안녕하세요! 오늘은 OpenAI Codex CLI를 Ollama와 로컬 모델로 무료 실행하는 방법에 대해 알아보겠습니다. Codex CLI는 OpenAI가 개발한 강력한 AI 코딩 에이전트로, 자연어를 코드로 변환하고 자동으로 코딩 작업을 수행합니다. 하지만 기본적으로 OpenAI API를 사용하므로 비용이 발생합니다. 이번 가이드에서는 Qwen3.5:4b 모델을 활용해 완전 무료로 로컬 환경에서 Codex를 실행하는 방법을 상세히 설명합니다.
이 블로그에서는 Codex CLI 설치, Ollama 설정, 로컬 모델 연동, config.toml 파일 구성, 실제 사용 예시까지 단계별로 다룹니다. API 비용 없이 내 PC에서 AI 코딩 에이전트를 활용하고 싶은 분들에게 완벽한 가이드를 제공합니다. 바로 시작해볼까요?

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
🤖 Codex CLI란 무엇인가?
Codex CLI는 OpenAI가 개발한 커맨드라인 기반 AI 코딩 에이전트입니다. 자연어 명령을 코드로 변환하고, 자동으로 파일을 생성/수정하며, 테스트를 실행하고 디버깅까지 수행합니다. Claude Code와 유사한 기능을 제공하지만, OpenAI 모델(GPT-OSS)을 기본으로 사용합니다.
💡 Codex CLI 핵심 기능
- 코드 생성: 자연어 명령을 코드로 변환 ("로그인 페이지 만들어줘", "숫자 리스트 정렬해줘")
- 디버깅 & 테스트: 코드 오류 자동 수정, 테스트 자동 실행
- 격리 환경 실행: 샌드박스에서 안전하게 코드 실행
- 다국어 지원: Python, JavaScript, TypeScript, Ruby, Go, PHP 등 12개 이상 언어
- 로컬 모델 지원:
--oss플래그로 오픈소스 모델 사용 가능
Codex CLI의 가장 큰 장점은 OpenAI API뿐 아니라 로컬 모델도 지원한다는 점입니다. --oss 플래그를 사용하면 Ollama, LM Studio, llama.cpp 등 다양한 로컬 서버와 연동할 수 있습니다.
💰 로컬 모델 사용의 이점
Codex CLI를 로컬 모델로 실행하면 다음 장점을 누릴 수 있습니다:
| 장점 | 설명 |
|---|---|
| 🆓 무료 | API 비용 0원, 하드웨어만 있으면 무제한 사용 |
| 🔒 프라이버시 | 코드가 외부 서버로 전송되지 않음 (기업 코드, 클라이언트 작업 보호) |
| 🌐 오프라인 | 인터넷 없이도 작동 가능 |
| ⚡ 무제한 요청 | Rate limit 없음, 하드웨어 용량까지 자유롭게 사용 |
| 🧪 실험自由 | 다양한 모델을 제한 없이 테스트 |
⚠️ 참고: 로컬 모델의 한계
로컬 모델은 클라우드 GPT-5 수준의 성능을 제공하지 않습니다. 특히 복잡한 multi-file 리팩토링, 대규모 아키텍처 설계 등은 클라우드 모델이 더 우수합니다. 하지만 코드 설명, 단순 수정, 문서 작성 등 일상적인 작업에는 로컬 모델이 충분합니다.
⚙️ 하드웨어 요구사항
로컬 모델 성능은 하드웨어에 크게 의존합니다. Qwen3.5:4b는 relatively 작은 모델이므로 일반 PC에서도 실행 가능합니다:
| 모델 크기 | RAM | GPU | 저장공간 | 예시 모델 |
|---|---|---|---|---|
| Small (4B-7B) | 8GB+ | GPU 없어도 가능 | 5-10GB | Qwen3.5:4b, Qwen3:0.6b |
| Medium (13B-34B) | 16GB+ | 8GB VRAM 권장 | 20-50GB | Qwen3.5:14b, DeepSeek-Coder-33B |
| Large (70B+) | 32GB+ | 24GB VRAM 필요 | 50-100GB | Qwen3.5:72b, Llama-4-70B |
Qwen3.5:4b는 4B 파라미터로 8GB RAM에서도 실행 가능합니다. GPU가 없어도 CPU만으로 작동하며, 약 3GB 저장공간을 차지합니다.
