안녕하세요! 오늘은 Cohere라는 대형 언어 모델 기반 응용 프로그램 구축 플랫폼에 대해서 알아보겠습니다. Cohere는 Command-R이라는 언어 모델을 통해 대화형 도구 사용, 검색 및 RAG(검색 증강 생성) 시스템 개선, Fine-Tuned 모델 생성 등 다양한 기능을 제공합니다. 또한, Cohere는 API나 클라우드 등의 다양한 접근 방식을 통해 사용자가 편리하게 접근할 수 있으며, 한국어를 포함한 10개 주요 언어를 지원합니다. 이 블로그에서는 Cohere의 개요와 특징, Sqlite DB와 AI 애플리케이션의 통합 예제에 대해서 살펴보겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Cohere와 Command-R
Cohere는 대규모 언어 모델을 통해 의미적 검색을 개선하고 데이터셋을 활용하여, 커스텀 모델을 생성할 수 있는 플랫폼으로 API, 클라우드 등 다양한 방식을 제공합니다. Command-R은 Cohere에서 제공하는 상호작용 및 긴 문맥 작업에 최적화된 대규모 언어 모델로, 검색 증강 생성과 다양한 언어에서 강력한 기능을 지원합니다.
Cohere 플랫폼
Cohere는 대규모 언어 모델을 기반으로 한 플랫폼으로, 대화형 응용 프로그램을 구축할 수 있도록 지원합니다. Cohere는 다양한 기능을 제공하며, 이를 통해 다양한 언어 관련 작업을 수행할 수 있습니다.
- Cohere의 언어 모델: Cohere는 Command-R, Rerank, Embed 등 다양한 언어 모델을 제공합니다. Command-R은 대화형 에이전트, 요약, 글쓰기 등과 같은 작업을 수행하는 텍스트 생성 모델입니다. Rerank는 특정 쿼리와의 의미적 관련성에 따라 텍스트 입력을 정렬하는 모델입니다. Embed는 검색, 분류, 군집화 등의 작업을 위한 임베딩 기능을 제공합니다.
- Cohere 플랫폼: Cohere는 모델을 배포하고 안전하고 개인 정보 보호가 되는 환경에서 실행할 수 있는 플랫폼을 제공합니다. 클라우드 AI 플랫폼에서 Cohere를 사용할 수 있으며, 필요에 따라 사내 클라우드나 기업이나 조직 내부에 있는 자체적으로 운영되는 컴퓨팅 리소스와 소프트웨어, 온프레미스 환경에서도 사용할 수 있습니다.
- Cohere의 활용: Cohere를 사용하여 대화형 응용 프로그램, 검색 시스템, 텍스트 분류 및 요약 등 다양한 언어 관련 작업을 구축할 수 있습니다. 또한 Cohere는 사용자의 요구에 맞게 모델을 세밀하게 조정하고 배포하는 기능을 제공하여 사용자가 자체적으로 모델을 개발할 수 있습니다.
요약하자면, Cohere는 다양한 언어 관련 작업을 위한 언어 모델과 플랫폼을 제공하여 사용자가 효율적으로 대화형 응용 프로그램을 개발하고 실행할 수 있도록 지원합니다.
https://docs.cohere.com/docs/the-cohere-platform
The Cohere Platform - Cohere Docs
Cohere offers world-class Large Language Models (LLMs) like Command, Rerank, and Embed. These help developers and enterprises build LLM-powered applications such as conversational agents, summarization, and search systems. They also provide fine-tuning opt
docs.cohere.com
Command-R 언어모델
Command-R은 대화형 상호작용 및 긴 문맥 작업에 최적화된 대규모 언어 모델입니다. 이 모델은 성능과 정확도 면에서 뛰어나면서도 다양한 환경에서 확장 가능하도록 설계되어 기업이 컨셉 증명을 넘어서 제품화할 수 있도록 지원합니다. Command-R은 검색 증강 생성 (RAG) 및 도구 사용 작업에서 높은 정밀도, 낮은 대기 시간 및 높은 처리량, 128k의 긴 문맥, 그리고 한국어를 포함한 10개 주요 언어에서 강력한 기능을 자랑합니다.
Command-R 모델은 사용자의 명령을 따르는 대화형 모델로, 이전 모델보다 훨씬 높은 품질로 언어 작업을 수행하며, 이를 통해 복잡한 워크플로우(코드 생성, RAG 등) 및 에이전트와 같은 작업을 수행할 수 있습니다. 최대 입력 토큰 수 (입력 문맥 창)는 128k이며, 최대 출력 토큰 수 (출력 문맥 창)는 4096개입니다.
