안녕하세요! 오늘은 Unsloth라는 대형 언어 모델 훈련도구에 대해서 알아보겠습니다. Unsloth는 메모리를 효율적으로 사용하여 대형 언어 모델을 더 빠르게 훈련시킬 수 있도록 지원하는 도구입니다. 해당 도구는 PyTorch를 기반으로 하며, 주로 CUDA를 사용하는 NVIDIA GPU에서 작동합니다. 이 블로그에서는 Unsloth의 기능과 특징, 설치방법, 코랩을 이용한 LLM 훈련 및 로컬 저장방법 등에 대해서 알아보겠습니다.


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Unsloth란?
Unsloth는 LLM(대규모 언어 모델)의 훈련을 최적화하기 위한 도구입니다. 이 도구는 훈련 속도를 높이고 메모리 사용량을 줄이며 정확성을 유지하거나 향상시킬 수 있도록 하며, 기능과 특징은 다음과 같습니다.
Unsloth 기능 및 특징
- 훈련 속도 향상: 기존에 비해 대규모 언어 모델의 훈련 속도를 약 30배 향상시킬 수 있습니다. 이를 통해 훈련 시간을 단축하고 빠른 실험을 수행할 수 있습니다. 기존의 Alpaca 모델의 훈련 시간이 85시간이 걸리는데 비해, Unsloth의 경우 3시간으로 단축됩니다.
- 메모리 사용량 감소: 최적화된 메모리 관리 기술을 사용하여 훈련 중에 사용되는 메모리 양을 줄일 수 있습니다. 이는 더 큰 배치 크기를 사용하거나 더 복잡한 모델을 훈련하는 데 도움이 됩니다. Unsloth를 사용하면 메모리 사용량을 줄여서 6배 더 큰 배치를 사용할 수 있습니다.
- 정확성 유지 또는 향상: Unsloth는 훈련 속도를 높이면서도 모델의 정확성을 유지하거나 향상시킬 수 있습니다. 이를 통해 빠른 훈련 속도와 높은 정확성을 동시에 달성할 수 있습니다.
- 다양한 하드웨어 지원: NVIDIA, Intel 및 AMD GPU를 지원하며 다양한 하드웨어 환경에서 사용할 수 있습니다.
- LoRA 어댑터 지원: Unsloth를 사용하면 LoRA 어댑터를 훈련시키고 로드하여 모델을 개선할 수 있습니다. 이를 통해 모델의 훈련 및 성능을 최적화할 수 있습니다. LoRA 어댑터에 대한 자세한 내용은 아래 더 보기를 클릭하세요
LoRA(Linearly lOptimized Real-time Adapters) 어댑터는 학습된 언어 모델을 고속화하기 위한 기술 중 하나입니다. LoRA는 선형 레이어를 최적화하는 데 중점을 두며, 특히 언어 모델의 Self-Attention 레이어에 적용됩니다. 일반적으로, 언어 모델의 학습 속도를 높이기 위해 Self-Attention 레이어의 선형 레이어에 Low-Rank Approximation이 적용됩니다. 이러한 근사 기법은 계산량을 줄이고 메모리 사용량을 최적화하여 모델의 효율성을 향상시킵니다.
LoRA 어댑터는 이러한 Low-Rank Approximation을 구현하는 데 사용되며, 언어 모델의 성능을 유지하면서도 학습 및 추론 속도를 향상시킵니다. LoRA 어댑터는 다양한 모델과 프레임워크에서 사용할 수 있으며, 일반적으로 Hugging Face의 Transformers 라이브러리와 같은 라이브러리를 통해 쉽게 적용할 수 있습니다. 이러한 어댑터는 머신 러닝 모델의 효율성을 극대화하기 위한 중요한 도구 중 하나입니다.
- 추론 속도 향상: Unsloth는 모델의 추론 속도를 향상시킵니다. 이를 통해 모델을 실제 환경에서 더 빠르게 실행할 수 있습니다.