🚀 Step 1: Codex CLI 설치
Codex CLI는 npm으로 설치합니다:
# Node.js가 설치되어 있어야 합니다
npm install -g @openai/codex설치 후 버전 확인:
codex --version
# 출력: codex-cli 0.130.0 (예시)⚠️ npm 설치 후 codex 명령어가 작동하지 않는 경우
npm 패키지가 설치되었지만 codex 명령어가 PATH에 없는 경우가 있습니다. 이는 Node.js 버전 관리 도구(nvm, fnm 등) 사용 시 발생할 수 있습니다. 해결 방법:
# 강제 재설치로 PATH 연결
npm install -g @openai/codex --force
# 설치 위치 확인
which codex
# 출력: /home/사용자/.nvm/versions/node/v22.xx.x/bin/codex이후 버전 확인: codex --version
📌 Homebrew로 설치 (macOS)
macOS 사용자는 Homebrew로도 설치 가능합니다:
brew install codex🦙 Step 2: Ollama 설치 및 모델 다운로드
Ollama는 로컬 모델 실행을 가장 쉽게 만드는 플랫폼입니다. 모델 다운로드, 양자화(quantization), OpenAI-compatible API를 자동으로 제공합니다.
Ollama 설치
# Linux/WSL
curl -fsSL https://ollama.com/install.sh | sh
# macOS (Homebrew)
brew install ollama
# Windows: https://ollama.com/download에서 설치 파일 다운로드Ollama는 설치 후 자동으로 백그라운드 서비스로 시작합니다. 시스템 재부팅 시도 자동 시작됩니다.
Qwen3.5:4b 모델 다운로드
# Qwen3.5 4B 모델 다운로드 (약 3GB)
ollama pull qwen3.5:4b
# 다른 코딩 특화 모델 옵션
ollama pull qwen3.5:14b # 더 큰 모델 (14B, 약 9GB)
ollama pull deepseek-coder:6.7b # 코딩 특화모델 다운로드 완료 후 확인:
ollama list
# 출력 예시:
# NAME ID SIZE MODIFIED
# qwen3.5:4b abc123def456 3.2 GB 2 minutes ago⚡ Step 3: ollama launch로 빠른 실행
Ollama v0.15+부터 ollama launch 명령으로 별도 설정 없이 Codex를 실행할 수 있습니다:
# 기본 실행 (모델 선택 필요)
ollama launch codex
# 특정 모델로 직접 실행
ollama launch codex --model qwen3.5:4b
# 클라우드 모델 사용 (Ollama Cloud)
ollama launch codex --model qwen3.5:27b-cloud
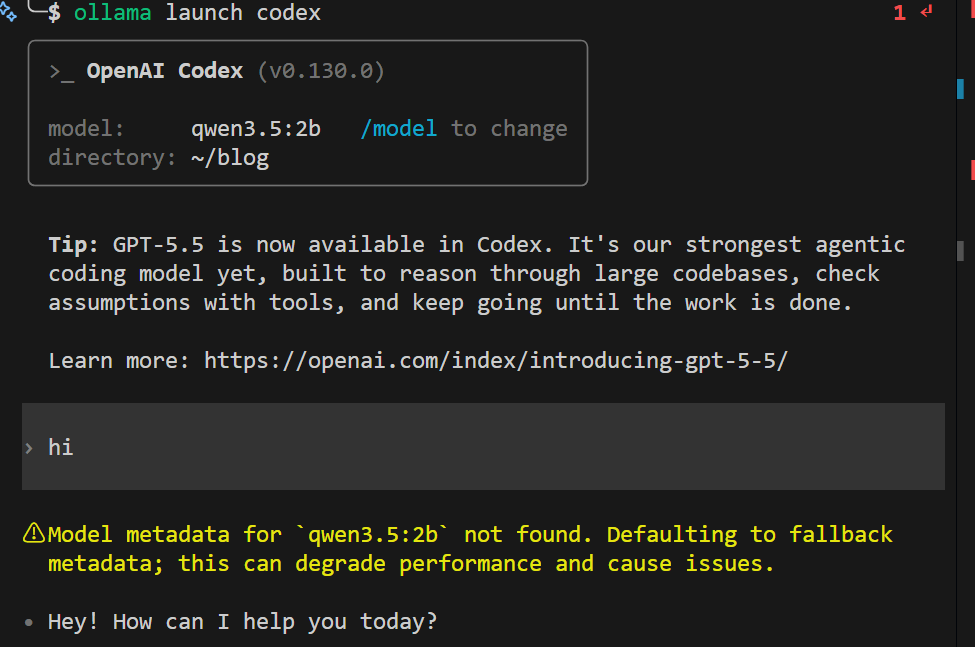
💡 ollama launch의 편리함
ollama launch codex는 config.toml 설정, 환경변수 export, base_url 지정 등 모든 복잡한 과정을 자동으로 처리합니다. 처음 실행 시 모델 선택이 필요하지만, 한 번 설정하면 다음 실행 시 자동으로 같은 모델을 사용합니다.
