안녕하세요! 오늘은 Moreh에서 개발한 한국어 대규모 언어 모델 Motif에 대해 소개해 드리겠습니다. Motif는 Llama 3 70B 사전 훈련 모델을 기반으로, Masked Structure Growth(MSG)와 같은 독창적인 훈련 기법을 통해 모델의 확장성을 높이면서 오픈 소스로 공개되었으며, KMMLU 벤치마크에서 GPT-4를 능가하는 64.74점을 기록하였습니다. 이 블로그에서는 Motif의 특징과 주요 기능, 활용 방법에 대해 알아보고, 성능을 테스트해 보겠습니다.

https://www.aitimes.com/news/articleView.html?idxno=165878
모레, '최강 한국어 성능' 갖춘 102B 오픈 소스 모델 공개..."GPT-4o·큐원2 모두 능가" - AI타임스
인공지능(AI) 인프라 솔루션 전문 모레(MOREH, 대표 조강원)는 자체 개발 한국어 파운데이션 대형언어모델(LLM) ‘라마3-모티프-102B(Llama-3-Motif-102B)\'를 허깅페이스에 오픈 소스로 공개한다고 3일 밝
www.aitimes.com
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Motif 개요
Motif는 Moreh에서 개발한 한국어 대규모 언어 모델(LLM)입니다. Motif는 Llama 3 70B 사전 훈련 모델을 기반으로 하며, LlamaPro와 같은 정교한 훈련 방법론을 사용하여 모델의 깊이를 심화하는 Masked Structure Growth (MSG)를 통해 사전 훈련된 가중치의 무결성을 유지하면서 모델을 효과적으로 확장했습니다.
Motif의 주요 특징은 다음과 같습니다.
- 뛰어난 한국어 성능: Motif는 기존 최상위 LLM의 한국어 성능을 능가하며, 한국어 AI 성능을 평가하는 KMMLU 벤치마크에서 64.74점을 기록했습니다. 이는 OpenAI의 GPT-4를 포함한 Meta, Google 등 글로벌 기술 대기업의 LLM보다 우수한 성능입니다.
- 오픈 소스: Motif는 오픈 소스 모델로 공개되어 개발자, 연구자, 기업들이 자유롭게 활용할 수 있습니다.
- MoAI 플랫폼 활용: Motif 개발에는 대규모 모델 훈련에 최적화된 최첨단 AI 인프라인 MoAI 플랫폼이 활용되었습니다. 이 플랫폼은 클러스터에서 수천 개의 GPU를 효율적으로 관리하며 자동 병렬화, GPU 가상화, 동적 GPU 할당과 같은 기능을 제공합니다.
- 다양한 작업 수행 가능: Motif는 텍스트 생성, 번역, 요약, 질의응답 등 다양한 자연어 처리 작업을 수행할 수 있습니다.
https://moreh.io/blog/introducing-motif-a-high-performance-open-source-korean-llm-by-moreh-241202
Introducing Motif: A High-Performance Open-Source Korean LLM by Moreh
Moreh announces the release of Motif, a high-performance 102B Korean language model (LLM), which will be made available as an open-source model.
moreh.io
Motif 벤치마크 결과
Motif는 공무원 시험(PSAT), 전문 자격증 시험, 대학수학능력시험(CSAT) 등 다양한 한국 표준 시험에서 출제된 45개 과목 35,030개 문항을 포함하는 KMMLU(Korean Massive Multitask Language Understanding ) 벤치마크 평가에서 64.74점을 기록하며 OpenAI의 GPT-4를 능가하는 한국어 성능을 보였습니다.

위 벤치마크 결과에 따르면, Moreh의 두 모델 Llama-3-Motif-102B와 Llama-3-Motif-102B-Instruct가 KMMLU 벤치마크 테스트에서 각각 64.74와 64.81의 점수를 기록하며 가장 높은 성능을 보였습니다. 이 점수는 Moreh 모델이 OpenAI의 최신 GPT-4 모델(64.11)과 Alibaba의 Qwen2-72B-Instruct(64.1)를 한국어 성능면에서 능가했음을 보여줍니다.
Llama-3-Motif-102B-Instruct는 Moreh의 모델 중 가장 뛰어난 성능을 기록했으며, Meta, Google, LG, Naver, Upstage와 같은 주요 AI 모델 제공업체들의 모델이 대체로 60% 이하의 점수를 기록한 것과 비교해 두드러진 우위를 보였습니다. 이는 Moreh의 모델이 특히 한국어에 특화된 언어 모델로서 강력한 경쟁력을 지니고 있음을 보여줍니다.
