목차
안녕하세요. 오늘은 구글이 개발한 대규모 언어모델 VideoPoet에 대한 논문을 살펴보겠습니다. VideoPoet은 구글 리서치에서 개발한 대규모 언어 모델로, 텍스트 입력을 통해 제로샷(Zero-Shot) 비디오 생성을 수행하는 능력을 갖춘 모델입니다. 이 블로그에서는 VideoPoet의 구조와 특징, 동작원리, DEMO 콘텐츠 등을 확인하실 수 있습니다. 그럼 출발하시죠~
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문 개요 및 목적
- 논문 제목 : "VideoPoet: A Large Language Model for Zero-Shot Video Generation"
- 논문 저자 : Google Research
- 논문 게재 사이트 : https://arxiv.org/abs/2312.14125
- 논문 게재일 : 2023년 12월
이 논문의 주요 목적은 대규모 언어 모델을 활용하여 Zero-Shot Video Generation 기술을 제시하고, 이를 통해 다양한 비디오 생성 작업에서 우수한 성능을 달성하는 것입니다.
제로샷(Zero-Shot) 비디오 생성은 모델이 특정 작업에 대한 사전 훈련을 받지 않았음에도 새로운 도메인이나 작업에 대한 생성을 수행할 수 있는 것을 의미합니다. VideoPoet에서 제로샷 비디오 생성은 모델이 비디오를 생성할 때 이전에 보지 못한 텍스트 입력에 대해 특별한 훈련 없이도 새로운 입력에 대한 출력을 생성하는 능력을 나타냅니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문의 연구내용 및 결과
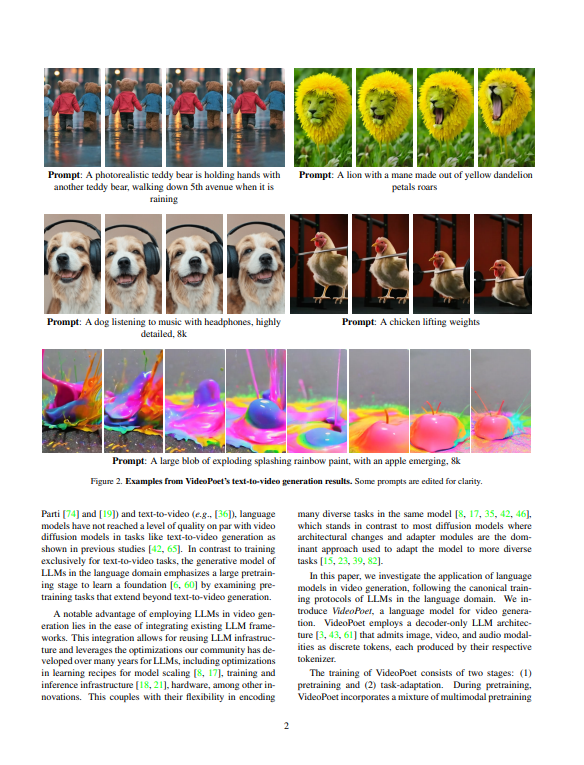
논문에서 제시한 기술은 VideoPoet라는 대규모 언어 모델을 활용한 Zero-Shot Video Generation입니다. 이 모델은 다양한 비디오 생성 작업에서 높은 품질의 동영상을 생성할 수 있는 능력을 갖추고 있으며, 텍스트 입력을 통해 영상을 생성하고, 이를 통해 특정 주제, 스타일 및 구조에 대해 사용자 지정이 가능한 비디오를 생성할 수 있습니다.
VideoPoet의 원리는 대규모 언어 모델이 텍스트 입력을 이해하고, 이를 기반으로 동적하고 의미 있는 비디오를 생성하는 것에 있습니다. 모델은 Zero-Shot 학습 프로토콜을 사용하며, 특정 비디오 벤치마크 데이터에 대한 학습이 없이도 높은 품질의 비디오를 생성할 수 있습니다. 이는 텍스트에서 비디오로의 변환이나 프레임 예측과 같은 작업에서 성능이 우수하게 나타납니다.