Command-R의 주요 기능은 다음과 같습니다.
- 다양한 언어로의 다국적 기능: Command-R은 다양한 사람, 조직 및 시장에 서비스할 수 있도록 설계되었습니다. 이 모델은 영어, 프랑스어, 스페인어, 이탈리아어, 독일어, 브라질 포르투갈어, 일본어, 한국어, 간체 중국어 및 아랍어와 같은 언어에서 높은 정확도로 상호 작용할 수 있도록 최적화되었습니다.
- 검색 증강 생성: Command-R은 자체적으로 정보를 생성하면서도 그 정보의 신뢰성을 높이기 위해 출처를 표기할 수 있는 능력을 가지고 있습니다. 이것은 제공된 문서 스니펫 목록을 기반으로 응답을 생성할 수 있으며, 정보의 출처를 나타내는 인용을 응답에 포함합니다.
- 도구 사용: Command-R은 대화형 도구 사용 기능으로 훈련되었습니다. 사용자와 시스템 사이의 상호작용을 통해 사용 가능한 도구 목록이 제공되고, 모델은 이러한 목록에서 실행할 작업을 결정하여 JSON 형식으로 생성합니다.
SQLite DB와 AI 통합 예제
다음은 데이터베이스와 언어 모델을 통합하는 예제를 살펴보겠습니다. 예제코드는 Cohere 플랫폼을 사용하여 SQLite 데이터베이스에서 판매 데이터와 제품 카탈로그 데이터를 조회하는 두 가지 함수를 정의한 후, 사용자의 요청에 따라 판매 보고서 및 제품 카탈로그 정보를 제공하기 위해 이러한 함수를 도구로 사용하고 모델을 통해 어떤 도구를 사용할지 결정해서 해당 도구를 실행한 후 결과를 반환합니다.
환경설정 및 API Key 발급
먼저 환경설정 및 API KEY 발급단계입니다. 이 블로그에서 사용한 예제코드의 실행환경은 Windows 11 Pro(23H2), 파이썬 버전 3.11, 코드 에디터는 비주얼 스튜디오 코드(이하 VSC)이며, 예제코드 실행을 위한 COHERE API KEY는 아래 사이트에 접속해서 가입 후 체험용 키를 발급하면 됩니다. 체험용 키를 사용한 호출은 무료이며, 호출빈도나 요청의 제한이 있으며 상업적인 용도로 사용할 수 없다고 돼있지만 예제코드 실행에 문제는 없습니다.
Login | Cohere
Cohere provides access to advanced Large Language Models and NLP tools through one easy-to-use API. Get started for free.
dashboard.cohere.com
VSC의 가상환경이 활성화된WSL 명령어 프롬프트 상태에서 아래 코드와 같이 pip 명령으로 의존성 라이브러리를 설치하고, export 명령으로 COHERE API KEY를 환경변수에 할당합니다.
pip install cohere rich
export COHERE_API_KEY=xxxxxxx데이터베이스 생성
다음은 예제코드에서 조회할 데이터 베이스 생성단계입니다. 이 예제에서 사용되는 SQLite 데이터베이스는 Python의 기본 라이브러리 중 하나인 sqlite3을 사용하므로 추가적인 의존성 설치가 필요하지 않습니다. VSC의 가상환경이 활성화된 WSL 명령어 프롬프트 상태에서 아래 코드를 복사하여 저장한 후, 실행하면 mydatabase.db라는 이름으로 SQLite 데이터베이스가 생성됩니다.