Motif 이용 방법
Motif는 Hugging Face에서 모델을 다운로드할 수 있으며, GitHub에서 스크립트를 다운로드하여 사용할 수 있습니다. 또한, AI 모델 허브에서 Motif를 활용한 챗봇 서비스를 무료로 이용할 수 있습니다. 모델의 크기가 102B인 점을 감안하면 AI 모델 허브에 접속해서 체험해 보시면 좋을 것 같습니다.
- Hugging Face : https://huggingface.co/moreh/Llama-3-Motif-102B-Instruct
- GitHub: https://github.com/moreh-io/motif-llm
- AI 모델 허브 챗봇 서비스: https://model-hub.moreh.io/
https://huggingface.co/moreh/Llama-3-Motif-102B-Instruct
moreh/Llama-3-Motif-102B-Instruct · Hugging Face
Introduction We introduce Llama-3-Motif, a new language model family of Moreh, specialized in Korean and English. Llama-3-Motif-102B-Instruct is a chat model tuned from the base model Llama-3-Motif-102B. Training Platform Llama-3-Motif-102B model family is
huggingface.co
AI Model hub
Experience various LLMs and multimodal models trained on AMD GPU clusters and the MoAI Platform.
model-hub.moreh.io

Motif 성능 테스트
다음은 Motif로 코딩, 수학, 추론 성능을 테스트해 보겠습니다. 코딩 성능은 코딩 교육 사이트 edabit.com의 Python, JavaScript, C++ 문제를 통해 테스트하고, 수학 문제는 기하학, 확률, 수열, 최적화, 복합 문제 등으로 구성된 6개의 문제를 사용했습니다. 모든 평가 항목은 재시도 없이 첫 번째 시도의 채점 결과를 그대로 반영하였습니다.