VideoPoet의 아키텍처
VideoPoet은 Transformer 아키텍처를 기반으로 하며, 여러 작업을 동시에 학습하는 다중 작업 학습을 통해 다양한 도메인(예: 이미지, 텍스트, 오디오 등)의 데이터 패턴을 학습합니다. 또한 제로샷(Zero-Shot) 생성 모델의 성능을 평가하는 프로토콜(Zero-Shot Generation Evaluation Protocol)을 사용하여 특정 작업에 대한 사전 훈련 없이도 텍스트 입력을 통해 비디오를 생성하고 평가할 수 있습니다.
Transformer 아키텍처는 자연어 처리 및 시퀀스 학습 작업에 사용되는 강력한 딥러닝 모델입니다. 이 모델은 어텐션 메커니즘(attention mechanism)을 사용하여 입력 시퀀스의 각 요소 간의 관계를 동적으로 학습합니다. 이를 통해 시퀀스의 장기 의존성을 잘 캡처하고 병렬 계산을 가능하게 합니다. 장기 의존성(long-term dependency)은 일련의 순차적인 요소들로 이루어진 시퀀스 데이터에서 현재 위치와 먼 과거의 위치 간에 존재하는 의존 관계를 나타냅니다. 특히, 언어나 시계열 데이터에서 특정 요소가 먼 과거의 요소에 영향을 받거나 그 반대로 현재 요소가 미래의 여러 단계에 걸쳐 영향을 미치는 경우를 가리킵니다.
Transformer 아키텍처에서는 인코더와 디코더라는 두 부분으로 구성됩니다. 인코더는 입력 시퀀스를 잘 이해하고, 디코더는 이를 기반으로 출력을 생성합니다. 어텐션 메커니즘은 특정 위치의 출력에 영향을 주는 입력의 다른 위치에 가중치를 부여하는 방식으로 작동하여 모델이 입력 시퀀스의 중요한 부분에 더 집중할 수 있도록 도와줍니다.
어텐션 메커니즘(Attention Mechanism)은 딥 러닝 모델에서 주어진 입력 시퀀스의 특정 부분에 "주의"를 기울이는 메커니즘입니다. 이는 모델이 입력 시퀀스의 다양한 부분에 동적으로 가중치를 부여하고, 특정 단어나 위치에 집중하여 출력을 생성하도록 함으로써 모델의 성능을 향상시킵니다.
어텐션 메커니즘은 주로 시퀀스-투-시퀀스(Seq2Seq) 모델과 같은 자연어 처리 작업에서 많이 사용됩니다. 어텐션 메커니즘은 크게 세 가지 주요 요소로 구성됩니다:
- 쿼리(Query): 어텐션 메커니즘이 어디에 주의해야 하는지를 결정하는데 사용되는 정보입니다. 쿼리는 일반적으로 디코더의 현재 상태나 출력과 관련이 있습니다.
- 키(Key): 입력 시퀀스의 각 요소에 대한 정보입니다. 키는 입력 시퀀스의 각 위치에서 얼마나 중요한지를 나타냅니다.
- 값(Value): 주어진 위치의 키에 대응하는 값입니다. 어텐션 가중치(attention weights)는 키와 관련하여 값을 조절하는 데 사용됩니다.
일반적인 어텐션 메커니즘의 동작은 다음과 같습니다:
- 쿼리(Query)와 모든 키(Key) 간의 유사도를 계산합니다.
- 유사도를 소프트맥스 함수를 사용하여 정규화합니다. 이렇게 얻은 어텐션 가중치는 각 키(Key)에 대한 중요성을 표현합니다.
- 어텐션 가중치를 값(Value)에 곱하여 가중 평균을 계산합니다.
- 최종적으로 얻은 가중 평균을 모델의 출력에 추가하거나 결합하여 최종 예측을 생성합니다.
어텐션 메커니즘은 주로 자연어 처리 작업에서 문장의 길이나 구조에 민감한 모델을 만드는 데에 사용되며, 번역, 요약, 이미지 캡션 등의 작업에서 탁월한 성능을 보여줍니다.
비디오 생성을 위한 언어모델의 훈련 방법
- 토큰화(Tokenization): 먼저, 비디오와 오디오 데이터를 작은 단위로 나누는 토큰화 작업을 수행합니다. 이 작업은 데이터를 모델이 이해하기 쉬운 토큰이라 불리는 작은 부분으로 분해하는 과정입니다.
