목차
안녕하세요. 오늘은 애플이 제한된 메모리 상에서 대규모 언어 모델 추론을 효과적으로 수행하는 혁신적인 기술을 제시한 논문에 대해 살펴보겠습니다. 이 논문은 윈도잉과 로우-칼럼 번들링이라는 새로운 개념을 소개합니다. 이 블로그에서는 이러한 기술이 어떻게 대규모 언어 모델의 실행을 혁신적으로 변화시키는지, 그리고 플래시 메모리를 활용하여 데이터 전송 및 메모리 사용을 어떻게 최적화하는지에 대해 알아보겠습니다. 그럼 시작해 볼까요?
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문 개요 및 목적
- 논문 제목: "LLM in a Flash: Efficient Large Language Model Inference with Limited Memory"
- 논문 저자: Keivan Alizadeh, Iman Mirzadeh, 및 Apple 팀
- 논문게재 사이트: arXiv
- 논문게재일: 2023년 12월

이 논문의 주요 목적은 제한된 DRAM 용량에서도 대규모 언어 모델(Large Language Models, LLMs)을 효율적으로 실행하기 위한 전략을 개발하고 제시하는 것입니다. 특히, 플래시 메모리를 활용하여 데이터 전송 및 메모리 사용을 최적화하는 혁신적인 기술들을 소개하고 있습니다. 다음은 플래시메모리와 DRAM의 기본적인 개념입니다.
- 플래시 메모리: 플래시 메모리는 비휘발성 메모리로, 전원이 꺼져도 데이터를 유지할 수 있습니다. 주로 휴대전화, USB 플래시 드라이브, SSD(솔리드 스테이트 드라이브) 등의 저장 매체에 사용됩니다.
- DRAM(Dynamic Random Access Memory): DRAM은 주로 주기억장치 또는 RAM이라고 불리며, 데이터를 일시적으로 저장하고 전원이 꺼지면 내용이 손실되는 휘발성 메모리입니다.
플래시 메모리는 일반적으로 더 큰 저장 용량을 가지지만 DRAM보다 느린 속도와 높은 읽기/쓰기 지연시간을 갖는 특성이 있습니다. 그러나 플래시 메모리는 전원이 꺼져도 데이터가 보존되는 비휘발성 메모리로서, 영구적인 데이터 저장에 적합합니다. 논문에서 제시한 방식은 플래시 메모리를 사용하여 DRAM 용량을 초과하는 대규모 언어 모델을 효율적으로 실행하는 방법에 중점을 두고 있습니다.
논문의 연구내용 및 결과
논문에서는 기존 대규모 언어 모델의 추론 프로세스에서 발생하는 메모리 부담을 최소화하기 위한 혁신적인 알고리즘을 제안합니다. 다음은 논문의 주요 연구내용 및 결과입니다.
윈도잉(Windowing) 기술
윈도잉(Windowing)은 논문에서 제안하는 대규모 언어 모델의 실행 방법 중 하나로, 각 시퀀스에 대해 한 번에 하나의 토큰만 처리하면서 메모리에 일부만을 로드하고 유지하는 기술입니다. 이 기술은 DRAM(Dynamic Random Access Memory) 및 GPU 메모리의 일부만을 사용하여 데이터 전송을 최소화하고 메모리 사용 효율성을 향상시킵니다. 구체적으로 윈도잉이 동작하는 방식은 다음과 같습니다.
- 한 번에 하나의 토큰 처리: 시퀀스(또는 쿼리)를 처리할 때 한 번에 하나의 토큰만을 고려합니다. 이는 모델이 현재 처리 중인 토큰에 집중하고, 다음 토큰으로 이동하기 전에 이전 토큰을 처리하도록 하는 기법입니다.
- 일부 메모리 로드: 현재 처리 중인 토큰에 필요한 데이터만을 메모리에 로드합니다. 이때, 모델이 현재 위치에서의 일부 데이터만을 DRAM에 유지하고, 그 외의 데이터는 플래시 메모리 등의 다른 저장 매체에 저장됩니다.
