안녕하세요! 오늘은 최초의 오픈소스 비디오 생성 AI, CogVideoX에 대해 알아보겠습니다. CogVideoX는 텍스트 프롬프트를 기반으로 최대 6초 길이, 720×480 해상도의 고품질 비디오를 생성하는 AI 모델로, 3D VAE 구조를 사용하여 비디오 데이터를 효율적으로 압축하고, 전문가 트랜스포머로 각 모달리티의 특징을 효과적으로 결합하며, 3D Full Attention을 통해 공간적 및 시간적 차원을 모두 고려해서 전체적인 맥락에 맞는 비디오를 생성합니다. 이 블로그에서는 CogVideoX의 개요, 특징 및 아키텍처, 설치방법에 대해 살펴보고 직접 비디오 생성 테스트를 해 보겠습니다.

https://www.aitimes.com/news/articleView.html?idxno=162895
지푸 AI, 동영상 생성 도구 오픈 소스로 공개..."동영상 기술 지각 변동 일어날 것" - AI타임스
동영상 생성 인공지능(AI)가 마침내 오픈 소스로 출시됐다. 일부 기술 회사들의 독점 영역이었던 동영상 생성 AI 기술을 이제부터는 누구나 활용할 수 있게 됐다.벤처비트는 27일(현지시간) 중국
www.aitimes.com
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
CogVideoX 개요
CogVideoX는 디퓨전 모델(Diffusion Model)과 트랜스포머(Transformer) 아키텍처를 결합하여 데이터 생성의 질과 효율성을 크게 향상시킨 텍스트 기반 비디오 생성 모델입니다. 이 모델은 도입부에서 소개한 것과 같이 비디오 데이터를 효율적으로 모델링하기 위해 3D VAE를 활용하며, 텍스트와 비디오 간의 정렬을 개선하기 위한 전문가 트랜스포머(Expert Transformer)와 3D Full Attention을 도입하여 다양한 비디오를 안정적으로 생성할 수 있습니다. 또한, 텍스트-비디오 데이터 처리 파이프라인을 구축하여 비디오 생성 품질과 의미적 일치를 크게 향상시켰습니다.
CogVideoX의 구성요소별 주요 특징은 다음과 같습니다.
1. 3D VAE(Variational Autoencoder)
3D VAE는 비디오의 공간적 및 시간적 정보를 동시에 압축하여 비디오 데이터를 효율적으로 처리합니다. 기존의 2D VAE와 달리, 3D VAE는 비디오의 연속적인 프레임 사이에서 발생할 수 있는 깜박임 현상을 줄여주는 장점이 있으며, 이를 통해 공간적으로는 8배, 시간적으로는 4배로 데이터를 압축하여 비디오 생성의 일관성을 높입니다.
위 설명도에서 3D VAE로 입력된 비디오는 인코더를 통해 잠재 표현으로 압축되고, KL 정규화로 표준 정규 분포에 가깝게 제한됩니다. 디코더는 이 잠재 표현을 사용해 원본과 유사한 비디오 프레임을 생성하며, 3D 및 2D 컨볼루션을 활용해 시공간적 특징을 효율적으로 처리합니다. 3D VAE는 CogVideoX에서 비디오의 효율적인 압축, 표현 학습, 재구성, 인과적 생성을 담당합니다. 3D VAE를 통해 비디오의 시공간적 특징을 효과적으로 활용하여 고품질의 비디오를 생성할 수 있습니다.
2. 전문가 트랜스포머와 3D Full Attention
CogVideoX는 비디오와 텍스트 간의 정렬을 개선하기 위해 전문가 트랜스포머(Expert Transformer)를 도입했습니다. 이 트랜스포머는 비디오와 텍스트 데이터를 독립적으로 처리하여 각 모달리티의 특징을 효과적으로 결합할 수 있습니다. 또한, 3D Full Attention 메커니즘을 사용하여 공간적 및 시간적 차원에서 비디오 데이터를 종합적으로 모델링함으로써 큰 동작을 포함하는 비디오를 일관되게 생성할 수 있습니다.
위 아키텍처의 구성요소에 대한 설명은 다음과 같습니다.
- 텍스트 인코더: 입력된 텍스트를 임베딩하여 텍스트의 의미를 표현하는 벡터로 변환합니다.