Unsloth 속도향상 원리
Unsloth는 대규모 언어 모델을 훈련하고 최적화하는 데 유용한 도구이며, 빠른 개발과 실험을 가능하게 합니다. Unsloth의 속도 향상은 주로 다음과 같은 방법을 통해 이루어집니다.
- 최적화된 커널 사용: Unsloth는 Triton과 같은 커널 최적화 기술을 사용하여 모델의 핵심 연산을 최적화합니다. Triton 커널은 PyTorch 모델의 연산을 GPU에서 더 효율적으로 실행할 수 있도록 최적화된 커널로, 일반적인 PyTorch 연산보다 훨씬 빠른 속도를 제공할 수 있습니다.
- 메모리 최적화: Unsloth는 메모리 사용을 최적화하여 GPU의 메모리 사용량을 줄입니다. 이는 GPU에서 동시에 처리할 수 있는 데이터 양을 늘려 더 많은 연산을 동시에 수행할 수 있게 합니다.
- 경사하강법 최적화: Unsloth는 경사하강법 최적화 과정을 최적화하여 모델의 학습 속도를 향상시킵니다. 이는 모델의 가중치를 더 빠르게 업데이트하여 학습 속도를 높이는 데 도움이 됩니다. 아래 더 보기를 클릭하시면 경사하강법 최적화에 대해 알아보실 수 있습니다.
경사하강법(Gradient Descent)은 기계 학습과 최적화에서 널리 사용되는 반복적인 최적화 알고리즘 중 하나입니다. 이 알고리즘은 함수의 최솟값을 찾기 위해 함수의 기울기(경사)를 이용합니다. 주어진 함수의 최솟값을 찾는 문제에서, 경사하강법은 현재 위치에서 함수의 기울기(경사)를 계산하고, 이를 이용하여 다음 단계로 이동합니다. 이 과정은 함수가 최솟값에 도달할 때까지 반복됩니다. 경사하강법의 주요 구성 요소와 작동 방식은 다음과 같습니다:
- 손실 함수(Loss Function): 경사하강법은 주어진 문제에 대한 손실 함수(또는 비용 함수)를 최소화하는 것을 목표로 합니다. 이 손실 함수는 모델의 예측과 실제 값 사이의 오차를 측정합니다. 경사하강법은 이 손실 함수를 최소화하기 위해 모델의 파라미터를 조정합니다.
- 기울기(Gradient) 계산: 경사하강법은 현재 위치에서 손실 함수의 기울기(경사)를 계산합니다. 이를 통해 함수가 감소하는 방향으로 이동할 수 있는 방향을 찾습니다. 경사하강법은 기울기를 계산하기 위해 미분 또는 자동 미분(예: 역전파)을 사용합니다.
- 학습률(Learning Rate): 경사하강법은 각 단계에서 이동할 거리를 결정하는 학습률 파라미터를 사용합니다. 학습률은 보통 0과 1 사이의 값으로 설정되며, 한 번의 업데이트 당 파라미터 값이 얼마나 변화할지를 제어합니다.
- 파라미터 업데이트: 경사하강법은 현재 위치에서 계산된 기울기를 사용하여 파라미터를 업데이트합니다. 업데이트는 현재 파라미터 값에서 학습률과 기울기를 곱한 값을 빼는 방식으로 이루어집니다. 이를 통해 손실 함수를 최소화하는 새로운 파라미터 값을 찾습니다.
- 수렴: 경사하강법은 손실 함수가 충분히 작아지거나 일정한 값 이하로 떨어질 때까지 반복적으로 파라미터를 업데이트합니다. 이를 통해 최적화된 파라미터를 찾고, 모델을 학습시킵니다.
경사하강법은 최적화 문제를 효과적으로 해결할 수 있는 강력한 알고리즘입니다. 하지만 학습률과 같은 하이퍼파라미터를 올바르게 설정해야 하며, 때로는 수렴하기 위해 다양한 최적화 알고리즘이 필요할 수 있습니다.
- 병렬화 및 배치 처리: Unsloth는 병렬화 기술과 배치 처리를 통해 모델의 학습을 더 효율적으로 수행합니다. 이는 GPU에서 동시에 여러 데이터를 처리하고 병렬로 연산을 수행함으로써 학습 속도를 높이는 데 도움이 됩니다.