- 텍스트-페어링 및 비페어링 데이터 활용: 훈련 데이터에는 두 가지 유형의 정보가 있습니다. 하나는 텍스트로 설명된 비디오 및 오디오 정보인 텍스트-페어링 데이터이고, 다른 하나는 비텍스트로만 존재하는 비페어링 된 데이터입니다. 텍스트-페어링 데이터는 모델에게 언어적인 맥락을 학습시키고, 비페어링 된 데이터는 비교적 덜 정형화된 상황에서의 학습을 가능케 합니다.
- 모델 학습: 토큰화된 데이터를 사용하여 모델을 훈련합니다. 모델은 이러한 토큰들 간의 관계를 학습하여 문장, 문맥, 그리고 시간적 상관관계를 이해하게 됩니다. 이 과정에서 텍스트와 비디오, 오디오 정보를 통합적으로 활용하여 다양한 멀티모달 학습이 이루어집니다.
이렇게 훈련된 언어 모델은 텍스트로 주어진 입력에 대해 의미 있는 비디오 생성을 수행할 수 있는 능력을 갖추게 됩니다. 간단한 훈련 절차에도 불구하고 이 모델은 다양한 비디오 생성 작업에서 강력한 성능을 보입니다.
VideoPoet의 시퀀스 구조
다음은 VideoPoet 시스템의 순서배치도입니다.
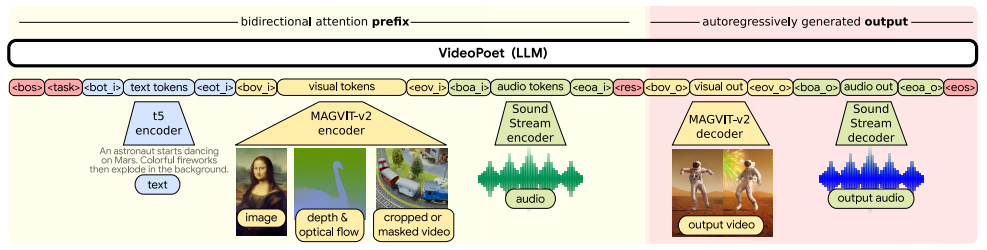
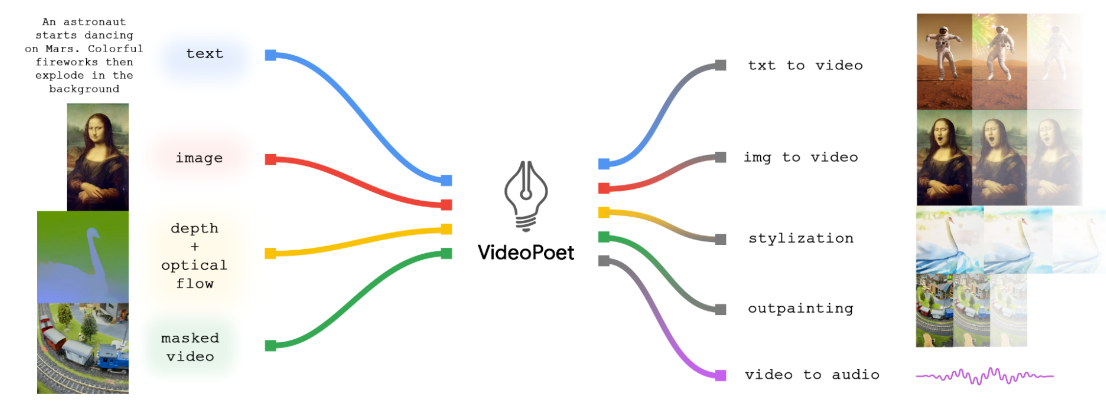
- 1. 입력 시퀀스: 모델의 입력 시퀀스는 다양한 모달리티를 포함합니다. 텍스트, 이미지, 비디오와 같은 다양한 형태의 데이터가 시퀀스로 구성됩니다. 텍스트 입력은 자연어 텍스트 시퀀스로, 이미지 입력은 픽셀 값의 이미지 시퀀스로, 비디오 입력은 프레임의 연속으로 표현됩니다.
