안녕하세요! 오늘은 Nexusflow에서 개발한 최신 AI 모델 Athene-V2에 대해 알아보겠습니다. Athene-V2는 720억 개의 매개변수를 가진 대규모 언어 모델(LLM)로, Qwen 2.5 72B를 기반으로 미세 조정된 모델입니다. 특히, GPT-4o와 경쟁할 수 있는 수준의 성능을 보여주는 Athene-V2는 챗봇, 코드 완성, 수학 문제 해결 등 다양한 분야에서 탁월한 결과를 제공합니다. Athene-V2는 Chat 모델과 Agent 모델로 구성되어 있으며, 각각 특정 기능에 맞게 최적화되었습니다. 이 블로그에서는 Athene-V2의 주요 특징, 벤치마크 결과, 그리고 코딩, 수학, 추론 성능 테스트 결과를 자세히 살펴보고, 모델의 실제 활용 가능성을 탐구해 보겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
Athene-V2 개요
Nexusflow에서 개발한 Athene-V2는 720억 개의 매개변수를 가진 대규모 언어 모델(LLM) 제품군으로, Qwen 2.5 72B를 기반으로 미세 조정되었습니다. Athene-V2는 특별히 설계된 데이터 및 강화 학습을 통해 GPT-4o와 경쟁할 수 있는 성능을 보여줍니다.
Athene-V2는 특정 기능 향상을 위해 맞춤화된 전문 모델로 구성되어 있습니다. 주요 모델은 다음과 같습니다.
- Athene-V2-Chat-72B: 뛰어난 챗봇 모델로, 다양한 벤치마크에서 GPT-4o와 동등한 성능을 자랑합니다. 특히 챗봇 도움말(Arena-Hard), 코드 완성(bigcode-bench-hard 2위), 수학(MATH) 분야에서 GPT-4o를 능가하며, 긴 로그 추출에서도 더 높은 정확도를 보여줍니다.
- Athene-V2-Agent-72B: 챗봇과 에이전트 기능의 균형을 이루는 모델로, 간결하고 지시적인 챗봇 응답을 제공합니다. 복잡한 기업 수준의 기능 호출 사용 사례에 중점을 둔 최신 Nexus-V2 기능 호출 벤치마크에서 GPT-4o를 능가합니다.
https://nexusflow.ai/blogs/athene-v2
Nexusflow.ai | Blog :: Introducing Athene-V2: Advancing Beyond the Limits of Scaling with Targeted Post-training
We’re thrilled to announce Athene-V2, our latest 72B model suite. Fine-tuned from Qwen 2.5 72B, Athene-V2 competes with GPT-4o across key capabilities, powered by a meticulously designed data and RLHF pipeline. As the industry recognizes the slow-down o
nexusflow.ai
Athene-V2 주요 특징
Athene-V2 모델 시리즈는 Qwen 2.5 72B를 기반으로 미세 조정된 72B 모델이며, 특화된 데이터 및 RLHF 파이프라인을 활용하여 GPT-4o에 필적하는 성능을 자랑합니다. Athene-V2는 크게 두 가지 모델, Athene-V2-Chat-72B와 Athene-V2-Agent-72B로 구성되며, 각 모델은 특정 기능에 최적화되어 차별화된 강점을 지니고 있습니다.
1. 최첨단 챗봇 모델
Athene-V2-Chat-72B는 다양한 벤치마크에서 GPT-4o와 동등한 성능을 보이는 최첨단 챗봇 모델입니다. 특히 챗봇 유용성 측면에서 GPT-4o를 능가하며 (Arena-Hard), 코드 완성 (bigcode-bench-hard 2위), 수학 (MATH) 분야에서 뛰어난 성능을 발휘합니다. 또한, 긴 로그 추출을 높은 정밀도로 처리하는 능력을 갖추고 있습니다 (Nexusflow 내부 벤치마크).
2. 챗봇과 에이전트 기능의 조화
Athene-V2-Agent-72B는 챗봇과 에이전트 기능 사이의 균형을 맞춘 모델로, 간결하고 지시적인 챗봇 응답을 제공합니다. 특히, 어려운 엔터프라이즈급 함수 호출 사용 사례에 중점을 둔 최신 Nexus-V2 함수 호출 벤치마크에서 GPT-4o를 능가하는 성능을 보입니다.
