안녕하세요. 오늘은 Google에서 최근 출시한 혁신적인 오픈 소스 번역 AI 모델인 TranslateGemma 4B IT에 대해 알아보겠습니다. 이 블로그에서는 무료로 내 컴퓨터에서 직접 실행할 수 있는 방법과 실제 따라 할 수 있는 코드 예제를 확인하실 수 있습니다. 그럼 같이 출발해볼까요?
🌍 TranslateGemma란 무엇인가?
TranslateGemma는 Google이 개발한 차세대 오픈 소스 번역 모델 시리즈입니다. Google의 최신 LLM인 Gemma 3를 기반으로 하며, 4B, 12B, 27B 파라미터 버전으로 제공됩니다. 특히 4B 버전은 모바일 기기와 엣지 장치에서도 실행 가능하도록 최적화되어 있습니다.
이 모델의 가장 큰 특징은 '지식의 증류 (Knowledge Distillation)' 기술을 활용했다는 점입니다. Google의 가장 강력한 Gemini 모델의 지능을 작고 효율적인 오픈 모델로 압축하여, 40억 개의 파라미터 (4B parameters)만으로도 상용 번역 서비스 수준의 품질을 제공합니다.
TranslateGemma는 텍스트 번역뿐만 아니라 이미지 내 텍스트 추출 및 번역도 가능한 멀티모달 번역 모델입니다. 55개 언어를 지원하며, 실제로는 500개 이상의 언어 쌍으로 훈련되었습니다.
💡 전문 용어 쉽게 이해하기:
- 파라미터 (Parameter): AI 모델이 학습한 '지식의 양'을 나타내는 숫자입니다. 파라미터가 많을수록 더 복잡한 것을 학습할 수 있지만, 그만큼 더 많은 컴퓨터 자원이 필요합니다.
- 지식 증류 (Knowledge Distillation): 큰 모델(선생님)의 지식을 작은 모델(학생)에게 전달하는 기술입니다. 작은 모델이 큰 모델의 성능을 흉내 낼 수 있게 합니다.
- 저자원 언어 (Low-Resource Language): 학습 데이터가 부족한 언어를 말합니다. 예를 들어 한국어, 영어는 데이터가 많지만, 아프리카의 소수 언어는 데이터가 적습니다.
- 멀티모달 (Multimodal): 텍스트뿐만 아니라 이미지, 오디오 등 다양한 형태의 데이터를 처리할 수 있는 능력을 말합니다.
🚀 TranslateGemma의 핵심 특징
| 특징 | 설명 |
|---|---|
| ⚡ 고효율 성능 | 4B 모델이 12B 베이스라인과 동등한 성능, 12B 모델은 27B보다 우수한 성능 |
| 🌐 55개 언어 지원 | 한국어, 영어, 중국어, 힌디어 등 주요 언어부터 저자원 언어까지 포함 |
| 📸 이미지 번역 | 이미지 내 텍스트를 자동으로 추출하고 번역하는 멀티모달 기능 |
| 💻 모바일 실행 | 4B 모델은 스마트폰과 노트북에서도 실행 가능 |
| 📖 오픈 소스 | Apache 2.0 라이선스로 상업적 이용이 가능한 완전한 오픈 소스 |
왜 TranslateGemma인가?
기존의 번역 모델은 성능과 크기 사이의 트레이드오프가 존재했습니다. 좋은 번역 품질을 원하면 큰 모델을 사용해야 했고, 작은 모델은 품질이 낮았습니다.
TranslateGemma는 이 패러다임을 깼습니다. 전문화된 2단계 미세조정 (Fine-Tuning) 과정을 통해 12B 모델이 27B 베이스라인을 surpass하고, 4B 모델이 12B 베이스라인과 대등한 성능을 보입니다.
이는 개발자들에게 엄청난 이점입니다. 더 적은 파라미터로 상용 서비스 수준의 번역 품질을 달성할 수 있으므로, 더 높은 처리량(throughput)과 더 낮은 지연 시간(latency)을 얻을 수 있습니다.
🥽 하드웨어 요구사항
TranslateGemma 4B IT 모델을 실행하기 위한 하드웨어 요구사항은 사용 환경에 따라 다릅니다.
| 구성 요소 | 최소 사양 (CPU) | 권장 사양 (GPU) |
|---|---|---|
| GPU | 없음 (CPU만 가능) | NVIDIA RTX 3060 이상 |
| VRAM | - | 8GB 이상 |
| 시스템 RAM | 16GB | 32GB 이상 |
| 저장 공간 | 15GB 여유 공간 | SSD 20GB 이상 |
💡 참고: TranslateGemma 4B는 CPU만으로도 실행 가능하지만, GPU가 있다면 훨씬 빠른 번역 속도를 경험할 수 있습니다. 모바일 기기에서도 실행 가능하도록 최적화되어 있습니다.
