안녕하세요! 오늘은 초당 500 토큰 이상의 추론 가속성능을 가진 Groq API와 파이썬 라이브러리 Streamlit을 활용해서 웹사이트 URL입력으로 내용을 빠르게 파악하고 대화하는 웹 페이지를 만들어보겠습니다. Streamlit은 데이터 처리, 시각화, 인터랙션 등을 수행하고, 이를 웹 브라우저에서 실시간으로 확인할 수 있 웹 애플리케이션 프레임워크입니다. Streamlit을 활용하면 같은 화면에서 URL만 바꿔서 입력하여 바로 응답을 얻을 수 있습니다. 이 블로그에서는 Groq API와 Streamlit을 활용해서 웹사이트 URL 채팅봇을 만들어 보겠습니다.


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Groq API, Streamlit 개요
Groq API는 대형 언어 모델 전용 추론 가속 장치인 Groq LPU (Language Processing Unit)를 기반으로 언어 모델을 사용하여 자연어 처리 및 다양한 언어 관련 작업을 수행하는 데 사용되는 API입니다. 이 API를 사용하면 사용자는 텍스트 기반의 입력을 제공하고 해당 입력에 대해 기존 인공지능 모델보다 매우 빠른 응답을 얻을 수 있습니다.
Groq API를 사용하기 위해서는 먼저 https://console.groq.com/keys에 접속해서 아래 화면과 같이 "Create API Key" 버튼을 클릭해서 새로운 API Key를 발급받습니다. 기타 Groq API에 대한 자세한 내용은 아래 포스트를 참고하시면 됩니다.
2024.02.29 - [AI 도구] - Groq LPU : 논문 한편 요약하는데 입력-추론-응답까지 2.4초!
Groq LPU : 논문 한편 요약하는데 입력-추론-응답까지 2.4초!
안녕하세요! 오늘은 Groq이라는 회사의 대형 언어 모델 추론성능 가속장치, LPU(Language Processing Unit)에 대해서 알아보겠습니다. Groq은 2016년에 과거 구글 직원이었던 조나단 로스에 의해 설립된 AI
fornewchallenge.tistory.com
Streamlit은 머신러닝과 데이터 과학을 위한 웹 애플리케이션을 만들고 공유하기 쉽게 해주는 오픈 소스 Python 라이브러리이며, Streamlit을 사용하면 몇 분 만에 손쉽게 데이터 앱을 구축하고 배포할 수 있습니다. Streamlit의 특징 및 장점은 다음과 같습니다.
- 실시간 업데이트: 코드를 수정하고 저장할 때마다 Streamlit 애플리케이션은 자동으로 새로 고쳐져서 최신 결과를 반영합니다. 이를 통해 빠르게 반복 및 개발할 수 있습니다.
- 다양한 컴포넌트: Streamlit은 텍스트, 표, 차트, 이미지, 위젯 등 다양한 컴포넌트를 지원하여 다양한 종류의 데이터와 결과물을 시각화할 수 있습니다.
- 상호작용성: 사용자는 Streamlit 애플리케이션을 통해 데이터와 모델에 대한 상호작용을 할 수 있습니다. 예를 들어, 사용자가 슬라이더를 조작하거나 버튼을 클릭하여 데이터를 필터링하거나 모델을 조작할 수 있습니다.
- 배포 및 공유: Streamlit 애플리케이션은 간단한 명령으로 배포되고, 다른 사용자와 공유하기 쉽습니다. 또한 Streamlit 공식 호스팅 플랫폼을 통해 애플리케이션을 온라인에 쉽게 배포할 수도 있습니다.
환경설정 및 의존성 설치
다음은 환경설정 및 의존성 설치단계입니다. 이 블로그에서 사용한 예제코드의 실행환경은 WSL(Windows Subsystem for Linux) 이며, 에디터는 비주얼 스튜디오 코드입니다. "python3.11 -m venv myenv"와 "source myenv/bin/activate" 명령어를 통해 가상환경을 생성 및 활성화 한 다음, 아래 코드를 requirements.txt 로 저장한 후, "pip install -r requirements.txt" 명령어로 의존성(dependency)을 설치해줍니다.
streamlit
groq
langchain
langchain-groq
python-dotenv
beautifulsoup4
faiss-cpu
ollama
의존성 설치에 포함된 각 라이브러리들의 용도는 다음과 같습니다.