- 동적 메모리 할당 및 해제: 윈도잉 기술은 동적으로 메모리를 할당하고 해제합니다. 현재 처리 중인 토큰에 필요한 메모리를 동적으로 할당하고, 이전에 처리한 토큰의 메모리는 효율적으로 해제하여 메모리 사용을 최적화합니다.
- 효율적인 뉴런 삭제 및 추가: 언어 모델이 문장이나 문맥을 처리하면서 일부 뉴런이 더 이상 필요하지 않거나 중요하지 않은 것으로 판단될 때, 이 불필요한 뉴런들을 효과적으로 식별하고 삭제합니다. 이로써 모델은 불필요한 정보를 저장하는 메모리 자원을 절약하고 더 빠르게 처리를 진행할 수 있게 됩니다.
모델이 처리 중인 토큰이나 현재 작업에 필요한 정보는 DRAM에 유지되어 빠르게 접근 가능하게 되고, 필요 없는 부분은 플래시 메모리에 임시로 저장됩니다. 이로써 전체 모델이 한 번에 DRAM에 올라오지 않더라도 효율적으로 처리가 가능하며, DRAM의 제한된 용량을 극복할 수 있습니다. 이러한 방식으로 윈도잉은 한 번에 하나의 토큰을 처리하면서도 모델이 더 큰 시퀀스를 처리할 수 있도록 하고, 메모리를 효율적으로 활용하여 대규모 언어 모델의 실행을 가능케 합니다.
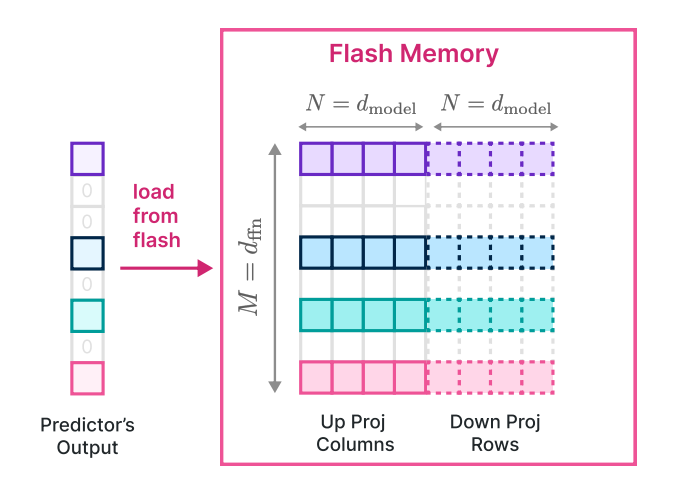
로우-칼럼 번들링(Row-Column Bundling) 기술
로우-칼럼 번들링은 데이터 처리량을 개선하고 메모리 사용을 효율화하기 위한 전략 중 하나로 소개되었습니다. 업 프로젝트(Up project)와 다운 프로젝트(Down project)에서 열과 행을 번들로 묶어 함께 로드하여 플래시 메모리로부터 효율적으로 데이터를 읽어옵니다. 이를 통해 데이터의 구조를 고려하여 동시에 여러 데이터를 묶어 처리함으로써 전체적인 성능을 향상시킵니다.
- 업 프로젝트(Up project): 모델의 입력에서 출력 방향으로 데이터를 처리하는 과정입니다. 여러 행을 번들로 묶어 동시에 처리하여 데이터를 전방향(Forward)으로 전달합니다.
- 다운 프로젝트(Down project): 모델의 출력에서 입력 방향으로 데이터를 처리하는 과정입니다. 여러 열을 번들로 묶어 동시에 처리하여 데이터를 역방향(Backward)으로 전달합니다.
로우-칼럼 번들링은 대규모 언어 모델이 다차원 행렬로 표현되는 가중치 행렬에 적용되는 기술입니다. 모델의 입력과 출력은 일반적으로 행렬의 형태를 가지며, 이 행렬에는 단어나 토큰에 대한 정보가 포함되어 있습니다.