💻 단계별 설치 가이드 (초보자용)
이제 TranslateGemma 4B IT를 직접 실행해보겠습니다. Python 기반의 Transformers 라이브러리를 사용하겠습니다.
1단계: Python 환경 설정
먼저 Python이 설치되어 있어야 합니다. 터미널(또는 명령 프롬프트)을 열고 다음 명령어로 Python 버전을 확인하세요.
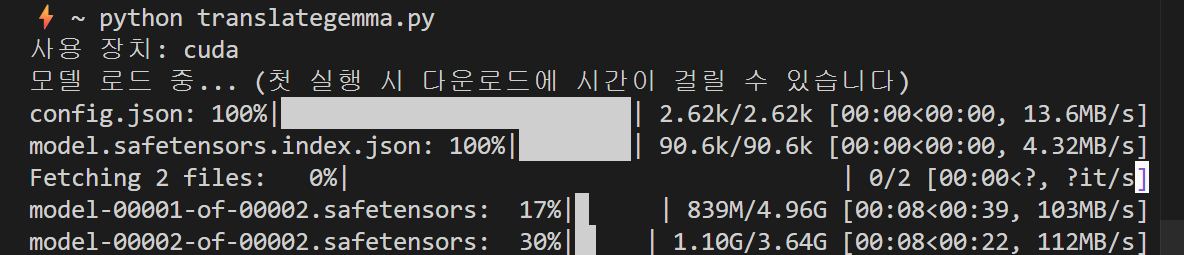
python --versionPython 3.8 이상이 설치되어 있어야 합니다. 설치되어 있지 않다면 python.org에서 다운로드하세요.
2단계: 필수 라이브러리 설치
다음 명령어로 필요한 라이브러리들을 설치합니다. GPU가 있다면 PyTorch와 CUDA 호환 버전을 설치해야 합니다.
# Transformers 라이브러리 업그레이드
pip install -U transformers
# PyTorch 설치 (CUDA 지원 GPU가 있는 경우)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# 추가 의존성 설치
pip install accelerate pillow sentencepiece3단계: 첫 번째 텍스트 번역
이제 실제로 번역을 해보겠습니다. 다음 Python 코드를 translategemma_test.py라는 파일로 저장하세요.
import torch
from transformers import pipeline
# 장치 설정 (GPU가 있다면 cuda 사용)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"사용 장치: {device}")
print("모델 로드 중... (첫 실행 시 다운로드에 시간이 걸릴 수 있습니다)")
# 파이프라인 로드
pipe = pipeline(
"image-text-to-text",
model="google/translategemma-4b-it",
device=device,
dtype=torch.bfloat16 if device == "cuda" else torch.float32
)
# 번역할 메시지 설정
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"source_lang_code": "en",
"target_lang_code": "ko",
"text": "Hello, how are you today? I hope you have a wonderful day!",
}
],
}
]
print("\n번역 중...")
output = pipe(text=messages, max_new_tokens=200)
# 번역 결과 출력
translated_text = output[0]["generated_text"][-1]["content"]
print(f"\n원문 (en): Hello, how are you today? I hope you have a wonderful day!")
print(f"번역 (ko): {translated_text}")이제 터미널에서 다음 명령어로 실행하세요.
python translategemma_test.py첫 실행 시 모델을 다운로드해야 하므로 약 5~10분 정도 걸릴 수 있습니다. 다운로드가 완료되면 번역이 수행됩니다.
pip install --upgrade torch torchvision torchaudio
4단계: 이미지 내 텍스트 번역
TranslateGemma의 가장 강력한 기능 중 하나는 이미지 내 텍스트 추출 및 번역입니다. 다음은 이미지에서 텍스트를 추출하고 번역하는 예제입니다.
import torch
from transformers import pipeline
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"image-text-to-text",
model="google/translategemma-4b-it",
device=device,
dtype=torch.bfloat16 if device == "cuda" else torch.float32
)
# 이미지에서 텍스트 추출 및 번역
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"source_lang_code": "en",
"target_lang_code": "ko",
"url": "https://c7.alamy.com/comp/2YAX36N/traffic-signs-in-czech-republic-pedestrian-zone-2YAX36N.jpg",
},
],
}
]
print("이미지 분석 및 번역 중...")
