안녕하세요! 오늘은 웹에서 사용자의 질문과 가장 유사한 Q&A 데이터셋을 벡터검색해서 유사도와 함께 표시하는 AI기반 Q&A 시스템을 만드는 프로젝트입니다. 기존의 키워드 검색방식은 만족하는 키워드가 없으면 검색결과가 전혀 안 나오지만, 벡터 검색방식은 질문의 내용과 의미상 가장 유사한 데이터를 검색해서 보여줍니다. 이 블로그에서는 허깅페이스의 Q&A 데이터셋 텍스트를 임베딩으로 변환하고, 주어진 쿼리와 유사한 임베딩을 가진 검색결과와 유사도를 표시하는 웹 페이지를 만들어 보겠습니다. 자, 같이 출발하실까요?
이번 프로젝트의 출처는 유튜브 "EASILY create Q&A Application using Embeddings with CUSTOM data" 입니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
벡터 검색이란?
벡터검색은 임베딩 검색(Embedding Search)이라고도 불리며, 기계 학습 모델에서 텍스트와 같은 비정형 데이터를 처리하는 데 사용되고, 단어, 문장 또는 문서를 고차원 공간의 점으로 매핑한 후(임베딩), 주어진 검색 쿼리 벡터와 각 문서 벡터 간의 거리를 계산해서, 가장 가까운 순서로 문서를 정렬하게 됩니다. 이렇게 함으로써 유사한 의미를 가진 단어나 문장은 고차원 벡터 공간에서 서로 가까워지게 됩니다.
벡터 검색의 원리를 이해하기 위한 간단한 예시입니다.
- 1. 임베딩 공간 설정: 각 문서를 2차원 벡터로 나타내겠습니다. - 문서 A는 (1, 2), 문서 B는 (4, 5)와 같은 방식으로 표현됩니다.
- 2. 쿼리 벡터 생성: 사용자가 검색하는 쿼리도 동일한 임베딩 공간에 매핑됩니다. - 사용자가 검색어를 입력했다고 가정하고, 이 쿼리는 (2, 3)과 같은 벡터로 표현될 수 있습니다.
- 3. 벡터 간 유사성 계산: 문서 간 유사성은 벡터 간 거리나 내적을 통해 계산됩니다. 여기서는 2차원 벡터이므로 두 점 (x1, y1)와 (x2, y2) 사이의 거리는 `sqrt((x2 - x1)^2 + (y2 - y1)^2)`입니다.
- 4. 검색 결과 정렬: 검색 쿼리 벡터와 각 문서 벡터 간의 거리를 계산하고, 가장 가까운 순서로 문서를 정렬합니다. 문서 A(1, 2), 문서 B(4, 5), 검색 쿼리(2, 3)에서 문서 A와 쿼리 간 거리는 sqrt((2-1)^2 + (3-2)^2) = sqrt(1 + 1) = sqrt(2), 문서 B와 쿼리 간 거리는 sqrt((4-2)^2 + (5-3)^2) = sqrt(4 + 4) = sqrt(8) 이므로, B와 쿼리 간의 거리가 A와 쿼리 간의 거리보다 큽니다. 따라서 유사성이 더 큰 문서는 A가 되고, 검색 결과는 A가 B보다 더 가까워진 것을 의미합니다.
벡터 검색의 원리는 이러한 방식으로 유사성을 계산하고, 쿼리와 가장 가까운 문서를 검색 결과로 반환하는 것입니다.
벡터 검색의 장점은 다음과 같습니다.
- 1. 의미론적 유사성 캡처: 벡터 검색은 단순한 키워드 일치가 아니라 의미론적 유사성을 고려하여 문서나 문장 간의 관련성을 측정합니다. 이는 단어 임베딩을 사용하여 단어 간 의미적 관계를 이해하고 유사성을 측정하기 때문입니다.
- 2. 다양한 작업에 유연한 적용: 벡터 검색은 텍스트 유사성 측정뿐만 아니라 다양한 자연어 처리 작업에 활용될 수 있습니다. 예를 들어, 문서 클러스터링, 문서 분류, 감정 분석 등에서도 효과적으로 사용될 수 있습니다.
- 3. 문맥적 이해: 벡터 검색은 문맥을 고려하여 검색 결과를 생성할 수 있습니다. 특정 단어나 문구의 문맥을 이해하고 해당 문맥에 맞는 결과를 반환할 수 있습니다.