이러한 속도 향상 기술들을 통해 Unsloth는 대규모 모델의 학습 및 미세 조정 속도를 크게 향상시킬 수 있습니다. 이는 연구 및 응용 분야에서 더 빠른 실험 및 개발을 가능하게 하여 생산성을 향상시킵니다.
Unsloth 라이브러리 설치
Unsloth가 메모리 사용량을 줄여주지만 Unsloth로 LLM을 로컬에서 훈련시키기 위해서는 최소 GPU RAM이 11GB 이상 필요합니다. GPU RAM 용량을 만족하는 경우에만 설치를 시도하시는 것이 시간을 절약하실 수 있을 것 같습니다. 제 컴퓨터도 GPU RAM 용량 부족으로 학습을 완료시키지 못해서 충돌 없이 패키지를 설치하는 단계까지만 전해드리겠습니다.
GPU Unsloth의 설치 방법은 Conda 또는 Pip을 사용하여 설치할 수 있습니다. Conda를 사용하는 경우 특정 CUDA 버전을 선택하여 설치할 수 있으며, Pip를 사용하는 경우 CUDA 버전에 따라 적절한 패키지를 선택하여 설치할 수 있습니다.
먼저 내 컴퓨터에 설치된 CUDA 컴파일러의 버전을 "nvcc --version" 명령으로 확인합니다.

다음은 pytorch 라이브러리 torch, torchvision, torchaudio과 xformers, triton을 설치해야 하는데요. 이 라이브러리들의 용도 및 기능은 아래 표와 같습니다. 제가 확인한 내용으로는 xformers와 충돌 없는 안정적인 Pytorch 버전은 2.2.0 버전이고, triton은 리눅스 플랫폼만 호환이 가능하므로, 실행환경을 셋업 할 때 꼭 참고하시면 좋을 것 같습니다.
| 라이브러리 | 용도 및 기능 |
| torch | 텐서 조작 및 수학적 연산을 위한 핵심 라이브러리로, 딥 러닝 모델의 학습 및 실행에 필요한 기본 기능을 제공합니다. |
| torchvision | 이미지 및 비디오 데이터 처리를 위한 확장 라이브러리로, 이미지 분류, 객체 검출, 영상 분할 등의 컴퓨터 비전 작업을 지원합니다. |
| torchaudio | 오디오 데이터 처리를 위한 확장 라이브러리로, 오디오 신호 처리, 음성 인식 등의 작업을 지원합니다. |
| xformers | 트랜스포머 모델링에 사용되는 다양한 어텐션 메커니즘과 최적화된 빌딩 블록을 제공하여 효율적이고 유연한 모델 구축을 지원합니다. |
| triton | 고도화된 사용자 정의 딥러닝 프리미티브를 작성하기 위한 언어 및 컴파일러로, CUDA보다 더 높은 생산성과 유연성을 제공하여 더 빠르고 효율적인 딥러닝 모델을 구현할 수 있습니다. |
https://github.com/openai/triton/tree/main
GitHub - openai/triton: Development repository for the Triton language and compiler
Development repository for the Triton language and compiler - openai/triton
github.com
다음 코드는 torch, torchvision, torchaudio과 xformers, triton 라이브러리를 설치하는 Pip 명령어이며, 맨 마지막코드는 Unsloth를 설치하는 코드입니다. Unsloth는 Pytorch와 CUDA Toolkit 버전에 따라서 설치 명령어가 조금씩 다르므로 설치 링크를 참고하시기 바랍니다. CUDA Toolkit 버전과 Pytorch버전에 주의해서 torch, torchvision, torchaudio과 xformers, triton 라이브러리를 설치하시면 됩니다.
pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0
pip install -U xformers --index-url https://download.pytorch.org/whl/cu121
pip install --upgrade --force-reinstall --no-cache-dir torch==2.2.0 triton ^
--index-url https://download.pytorch.org/whl/cu121
pip install "unsloth[cu121-ampere-torch220] @ git+https://github.com/unslothai/unsloth.git"
또 한 가지 중요한 것은 모델로딩이 끝나고 학습이 시작되는 과정에서 CUDA_HOME 디렉토리 위치와 Python의 헤더 파일 위치를 시스템에서 찾을 수 없기 때문에 발생하는 에러가 있습니다. 이 경우 본인의 WSL 시스템 상에서의 경로를 아래와 같이 학습예제 코드의 시작 부분에 지정해 주면 해당에러를 해결하실 수 있습니다.
os.environ["CUDA_HOME"] = "/usr/local/cuda-12.3"
os.environ["C_INCLUDE_PATH"] = "/usr/include/python3.10"
저는 GPU VRAM 부족으로 모델을 학습시키는 과정에서 Segmentation fault가 발생하여 학습을 완료하지 못하였습니다.


Colab환경 LLM 학습
로컬 컴퓨터의 GPU VRAM이 부족한 경우, 구글 코랩(Colab) 환경에서 Unsloth의 성능을 확인해 볼 수 있습니다.
https://colab.research.google.com/drive/10NbwlsRChbma1v55m8LAPYG15uQv6HLo?usp=sharing
Alpaca + Gemma 7b full example.ipynb
Colaboratory notebook
colab.research.google.com
위 링크는 구글 코랩에서 Unsloth를 사용하여 Gemma 7B 모델에게 알파카 데이터셋(yahma/alpaca-cleaned)을 학습시키고, 피보나치수열을 예측하도록 하는 예제코드이며, 코드의 주요 내용은 다음과 같습니다.
먼저 Google Colab 환경에서 Unsloth 라이브러리를 설치하는 작업을 수행합니다. Torch 라이브러리의 CUDA 버전을 확인하고, 해당하는 버전에 맞추어 Unsloth 라이브러리를 설치합니다.
%%capture
import torch
major_version, minor_version = torch.cuda.get_device_capability()
if major_version >= 8:
# Use this for new GPUs like Ampere, Hopper GPUs (RTX 30xx, RTX 40xx, A100, H100, L40)
!pip install "unsloth[colab-ampere] @ git+https://github.com/unslothai/unsloth.git"
else:
# Use this for older GPUs (V100, Tesla T4, RTX 20xx)
!pip install "unsloth[colab] @ git+https://github.com/unslothai/unsloth.git"
pass
다음은 Unsloth 라이브러리에서 FastLanguageModel 클래스를 import 한 후, `FastLanguageModel.from_pretrained()` 메서드를 사용하여 미리 학습된 Gemma 7B 모델을 가져옵니다. Gemma 이외에도 총 35개의 모델을 지원합니다.
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
# 4bit pre quantized models we support for 4x faster downloading + no OOMs.
fourbit_models = [
"unsloth/mistral-7b-bnb-4bit",
"unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"unsloth/llama-2-7b-bnb-4bit",
"unsloth/gemma-7b-bnb-4bit",
"unsloth/gemma-7b-it-bnb-4bit", # Instruct version of Gemma 7b
"unsloth/gemma-2b-bnb-4bit",
"unsloth/gemma-2b-it-bnb-4bit", # Instruct version of Gemma 2b
] # More models at https://huggingface.co/unsloth
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/gemma-7b-bnb-4bit", # Choose ANY! eg teknium/OpenHermes-2.5-Mistral-7B
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
다음은 FastLanguageModel 클래스의 get_peft_model 메서드를 사용하여 주어진 모델의 특정 레이어를 수정하거나 추가하여 모델의 성능을 향상시키는 작업을 수행합니다.
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
use_gradient_checkpointing = True,
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
다음은 "yahma/alpaca-cleaned" 데이터셋에서 각 예제의 지시사항(instruction), 입력(input), 출력(output)을 가져와서 이를 특정한 서식에 맞게 조합하여 최종적으로 생성된 텍스트를 반환합니다. "yahma/alpaca-cleaned" 데이터셋은 아래 화면과 같이 지시사항, 입력, 출력으로 구성된 52,000개의 데이터로 구성되어 있습니다.