- 3D VAE: 초기 비디오 프레임을 잠재 공간으로 압축하며, 인과적(미래 정보를 사용하지 않음) 컨볼루션을 사용하여 미래 프레임 정보에 의존하지 않고 비디오를 압축합니다.
- 전문가 트랜스포머: 텍스트 임베딩과 3D VAE에서 나온 잠재 표현을 결합한 후, 3D Full Attention, Scale & Shift, Gate, Feed Forward 등의 여러 계층을 통해 텍스트와 비디오 정보를 효과적으로 융합합니다.
- 디코더: 융합된 정보를 사용하여 입력된 텍스트와 일치하는 비디오 프레임을 생성합니다.
3. CogVideoX 성능평가
CogVideoX는 텍스트 기반 비디오 생성 분야에서 뛰어난 성능을 보여주는 모델입니다. GPT-4 기반 자동 평가와 다양한 측면에서의 비교를 통해 CogVideoX가 고품질의 비디오를 생성하고 텍스트를 정확하게 반영하는 능력이 뛰어남을 확인할 수 있습니다. 특히, 다이나믹 퀄리티, 외관 스타일, 멀티 객체 표현, 인간 행동 묘사 등에서 강점을 보입니다.
- GPT40-MTScore: GPT-4를 이용한 자동 평가 지표로, 생성된 비디오와 텍스트의 일치도를 측정합니다.
- Dynamic Quality: 비디오의 움직임과 변화의 자연스러움을 평가합니다. CogVideoX는 높은 점수를 기록하여 역동적이고 사실적인 비디오를 생성하는 능력이 뛰어남을 나타냅니다.
- Dynamic Degree: 비디오의 움직임과 변화의 정도를 평가합니다.
- Appearance Style: 비디오의 시각적 스타일과 미적 품질을 평가합니다.
- Multiple Objects: 여러 객체가 등장하는 장면을 얼마나 잘 처리하는지 평가합니다.
- Human Action: 인간의 행동을 얼마나 사실적으로 묘사하는지 평가합니다.
- Scene: 장면의 구성 및 배경 표현을 평가합니다.
https://huggingface.co/THUDM/CogVideoX-5b
THUDM/CogVideoX-5b · Hugging Face
CogVideoX-5B 📄 中文阅读 | 🤗 Huggingface Space | 🌐 Github | 📜 arxiv Demo Show Video Gallery with Captions A garden comes to life as a kaleidoscope of butterflies flutters amidst the blossoms, their delicate wings casting shadows on the petal
huggingface.co
CogVideoX 설치방법
CogVideoX 모델은 GPU 성능이 충분한 경우 로컬에 직접 설치하거나, 그렇지 않은 경우에는, Lightning AI와 같은 클라우드 GPU를 활용하여 설치할 수 있고, 아래 허깅페이스 링크를 통해서는 설치과정 없이 간단하게 실행해 보실 수 있습니다.
https://huggingface.co/spaces/THUDM/CogVideoX-5B-Space
CogVideoX-5B - a Hugging Face Space by THUDM
huggingface.co
여기서는 Lightning AI의 클라우드 GPU를 활용한 설치방법을 알아보겠습니다. Lightning AI는 일정기능 무료로 클라우드 GPU를 사용할수 있는 플랫폼으로 설치와 같은 기본적인 내용은 아래 포스팅을 참고하시면 될 것 같습니다.
2024.06.02 - [AI 도구] - ⚡️🆓Lightning AI: 무료 GPU 클라우드 기반 AI 개발 플랫폼 Ollama 가이드
⚡️🆓Lightning AI: 무료 GPU 클라우드 기반 AI 개발 플랫폼 Ollama 가이드
안녕하세요! 오늘은 Lightning AI라는 클라우드 컴퓨팅 기반 AI 개발 플랫폼을 소개해 드리겠습니다. Lightning AI는 머신러닝(ML)과 인공지능(AI) 프로젝트를 빠르고 효율적으로 개발, 프로토타입, 훈련,
fornewchallenge.tistory.com
1. 먼저 Lightning AI를 실행하고 우측 상단 모서리 프로필 아이콘 밑에 Studio environment를 클릭하고, GPU Machine을 선택합니다. GPU Machine은 원활한 비디오 생성을 위해 L40 이상으로 선택합니다.