간단한 키워드 매칭이 필요한 경우에는 키워드 검색이 효과적일 수 있지만, 의미적 유사성이나 문맥적 이해가 필요한 경우에는 벡터 검색이 더 효과적일 수 있습니다.
환경설정 및 종속성 설치
먼저, 기본 환경설정을 위한 가상환경 생성과 활성화 모두 WSL(Windows Subsystem for Linux)에서 진행합니다. WSL 프롬프트에서 가상환경 생성은 "python3.11 -m venv myenv", 활성화는 "source myenv/bin/activate" 명령어를 입력하면 됩니다. 단, 가상환경 이름을 설정할 때 "txtai"로 정하면 종속성 설치 오류가 발생하니 다른 이름으로 설정하시기 바랍니다.
다음은 코드 실행을 위한 종속성 설치입니다. 아래에 텍스트 내용을 복사해서 원하는 폴더에 requirements.txt라는 이름으로 파일을 만든 다음 가상환경이 활성화된 WSL 프롬프트에서 "pip install -r requirements.txt" 명령어로 종속성을 설치해 줍니다. 각 라이브러리의 용도는 다음과 같습니다.
- 1. txtai: 텍스트 데이터에 대한 자연어 처리 (NLP) 작업을 수행하는 Python 라이브러리입니다. 벡터 검색, 문서 유사성 측정, 텍스트 클러스터링 및 텍스트 임베딩과 같은 작업을 간편하게 수행할 수 있도록 도와줍니다. 또한 원하는 텍스트 작업에 대한 커스터마이징이 가능합니다.
- 2. sentencepiece: 구글에서 개발한 오픈 소스 문장 분리 라이브러리입니다. 특히, 자연어 처리에서 서브워드 분절(Subword Segmentation) 작업에 사용됩니다. 문장을 최소 단위의 서브워드로 분리하여 언어의 다양한 표현을 더 효율적으로 다룰 수 있도록 도와줍니다.
- 3. sacremoses: 텍스트의 토큰화(Tokenization), 디토큰화(Detokenization), 그리고 텍스트 정규화 등의 작업을 수행하는 라이브러리입니다. 자연어 처리에서 전처리 및 후처리 작업에 사용됩니다.
- 4. fasttext: 페이스북에서 개발한 단어 임베딩과 텍스트 분류를 위한 라이브러리입니다. 특히, 빠른 학습 속도와 효율적인 임베딩을 제공하여 자연어 처리 작업에서 활용됩니다.
- 5. torch, torchvision: PyTorch라는 딥러닝 프레임워크를 지원하는 라이브러리이며, `torchvision`은 이미지 및 비전 관련 작업을 위한 PyTorch 패키지입니다. 딥러닝 모델을 구축하고 학습하는 데 사용됩니다.
- 6. gradio: 간단하게 웹 기반 인터페이스를 만들어주는 라이브러리로, 모델 배포 및 모델의 결과를 시각적으로 확인하는 데 사용됩니다. 특히, 모델을 사용자 친화적인 웹 애플리케이션으로 변환하는 데 유용합니다.
- 7. datasets: Hugging Face에서 제공하는 라이브러리로, 다양한 자연어 처리 작업에 사용되는 다양한 데이터셋을 쉽게 접근할 수 있도록 도와줍니다. 특히, 사전 훈련된 모델의 학습에 사용되는 데이터셋을 제공합니다.
txtai[all]
sentencepiece
sacremoses
fasttext
torch
torchvision
gradio
datasets"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
허깅페이스 데이터셋과 임베딩 모델
이번 프로젝트에서 검색에 사용할 데이터셋은 총 6,642개의 질문/답변 쌍으로 구성된 허깅페이스의 web_questions 데이터셋을 사용합니다. 데이터셋은 "url", "question", "answers"로 이루어지며, 예시는 다음과 같습니다.