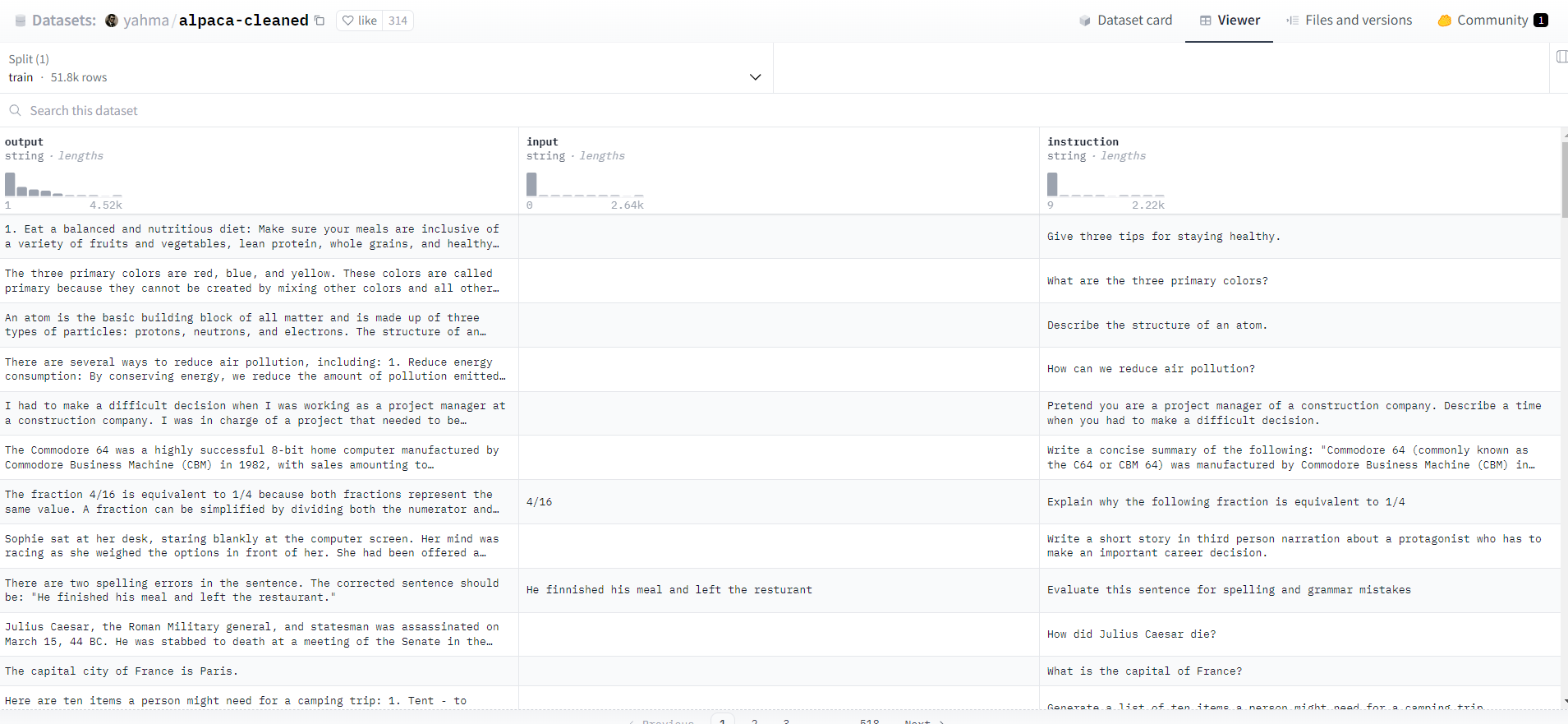
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
from datasets import load_dataset
dataset = load_dataset("yahma/alpaca-cleaned", split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)
다음 코드는 Transfer Learning Library (TRL)를 사용하여 모델을 학습하는 과정입니다. SFTTrainer를 사용하여 모델, 토크나이저, 학습 데이터셋, 학습 파라미터 등을 설정하고 Gemma 7B 모델을 학습시킵니다. TrainingArguments를 통해 학습에 필요한 다양한 하이퍼파라미터와 설정을 지정할 수 있으며, 이를 통해 모델의 성능을 조절하고 학습 과정을 관리할 수 있습니다. 아래 더 보기를 클릭하시면 Transfer Learning Library와 SFTTrainer에 대해 확인하실 수 있습니다.