| 라이브러리 | 용도 |
| Streamlit | 데이터 과학 및 머신러닝 실시간 웹 애플리케이션 개발 및 공유 |
| Groq | 대규모 언어 모델의 추론성능 가속화를 위한 기술 개발 |
| Langchain | 자연어 처리 및 관련 작업을 위한 오픈 소스 라이브러리 |
| Langchain-groq | Groq API를 통한 자연어 처리 및 관련 작업을 지원하는 Langchain 확장 라이브러리 |
| Python-dotenv | 파이썬 환경 변수 관리를 위한 도구 |
| Beautifulsoup4 | HTML 및 XML 문서 파싱 및 탐색을 위한 라이브러리 |
| Faiss-cpu | 대량의 벡터 데이터에 대한 빠른 유사성 검색을 위한 Faiss 라이브러리의 CPU 버전 |
| Ollama | 자연어 처리 작업을 위한 벡터 임베딩 라이브러리 |
의존성 설치가 완료되면 아래 명령어를 이용하여 환경 변수인 GROQ_API_KEY에 본인이 발급받은 GROQ_API_KEY값을 할당해 줍니다. 보통 API 키나 비밀 정보와 같은 중요한 값들은 환경 변수에 저장하여 보안을 유지하고 소스 코드에 민감한 정보가 노출되지 않도록 합니다. 이렇게 하면 보안상의 이점을 얻을 수 있으며, 필요할 때 쉽게 값만 변경하여 관리할 수 있습니다.
또한 문서의 내용을 벡터로 변환하기위한 임베딩 모델은 Ollama의 Llama2 모델을 사용하므로 대형 언어 모델 활용도구인 Ollama를 설치하여 "ollama pull llama2" 명령어로 언어 모델을 사전에 다운로드 해놓아야 합니다. Ollama의 설치는 아래 포스트를 참고하시기 바랍니다.
export GROQ_API_KEY="본인이 발급받은 Groq API Key값"
2023.12.15 - [대규모 언어모델] - Ollama를 활용한 대규모 언어 모델 웹 인터페이스 만들기: Mistral 7B와의 대화
Ollama를 활용한 대규모 언어 모델 웹 인터페이스 만들기: Mistral 7B와의 대화
안녕하세요. 오늘은 내 컴퓨터에서 웹 인터페이스로 최신 언어모델과 대화하는 프로젝트에 도전해 보겠습니다. 이 블로그에서는 Ollama라는 오픈소스 도구를 이용해서 최신 인기 대규모 언어모
fornewchallenge.tistory.com
URL 채팅예제
다음은 예제코드 실행 단계입니다. 예제코드의 출처는 유튜브 "Chat with Documents is Now Crazy Fast thanks to Groq API and Streamlit"이며, 블로그 내용을 위해 일부 수정하였습니다. 이 코드는 사용자가 입력한 URL에서 웹 페이지를 로드하고, 해당 페이지의 내용을 사용하여 질문에 답변하는 Streamlit 애플리케이션으로 코드의 동작순서는 다음과 같습니다.
- 1. 사용자는 "Enter the URL of the article" 텍스트 상자에 URL을 입력합니다.
- 2. 사용자가 URL을 입력하면, 해당 URL에서 웹 페이지를 로드하고, 그 내용을 사용하여 질문에 답변할 수 있도록 합니다.
- 3. 웹 페이지에서 로드된 문서들은 OllamaEmbeddings를 사용하여 임베딩됩니다. 이는 문서의 내용을 벡터로 변환하여 분석 및 유사성 비교에 사용됩니다. OllamaEmbedding은 기본적으로 Ollama의 Llama2 모델을 사용합니다.
- 4. 문서들은 RecursiveCharacterTextSplitter를 사용하여 적절한 크기의 청크로 분할됩니다. 이것은 문서를 작은 조각으로 나누어 처리 효율성을 높이는 데 도움이 됩니다.
- 5. 분할된 문서들은 FAISS를 사용하여 벡터 검색 인덱스로 변환됩니다. 이 인덱스는 문서들 간의 유사성을 측정하고, 유사한 문서를 찾는 데 사용됩니다.
- 6. ChatGroq를 사용하여 사용자가 입력한 질문에 대한 답변을 생성합니다. 이때, 사용자가 입력한 질문은 ChatPromptTemplate을 사용하여 적절한 형식으로 변환됩니다.