import sqlite3
# Connect to SQLite database (or create it if it doesn't exist)
conn = sqlite3.connect('mydatabase.db')
c = conn.cursor()
# Create tables
c.execute('''CREATE TABLE IF NOT EXISTS sales_data
(date TEXT PRIMARY KEY, total_sales_amount INTEGER, total_units_sold INTEGER)''')
c.execute('''CREATE TABLE IF NOT EXISTS product_catalog
(product_id TEXT PRIMARY KEY, category TEXT, name TEXT, price INTEGER, stock_level INTEGER)''')
# Insert sales data
sales_data = [
('2023-09-28', 5000, 100),
('2023-09-29', 10000, 250),
('2023-09-30', 8000, 200)
]
c.executemany('INSERT INTO sales_data VALUES (?,?,?)', sales_data)
# Insert product catalog data
product_catalog = [
('E1001', 'Electronics', 'Smartphone', 500, 20),
('E1002', 'Electronics', 'Laptop', 1000, 15),
('E1003', 'Electronics', 'Tablet', 300, 25),
('C1001', 'Clothing', 'T-Shirt', 20, 100),
('C1002', 'Clothing', 'Jeans', 50, 80),
('C1003', 'Clothing', 'Jacket', 100, 40)
]
c.executemany('INSERT INTO product_catalog VALUES (?,?,?,?,?)', product_catalog)
# Commit changes and close connection
conn.commit()
conn.close()
# Reconnect to SQLite database to retrieve data
conn = sqlite3.connect('mydatabase.db')
c = conn.cursor()
# Retrieve and print sales data
c.execute('SELECT * FROM sales_data')
print("Sales Data:")
for row in c.fetchall():
print(row)
# Retrieve and print product catalog data
c.execute('SELECT * FROM product_catalog')
print("\nProduct Catalog:")
for row in c.fetchall():
print(row)
conn.close()
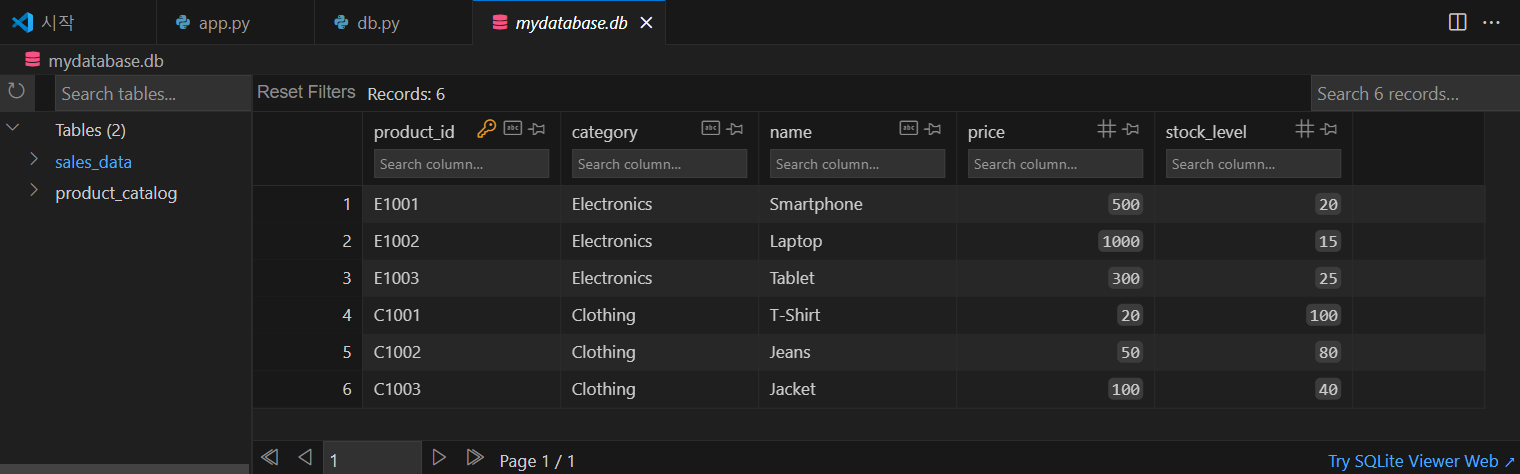
VSC 확장기능에서 SQLite를 검색하시면 아래 화면과 같이 뷰어를 통해 생성된 DB의 내용을 조회하실 수 있습니다.
예제코드 실행
다음은 예제코드 실행단계입니다. 이 코드의 출처는 Cohere docs이며 제가 일부 한글 수정과, JSON 직렬화 관련 에러수정을 하였습니다. 이 코드는 Cohere API를 사용하여 사용자의 요청에 따라 특정 날짜의 판매 요약 정보와 'Electronics' 카테고리의 제품 세부 정보를 제공하는 대화형 인터페이스를 구현하는 프로그램입니다. SQLite 데이터베이스에서 데이터를 조회하여 사용자의 요청에 맞게 결과를 반환하고, 최종적으로 사용자에게 응답을 제공합니다.