Transfer Learning Library (TRL)는 Hugging Face에서 개발한 라이브러리로, 전이 학습을 위한 다양한 기능을 제공합니다. 이 라이브러리는 다양한 모델 아키텍처를 쉽게 전이 학습할 수 있도록 설계되어 있으며, 모델 학습, 평가, 추론 등을 간편하게 수행할 수 있습니다. TRL은 PyTorch와 호환되며, 대규모 자연어 처리 모델의 효율적인 학습을 지원합니다.
SFTTrainer는 Transfer Learning Library의 일부인 trl 패키지에서 제공되는 클래스입니다. 이 클래스는 Self Fine-Tuning을 위한 트레이너로 사용됩니다. Self Fine-Tuning은 사전에 학습된 언어 모델을 사용하여 주어진 지시에 따라 모델을 미세 조정하는 기술입니다. SFTTrainer를 사용하면 이러한 Self Fine-Tuning 과정을 수행할 수 있습니다. SFTTrainer는 사전에 학습된 모델, 토크나이저, 학습 데이터셋 등을 입력으로 받아 모델을 학습시키고 미세 조정합니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
이 코드는 `trainer.train()` 메서드를 호출하여 모델을 학습시키고, 학습 과정에서 발생한 통계 정보를 반환합니다. 이 통계 정보에는 각 에포크(epoch)에서의 손실(loss) 값 및 정확도(accuracy) 등의 학습 메트릭이 포함될 수 있습니다. 이 값은 모델이 학습하는 동안 각 단계(또는 반복)에서의 모델이 예측한 출력과 실제 정답 간의 차이를 나타내며, 학습이 진행됨에 따라 이 손실이 감소하게 됩니다. 이 과정에서 학습 중 소요되는 최대 메모리 양(GPU VRAM)이 11GB 이상 올라갑니다.
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)
trainer_stats = trainer.train()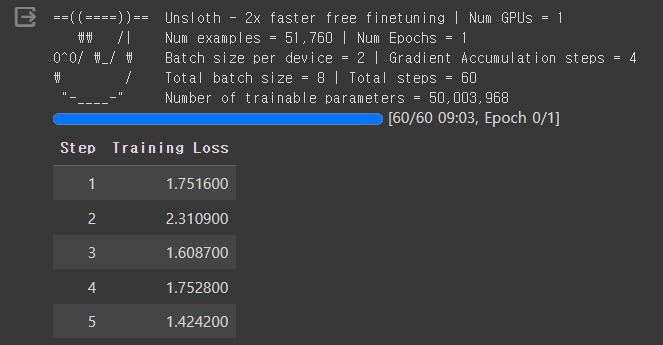

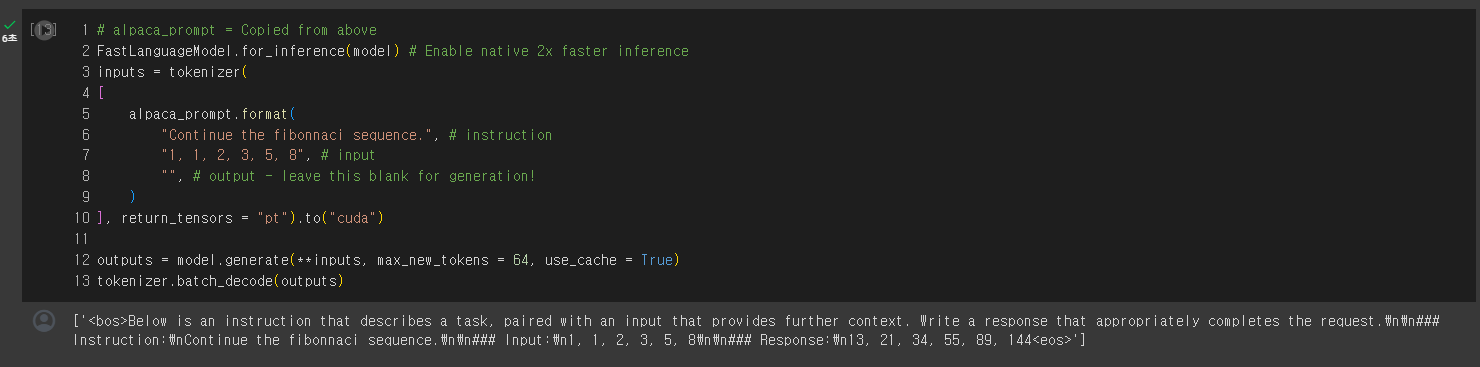
다음은 "피보나치수열을 계속하라"라는 주어진 프롬프트를 사용하여 언어 모델을 활용하여 텍스트를 생성하는 과정으로, Gemma 7B 모델은 입력된 텍스트를 기반으로 프롬프트에 대한 응답을 생성하고, 이를 디코딩하여 최종 출력을 생성합니다. 이 과정에서 CUDA를 사용하여 GPU 가속화를 수행합니다.