3. LLM 사후 훈련의 파레토 프론티어: 특화된 기능 강화
두 모델은 LLM 사후 훈련에서 나타나는 파레토 프론티어 현상을 잘 보여줍니다. 파레토 프론티어란 여러 성능 지표 간의 균형이 최적화된 지점을 의미하며, 이 지점을 넘어서면 특정 기능을 향상시키기 위해 다른 측면을 포기하는 전략적 선택이 필요합니다. Athene-V2-Agent 모델은 에이전트 지향 기능을 강조하면서 일반적인 챗봇 유연성을 일부 포기하는 반면, Athene-V2-Chat 모델은 뛰어난 대화 능력을 보유하지만 에이전트 관련 작업에서는 제한적인 모습을 보입니다.

Athene-V2 모델 시리즈는 챗봇과 에이전트 기능을 특화하여 각 영역에서 뛰어난 성능을 발휘하도록 설계되었습니다. Athene-V2-Chat-72B는 챗봇 기능에 중점을 둔 모델이며, Athene-V2-Agent-72B는 챗봇과 에이전트 기능의 균형을 이루는 모델입니다. 두 모델은 각자의 강점을 가지고 있으며, 특정 작업에 따라 적합한 모델을 선택하는 것이 중요합니다.
Athene-V2 벤치마크 결과
Athene-V2는 다양한 벤치마크에서 GPT-4o와 경쟁하며, 특정 영역에서는 더 나은 성능을 보여줍니다. 벤치마크 결과는 Athene-V2 모델 제품군이 LLM 사후 훈련의 파레토 프론티어를 따라 위치한다는 것을 보여줍니다. 즉, Athene-V2는 여러 성능 지표 간의 균형을 최적화하여 특정 기능을 향상시키도록 설계되었습니다.
Athene-V2는 Agent와 Chat 두 가지 모델로 나뉘어 평가되었습니다. Agent 모델은 72B 파라미터를 가지며, Chat 모델도 마찬가지입니다. 전반적으로 Athene-V2는 다른 모델들과 비교했을 때 준수한 성능을 보여줍니다. 특히 Agent 모델의 경우 Nexus-V2-Agentic 벤치마크에서 69.4%로 가장 높은 성능을 기록했습니다. Chat 모델은 Log-Extraction 벤치마크에서 85.0%로 가장 높은 성능을 보였습니다.
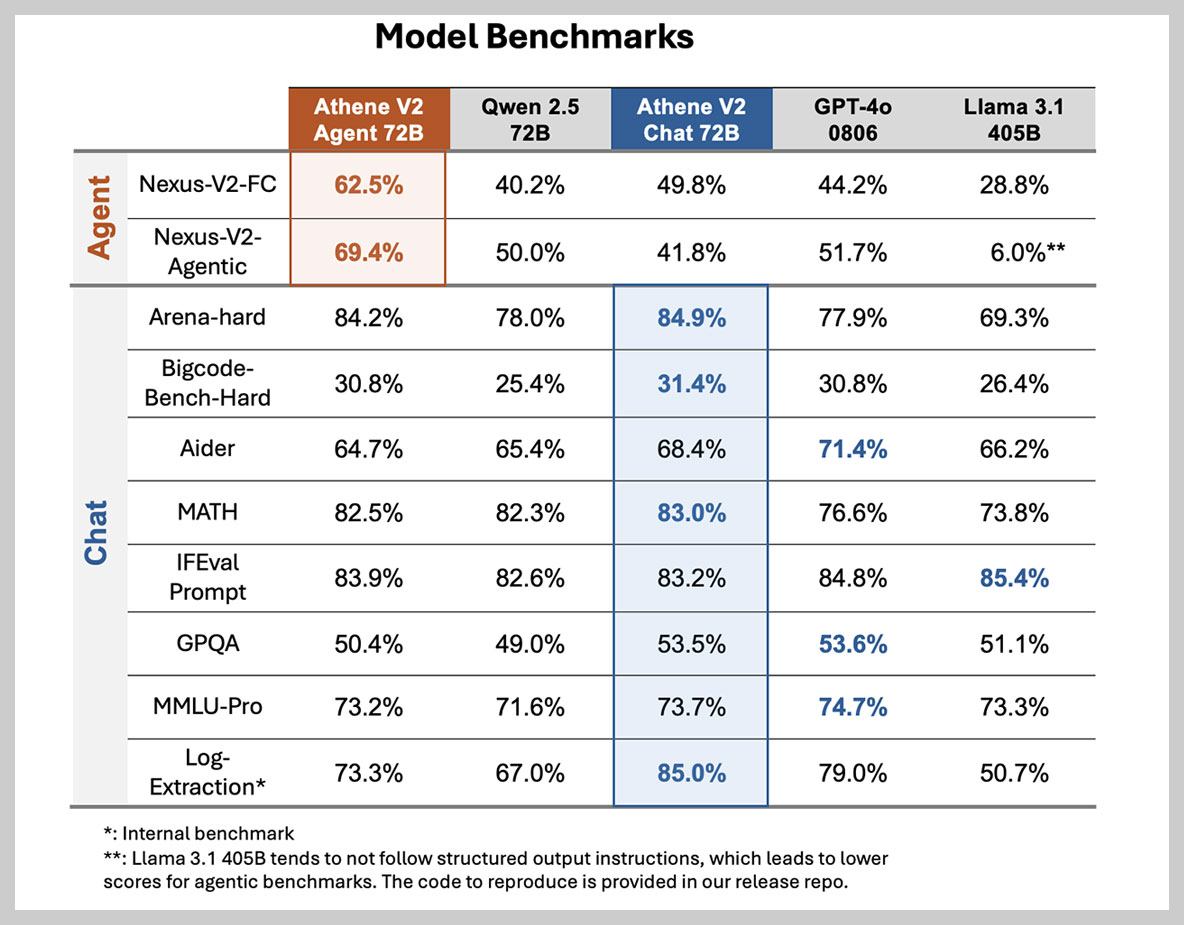
Agent 모델 분석:
- Nexus-V2-FC: 62.5%로 Qwen 2.5과 다른 모델들에 비해서는 가장 높은 성능을 보입니다.
