안녕하세요. 오늘 살펴볼 AI 논문은 Visual Instruction Tuning (시각적 지시 조정) 기술과 이에 기반하여 개발된 LLaVA (Language-Image Visual Assistant)라는 멀티모달 언어모델에 대한 내용입니다. 시각적 지시 조정은 시각적인 콘텐츠에 대한 언어모델의 인지 정확도를 높이기 위한 기술이며, 논문에서는 이 기술을 기반으로 언어적 지시에 따라 시각적 작업을 수행하는데 특화된 LLaVA이라는 언어모델을 제시하고 있습니다. 이 블로그에서는 Visual Instruction Tuning 기술의 원리와 LLaVA 모델의 특징에 대해 알아보실 수 있습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문의 개요 및 목적
- 논문 제목: Visual Instruction Tuning(시각적 지시 조정)
- 논문 저자: Haotian Liu, Chunyuan Li, Microsoft Research 등
- 논문 게재 사이트: arXiv
- 논문 게재일:2023. 12
이 논문의 핵심 목적은 시각과 언어 간의 상호 작용을 향상하기 위한 새로운 방법인 "Visual Instruction Tuning"을 제안하고, 이를 통해 개발한 멀티모달 언어모델인 LLaVA(Language-Image Visual Assistant)를 제시하여 효과와 성능을 입증하는 것입니다.


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문의 연구내용
논문에서는 시각적 인지 모델의 정확성 향상을 위해 Visual Instruction Tuning(시각적 지시 조정)을 소개하고, 언어-이미지 훈련 데이터를 기반으로 한 자동화된 파이프라인을 구축하여 개발한 LLaVA (Language-Image Visual Assistant) 언어모델을 제안합니다.
Visual Instruction Tuning(VIT, 시각적 지시 조정)
Visual Instruction(시각적 지시)이란 화면이나 이미지 같은 시각적인 컨텐츠에 대한 언어적인 설명이나 지시를 말합니다.(예. 빨간색 자동차를 찾아라, 이 음식으로 어떤요리를 만들수 있는지 알려줘 등) Visual Instruction Tuning은 언어와 이미지를 결합한 모델의 성능을 향상하기 위한 개념입니다. VIT의 주요 목적은 언어와 이미지 간의 상호 작용에서 발생하는 모호성을 극복하고, 모델이 언어적 지시에 더 적합하게 반응하도록 하는 것입니다. 특히, 시각 모델의 성능을 높이기 위해 이미지와 언어를 연결하는 자동화된 프로세스를 사용합니다.
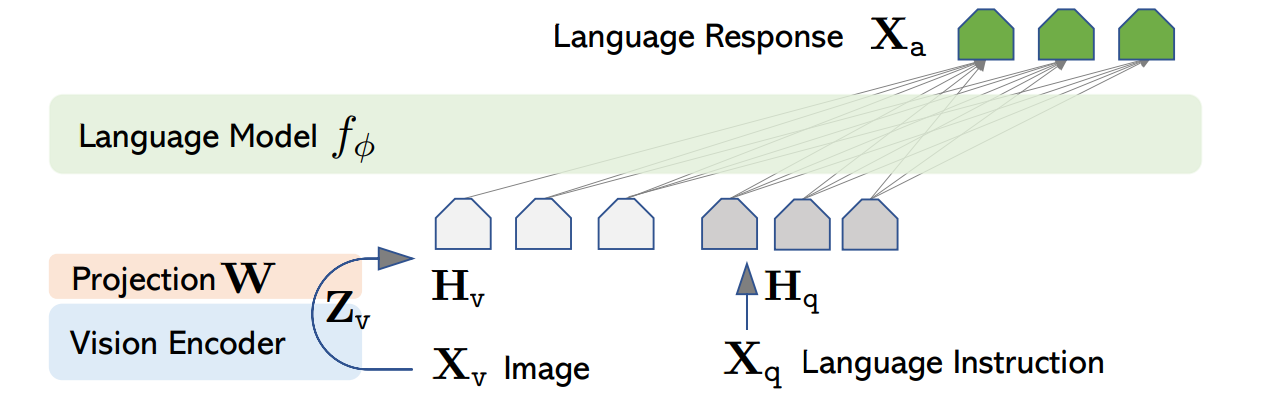
다음은 시각적 지시 조정 아키텍처의 동작순서와 설명입니다.
- 1. 이미지 입력: 이미지 (Xv)가 시각적 인코더에 입력됩니다.(예. 공항 비행기 출발 시각 전광판)
- 2. 시각적 특징 추출: 시각적 인코더는 시각적 특징 (Zv)을 생성합니다.
- 3. 특성 투영: 투영 레이어 (W)는 시각적 특징 (Zv)을 언어 임베딩 토큰 (Hv)으로 변환하여 LLM과 호환되도록 합니다.
- 4. 지시 입력: 사용자의 언어 지시 (Xq)도 입력으로 제공됩니다.(예. 뉴캐슬 행 비행기는 몇시에 출발해?)