# alpaca_prompt = Copied from above
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"Continue the fibonnaci sequence.", # instruction
"1, 1, 2, 3, 5, 8", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True)
tokenizer.batch_decode(outputs)
학습이 모두 완료되면 아래 화면과 같이 Gemma 7B 모델이 피보나치수열을 응답하게 됩니다.
LLM 저장 및 다운로드
다음은 훈련이 완료된 후, Gemma 모델을 함께 훈련된 매개변수(weights)와 필요한 구성 요소들과 함께 파일로 저장하고 내 컴퓨터로 다운로드하는 단계입니다.
model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m")
위 코드는 모델과 토크나이저를 GGUF(GPT4All Unified Format) 파일 형식으로 저장하는 메서드를 호출하는 코드입니다. GGUF는 모델의 가중치, 토크나이저 정보 및 양자화(quantization) 관련 설정을 포함하는 특정한 파일 형식입니다. 이 코드에서는 양자화 방법을 "q4_k_m"으로 설정하여, 4비트 양자화와 클러스터링(클러스터링 센터 개수를 자동으로 선택하는 방법)을 사용하여 모델을 양자화합니다. 이 코드를 실행하면 모델의 가중치(weight)를 파일로 저장하는 과정을 통해 학습된 모델의 상태를 나중에 불러와서 재사용하거나 공유할 수 있습니다.
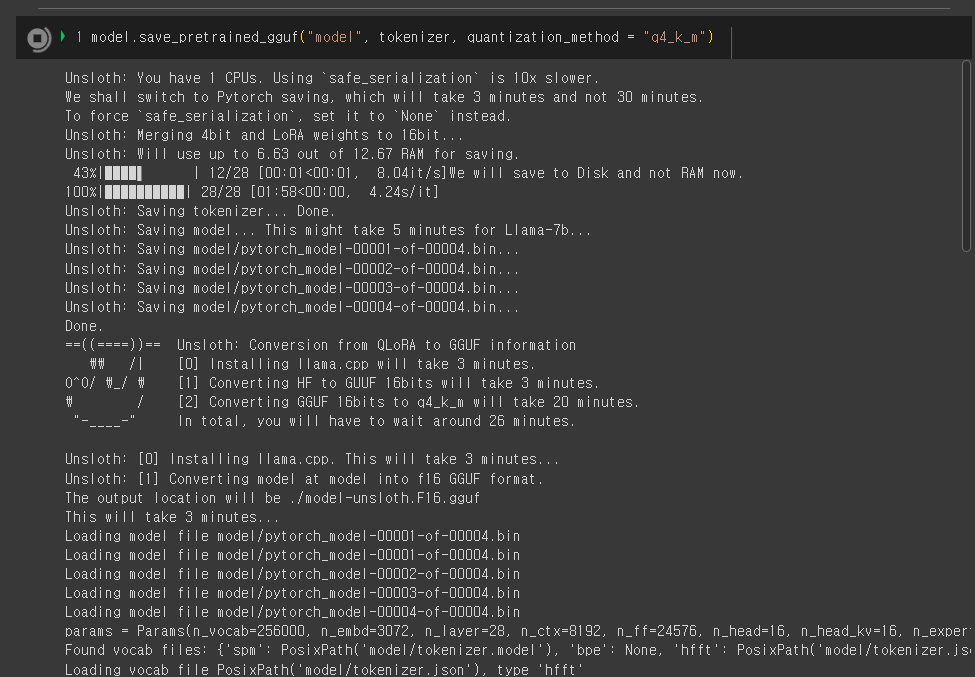
모델을 저장하는 과정이 완료되면 구글 코랩의 화면 좌측 파일 메뉴를 클릭한 후, llama.cpp 디렉토리에 "model-unsloth-Q4_K_M.gguf" 파일이 생성되고, 이 파일을 내 컴퓨터로 다운로드하여 "LM Studio"나 "GPT4 All"과 같은 LLM 도구를 이용하여 로컬에서 대형 언어 모델을 사용하실 수 있습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
마치며