- Nexus-V2-Agentic: 69.4%로 가장 높은 성능을 기록했으며, 다른 모델들과 비교했을 때도 우수한 성능입니다.
Chat 모델 분석:
- Arena-hard(자연어 추론 및 문제해결): 84.2%로 다른 모델들과 비교했을 때 높은 성능을 보입니다.
- Bigcode-Bench-Hard(코드 생성 및 분석): 31.4%로 가장 높은 성능을 보입니다.
- MATH(수학 문제 해결): 83.0%로 GPT-4o보다 매우 높은 성능을 보이며, 다른 모델들과 비교했을 때도 우수합니다.
- GPQA(질문 답변): 53.5%로 다른 모델들과 GPT-4o와 비슷한 수준의 성능을 보입니다.
- Log-Extraction(로그 데이터 분석): 85.0%로 가장 높은 성능을 보이며, 다른 모델들과 비교했을 때도 우수합니다.
Athene-V2는 Agent 모델과 Chat 모델 모두에서 준수한 성능을 보여주는 모델입니다. 특히 Agent 모델의 Nexus-V2-Agentic 벤치마크와 Chat 모델의 Log-Extraction 벤치마크에서 뛰어난 성능을 보였습니다.
https://huggingface.co/Nexusflow/Athene-V2-Chat
Nexusflow/Athene-V2-Chat · Hugging Face
Athene-V2-Chat-72B: Rivaling GPT-4o across Benchmarks Nexusflow HF - Nexusflow Discord - Athene-V2 Blogpost We introduce Athene-V2-Chat-72B, an open-weights LLM on-par with GPT-4o across benchmarks. It is currently the best open model according to Chatbot
huggingface.co
Athene-V2 사용방법
현재 Athene-V2 모델은 https://glhf.chat/landing/home에서 무료로 사용하실 수 있습니다. glhf 사이트 가입 및 로그인 후 아래와 같이 채팅창에 허깅페이스 모델 링크를 복사해서 붙여 넣으면 Athene-V2 모델과 대화하실 수 있습니다.