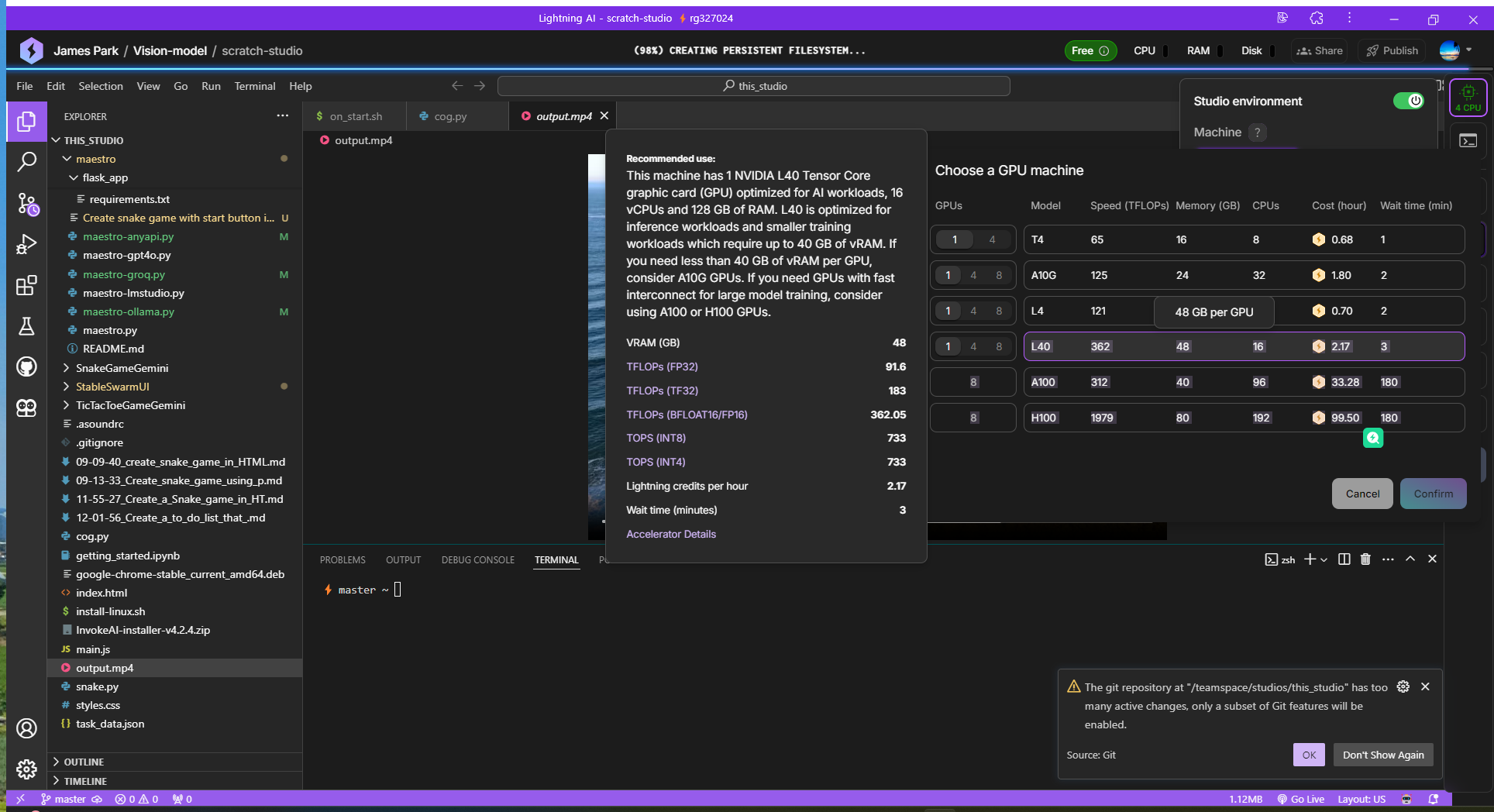
2. 다음은 아래 명령어를 이용해서 필요한 의존성 패키지를 설치합니다.