- 2. 토크나이저와 임베딩: 입력 시퀀스는 토크나이저를 통해 토큰으로 분할되고, 이 토큰들은 임베딩 레이어를 통해 연속적인 벡터로 변환됩니다. 임베딩된 정보는 모델이 텍스트, 이미지, 비디오 등을 이해하고 처리할 수 있는 형태로 변환됩니다.
- 3. Transformer 아키텍처: VideoPoet은 Transformer 아키텍처를 기반으로 합니다. Transformer는 주로 언어 모델링에 사용되었지만, VideoPoet에서는 비디오 생성과 관련된 여러 작업에 활용됩니다. Self-attention 메커니즘을 사용하여 입력 시퀀스의 각 요소 간의 상호 작용을 모델링합니다.
- 4. 다중 작업 학습: 모델은 다양한 작업에 대한 다중 작업 학습을 수행합니다. Text-to-Video, Image-to-Video, Video Styling 등의 작업을 통해 모델은 각 작업에 대한 능력을 향상시킵니다. 다중 작업 학습을 통해 모델은 여러 도메인에서의 다양한 데이터 패턴을 학습하게 됩니다.
- 5. Zero-Shot 학습 프로토콜: Zero-Shot Generation Evaluation Protocol을 사용하여 모델의 성능을 평가합니다. 이는 특정 작업에 대한 사전 훈련 없이 텍스트 입력을 통해 비디오를 생성하고 평가하는 방식입니다.
- 6. 시퀀스 출력: 모델의 출력은 비디오 또는 이미지의 시퀀스로 구성됩니다. Zero-Shot Generation에서는 주어진 텍스트 입력에 기반하여 비디오를 생성하고 이를 출력 시퀀스로 제공합니다.
VideoPoet의 동작 원리
VideoPoet은 다양한 모달리티의 데이터를 통합하여 학습한 다목적 언어 모델입니다. VideoPoet은 학습 단계에서 텍스트에 대응하는 비디오 및 오디오 데이터를 학습합니다. 이 학습된 관계를 활용하여 새로운 텍스트 입력에 대한 비디오를 생성하는 과정은 다음과 같이 이루어집니다:
- 1. 텍스트 입력 이해: 새로운 텍스트 입력이 모델에 주어지면, 모델은 언어 이해 능력을 활용하여 텍스트의 의미를 이해합니다. 이때, 모델은 학습 단계에서 텍스트와 해당하는 비디오, 오디오 데이터 간의 관계를 학습했으므로, 텍스트에 대응하는 시각적 및 오디오적 특징을 추론할 수 있습니다.
- 2. 시각/오디오 생성: 텍스트 이해 단계 이후, 모델은 자체의 생성 능력을 활용하여 새로운 비디오와 오디오를 생성합니다. 이때, 모델은 학습 단계에서 습득한 시각적 및 오디오적 패턴을 기반으로 새로운 텍스트 입력에 대한 다양한 시뮬레이션을 수행합니다.
- 3. Zero-Shot Learning: 학습하지 않은 텍스트에 대한 생성이 Zero-Shot Learning 원리에 기반합니다. 모델은 학습 단계에서 텍스트와 관련된 시각/오디오 특징을 학습하면서, 이러한 특징들 간의 일반적인 관계를 습득합니다. 그래서 학습되지 않은 텍스트에 대해서도 학습된 관계를 활용하여 유추하고, 이를 바탕으로 새로운 비디오를 생성합니다.
사전에 학습되지 않은 새로운 텍스트 입력에 대한 예측을 하기 위해 VideoPoet은 다음과 같은 방식으로 작동합니다.
- 1. 텍스트 임베딩과 모달리티 토큰: 주어진 텍스트 입력은 먼저 텍스트 임베딩으로 변환됩니다. 이 텍스트 임베딩은 모델이 언어적 맥락을 이해하고 다른 모달리티의 데이터와 연결하는 데 사용됩니다.
- 2. 비디오, 이미지, 오디오 데이터의 토큰화: 비디오, 이미지, 오디오 데이터는 각각 모달리티별로 토큰화됩니다. 각 모달리티의 데이터가 이산 토큰으로 변환되어 모델이 처리할 수 있는 형태로 만들어집니다.