또는 glhf 사이트의 API 설정을 참고하여 https://glhf.chat/users/settings/api 에서 아래와 같이 코드를 참조하여 챗봇을 만들어서 대화하실 수도 있습니다.

다음 코드는 Athene-V2 모델과 대화하는 streamlit 웹 애플리케이션입니다.
import os
import streamlit as st
from openai import OpenAI
# 페이지 설정
st.set_page_config(page_title="Chat with Athene-V2-Chat", layout="wide")
# 스타일 적용
st.markdown("""
<style>
.stTextInput {
position: fixed;
bottom: 3rem;
width: calc(100% - 4rem);
}
.main {
padding-bottom: 5rem;
}
</style>
""", unsafe_allow_html=True)
# API 키 설정
os.environ['GLHF_API_KEY'] = '발급받은 API key'
client = OpenAI(
api_key=os.environ['GLHF_API_KEY'],
base_url="https://glhf.chat/api/openai/v1"
)
# Streamlit 앱 제목
st.title("Chat with Athene-V2-Chat")
# 세션 상태 초기화
if "messages" not in st.session_state:
st.session_state.messages = []
# 채팅 기록 표시
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 사용자 입력 받기
user_input = st.chat_input("메시지를 입력하세요...")
if user_input:
# 사용자 메시지 표시
with st.chat_message("user"):
st.markdown(user_input)
# 메시지 기록에 추가
st.session_state.messages.append({"role": "user", "content": user_input})
# API 호출
try:
# 응답을 위한 빈 메시지 컨테이너 생성
with st.chat_message("assistant"):
message_placeholder = st.empty()
full_response = ""
# 스트리밍 응답 생성
for response in client.chat.completions.create(
model="hf:Nexusflow/Athene-V2-Chat",
messages=[{"role": "user", "content": user_input}],
stream=True
):
# 응답의 다음 토큰 가져오기
content = response.choices[0].delta.content
if content is not None:
full_response += content
# 실시간으로 응답 표시
message_placeholder.markdown(full_response + "▌")
# 최종 응답 표시
message_placeholder.markdown(full_response)
# 메시지 기록에 추가
st.session_state.messages.append({"role": "assistant", "content": full_response})
except Exception as e:
st.error(f"Error: {str(e)}")코드를 "streamlit run app.py" 명령어로 실행하면 아래와 같이 Athene-V2 모델과 대화할 수 있는 웹 페이지가 열립니다.

Athene-V2 성능 테스트
다음은 Athene-V2로 코딩, 수학, 추론 성능을 테스트해 보겠습니다. 코딩 성능은 코딩 교육 사이트 edabit.com의 Python, JavaScript, C++ 문제를 통해 테스트하고, 수학 문제는 기하학, 확률, 수열, 최적화, 복합 문제 등으로 구성된 6개의 문제를 사용했습니다. 모든 평가 항목은 재시도 없이 첫 번째 시도의 채점 결과를 그대로 반영하였습니다.
1. 코딩성능 테스트: Python, JavaScript, C++ 언어별 Medium, Hard, Very Hard, Expert 난이도 문제로 테스트하였습니다.