- 7. 생성된 답변과 함께, "Response time"과 "Token speed"가 출력됩니다. "Response time"은 질문에 대한 답변을 생성하는 데 걸린 시간을 나타내며, "Token speed"는 답변에 사용된 토큰의 속도를 나타냅니다.
- 8. "Document Similarity Search" 확장 메뉴를 통해, 사용자에게 답변에 사용된 문서와 유사한 다른 문서들을 표시합니다.
이러한 단계를 거쳐서 사용자가 입력한 URL의 웹 페이지를 기반으로 자연어 처리 모델을 사용하여 질문에 답변하고, 관련 문서를 제공하는 Streamlit 애플리케이션이 실행됩니다. 아래 코드를 복사하여 groqstreamlit.py로 저장합니다.
import os
import streamlit as st
from langchain_groq import ChatGroq
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains import create_retrieval_chain
import time
from dotenv import load_dotenv
load_dotenv() #
groq_api_key = os.environ['GROQ_API_KEY']
st.title("Chat with URLs - Powered by Groq API")
url_input = st.text_input("Enter the URL of the article:")
if url_input:
embeddings = OllamaEmbeddings()
loader = WebBaseLoader(url_input)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
documents = text_splitter.split_documents(docs)
vector = FAISS.from_documents(documents, embeddings)
llm = ChatGroq(groq_api_key=groq_api_key, model_name='mixtral-8x7b-32768')
prompt = ChatPromptTemplate.from_template("""
Answer the following question based only on the provided context.
Think step by step before providing a detailed answer.
I will tip you $200 if the user finds the answer helpful.
<context>
{context}
</context>
Question: {input}""")
document_chain = create_stuff_documents_chain(llm, prompt)
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
prompt_text = st.text_input("Input your prompt here")
if prompt_text:
start_time = time.process_time()
response = retrieval_chain.invoke({"input": prompt_text})
end_time = time.process_time()
response_time = end_time - start_time
token_speed = len(response["answer"].split()) / response_time # 토큰 속도 계산
st.write(f"Response time: {response_time} seconds")
st.write(f"Token speed: {token_speed:.2f} tokens/s") # 소수점 둘째 자리까지 출력
st.write(response["answer"])
with st.expander("Document Similarity Search"):
for i, doc in enumerate(response["context"]):
st.write(doc.page_content)
st.write("--------------------------------")
다음은 "streamlit run groqstreamlit.py" 명령어를 입력해서 예제 코드를 실행하면 http://localhost:8501/주소에서 아래 화면과 같이 페이지 제목과 URL 입력상자로 구성된 Streamlit 초기화면이 나옵니다.

우측 모서리 상단의 Settings 메뉴에서 Wide mode를 클릭하면 가독성을 더 높일 수 있습니다.

다음은 URL 입력상자에 본인이 원하는 웹페이지 주소를 입력합니다. 저는 피규어 01 휴머노이드에 관한 기사의 URL을 입력하였습니다.
OpenAI-powered humanoid is 'closest robot to a human being, ever', to challenge Tesla's Optimus
Figure’s humanoid robot Figure 01 showcased new features that was added to it thanks to OpenAI’s LLMs. With the new features, Figure claims that their Figure 01 robot is now the closest a humanoid has been to a robot
www.firstpost.com
URL을 입력한 후 프롬프트 입력란에 질문내용을 입력하면 아래 화면과 같이 원하는 응답을 얻을 수 있습니다.