VSC 메뉴에서 파일-새 파일-Python파일을 선택한 후, 아래 코드를 복사하여 저장하고, 실행합니다.
# 1. Configuration and Creating Tools
import cohere, json, os, sqlite3
from rich import print
co = cohere.Client(os.environ["COHERE_API_KEY"])
conn = sqlite3.connect('mydatabase.db')
c = conn.cursor()
def query_daily_sales_report(day: str) -> dict:
"""
Function to retrieve the sales report for the given day from the SQLite database
"""
c.execute('SELECT total_sales_amount, total_units_sold FROM sales_data WHERE date = ?', (day,))
result = c.fetchone()
if result:
return {
'date': day,
'summary': f"Total Sales Amount: {result[0]}, Total Units Sold: {result[1]}"
}
else:
return {'date': day, 'summary': 'No sales data available for this day.'}
def query_product_catalog(category: str) -> dict:
"""
Function to retrieve products for the given category from the SQLite database
"""
c.execute('SELECT product_id, name, price, stock_level FROM product_catalog WHERE category = ?', (category,))
products = [{'product_id': row[0], 'name': row[1], 'price': row[2], 'stock_level': row[3]} for row in c.fetchall()]
return {
'category': category,
'products': products
}
functions_map = {
"query_daily_sales_report": query_daily_sales_report,
"query_product_catalog": query_product_catalog
}
tools = [
{
"name": "query_daily_sales_report",
"description": "Connects to a database to retrieve overall sales volumes and sales information for a given day.",
"parameter_definitions": {
"day": {
"description": "Retrieves sales data for this day, formatted as YYYY-MM-DD.",
"type": "str",
"required": True
}
}
},
{
"name": "query_product_catalog",
"description": "Connects to a a product catalog with information about all the products being sold, including categories, prices, and stock levels.",
"parameter_definitions": {
"category": {
"description": "Retrieves product information data for all products in this category.",
"type": "str",
"required": True
}
}
}
]
# preamble containing instructions about the task and the desired style for the output.
preamble = """
## Task & Context
You help people answer their questions and other requests interactively. You will be asked a very wide array of requests on all kinds of topics. You will be equipped with a wide range of search engines or similar tools to help you, which you use to research your answer. You should focus on serving the user's needs as best you can, which will be wide-ranging.
## Style Guide
Unless the user asks for a different style of answer, you should answer in full sentences, using proper grammar and spelling.
"""
# user request
message = """2023년 9월 29일의 판매 요약 정보를 제공하고, 'Electronics' 카테고리의 제품에 대한 세부 정보도 알려주세요. 예를 들어 가격과 재고 수준을 한국어로 알려주세요."""
# 2. The model smartly decides which tool(s) to use and how
response = co.chat(
message=message,
tools=tools,
preamble=preamble,
model="command-r"
)
print("The model recommends doing the following tool calls:")
print("\n".join(str(tool_call) for tool_call in response.tool_calls))
# 3. 도구 호출이 실행됩니다.
tool_results = []
for tool_call in response.tool_calls:
# 여기에 모델이 추천한 도구를 호출하고, 모델이 추천한 매개변수를 사용하여 호출할 것입니다.
print(f"= running tool {tool_call.name}, with parameters: {tool_call.parameters}")
output = functions_map[tool_call.name](**tool_call.parameters)
# 결과를 리스트에 저장합니다.
outputs = [output]
print(f"== tool results: {outputs}")
# 도구 결과를 다음 형식으로 저장합니다.
tool_results.append({
"call": {
"name": tool_call.name,
"parameters": tool_call.parameters
},
"outputs": outputs
})
# tool_results에 유효한 호출이 있는지 확인합니다.
for tool_result in tool_results:
if "call" not in tool_result or "name" not in tool_result["call"]:
raise ValueError("tool_results의 모든 요소에는 'name' 속성이 지정된 호출이 있어야 합니다.")
print("Tool results that will be fed back to the model in step 4:")
print(json.dumps(tool_results, indent=4, default=str)) # ToolCall 객체를 직렬화하기 위해 default=str을 사용합니다.
# 4. The model generates a final answer based on the tool results
response = co.chat(
message=message,
tools=tools,
tool_results=tool_results,
preamble=preamble,
model="command-r",
temperature=0.3
)
print("Final answer:")
print(response.text)
# Bonus: Citations come for free with Cohere!
# ...
print("Citations that support the final answer:")
for cite in response.citations:
print(cite)
def insert_citations_in_order(text, citations):
"""
A helper function to pretty print citations.