로우-칼럼 번들링의 핵심 아이디어는 행렬의 특정 부분, 즉 로우와 칼럼을 함께 번들로 묶어 처리함으로써 데이터를 효율적으로 로드하고 관리하는 것입니다. 이를 통해 데이터 전송 속도를 개선하고 메모리 관리의 효율성을 증대시킬 수 있습니다. 구체적으로는 다음과 같은 특징을 갖고 있습니다:
- 동시에 여러 데이터 로드: 로우-칼럼 번들링은 열과 행을 번들로 묶어서 함께 로드함으로써 한 번에 여러 데이터를 처리할 수 있습니다. 이는 플래시 메모리로부터 효율적으로 데이터를 읽어오는 데 기여하며, 데이터 처리량을 향상시킵니다.
- 플래시 메모리 저장 방식: 로우-칼럼 번들링은 플래시 메모리의 특성을 고려하여 데이터를 저장하고 로드하는 방식을 최적화합니다. 특히, 캐싱을 적절히 활용하여 DRAM의 메모리 소비를 최소화하고 플래시 메모리의 효율을 극대화합니다.
- 데이터 처리량 개선: 번들로 묶어 함께 처리함으로써 데이터 처리량이 개선됩니다. 열과 행을 효율적으로 관리하면서 필요한 데이터를 빠르게 읽어올 수 있어, 모델의 실행 속도를 향상시키는 데 기여합니다.
로우-칼럼 번들링은 윈도잉과 함께 사용되어 대규모 언어 모델의 실행을 최적화하는 중요한 전략 중 하나로 떠오르고 있습니다. 이 기술은 전체적인 메모리 효율성을 향상시키면서 모델의 성능을 유지하는 데에 기여하고 있습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
효율적인 메모리 사용 알고리즘
이 논문에서 제안된 "효율적인 메모리 사용" 부분은 대규모 언어 모델 추론 시 발생하는 메모리 부담을 최소화하고자 하는 핵심 내용입니다. 아래는 이 부분에 대한 구체적인 설명입니다.
- 가중치 양자화 (Weight Quantization): 신경망의 가중치를 정수 또는 낮은 비트 수의 부동소수점으로 표현하여 메모리 사용을 최적화합니다. 양자화된 가중치는 메모리를 더 효율적으로 활용할 수 있도록 합니다. 기존 기술 대비 작은 모델 크기로 메모리를 절약할 수 있는 효과적인 방법 중 하나입니다.
- 파라미터 공유 (Parameter Sharing): 모델 내에서 중복되는 파라미터를 공유함으로써 메모리 사용을 최적화합니다. 이는 유사한 기능을 수행하는 레이어 간 가중치를 공유함으로써 이루어집니다. 파라미터 공유는 모델의 크기를 줄여주며, 적은 메모리로도 효과적인 모델을 구축할 수 있게 합니다.
- 메모리 풀링 (Memory Pooling) 및 캐시 메커니즘: 동적으로 메모리를 할당하고 해제하는 데에 메모리 풀링을 사용하여 메모리 사용량을 최적화합니다. 메모리 풀이란 프로그램이 실행되기 전에 일정 크기로 미리 할당된 메모리 영역을 말합니다. 캐시 사용 최적화 메커니즘을 도입하여 빠른 데이터 접근이 가능하도록 합니다.
- 메모리 사용량 모니터링 및 최적화 전략: 모델이 실행되는 동안 메모리 사용량을 지속적으로 모니터링하고, 최적화 전략을 동적으로 적용하여 메모리 사용 효율을 꾸준히 향상시킵니다. 상황에 따라 적응적으로 메모리 사용량을 최적화함으로써 모델의 효율성을 유지합니다.
이러한 알고리즘과 기술은 LLM in a flash가 한정된 메모리 자원에서도 효율적으로 동작하도록 하는 핵심적인 방법들입니다. 이러한 구체적인 접근 방식은 대규모 언어 모델이 메모리 사용 측면에서 뛰어난 효율성을 보이게 함으로써, 제한된 기기 자원에서의 성능 향상을 실현하는 데 기여하고 있습니다.