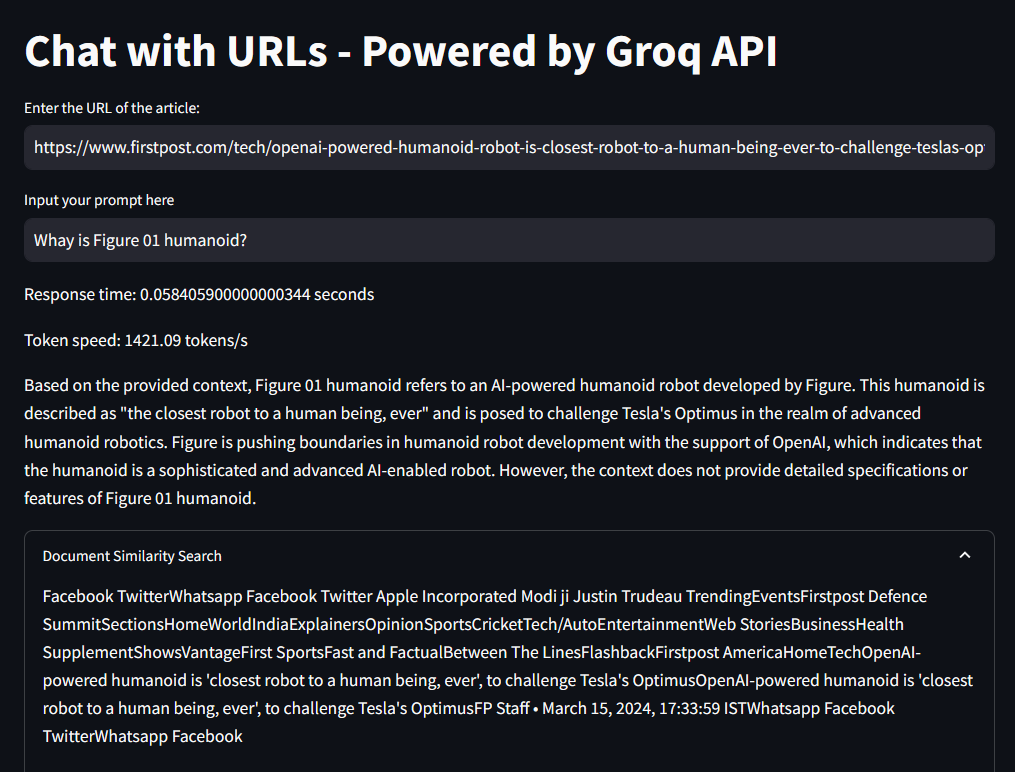
웹 브라우저의 번역기능을 활용하면 다음과 같이 좀 더 쉽게 응답내용을 파악하실 수 있으며, 이 상태에서 웹사이트의 URL을 바꿔서 입력하면 응답내용도 자동으로 변경됩니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
맺음말
오늘은 Groq API와 Streamlit을 활용하여 웹사이트 URL을 입력받고, 해당 웹 페이지의 내용을 기반으로 자연어 처리 모델을 사용하여 질문에 응답하고 관련 문서를 제공하는 웹 애플리케이션을 만드는 방법을 살펴보았습니다. Groq API는 대형 언어 모델을 효율적으로 활용할 수 있도록 해주는 기술로, 빠른 추론 속도를 제공하며, Streamlit은 이러한 기술을 바탕으로 데이터 앱을 신속하게 구축하고 공유할 수 있는 웹 애플리케이션 프레임워크입니다.
Groq API나 Streamlit과 같은 기술과 도구들을 활용하면 자연어 처리 및 정보 검색에 관련된 다양한 작업을 보다 신속하고 효율적으로 수행할 수 있으며, 사용자에게 더 나은 웹 경험을 제공할 수 있습니다. 여러분도 한번 간단한 웹 애플리케이션을 만들어 보시면 어떨까요? 그럼 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2024.03.14 - [AI 도구] - 🚀 Groq LPU에 날개를 달아주는 FunckyCall 프록시 서버 완벽 가이드
🚀 Groq LPU에 날개를 달아주는 FunckyCall 프록시 서버 완벽 가이드
안녕하세요! 오늘은 최근 혁신적인 추론속도로 주목받고 있는 Groq의 LPU 언어 모델이 인터넷 검색과 같은 다양한 함수처리 기능을 통합할 수 있도록 지원하는 FunckyCall이라는 프록시 서버에 대해
fornewchallenge.tistory.com

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다.
'AI 도구' 카테고리의 다른 글
| 🛠️📈Cohere: 쿼리 없이 데이터베이스와 AI로 대화하는 방법 (0) | 2024.03.23 |
|---|---|
| Ultralytics YOLO v8: 누구나 손쉽게 할 수 있는 컴퓨터 비전 작업 솔루션 (2) | 2024.03.22 |
| 🚀 Groq LPU에 날개를 달아주는 FunckyCall 프록시 서버 완벽 가이드 (0) | 2024.03.14 |
| MusicLang: 대형 언어 모델로 누구나 쉽게 MIDI 음악 작곡하기 (0) | 2024.03.13 |
| [꿀팁] 비행기 모드 AI 채팅! MLCChat으로 스마트폰 데이터 연결 없이 AI 즐기기 (0) | 2024.03.10 |