| Athene-V2 | Medium | Hard | Very Hard | Expert |
| Python | Pass | Pass | Pass | Pass |
| JavaScript | Pass | Pass | Pass | Pass |
| C++ | Pass | Pass | Pass | Fail |


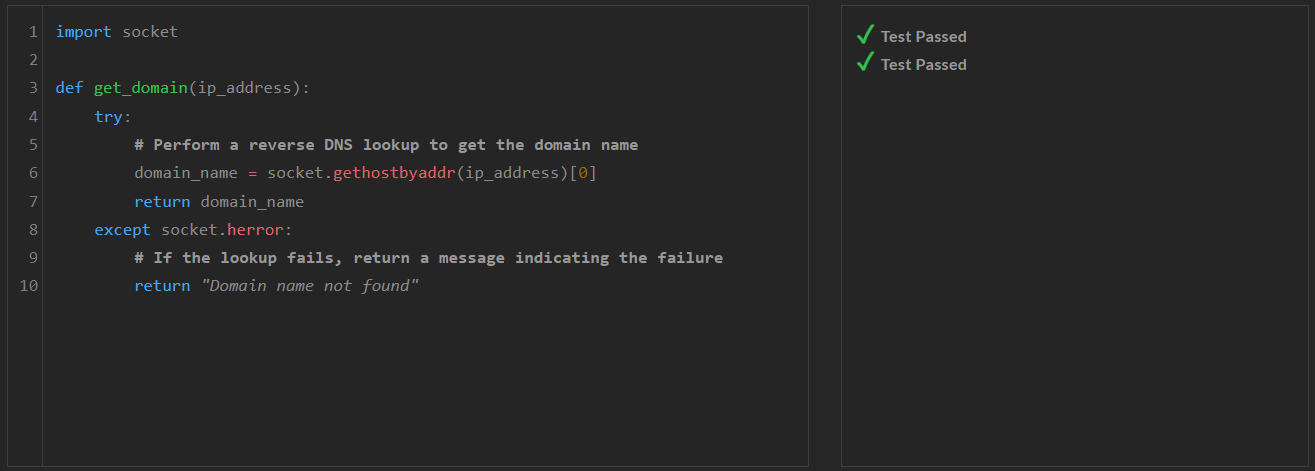











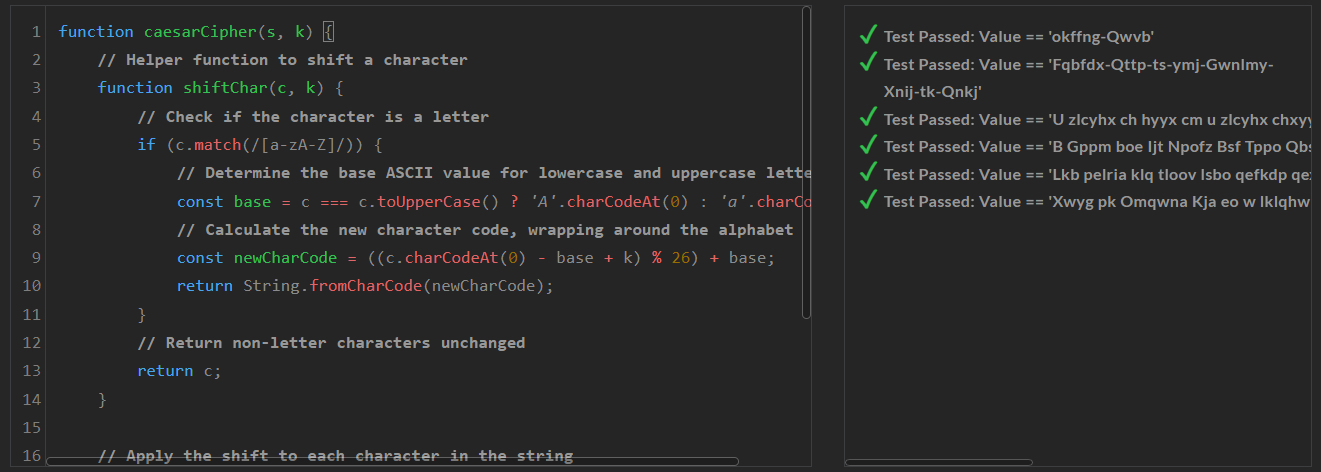







코딩 테스트 결과, Athene-V2는 Python, JavaScript, C++ 중에서 C++의 Expert 난이도를 제외한 모든 문제를 맞히면서, 우수한 코딩 성능을 보여주었습니다.