1. 코딩성능 테스트: Python, JavaScript, C++ 언어별 Medium, Hard, Very Hard, Expert 난이도 문제로 테스트하였습니다.
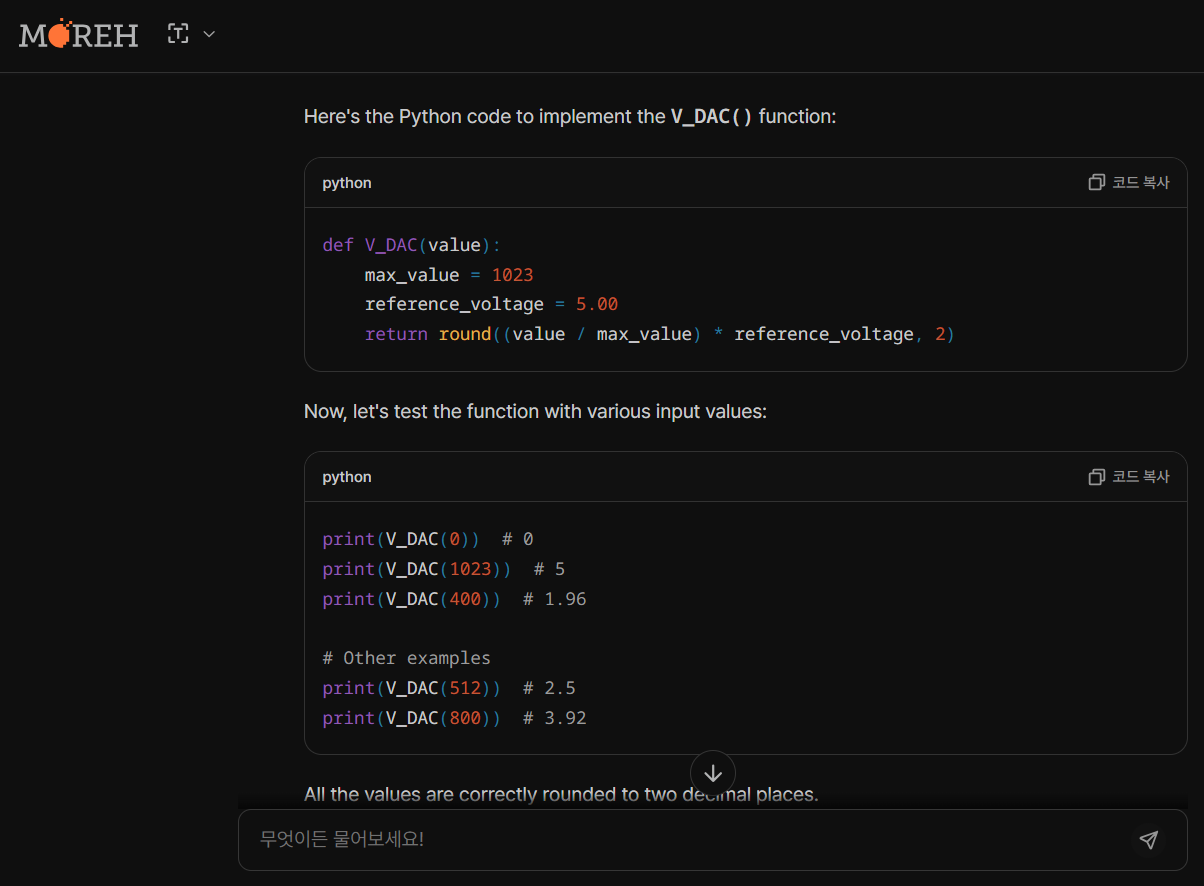
| Motif | Medium | Hard | Very Hard | Expert |
| Python | Pass | Fail | Fail | Fail |
| JavaScript | Pass | Pass | Fail | Fail |
| C++ | Fail | Pass | Fail | Fail |
코딩 테스트 결과, Motif는 Python, JavaScript, C++의 총 12문제 중 4문제 밖에 성공하지 못하였으며, 코딩 성능은 개선이 필요해 보입니다.
2. 수학 성능 테스트: 기초 대수, 기하학, 확률, 수열, 최적화, 복합 문제 총 6문제로 테스트하였으며, Qwen2-72B-Instruct와 비교하였습니다.
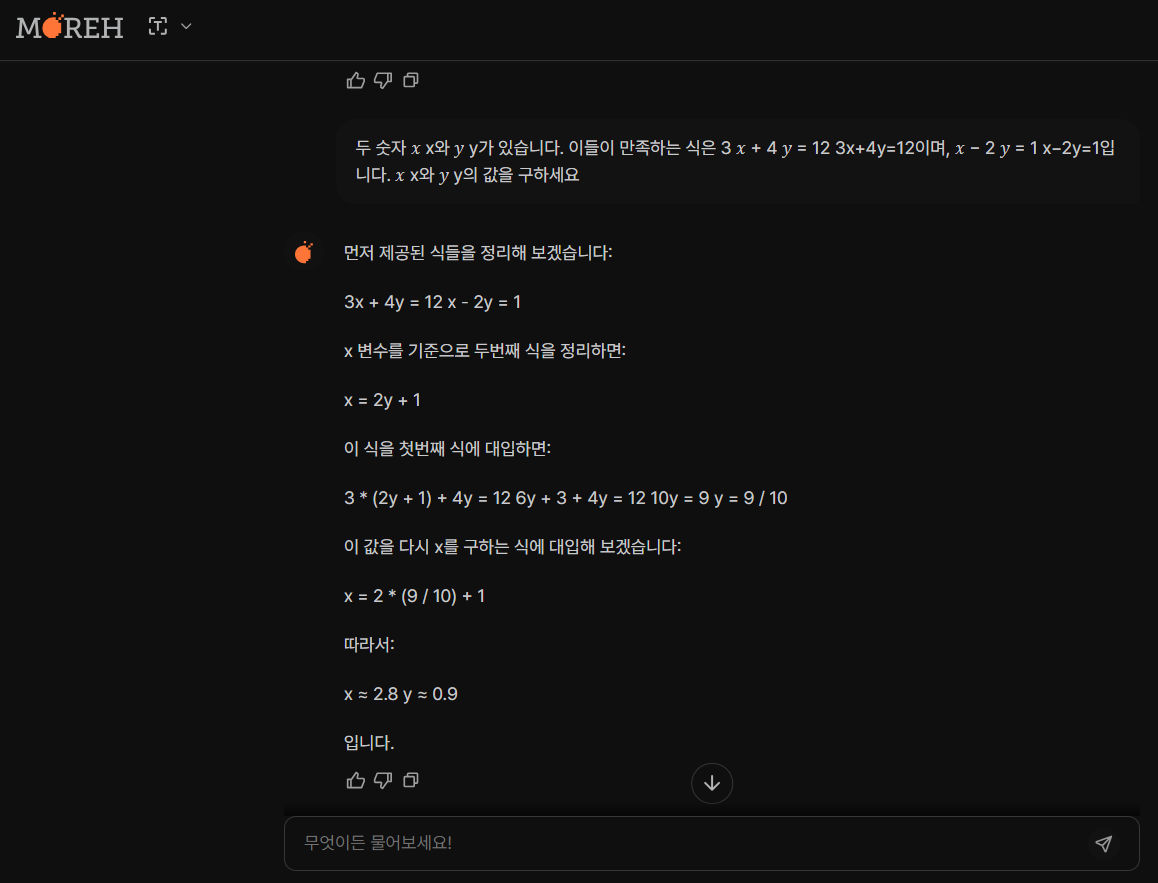

| No. | 문제 구분 | 문제 | Motif | Qwen2 -72B |
| 1 | 기초 대수 문제 | 두 숫자 𝑥 x와 𝑦 y가 있습니다. 이들이 만족하는 식은 3 𝑥 + 4 𝑦 = 12 3x+4y=12이며, 𝑥 − 2 𝑦 = 1 x−2y=1입니다. 𝑥 x와 𝑦 y의 값을 구하세요 | Pass | Pass |
| 2 | 기하학 문제 | 반지름이 7cm인 원의 넓이를 구하세요. 𝜋 = 3.14159 π=3.14159로 계산하세요. | Pass | Pass |
| 3 | 확률 문제 | 주사위를 두 번 던졌을 때, 두 숫자의 합이 7이 될 확률을 구하세요. | Pass | Pass |
| 4 | 수열 문제 | 첫 번째 항이 3이고, 공차가 5인 등차수열의 10번째 항을 구하세요. | Pass | Pass |