pip install imageio-ffmpeg
pip install torch torchvision torchaudio -f https://download.pytorch.org/whl/cu121/torch_stable.html
3. 다음은 아래 코드를 복사해서 새 파이썬 파일을 만들고 실행합니다. 이 코드는 텍스트 프롬프트를 입력으로 받아 이를 바탕으로 팬다가 기타를 연주하는 동영상을 생성하고, 이를 output.mp4 파일로 저장합니다. prompt는 사용자가 원하는 비디오 내용으로 수정할 수 있으며, 비디오 생성 소요시간은 Lightning AI L40 모델 기준으로 4~5분 정도 소요됩니다.
import torch
from diffusers import CogVideoXPipeline
from diffusers.utils import export_to_video
prompt = ("A panda, dressed in a small, red jacket and a tiny hat, "
"sits on a wooden stool in a serene bamboo forest. "
"The panda's fluffy paws strum a miniature acoustic guitar, "
"producing soft, melodic tunes. Nearby, a few other pandas gather, "
"watching curiously and some clapping in rhythm. Sunlight filters "
"through the tall bamboo, casting a gentle glow on the scene. "
"The panda's face is expressive, showing concentration and joy as it plays. "
"The background includes a small, flowing stream and vibrant green foliage, "
"enhancing the peaceful and magical atmosphere of this unique musical performance.")
pipe = CogVideoXPipeline.from_pretrained(
"THUDM/CogVideoX-5b",
torch_dtype=torch.bfloat16
)
pipe.enable_model_cpu_offload()
pipe.vae.enable_tiling()
video = pipe(
prompt=prompt,
num_videos_per_prompt=1,
num_inference_steps=50,
num_frames=49,
guidance_scale=6,
generator=torch.Generator(device="cuda").manual_seed(42),
).frames[0]
export_to_video(video, "output.mp4", fps=8)위 코드에서 비디오 생성을 위한 주요 파라미터는 다음과 같습니다.
- prompt: 텍스트 프롬프트.
- num_videos_per_prompt: 프롬프트 당 생성할 비디오의 수.
- num_inference_steps: 모델 추론 단계의 수 (높을수록 품질이 높아짐).
- num_frames: 생성할 프레임의 수.
- guidance_scale: 텍스트 가이드 강도 (높을수록 프롬프트와 더 잘 맞춤).
- generator: 무작위 시드 설정을 위한 생성기.
비디오 생성결과
위 코드를 통해 생성된 비디오는 다음과 같습니다. 생성된 비디오는 720×480 해상도의 화질로 세밀한 디테일까지 잘 표현하였으며, 객체들의 움직임이 자연스럽고 대부분 입력된 텍스트 프롬프트의 내용을 잘 반영하였습니다.
|
|
| A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical atmosphere of this unique musical performance. |
|
|
| Create a video of a stunning beach with waves crashing gently against the shore. The scene should feature clear turquoise waters, soft white sand, and a vibrant sky with a few wispy clouds. Capture the rhythmic motion of the waves, the sparkle of sunlight on the water, and the tranquil beauty of the beach environment. |
|
|
| Drone view of waves crashing against the rugged cliffs along Big Sur’s gray point beach. The crashing blue waters create white-tipped waves, while the golden light of the setting sun illuminates the rocky shore. A small island with a lighthouse sits in the distance, and green shrubbery covers the cliff’s edge. The steep drop from the road down to the beach is a dramatic feat, with the cliff’s edges jutting out over the sea. This is a view that captures the raw beauty of the coast and the rugged landscape of the Pacific Coast Highway. |
|
|
| An elderly gentleman, with a serene expression, sits at the water's edge, a steaming cup of tea by his side. He is engrossed in his artwork, brush in hand, as he renders an oil painting on a canvas that's propped up against a small, weathered table. The sea breeze whispers through his silver hair, gently billowing his loose-fitting white shirt, while the salty air adds an intangible element to his masterpiece in progress. The scene is one of tranquility and inspiration, with the artist's canvas capturing the vibrant hues of the setting sun reflecting off the tranquil sea. |