설정만 하고 실행하지 않으려면:
# 설정만 구성
ollama launch codex --config🔧 Step 4: 수동 설정 (--oss 플래그)
ollama launch 대신 수동으로 설정하려면 --oss 플래그를 사용합니다:
# 기본 오픈소스 모델 실행
codex --oss
# 특정 모델 지정
codex --oss -m qwen3.5:4b
# 클라우드 모델 사용
codex --oss -m gpt-oss:120b-cloud--oss 플래그는 Codex가 OpenAI API 대신 로컬 inference 서버를 사용하게 합니다.

📝 Step 5: config.toml 프로필 설정
영구적인 설정을 위해 ~/.codex/config.toml 파일을 구성합니다:
config.toml 파일 생성
# 파일 위치
~/.codex/config.toml
# 파일이 없으면 생성
mkdir -p ~/.codex
touch ~/.codex/config.tomlOllama 프로필 설정
# ~/.codex/config.toml
[model_providers.ollama-local]
name = "Ollama Local"
base_url = "http://localhost:11434/v1"
[profiles.qwen-4b-local]
model = "qwen3.5:4b"
model_provider = "ollama-local"
[profiles.qwen-14b-local]
model = "qwen3.5:14b"
model_provider = "ollama-local"
[profiles.qwen-cloud]
model = "qwen3.5:27b-cloud"
model_provider = "ollama-local"프로필로 실행:
# 로컬 Qwen3.5:4b 사용
codex --oss --profile qwen-4b-local
# 로컬 Qwen3.5:14b 사용 (더 큰 모델)
codex --oss --profile qwen-14b-local
# 클라우드 모델 사용
codex --oss --profile qwen-cloud📌 base_url 설명
http://localhost:11434/v1은 Ollama의 OpenAI-compatible API endpoint입니다. Codex는 이 endpoint를 통해 로컬 모델과 통신합니다. LM Studio는 http://localhost:1234/v1, llama.cpp는 http://localhost:8000/v1 등 다른 서버는 다른 port를 사용합니다.
🔄 Codex 설정 복원
ollama launch 사용 후 원래 설정으로 복원하려면:
# 원래 프로필로 복원
ollama launch codex --restore이 명령은 Codex App의 설정과 config 파일을 이전 상태로 복원합니다. Codex가 실행 중이면 Ollama가 재시작을 요청합니다. 백업은 ~/.ollama/backup/codex/에 저장됩니다.
🐛 문제 해결
| 문제 | 원인 | 해결 방법 |
|---|---|---|
| codex 명령어 실행 실패 | npm 설치 후 PATH에 연결되지 않음 | npm install -g @openai/codex --force로 재설치 |
| Codex가 열리지 않음 | 첫 실행 시 초기화 필요 | Codex 수동으로 한 번 열고 ollama launch codex 재실행 |
| 모델이 변경되지 않음 | Codex 이미 실행 중 | Codex 종료 후 ollama launch codex 재실행 |
| 모델 다운로드 실패 | 네트워크/저장공간 문제 | Ollama 서비스 확인: ollama serve |
| Context length 오류 | 모델 context window 제한 | 64k+ context 모델 사용 권장 |
| 성능 저하 | KV Cache bug (llama.cpp) | settings.json에 설정 추가 |
📊 Context Window 요구사항
⚠️ 중요: Context Window
Codex는 최소 64k tokens의 context window를 권장합니다. 작은 모델(Qwen3.5:4b)은 context window가 제한적일 수 있어, 큰 파일이나 multi-file 작업에서 문제가 발생할 수 있습니다. Qwen3.5:14b 이상 모델을 권장합니다.