- 3. 입력 데이터의 통합: 텍스트 임베딩과 각 모달리티의 토큰이 결합되어 모델의 입력으로 제공됩니다. 이렇게 하면 모델은 다양한 모달리티의 정보를 통합하여 하나의 입력 시퀀스로 처리할 수 있습니다.
- 4. 예측과 시뮬레이션: VideoPoet은 주어진 텍스트 설명에 기반하여 다양한 모달리티의 데이터를 생성하려고 노력합니다. 텍스트에 대한 언어적 이해와 함께 시각적 및 청각적 특성을 결합하여 새로운 비디오를 예측하고 시뮬레이션합니다.
- 5. 자기회귀적 예측: VideoPoet은 자기회귀적인 방식으로 작동합니다. 즉, 이전 예측에서 생성된 정보가 현재 예측의 일부로 사용되어 다음 예측을 수행하게 됩니다. 이는 모델이 이전 단계에서 생성한 내용을 바탕으로 단계적으로 더 높은 수준의 텍스트 및 모달리티 데이터를 예측하고 생성하는 것을 의미합니다.
이러한 방식으로 VideoPoet은 다양한 모달리티의 데이터를 활용하여 새로운 텍스트 입력에 대한 예측을 수행하고, 이를 시뮬레이션하여 다목적 비디오 생성을 실현합니다.
요약하면, VideoPoet은 학습된 텍스트-비디오/오디오 관계를 활용하여 새로운 텍스트 입력에 대한 비디오를 생성하는 데에 성공합니다. 이는 학습 초기에 모델이 다양한 데이터로부터 언어와 시각/오디오 간의 연결을 학습했기 때문에 가능한 것입니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
VideoPoet의 주요 특징 및 성능평가
- 모델 크기 및 학습 데이터 규모: VideoPoet은 대규모 언어 모델로, 모델의 크기는 300만, 10억, 80억 개의 파라미터로 실험되었습니다. - 모델은 58억 비주얼 토큰과 37억 오디오 토큰으로 이루어진 데이터셋에서 학습되었습니다.
- Zero-Shot Video Generation: VideoPoet은 Zero-Shot 학습 프로토콜을 사용하여, 특정 비디오 벤치마크에 대한 사전 학습 없이도 텍스트 입력을 통해 높은 품질의 동영상을 생성합니다. 텍스트 입력에는 예측 프레임, 비디오 스타일 및 특정 구조 등의 정보가 포함될 수 있습니다.
- 다양한 작업 수행 능력: VideoPoet은 다양한 작업에 적용 가능한 범용적인 능력을 갖추고 있습니다. 텍스트 입력을 통해 비디오를 생성할 뿐만 아니라, 이미지에서 비디오로, 3D 구조 및 카메라 모션의 이해, 그리고 다양한 비디오 편집 작업도 수행할 수 있습니다.
- 성능평가 및 경쟁력: MSR-VTT, UCF-101, Kinetics 600 등 다양한 벤치마크에서 VideoPoet은 다른 비디오 생성 모델들과 비교하여 경쟁력 있는 성과를 보여줍니다. CLIP similarity score, FVD, Inception Score 등의 측정기준을 사용하여 비디오 생성 품질을 평가하며, 특히 Zero-Shot 학습에서도 우수한 성능을 보입니다.
- 종합적인 작업 능력: VideoPoet은 텍스트 입력을 통한 비디오 생성뿐만 아니라, 다양한 작업들을 체인 형태로 연결하여 수행할 수 있습니다. 이미지에서 비디오로의 변환, 비디오 스타일라이징, 3D 구조 및 카메라 모션 제어 등 다양한 능력을 종합적으로 보유하고 있습니다.
VideoPoet DEMO 사이트
아래 링크를 통해 다음과 같은 VideoPoet의 비디오 생성 기능을 체험해 보실 수 있습니다.
- 시각적 묘사 - 프롬프트를 시간에 따라 변경하여 시각적 이야기를 전할 수 있습니다.
- 긴 비디오 생성 - 기본적으로 VideoPoet은 2초의 비디오를 생성합니다. 그러나 모델은 또한 1초의 비디오 클립 입력을 받아 1초의 비디오 출력을 예측함으로써 무한히 반복되어 어떠한 길이의 비디오도 생성할 수 있습니다.