2. 수학 성능 테스트: 기초 대수, 기하학, 확률, 수열, 최적화, 복합 문제 총 6문제로 테스트하였습니다.
| No. | 문제 구분 | 문제 | Athene-V2 | GPT-4o-mini |
| 1 | 기초 대수 문제 | 두 숫자 𝑥 x와 𝑦 y가 있습니다. 이들이 만족하는 식은 3 𝑥 + 4 𝑦 = 12 3x+4y=12이며, 𝑥 − 2 𝑦 = 1 x−2y=1입니다. 𝑥 x와 𝑦 y의 값을 구하세요 | Pass | Pass |
| 2 | 기하학 문제 | 반지름이 7cm인 원의 넓이를 구하세요. 𝜋 = 3.14159 π=3.14159로 계산하세요. | Pass | Pass |
| 3 | 확률 문제 | 주사위를 두 번 던졌을 때, 두 숫자의 합이 7이 될 확률을 구하세요. | Pass | Pass |
| 4 | 수열 문제 | 첫 번째 항이 3이고, 공차가 5인 등차수열의 10번째 항을 구하세요. | Pass | Pass |
| 5 | 최적화 문제 | 어떤 직사각형의 둘레가 36cm입니다. 이 직사각형의 넓이를 최대화하려면 가로와 세로의 길이는 각각 얼마여야 하나요? | Pass | Pass |
| 6 | 복합 문제 | 복소평면에서 다음 극한값을 구하시오. lim[n→∞] (1 + i/n)^(n^2) 여기서 i는 허수단위 (i^2 = -1)입니다. | Pass | Pass |
수학 성능 테스트 결과, Athene-V2는 모든 문제를 맞혔으며, GPT-4o-mini와 비슷한 성능을 보였습니다.






3. 추론 성능 테스트
| No. | 문제 | Athene-V2 | GPT-4o-mini |
| 1 | 5학년과 6학년 학생 160명이 나무 심기에 참가하였습니다. 6학년 학생들이 각각 평균5그루,5학년 학생들이 각각 평균 3그루씩 심은 결과 모두 560그루를 심었습니다. 나무심기에 참가한 5,6학년 학생은 각각 몇명일까요? |
Pass | Pass |
| 2 | 베티는 새 지갑을 위해 돈을 모으고 있습니다. 새 지갑의 가격은 $100입니다. 베티는 필요한 돈의 절반만 가지고 있습니다. 그녀의 부모는 그 목적을 위해 $15를 주기로 결정했고, 할아버지와 할머니는 그녀의 부모들의 두 배를 줍니다. 베티가 지갑을 사기 위해 더 얼마나 많은 돈이 필요한가요? | Pass | Pass |
| 3 | 전국 초등학생 수학경시대회가 열렸는데 영희,철수,진호 세사람이 참가했습니다. 그들은 서울,부산,인천에서 온 학생이고 각각 1등,2등,3등 상을 받았습니다. 다음과 같은 사항을 알고 있을때 진호는 어디에서 온 학생이고 몇등을 했습니까? 1) 영희는 서울의 선수가 아닙니다. 2) 철수는 부산의 선수가 아닙니다. 3)서울의 선수는 1등이 아닙니다. 4) 부산의 선수는 2등을 했습니다. 5)철수는 3등이 아닙니다. | Pass | Pass |
| 4 | 방 안에는 살인자가 세 명 있습니다. 어떤 사람이 방에 들어와 그중 한 명을 죽입니다. 아무도 방을 나가지 않습니다. 방에 남아 있는 살인자는 몇 명입니까? 단계별로 추론 과정을 설명하세요. | Pass | Pass |
| 5 | A marble is put in a glass. The glass is then turned upside down and put on a table. Then the glass is picked up and put in a microwave. Where's the marble? Explain your reasoning step by step. | Pass | Pass |
| 6 | 도로에 5대의 큰 버스가 차례로 세워져 있는데 각 차의 뒤에 모두 차의 목적지가 적혀져 있습니다. 기사들은 이 5대 차 중 2대는 A시로 가고, 나머지 3대는 B시로 간다는 사실을 알고 있지만 앞의 차의 목적지만 볼 수 있습니다. 안내원은 이 몇 분의 기사들이 모두 총명할 것으로 생각하고 그들의 차가 어느 도시로 가야 하는지 목적지를 알려 주지 않고 그들에게 맞혀 보라고 하였습니다. 먼저 세번째 기사에게 자신의 목적지를 맞혀 보라고 하였더니 그는 앞의 두 차에 붙여 놓은 표시를 보고 말하기를 "모르겠습니다." 라고 말하였습니다. 이것을 들은 두번째 기사도 곰곰히 생각해 보더니 "모르겠습니다." 라고 말하였습니다. 두명의 기사의 이야기를 들은 첫번째 기사는 곰곰히 생각하더니 자신의 목적지를 정확하게 말하였습니다. 첫번째 기사가 말한 목적지는 어디입니까? | Pass | Pass |
추론 테스트 결과, Athene-V2는 6문제 모두를 맞추면서 우수한 추론 성능을 보였습니다. 오픈소스 모델 중 모든 추론 문제를 맞힌 모델은 Athene-V2 모델이 처음입니다.