|
|
| A garden comes to life as a kaleidoscope of butterflies flutters amidst the blossoms, their delicate wings casting shadows on the petals below. In the background, a grand fountain cascades water with a gentle splendor, its rhythmic sound providing a soothing backdrop. Beneath the cool shade of a mature tree, a solitary wooden chair invites solitude and reflection, its smooth surface worn by the touch of countless visitors seeking a moment of tranquility in nature's embrace. |
|
|
| A professional dancer, dressed in a flowing, white costume, performs an intricate ballet routine on a grand stage. The dancer gracefully leaps and spins, their movements precise and elegant, with each step perfectly synchronized to the classical music playing in the background. The stage is illuminated with soft, golden lights, casting dramatic shadows that enhance the dancer's fluid movements. As the routine progresses, the dancer executes a series of challenging pirouettes, grand jetés, and arabesques, showcasing exceptional balance and control. The audience watches in awe, captivated by the dancer's skill and the beauty of the performance. |
|
|
| Two professional boxers face off in a packed arena, surrounded by cheering fans and bright spotlights. The ring is illuminated, casting shadows on the canvas floor as the boxers move with agility and precision. One boxer, wearing red shorts and gloves, advances with a series of rapid jabs, while the other, in blue shorts and gloves, skillfully dodges and counters with powerful hooks. Sweat flies with each punch, and the intensity of the match is palpable. The crowd roars with excitement, and the referee closely monitors the action, ready to step in if needed. The background features the vibrant energy of the audience, with flashes of camera lights capturing the high-stakes bout. The atmosphere is electric, with each boxer showcasing their strength, speed, and strategy in an exhilarating display of athleticism. |
마치며
CogVideoX는 텍스트 프롬프트를 바탕으로 고품질의 비디오를 생성하는 오픈소스 AI 모델로, 다양한 활용 가능성을 열어줍니다. 이 모델은 비디오를 안정적으로 생성하며, 전문가 트랜스포머와 3D Full Attention을 통해 텍스트와 비디오 간의 정렬을 개선하여 일관성 있는 결과를 제공합니다. 또한, 3D VAE 구조를 사용하여 비디오 데이터를 효율적으로 압축하고 처리하여 높은 품질의 비디오 생성이 가능합니다.
이번 포스팅에서는 CogVideoX의 개요와 아키텍처, 설치 방법을 살펴보고, 직접 비디오 생성 테스트를 통해 모델의 성능을 확인해 보았습니다. 생성된 비디오는 선명하고 자연스러운 움직임을 잘 표현하였으며, 텍스트 프롬프트를 잘 반영하였으나, 발레 댄서의 복잡한 동작을 표현하는 부분은 좀 더 개선이 필요한 부분을 확인할 수 있었습니다. 여러분도 직접 다양한 비디오를 생성해 보시면서 CogVideoX를 체험해 보시면 좋을 것 같습니다.
앞으로 CogVideoX와 같은 오픈소스 비디오 생성 AI의 발전이 다양한 창작 활동과 산업에 큰 변화를 가져올 것을 기대해 보면서 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다!

2024.08.21 - [AI 언어 모델] - ⚡Hermes 3: Llama 3.1을 넘어선 최첨단 오픈 소스 언어 모델의 등장
⚡Hermes 3: Llama 3.1을 넘어선 최첨단 오픈 소스 언어 모델의 등장
안녕하세요! 오늘은 Nous Research에서 개발한 최신 오픈 소스 대규모 언어 모델 Hermes 3에 대해 알아보겠습니다. Hermes 3는 AGIEval(일반 인공지능 평가 능력), ARC-C(상식적 추론 능력), ARC-E(과학적 추론
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 🌋LLaVA-OneVision: GPT-4o 대체할 오픈소스 비디오·다중 이미지 분석 모델 (23) | 2024.09.08 |
|---|---|
| Qwen2-VL: 👁️알리바바의 오픈소스 비전 언어모델 (32) | 2024.09.03 |
| 🤖마이크로소프트 Phi-3.5 시리즈: 소형 MoE 모델의 혁신 (13) | 2024.08.24 |
| ⚡Hermes 3: Llama 3.1을 넘어선 최첨단 오픈 소스 언어 모델의 등장 (2) | 2024.08.21 |
| 🚀EXAONE 3.0 7.8B 리뷰: LG AI 연구소의 혁신적인 언어 모델 (4) | 2024.08.11 |



