 밀폐되지 않은 상태를 고려하여 답변하여야 하므로, DeepSeek-V2.5의 답변은 오답으로 처리하였습니다.


테스트 결과, DeepSeek V2.5는 Python 및 C++ 코딩과 수학 작업에서 뛰어난 정확도를 보여주었으며, 추론 작업에서도 GPT-4o-mini에 근접하는 성능을 나타냈습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
마치며
DeepSeek-V2.5는 대화 및 코딩 능력을 통합한 최첨단 AI 모델로, 뛰어난 성능과 효율성을 자랑합니다. 이전 모델들인 DeepSeek-V2-Chat과 DeepSeek-Coder-V2-Instruct의 강점을 결합하여, 대화와 코딩 작업 모두에서 탁월한 결과를 보여주었습니다. 특히 벤치마크와 성능 테스트에서 두각을 나타내며, Python과 C++ 코딩 문제를 포함한 다양한 작업에서 높은 정확도를 기록하였습니다.
DeepSeek-V2.5를 테스트해 본 느낌은 다음과 같습니다.
- 코딩과 수학능력이 뛰어나다.
- GPT-4o-mini와 같은 상용모델과도 경쟁력이 있다.
- 오프소스와 상용모델의 성능차이가 점점 좁아지고 있다.
앞으로도 DeepSeek-V2.5는 다양한 AI 응용 분야에서 유용하게 활용될 것으로 기대되며, 코딩과 수학 문제 해결, 추론 작업 등에서의 우수한 성능은 많은 사용자들에게 큰 도움이 될 것 같습니다. 이상으로, DeepSeek-V2.5의 개요와 성능에 대한 블로그를 마치고 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다!

2024.06.20 - [AI 언어 모델] - DeepSeek-Coder-V2: 현존 최강 AI 코딩 언어 모델 분석 및 테스트
DeepSeek-Coder-V2: 현존 최강 AI 코딩 언어 모델 분석 및 테스트
안녕하세요! 오늘은 최신 코딩 언어 모델 DeepSeek-Coder-V2에 대해 알아보겠습니다. 이 모델은 수학적 추론과 코딩 능력 벤치마크에서 GPT-4-터보, Claude-3-Opus, Gemini-1.5-pro와 같은 고성능 상용 AI 모델을
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 🖼️Pixtral 12B: 추론과 코딩에 강한 Mistral AI의 첫번째 멀티모달 모델 (28) | 2024.09.18 |
|---|---|
| 🌟업스테이지 Solar Pro Preview 분석: 단일 GPU 최강 AI 모델 (27) | 2024.09.16 |
| 🌋LLaVA-OneVision: GPT-4o 대체할 오픈소스 비디오·다중 이미지 분석 모델 (23) | 2024.09.08 |
| Qwen2-VL: 👁️알리바바의 오픈소스 비전 언어모델 (32) | 2024.09.03 |
| 🎥CogVideoX: 최초의 오픈소스 비디오 생성 AI (22) | 2024.08.30 |