| 5 | 최적화 문제 | 어떤 직사각형의 둘레가 36cm입니다. 이 직사각형의 넓이를 최대화하려면 가로와 세로의 길이는 각각 얼마여야 하나요? | Pass | Pass |
| 6 | 복합 문제 | 복소평면에서 다음 극한값을 구하시오. lim[n→∞] (1 + i/n)^(n^2) 여기서 i는 허수단위 (i^2 = -1)입니다. | Pass | Fail |
수학 성능 테스트 결과, Motif는 모든 문제를 맞혔으며, Qwen2-72B보다 복합 문제에서 나은 성능을 보였습니다.
3. 추론 성능 테스트
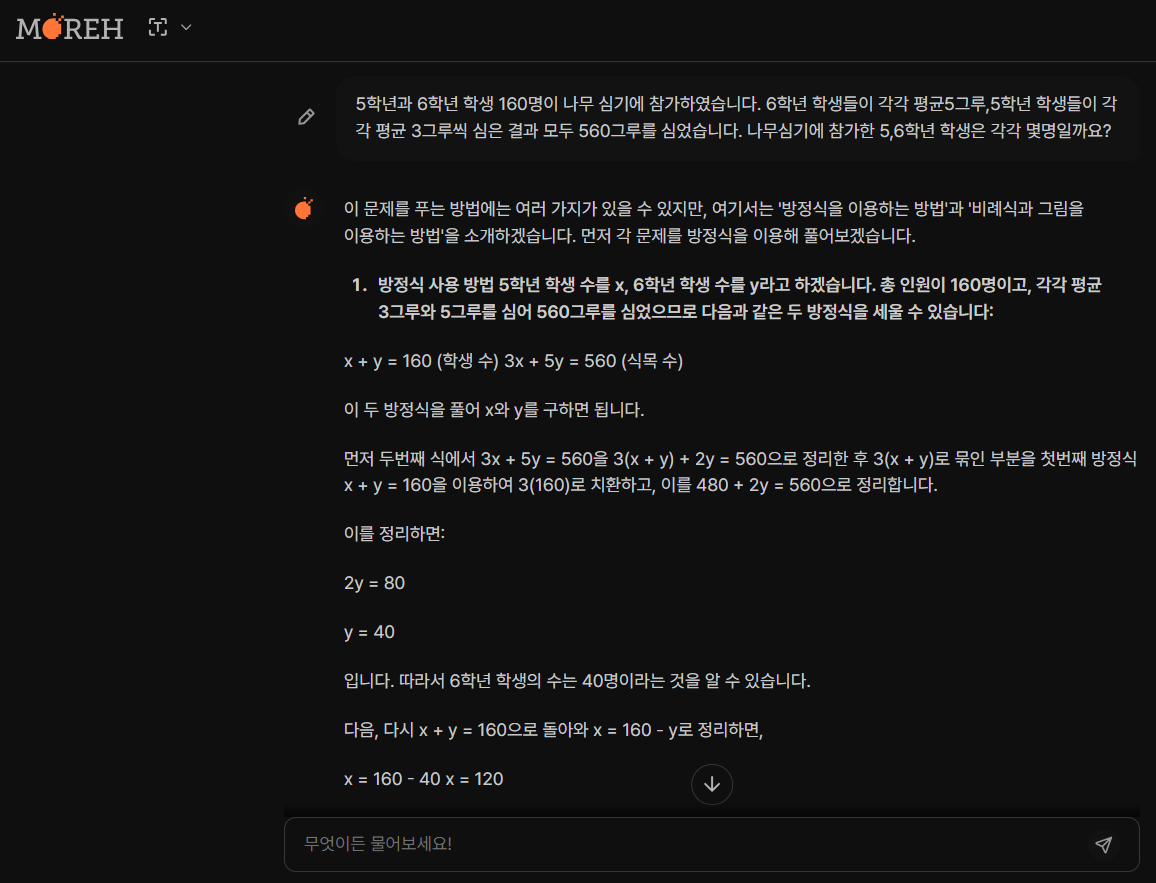
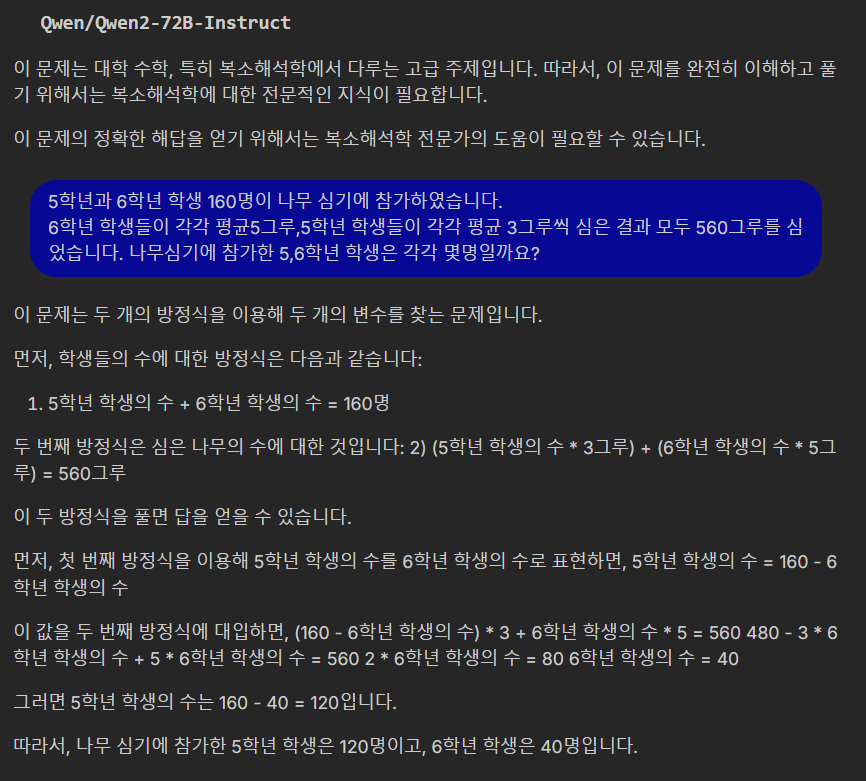
| No. | 문제 | Motif | Qwen2 -72B |
| 1 | 5학년과 6학년 학생 160명이 나무 심기에 참가하였습니다. 6학년 학생들이 각각 평균5그루,5학년 학생들이 각각 평균 3그루씩 심은 결과 모두 560그루를 심었습니다. 나무심기에 참가한 5,6학년 학생은 각각 몇명일까요? |
Pass | Pass |
| 2 | 베티는 새 지갑을 위해 돈을 모으고 있습니다. 새 지갑의 가격은 $100입니다. 베티는 필요한 돈의 절반만 가지고 있습니다. 그녀의 부모는 그 목적을 위해 $15를 주기로 결정했고, 할아버지와 할머니는 그녀의 부모들의 두 배를 줍니다. 베티가 지갑을 사기 위해 더 얼마나 많은 돈이 필요한가요? | Pass | Pass |
| 3 | 전국 초등학생 수학경시대회가 열렸는데 영희,철수,진호 세사람이 참가했습니다. 그들은 서울,부산,인천에서 온 학생이고 각각 1등,2등,3등 상을 받았습니다. 다음과 같은 사항을 알고 있을때 진호는 어디에서 온 학생이고 몇등을 했습니까? 1) 영희는 서울의 선수가 아닙니다. 2) 철수는 부산의 선수가 아닙니다. 3)서울의 선수는 1등이 아닙니다. 4) 부산의 선수는 2등을 했습니다. 5)철수는 3등이 아닙니다. | Fail | Fail |