output = pipe(text=messages, max_new_tokens=200)
# 결과 출력
translated_text = output[0]["generated_text"][-1]["content"]
print(f"\n추출 및 번역 결과:\n{translated_text}")

📊 다른 모델과의 비교
TranslateGemma는 효율성 면에서 혁신적인 발전을 보여줍니다. WMT24++ 벤치마크에서 측정한 결과입니다.
| 모델 | 파라미터 | 상대 오류율 | 주요 특징 |
|---|---|---|---|
| TranslateGemma 12B | 12B | 기준 | 27B보다 낮은 오류율 |
| Gemma 3 27B | 27B | +15% | 베이스라인 모델 |
| TranslateGemma 4B | 4B | +8% | 12B와 유사한 성능 |
| Gemma 3 12B | 12B | +25% | 베이스라인 모델 |
성능 분석: 어떤 모델을 선택할까요?
단순히 파라미터 수만 보고 선택할 것인지, 아니면 실제 성능과 배포 환경을 고려할 것인지에 따라 판단이 달라질 수 있습니다.
TranslateGemma 4B는 특히 모바일 및 엣지 배포에서 탁월한 선택입니다. 12B 베이스라인과 대등한 성능을 보이면서 훨씬 적은 자원을 소모하므로, 스마트폰이나 노트북에서도 실시간 번역이 가능합니다.
반면, 최고 수준의 번역 정확도가 필요한 서비스라면 12B 모델을 고려해볼 수 있습니다. 27B 베이스라인보다 낮은 오류율을 보이면서도 배포 비용은 훨씬 낮습니다.
하지만 대부분의 실용적인 사용 케이스에서 4B 모델은 충분한 품질과 압도적인 효율성을 제공합니다.
🌍 지원 언어 목록
TranslateGemma는 55개 언어를 공식적으로 지원하며, 실제로는 500개 이상의 언어 쌍으로 훈련되었습니다.
| 언어 | 언어 코드 | 비고 |
|---|---|---|
| 한국어 | ko | 고자원 언어 |
| 영어 | en | 고자원 언어 |
| 중국어 | zh | 고자원 언어 |
| 일본어 | ja | 고자원 언어 |
| 스페인어 | es | 고자원 언어 |
| 프랑스어 | fr | 고자원 언어 |
| 독일어 | de | 중간 자원 언어 |
| 히인디어 | hi | 중간 자원 언어 |
| 아랍어 | ar | 중간 자원 언어 |
| 태국어 | th | 저자원 언어 |
💡 언어 코드란? ISO 639-1 표준에 따른 2글자 언어 코드입니다. 예를 들어 한국어는 "ko", 영어는 "en", 중국어는 "zh"입니다. 지역별 변형을 지정할 수도 있습니다. 예를 들어 "en-US"는 미국 영어, "en-GB"는 영국 영어를 의미합니다.
🎯 실제 활용 사례
TranslateGemma의 효율성과 기능은 다음과 같은 실제 애플리케이션에 적합합니다.
| 사용 사례 | 설명 |
|---|---|
| 🌐 웹사이트 번역 | 실시간으로 웹사이트 콘텐츠를 다국어로 번역 |
| 📱 모바일 번역 앱 | 오프라인에서도 작동하는 번역 앱 개발 |
| 📸 여행 사진 번역 | 여행지의 간판, 메뉴판 등을 실시간 번역 |
| 📚 문서 번역 | PDF, 워드 문서 등을 대량으로 번역 |
| 🎬 자막 생성 | 비디오 자막을 실시간으로 번역 |
⚙️ 고급 사용법
TranslateGemma의 기본 chat template 외에도 다양한 프롬프팅 기법을 활용할 수 있습니다.