"""
offset = 0
document_id_to_number = {}
citation_number = 0
modified_citations = []
# Process citations, assigning numbers based on unique document_ids
for citation in citations:
citation_numbers = []
for document_id in sorted(citation.document_ids):
if document_id not in document_id_to_number:
citation_number += 1 # Increment for a new document_id
document_id_to_number[document_id] = citation_number
citation_numbers.append(document_id_to_number[document_id])
# Adjust start/end with offset
start, end = citation.start + offset, citation.end + offset
placeholder = ''.join([f'[{number}]' for number in citation_numbers])
# Bold the cited text and append the placeholder
modification = f'**{text[start:end]}**{placeholder}'
# Replace the cited text with its bolded version + placeholder
text = text[:start] + modification + text[end:]
# Update the offset for subsequent replacements
offset += len(modification) - (end - start)
# Prepare citations for listing at the bottom, ensuring unique document_ids are listed once
unique_citations = {number: doc_id for doc_id, number in document_id_to_number.items()}
citation_list = '\n'.join([f'[{doc_id}] source: {tool_results[doc_id - 1]["outputs"]} \n based on tool call: {dict(tool_results[doc_id - 1]["call"])}' for doc_id, number in sorted(unique_citations.items(), key=lambda item: item[1])])
text_with_citations = f'{text}\n\n{citation_list}'
return text_with_citations
print(insert_citations_in_order(response.text, response.citations))
# ...
이 코드의 내용을 살펴보면, 먼저 SQLite 데이터베이스에서 판매 데이터와 제품 카탈로그 데이터를 조회하는 두 가지 함수를 정의한 후, 사용자의 요청에 따라 판매 보고서 및 제품 카탈로그 정보를 제공하기 위해 이러한 함수를 도구로 사용하고 모델을 통해 실행합니다.
이때, 모델은 어떤 도구를 사용할지 결정하고 해당 도구를 실행한 후 결과를 반환합니다. 마지막으로, 모델이 생성한 최종 응답에 인용을 추가하여 사용자에게 반환됩니다. 코드에 대한 자세한 내용은 더 보기를 클릭하시면 알아보실 수 있습니다.
1. `import cohere, json, os, sqlite3`: Cohere API, JSON 모듈, OS 모듈, SQLite3 모듈을 가져옵니다.
2. `from rich import print`: Rich 라이브러리에서 print 함수를 가져옵니다. Rich는 텍스트 출력을 꾸며주는 라이브러리입니다.
3. `co = cohere.Client(os.environ["COHERE_API_KEY"])`: Cohere API를 사용하기 위해 인증된 API 키를 환경 변수에서 가져와서 Cohere 클라이언트를 초기화합니다.
4. `conn = sqlite3.connect('mydatabase.db')`: SQLite 데이터베이스에 연결합니다. 'mydatabase.db'는 SQLite 데이터베이스 파일의 이름입니다.
5. `c = conn.cursor()`: 데이터베이스에서 쿼리를 실행하기 위한 커서를 만듭니다.
6. `query_daily_sales_report(day: str) -> dict`: 매개변수로 날짜를 받아 해당 날짜의 판매 보고서를 SQLite 데이터베이스에서 검색하는 함수를 정의합니다. 반환값은 사전 형식입니다.
7. `query_product_catalog(category: str) -> dict`: 매개변수로 카테고리를 받아 해당 카테고리의 제품을 SQLite 데이터베이스에서 검색하는 함수를 정의합니다. 반환값은 사전 형식입니다.
8. `functions_map`: 함수 이름을 키로 사용하여 해당 함수를 매핑한 딕셔너리입니다. 이 딕셔너리는 도구에서 함수를 호출할 때 사용됩니다.
9. `tools`: 도구의 목록입니다. 각 도구에는 이름, 설명 및 매개변수 정의가 포함됩니다.
10. `preamble`: 작업 및 맥락에 대한 사전 설명입니다.
11. `message`: 사용자의 요청 메시지입니다. 판매 요약과 'Electronics' 카테고리의 제품 세부 정보를 요청합니다.
12. `response = co.chat(...)` : Cohere API를 사용하여 메시지에 대한 응답을 가져옵니다. 이때 도구 목록과 사전 설명을 제공합니다.
13. `print("The model recommends doing the following tool calls:")`: 모델이 추천하는 도구 호출을 출력합니다.