- 5. 대규모 언어모델(LLM) 처리: LLM은 언어 임베딩 토큰 (Hv)과 언어 지시 (Xq)를 함께 처리합니다.
- 6. 언어 응답 생성: LLM은 이미지와 지시를 이해한 후에 언어 응답 (Xa)을 생성합니다.(예. 12시30분에 출발합니다.)
언어-이미지 데이터셋으로 훈련된 LLaVA 모델은 시각적 인코더를 사용하여 이미지에서 특징을 추출하고, 투영 레이어에서 변환된 언어 임베딩과 통합하여 대규모 언어 모델에서 처리하여 응답을 생성하는 구조를 가지고 있습니다.
LLaVA (Language-Image Visual Assistant, 언어-이미지 시각 어시스턴트)
LLaVA는 언어와 이미지 간의 복합적인 상호 작용에 중점을 둔 멀티모달 모델로, Visual Instruction Tuning(VIT)을 기반으로 개발되었습니다. 이 모델은 언어적 지시에 따라 시각적 작업을 수행하도록 훈련되며, 주로 과학 분야의 질문 응답 작업과 같은 실제 응용에서 높은 정확도를 보입니다.
LLaVA는 다음과 같은 단계로 학습되고 조정됩니다.
- 1. 데이터 수집: LLaVA의 학습을 위해 언어-이미지 데이터셋을 수집합니다. 이 데이터셋은 특히 시각적 작업을 수행하는 데 필요한 언어적 지시와 함께 이미지를 포함합니다.
- 2. 전처리: 수집된 데이터는 전처리 단계를 거쳐 언어와 이미지의 상호작용을 용이하게 합니다. 이는 이미지의 시각적 특징과 언어적 특징 간의 관계를 강조하기 위해 정교하게 수행됩니다.
- 3. 비전 인코더 활용: 비전 인코더를 사용하여 이미지의 시각적 특징을 추출합니다. 이는 대규모 언어모델이 이미지에 대해 이해하는데 중요한 역할을 합니다.
- 4. 언어 및 이미지 간의 조정 (Fine-tuning): LLaVA는 전처리된 데이터를 기반으로 학습되며, 특히 시각적 작업에 대한 정확한 언어적 이해를 갖도록 조정됩니다. 이 단계에서 VIT의 원리가 활용되어 모델이 주어진 언어적 지시에 따라 이미지를 올바르게 이해하도록 보장됩니다.
- 5. 벤치마크 학습: LLaVA는 벤치마크 작업, 특히 과학 분야의 질문 응답 작업을 위해 학습됩니다. 이를 통해 모델은 실제 응용에서의 성능을 향상하기 위한 특정 작업에 적합하게 학습됩니다.
LLaVA는 다양한 벤치마크에서 우수한 성능을 보여주며, 지시 튜닝과 세부 및 복잡한 질문의 추가가 성능 향상에 큰 영향을 미침을 확인할 수 있습니다. 언어 및 이미지 간 상호작용에 중점을 둔 LLaVA의 설계는 실제 상황에서의 작업에 효과적으로 적용됨을 시사합니다. LLaVA의 다양한 벤치마크 결과와 성능 분석은 모델이 실제 환경에서 효과적으로 작동하며 다양한 작업에 적응할 수 있는 능력을 보여줍니다.
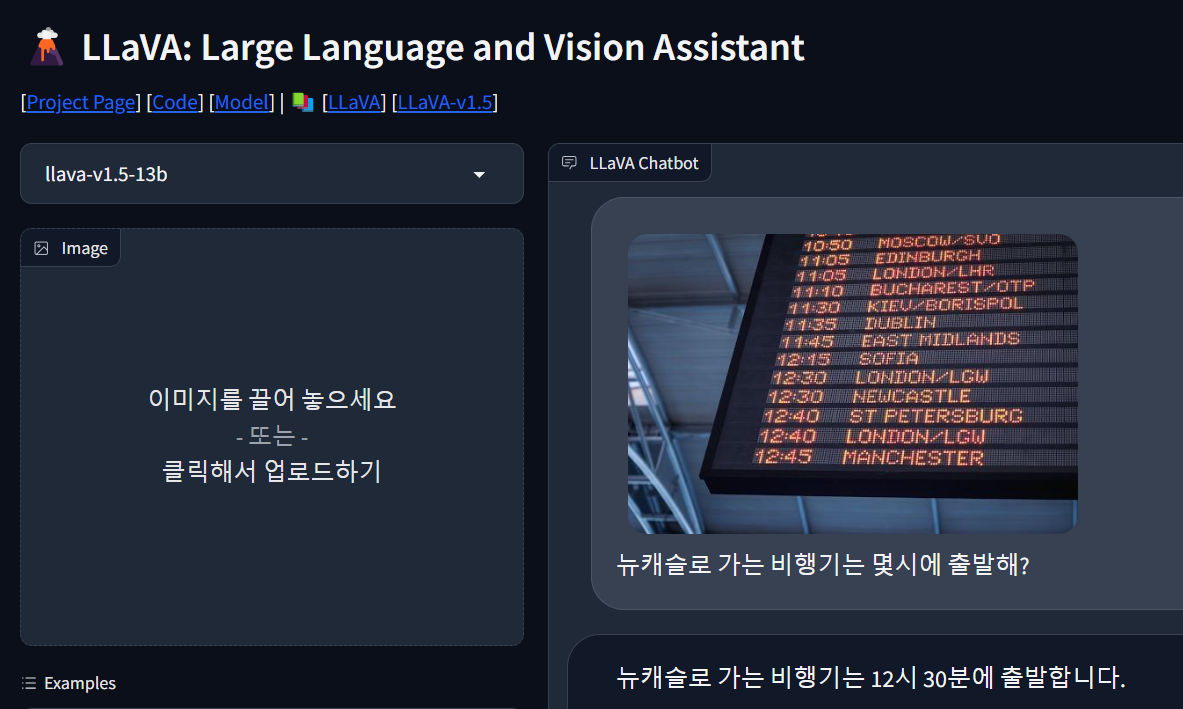
DEMO
다음 사이트에서 Visual Instruction Tuning (시각적 지시 조정) 기반으로 개발된 LLaVA (Language-Image Visual Assistant) 언어모델과 채팅 DEMO를 해보실수 있습니다.