- 제어 가능한 비디오 편집 - VideoPoet 모델은 주제를 다양한 동작(댄스 스타일 등)을 따르도록 편집할 수 있습니다.
- 인터랙티브 비디오 편집 - 추가적인 프롬프트 없이 입력 비디오를 확장한 몇 가지 후보 비디오를 제시하고, 이를 통해 더 긴 비디오에서 원하는 동작을 정밀하게 제어할 수 있습니다.
- 이미지에서 비디오 생성 - VideoPoet은 어떠한 입력 이미지라도 주어진 텍스트 프롬프트와 일치하는 비디오를 생성할 수 있습니다.
- 제로샷 스타일라이제이션 - VideoPoet은 텍스트 프롬프트에 따라 입력 비디오를 스타일화 할 수 있으며, 매력적인 프롬프트 스타일 준수 성능을 보여줍니다.
- 시각적 스타일 및 효과 적용 - 스타일 및 효과는 텍스트-투-비디오 생성에서 쉽게 조합될 수 있습니다.
- 제로샷 제어 가능한 카메라 모션 - 텍스트 프롬프트에서 카메라 샷의 유형을 지정함으로써 고품질의 카메라 모션 사용자 정의가 가능합니다.
https://sites.research.google/videopoet/
VideoPoet – Google Research
A Large Language Model for Zero-Shot Video Generation. VideoPoet demonstrates simple modeling method that can convert any autoregressive language model into a high quality video generator.
sites.research.google

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문의 결론 및 전망
이 논문은 VideoPoet이라는 대규모 언어 모델을 활용한 Zero-Shot Video Generation 기술을 제시하였습니다. 높은 품질의 비디오 생성 능력을 바탕으로 VideoPoet은 다양한 작업에서 우수한 성능을 보여주며, 특히 텍스트 입력을 통한 Zero-Shot 학습 프로토콜을 통해 벤치마크에 대한 사전 학습이 없이도 뛰어난 성과를 달성했습니다. 논문의 결과를 토대로, 대규모 언어 모델이 비디오 생성 분야에서의 활용 가능성과 향후 연구 방향을 모색할 수 있을 것으로 전망됩니다.
이러한 발전은 생성형 AI의 미래에 많은 가능성을 열어놓습니다. 예측 불가능한 도메인에서도 효과적으로 작동하는 Zero-Shot 학습은 실제 환경에서의 응용 가능성을 높여주며, 비디오 생성 분야에서 뛰어난 품질과 다양성을 제공하는 모델은 창의적이고 혁신적인 비디오 콘텐츠의 생산에 기여할 것으로 기대됩니다.
이상으로 구글의 새로운 비디오 생성을 위한 대규모 언어 모델 VideoPoet에 대해서 알아보았습니다. 이제 누구나 쉽게 상상하는 것을 비디오 작품으로 만들 수 있는 시대가 된 거 같습니다. 저는 그럼 다음에 더 유익한 자료를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2023.12.22 - [AI 논문 분석] - [AI 논문 리뷰] 대규모 언어 모델을 위한 애플의 메모리 최적화 기술
[AI 논문 리뷰] 대규모 언어 모델을 위한 애플의 메모리 최적화 기술
안녕하세요. 오늘은 애플이 제한된 메모리 상에서 대규모 언어 모델 추론을 효과적으로 수행하는 혁신적인 기술을 제시한 논문에 대해 살펴보겠습니다. 이 논문은 윈도잉과 로우-칼럼 번들링이
fornewchallenge.tistory.com
'AI 논문 분석' 카테고리의 다른 글
| SOLAR 10.7B: 대규모 언어 모델의 효과적인 깊이 업스케일링 (2) | 2023.12.31 |
|---|---|
| FERRET: 이미지에서 무엇이든 찾아서 표현하는 애플의 언어 모델 (0) | 2023.12.25 |
| [AI 논문 리뷰] 대규모 언어 모델을 위한 애플의 메모리 최적화 기술 (0) | 2023.12.22 |
| AI 논문 분석: 대규모 언어 모델을 활용한 프로그램 탐색, FunSearch (0) | 2023.12.19 |
| AI 논문 분석 : 이미지 애니메이션의 혁신 라이브포토(LivePhoto) (2) | 2023.12.12 |