14. `print("\n".join(str(tool_call) for tool_call in response.tool_calls))`: 모델이 추천하는 도구 호출 목록을 출력합니다.
15. `tool_results = []`: 도구 실행 결과를 저장할 빈 리스트를 만듭니다.
16. `for tool_call in response.tool_calls:`: 모델이 추천한 각 도구 호출에 대해 반복합니다.
17. `print(f"= running tool {tool_call.name}, with parameters: {tool_call.parameters}")`: 각 도구 호출의 이름과 매개변수를 출력합니다.
18. `output = functions_map[tool_call.name](**tool_call.parameters)`: 해당 도구를 호출하고 결과를 가져옵니다.
19. `outputs = [output]`: 결과를 리스트로 래핑합니다.
20. `tool_results.append({ ... })`: 도구 호출과 결과를 딕셔너리로 묶어 `tool_results` 리스트에 추가합니다.
21. `for tool_result in tool_results:`: 도구 실행 결과 목록을 반복합니다.
22. `if "call" not in tool_result or "name" not in tool_result["call"]:`: 각 결과에 호출 이름이 있는지 확인합니다.
23. `raise ValueError("tool_results의 모든 요소에는 'name' 속성이 지정된 호출이 있어야 합니다.")`: 호출 이름이 없으면 ValueError를 발생시킵니다.
24. `print("Tool results that will be fed back to the model in step 4:")`: 도구 결과를 출력합니다.
25. `print(json.dumps(tool_results, indent=4, default=str))`: 도구 결과를 JSON 형식으로 출력합니다.
26. `response = co.chat(...)` : 도구 실행 결과를 기반으로 최종 응답을 생성합니다.