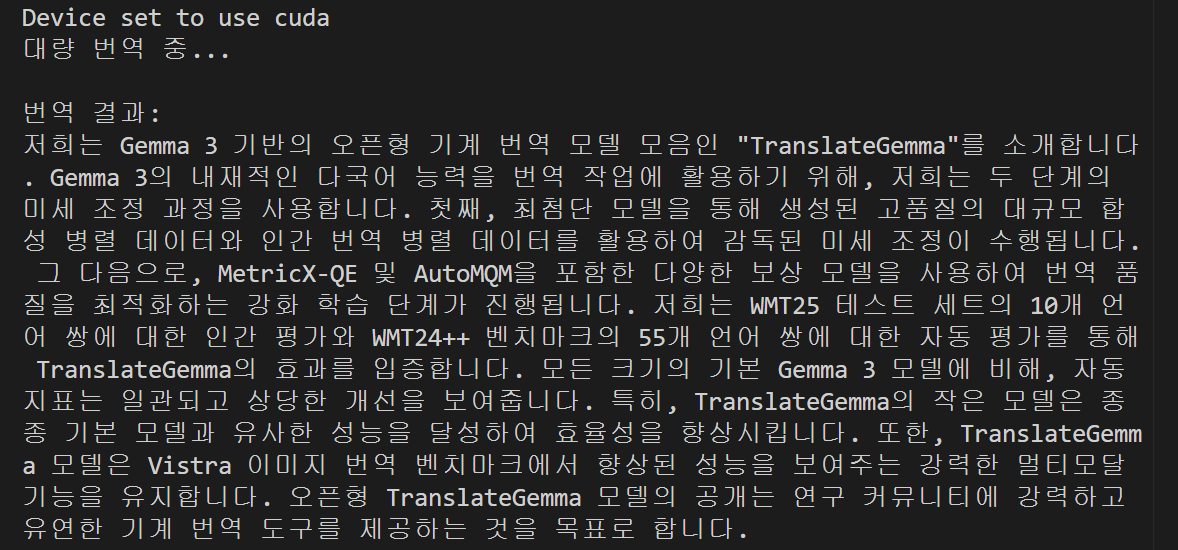
대량 번역 (Batch Translation)
여러 문장이나 긴 문장을 한 번에 번역할 수 있습니다.
import torch
from transformers import pipeline
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"image-text-to-text",
model="google/translategemma-4b-it",
device=device,
dtype=torch.bfloat16 if device == "cuda" else torch.float32
)
# 번역할 문장 리스트 (삼중 따옴표 사용)
texts = [
"""We present TranslateGemma, a suite of open machine translation models based on the Gemma 3 foundation models. To enhance the inherent multilingual capabilities of Gemma 3 for the translation task, we employ a two-stage fine-tuning process. First, supervised fine-tuning is performed using a rich mixture of high-quality large-scale synthetic parallel data generated via state-of-the-art models and human-translated parallel data. This is followed by a reinforcement learning phase, where we optimize translation quality using an ensemble of reward models, including MetricX-QE and AutoMQM, targeting translation quality. We demonstrate the effectiveness of TranslateGemma with human evaluation on the WMT25 test set across 10 language pairs and with automatic evaluation on the WMT24++ benchmark across 55 language pairs. Automatic metrics show consistent and substantial gains over the baseline Gemma 3 models across all sizes. Notably, smaller TranslateGemma models often achieve performance comparable to larger baseline models, offering improved efficiency. We also show that TranslateGemma models retain strong multimodal capabilities, with enhanced performance on the Vistra image translation benchmark. The release of the open TranslateGemma models aims to provide the research community with powerful and adaptable tools for machine translation."""
]
print("대량 번역 중...\n")
for text in texts:
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"source_lang_code": "en",
"target_lang_code": "ko",
"text": text,
}
],
}
]
output = pipe(text=messages, max_new_tokens=2000)
translated = output[0]["generated_text"][-1]["content"]
print(f"번역 결과:\n{translated}\n")위와 같이 번역 문장이 잘리는 경우 max_new_tokens 값을 늘리면 됩니다.
로컬 이미지 번역
인터넷에 있는 이미지뿐만 아니라 로컬에 저장된 이미지도 번역할 수 있습니다.
import torch
from transformers import pipeline
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"image-text-to-text",
model="google/translategemma-4b-it",
device=device,
dtype=torch.bfloat16 if device == "cuda" else torch.float32
)
# 로컬 이미지 로드
local_image_path = "./trgemmatest.jpg"
# 메시지 설정 - content는 하나의 아이템만!
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"source_lang_code": "ja",
"target_lang_code": "ko",
"url": local_image_path # 로컬 파일 경로를 url로 지정
}
]
}
]
print("이미지 분석 및 번역 중...")