| 4 | 방 안에는 살인자가 세 명 있습니다. 어떤 사람이 방에 들어와 그중 한 명을 죽입니다. 아무도 방을 나가지 않습니다. 방에 남아 있는 살인자는 몇 명입니까? 단계별로 추론 과정을 설명하세요. | Pass | Fail |
| 5 | A marble is put in a glass. The glass is then turned upside down and put on a table. Then the glass is picked up and put in a microwave. Where's the marble? Explain your reasoning step by step. | Fail | Fail |
| 6 | 도로에 5대의 큰 버스가 차례로 세워져 있는데 각 차의 뒤에 모두 차의 목적지가 적혀져 있습니다. 기사들은 이 5대 차 중 2대는 A시로 가고, 나머지 3대는 B시로 간다는 사실을 알고 있지만 앞의 차의 목적지만 볼 수 있습니다. 안내원은 이 몇 분의 기사들이 모두 총명할 것으로 생각하고 그들의 차가 어느 도시로 가야 하는지 목적지를 알려 주지 않고 그들에게 맞혀 보라고 하였습니다. 먼저 세번째 기사에게 자신의 목적지를 맞혀 보라고 하였더니 그는 앞의 두 차에 붙여 놓은 표시를 보고 말하기를 "모르겠습니다." 라고 말하였습니다. 이것을 들은 두번째 기사도 곰곰히 생각해 보더니 "모르겠습니다." 라고 말하였습니다. 두명의 기사의 이야기를 들은 첫번째 기사는 곰곰히 생각하더니 자신의 목적지를 정확하게 말하였습니다. 첫번째 기사가 말한 목적지는 어디입니까? | Fail | Pass |
추론 테스트 결과, Motif는 6문제 중 3문제를 맞히면서, 최근 발표된 Athene-V2나 Qwen2.5보다는 낮은 성능을 보였지만, Qwen2-72B와 비슷한 추론 성능을 보였습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
맺음말