한정된 자원에서의 언어 모델 성능 향상 전략
논문에서는 제한된 자원(메모리 등)에서도 대규모 언어 모델의 성능을 향상하기 위한 다양한 전략을 소개하고 있습니다.
- 모델 아키텍처의 최적화 : 한정된 자원에서의 성능 향상을 위해 모델 아키텍처를 최적화했습니다. 모델의 구조를 단순화하고 불필요한 파라미터를 제거함으로써 모델의 크기를 줄이고, 동시에 핵심적인 언어 표현 능력을 유지했습니다. 이로써 작은 메모리 환경에서도 효율적인 모델 구동이 가능해졌습니다.
- 언어 모델 알고리즘의 최적화 : 한정된 자원에서 성능을 극대화하기 위해 언어 모델의 핵심 알고리즘을 최적화했습니다. 효율적인 토큰화 및 임베딩 기법의 도입, 추론 시간 복잡도 감소를 위한 새로운 알고리즘 적용 등이 포함되어 있습니다. 이로써 한정된 메모리에서도 빠르고 정확한 추론이 가능해졌습니다.
- 경량화된 모델 훈련 : 모델 훈련 과정에서도 자원 효율성을 고려하여 경량화된 훈련 전략을 도입했습니다. 데이터 샘플링 및 배치 처리 방법의 최적화, 효율적인 하드웨어 가속 활용 등이 통합되어, 제한된 자원에서도 높은 성능의 모델을 효율적으로 훈련시킬 수 있게 되었습니다.
- 다중 태스크 학습 : 다중 태스크 학습을 통해 제한된 자원에서의 성능을 극대화했습니다. 모델은 여러 언어 태스크를 동시에 학습하고, 이를 통해 효과적으로 정보를 전이하면서 자원 사용 효율성을 높였습니다. 이는 제한된 자원에서도 다양한 언어적 요구에 대응할 수 있는 모델을 형성하는 데 기여합니다.
- 언어 모델의 캐싱 및 메모리 관리 : 한정된 자원에서의 성능을 높이기 위해 언어 모델의 캐싱 및 메모리 관리 방식을 최적화했습니다. 이는 빈번한 추론 작업에서 중복되는 연산을 최소화하고, 이전 결과를 효과적으로 활용함으로써 추론 성능을 향상시키는 데 기여합니다.
이러한 다양한 전략들이 결합되어, 제한된 자원에서도 대규모 언어 모델의 성능을 극대화하는 효과를 얻었습니다. 다음은 기존 기술과 애플의 LLM in a flash 기술의 비교표입니다.
| 항목 | LLM in a Flash | 기존 기술 |
| 메모리 최적화 알고리즘 | - 가중치 양자화, 파라미터 공유 등 종합적 최적화 | - 주로 파라미터 양 최소화에 중점 |
|
메모리 관리 기술 및
동적 조절 |
- 스마트 메모리 할당 및 해제 | - 정적 메모리 할당 및 해제 |
| - 메모리 풀링 및 캐시 메커니즘 적극 활용 | - 풀링 및 캐싱 기능이 제한적 | |
| - 동적 메모리 할당 및 해제 | - 상황에 따른 동적인 조절이 부족 | |
|
데이터 처리량 개선
|
- 윈도잉(Windowing) 기술 | - 윈도잉과 로우-컬럼 번들링은 없거나 제한적 |
| - 로우-컬럼 번들링(Row-Column Bundling) 기술 | ||
| 추론지연 시간 | - 다양한 최적화 기법을 통한 추론 시간 최소화 | - 모델 크기 감소 및 간단한 모델 구조로 최적화 |
연구팀은 실제 테스트와 실험을 통해 새로운 메모리 최적화 기법이 다양한 환경에서 효과적으로 작동함을 입증했습니다. 이에 따라, 기기의 메모리 한계 속에서도 언어 모델의 효율성과 성능을 유지하는 데 성공했습니다.