27. `print("Final answer:")`: 최종 응답을 출력합니다.
28. `print(response.text)`: 최종 응답 텍스트를 출력합니다.
위의 코드는 다음과 같은 과정을 거쳐 동작합니다.
1. 필요한 라이브러리를 가져오고, Cohere API에 연결하고, SQLite 데이터베이스에 연결합니다.
2. 판매 보고서 및 제품 카탈로그를 조회하기 위한 함수를 정의합니다.
3. 각 함수와 해당하는 도구를 매핑합니다.
4. 각 도구에 대한 정보를 tools 리스트에 정의합니다.
5. 작업과 스타일 가이드를 포함한 사전 정보를 설정합니다.
6. 사용자의 요청 메시지를 작성합니다.
7. Cohere API를 사용하여 모델에게 메시지를 보내고, 어떤 도구를 사용해야 하는지 추천받습니다.
8. 모델이 추천한 도구를 실행하고, 그 결과를 tool_results 리스트에 저장합니다.
9. tool_results 리스트에 있는 결과를 다시 확인하고, 잘못된 결과가 없는지 확인합니다.
10. 모델에게 최종 응답을 제공하기 위해, 이전 단계에서 얻은 결과를 사용하여 다시 Cohere API를 호출합니다.
11. 모델이 생성한 최종 응답을 출력합니다.
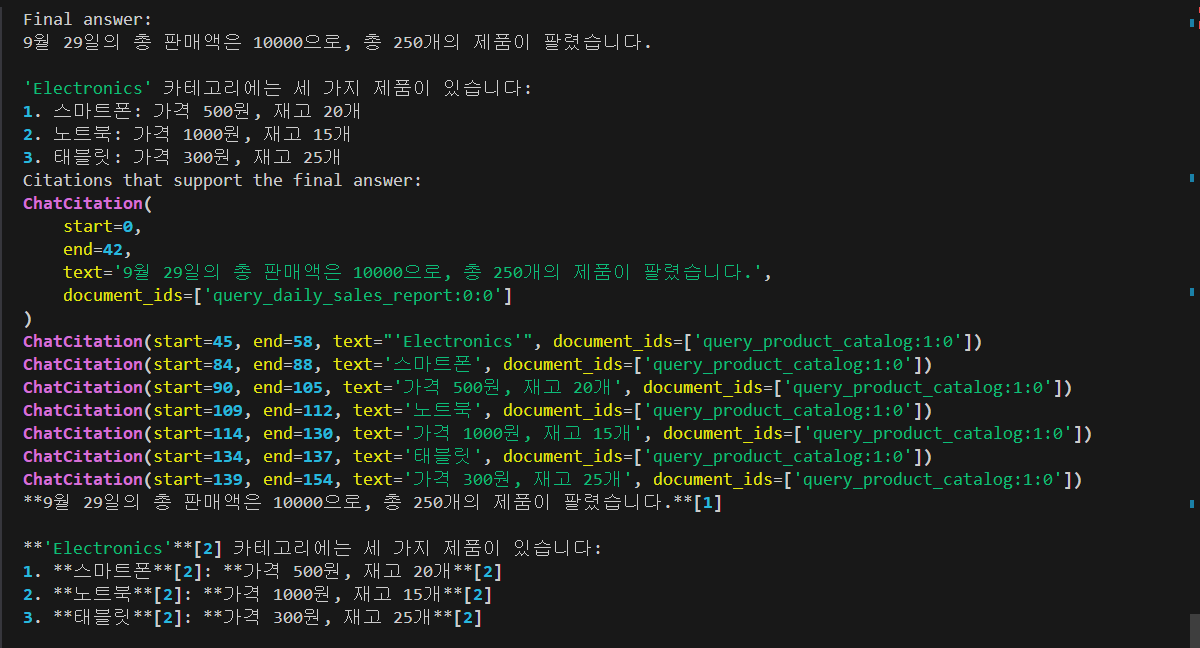
이러한 프로세스를 통해 사용자의 요청에 대한 응답을 생성하고, 필요한 도구 및 데이터를 적절하게 활용하여 결과를 제공합니다. 아래 화면은 코드를 실행한 결과입니다. 9월 29일의 총판매액과 전자제품 카테고리의 재고 정보가 출력됩니다.

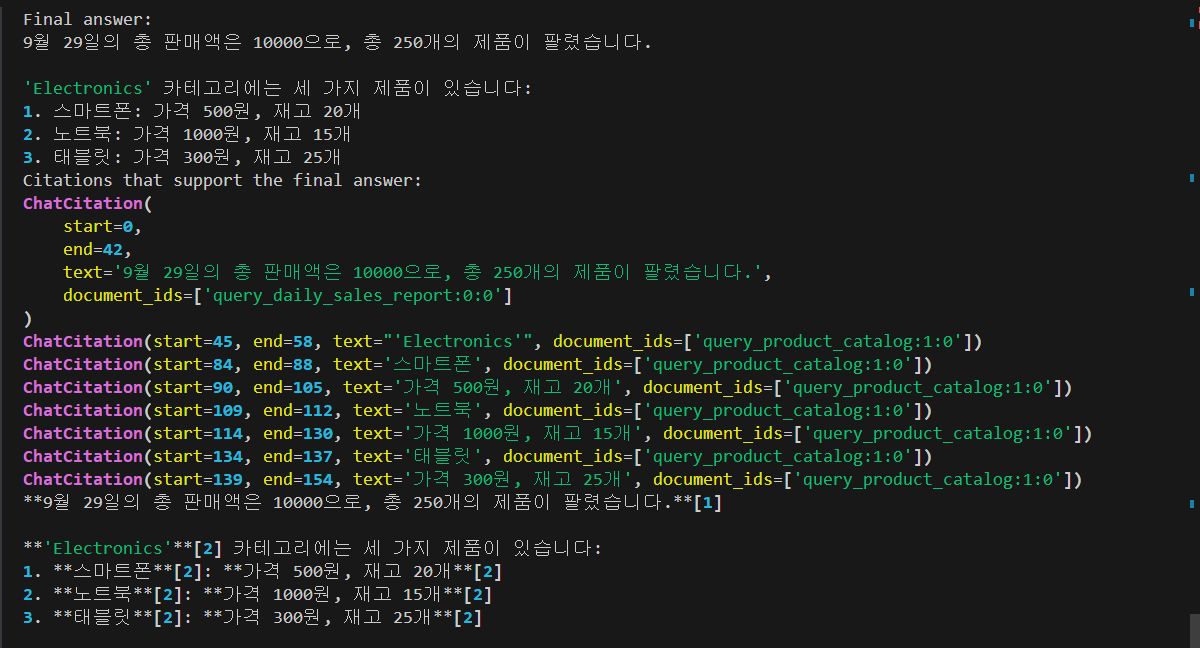
위 실행 결과에 표시된 내용에 대한 설명은 다음과 같습니다:
- 먼저, 모델이 "2023년 9월 29일의 판매 요약 정보를 제공하고, 'Electronics' 카테고리의 제품에 대한 세부 정보도 알려주세요"라는 요청에 따라 두 가지 도구 호출을 권장합니다. 첫 번째 도구는 "query_daily_sales_report"이며, 두 번째는 "query_product_catalog"입니다.