Motif는 한국어에 특화된 고성능 언어 모델로, 기존의 LLM들과 비교했을 때 뛰어난 성능을 보였으며, 특히 한국어 성능에서 두각을 나타냈습니다. KMMLU 벤치마크에서 GPT-4를 능가하는 성과를 달성한 것은 Motif가 한국어 처리에서 우수한 능력을 발휘한다는 것을 보여줍니다. 또한, 오픈 소스로 제공되어 다양한 연구자와 개발자가 손쉽게 활용할 수 있다는 점에서 큰 장점이 있습니다. 하지만, 기초적인 수학이 아닌, 복잡한 코딩이나 추론 문제에서는 개선이 필요한 것으로 보입니다.
오늘 블로그 내용은 여기까지입니다. 앞으로 Motif가 한국어 기반의 AI 애플리케이션 개발에 중요한 역할을 하면서 발전해 나가길 기대하면서 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.04.13 - [AI 언어 모델] - [AI 논문] 올해의 한국어 LLM에 선정된 야놀자 언어 모델, EEVE
[AI 논문] 올해의 한국어 LLM에 선정된 야놀자 언어 모델, EEVE
안녕하세요! 오늘은 최근 "올해의 한국어 LLM"으로 선정된 야놀자의 대형 언어 모델, EEVE에 대해 살펴보겠습니다. EEVE모델은 Efficient and Effective Vocabulary Expansion의 약자로, 효율적이고 효과적인 어
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 🦙Llama 3.3: Claude 3.5 Sonnet 따라잡은 메타의 최신 AI 언어 모델 (116) | 2024.12.08 |
|---|---|
| 👁️PaliGemma 2: 구글의 최신 오픈소스 비전-언어 모델(VLM) (98) | 2024.12.08 |
| 🚀Athene-V2 : GPT-4o를 넘어선 최신 오픈소스 모델 ! (+무료 API) (12) | 2024.11.30 |
| 🤖💪Qwen2.5 Coder 32B: 오픈소스로 GPT-4o급 성능에 아티팩트까지! (50) | 2024.11.14 |
| 💡Ollama 로컬 멀티모달 AI: Llama 3.2 Vision 설치 및 활용 가이드 (14) | 2024.11.10 |