"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
맺음말
오늘 소개한 Athene-V2는 LLM(대규모 언어 모델)의 새로운 잠재력을 보여주는 강력한 도구입니다. Qwen 2.5 72B를 기반으로 미세 조정된 Athene-V2는 챗봇과 에이전트 작업에서 탁월한 성능을 발휘하며, 특히 복잡한 기업용 기능 호출이나 수학 문제 해결 등 전문 영역에서 GPT-4o와 경쟁할 만한 결과를 보여줍니다. Athene-V2의 주요 모델인 Athene-V2-Chat-72B와 Athene-V2-Agent-72B는 각각 대화 중심과 기능 호출 중심으로 설계되어 사용자의 목적에 맞게 선택할 수 있습니다. 또한, 다양한 벤치마크 결과를 통해 Athene-V2가 높은 정확도와 강력한 성능을 제공한다는 점이 증명되었습니다.
Athene-V2를 직접 사용해 본 소감은 다음과 같습니다.
- 이 블로그의 모든 추론 문제를 맞힌 첫 번째 오픈소스 모델이다.
- Claude 3.5 Sonnet이나 GPT-4o의 코딩성능과 비슷하다.
- glhf의 웹 채팅과 API는 가끔 응답이 느리거나 끊긴다.
오늘은 Nexusflow의 Athene-V2에 대해 알아보았는데요, 직접 사용해 보면서 그 가능성을 체감해 보시는 것도 추천드립니다. 다양한 기능과 실용성 덕분에 AI 기술의 진보를 느낄 수 있는 좋은 기회가 될 것입니다. 그럼 다음 시간에도 더 흥미롭고 유익한 내용을 가지고 다시 찾아뵙겠습니다. 감사합니다!

2024.11.14 - [AI 언어 모델] - 🤖💪Qwen2.5 Coder 32B: 오픈소스로 GPT-4o급 성능에 아티팩트까지!
🤖💪Qwen2.5 Coder 32B: 오픈소스로 GPT-4o급 성능에 아티팩트까지!
안녕하세요! 오늘은 알리바바의 최신 코딩 모델 Qwen2.5-Coder-32B에 대해 알아보겠습니다. Qwen2.5-Coder는 92개 프로그래밍 언어를 지원하며, Cursor 및 Artifacts와 통합되어 사용자 친화적인 개발 환경을
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 👁️PaliGemma 2: 구글의 최신 오픈소스 비전-언어 모델(VLM) (98) | 2024.12.08 |
|---|---|
| 🚀Motif: KMMLU에서 GPT-4o를 뛰어넘은 한국어 오픈소스 LLM (120) | 2024.12.05 |
| 🤖💪Qwen2.5 Coder 32B: 오픈소스로 GPT-4o급 성능에 아티팩트까지! (50) | 2024.11.14 |
| 💡Ollama 로컬 멀티모달 AI: Llama 3.2 Vision 설치 및 활용 가이드 (14) | 2024.11.10 |
| ✨Claude 3.5 Haiku: Anthropic 최고 가성비 AI 모델 분석 및 테스트 (19) | 2024.11.07 |