| 모델 | Context Window | 권장 용도 |
|---|---|---|
| Qwen3.5:4b | 32k (제한적) | 단순 코드 수정, 문서 작성 |
| Qwen3.5:14b | 128k | 일반 코딩 작업 (권장) |
| Qwen3.5:32b | 128k | 복잡한 multi-file 작업 |
| Qwen3.5:72b | 256k | 대규모 리팩토링 |
⚖️ 클라우드 vs 로컬 모델 비교
| 비교 항목 | 클라우드 GPT-5 | 로컬 Qwen3.5:4b | 로컬 Qwen3.5:14b |
|---|---|---|---|
| 비용 | API 요청당 비용 | 무료 | 무료 |
| 프라이버시 | 코드 외부 전송 | 100% 로컬 | 100% 로컬 |
| 성능 | ★★★★★ 최고 | ★★☆☆☆ 기본 | ★★★★☆ 우수 |
| Context Window | 200k+ | 32k | 128k |
| Rate Limit | 있음 | 없음 | 없음 |
| 오프라인 | 불가 | 가능 | 가능 |
| 하드웨어 | 필요 없음 | 8GB RAM | 16GB RAM |
🏆 Codex용 최적 로컬 모델
Codex CLI에서 잘 작동하는 로컬 모델 목록:
| 모델 | 크기 | 특징 | VRAM |
|---|---|---|---|
| Qwen3.5:14b | 14B | 코딩 특화, 128k context | 10GB+ |
| DeepSeek-Coder:33B | 33B | 코딩 벤치마크 우수 | 20GB+ |
| Gemma4:26b | 26B | Google 모델, 빠른 추론 | 16GB+ |
| CodeLlama-34B | 34B | Meta 코딩 모델 | 20GB+ |
| Qwen3.5:4b | 4B | 저사양 PC용, 기본 작업 | 3GB |
🎯 맺음말
지금까지 OpenAI Codex CLI를 Ollama와 Qwen3.5:4b 로컬 모델로 무료 실행하는 방법에 대해 알아보았습니다. Codex CLI는 자연어를 코드로 변환, 자동 디버깅, 격리 환경 실행 등 강력한 기능을 제공하며, --oss 플래그와 ollama launch 명령으로 완전 무료로 로컬에서 실행할 수 있습니다.
특히 ollama launch codex는 config 설정, 환경변수, base_url 등 복잡한 과정을 자동으로 처리해 초보자도 쉽게 시작할 수 있습니다. Qwen3.5:4b는 저사양 PC에서도 작동하며, 더 큰 작업에는 Qwen3.5:14b를 권장합니다.
다만 로컬 모델은 클라우드 GPT-5 수준의 성능을 제공하지 않으므로, 복잡한 multi-file 리팩토링이나 대규모 아키텍처 설계에는 한계가 있습니다. 일상적인 코드 설명, 단순 수정, 문서 작성 등에는 충분히 활용 가능합니다.
여러분도 한번 Codex CLI를 Ollama 로컬 모델로 직접 체험해보시길 추천드리면서 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

📚 참고 문헌 및 출처
- Ollama Documentation. (2026). Codex CLI Integration. Retrieved from https://docs.ollama.com/integrations/codex
- OpenAI. (2026). Codex CLI Documentation. Retrieved from https://developers.openai.com/codex/cli/
- Inventive HQ. (2026). How to Run OpenAI Codex CLI with Local Models. Retrieved from https://inventivehq.com/knowledge-base/openai/how-to-use-local-models
- Elisa Terumi. (2026). How to run the Codex CLI locally with Ollama. Retrieved from https://exploringartificialintelligence.substack.com/p/how-to-run-the-codex-cli-locally
- PromptSpace. (2026). OpenAI Codex App + Ollama: Run Locally for $0. Retrieved from https://www.promptspace.in/blog/how-to-use-openai-codex-app-local-models-2026-guide
'AI 도구' 카테고리의 다른 글
| 🧠 AgentMemory: AI 코딩 에이전트에 지속적 메모리 시스템 구축 가이드 (0) | 2026.05.19 |
|---|---|
| 🆓 Claude Code 무료 대안! Mistral Vibe 커스텀 프로바이더 연동 완전 정복 (0) | 2026.05.18 |
| 🤖 Kimi WebBridge: Claude Code·Cursor에서 브라우저 자동화하는 1분 설정법 (0) | 2026.05.16 |
| 🤖 DeepSeek-TUI: Claude Code 대비 1/10 가격 터미널 코딩 에이전트 완벽 가이드 (0) | 2026.05.16 |
| 🖱️👆 Google DeepMind AI Pointer: 50년 만의 마우스 포인터 혁신 + 직접 체험 (0) | 2026.05.15 |