오늘은 Unsloth라는 대형 언어 모델 훈련 도구에 대해 알아보았습니다. Unsloth는 효율적인 메모리 사용과 빠른 훈련 속도를 제공하여 대규모 언어 모델을 효과적으로 학습할 수 있는 도구입니다. 기존에 비해 약 30배의 훈련 속도 향상을 제공하여 훈련 시간을 단축하고 빠른 실험을 가능하게 하며, 최적화된 메모리 관리 기술을 사용하여 훈련 중 사용되는 메모리 양을 줄여 더 큰 배치 크기나 더 복잡한 모델을 훈련할 수 있습니다.
이 블로그를 통해 Unsloth의 주요 기술 및 동작 원리, 종속성 설치 방법, 코랩을 활용한 훈련 방법 등에 대해 알아보고, 또한 실제 예제를 통해 Unsloth를 사용하여 Gemma 7B 모델을 훈련하고, 피보나치수열을 생성하는 과정을 살펴보았으며, 마지막으로, 학습이 완료된 모델을 저장하고 내 컴퓨터에 다운로드하는 과정을 소개하였습니다.
오늘 내용은 여기까지입니다. 여러분도 내 컴퓨터나 구글 코랩에서 Unsloth를 사용하여 대규모 언어 모델을 학습시켜서 나만의 언어 모델을 만들어 보시면 어떨까요? 저는 그럼 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.02.29 - [AI 도구] - Groq LPU : 논문 한편 요약하는데 입력-추론-응답까지 2.4초!
Groq LPU : 논문 한편 요약하는데 입력-추론-응답까지 2.4초!
안녕하세요! 오늘은 Groq이라는 회사의 대형 언어 모델 추론성능 가속장치, LPU(Language Processing Unit)에 대해서 알아보겠습니다. Groq은 2016년에 과거 구글 직원이었던 조나단 로스에 의해 설립된 AI
fornewchallenge.tistory.com
'AI 도구' 카테고리의 다른 글
| MusicLang: 대형 언어 모델로 누구나 쉽게 MIDI 음악 작곡하기 (0) | 2024.03.13 |
|---|---|
| [꿀팁] 비행기 모드 AI 채팅! MLCChat으로 스마트폰 데이터 연결 없이 AI 즐기기 (0) | 2024.03.10 |
| Groq LPU : 논문 한편 요약하는데 입력-추론-응답까지 2.4초! (4) | 2024.02.29 |
| 🤯 파이데이터(Phidata) : 5줄 코드로 토큰 과금없는 AI 어시스턴트 만들기 (2) | 2024.02.27 |
| 🏆텍스트 임베딩의 혁신! 오픈AI 뛰어넘은 노믹 임베드의 모든것! (2) | 2024.02.25 |