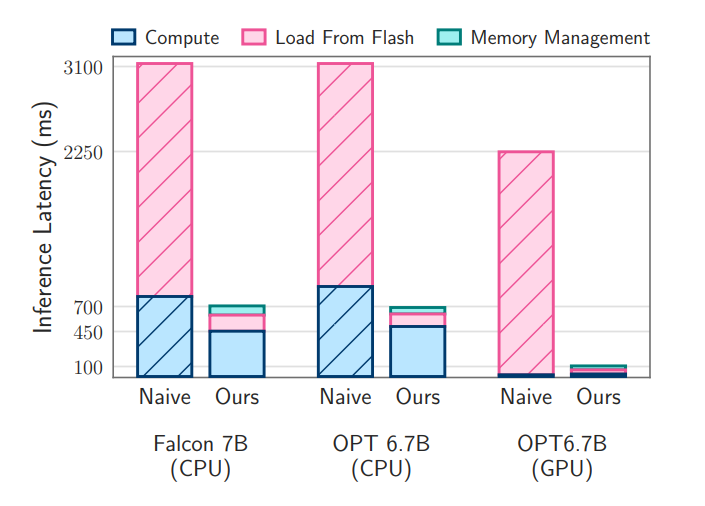
논문에서는 제안된 기법들을 OPT 6.7B 및 Falcon 7B 모델에서 평가하였습니다. 실험 결과, 제안된 기술들이 기존 방법들에 비해 대규모 언어 모델을 실행하는 데 있어서 높은 효율성을 보였습니다. 특히, CPU 및 GPU에서 각각 4-5배 및 20-25배의 속도 향상이 있었습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문의 결론 및 전망
이 논문은 DRAM 용량 제약이 있는 환경에서도 대규모 언어 모델의 실행 효율성을 극대화하기 위한 혁신적인 전략들을 제시하였습니다. 향후에는 이러한 하드웨어 특성을 고려한 추론 최적화 알고리즘 개발이 중요하며, 더 크고 복잡한 언어 모델에 대한 효율적인 실행이 가능할 것으로 전망됩니다.
논문의 결론에서는 새로운 메모리 최적화 방법이 언어 모델 추론 분야에서 혁신적으로 작용함을 확인하였으며, 이를 통해 제한된 자원에서도 대규모 언어 모델의 효율적인 활용이 가능하다는 점이 강조됩니다. 또한, 이러한 결과를 토대로 언어 모델의 미래적인 발전 방향과 새로운 기술 도입에 대한 전망이 소개되었습니다. 이러한 논문의 기술적인 내용과 연구결과는 언어 모델과 메모리 최적화 기술에 관심 있는 연구자 및 엔지니어들에게 중요한 참고 자료가 될 것으로 기대됩니다.
오늘은 대규모 언어 모델을 위한 메모리 최적화 기술에 대해 알아보았습니다. 그럼 저는 다음에 더욱 유익한 정보를 가지고 다시 찾아뵙겠습니다 감사합니다.
2023.12.19 - [AI 논문 분석] - AI 논문 분석: 대규모 언어 모델을 활용한 프로그램 탐색, FunSearch
AI 논문 분석: 대규모 언어 모델을 활용한 프로그램 탐색, FunSearch
안녕하세요, 여러분! 오늘은 대규모 언어 모델을 활용한 프로그램 탐색에 대한 흥미로운 논문을 소개해드리려고 합니다. 이 논문은 Google DeepMind에서 발표한 논문으로, FunSearch라는 새로운 알고리
fornewchallenge.tistory.com
'AI 논문 분석' 카테고리의 다른 글
| FERRET: 이미지에서 무엇이든 찾아서 표현하는 애플의 언어 모델 (0) | 2023.12.25 |
|---|---|
| VideoPoet: 구글의 제로샷(Zero-Shot) 비디오 생성 대규모 언어 모델 (2) | 2023.12.23 |
| AI 논문 분석: 대규모 언어 모델을 활용한 프로그램 탐색, FunSearch (0) | 2023.12.19 |
| AI 논문 분석 : 이미지 애니메이션의 혁신 라이브포토(LivePhoto) (2) | 2023.12.12 |
| AI 논문 분석 : 캐릭터 이미지 한 장으로 애니메이션 만들기, Animate Anyone (4) | 2023.12.05 |