논문의 결론 및 전망
논문은 LLaVA의 다양한 활용 가능성을 제시하며, 향후 발전 가능성에 대한 전망을 제시합니다. 먼저, LLaVA의 주요 활용방안 중 하나는 실제 시나리오에서의 자연어와 이미지 간의 유연한 상호작용입니다. 이는 실제 세계의 작업 및 작업 환경에서 지시에 따라 비주얼 태스크를 완료하는 데 큰 도움이 될 수 있습니다.
또한, LLaVA는 높은 정확도와 강력한 다중 모달 기능을 바탕으로 다양한 분야에 적용될 수 있습니다. 논문에서는 학문적인 벤치마크에서부터 일상적인 대화 및 비주얼 태스크에 이르기까지, LLaVA의 활용 범위가 광범위할 것으로 전망하고 있습니다.
특히, LLaVA가 다양한 데이터 시나리오에서 성능 향상을 보여주는 것은 그 활용 가능성을 높여주고 있습니다. 향후 전망에서는 LLaVA의 성능을 더욱 향상하고, 다양한 분야에 맞춰 세부적인 튜닝 및 개선이 이루어질 것으로 기대됩니다. 또한, LLaVA의 활용이 확대되면서 실제 상황에서의 유용성이 더욱 부각될 것으로 예상되며, 다양한 산업 분야에서의 적용 가능성이 높아질 것으로 전망됩니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
마치며
오늘은 Visual Instruction Tuning(시각적 지시 조정)과 이에 기반하여 개발된 LLaVA (Language-Image Visual Assistant) 라는 멀티모달 언어모델에 대한 내용을 살펴보았습니다. Visual Instruction Tuning은 언어와 이미지 간의 상호 작용을 향상하기 위한 새로운 방법으로, 시각적 인지 모델의 정확성 향상에 기여할 수 있는 잠재력을 가지고 있습니다.
LLaVA는 Visual Instruction Tuning을 기반으로 개발된 멀티모달 모델로, 언어적 지시에 따라 시각적 작업을 수행하는 데 뛰어난 성능을 보입니다. LLaVA는 다양한 활용 가능성을 제시하며, 향후 발전 가능성에 대한 전망을 제시합니다. LLaVA의 향후 발전과 다양한 분야에서의 활용이 기대해 봅니다.
그럼 저는 다음시간에 더 유익한 자료를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2023.12.01 - [AI 논문 분석] - AI 논문 요약, '유망 신소재' 38만개 찾은 딥마인드의 AI기술
AI 논문 요약, '유망 신소재' 38만개 찾은 딥마인드의 AI기술
안녕하세요. 오늘은 AI분야 최신 논문을 요약해서 알아보는 여섯 번째 시간입니다. 최근 구글 딥마인드가 AI로 유망 신소재 38만 개를 찾았다는 기사와 논문이 발표되었는데요. 딥마인드가 신소
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| 제미나이 웹 챗봇 만들기 : 주식 정보 검색도 쌉가능 (2) | 2023.12.26 |
|---|---|
| 제미나이 API로 실시간 주식정보 가져오기 : 초보 탈출? (3) | 2023.12.23 |
| Ollama와 Langchain을 이용한 환각없는 RAG 챗봇 만들기 (2) | 2023.12.19 |
| 초보도 할 수 있는 구글 제미나이로 AI 레시피 생성 웹페이지 만들기 (2) | 2023.12.18 |
| Ollama를 활용한 대규모 언어 모델 웹 인터페이스 만들기: Mistral 7B와의 대화 (8) | 2023.12.15 |