{ "answers": ["Jamaican Creole English Language", "Jamaican English"],
"question": "what does jamaican people speak?",
"url": "http://www.freebase.com/view/en/jamaica" }
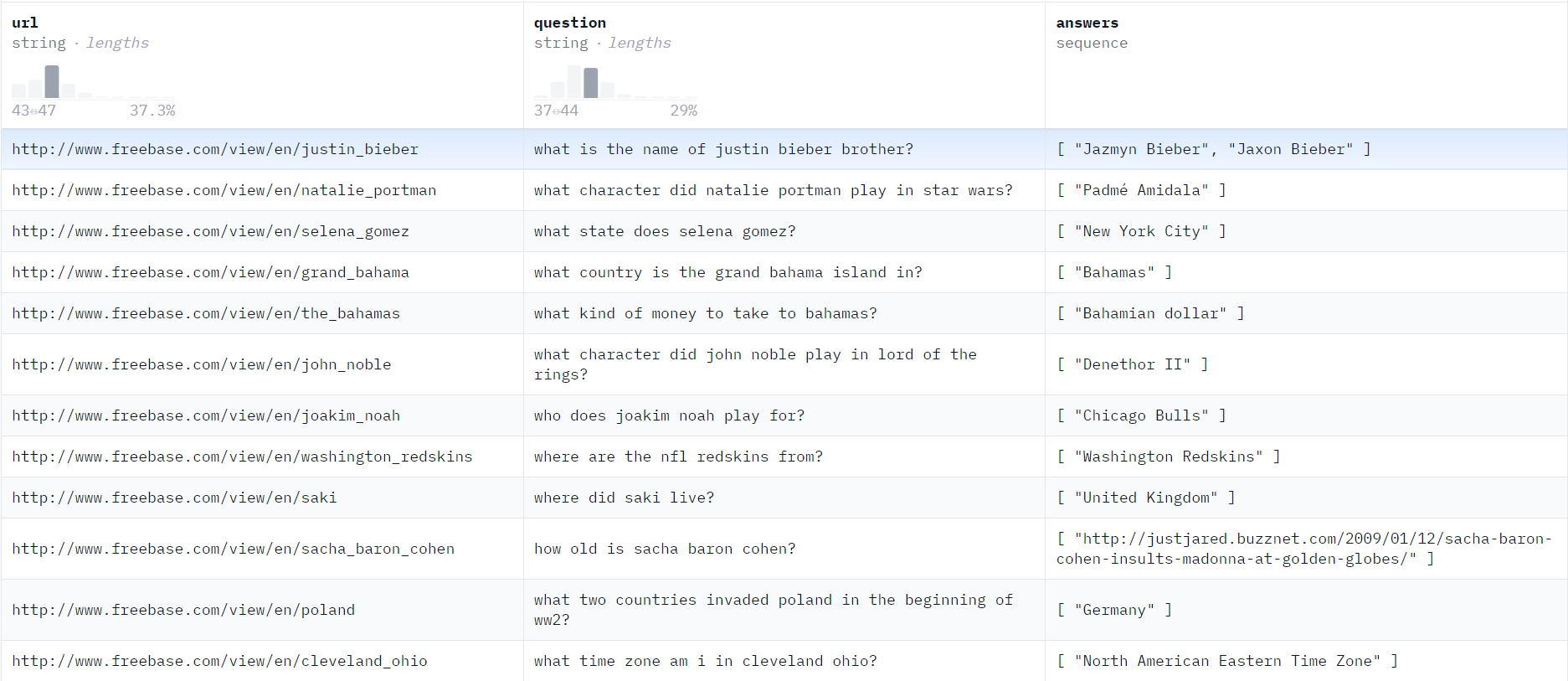
아래는 허깅페이스 web_questions 데이터셋의 세부내용을 조회할 수 있는 사이트입니다.
https://huggingface.co/datasets/web_questions
web_questions · Datasets at Hugging Face
Subset default (5.81k rows) Split train (3.78k rows)test (2.03k rows)
huggingface.co
또한, 이 코드에서는 `sentence-transformers` 라이브러리를 사용하여 단어 임베딩이 적용되었습니다. `sentence-transformers`는 사전 훈련된 모델을 사용하여 문장이나 문서를 벡터로 효과적으로 표현하는 데 도움이 되는 라이브러리입니다. 코드에서 사용된 모델인 "nli-mpnet-base-v2"는 Multilingual Natural Language Inference (NLI) 모델이며, 이는 문장 간의 의미론적 유사성을 표현하기 위해 학습되었습니다.
단어 임베딩은 각 단어나 문장을 고차원 벡터로 변환하는 기술로, 이를 통해 모델은 단어 간의 의미론적 관계를 학습하고 문서 간의 유사성을 측정할 수 있게 됩니다. 이는 벡터 검색 및 정보 검색 작업에 특히 유용합니다. `nli-mpnet-base-v2` 모델의 임베딩 차원은 일반적으로 768차원입니다. 이것은 각 문장이나 문서를 768차원의 벡터로 매핑한다는 의미입니다.