- 각 도구는 요청된 정보를 데이터베이스에서 검색하고 해당 결과를 출력합니다. 첫 번째 도구는 2023년 9월 29일의 총판매액과 판매된 제품 수를 반환하고, 두 번째 도구는 'Electronics' 카테고리에 속하는 제품들의 목록을 반환합니다.
- 각 도구 호출 결과는 모델에 다시 전달됩니다. 이 결과는 최종 응답 생성에 사용됩니다.
- 마지막으로, 모델이 최종 응답을 생성하고 제공된 정보를 요약하여 사용자에게 반환합니다. 여기에는 9월 29일의 판매 정보와 'Electronics' 카테고리에 속하는 제품 목록이 포함됩니다. 또한, 최종 응답에는 각 정보의 출처를 나타내는 인용문도 포함되어 있습니다.
- 마지막으로, 각 인용문에는 해당 정보가 어디에서 나왔는지를 설명하는 추가 정보가 포함됩니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
맺음말
오늘은 Cohere라는 대규모 언어 모델 기반 응용 프로그램 구축 플랫폼에 대해 알아보았습니다. Cohere는 Command-R이라는 언어 모델을 통해 대화형 도구 사용, 검색 및 RAG(검색 증강 생성) 시스템 개선, Fine-Tuned 모델 생성 등 다양한 기능을 제공합니다. 또한, Cohere는 API나 클라우드 등의 다양한 접근 방식을 통해 사용자가 편리하게 접근할 수 있으며, 한국어를 포함한 10개 주요 언어를 지원합니다.
오늘 다룬 내용을 간략하게 요약하면 다음과 같습니다.
- Cohere 플랫폼 소개: Cohere는 대규모 언어 모델 기반 플랫폼으로, 대화형 응용 프로그램을 구축할 수 있도록 지원합니다. 다양한 기능을 제공하며, 사용자의 요구에 맞게 모델을 세밀하게 조정하고 배포할 수 있습니다.
- Command-R 언어 모델: Command-R은 대화형 상호작용 및 긴 문맥 작업에 최적화된 대규모 언어 모델입니다. 높은 성능과 정확도를 제공하며, 다양한 환경에서 확장 가능하도록 설계되었습니다.
- SQLite DB와 AI 통합 예제: SQLite 데이터베이스와 Cohere API를 사용하여 판매 보고서 및 제품 카탈로그 정보를 제공하는 예제 코드를 살펴보았습니다. 모델은 사용자의 요청에 따라 어떤 도구를 사용할지 결정하고, 도구를 실행하여 결과를 반환합니다.
우리가 평소에 사용하던 모든 것이 AI 언어 모델과 결합되어 가고 있네요. 오늘 블로그 내용이 여러분에게 도움이 되었기를 바라면서 저는 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다!
2024.02.29 - [AI 도구] - Groq LPU : 논문 한편 요약하는데 입력-추론-응답까지 2.4초!
Groq LPU : 논문 한편 요약하는데 입력-추론-응답까지 2.4초!
안녕하세요! 오늘은 Groq이라는 회사의 대형 언어 모델 추론성능 가속장치, LPU(Language Processing Unit)에 대해서 알아보겠습니다. Groq은 2016년에 과거 구글 직원이었던 조나단 로스에 의해 설립된 AI
fornewchallenge.tistory.com

'AI 도구' 카테고리의 다른 글
| PraisonAI: 명령어 1줄! 코드 없이 AI 에이전트로 영화 대본 만들기 (0) | 2024.03.28 |
|---|---|
| 오픈소스 AI 엔지니어 Devika 체험: 계획-검색-코딩 자동화 성공! (0) | 2024.03.24 |
| Ultralytics YOLO v8: 누구나 손쉽게 할 수 있는 컴퓨터 비전 작업 솔루션 (2) | 2024.03.22 |
| 🚀Groq API와 Streamlit으로 만드는 슈퍼 패스트 웹사이트 URL 채팅봇! (2) | 2024.03.16 |
| 🚀 Groq LPU에 날개를 달아주는 FunckyCall 프록시 서버 완벽 가이드 (0) | 2024.03.14 |