# 파이프라인 실행 (images 파라미터 제거)
output = pipe(text=messages, max_new_tokens=500)
# 결과 출력
translated_text = output[0]["generated_text"][-1]["content"]
print(f"\n번역 결과:\n{translated_text}")
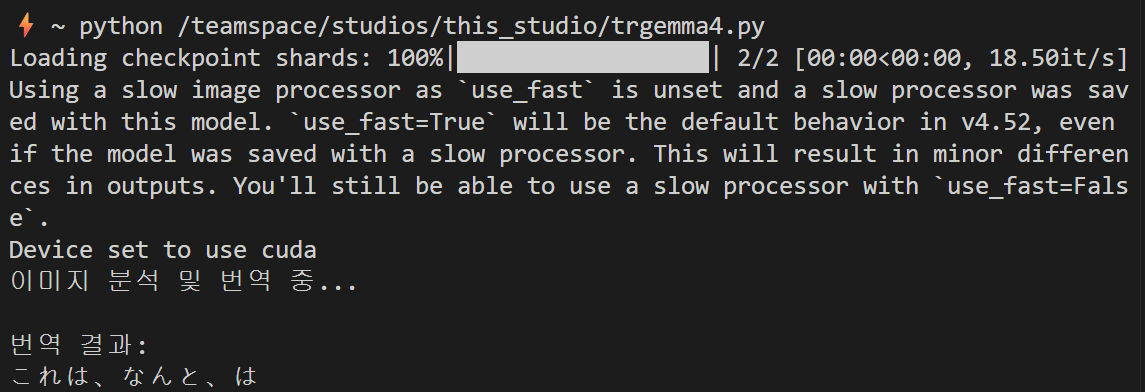
일본어 번역은 제대로 되지 않는것 같습니다.
⚠️ 제한 사항 및 주의점
TranslateGemma 사용 시 다음 제한 사항을 고려해야 합니다.
- 맥락 이해: 복잡한 문학적 표현이나 문화적 뉘앙스는 완벽하게 번역되지 않을 수 있습니다.
- 전문 용어: 의학, 법률 등 전문 분야의 용어는 추가 학습이 필요할 수 있습니다.
- 입력 길이: 2K 토큰(약 1500단어)의 입력 컨텍스트 제한이 있습니다.
- 저자원 언어: 55개 언어 외의 언어는 번역 품질이 낮을 수 있습니다.
📚 추가 리소스 및 링크
TranslateGemma에 대해 더 자세히 알아보고 싶으시다면 다음 리소스를 확인해보세요.
- 기술 보고서: TranslateGemma Technical Report (arXiv)
- Hugging Face: TranslateGemma 4B IT 모델 카드
- Kaggle: TranslateGemma on Kaggle
- Google AI Studio: Vertex Model Garden
- Gemma Cookbook: Google Colab 예제
🎯 마치며
TranslateGemma 4B는 단순히 작은 번역 모델이 아닙니다. 이는 '언어 장벽의 해소'를 향한 중요한 발걸음입니다. 모바일 기기에서도 실행 가능한 효율성과 상용 서비스 수준의 번역 품질을 결합하여, 누구나 어디서나 고품질 번역을 이용할 수 있는 세상을 만들고 있습니다.
특히 Apache 2.0 라이선스로 제공되므로 상업적 이용이 가능하며, 개발자와 크리에이터들이 자유롭게 프로젝트에 통합할 수 있습니다. RTX 3060 수준의 GPU를 가진 분들은 물론, CPU만으로도 실행 가능하므로 지금 바로 로컬에서 실행해볼 수 있습니다.
여러분도 한번 TranslateGemma를 직접 사용해보시길 추천드리면서 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.
📚 참고 문헌 및 출처
- Google Translate Research Team. (2026). TranslateGemma Technical Report. arXiv preprint arXiv:2601.09012. Retrieved from https://arxiv.org/pdf/2601.09012
- Google. (2026). TranslateGemma: Open Translation Models Built on Gemma 3. Retrieved from https://blog.google/innovation-and-ai/technology/developers-tools/translategemma/
- Google. (2026). TranslateGemma 4B IT Model Card. Retrieved from https://huggingface.co/google/translategemma-4b-it
'AI 언어 모델' 카테고리의 다른 글
| 📖 Qwen3-TTS 무료 사용법: 음성 복제부터 디자인까지 완벽 가이드 (2) | 2026.01.24 |
|---|---|
| 🔥 GLM-4.7-Flash: 완전 무료! 30B급 최강 AI로 ChatGPT 비용 100% 절감하는 법 (0) | 2026.01.21 |
| 🔬 MedGemma 1.5 + MedASR: 내 PC에서 무료로 돌리는 의료용 AI 완벽 가이드 (0) | 2026.01.17 |
| 🚀0.5초 만에 이미지 생성: FLUX.2 [klein] 4B, 9B (0) | 2026.01.16 |
| 🐱DeepSeek 넘어선 560B 파라미터 추론 모델 LongCat 완벽 가이드 (1) | 2026.01.15 |