파이썬 코드 실행하기
다음은 파이썬 코드 실행단계입니다. 이 코드는 txtai 라이브러리를 사용하여 간단한 벡터 검색 질문 응답 애플리케이션을 구축하고, Gradio 사용자 인터페이스를 통합하는 코드이며, 동작순서는 다음과 같습니다.
- 1. 데이터셋 로딩: "web_questions" 데이터셋의 훈련 세트를 `datasets` 라이브러리를 사용하여 로드합니다. 이 데이터 세트는 6,642개의 질문/답변 쌍으로 구성되어 있습니다.
- 2. 임베딩 초기화 및 인덱싱: "sentence-transformers/nli-mpnet-base-v2" 사전 훈련된 모델을 사용하여 `txtai`의 임베딩 모델을 초기화합니다. 데이터셋의 각 질문과 답변을 해당 문장에 대한 임베딩으로 변환하고 인덱싱 합니다.
- 3. 임베딩 저장: 초기화된 임베딩을 "questions.tar.gz"라는 파일로 저장합니다.
- 4. 애플리케이션 초기화: 저장된 임베딩 파일을 사용하여 `txtai` 애플리케이션을 초기화합니다.
- 5. 검색 함수: 사용자가 입력한 쿼리와 유사한 질문을 찾아 그에 대한 텍스트, 답변 및 유사도 점수를 반환합니다.
- 6. Gradio 인터페이스: Gradio를 사용하여 간단한 웹 인터페이스를 구현합니다. 사용자는 텍스트 상자에 질문을 입력하고, 시스템은 해당 질문과 유사한 것을 찾아 결과를 출력합니다. 출력에는 찾은 질문, 해당하는 답변, 그리고 유사도 점수가 표시됩니다.
from datasets import load_dataset
from txtai import Embeddings
import gradio as gr
from txtai.app import Application
# Load dataset
ds = load_dataset("web_questions", split="train")
# Initialize and index embeddings
embeddings = Embeddings(path="sentence-transformers/nli-mpnet-base-v2", content=True)
embeddings.index([(uid, {"url": row["url"], "text": row["question"],
"answer": ", ".join(row["answers"])}, None)
for uid, row in enumerate(ds)])
# Save the embeddings
embeddings.save("questions.tar.gz")
# Initialize the saved embeddings
app = Application("path: questions.tar.gz")
def search_question(query):
results = app.search(f"select text, answer, score from txtai where similar('{query}') limit 1")[0]
return results['text'], results['answer'], results['score']
interface = gr.Interface(
fn=search_question,
inputs=gr.components.Textbox(label="Enter your query"),
outputs=[gr.components.Textbox(label="Question"),gr.components.Textbox(label="Answer"),gr.components.Number(label="Similarity")]
)
interface.launch()
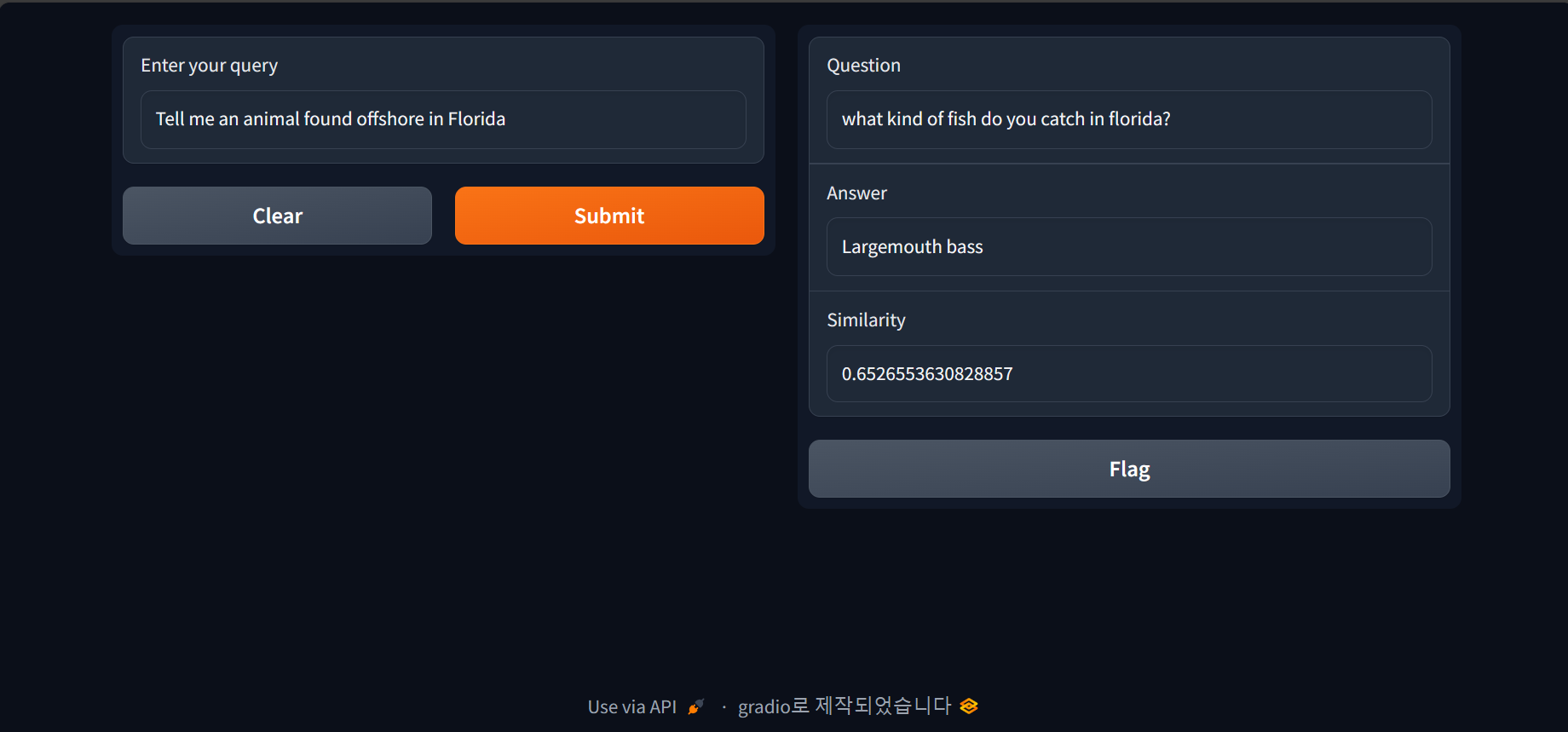
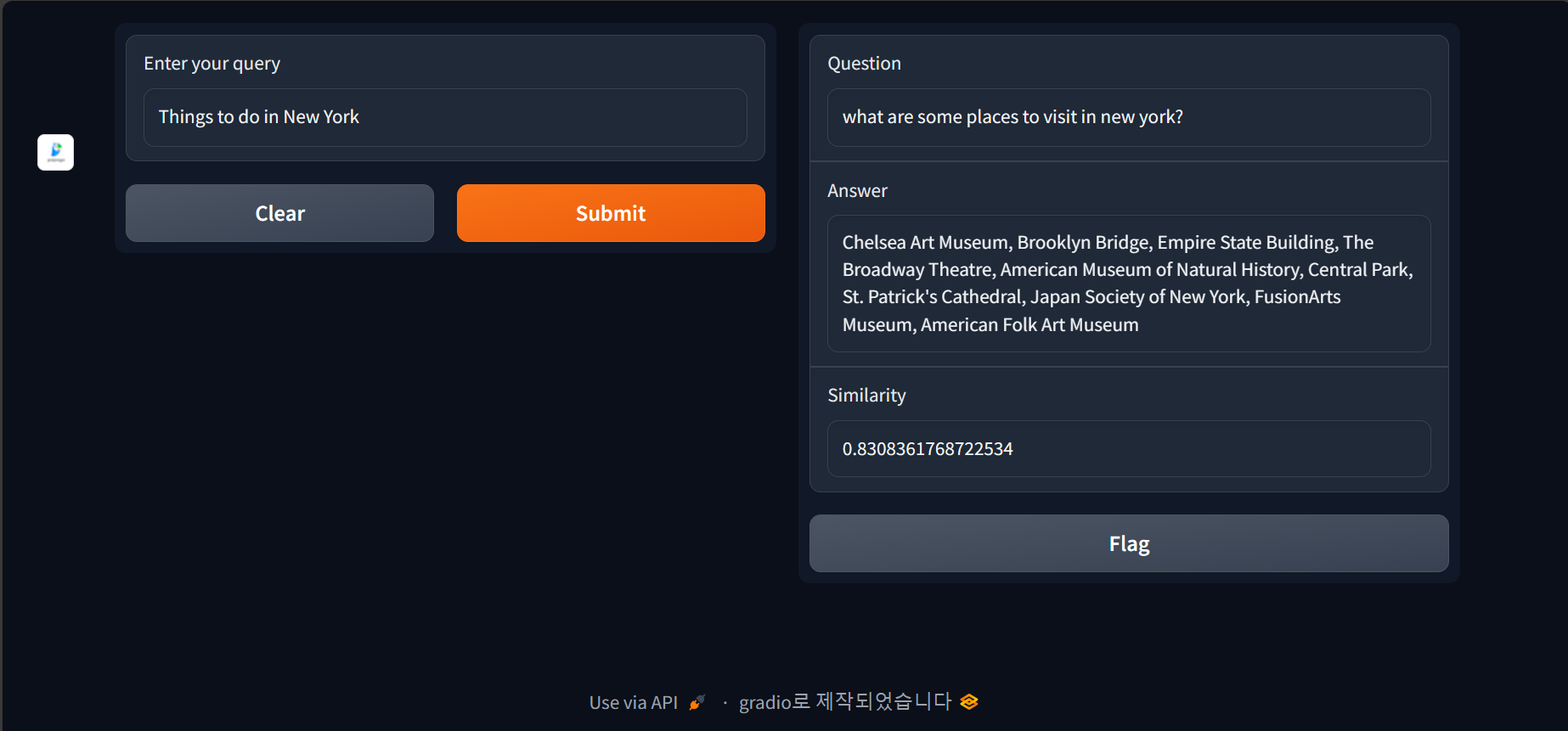
코드를 실행하면 http://127.0.0.1:7860의 주소에서 다음과 같은 화면이 열리게 됩니다. "Enter your query"라고 돼있는 부분에 질문을 입력하면, 허깅페이스 web_questions 데이터셋을 벡터검색해서 가장 유사한 Q&A 데이터셋과 유사도(Similarity)가 화면 오른쪽에 표시됩니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
마치며
이상과 같이 벡터 검색을 활용한 Q&A 시스템을 만들어보았습니다. 이 시스템은 기존의 키워드 검색 방식보다 의미론적 유사성을 고려하여 사용자의 질문에 가장 적합한 답변을 찾아주는 특징이 있습니다. 벡터 검색은 단어나 문장을 벡터로 변환하고, 그 벡터 간의 유사성을 계산하여 검색 결과를 제공합니다. 이를 통해 텍스트 데이터에 대한 더 나은 이해와 의미적 관련성을 고려한 검색이 가능합니다.
허깅페이스의 web_questions 데이터셋을 사용하여 모델을 초기화하고, 벡터검색을 통해 사용자가 입력한 질문과 의미상 가장 유사한 데이터를 찾아내어 결과를 표시하는 그라디오 웹 인터페이스를 구현하여, 사용자는 직관적이고 편리한 방식으로 웹에서 Q&A를 수행할 수 있습니다.
이 프로젝트를 통해 벡터 검색의 원리와 장점을 이해하고, 텍스트 데이터를 효과적으로 활용하여 유사성을 계산하는 방법을 살펴보았으며, 그라디오를 사용하여 간단한 웹 인터페이스를 구현하는 경험을 쌓을 수 있었습니다. 이 프로젝트를 기반으로 여러 응용 분야에서 벡터 검색을 적용하여 더 다양한 프로젝트를 시도해 볼 수 있을 것 같습니다.
그럼 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2024.01.01 - [대규모 언어모델] - 제미나이 프로 비전과 이미지로 대화하는 웹 챗봇 만들기
제미나이 프로 비전과 이미지로 대화하는 웹 챗봇 만들기
안녕하세요! 오늘은 제미나이 프로 비전 API를 활용해서 이미지를 업로드하고 대화하는 웹 챗봇을 만들어 보겠습니다. 제미나이 프로 비전은 구글이 출시한 멀티모달 AI 모델이며, 이미지, 텍스
fornewchallenge.tistory.com
'AI 도구' 카테고리의 다른 글
| Open Interpreter: 내PC 브라우저 제어, 파일 변환, PDF 요약까지 (2) | 2024.01.27 |
|---|---|
| 대규모 언어 모델을 활용한 고객리뷰 분석(feat. Solar, Mistral) (0) | 2024.01.10 |
| 고성능 그래픽카드 없이도 실시간 이미지 생성 가능! KREA AI (4) | 2023.12.11 |
| Fooocus: 이미지 생성의 새로운 차원을 여는 AI 아트 소프트웨어! (1) | 2023.12.09 |
| Stable Diffusion과 ComfyUI로 AI 사진작가에 도전하세요 (5) | 2023.12.04 |



